1. Introduction
Attributed networks can be utilized to depict social connections, where the graph nodes denote individuals and the edges between them signify their relationships. Attributed networks provide a wealth of attributes in addition to network topology. Anomaly detection is the process of identifying patterns or data points that do not conform to the expected or normal behavior of a system or dataset. It involves analyzing data to find unusual patterns, behaviors, or events that could indicate a potential problem or opportunity for further investigation. Anomaly detection in attributed networks aims to identify users whose characteristics deviate significantly from the norm, and has applications in areas such as detecting social spammers, bots, and fake accounts [
1].
In a social network, the norm refers to the typical behavior of users with a particular set of attributes, such as the frequency of posting updates, the number of followers, or the topics they usually discuss. Anomaly detection techniques aim to identify users whose behavior deviates significantly from this norm, indicating that they may be engaged in suspicious or malicious activities, such as spamming, phishing, or spreading false information.
The study of methods for social network anomaly detection is presently gaining popularity. Graphs are classified as non-Euclidean data because they neither follow a grid pattern nor do they obey Euclidean geometry [
2]. Unlike traditional data, which are often represented in a tabular format, graphs can have complex structures, and relationships between nodes can be non-linear and non-transitive. As a result, traditional data analysis techniques may not be suitable for analyzing social network data. Anomaly detection is one such technique that involves identifying unusual patterns or behaviors in a network that deviate from normal or expected behavior.
2. Related Work
Recently, a number of methods for using machine learning to find anomalies in graphs have been suggested [
3,
4,
5]. The use of machine-learning-based algorithms in anomaly detection on graphs can be challenging. It often involves manual feature selection, which is unsuited for large networks with many features [
6,
7]. The rich and essential information that resides in graphs is beyond what can be grasped by analyzing individual nodes or structure information alone [
7,
8]. When examining isolated data points, it may be difficult to see complicated relationships or patterns that exist in a graph or network. It might be possible to gain important insights or reach conclusions by looking at the graph’s structure as a whole that cannot be obtained by looking at individual components separately. The use of matrix decomposition and matrix factorization techniques has been used for anomaly detection [
9,
10], but with large graphs they do not perform well. The detection of graph anomalies has recently been studied using deep learning architectures [
11,
12,
13].
In order to expand CNN techniques to non-Euclidean data, authors M. Henaff et al. [
14] and Niepert et al. [
15] suggested models for applying convolutional neural networks to graph data. A model put forth by Niepert et al. places nodes in relation to structural factors such as betweenness centrality and the number of neighbors. It then gives a set of adjacent nodes with a fixed size and a sequence of nodes with a fixed length. CNNs can be applied to the graph using the model, which assigns node numbers using graph labeling methods. However, as pointed out in the citation Zhang et al., 2019 [
16], this method heavily depends on the structure of the graph and might need to generalize to a wider variety of applications.
A type of neural network referred to as a graph neural network (GNN) is designed to operate on graph-structured data, which represents a group of entities (known as “nodes”) and their interconnections (known as “edges”) using mathematical techniques.
To create node embeddings for node classification, Max Kipf introduced the Graph Convolutional Network (GCN), a graph-based neural network [
17]. It creates a node’s representation in the network by gathering its neighbors’ attributes, and creates node embeddings by presenting each node as a combination of its neighbors’ features. Kaize Ding (2019) [
18] proposed a methodology that makes use of autoencoders for anomaly detection in light of this work. A total of two GCN layers are used in this work’s autoencoder architecture for anomaly detection.
In their study, Zhang et al., 2022 [
19] introduced a novel fraud detection system called eFraudCom, which utilizes a competitive graph neural network (CGNN) to identify fraudulent activities on an e-commerce platform. The CGNN system is based on graph convolutional networks (GCN) and graph autoencoders (GAE). While this approach may be effective for detecting fraud in e-Commerce applications, the approach is not robust to the presence of anomalous nodes, which can affect the system’s accuracy in detecting fraud or other anomalies.
2.1. Limitation of the Existing Methods
Graph neural network (GNN)-based approaches have shown promise for anomaly detection in graphs. However, these methods face two primary challenges.
Firstly, the latent representation of nodes in the graph can be significantly impacted by the presence of anomalous nodes in their immediate neighborhood. This effect can lead to the incorrect classification of normal nodes as anomalous, compromising the accuracy of the anomaly detection approach. This issue arises due to the nature of GNNs, where the representation of a node is determined by aggregating the representations of its neighboring nodes. As a result, the presence of anomalous nodes can significantly influence the latent representation of a node, leading to false positives.
Secondly, anomalous nodes may not be detected by GNN-based approaches since their representations are normalized by the aggregate of genuine nodes in their neighborhood. This means that anomalous nodes may be masked by the presence of numerous normal nodes in their immediate vicinity. As a result, such nodes may not be effectively flagged as anomalous, leading to a failure of the anomaly detection approach.
