
An Enhanced Detection Method of PCB Defect Based on Improved YOLOv7

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
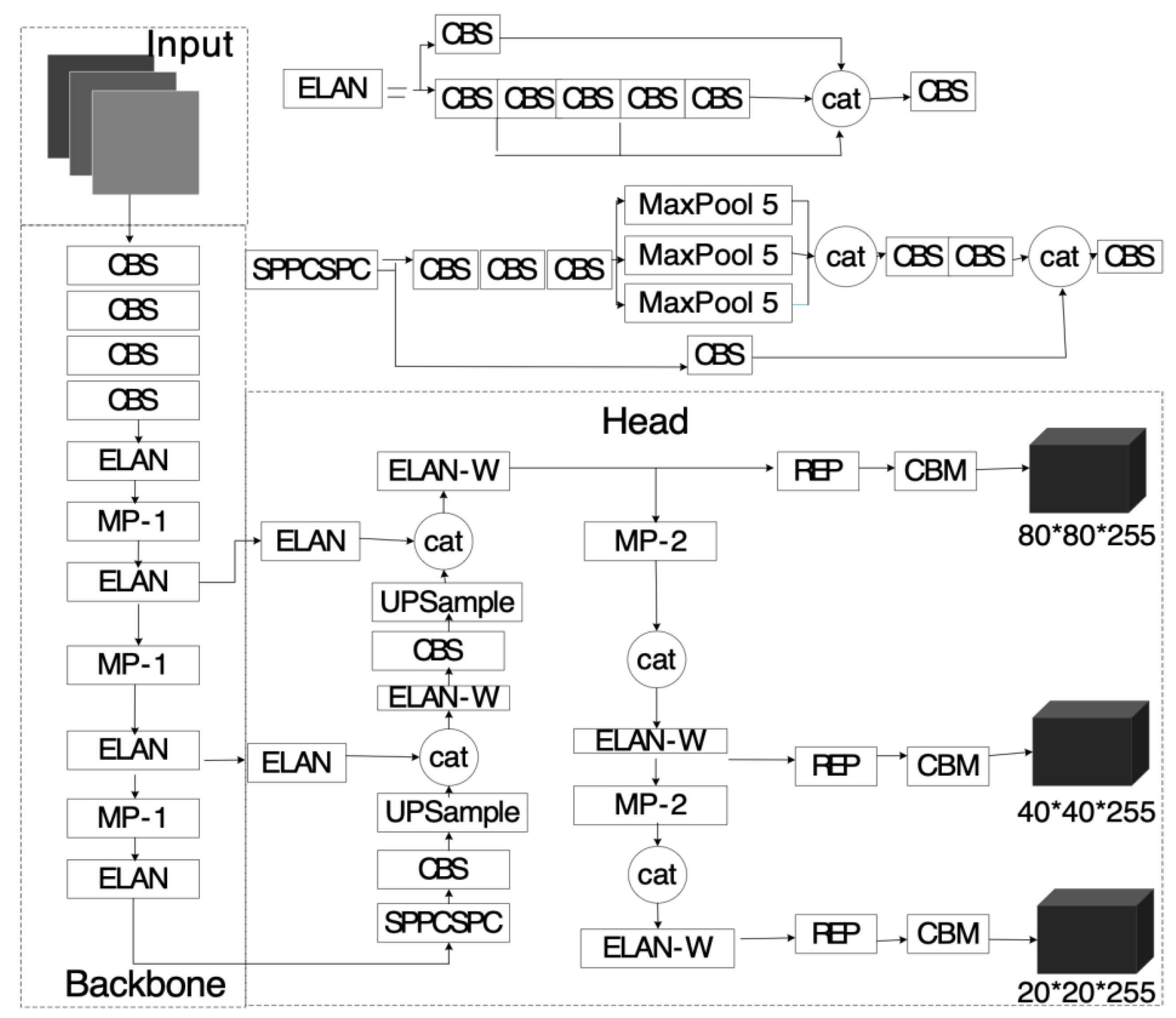
3.1. YOLOv7 Description
3.2. Improved Swin Transformer v2
3.2.1. Swin Transformer v2
3.2.2. SwinV2_TDD
3.3. Improved SA Mechanism
3.3.1. SA
3.3.2. MFSA
3.4. Change the Activation Function to Mish
3.5. Enhanced YOLOv7 Backbone
4. Results
4.1. Experimental Conditions
4.2. Dataset
4.3. Evaluation Indicators
4.4. Analysis of Experimental Results
4.4.1. Performance Analysis of SwinV2_TDD Structure
4.4.2. MFSA Magnification Factor Experiment
4.4.3. Performance Analysis of MFSA Mechanism
4.4.4. Comparison of Model Performance with Different Activation Functions
4.4.5. Comparison of Performance between Different Models
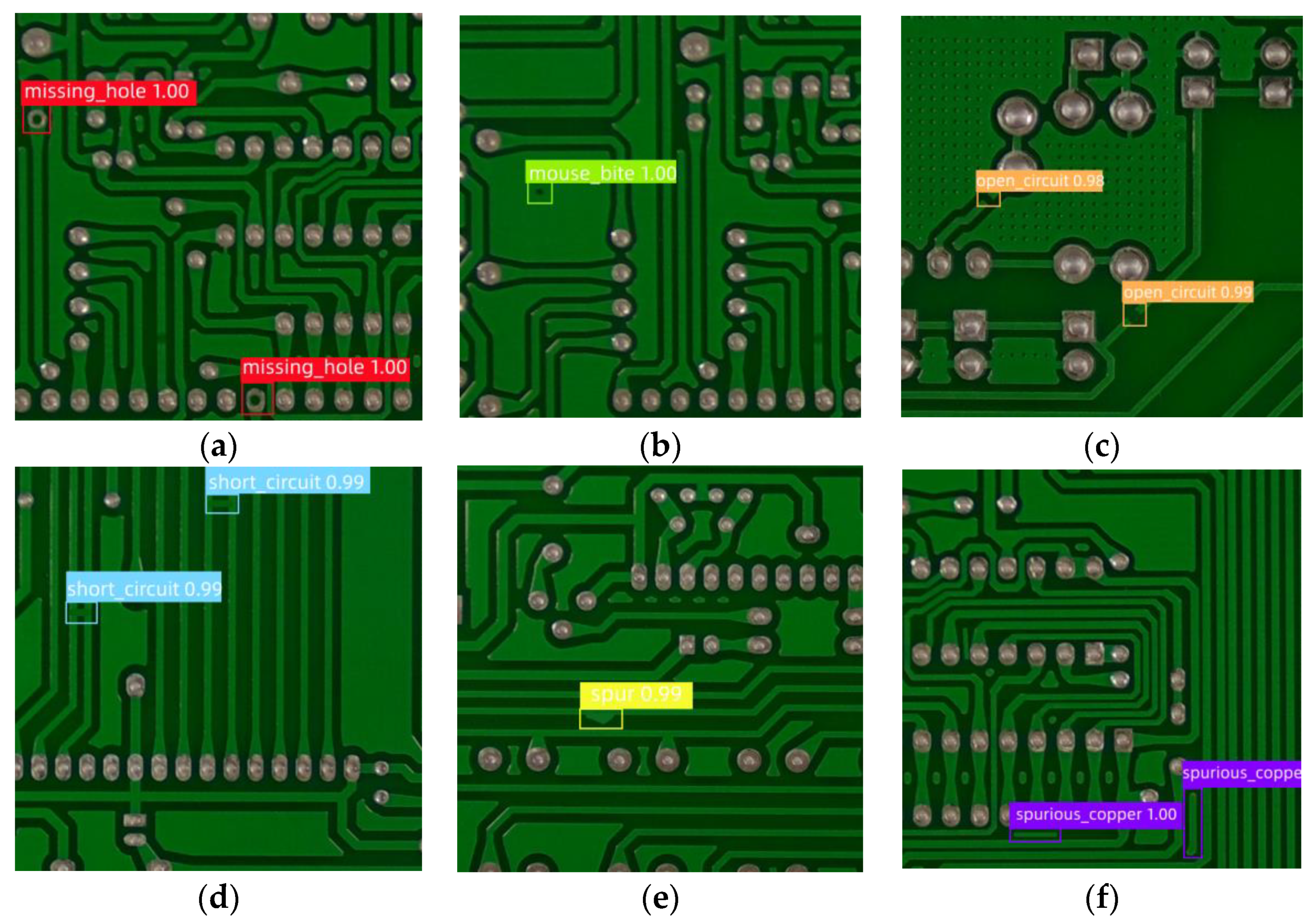
4.4.6. Display of Detection Effect
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, L.J.; Zhang, X.; Wang, C.Y.; Wang, L.F.; Li, S.; Song, Y.X.; Zhang, L.Q. Experimental study of micro-holes position accuracy on drilling flexible printed circuit board. In Proceedings of the 11th Global Conference on Sustainable Manufacturing, Berlin, Germany, 23–25 September 2013. [Google Scholar]
- Deng, L. Research on PCB Surface Assembly Defect Detection Method Based on Machine Vision. Master’s Thesis, Wuhan University of Technology, Wuhan, China, 2019. [Google Scholar]
- Zhu, Y.; Ling, Z.G.; Zhang, Y.Q. Research progress and prospect of machine vision technology. J. Graph. 2020, 41, 871–890. [Google Scholar]
- Khalid, N.K.; Ibrahim, Z.; Abidin, M.S.Z. An Algorithm to Group Defects on Printed Circuit Board for Automated Visual Inspection. Int. J. Simul. Syst. Sci. Technol. 2008, 9, 1–10. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Liu, Z.; Qu, B. Machine vision based online detection of PCB defect. Microprocess. Microsyst. 2021, 82, 103807. [Google Scholar] [CrossRef]
- Kim, J.; Ko, J.; Choi, H.; Kim, H. Printed circuit board defect detection using deep learning via a skip-connected convolutional autoencoder. Sensors 2021, 21, 4968. [Google Scholar] [CrossRef]
- Gaidhane, V.H.; Hote, Y.V.; Singh, V. An efficient similarity measure approach for PCB surface defect detection. Pattern Anal. Appl. 2018, 21, 277–289. [Google Scholar] [CrossRef]
