Abstract
In the era of digital information, online platforms play a crucial role in shaping public opinion. However, the extensive spread of misinformation and fake news poses a significant challenge, largely fueled by non-credible users. Detecting user credibility is vital for ensuring the reliability of information on these platforms. This study employs supervised machine learning algorithms, leveraging key user features to enhance credibility detection. Feature selection methods, specifically SelectKBest and correlation-based algorithms, are explored for their impact on X-Platform user credibility detection. Utilizing various classifiers, including support vector machine, logistic regression, and XGBoost, experiments are conducted on the ArPFN dataset, which is a labeled, balanced, publicly available dataset. The evaluation includes measures like accuracy, precision, recall, and F1-score to assess efficiency. This research considers feature categories and selection methods with SML to detect their impact on the accuracy of X-Platform user credibility detection, making this research a reference for researchers and practitioners working in the field of SML, feature engineering, and social media analysis. We aim to advance the field’s understanding of effective strategies for mitigating the spread of fake news. The novelty of this study lies in the comprehensive exploration of feature selection methods and their influence on credibility detection, contributing valuable insights for future research in this domain.
1. Introduction
The landscape of online information dissemination is marred by the proliferation of misinformation, necessitating advanced strategies for user credibility detection. In this context, our work stands out due to its unique focus on the impact of feature selection techniques, specifically SelectKBest and correlation-based algorithms, on X-Platform user credibility detection. By employing various supervised machine learning classifiers, our goal is not only to address current challenges, including overcoming limitations of handcrafted features that are problem-specific and complicated to generalize [1], but also to provide novel insights into the efficacy of different methods for credibility assessment.
This study offers a distinctive perspective, contributing to the advancement of techniques combating the spread of fake news on online platforms. Recognizing the importance of feature selection during the building of a machine-learning model is a crucial step. In real-life problems, not all features in the dataset contribute to model development. Adding irrelevant features not only reduces the model’s ability to generalize but also decreases overall classifier accuracy. Moreover, increasing the number of variables in a model adds complexity.
Detecting trusted sources in online social networks (OSNs), especially on platforms like X-Platform, is vital due to their role as major sources of information that attract individuals of all ages and positions. Therefore, the detection of untrustworthy X-Platform users is crucial in combating the proliferation of misinformation in our communities.
Many studies that applied supervised machine learning (SML) methods for X-Platform user credibility detection (XUCD) as a classification problem often treated user features equally. However, a significant challenge in data classification involves managing high-dimensional datasets, further worsened by the existence of irrelevant and redundant features. This complexity negatively impacts performance, leading to suboptimal outcomes. The accuracy of user credibility detection relies significantly on the quality of the features used in the classification process [2]. Notably, not all features equally impact correct predictions of the target class. Therefore, it is imperative to identify the most critical features to enhance classifier accuracy. Various feature selection methods, including SelectKBest and correlation-based algorithms, exist in machine learning, but their effectiveness in detecting user credibility remains unclear. This study focuses on XUCD, conducting experiments to assess the influence of feature selection on user credibility detection performance using SML. Additionally, various feature categories and their combinations are considered in the study.
2. Research Background
2.1. User Credibility Detection
User credibility refers to the perception of trustworthiness and reliability generated by individuals who participate in OSNs. This concept is especially vital in the realm of online communication, particularly within the context of social media and other OSNs where users have the freedom to share content and express their viewpoints. Different definitions highlight credibility as “the fact that someone can be believed or trusted” [3], or “the quality of being trustworthy” [4,5]. In simpler terms, credibility can be usefully reduced to “offering reasonable grounds for being believed” [5]. Alternatively, as the authors of [6] suggest, it can be seen as “a perceived quality composed of multiple dimensions”.
User credibility in OSNs revolves around the positive qualities of the account or news content provider that lead to the acceptance of their provided content by their followers [7]. In contrast, user credibility detection is the understanding of the concept of user credibility and how it is measured in OSNs. This understanding includes familiarity with the various features used to determine whether a user is credible or not. Evaluating user credibility in OSNs is a complex task that often requires a combination of diverse features and methodologies. To address this complexity, machine learning algorithms can be employed to automatically extract and analyze these features, thereby providing a quantitative assessment of user credibility. This, in turn, enhances the quality and dependability of online communication.
These identified features can be broadly categorized as follows:
- Content-related features: These features consider the quality and relevance of the content that a user shares, as well as the tone and language employed in their posts [8,9,10].
