
The Role of Socioeconomic Factors in Improving the Performance of Students Based on Intelligent Computational Approaches

 ,
,  , ,
, ,  , and
, and
Abstract
:1. Introduction
- A comprehensive study on the impact of the SES of a student on his or her educational performance and achievements is conducted in this article. The primary goal of the proposed research study is to determine the critical socioeconomic factors that influence student performance and to evaluate the educational systems of public and private schools using data from a questionnaire survey.
- We created our own dataset by visiting different government and private schools in Khyber Pakhtunkhwa, Pakistan. The created dataset consists of a total of 18 crucial socioeconomic factors that have a great impact on the educational achievements of a student.
- We proposed a novel approach using different ML algorithms to identify the impact of a student’s SES on his or her educational achievements. The proposed system worked on full features and on selected features as well, using two important feature selection algorithms, FCBF and Relief. Furthermore, the feature selectors present significant and correlated features to the ML models and play an important role in enhancing the performance of the models.
- The performance of the proposed system using different ML models was tested on both full and selected features. Furthermore, to track the performance of each model, different performance measures were used. The experimental outcomes of the proposed system were found to be better than those of earlier statistical techniques.
2. Related Work
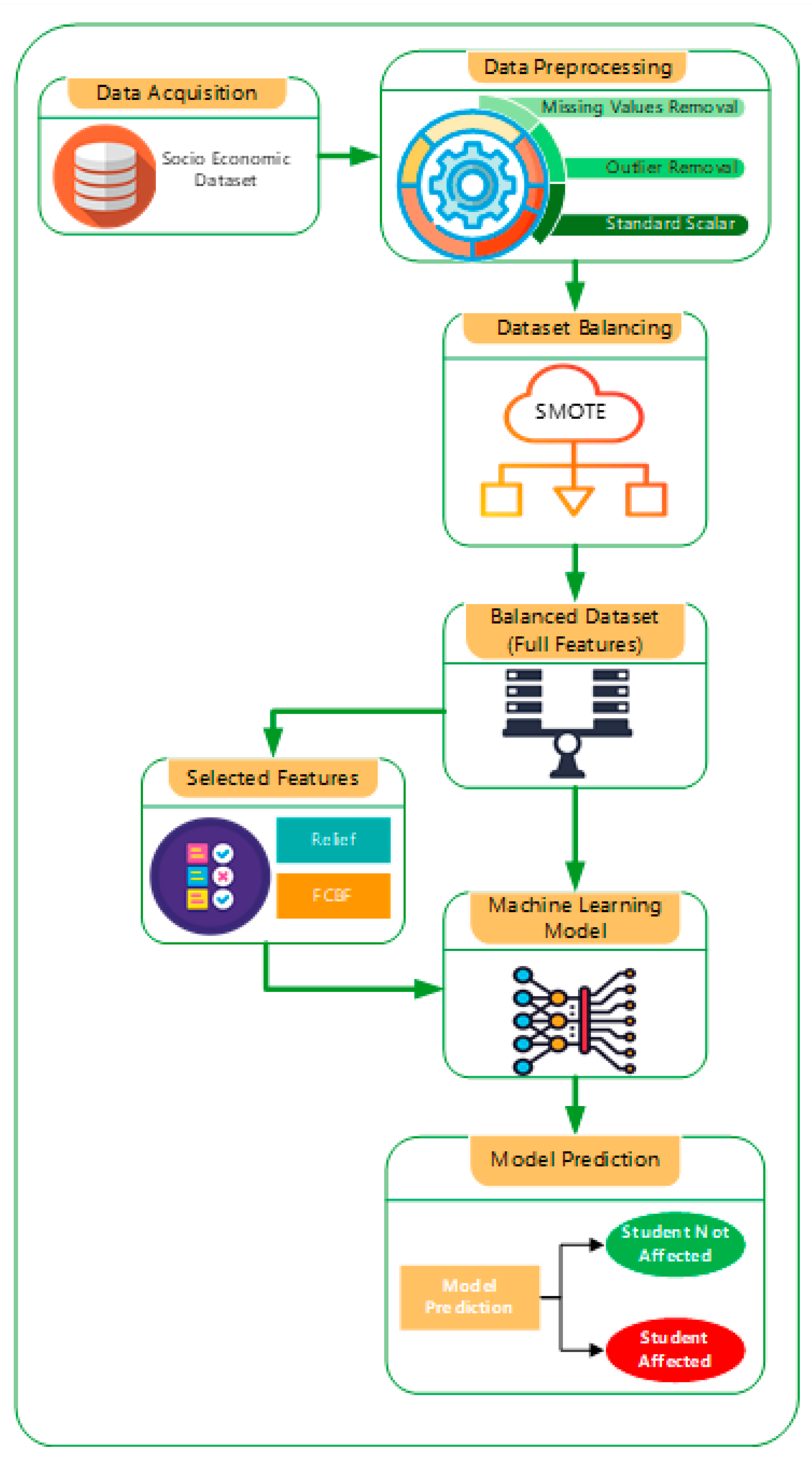
3. Proposed Methodology
3.1. Dataset Acquisition
3.2. Proposed System Framework Based on Intelligent ML Models
3.2.1. Preprocessing of Data
3.2.2. Feature Selection Algorithms
- 1.
