1. Introduction
Generalized Zero-Shot Learning (GZSL) [
1] has attracted significant research interest due to its ability to transfer knowledge to unseen classes using additional class-level semantic descriptors, such as word vectors [
2] or attributes [
3]. As an extension of Zero-Shot Learning (ZSL) [
3,
4], GZSL aims to classify both seen and unseen classes simultaneously during testing. This capability is crucial in various real-world applications where the availability of labeled samples for all possible classes is limited or infeasible [
5,
6].
A key idea in GZSL is learning transferable representations, which encompass two essential concepts:
discriminative and
semantic-relevant features.
Discriminative features are crucial for accurate category discrimination, possessing strong decision-making power and promoting the classification task of unseen classes. In contrast,
semantic-relevant facilitates a shared semantic space between seen and unseen classes using pre-defined semantic descriptors, reflecting the semantic relationships between different classes as accurately as possible. GZSL can be viewed as a multi-task problem, where learning discriminative features optimizes a discrimination sub-task, and learning semantically-relevant features optimizes a visual-semantic alignment sub-task. By adopting a multi-task perspective, GZSL aims to obtain comprehensive representations between tasks that can generalize well to unseen classes during testing. However, since semantic descriptors are not specifically designed for image classification [
1,
7,
8], two main challenges arise: (1) appropriately balancing these sub-tasks and resolving their conflict, and (2) ensuring the stability and expressiveness of learned representations.
Unfortunately, existing methods tend to bypass or ignore these challenges between
discriminative and
semantic-relevant, resulting in passable performance on unseen classes. Specifically: (1) some researchers focus solely on semantic-relevant representations through elaborate visual-semantic alignment [
8,
9,
10], while others concentrate on advanced discrimination techniques to extract more generalizable discriminative representations [
11,
12]. (2) Furthermore, the conflict between discrimination and visual-semantic alignment is often neglected, as recent methods primarily focus on learning shared representations between these two sub-task [
7,
13,
14]. As a result, their poor generalization can be attributed to the discarding of some task-specific information between sub-tasks, which can be viewed as the “diamond in the rough” for GZSL. Some works in domain generalization (DG) have shown that this specific information could enhance a model’s generalization performance when classifying unseen classes [