- Annaby, M.H.; Fouda, Y.M.; Rushdi, M.A. Improved normalized cross-correlation for defect detection in printed-circuit boards. IEEE Trans. Semicond. Manuf. 2019, 32, 199–211. [Google Scholar] [CrossRef]
- Tsai, D.M.; Huang, C.K. Defect detection in electronic surfaces using template-based Fourier image reconstruction. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 9, 163–172. [Google Scholar] [CrossRef]
- Cho, J.W.; Seo, Y.C.; Jung, S.H.; Jung, H.K.; Kim, S.H. A study on real-time defect detection using ultrasound excited thermography. J. Korean Soc. Nondestruct. Test. 2006, 26, 211–219. [Google Scholar]
- Dong, J.Y.; Lu, W.T.; Bao, X.M.; Luo, S.Y.; Wang, C.Q.; Xu, W.Q. Research progress of the PCB surface defect detection method based on machine vision. J. Zhejiang Sci.-Tech. Univ. (Nat. Sci. Ed.) 2021, 45, 379–389. [Google Scholar]
- Chen, S. Analysis of PCB defect detection technology based on image processing and its importance. Digit. Technol. Appl. 2016, 10, 64–65. [Google Scholar]
- Li, Z.M.; Li, H.; Sun, J. Detection of PCB Based on Digital Image Processing. Instrum. Tech. Sens. 2012, 8, 87–89. [Google Scholar]
- Liu, B.F.; Li, H.W.; Zhang, S.Y.; Lin, D.X. Automatic Defect Inspection of PCB Bare Board Based on Machine Vision. Ind. Control. Comput. 2014, 27, 7–8. [Google Scholar]
- Malge, P.S.; Nadaf, R.S. PCB defect detection, classification and localization using mathematical morphology and image processing tools. Int. J. Comput. Appl. 2014, 87, 40–45. [Google Scholar]
- Moganti, M.; Ercal, F. Automatic PCB inspection systems. IEEE Potentials 1995, 14, 6–10. [Google Scholar] [CrossRef]
- Ray, S.; Mukherjee, J. A Hybrid Approach for Detection and Classification of the Defects on Printed Circuit Board. Int. J. Comput. Appl. 2015, 121, 42–48. [Google Scholar] [CrossRef]
- Ardhy, F.; Hariadi, F.I. Development of SBC based machine-vision system for PCB board assembly automatic optical inspection. In Proceedings of the 2016 International Symposium on Electronics and Smart Devices (ISESD), Bandung, Indonesia, 29–30 November 2016; pp. 386–393. [Google Scholar]
- Baygin, M.; Karakose, M.; Sarimaden, A.; Akin, E. Machine vision-based defect detection approach using image processing. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017; pp. 1–5. [Google Scholar]