- FCBF Feature Selection Algorithm:
- 2.
- Relief Feature Selection Algorithm:
3.2.3. Utilized ML Classification Algorithms
3.2.4. Model Validation Techniques
3.2.5. Performance Metrics
4. Results and Discussion
4.1. Experimental Setup and Environment
4.2. Experimental Outcomes of the Utilized Models Using Full Features
4.3. Results of the Investigated Models on Selected Features (Relief)
4.4. Results of the Investigated Models on Selected Features (FCBF)
4.5. Comparison of the Proposed Work with Earlier Approaches
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lempp, H.; Seale, C. The hidden curriculum in undergraduate medical education: Qualitative study of medical students’ perceptions of teaching. Bmj 2004, 329, 770–773. [Google Scholar] [CrossRef] [PubMed]
- Kimaiga, H.O. The Influence of Parental Socio Economic Status on Pupil’s Academic Performance at Kenya Certificate of Primary Education in Kiamokama Division of Kisii County; University of Nairobi: Nairobi, Kenya, 2014. [Google Scholar]
- Guo, L.-H.; Cheng, S.; Liu, J.; Wang, Y.; Cai, Y.; Hong, X.-C. Does social perception data express the spatio-temporal pattern of perceived urban noise? A case study based on 3137 noise complaints in Fuzhou, China. Appl. Acoust. 2022, 201, 109129. [Google Scholar] [CrossRef]
- Akhtar, Z. Socio-economic status factors effecting the students achievement: A predictive study. Int. J. Soc. Sci. Educ. 2012, 2, 281–287. [Google Scholar]
- Li, T.; Li, Y.; Hoque, M.A.; Xia, T.; Tarkoma, S.; Hui, P. To what extent we repeat ourselves? Discovering daily activity patterns across mobile app usage. IEEE Trans. Mob. Comput. 2020, 21, 1492–1507. [Google Scholar] [CrossRef]
- Saifi, S.; Mehmood, T. Effects of socioeconomic status on students achievement. Int. J. Soc. Sci. Educ. 2011, 1, 119–128. [Google Scholar]
- Sirin, S.R. Socioeconomic status and academic achievement: A meta-analytic review of research. Rev. Educ. Res. 2005, 75, 417–453. [Google Scholar] [CrossRef]
- Eamon, M.K. Social-demographic, school, neighborhood, and parenting influences on the academic achievement of Latino young adolescents. J. Youth Adolesc. 2005, 34, 163–174. [Google Scholar] [CrossRef]
- Machebe, C.H.; Ezegbe, B.N.; Onuoha, J. The Impact of Parental Level of Income on Students’ Academic Performance in High School in Japan. Univers. J. Educ. Res. 2017, 5, 1614–1620. [Google Scholar]
- Rasul, S.; Bukhsh, Q. A study of factors affecting students’ performance in examination at university level. Procedia-Soc. Behav. Sci. 2011, 15, 2042–2047. [Google Scholar] [CrossRef]
- Iqbal, S.M.; Long, C.S.; Fei, G.C.; Bukhari, S.M. Moderating effect of top management support on relationship between transformational leadership and project success. Pak. J. Commer. Soc. Sci. 2015, 9, 540–567. [Google Scholar]
- Tomul, E.; Polat, G. The effects of socioeconomic characteristics of students on their academic achievement in higher education. Am. J. Educ. Res. 2013, 1, 449–455. [Google Scholar] [CrossRef]
- Musso, M.F.; Hernández, C.F.R.; Cascallar, E.C. Predicting key educational outcomes in academic trajectories: A machine-learning approach. High. Educ. 2020, 80, 875–894. [Google Scholar] [CrossRef]