15,
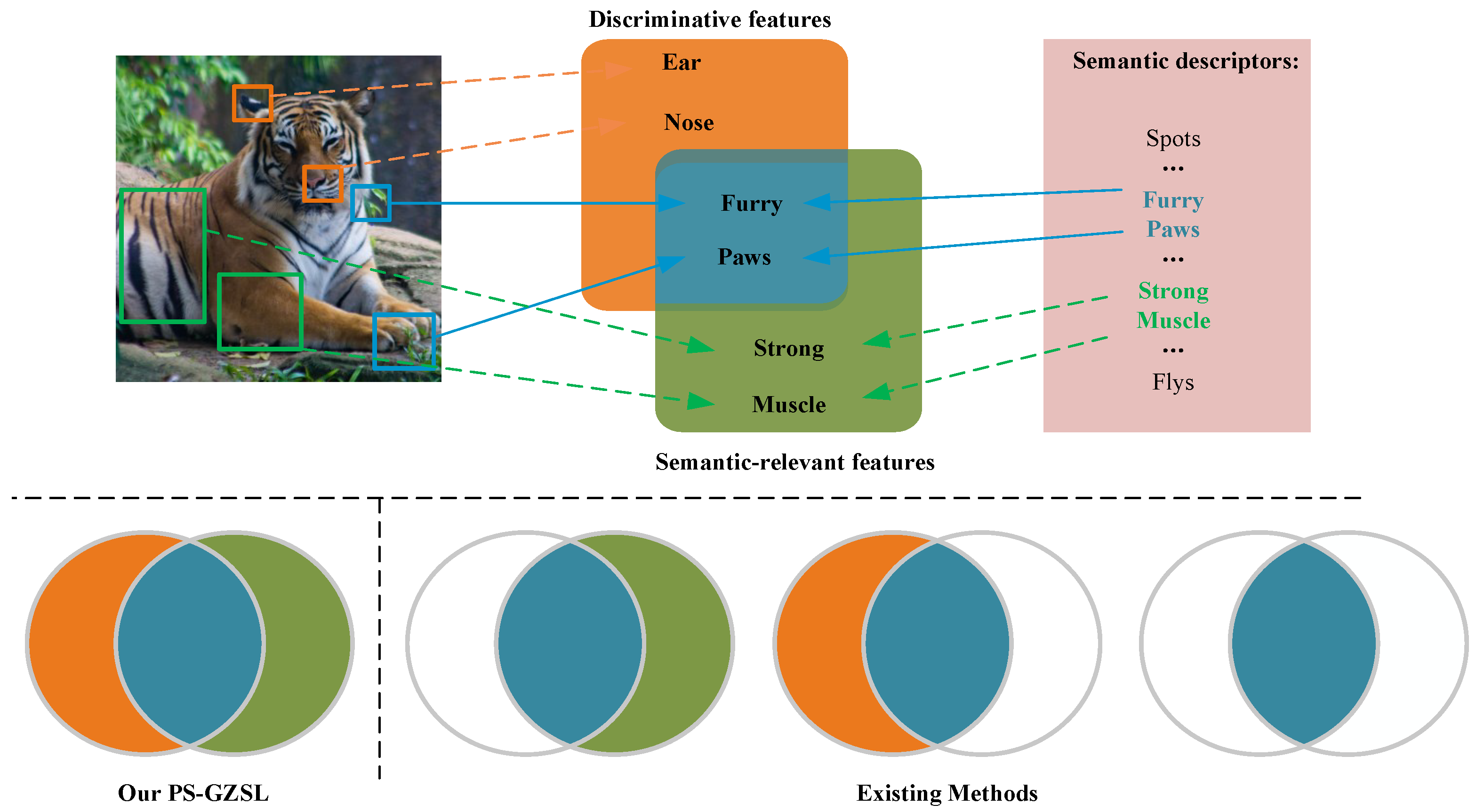
16]. For example, in the AWA1 dataset shown in
Figure 1. attributes like “Strong, Big” that are not visually discriminative can still reduce the misclassification between tigers and cats. Similarly, visual cues like the ear and nose shape are salient for classifying image samples but not represented in the semantic descriptors.
To address the aforementioned challenges and limitations, we propose a novel partially-shared representation learning network, termed PS-GZSL, which jointly preserves complementary and transferable information between discriminative and semantic-relevant features. First, to resolve the conflict between tasks and avoid information loss, PS-GZSL proposes a partially-shared multi-task learning mechanism to explicitly model both task-shared and task-specific representations. As depicted in
Figure 2, PS-GZSL utilizes three Mixture-of-Experts (MoE) [
17,
18] to factorize a visual feature into three latent representations: a task-shared discriminative and semantic representation
, a task-specific discriminative representation
, and a task-specific semantic-relevant representation
. Each sub-task corresponds to a task-specific and a task-shared representation. Second, to ensure the stability and expressiveness of learned representations, PS-GZSL draws inspiration from the success of contrastive learning [
19] and metric learning [
20], proposing two effective sub-tasks: an instance-level contrastive discrimination task and a relation-based visual-semantic alignment task. These tasks have been proven to achieve better generalization performance, respectively. To avoid representation degeneration, PS-GZSL randomly drops out experts in each MoE. Furthermore, PS-GZSL is a hybrid GZSL framework that integrates with a feature generation component. In feature generation, PS-GZSL adopts a conditional generative adversarial network [
21] with a feedback mechanism to mitigate the bias towards seen classes in the latent representation space.
In summary, the main contributions of our work can be summarized:
We describe a novel perspective grounded in multi-task learning, which reveals that existing methods exhibit an inherent generalization weakness of losing some transferable visual features.
We propose a novel GZSL method, termed partially-shared multi-task representation learning network (PS-GZSL), to jointly preserve complementary and transferable information between discriminative and semantic-relevant features
Extensive experiments on five widely-used GZSL benchmark datasets validate the effectiveness of our PS-GZSL and show that the joint contributions of the task-shared and task-specific representations result in more transferability representation.