- Ma, J. Defect detection and recognition of bare PCB based on computer vision. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 11023–11028. [Google Scholar]
- Deng, Y.S.; Luo, A.C.; Dai, M.J. Building an automatic defect verification system using deep neural network for pcb defect classification. In Proceedings of the 2018 4th International Conference on Frontiers of Signal Processing (ICFSP), Poitiers, France, 24–27 September 2018; pp. 145–149. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Huang, W.; Wei, P. A PCB dataset for defects detection and classification. arXiv 2019, arXiv:1901.08204. [Google Scholar]
- He, X.Z. Research on Image Detection of Solder Joint Defects Based on Deep Learning. Master’s Thesis, Southwest University of Science and Technology, Mianyang, China, 2021; pp. 30–38. [Google Scholar]
- Geng, Z.; Gong, T. PCB surface defect detection based on improved Faster R-CNN. Mod. Comput. 2021, 19, 89–93. [Google Scholar]
- Ding, R.; Dai, L.; Li, G.; Liu, H. TDD-net: A tiny defect detection network for printed circuit boards. CAAI Trans. Intell. Technol. 2019, 4, 110–116. [Google Scholar] [CrossRef]
- Sun, C.; Deng, X.Y.; Li, Y.; Zhu, J.R. PCB defect detection based on improved Inception-ResNet-v2. Inf. Technol. 2020, 44, 4. [Google Scholar]
- Hu, S.S.; Xiao, Y.; Wang, B.S.; Yin, J.Y. Research on PCB defect detection based on deep learning. Electr. Meas. Instrum. 2021, 58, 139–145. [Google Scholar]
- Li, C.F.; Cai, J.L.; Qiu, S.H.; Liang, H.J. Defect detection of PCB based on improved YOLOv4 algorithm. Electron. Meas. Technol. 2021, 44, 146–153. [Google Scholar]
- Wang, S.Q.; Lu, H.; Lu, D.; Liu, Y.; Yao, R. PCB Board Defect Detection Based on Lightweight Artificial Neural Network. Instrum. Tech. Sens. 2022, 5, 98–104. [Google Scholar]
- Zhou, W.J.; Li, F.; Xue, F. Identification of Butterfly Species in the Wild Based on YOLOv3 and Attention Mechanism. J. Zhengzhou Univ. (Eng. Sci.) 2022, 43, 34–40. [Google Scholar] [CrossRef]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Misra, D. Mish: A self-regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Kateb, Y.; Meglouli, H.; Khebli, A. Steel surface defect detection using convolutional neural network. Alger. J. Signals Syst. 2020, 5, 203–208. [Google Scholar] [CrossRef]