- Cao, H. Entrepreneurship education-infiltrated computer-aided instruction system for college Music Majors using convolutional neural network. Front. Psychol. 2022, 13, 900195. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Z.; Liu, Q.; Huang, X. The influence of digital educational games on preschool Children’s creative thinking. Comput. Educ. 2022, 189, 104578. [Google Scholar] [CrossRef]
- Wu, B.; Liu, Z.; Gu, Q.; Tsai, F.-S. Underdog mentality, identity discrimination and access to peer-to-peer lending market: Exploring effects of digital authentication. J. Int. Financ. Mark. Inst. Money 2023, 83, 101714. [Google Scholar] [CrossRef]
- Farooq, M.S.; Chaudhry, A.H.; Shafiq, M.; Berhanu, G. Factors affecting students’ quality of academic performance: A case of secondary school level. J. Qual. Technol. Manag. 2011, 7, 1–14. [Google Scholar]
- Ogunshola, F.; Adewale, A. The effects of parental socio-economic status on academic performance of students in selected schools in Edu Lga of Kwara State Nigeria. Int. J. Acad. Res. Bus. Soc. Sci. 2012, 2, 230–239. [Google Scholar]
- Korir, W. Influence of number of siblings and learning resources at home on students’ academic performance. J. Emerg. Trends Educ. Res. Policy Stud. 2017, 8, 291–299. [Google Scholar]
- Nyakan, P.; Yambo, J. Family Based Socio-Economic Factors that Affect Students’ academic Performance in Public Secondary Schools in Rongo Sub-County, Migori County, Kenya. J. Bus. Manag. Sci. 2016, 2, 8. [Google Scholar]
- Hossain, A.; Zeheen, A.; Islam, M.A. Socio-economic background and performance of the students at presidency university in Bangladesh. Eur. J. Educ. Stud. 2012, 5. [Google Scholar] [CrossRef]
- Suleman, Q.; Hussain, I.; Khan, F.U.; Nisa, U. Effects of parental socioeconomic status on the academic achievement of secondary school students in karak district, pakistan. Int. J. Hum. Resour. Stud. 2012, 2, 14–32. [Google Scholar] [CrossRef]
- Okioga, C.K. The impact of students’ socio-economic background on academic performance in Universities, a case of students in Kisii University College. Am. Int. J. Soc. Sci. 2013, 2, 38–46. [Google Scholar]
- Singh, A.; Singh, J.P. The influence of socio-economic status of parents and home environment on the study habits and academic achievement of students. Educ. Res. 2014, 5, 348–352. [Google Scholar]
- Dudaite, J. Impact of socio-economic home environment on student learning achievement. Indep. J. Manag. Prod. 2016, 7, 854–871. [Google Scholar] [CrossRef]
- Peña-López, I. PISA 2015 Results (Volume I). Excellence and Equity in Education; OECD Publishing: Paris, France, 2016. [Google Scholar]
- Zhang, J.; Tian, J.; Li, M.; Leon, J.I.; Franquelo, L.G.; Luo, H.; Yin, S. A parallel hybrid neural network with integration of spatial and temporal features for remaining useful life prediction in prognostics. IEEE Trans. Instrum. Meas. 2022, 72, 3501112. [Google Scholar] [CrossRef]