2. Related Works
Early approaches for ZSL/GZSL can be broadly classified into two main groups: Embedding-based methods and Generative-based methods. The former group [
22,
23,
24,
25,
26,
27] learns an encoder to map the visual features of seen classes to their respective semantic descriptors. In contrast, the latter group [
21,
28,
29,
30,
31,
32] learns a conditional generator, such as cVAE [
33] or cGAN [
34], to synthesize virtual unseen features based on the seen samples and semantic descriptors of both classes.
Recent state-of-the-art methods typically graft an encoder on top of a conditional generator, with a focus on improving the transferability of visual representations. (1) Some methods emphasize preserving semantic-relevant information that corresponds to predefined descriptors. For example, CADA-VAE [
9] employs two aligned Variational Autoencoders(VAEs) to learn shared latent representations between semantic descriptors and visual features. SDGZSL [
10] integrates a disentanglement constraint and a Relation network [
20] to ensure the semantic-consistency of the learned representation. SE-GZSL [
35] uses two AutoEncoders and Mutual information maximization to capture semantic-relevant information. (2) Some others prioritize the preservation of more discriminative information. DLFZRL [
11] adopts a hierarchical factorizing approach and adversarial learning to learn the discriminative latent representation, regardless of whether it is semantically relevant or not. DR-GZSL [
7] utilizes an auxiliary classifier and a shuffling disentanglement mechanism to extract the discriminative part of the semantic-relevant representation. CE-GZSL [
13] integrates the semantic-supervised learning module and label-supervised discrimination module in the latent space to learn discriminative visual representations. In summary, these methods differ in the transferable characteristics of the data they model for recognition.
In contrast to existing methods, we argue that both discriminative and semantic-relevant representations are important for recognizing test classes. However, due to the conflict between them, these methods implicitly discard some valuable features. We are thus motivated to adopt the soft-parameter sharing mechanism [
17,
36] in multi-task learning. This flexibility stems is derived from information routing between tasks, and its characteristics of seeking similarities while preserving differences have led to significant successes in multi-task learning domains such as recommendation systems. We are the first to apply this idea and revise it for representation learning in GZSL. A novel multi-task representation learning paradigm is proposed that models task-specific and task-shared representations in parallel, unlike existing paradigms [
37,
38] that use a single MoE for each sub-task and a hierarchical structure. For the sake of clear understanding, we highlight the distinctions between our approach and those counterparts in
Table 1.
3. Methods
To learn more transferable representations, in this section, we present our proposed PS-GZSL method, which combines MoE, a partially-shared mechanism, an instance contrastive discrimination module, and a relation-based visual-semantic alignment module. To alleviate the bias towards seen, we also adopt a feature generation module with latent feedback. The overall framework of our proposed PS-GZSL is shown in
Figure 2, Then, the definition of the ZSL/GZSL problem and all the above modules are explained in detail.
3.1. Problem Definition
In Zero-Shot learning, we are given two disjoint sets of classes: with seen classes and with unseen classes, where we have and . For the semantic descriptors = , each class, whether seen or unseen, is associated with a semantic descriptor that can take the form of sentences or attributes. Under ZSL setting, we have and available during training phase. Let denote the extracted feature instances of images. The goal of ZSL is to learn a model f to classify unseen samples during the test phase, which can be formulated as . GZSL is a more realistic and challenging problem that requires f to handle both seen and unseen samples: .
3.2. Task-Shared and Task-Specific Representations
To begin our PS-GZSL, we first provide definitions for three visual representations that are concerning discriminative and semantic-relevant concepts.
Discriminative and Semantic-relevant Representations. Firstly, we define task-shared discriminative and semantic-relevant representations to encode the discriminative features of images that are related to corresponding semantic descriptors. These visual features are used for the both discrimination task and the visual-semantic alignment task during the training phase.
Discriminative but Non-semantic Representations. Secondly, discriminative but non-semantic features are encoded in discrimination task-specific representations, denoted as . These features are important for discrimination, but they may not contribute to the visual-semantic alignment task since not represented in the semantic descriptors.
