

Knowledge-Guided Prompt Learning for Few-Shot Text Classification


Abstract
:1. Introduction
2. Method
2.1. Problem Definition
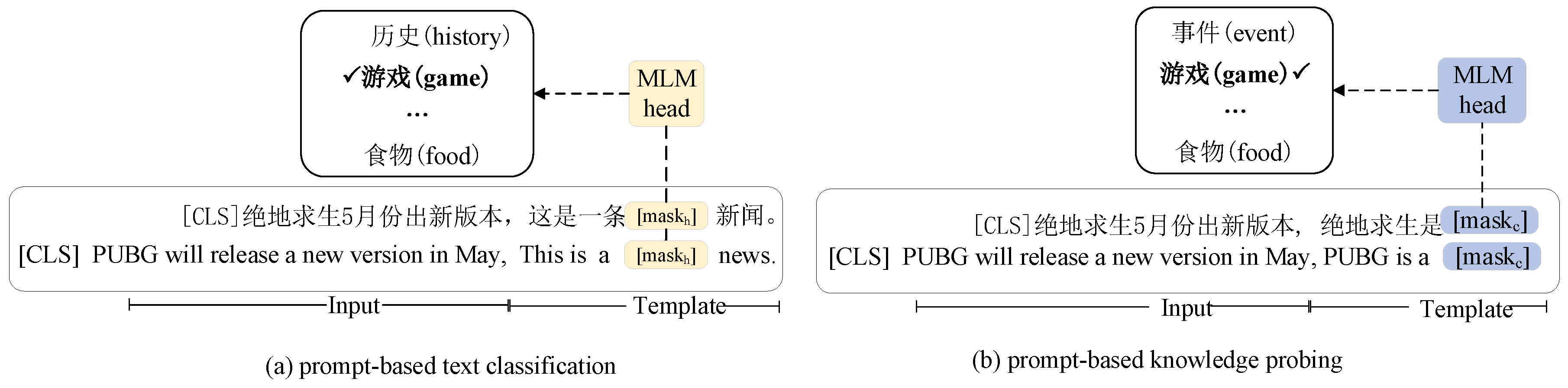
2.2. Prompt-Based Text Classification
2.3. Prompt-Based Knowledge Probing
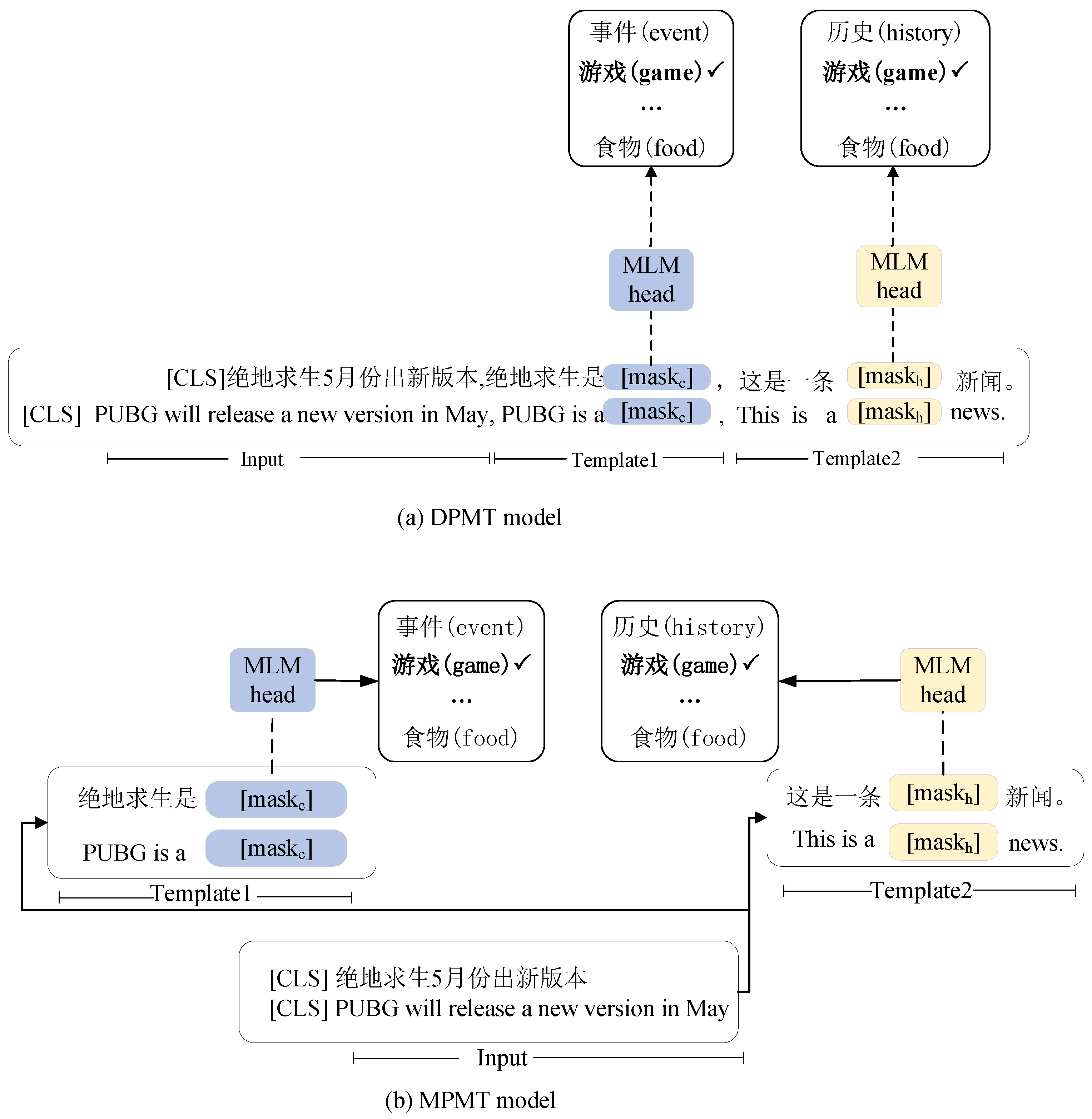
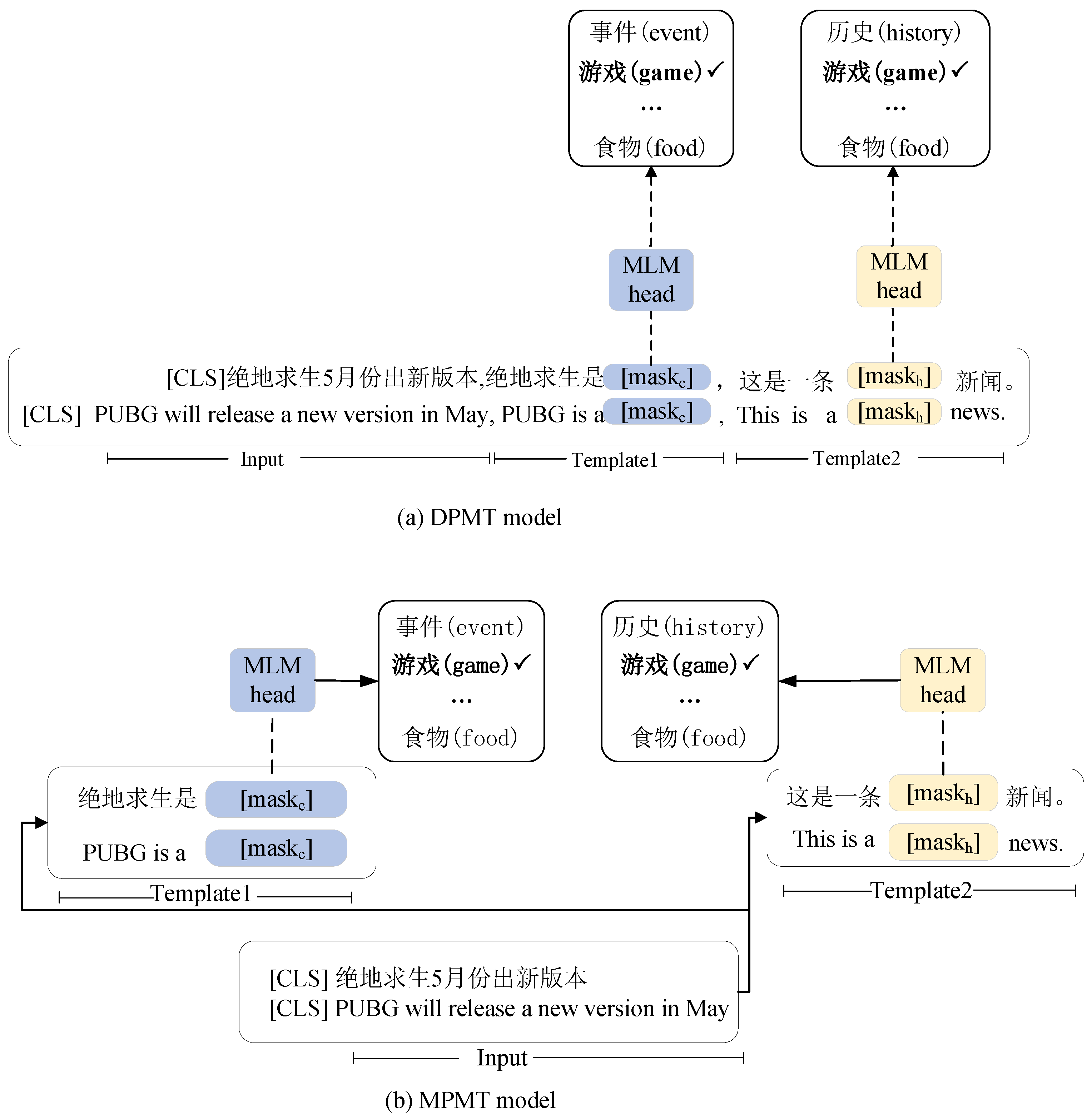
2.4. Knowledge-Guided Models
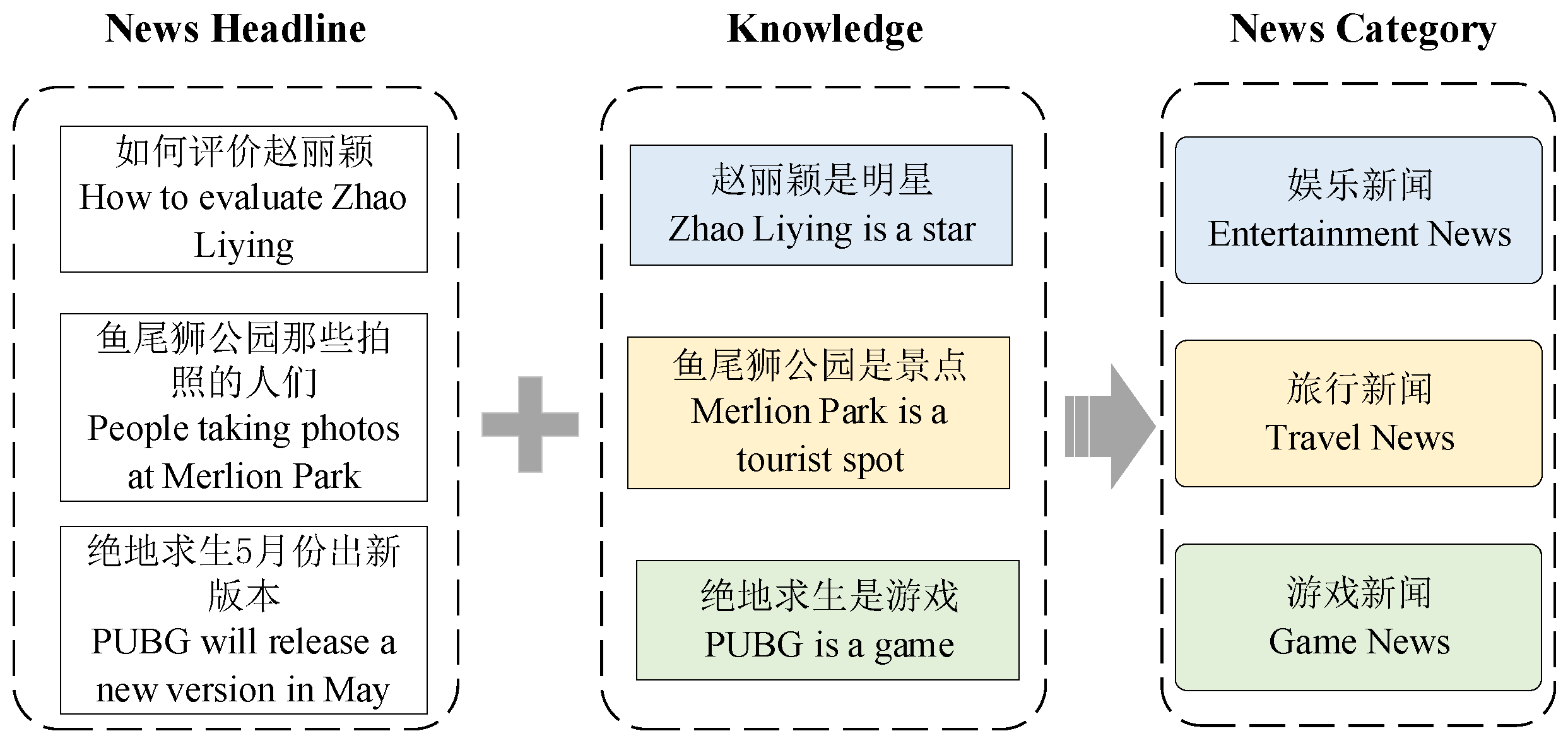
2.4.1. Knowledge-Encoded Template
2.4.2. Multi-Task Framework
3. Experiments
3.1. Datasets and Experiment Settings
- NLPCC: This is a Chinese news headline dataset provided by the NLPCC shared task http://tcci.ccf.org.cn/conference/2017/taskdata.php (accessed on 1 February 2023). The data are collected from several Chinese news websites such as toutiao, sina, and so on.