- Zhang, J.; Li, X.; Tian, J.; Jiang, Y.; Luo, H.; Yin, S. A variational local weighted deep sub-domain adaptation network for remaining useful life prediction facing cross-domain condition. Reliab. Eng. Syst. Saf. 2023, 231, 108986. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, K.; An, Y.; Luo, H.; Yin, S. An Integrated Multitasking Intelligent Bearing Fault Diagnosis Scheme Based on Representation Learning Under Imbalanced Sample Condition. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef]
- Masci, C.; Johnes, G.; Agasisti, T. Student and school performance across countries: A machine learning approach. Eur. J. Oper. Res. 2018, 269, 1072–1085. [Google Scholar] [CrossRef]
- Masci, C.; Ieva, F.; Agasisti, T.; Paganoni, A.M. Does class matter more than school? Evidence from a multilevel statistical analysis on Italian junior secondary school students. Socio-Econ. Plan. Sci. 2016, 54, 47–57. [Google Scholar] [CrossRef]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef]
- Hussain, S.; Muhsin, Z.; Salal, Y.; Theodorou, P.; Kurtoğlu, F.; Hazarika, G. Prediction model on student performance based on internal assessment using deep learning. Int. J. Emerg. Technol. Learn. 2019, 14, 4–22. [Google Scholar] [CrossRef]
- Belachew, E.B.; Gobena, F.A. Student performance prediction model using machine learning approach: The case of Wolkite university. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2017, 7, 46–50. [Google Scholar] [CrossRef]
- Oloruntoba, S.; Akinode, J. Student academic performance prediction using support vector machine. Int. J. Eng. Sci. Res. Technol. 2017, 6, 588–597. [Google Scholar]
- Agasisti, T.; Ieva, F.; Paganoni, A.M. Heterogeneity, school-effects and the North/South achievement gap in Italian secondary education: Evidence from a three-level mixed model. Stat. Methods Appl. 2017, 26, 157–180. [Google Scholar] [CrossRef]
- Rauer, J.N.; Kroiss, M.; Kryvinska, N.; Engelhardt-Nowitzki, C.; Aburaia, M. Cross-university virtual teamwork as a means of internationalization at home. Int. J. Manag. Educ. 2021, 19, 100512. [Google Scholar] [CrossRef]
- Kryvinska, N.; Baroková, A.; Auer, L.; Ivanochko, I.; Strauss, C. Business value assessment of services re-use on SOA using appropriate methodologies, metrics and models. Int. J. Serv. Econ. Manag. 12 2013, 5, 301–327. [Google Scholar] [CrossRef]
- Available online: https://scikit-learn.org/stable/index.html (accessed on 12 April 2023).
- Available online: https://pandas.pydata.org/ (accessed on 12 April 2023).
- Available online: https://numpy.org/ (accessed on 12 April 2023).
- Available online: https://seaborn.pydata.org/ (accessed on 12 April 2023).
- Available online: https://matplotlib.org/ (accessed on 12 April 2023).
- Gerritsen, L.; Conijn, R. Predicting Student Performance with Neural Networks; Tilburg University: Tilburg, The Netherlands, 2017. [Google Scholar]
- Stapel, M.; Zheng, Z.; Pinkwart, N. An Ensemble Method to Predict Student Performance in an Online Math Learning Environment. In Proceedings of the 9th International Conference on Educational Data Mining, Raleigh, NC, USA, 29 June–2 July 2016; Available online: https://files.eric.ed.gov/fulltext/ED592647.pdf (accessed on 12 April 2023).