Non-Discriminative but Semantic-relevant Representations. Finally, non-discriminative but semantic-relevant features are encoded in visual-semantic alignment task-specific representations, denoted as . These features are not discriminative in seen classes but may be critical for recognizing unseen classes. Thus, these features only contribute to the visual-semantic alignment task during training.
3.3. Representation Learning
As shown in
Figure 2, Our encoder module consists of three parallel Mixture-of-experts (MoE) modules (
), which explicitly factorize a visual feature
x into three latent representations:
,
, and
, i.e.,
=
,
=
and
=
.
3.3.1. Mixture-of-Experts
PS-GZSL adopts a gated MoE module to replace simple Multi-Layer Perceptrons (MLPs) in order to obtain more expressive representations, MoE is a neural network architecture that comprises several experts, each of which specializes in a specific part of the input space. The output of the network is then computed as a weighted combination of the outputs of the experts by a gating network, as shown in
Figure 3.
Given a visual feature as input, the MoE module can be formulated as:
where, the gate network
g combines the results of
n expert networks, where
and
represents the
ith logit of the output, indicating the weight assigned to expert
.
We denote the aforementioned three MoE modules as , and for the task-shared representation and two task-specific representation and , respectively. It’s worth noting that we’ve incorporated the dropout technique in the gate network, which randomly discards some outputs of the experts. This technique helps prevent overfitting and also ensures that the representations (, , and ) remain informative for subsequent sub-tasks.
3.3.2. Instance Contrastive Discrimination Task
According to the definition above, both
and
are expected to capture the discriminative features. For convenience, we denote
w =
=
. To compare the similarities and differences of visual representations
w, an instance contrastive discrimination task is proposed, which assigns samples to different categories according to the comparison results. Specifically, PS-GZSL takes Supervised Contrastive Learning (SupCon) [
19] loss as the objective function in this task since SupCon shows better generalization performance and stronger robustness in discriminative representation learning compared with other metric learning loss.
We follow the strategy proposed in [
19] where the representation
w is further propagated through a projection network
P (as shown in
Figure 4) to obtain a new representation denoted as
z =
. For every
encoded from a visual feature
, the SupCon loss of
is as follows:
where,
denotes the temperature parameter for stable training.
represents the indices of all positives in the mini-batch that are distinct from
i, and
is its cardinality.
To simultaneously learn the MoE modules
,
, and the projection network
P, the loss function for this discrimination task is calculated as the sum of instance-level SupCon loss within a batch of samples
I.
Such a contrastive learning encourages and to capture the strong inter-class discriminative features, and intra-class structure shared in the latent space, making both and more discriminative and more transferable. Furthermore, we demonstrate the superiority of SupCon loss over softmax loss in ablation experiments.
3.3.3. Relation-Based Visual-Semantic Alignment Task
In the same way, both
and
are devised to capture semantic-relevant information that corresponds to the annotated semantic descriptors
A. For convenience, we denote
v =
=
. In order to learn semantic-relevant representations
v without directly mapping visual features into the semantic space, we adopt a Relation network in [
20] as a visual-semantic alignment task. The goal is to maximize the similarity score (
) between
v and the corresponding semantic descriptor
a through a deeper end-to-end architecture, which includes a learned nonlinear metric in the form of our alignment task. Thus, the objective of this task is to accurately measure the similarity score between pairs of
v and
a via a neural network. The similarity score
of the matched pairs is set to 1, while mismatched pairs are assigned 0, which can be formulated as:
where
t and
c refer to the
t-th visual sample’s semantic-relevant representation and
c-th class-level semantic descriptor from the seen classes,
and
denote the ground truth label of
and
.
In [
20], they utilize mean square error(MSE) as a loss function while ignoring the class-imbalance problem in zero-shot learning. Moreover, as SupCon requires a large batch size, “Softmax + Cross Entropy” is a more efficient alternative than MSE in this scenario (as shown in
Figure 5).
Denote the relation module as
R. We can calculate the loss function of this task as:
where,
S denotes the number of seen classes, and
denotes the scaling factor to stable the softmax activation for robust performance.