- THUCNews: This dataset is collected by Tsinghua University http://thuctc.thunlp.org/ (accessed on 1 February 2023); it contains complete news content and corresponding labels. In our experiment, we only used the headlines for classification.
- AIStudio: This is another news headline dataset used for the AIStudio data competition https://aistudio.baidu.com/aistudio/datasetdetail/103654/0 (accessed on 1 February 2023); each headline has an associated category label.
- PTC: This is the prompt-learning-based text classification model we presented in Section 2.2.
- PTCKT: This is our prompt-learning-based text classification model with the knowledge prompting template introduced in Section 2.4.
- DPMT: This is our dependent prompting multi-task model described in Section 2.4.2. In this model, the conceptual knowledge and text label are encoded in one prompting template; thus, their mask slots will be predicted sequentially.
- IPMT: This is our independent prompting multi-task model presented in Section 2.4.2. In this model, the conceptual knowledge and headline label are encoded independently with their own prompting template by sharing the headline text.
- KPT: This is a knowledgeable prompt-tuning method that incorporates knowledge into Prompt Verbalizer for Text Classification [20]. This expands the label word space using external knowledge bases.
- BERT: This is the BERT [22] model for classification. A headline was encoded by BERT, and then, the vector of the first token was used for classification.
- BERT-CNN: This model builds a convolutional neural network (CNN) on top of BERT. It predicts the label after the CNN layer.
- BERT-RNN: Instead of a CNN, a recurrent neural network (RNN) was used to encode the vector on top of BERT.
- BERT-RCNN: Instead of a CNN and an RNN, the combination of a CNN and an RNN was used to encode the vector on top of BERT. After the BERT encoding, the vectors were processed by an RNN and then sent to a CNN before classifying.