- Interaction-based features: These features encompass a user’s engagement with other users and the level of social support they offer [9].
- Profile-based features: These features include a user’s demographic information, social standing, and reputation within the platform [8,10].
- Sentiment-related features: These features delve into a user’s expression of their opinions, feelings, or assessments of products, events, information, or services through online text [5,11,12,13].
Additionally, certain features can be designated as statistical information [13].
2.2. Supervised Machine Learning (SML)
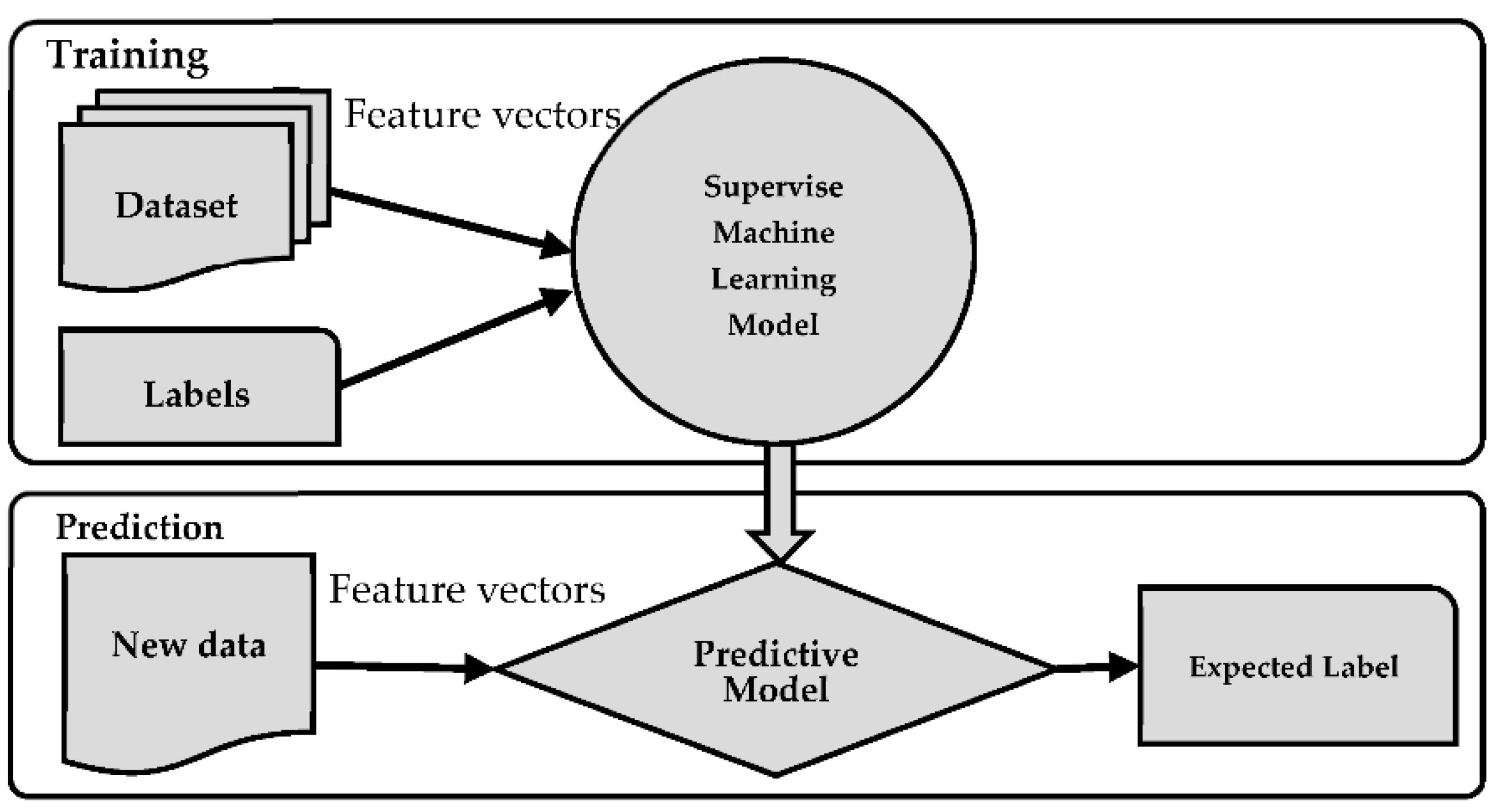
SML, a subfield within artificial intelligence, centers on the creation of algorithms and models capable of autonomously learning from training data and making predictions or decisions, as depicted in Figure 1 [13].