3.4. Feature Generation with Latent Feedback
In order to alleviate the phenomenon that encoded representations are biased towards seen classes in GZSL, we integrate the proposed representation learning method on top of a conditional GAN (cGAN) [
21]. Specifically, we adopt a conditional generator network G to generate virtual unseen features
, here
represent a Gaussian noise. In the meanwhile, we train a discriminator
D to distinguish between a real pair
and a generated pair
. The generator
G and the discriminator
D are jointly trained by minimizing the adversarial objective given as:
where
and
represent the joint distribution of real/synthetic visual-semantic pairs, respectively.
However, the objective stated above does not guarantee that the generated features are discriminative or semantic-relevant. Drawing on the feedback mechanism in [
13,
21,
39], we aim to improve the quality of generated features by passing them through the aforementioned multi-task network. Therefore, Equation (
6) can be reformulated as:
3.5. Training and Inference
As a summary, the overall loss of our proposed method is formulated as:
Given visual features and corresponding semantic descriptors from seen classes, PS-GZSL solves GZSL in four steps:
Training feature generation and representation learning models based on Equation (
8).
These learned models are then used to synthesize and extract unseen class representations .
Using real visual samples x from seen classes for training the partially-shared representation learning part and synthesized visual samples for tuning generator.
The final generalized zero-shot classifier is a single layer linear softmax classifier, learned on
and
c (extracted from real seen
x and synthesized samples
), as depicted in
Figure 6.
4. Experiments
4.1. Datasets
We perform our PS-GZSL on five widely used benchmark datasets for GZSL, including Animals with Attributes 1&2 (AWA1 [
3] & AWA2 [
1]), Caltech-UCSD Birds-200-2011 (CUB) [
40], Oxford Flowers (FLO) [
41]), and SUN Attribute (SUN) [
42]. For visual features, we follow the standard GZSL practice of using ResNet101 [
43] pre-trained on ImageNet-1k [
44] without fine-tuning, resulting in 2048-dimensional features for each image. The semantic descriptors used for AWA1, AWA2, and SUN are their respective class-level attributes. For CUB and FLO, the semantic descriptors are generated from 10 textual descriptions by character-based CNN-RNN [
45]. In addition, we employ the Proposed Split(PS) in [
1] to split seen and unseen classes on each dataset. The statistics of the datasets and GZSL split settings are illustrated in
Table 2.
4.2. Metrics
To assess the model performance in GZSL setting, we use the harmonic mean of per-class Top-1 accuracy on seen classes and unseen classes, formulated as , where S and U represent seen accuracy and unseen accuracy, respectively. In addition, we adopt U as the evaluation metric for ZSL.
4.3. Implementation Details
In our PS-GZSL, all networks are implemented with Multi-Layer Perceptrons(MLPs). The architecture of the discriminator and generator of the feature generation architectures consist of single-layer MLPs with a 4096-unit hidden layer activated by LeakyReLU. In representation learning, each MoE module contains three experts and corresponds to a gate network. The dimension of task-specific representation (
&
) and task-shared representation (
) are set to 1024 in all of the five datasets. For the projection network
P, we set the size of the projection’s output
z to 256 for AWA2, FLO, and SUN and 512 for AWA1 and CUB. The relation network
R contains two FC+ReLU layers, and we utilize 2048 hidden units for AWA1, AWA2, and CUB and 1024 units for FLO and SUN. The difference among datasets has motivated us to perform numerous experiments aimed at determining the optimal number of synthesized unseen visual instances in each dataset. Once PS-GZSL is trained, we use a fixed 400 per unseen class for CUB, 2400 for AWA1&2, 600 for FLO, and 100 for SUN. The weighting coefficients in Equation (
7) are set to
= 0.001 and
= 0.001, and the value of temperature in Equations (
2) and (
5) are set to
= 0.1 and
= 0.1. We optimize the overall loss function (Equation (
8)) with the Adam optimizer, using
= 0.5,
= 0.999. The mini-batch size is set to 512 for AWA1, AWA2, CUB, and SUN, and 3072 for FLO in our method. All experiments are implemented with PyTorch, and trained on a single NVIDIA RTX 2080Ti GPU.