2.2. Contributions of This Paper
The extended version of the paper presents a novel architecture for edge anomaly detection that integrates the encoder proposed in the original conference paper [
20]. While the original paper focused solely on node anomaly detection, the extended version includes an evaluation of the proposed encoder on edge anomaly detection. The results indicate that the proposed encoder outperforms current GNN encoders for detecting edge anomalies. Additionally, the proposed edge anomaly detection architecture, when used in combination with the proposed encoder, outperforms existing edge anomaly detection methods.
The proposed model, Anomaly Encoder (AnomEn), addresses the issue of accurately reflecting a node’s inherent characteristics by balancing the weight assigned to a node’s own features and its neighbors’ features. The proposed AnomEn method differs from DOMINANT [
18] in that it balances the weight between a node’s own features and its neighbors’ features during the aggregation process to obtain the latent representation.
In summary, the primary contributions of this paper are:
Proposal of a new network-embedding technique called Anomaly Encoder (AnomEn) for anomaly detection. The method weights the self-features and neighborhood features of the node to create a representation of the node. This representation is then used as an encoder in an anomaly detection framework that aims to identify anomalies in the network.
Proposal of a framework for attributed networks based node anomaly identification. The system employs the proposed encoder, AnomEn, to generate latent representations of nodes, and two decoders: a structure reconstruction decoder and an attribute reconstruction decoder. The framework aims to identify node anomalies in attributed networks.
Introduction of an edge anomaly detection architecture built on an auto-encoder that makes use of the AnomEn encoder presented in this work. The architecture aims to detect edge anomalies in attributed networks.
3. Notations and Problem Statement
This section provides a formal definition of frequently used notations and the problem under study.
Table 1 summarizes the notations used in the paper.
Consider the network with node attributes G = (V, E), where V is the set of nodes and E is the collection of edges.
Problem: Given an input of an attributed undirected network ‘G’, the goal is to identify all anomalous nodes that deviate significantly in terms of their structure and attribute information from the majority of the nodes.
4. Methodology
The Anomaly Encoder (AnomEn) is a proposed graph neural network that serves as an encoder that takes in a high-dimensional adjacency matrix and feature matrix and outputs a low-dimensional vector representation. The generated vector representations of the nodes can be used as input to machine learning models that can classify nodes as normal or anomalous.
The low-dimensional vector produced by AnomEn can be used for both node anomaly detection and edge anomaly detection tasks. The proposed architecture for these tasks utilizes the AnomEn encoder to extract relevant information from the input data and perform anomaly detection.
4.1. Proposed Graph Neural Network: AnomEn
The AnomEn encoder takes inspiration from the GCN model. The GCN model is a graph neural network that uses convolutional operations to generate a latent representation of the graph data. To form a representation of the central node, this process aggregates the features of the neighboring nodes. The GCN model has a weakness in that it may be impacted by anomalous neighboring nodes. The representation of normal nodes may be affected, leading to false positive detections. Additionally, the representation of anomalous nodes may be flattened by the aggregate operation, which can lead to false negatives and cause them to go undetected. These limitations highlight the need for a more robust and effective approach to graph representation learning, such as the AnomEn encoder, which balances the contribution of the node’s self features and attributes of its neighbors to create a more accurate representation of the graph data as shown in Algorithm 1.
The proposed encoder is inspired by the Graph Convolutional Network (GCN) model [
21], which generates latent representation by aggregating the features of neighboring nodes. GCN is not immune to the existence of anomalous nodes, though. So, as illustrated in Algorithm 1, a weighted sum of a node’s self-features and those of its neighbours is proposed.
As illustrated in the algorithm, the feature matrix of each node forms its initial representation.
Neighbors send messages to each other. Every node receives messages from its neighbors as shown below.
A node then combines its features with its neighbors’ features and gives greater weight than its neighbors’ features as shown below. Here N(v) represents the set of neighbors of vertex v in a graph.
In this method, each node has a latent representation that reflects its characteristics and is less affected by anomalous neighbors.
| Algorithm 1: Weighted Neighbourhood Aggregation Procedure |
Input: Adjacency matrix A, Feature matrix X Output: Vector representations  |
4.2. Node Anomaly Detection Task
A viable method to identify anomalies is to make use of the discrepancy between the input and reconstructed data, as suggested by methods [
17,
21,
22]. The related node is considered anomalous when the difference between the input and reconstructed data exceeds a predetermined threshold. Nodes that do not follow the patterns set by other nodes cannot properly reconstruct the original data. A deep autoencoder creates the latent representation of the input and uses it to reconstruct the original data in an unsupervised way.