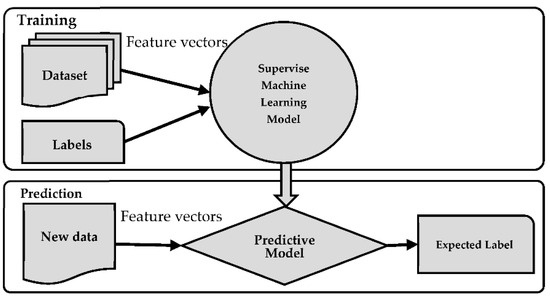
Figure 1.
Supervised machine learning.
SML finds widespread application across various domains, including detection and natural language processing. Different SML methodologies are harnessed for X-Platform user credibility assessment, classifying users as either credible or non-credible. The most prevalent machine learning techniques employed in user credibility detection encompass logistic regression (LR) [10,13,14], support vector machine (SVM) [10,13,14], naïve Bayes (NB) [10,13,14], decision tree (DT) [13], and random forest (RF) [10,13,14].
2.2.1. Support Vector Machine (SVM)
SVM primarily serves to complete classification tasks. It segregates data into distinct categories, through identifying a hyperplane, often referred to as a state line boundary, that can separate the dataset into these distinct categories [15,16].
2.2.2. Logistic Regression (LR)
LR is a widely adopted technique that calculates a categorical variable based on independent variables. It overcomes the limitations of linear regression for improved classification [16,17].
2.2.3. Naïve Bayes (NB)
The NB model employs Bayes’ theorem to compute probabilities assigned to various categories within a given dataset and subsequently classifies the test data [16,18]. NB calculates the conditional probability for each class label and selects the label with the highest probability as the predicted label [19].
2.2.4. Decision Tree (DT)
DT is employed in classification tasks. It segregates data based on specific features and classifies them through navigating through the tree from the root nodes to the terminal nodes, where the label can be determined. At each node, a test is conducted on a particular attribute, with each branch emanating from the node representing the possible options for that attribute. This process is iterated across all subtrees rooted within the new node [16,20].
2.2.5. Random Forest (RF)
RF is a machine learning algorithm that employs an ensemble of trees, comprising a multitude of DTs that work collectively. This ensemble is constructed from a randomly selected subset of the training dataset. The model will aggregate votes from various DT approaches to determine the true class of the test dataset [16,21,22].
2.2.6. Boosting Algorithms
Boosting algorithms adopt a ‘greedy’ approach. In contrast to RF, boosting models do not concurrently grow decision trees; instead, they sequentially train individual trees, with each tree being an enhanced version of its predecessor for the reduction in error rates. Adaptive boosting (AdaBoost) stands out as the most commonly used form of a boosting algorithm. Gradient boosting (GB) represents an advanced version, offering a more generalized solution. This concept has further evolved with the introduction of XGBoost (XGB). XGB, a specific implementation of the regular GB, introduces a regularization term that controls model complexity, effectively preventing data overfitting [23].
2.3. Feature Selection
There are two main categories of feature selection techniques: supervised feature selection methods and unsupervised feature selection methods [24,25,26].
Supervised feature selection techniques are well-suited for labeled datasets where the target variable is taken into account. In contrast, unsupervised feature selection techniques can be applied to unlabeled datasets where the target variable is not considered [25].