- Zohair, A.; Mahmoud, L. Prediction of Student’s performance by modelling small dataset size. Int. J. Educ. Technol. High. Educ. 2019, 16, 27. [Google Scholar] [CrossRef]
- Kirsal Ever, Y.; Dimililer, K.; Sekeroglu, B. Comparison of machine learning techniques for prediction problems. In Web, Artificial Intelligence and Network Applications: Proceedings of the Workshops of the 33rd International Conference on Advanced Information Networking and Applications (WAINA-2019); Springer: Berlin/Heidelberg, Germany, 2019; pp. 713–723. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Feature Name | Code | Description of the Feature |
|---|---|---|---|
| 1 | School access | SA | Easy access to school Y = 1 N = 0 |
| 2 | Market access | MA | Access to market Y = 1 N = 0 |
| 3 | Hospital access | HA | Access to hospital Y = 1 N = 0 |
| 4 | Rented house | RH | Living in rented house Y = 1 N = 0 |
| 5 | Main source of income | MI | Main source of family income 1 = father, 2 = mother, 3 = brother, 4 = sister, 5 = other |
| 6 | Family income | FI | Total monthly income of the family 1 = 5–20k, 2 = 21–40k, 3 = 41–50k, 4 = 51–60k, 5 = above state |
| 7 | Defendant Family | DF | 1 = 1–3, 2 = 4–7, 3 = 8–11, 4 = 12–15, 5 = MORE |
| 8 | Family Size | FS | Number of people in the family 1 = 3–5, 2 = 5–8, 3 = 8–12, 4 = 12–15 |
| 9 | Father Education | FE | Highest education of the father 1 = primary, 2 = High, 3 = Graduate, 4 = Postgraduate, 5 = No Education |
| 10 | Mother Education | ME | Highest education of the mother 1 = primary, 2 = High, 3 = Graduate, 4 = Postgraduate, 5 = No Education |
| 11 | Father’s Occupation | FO | Occupation of the father 1 = Govt. sector, 2 = private sector, 3 = business, 4 = Farmer, 5 = other, 6 = none |
| 12 | Mother’s Occupation | MO | Occupation of the mother 1 = Govt. sector, 2 = private sector, 3 = business, 4 = Farmer, 5 = other, 6 = none |
| 13 | Transport facility | TF | Having transport facility Y = 1, N = 0 |
| 14 | Traveling source | TS | Conveyance Type 1 = By walk, 2 = By wan, 3 = by cycle, 4 = by car |
| 15 | Board-Exam percentage | BP | 1 = 33–50%, 2 = 51–60%, 3 = 61–70%, 4 = 71–80%, 5 = 81% and above, 6 = fail |
| 16 | Learning Facilities | LF | Having learning facilities Y = 1, N = 0 |
| 17 | Studying at home | SH | Type of study at home 1 = Family Member, 2 = Tutor, 3 = self-study |
| 18 | Education satisfaction | ES | Satisfied with the quality of education Y = 1, N = 0 |
| S. No | Feature No | Feature Code | Feature Score |
|---|---|---|---|
| 1 | 17 | LF | 0.77 |
| 2 | 03 | AH | 0.56 |
| 3 | 14 | TF | 0.53 |
| 4 | 16 | BP | 0.53 |
| 5 | 15 | SA | 0.44 |
| 6 | 02 | AM | 0.31 |
| 7 | 18 | SH | 0.29 |
| 8 | 09 | FE | 0.23 |
| 9 | 05 | EF | 0.21 |
| 10 | 13 | NS | 0.031 |
| 11 | 10 | ME | 0.030 |
| 12 | 07 | DF | 0.012 |
| S. No | Feature No | Feature Code | Feature Score |
|---|---|---|---|
| 1 | 11 | FO | 0.32 |
| 2 | 03 | HA | 0.20 |
| 3 | 02 | MA | 0.16 |
| 4 | 10 | ME | 0.16 |
| 5 | 12 | MO | 0.14 |