3.2. Experimental Results
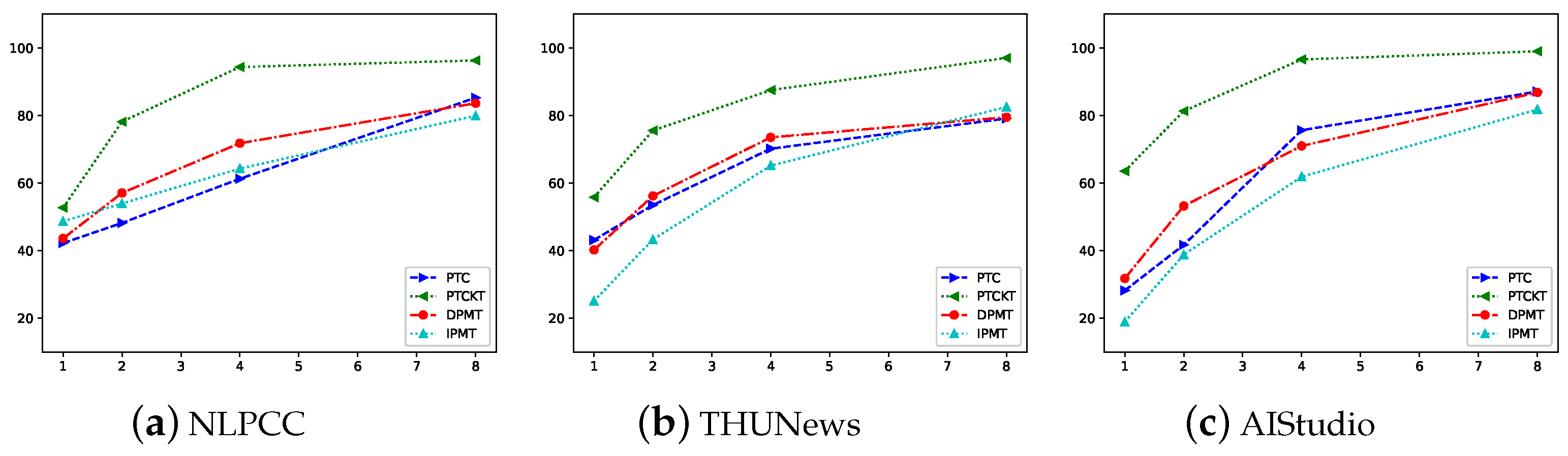
3.3. Impact of Training Data Size
3.4. Impact of Prompting Templates
3.5. Interpretability of Our Models
4. Related Work
- Knowledge probing: As implicit knowledge is learned by pre-training language models when training on a large scale of datasets, knowledge probing [6,23] is proposed to analyze the factual and commonsense knowledge stored in PLMs. Reference [6] utilized a cloze-style prompting template to probe the knowledge that PLMs obtain during pretraining and released a public available dataset for evaluation. After that, various work was performed aimed at extracting such knowledge more effectively [7,24,25]. Different from previous work, Reference [14] proposed to probe domain-specific knowledge instead of general domain knowledge, and they created a biomedical benchmark. The experiments showed that the biomedical-specific PLM contained more biomedical factual information than the general PLM.
- Prompt-based text classification: With the emergence of GPT-3 [10], PLM-based prompt learning has received considerable attention, especially in a few-shot setting. For text classification, Reference [11] proposed the PET model, which utilizes prompt learning to annotate a large unlabeled dataset for future training. After that, prompting research can mainly be divided into two kinds of work: prompt engineering [21,26] and answer engineering [27,28]. Prompt engineering is aimed at choosing a proper prompting template for downstream tasks. For example, instead of setting the prompting template manually, Reference [26] utilized the seq2seq pre-trained model to generate the templates automatically. Answer engineering aims at constructing a suitable map between the prediction space of PLMs and the actual labels. For instance, Reference [20] proposed to make use of a knowledge base to enrich the output space of the certain class.