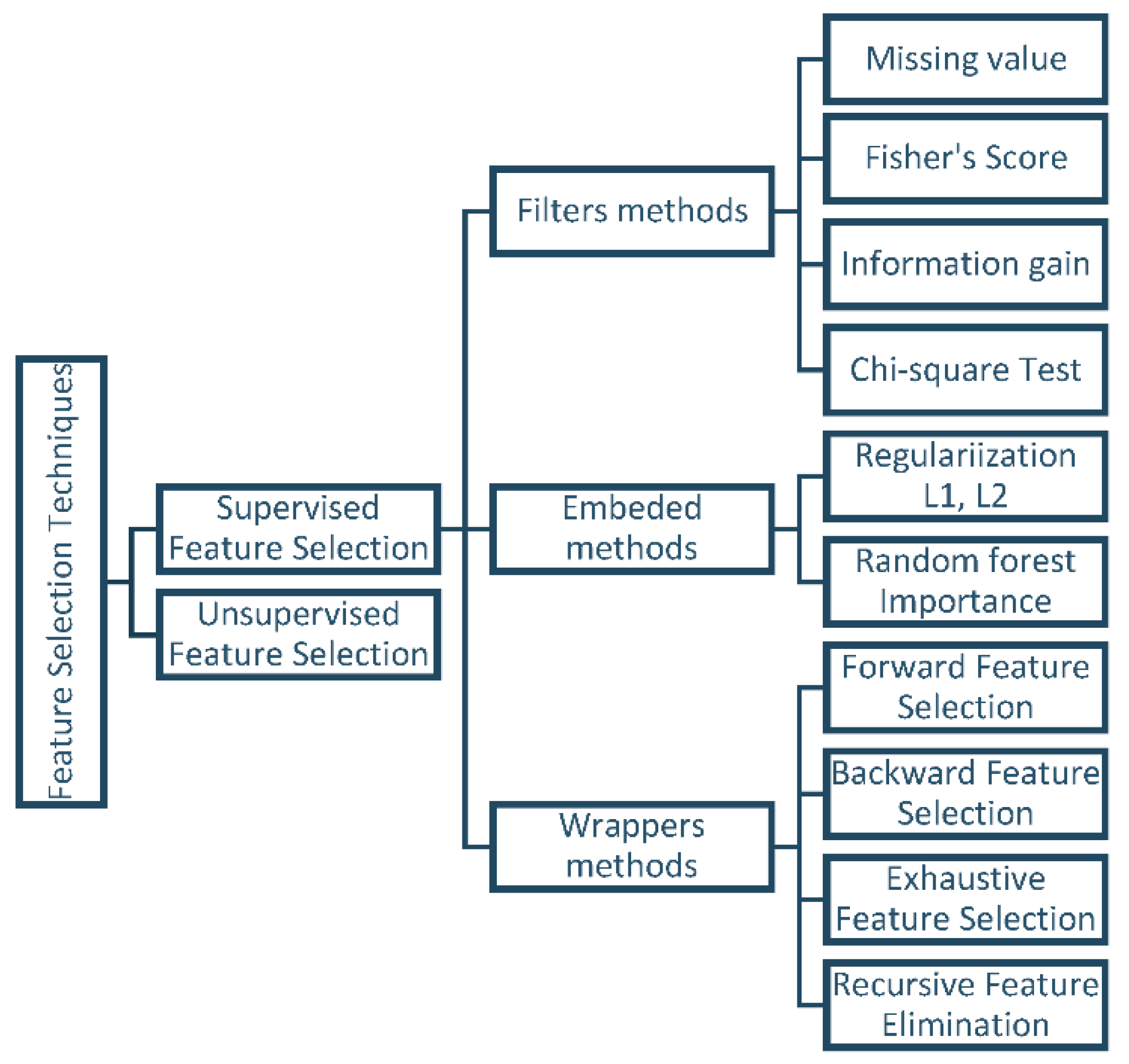
Supervised feature selection algorithms can be divided into three groups: filter methods, wrapper methods, and embedded methods.
- Filter methods assess features based on data characteristics, such as Pearson’s correlation and chi-square, without involving any classification algorithms. These methods are employed to rank features based on their importance and then select the top-ranked features for the model [24]. One of the main advantages of filter methods is that they do not require data alteration to fit the algorithms. However, a drawback of ranking methods is that the selected subset may not be optimal, potentially containing redundant features [27].
- Wrapper methods utilize classifiers to select a set of features and recommend an appropriate approach for feature selection, irrespective of the machine learning algorithm used [24]. Evaluating and selecting variable subsets is performed via handling the predictor as a black box and using its performance as the objective function [27]. Recursive feature elimination is a familiar example of a wrapper method [24].
- Embedded methods employ algorithms with built-in feature selection mechanisms. These methods offer advantages such as interaction with the classification model and require fewer computational resources than wrapper methods. They make use of regularization techniques like L1 or L2 regularization [24]. Examples of embedded methods include the least absolute shrinkage and selection operator (LASSO) and random forest (RF), both of which have their own unique feature selection approaches [28]. Figure 2 presents the most popular algorithms encountered in feature selection [29].