| 6 | 18 | SH | 0.13 |
| 7 | 16 | BP | 0.13 |
| 8 | 01 | SA | 0.12 |
| 9 | 09 | FE | 0.09 |
| 10 | 17 | LF | 0.09 |
| 11 | 8 | FS | 0.01 |
| 12 | 07 | DF | 0.003 |
| Actual | Predicted | |
|---|---|---|
| Unaffected Student | Affected Student | |
| Unaffected student | TN | FP |
| Affected student | FN | TP |
| Classifiers | Parameter Settings |
|---|---|
| DT | max_depth = 100, max_leaf_nodes = 13, min_samples_split = 10, random_state = 5, min_samples_leaf = 1 |
| MLP | Alpha = 0.007, random_state = 5, solver = ‘lbfgs’, activation = ‘relu’ |
| KNN | metric = ‘manhattan’, n_neighbors = 3, weights = ‘uniform’ |
| RF | max_depth = 10, min_samples_leaf = 5, min_samples_split = 5, n_estimators = 100 |
| NB | GaussianNB() |
| AB | n_estimators = 50, learning_rate = 1.0 |
| LR | C = 1.0, random_state = 5, solver = ‘liblinear’ |
| ET | n_estimators = 50, criterion = ‘gini’, min_samples_split = 2, min_samples_leaf = 1 |
| GB | learning_rate = 1.0, n_estimators = 50, max_depth = 1.0, random_state = 5 |
| Classifiers | Accuracy | Sensitivity | Specificity | Precision | Recall | AUC | F1 | MCC |
|---|---|---|---|---|---|---|---|---|
| DT | 73.22 | 70.73 | 75.86 | 73.10 | 73.12 | 75.90 | 0.73 | 0.466 |
| MLP | 72.38 | 76.34 | 69.86 | 74.11 | 72.12 | 79.20 | 0.73 | 0.450 |
| KNN (K = 3) | 78.00 | 86.20 | 73.68 | 81.13 | 78.00 | 83.50 | 0.74 | 0.576 |
| RF | 78.24 | 74.80 | 82.14 | 79.00 | 78.00 | 85.00 | 0.78 | 0.568 |
| NB | 69.87 | 68.06 | 71.66 | 70.00 | 70.00 | 76.50 | 0.70 | 0.397 |
| AB | 71.54 | 68.34 | 71.86 | 72.00 | 72.10 | 80.80 | 0.72 | 0.536 |
| LR | 71.54 | 70.08 | 72.95 | 72.05 | 72.00 | 78.50 | 0.72 | 0.405 |
| ET | 82.84 | 87.00 | 79.85 | 84.00 | 83.15 | 92.60 | 0.83 | 0.660 |
| GB | 77.40 | 80.19 | 75.36 | 78.00 | 77.06 | 84.90 | 0.78 | 0.549 |
| KNN (K = 3 to 9) | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| K = 3 | 78.24 | 86.20 | 73.68 |
| K = 4 | 71.12 | 84.84 | 65.89 |
| K = 5 | 75.31 | 80.43 | 72.10 |
| K = 6 | 71.54 | 81.33 | 67.07 |
| K = 7 | 73.64 | 76.02 | 71.94 |
| K = 8 | 69.95 | 74.41 | 66.66 |
| K = 9 | 75.73 | 75.22 | 76.19 |
| Model | Accuracy | Sensitivity | Specificity | AUC | Precision | Recall | F1 | MCC |
|---|---|---|---|---|---|---|---|---|
| KNN (N = 3) | 78.24 | 83.16 | 75.00 | 85.30 | 80.00 | 78.00 | 0.78 | 0.567 |
| DT | 75.73 | 68.75 | 89.87 | 75.40 | 82.00 | 76.00 | 0.76 | 0.551 |
| ET | 83.68 | 83.76 | 83.61 | 91.20 | 84.00 | 84.00 | 0.84 | 0.674 |
| GB | 79.08 | 81.48 | 77.10 | 86.00 | 79.00 | 79.00 | 0.79 | 0.583 |
| RF | 82.01 | 78.13 | 86.49 | 88.10 | 83.00 | 82.00 | 0.82 | 0.645 |
| AB | 74.90 | 73.11 | 76.67 | 81.60 | 75.00 | 75.00 | 0.75 | 0.498 |
| NB | 74.89 | 72.65 | 77.48 | 78.30 | 75.00 | 75.00 | 0.75 | 0.500 |
| LR | 78.66 | 75.57 | 82.41 | 82.70 | 79.00 | 79.00 | 0.79 | 0.577 |
| MLP | 74.06 | 77.89 | 71.53 | 79.10 | 76.00 | 74.00 | 0.74 | 0.484 |
| KNN (K = 3 to 9) | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| K = 3 | 78.26 | 82.00 | 76.74 |
| K = 4 | 76.57 | 86.90 | 70.97 |