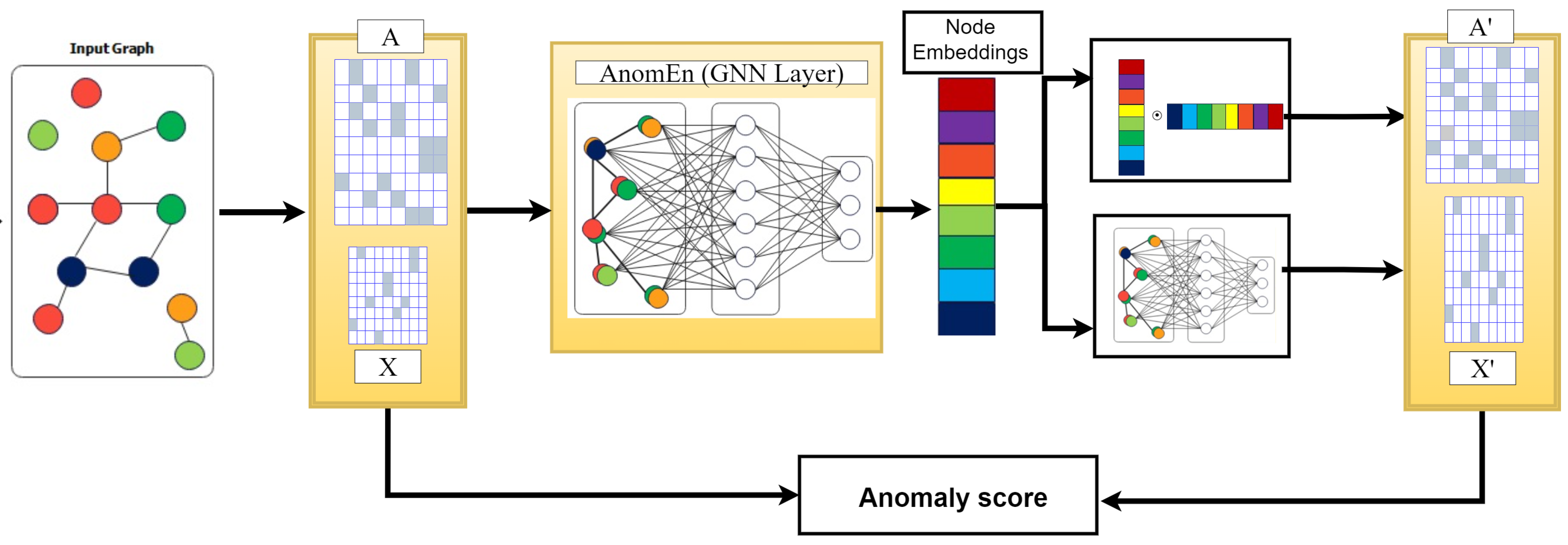
The proposed encoder, AnomEn, is utilized to introduce a new architecture for the purpose of detecting node anomalies. This architecture is called NodeAnomEn, and it is an end-to-end framework for learning joint representations to detect anomalies in attributed networks, as depicted in
Figure 1. The approach is based on an unsupervised learning mechanism that utilizes an autoencoder. Autoencoders consist of an encoder and a decoder and are primarily used for reconstructing input data. In this case, the encoder takes the network structure and attribute information as input and generates a node embedding. The decoder then uses this node embedding to reconstruct the network structure and attribute information. Any discrepancies between the reconstructed information and the input network are considered anomalies. The NodeAnomEn structure is composed of three elements. Firstly, the AnomEn encoder serves as a starting point, building a reliable latent representation of nodes using network structure and attribute data [
20]. Secondly, an attribute reconstruction decoder reconstructs the node attribute data. Thirdly, a structural decoder reconstructs the network structure data. By calculating the difference between the reconstructed and actual data, anomalies in a dataset can be identified.
4.2.1. Network Encoder
In total, two convolutional layers are used to map the input to node embeddings, which can be formulated as follows:
where
is the weight matrix in the first layer and
is the weight matrix in the second layer.
The adjacency matrix and feature matrix’s dot product is used to compute the aggregate of neighbouring nodes’ features during convolution. An identity matrix, or “I” is added to the adjacency matrix in order to include a node’s self-features. The terms and indicate the different weights given to the node’s self-features and neighbours, respectively. The letter “D” stands for the diagonal matrix of A. The adjacency matrix is calculated in the preprocessing phase as (A() + I), where denotes the weights given to the features of the node and its neighbours.
4.2.2. Structure Reconstruction Decoder
The node embeddings produced by the encoder are fed into the decoder for structure reconstruction, which then reconstructs the original network structure.
It is possible to calculate the likelihood that an edge will appear between any two possible node pairs by computing the inner product between embeddings. Subsequently, the reconstruction error is calculated using the following formula:
4.2.3. Attribute Reconstruction Decoder
To reconstruct node attributes, an additional convolutional layer is utilized to predict the input node attribute in the following manner:
The reconstruction error is computed using the following procedure:
4.2.4. Loss Function
The objective of NodeAnomEn algorithm is to minimize the following function:
Here, the term represents the error in reconstructing the network structure, while denotes the error in reconstructing the node attributes.