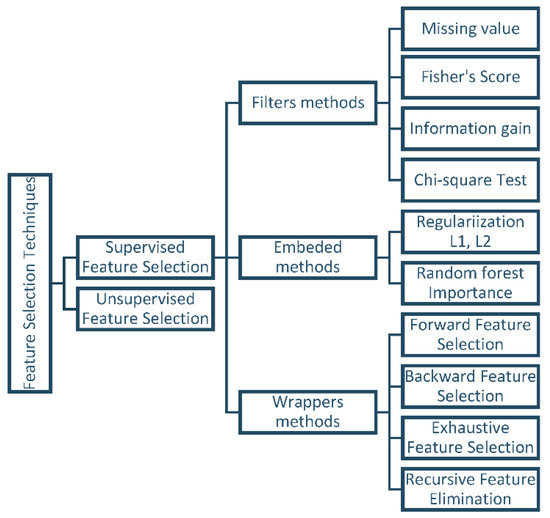 Figure 2. Feature selection techniques [29].
Figure 2. Feature selection techniques [29].
Popular supervised feature selection algorithms include:
- Recursive feature elimination (RFE): RFE is a backward feature selection method that iteratively eliminates the least important feature until the desired number of features is reached [30].
- SelectKBest: A straightforward feature selection method that selects the top K features based on a statistical test, such as chi-squared, ANOVA F test, or mutual information [30].
- Principal Component Analysis (PCA): A dimensionality reduction technique that transforms data into a lower-dimensional space while maintaining the most important information. The machine learning model can use these resulting principal components as features in the dataset [31].
- Mutual information: Utilizes information-theoretic ranking criteria to measure the dependency between two random variables, and it can be used to compute the relevance of a feature to the target variable [27,31].
2.4. User Credibility Datasets
There are several pre-existing online datasets accessible for the task of XUCD. The most appropriate datasets are outlined as follows:
- CredBank: A set of streaming tweets monitored from mid-October 2014 to the end of February 2015. It categorizes tweets into events or non-events and provides credibility ratings for those events [32].
- FakeNewsNet: A collection of fake news stories and X-Platform users who shared them. Users’ features include profile details, timeline content, follower counts, and the accounts they follow [33].
- ArPFN: A dataset that includes X-Platform users associated with the number of fake and true tweets they have shared on the X-Platform. Each user has 39 features separated into four files characterized into profile features, text features, emotional features, and statistical features [34].
- PHEME: A dataset consisting of tweets related to breaking news events and offering references for assessing their credibility and veracity. It encompasses a range of tweet-level features, including sentiment analysis, information sources, and retweet counts [35].
These datasets can be utilized as training sets in conjunction with machine learning models for evaluating the effectiveness of different models in the realm of XUCD. Table 1 provides a comparative overview of the principal characteristics of the aforementioned datasets.

Table 1.
Dataset comparison.
3. Literature Review
The trustworthiness of information hinges significantly on the credibility of the users providing it. In OSNs, where a substantial volume of information is contributed by unknown individuals lacking established credibility indicators, determining the reliability of such information poses a formidable challenge. Consequently, the credibility of the information primarily relies on the trustworthiness of its source. As a result, automated techniques for detecting user credibility have been the subject of numerous scholarly publications. To illustrate, a simple search on the Google Scholar database using keywords like “user’s credibility + detection + Twitter” within the timeframe of 2015 to 2023 yields a staggering 17,300 related articles. In this section, we will focus on discussing those studies most pertinent to our research.
3.1. X-Platform User Credibility Detection Methods
A wide array of techniques is employed for user credibility detection on OSNs. Studies using machine learning techniques are often grounded in SML, with approaches like:
- Support vector machines (SVMs) [6,8,36,37,38,39,40].
- Naïve Bayes (NB) [38].
- Random forest (RF) [10,13,41,42,43,44].
- XGBoost [7,45,46,47].
- Logistic regression (LR) [46,48,49].
- Decision tree (DT) [5,8,50,51].
- Ensemble models are also utilized in some studies [45,52].
Furthermore, a common approach in the literature combines SML with other techniques in a hybrid model. These hybrid models encompass:
- Graph-based approaches: For instance, researchers use twin-bipartite graphs to model relationships among users, products, and shops (a PCS graph), calculating scores and user credibility iteratively [38]. Another approach leverages node2vec to extract features from the X-Platform followers/followed graph, considering both user features and social graph data [50].
- Behavior analysis: The CredRank algorithm is introduced to assess user credibility by clustering users based on behavioral similarities [4].