- Multi-task learning: Multi-task learning, which learns multiple tasks simultaneously, has been widely used in natural language processing. It exploits multiple task-generic and task-specific information, making it suitable for few-shot learning [13]. For example, Reference [29] exploited a multi-task framework to solve two text classification tasks together in the few-shot scenario, and their experimental results demonstrated the effectiveness of the multi-task model. Normally, the related tasks should share parameters in some strategies [29,30]; thus, they are able to reinforce each other by updating the shared parameter during the training process. Recently. Reference [31] developed a system that maps various NLP tasks into human-readable prompted form, combining multi-task learning with prompt learning for zero-shot learning and leading to zero-shot task generalization.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Leeuwenberg, A.; Moens, M.F. Temporal Information Extraction by Predicting Relative Time-lines. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, Brussels, Belgium, 31 October–4 November 2018; pp. 1237–1246. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Takanobu, R.; Zhu, Q.; Huang, M.; Zhu, X. Recent Advances and Challenges in Task-Oriented Dialog Systems. Sci. China Technol. Sci. 2020, 63, 2011–2027. [Google Scholar] [CrossRef]
- Flisar, J.; Podgorelec, V. Improving short text classification using information from DBpedia ontology. Fundam. Informaticae 2020, 172, 261–297. [Google Scholar] [CrossRef]
- Zhan, Z.; Hou, Z.; Yang, Q.; Zhao, J.; Zhang, Y.; Hu, C. Knowledge attention sandwich neural network for text classification. Neurocomputing 2020, 406, 1–11. [Google Scholar] [CrossRef]
- Tenney, I.; Xia, P.; Chen, B.; Wang, A.; Poliak, A.; McCoy, R.T.; Kim, N.; Durme, B.V.; Bowman, S.; Das, D.; et al. What do you learn from context? Probing for sentence structure in contextualized word representations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Riedel, S.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, 3–7 November 2019; pp. 2463–2473. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Friedman, D.; Chen, D. Factual Probing Is [MASK]: Learning vs. Learning to Recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, Online, 30 August–3 September 2021; pp. 5017–5033. [Google Scholar] [CrossRef]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Long Papers; Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 1, pp. 328–339. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, virtual, 6–12 December 2020. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, 19–23 April 2021; Merlo, P., Tiedemann, J., Tsarfaty, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 255–269. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2022; Just Accepted. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-shot Learning. Acm Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Sung, M.; Lee, J.; Yi, S.; Jeon, M.; Kim, S.; Kang, J. Can Language Models Be Biomedical Knowledge Bases? In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Online and Punta Cana, Dominican Republic, Virtual, 7–11 November; 2021; pp. 4723–4734. [Google Scholar] [CrossRef]
- Chen, J.; Hu, Y.; Liu, J.; Xiao, Y.; Jiang, H. Deep Short Text Classification with Knowledge Powered Attention. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HW, USA, 27 January–1 February 2019; AAAI Press: Menlo Park, CA, USA, 2019; pp. 6252–6259. [Google Scholar] [CrossRef] [Green Version]
- Ding, N.; Hu, S.; Zhao, W.; Chen, Y.; Liu, Z.; Zheng, H.; Sun, M. OpenPrompt: An Open-source Framework for Prompt-learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, ACL 2022—System Demonstrations, Dublin, Ireland, 22–27 May 2022; Basile, V., Kozareva, Z., Stajner, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 105–113. [Google Scholar] [CrossRef]