4.2.5. Anomaly Detection
The node’s anomalous score is determined by adding the structure reconstruction error and the attribute reconstruction error.
The anomaly score for each node is determined by a balance between the attribute error and adjacency matrix reconstruction error, controlled by the parameter
. Nodes with higher anomaly scores are identified as anomalies, and every node is ranked according to their computed anomaly score. This approach is influenced by techniques that aim to detect anomalies in a node feature subspace, as discussed in [
3].
4.3. Edge Anomaly Detection Task
Edge anomaly detection is based on the following principle. The opposite of outlier edge identification is the detection of missing edges which is also known as link prediction [
22]. The aim is to find the missing edges between pair of nodes in the graph.
The goal of the algorithm is to calculate the anomaly score for each edge in the graph. The score is based on the similarity between nodes. Edges with low similarity between the two end nodes are more likely to be outliers. The algorithm calculates the anomaly score for each edge by measuring the similarity of the nodes (as illustrated in Algorithm 2). After the model is trained, it predicts the label (positive or negative) for each possible edge in the graph. A positive label indicates the presence of an edge between two nodes, while a negative label signifies the absence of an edge. Ideally, the graph should only contain positive edges. If any negative edges are present, they are considered anomalies and indicate deviations from the normal patterns in the network.
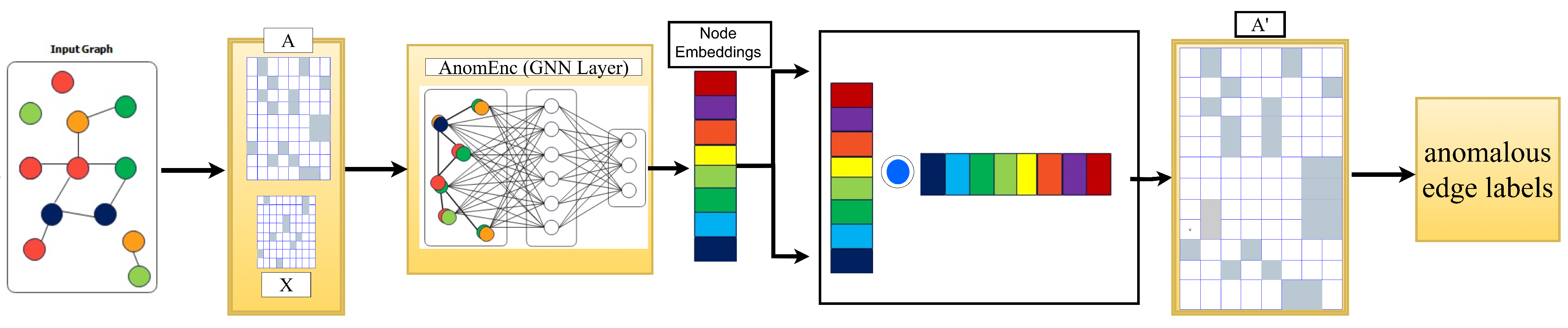
This section introduces the proposed Edge Anomaly Encoder (EdgeAnomEn) for edge anomaly detection using the proposed methodology. The proposed architecture is shown in
Figure 2. EdgeAnomEn employs an unsupervised learning mechanism based on auto encoder. It consists of: (i) Two layers of AnomEn in encoder. (ii) One dot product decoder.
| Algorithm 2: Edge anomaly detection procedure |
| Input: Adjacency matrix A, Feature matrix X, existing edge labels L Output: Set of anomalous edges A , ; ; ; ;  |
Network Encoder
A total of two convolutional layers are used to map the input to node embeddings,
, which can be formulated as follows:
where
is the weight matrix in the first layer and
is the weight matrix in the second layer.
In this equation, D is the diagonal degree matrix of the graph, A is the adjacency matrix, I is the identity matrix, X is the input feature matrix, is a hyper parameter that balances the importance of the adjacency matrix and the identity matrix, is the rectified linear unit activation function, W is the weight matrix of the first convolutional layer, and b is the bias term of the first convolutional layer.
The encoder creates the node embeddings using the network structure and attribute information as input. The decoder then uses the input of these node embeddings to reconstruct the network topology. Decoder predicts the label for all possible edges as either positive edge or negative edge. Positive edge means the edge between the respective nodes are present in the graph. Negative edges means that the edge between the respective two end nodes is very unlikely.
Subsequently, the predicted edge label is compared with the existing edge label. If the predicted label and existing label bear a difference in an edge, then that edge is considered as anomalous.
5. Experimental Setup
This section describes the experiments performed on real world attributed networks to empirically evaluate the proposed method. The proposed graph representation learning methodology is examined on both node and edge anomaly detection tasks.