4.4. Comparison with State-of-the-Arts
Recently, some methods have introduced transductive zero-shot learning on target datasets, where they use unlabeled unseen samples for training models, leading to significant performance increases. However, it is costly and even unrealistic in real-world zero-shot scenarios. Thus, we only present results under the inductive setting.
Our PS-GZSL is compared with other GZSL methods on five widely used datasets without fine-tuning the pre-trained backbone. Results of our method in GZSL are given in
Table 3, which indicates that PS-GZSL is compatible with the state-of-the-art. Specifically, PS-GZSL attains the best harmonic mean
H on four datasets, i.e., 70.6 on AWA1, 71.8 on AWA2, 67.4 on CUB, and 43.3 on SUN. Notably, on CUB, PS-GZSL is the first one that attains a performance > 70.0 on unseen accuracy, which is even higher than the seen accuracy. This is because PS-GZSL retains more information in the learned representations to enhance GZSL classification during testing. As a result, representations for seen classes contain some redundancy, which adversely affects their classification accuracy. On FLO, PS-GZSL achieves the second-best harmonic mean
H with 73.8, only lower than FREE [
14]. However, PS-GZSL outperforms FREE by a considerable margin on the other four datasets. These results show that PS-GZSL can acquire classification knowledge transferable to unseen classes by utilizing the partially-shared mechanism and MoE, thereby learning more transferable representations from the seen classes. Specifically, by explicitly preserving these task-specific representations, the three MoE modules can effectively reduce the loss of information caused by the conflict between discrimination and visual-semantic alignment, thus enabling the preservation of more useful features for the testing phase.
Furthermore, we also report the performances of our PS-GZSL in the conventional ZSL scenario, as presented in
Table 4. To provide a comprehensive comparison, we have selected both previous conventional ZSL methods and recent GZSL methods under the conventional zero-shot setting. PS-GZSL achieves the best performance on three datasets and the second-best on FLO and SUN. This shows its superiority over existing GZSL methods on unseen classes and its strong generalization ability. These results prove the effectiveness of our PS-GZSL in both GZSL and conventional ZSL.
4.5. Ablation Studies
Ablation studies were conducted to gain further insight into our PS-GZSL, evaluating the effects of different model architectures and representation components.
4.5.1. t-SNE Visualization
To further validate the transferability of our PS-GZSL, we visualize the task-shared representation
and the multi-task joint representation
from unseen visual samples in
Figure 7. We choose 10 unseen categories of test unseen set on AWA2 and 50 unseen categories of test unseen set on CUB. These data are sufficient in quantity and explicitly show the model’s learned representation for the class comparison in unseen classes. Clearly, as we expected, the multi-task joint representation is more discriminative than the individual task-shared representation. However, we can still see discriminative patterns from
, which is consistent with the assumption of previous methods based on learning the shared parts. This demonstrates that these task-shared representations may help classify between these categories, but the discriminative knowledge transfer from known to unknown categories is impaired due to the loss of task-specific information.
4.5.2. Effectiveness of Task-Shared & Task-Specific Representations
In order to validate our key motivation for the partially-shared mechanism of PS-GZSL: In addition to task-shared
discriminative and semantic-relevant representations, task-specific
only discriminative representations and
only semantic-relevant representations are both useful in GZSL. We studied the performance of different combinations among
,
and
. The results are presented in
Figure 8, where we observe that using
alone achieves comparable poor performance. However, when
is concatenated with either
or
, the performance is improved, which demonstrates that both the
and
are helpful in GZSL. The best performance is achieved when we concatenate
,
, and
together. This reveals that task joint representation
can capture complete correlation information among categories and their semantic descriptors, resulting in more informative and transferable representations for the test phase. Thus, both the task-shared and task-specific representations between discrimination and visual-semantic alignment are crucial to improve the classification performance in GZSL.
4.5.3. Analysis of Model Components
To assess the contributions of each component in PS-GZSL, different stripped-down architectures of we proposed methods were evaluated. The GZSL performance of each version on the AWA2 and CUB is represented in
Table 5.