| K = 5 | 78.15 | 81.73 | 75.56 |
| K = 6 | 76.98 | 83.87 | 72.60 |
| K = 7 | 78.24 | 78.95 | 77.60 |
| K = 8 | 78.24 | 83.67 | 74.47 |
| K = 9 | 76.99 | 78.38 | 75.78 |
| Model | Accuracy | Sensitivity | Specificity | AUC | Precision | Recall | F1 | MCC |
|---|---|---|---|---|---|---|---|---|
| KNN (K = 3) | 74.89 | 82.52 | 69.12 | 83.00 | 77.00 | 75.00 | 0.75 | 0.512 |
| DT | 71.12 | 64.97 | 82.93 | 75.10 | 77.00 | 71.00 | 0.72 | 0.455 |
| ET | 79.58 | 81.82 | 76.27 | 85.90 | 79.00 | 79.00 | 0.79 | 0.582 |
| GB | 82.01 | 83.87 | 80.00 | 87.00 | 82.00 | 82.00 | 0.82 | 0.640 |
| RF | 79.50 | 76.00 | 82.09 | 85.10 | 82.00 | 79.00 | 0.80 | 0.595 |
| AB | 71.13 | 71.64 | 70.48 | 78.80 | 72.00 | 72.00 | 0.72 | 0.420 |
| NB | 66.95 | 68.46 | 65.13 | 73.50 | 67.00 | 67.00 | 0.67 | 0.335 |
| LR | 71.12 | 71.62 | 70.47 | 76.00 | 71.00 | 71.00 | 0.71 | 0.419 |
| MLP | 72.80 | 68.89 | 77.88 | 73.50 | 74.00 | 73.00 | 0.73 | 0.464 |
| KNN (K = 3 to 9) | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| K = 3 | 74.89 | 73.95 | 67.50 |
| K = 4 | 70.71 | 73.95 | 67.50 |
| K = 5 | 77.82 | 73.95 | 67.50 |
| K = 6 | 70.71 | 73.95 | 67.50 |
| K = 7 | 73.64 | 73.95 | 67.50 |
| K = 8 | 70.71 | 73.95 | 67.50 |
| K = 9 | 70.71 | 73.95 | 67.50 |
| Reference | Dataset | Approach/Model | Accuracy |
|---|---|---|---|
| Gerristen et al. [44] | Moodle log | LR NN | 62.40% 66.10% |
| Stapel et al. [45] | Own dataset (Small dataset) | NB LR DT | 65.40% 68.20% 71.50% |
| Zohair et al. [46] | Own dataset (Small dataset) | LDA SVM | 71.10% 76.30% |
| Sekeroglu et al. [47] | SPD SAPD | BPNN | 79.22% (SPD) 80.10% (SAPD) |
| Proposed | Developed dataset (18-features) | Full features + ET Relief (12 features) + ET FCBF (12 features) + GB | 82.84% 83.68% 82.01% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhammad, Y.; Hassan, M.A.; Almotairi, S.; Farooq, K.; Granelli, F.; Strážovská, Ľ. The Role of Socioeconomic Factors in Improving the Performance of Students Based on Intelligent Computational Approaches. Electronics 2023, 12, 1982. https://doi.org/10.3390/electronics12091982
Muhammad Y, Hassan MA, Almotairi S, Farooq K, Granelli F, Strážovská Ľ. The Role of Socioeconomic Factors in Improving the Performance of Students Based on Intelligent Computational Approaches. Electronics. 2023; 12(9):1982. https://doi.org/10.3390/electronics12091982
Chicago/Turabian StyleMuhammad, Yar, Muhammad Abul Hassan, Sultan Almotairi, Kawsar Farooq, Fabrizio Granelli, and Ľubomíra Strážovská. 2023. "The Role of Socioeconomic Factors in Improving the Performance of Students Based on Intelligent Computational Approaches" Electronics 12, no. 9: 1982. https://doi.org/10.3390/electronics12091982
APA StyleMuhammad, Y., Hassan, M. A., Almotairi, S., Farooq, K., Granelli, F., & Strážovská, Ľ. (2023). The Role of Socioeconomic Factors in Improving the Performance of Students Based on Intelligent Computational Approaches. Electronics, 12(9), 1982. https://doi.org/10.3390/electronics12091982