5.1. Experimental Setup for Node Anomaly Detection Task
The method has been proven to yield performance enhancements in both scenarios, and was evaluated on the Twitter [
23], Enron, and Amazon datasets during the study. The number of nodes, attributes, and anomalous nodes used for each dataset can be found in
Table 2. The witter dataset includes 1950 human accounts that have been verified and 3000 fake accounts, which were procured from websites that specialize in selling such accounts. However, only 100 fake accounts were ultimately included in the dataset, which represents roughly 5% of the authentic user base. Additionally, the dataset contains anomalous nodes equivalent to 5% of the regular nodes. The architecture employed in this study features two convolutional layers, with the first layer having a size of 256.
Table 3 presents the AUC values for various embedding dimensions of the second layer. The Enron and Amazon datasets have a learning rate of 0.0005, while the learning rate for the Twitter dataset is 0.0133 multiplied by 0.001. The
value used for all three datasets is 0.8.
The following methods are used for comparison:
LOF [
24]: “Identifying Density-Based Local Outliers” presents a novel approach for detecting local outliers in datasets using density-based clustering techniques. The authors propose a metric called the Local Outlier Factor (LOF), which measures the degree of outlierness of a data point with respect to its local neighborhood. The LOF metric is based on the concept of the local density of a data point relative to the densities of its neighbors.
DOMINANT [
18]: The paper “Deep Anomaly Detection on Attributed Networks” proposes a method for detecting anomalous behavior in attributed networks using deep learning techniques. The authors use a two-stage approach that first learns a node embedding using a Graph Convolutional Network (GCN) and then uses an Autoencoder to detect anomalies in the learned embedding.
Scan [
25]: A structural clustering algorithm for networks by Xu et al. (2007) presents a novel algorithm for clustering nodes in complex networks based on their structural properties. The algorithm, called SCAN (Structural Clustering Algorithm for Networks), is designed to identify clusters that exhibit high internal connectivity and low external connectivity, known as “communities” in the network analysis literate.
AMEN [
26]: Scalable Anomaly Ranking of Attributed Neighborhoods by Perozzi and Akoglu (2016) proposed a new method for detecting anomalies in attributed networks. The method is based on the observation that anomalies often manifest themselves as neighborhoods in the network that have unusual patterns of attributes (such as node features or edge weights). The authors’ approach involves first selecting a set of “anchor nodes” that are representative of different parts of the network. For each anchor node, they then construct an attributed neighborhood consisting of the node itself and its neighbors within a certain distance. They use a dimensionality reduction technique (specifically, Singular Value Decomposition or SVD) to transform the high-dimensional attribute vectors of the nodes in each neighborhood into a lower-dimensional space.
5.2. Experimental Setup for Edge Anomaly Detection Task
The proposed EdgeAnomEn architecture, which competes with the existing approaches, makes use of the proposed encoder Anom-En that was introduced in part II. Here, first layer and second layer have used layer size of 128 and 64, respectively.
GNN-CL [
23]: This method presents a graph neural network (GNN) with continual learning for detecting fake news from social media. The proposed framework leverages both node and edge information in the social network and achieves state-of-the-art performance on two publicly available datasets. The approach is robust to concept drift, and the authors suggest that it has the potential to be applied to other tasks in social network analysis.
The proposed architecture has produced the best results when compared to the current approaches as shown in
Table 3. The proposed method is compared with the existing methods UPFD-GCN [
17], GCN-FN [
27], GNN-CL [
23], UPFD-GAT [
28], UPFD-SAGE [
29]. GNN-CL is a GNN developed specifically for graph classification which encodes the news propagation graph. Profile information and textual embeddings of comments are considered user features.
6. Performance Evaluation & Results
Kaize Ding et al. [
18] reported the AUC scores for various anomaly detection methods, including LOF [
24], SCAN [
25], AMEN [
26], Radar [
30], Anomalous [
31], and Dominant [
18], on the ’BlogCatalog’ dataset. The AUC scores for these methods were 0.4915, 0.2727, 0.6648, 0.7104, 0.7281, and 0.7813, respectively. It is evident that the Dominant method outperformed all other methods, and thus, it was selected as the reference method for comparison.
Table 3 illustrates the AUC scores for the proposed method and reference methods on the Twitter, Enron, and Amazon datasets.
The performance of the proposed method and the baseline method on the Twitter dataset was compared in
Figure 2 for various embedding vector sizes (8, 16, 32, 64, 128, and 256). The results showed that the proposed method achieved the best AUC value of 0.6401, while the baseline method achieved an AUC value of 0.630 when the dimensions of the first and second layers were set to 256 and 64, respectively. The proposed method consistently outperformed the baseline method across all other layer dimensions, as indicated by
Figure 2.