We observe that PS-GZSL outperforms PS-GZSL w/o MoE which validates that the MoE can improve the transferability of representation in GZSL. More importantly, we observe that PS-GZSL w/o MoE&PS outperforms PS-GZSL w/o MoE. This reveals the fact that simply splitting the visual encoder into three branches is not sufficient for learning the ideal transferable representations. Because any arbitrary mutually exclusive information decomposition can satisfy the regularizer, even if the encodes total information and , are non-informative for both tasks. This further demonstrates the superiority of our MoE module and expert dropout mechanism, which avoids the inexpressive issue among , , and . The above results indicate that our partially-shared mechanism and MoE module are mutually complementary in our method and prove that jointly preserving shared and specific representations between discriminative features and semantic features can preserve more complete and transferable information.
4.6. Hyper-Parameter Analysis
In our PS-GZSL approach, the hyperparameters that exert the greatest influence are the number of synthesized samples per class, the number of experts in each branch, and the dimensions of , , and .
Visualization of Different Number of Synthesized Samples. The number of synthesized samples per class was varied, as shown in
Figure 9. The results show that the performance on all four datasets increased with an increasing number of synthesized examples. This demonstrated that the bias towards seen problems was relieved by the feature generation in our PS-GZSL. However, generating too many samples will impair the accuracy of seen classes (
) and eventually hamper the harmonic mean
. Therefore, selecting an appropriate value to achieve the balance between
and
is important.
Visualization of Different Number of Experts. Since we use MoE modules for each branch, the architecture of the expert network is very important for our method. As shown in
Figure 10, we study different numbers of experts for task-specific and task-shared, noted as
num_sp and
num_sh, respectively. As the numbers of task-specific experts and task-shared experts increase, the harmonic mean is boosted and then drops, which achieves the peek performance when num_sp = 3 and num_sh = 3. Thus, for convenience, both num_sp and num_sh are set to 3 in order to achieve a considerable performance in all of the remaining datasets.
Visualization of Different Representations Dimensions. Intuitively, the dimensions
,
, and
will have a significant impact on the optimization of these two sub-tasks. This will ultimately affect the transferability and expressiveness of the concatenated final representations. To explore the sensitivity of our PS-GZSL to the dimensionality in the latent space. As shown in
Figure 11, the harmonic mean accuracy of PS-GZSL for different latent dimensions on AWA2 and CUB, i.e., 256, 512, 1024, and 2048 for both task-specific and task-shared representations(denoted as
spSize and
shSize, respectively) are represented. As
spSize and
shSize are both set to 1024, PS-GZSL consistently performs better than all others on AWA2 and CUB. Therefore, both
spSize and
shSize are set to 1024 in all of the remaining datasets.
5. Conclusions
In this paper, we propose a new way of learning the composite method by accounting for all the features based on multi-task representation learning. Specifically, the recent representation learning method in GZSL discards some specific information between two tasks (i.e., classification task and visual semantic alignment task). As explained in the introduction, this specific information can be either discriminative or semantic-relevant, depending on their contribution to the testing phase.
Further on, we believe that jointly preserving task-specific and task-shared features leads to a more complete and more transferable representation in GZSL. To support this claim, a novel representation learning method termed PS-GZSL is proposed. Unlike most existing methods, PS-GZSL explicitly factorizes visual features into one task-shared and two task-specific representations through the partially-shared mechanism between the discrimination and visual semantic alignment task. This flexibility enables PS-GZSL to preserve more complete knowledge. Furthermore, PS-GZSL carefully designs the mixture of experts and gate networks for learning informative representations for each branch. As evaluated in extensive experiments, the good transferability of PS-GZSL has been demonstrated.
As a starting point, this study shows the potential ability of the partially-shared mechanism in learning transferable representation in GZSL. There is still a large research space in this direction. First, the relative loss weight ratio of each sub-task is set to 1, but future work could investigate the use of adaptive weights to balance the two tasks during optimization. Second, ideally, the encoding information of task-shared and task-specific representations should be no redundancy. It is also important to devise a regularizer to accomplish this. In the future, we will investigate these potential directions.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}