- Guo, X. Research on PCB Bare Board Defect Detection Algorithm Based on Deep Learning. Master’s Thesis, Nanchang University, Nanchang, China, 2021. [Google Scholar] [CrossRef]
- Guo, D.; Qiu, B.; Liu, Y.; Xiang, G. Supernova Detection Based on Multi-scale Fusion Faster RCNN. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiments | P/% | R/% | mAP/% | mAP0.5:0.95/% |
|---|---|---|---|---|
| YOLOv7s | 86.47 | 97.21 | 95.08 | 51.25 |
| Swin Transformer v2-YOLOv7 | 89.03 | 98.87 | 97.14 | 52.47 |
| SwinV2_TDD-YOLOv7 | 90.21 | 99.11 | 97.54 | 53.50 |
| Magnification Factor | mAP/% | FPR/% |
|---|---|---|
| 1 | 93.23 | 7.64 |
| 2 | 96.05 | 5.22 |
| 3 | 97.16 | 4.41 |
| 4 | 96.78 | 5.60 |
| 5 | 95.56 | 6.85 |
| 6 | 93.04 | 7.02 |
| 7 | 93.73 | 7.19 |
| 8 | 91.56 | 7.78 |
| 9 | 91.04 | 8.56 |
| Experiments | P/% | R/% | mAP/% | mAP0.5:0.95/% |
|---|---|---|---|---|
| YOLOv7s | 86.47 | 97.21 | 95.08 | 51.25 |
| SA-YOLOv7 | 88.63 | 98.21 | 96.54 | 51.92 |
| MFSA-YOLOv7 | 89.88 | 98.84 | 97.16 | 52.73 |
| Experiments | P/% | R/% | mAP/% | mAP0.5:0.95/% |
|---|---|---|---|---|
| Sigmoid | 83.62 | 94.19 | 92.38 | 48.61 |
| ReLU | 85.41 | 96.12 | 94.78 | 50.93 |
| SiLU | 86.47 | 97.21 | 95.08 | 51.25 |
| Mish | 87.93 | 98.34 | 96.17 | 51.74 |
| Algorithms | P/% | R/% | mAP/% | mAP0.5:0.95/% |
|---|---|---|---|---|
| SSD512 | 84.07 | 94.85 | 92.09 | 48.79 |
| YOLOv3 | 85.13 | 95.36 | 92.75 | 49.12 |
| YOLOv5s | 86.47 | 97.21 | 94.69 | 50.53 |
| YOLOv7s | 87.21 | 97.81 | 95.08 | 51.25 |
| Faster R-CNN | 85.42 | 96.48 | 93.08 | 49.87 |
| DenseNet | 87.35 | 97.46 | 94.12 | 51.39 |
| Our proposed | 94.53 | 99.49 | 98.74 | 53.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Kang, H. An Enhanced Detection Method of PCB Defect Based on Improved YOLOv7. Electronics 2023, 12, 2120. https://doi.org/10.3390/electronics12092120
Yang Y, Kang H. An Enhanced Detection Method of PCB Defect Based on Improved YOLOv7. Electronics. 2023; 12(9):2120. https://doi.org/10.3390/electronics12092120
Chicago/Turabian StyleYang, Yujie, and Haiyan Kang. 2023. "An Enhanced Detection Method of PCB Defect Based on Improved YOLOv7" Electronics 12, no. 9: 2120. https://doi.org/10.3390/electronics12092120