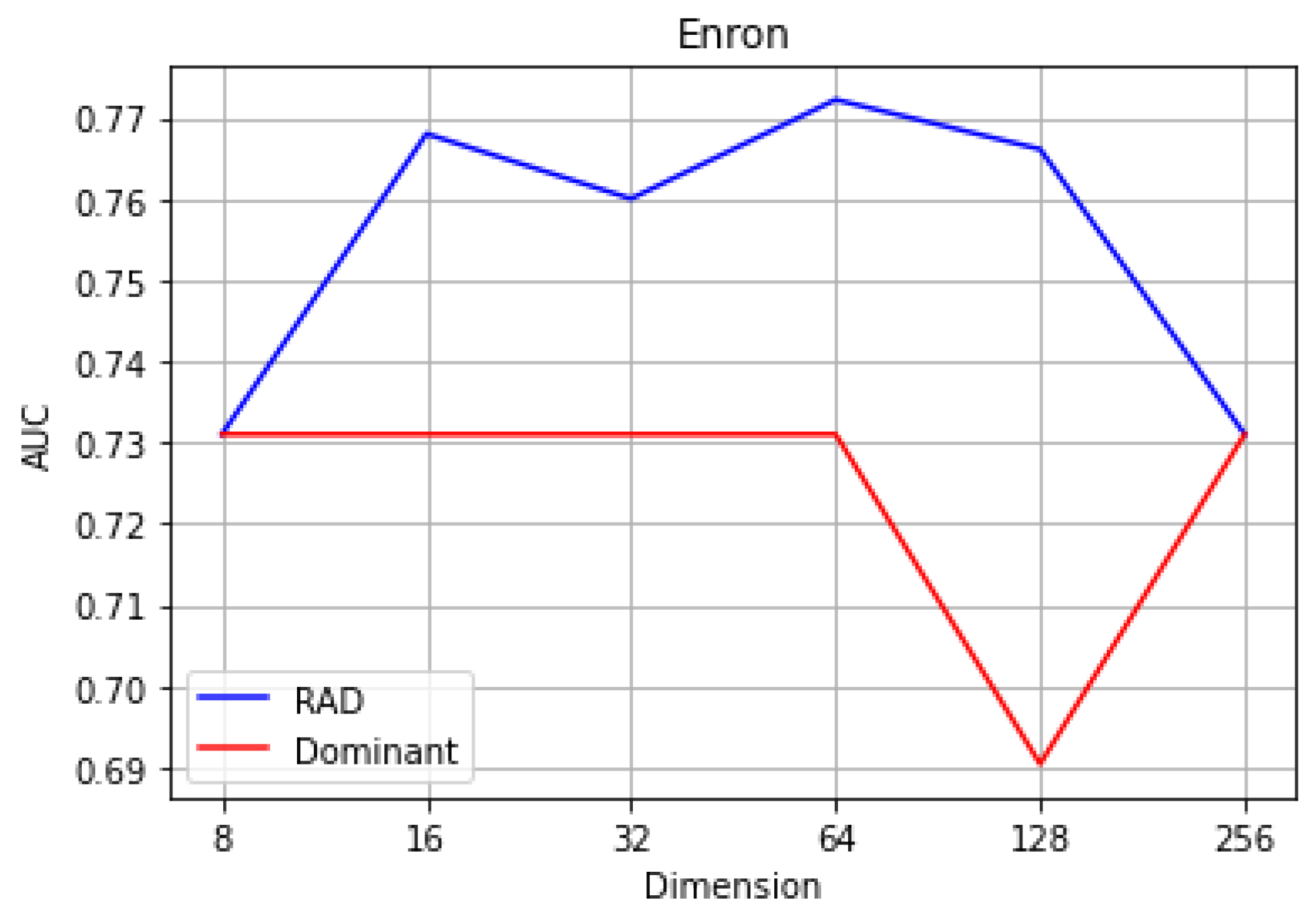
Figure 3 presents the comparison of the proposed method and the baseline method on the Enron dataset for the same embedding vector sizes. The best AUC value of 0.7722 was obtained for NodeAnomEn, while the AUC value for DOMINANT was 0.7310, when the dimensions of the first and second layers were set to 256 and 64, respectively. The proposed method showed superior performance to the baseline method across the Enron dataset, as illustrated by
Figure 3. Based on the AUC values obtained from the experiments, the proposed method outperforms the baseline methods on the Enron dataset by approximately 5.48%.