- Chen, J.; Wang, A.; Chen, J.; Xiao, Y.; Chu, Z.; Liu, J.; Liang, J.; Wang, W. CN-Probase: A Data-Driven Approach for Large-Scale Chinese Taxonomy Construction. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1706–1709. [Google Scholar] [CrossRef] [Green Version]
- Le Scao, T.; Rush, A. How many data points is a prompt worth? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, Online, 6–11 June 2021; pp. 2627–2636. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2225–2240. [Google Scholar] [CrossRef]
- Hambardzumyan, K.; Khachatrian, H.; May, J. WARP: Word-level Adversarial ReProgramming. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Trento, Italy, 20–23 May 2019; Long Papers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; Volume 1, pp. 4921–4933. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Long and Short Papers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Petroni, F.; Lewis, P.S.H.; Piktus, A.; Rocktäschel, T.; Wu, Y.; Miller, A.H.; Riedel, S. How Context Affects Language Models’ Factual Predictions. In Proceedings of the Conference on Automated Knowledge Base Construction, AKBC 2020, Virtual, 22–24 June 2020. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How Can We Know What Language Models Know? Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan, I.; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. arXiv 2020, arXiv:2010.15980, 4222–4235. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Long Papers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; Volume 1, pp. 3816–3830. [Google Scholar] [CrossRef]
- Schick, T.; Schmid, H.; Schütze, H. Automatically Identifying Words That Can Serve as Labels for Few-Shot Text Classification. In Proceedings of the 28th International Conference on Computational Linguistics; International Committee on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 5569–5578. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction. In Proceedings of the WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; Laforest, F., Troncy, R., Simperl, E., Agarwal, D., Gionis, A., Herman, I., Médini, L., Eds.; ACM: New York, NY, USA, 2022; pp. 2778–2788. [Google Scholar] [CrossRef]
- Hu, Z.; Li, X.; Tu, C.; Liu, Z.; Sun, M. Few-Shot Charge Prediction with Discriminative Legal Attributes. In Proceedings of the 27th International Conference on Computational Linguistics, COLING 2018, Santa Fe, NM, USA, 20–26 August 2018; Bender, E.M., Derczynski, L., Isabelle, P., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 487–498. [Google Scholar]
- Ma, Y.; Cambria, E.; Gao, S. Label Embedding for Zero-shot Fine-grained Named Entity Typing. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference: Technical Papers, Osaka, Japan, 11–16 December 2016; Calzolari, N., Matsumoto, Y., Prasad, R., Eds.; ACL: Stroudsburg, PA, USA, 2016; pp. 171–180. [Google Scholar]
- Sanh, V.; Webson, A.; Raffel, C.; Bach, S.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Raja, A.; Dey, M.; et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. In Proceedings of the Tenth International Conference on Learning Representations, ICLR 2022, Virtual, 25–29 April 2022; Available online: https://openreview.net/forum?id=9Vrb9D0WI4 (accessed on 1 February 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Text Class Size | Concept Class Size | Data Size |
|---|---|---|---|
| NLPCC | 7 | 14 | 1813 |
| THUCNews | 7 | 17 | 2354 |
| AIStudio | 7 | 17 | 1441 |
| NLPCC | THUNews | AIStudio | ||||
|---|---|---|---|---|---|---|
| ACC (%) Avg/Std | F1 (%) Avg/Std | ACC (%) Avg/Std | F1 (%) Avg/Std | ACC (%) Avg/Std | F1 (%) Avg/Std | |
| PTC | 49.9/9.1 | 48.2/9.8 | 54.8/8.7 | 53.5/8.5 | 46.0/5.7 | 41.7/7.4 |
| PTCKT | 79.0/9.3 | 78.2/9.6 | 77.9/3.7 | 75.5/4.1 | 86.4/9.7 | 81.3/10.3 |
| DPMT | 58.9/7.3 | 57.1/7.7 | 60.9/13.8 | 56.2/14.7 | 59.3/8.2 | 53.2/10.8 |