Similarly,
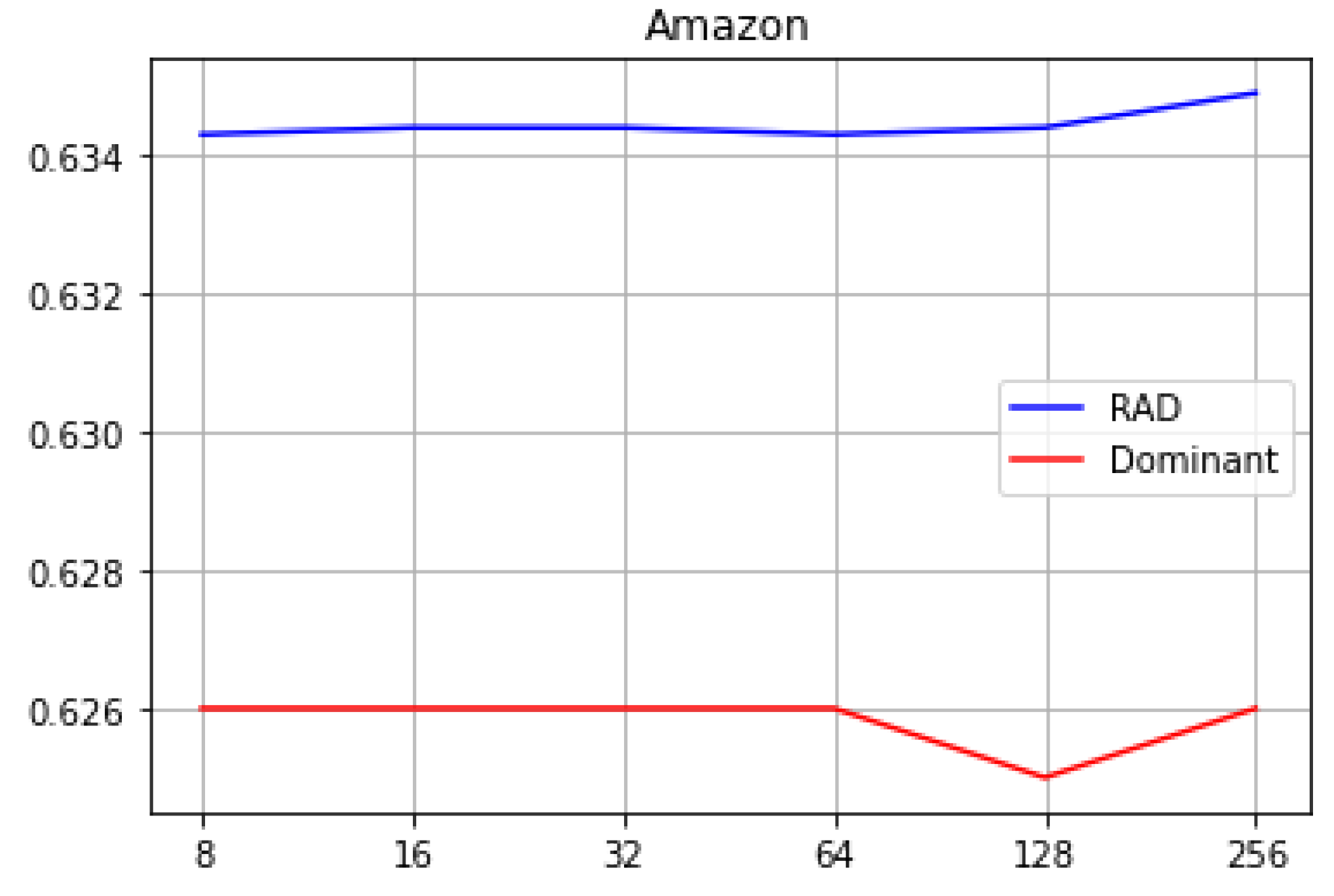
Figure 4 compares the proposed method and the baseline method on the Amazon dataset for embedding vector sizes of 8, 16, 32, 64, 128, and 256. The results demonstrated that the proposed method outperformed the baseline method, achieving the best AUC value of 0.6344 compared to the AUC value of 0.6260 for DOMINANT, when the first and second layer dimensions were set to 256 and 32, respectively.
Figure 5 shows that the proposed method consistently outperforms the baseline method across all other layer dimensions.
Therefore, the proposed method outperforms the baseline method on all three datasets for the node anomaly detection task.