| IPMT | 54.5/6.1 | 54.0/6.7 | 50.6/6.7 | 43.3/10.7 | 43.2/11.4 | 38.8/10.4 |
| KTP | 68.8/6.5 | 67.6/6.8 | 73.5/4.6 | 72.9/8.7 | 79.7/8.6 | 77.3/10.5 |
| WARP | 67.6/8.1 | 65.8/8.9 | 69.5/7.6 | 66.8/7.5 | 74.9/10.2 | 72.7/9.5 |
| BERT | 42.7/25.0 | 34.1/29.1 | 58.4/32.1 | 51.7/32.9 | 58.4/32.1 | 51.7/32.9 |
| BERT-CNN | 60.2/8.8 | 56.0/12.0 | 73.8/8.5 | 72.7/9.5 | 73.8/8.5 | 72.7/9.5 |
| BERT-RNN | 60.4/8.3 | 56.2/7.2 | 75.2/11.6 | 73.0/14.9 | 75.2/11.6 | 73.0/14.9 |
| BERT-RCNN | 58.0/7.7 | 56.4/4.6 | 70.79/18.7 | 67.5/24.3 | 70.8/18.7 | 67.5/24.3 |
| NLPCC | THUNews | AIStudio | ||||
|---|---|---|---|---|---|---|
| ACC (%) | F1 (%) | ACC (%) | F1 (%) | ACC (%) | F1 (%) | |
| PTC | 17.6 | 14.6 | 11.4 | 9.2 | 13.9 | 9.3 |
| PTCKT | 25.6 | 26.4 | 18.5 | 16.1 | 24.9 | 17.5 |
| DPMT | 19.7 | 17.0 | 12.8 | 10.9 | 14.3 | 10.0 |
| IPMT | 17.6 | 14.6 | 11.4 | 9.2 | 13.9 | 9.3 |
| KTP | 18.3 | 17.5 | 19.5 | 17.3 | 18.4 | 16.3 |
| WARP | 8.4 | 6.7 | 7.5 | 5.4 | 9.5 | 7.2 |
| BERT | 17.7 | 4.4 | 15.1 | 3.7 | 30.4 | 7.8 |
| BERT-CNN | 12.5 | 3.6 | 11.2 | 3.4 | 5.0 | 2.2 |
| BERT-RNN | 12.8 | 6.1 | 7.1 | 2.9 | 17.0 | 12.1 |
| BERT-RCNN | 14.5 | 5.5 | 8.4 | 4.4 | 23.3 | 10.3 |
| Models | Prompting Templates |
|---|---|
| PTC/PTCKT | 1. [x], 这是一条[mask]新闻。(This is a [mask] news.) |
| 2. [x],这条新闻的类型是[mask]。(The type of this news is [mask]) | |
| 3. [x], 类别:[mask]。(type:[mask]) | |
| 4. [x], 这条新闻的主题是[mask]。(The topic of this news is [mask]) | |
| ]DPMT | 1. [x],[e]是[mask],这是一条[mask]新闻。([e] is [mask], This is a [mask] news) |
| 2. [x],[e]的类型是[mask],新闻的类型是[mask]。 | |
| The type of [e] is [mask], the type of this news is [mask] | |
| 3. [x],[e]:[mask],类别:[mask]。([e]:[mask],type:[mask]) | |
| 4. [x],[e]是[mask]的实体,新闻的主题是[ mask ]。 | |
| [e] is a entity of [mask], the topic of this news is [mask] | |
| IPMT | 1. [x] , [e] 是[mask]。([e] is [mask]) |
| [x] ,这是一条[mask] 新闻。(This is a [mask] news) | |
| 2. [x] , [e] 的类型是[ mask ]。(The type of [e] is [mask]) | |
| [x] ,新闻的类型是[mask ]。(The type of the news is [mask]) | |
| 3. [x] , [e] : [mask]。([e]: [mask]) | |
| [x] ,类别: [mask] 。(type: [mask]) | |
| 4. [x] , [e] 是[mask] 的实体。([e] is the entity of [mask]) | |
| [x] ,新闻的主题是[mask] 。(the topic of the news is [mask] |
| Headline: | 我的世界1.10最新生物召唤指令详解 |
| Detailed explanation of the latest creature summoning instructions in minecraft1.10 | |
| PTC: | [x],这是一条[金融]新闻。 |
| This is a [financial] news. | |
| PTCKT: | [x], 我的世界是游戏,这是一条[游戏]新闻。 |
| Minecraft is a game, this is a [game] news | |
| DPMT: | [x], 我的世界是[游戏],这是一条[游戏]新闻。 |
| Minecraft is a game, this is a [game] news. | |
| IPMT: | [x],我的世界是[游戏](Minecraft is a game) |
| [x],这是一条[游戏]新闻。 (this is a [game] news.) | |
| Headline: | 李娜在法向全球发出来汉邀约 |
| Li Na sent an invitation to Wuhan to the world in France | |
| PTC: | [x],这是一条[历史]新闻。 |
| this is a [history ] news | |
| PTCKT: | [x],李娜是体育人物,这是一条[体育]新闻。 |
| Li Nais a sports figure, this is a [sports ] news | |
| DPMT: | [x],李娜是[娱乐人物],这是一条[娱乐]新闻。 |
| Li Na is an [entertainment figure], this is an [entertainment] news. | |
| IPMT: | [x],李娜是[娱乐人物]。(Li Na is [entertainment figure].) |
| [x],这是一条[娱乐]新闻。(this is an [entertainment] news.) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Chen, R.; Li, L. Knowledge-Guided Prompt Learning for Few-Shot Text Classification. Electronics 2023, 12, 1486. https://doi.org/10.3390/electronics12061486
Wang L, Chen R, Li L. Knowledge-Guided Prompt Learning for Few-Shot Text Classification. Electronics. 2023; 12(6):1486. https://doi.org/10.3390/electronics12061486
Chicago/Turabian StyleWang, Liangguo, Ruoyu Chen, and Li Li. 2023. "Knowledge-Guided Prompt Learning for Few-Shot Text Classification" Electronics 12, no. 6: 1486. https://doi.org/10.3390/electronics12061486
APA StyleWang, L., Chen, R., & Li, L. (2023). Knowledge-Guided Prompt Learning for Few-Shot Text Classification. Electronics, 12(6), 1486. https://doi.org/10.3390/electronics12061486