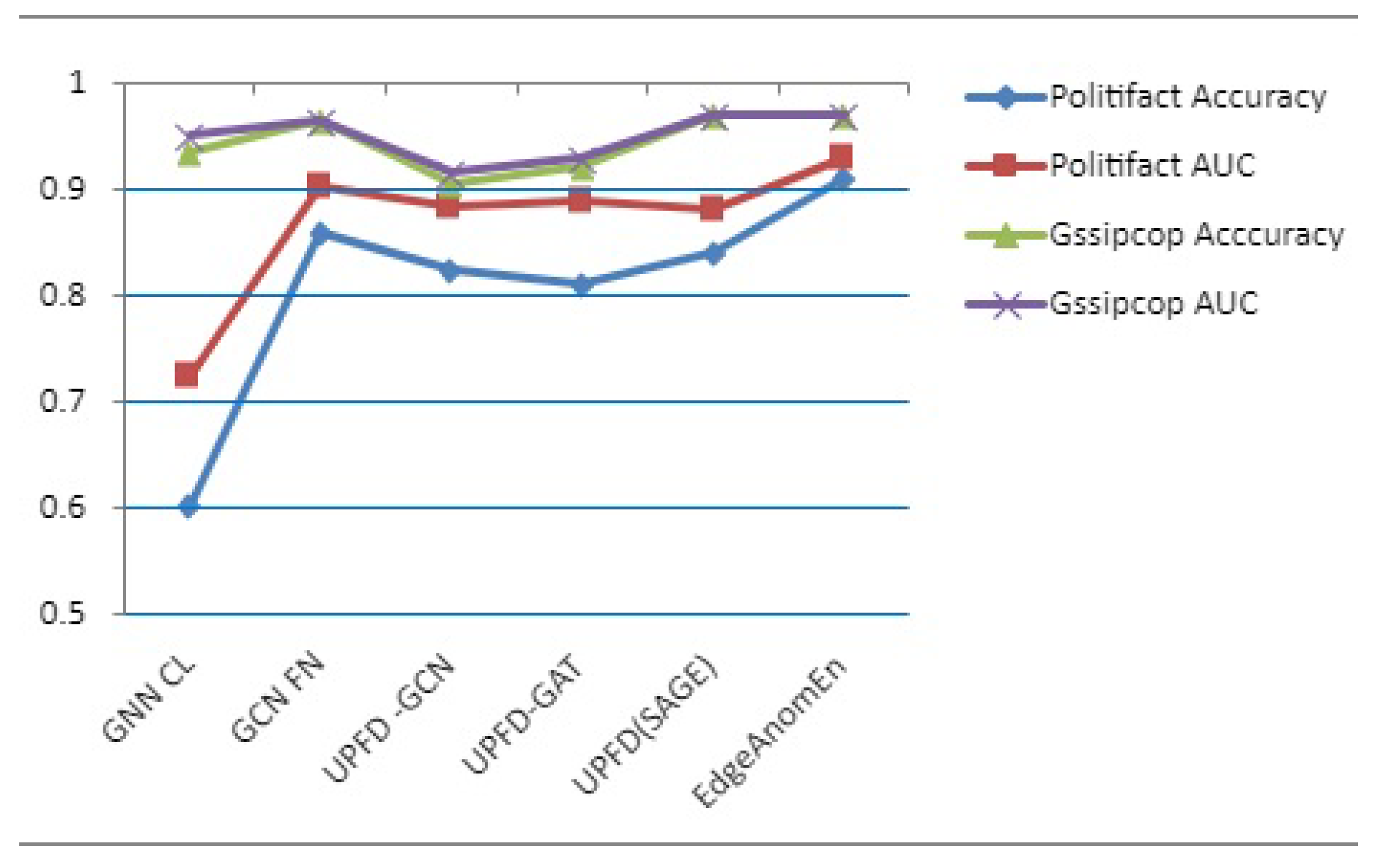
Table 3 presents the performance evaluation results of various models, specifically on two datasets—Politifact and Gossipcop. The evaluation metrics used in this study are accuracy and area under the curve (AUC).
For the Politifact dataset, the results show that the proposed model, EdgeAnomEn, outperforms all other models, achieving the highest accuracy score of 0.9129 and AUC score of 0.9388. The next best performing model is UPFD(SAGE), achieving an accuracy score of 0.8462 and AUC score of 0.8859.
For the Gossipcop dataset, the proposed model, EdgeAnomEn, again performs the best, achieving the highest accuracy score of 0.9798 and AUC score of 0.9796. The second-best performing model is UPFD(SAGE), achieving an accuracy score of 0.9723 and AUC score of 0.9722.
The results suggest that the proposed model, EdgeAnomEn, is highly effective for both datasets and outperforms the other models in all evaluation metrics. UPFD(SAGE) also performs well on both datasets, but falls short of EdgeAnomEn in terms of accuracy and AUC scores.
It is evident that EdgeAnomEn exhibits superior performance as compared to all the baseline models.
7. Conclusions
The task of identifying anomalous users on attributed social networks is a challenging problem that requires the integration of network structure and node attributes. Graph Neural Networks (GNNs) are well-suited for this task. However, the use of aggregate operations in GNNs can lead to false positives and false negatives. The AnomEn approach, a robust graph neural network developed for anomaly detection, addresses these challenges using a weighted aggregate mechanism that places greater emphasis on a node’s own features and less emphasis on its neighbors’ features. The proposed AnomEn method serves as the encoder in node and edge anomaly detection architectures and outperforms existing methods in both tasks. The findings demonstrate the effectiveness and robustness of the proposed method in detecting anomalies on attributed networks.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}