- Machine learning and deep learning: The UCred model combines machine learning and deep learning methods, integrating RoBERT (robustly optimized BERT), Bi-LSTM (bidirectional LSTM), and RF outputs through a voting classifier for enhanced XUCD accuracy [53]
- Feature-hybrid approaches: Some studies, like the one presented in [46], combine sentiment analysis with social network features to identify attributes useful for XUCD. This approach assigns sentiment scores based on user history, employing reputation-based techniques.
- Reputation features: A probabilistic reputation feature model, as suggested in [45], surpasses raw reputation features in enhancing overall accuracy in user trust detection in OSNs.
- Domain-based analysis: The integration of semantic and sentiment analyses in domain-based credibility estimation and prediction is demonstrated in [47].
- Sentiment analysis and machine learning: The study located as reference [40] employs sentiment analysis and machine learning to determine both the credibility of users’ profiles and the credibility of the content.
These diverse techniques contribute to the advancement of user credibility detection in OSNs, reflecting the multifaceted nature of this field.
3.2. Feature Selection
Dealing with features begins with feature extraction, which is the process of extracting information from a given dataset [54]. Working with this multitude of features in data analysis can be a complex task, but it can be streamlined via reducing the dataset’s dimensionality and pinpointing the most relevant features for accurate classification [41]. Several studies [7,10,13,41,42,43,50,51,55,56,57,58,59,60] have adopted various feature selection methods to concentrate on the most pertinent and significant features for prediction, concurrently minimizing computational complexity. Among the methods employed in these studies are:
- Correlation-based feature selection: In [13], this technique was used to reduce the number of features from thirty-four to seven which are crucial for classifying Facebook users as credible. The study in [55] employs this method to identify the most discriminatory features for user credibility classification and remove irrelevant and biased ones. Meanwhile, the authors of [60] measured X-Platform users’ credibility in the stock market using the correlation between each user’s credibility and his or her social interaction features.
- Extra-trees classifier: The authors of [57] used the extra-trees classifier to eliminate irrelevant features, selecting only the top three breast cancer features that maximize model accuracy.
- SelectKBest algorithm: The authors of [10] utilized the k-best method for selecting the final feature set in their research for detecting false news on the X-Platform.
- Multiple feature selection methods: The researchers in [56] applied five feature selection methods, namely information gain, chi-square, RELIEF, correlation, and significance, to enhance spam detection.
- Dynamic feature selection technique: The study in [58] introduced a dynamic feature selection technique by grouping similar X-Platform users using k-means clustering to adapt features for each user group, enhancing the classification of spam users on the X-Platform.
- Hybrid approaches: The authors of [41] proposed a hybrid approach that combined logistic regression with dimensional reduction using principal component analysis (LR-PCA) to extract specific features from a high-dimension dataset. This approach increased classification accuracy in different machine learning classifiers.
- Recursive feature elimination (RFE): The study in [59] employed RFE to evaluate the optimal features that improve classification accuracy in detecting spammers on X-Platform. The top 10 features were selected from a larger set including 31 features, resulting in improved accuracy.
- Random forest feature importance: Some machine learning methods, such as random forest, intrinsically measure feature importance. In [42], the top features identified by random forest were analyzed and over 90% accuracy was achieved using fewer than 20 features to detect online bots on the X-Platform.
- Gradient-boosting models: In [50], a light gradient-boosting machine (light-GBM) model was used to assess the importance of each of their dataset features and eliminated the least important ones under specific conditions.
- Hybrid Harris hawk algorithm: In the context of Arabic tweet credibility, the authors of [7] adapted a binary variant of the hybrid Harris hawk (HHO) algorithm for feature selection, categorizing features into content, user profiles, and word features.
- Ant colony optimization (ACO): The authors of [51] applied an ant colony optimization (ACO) algorithm for feature selection, significantly reducing the number of features from eighteen to five and enhancing classification accuracy in distinguishing credible from fake OSN content.
- Mean decrease accuracy and Gini graphs: In [43], these graphs were employed to select the top 10 features out of 26 based on content, user, emotion, polarity, and sentiment characteristics, concluding that sentiment and polarity of tweets were the most critical variables in determining tweet credibility.
In summary, a well-crafted feature set, comprising independent features highly correlated with the desired outcomes, greatly facilitates the learning process [2].
3.3. Credibility Detection in the Literature
Finally, Table 2 compares the literature that most relates to performing the task of XUCD in terms of the main objectives of the proposed solution.
Table 2.
Credibility detection in the literature.
4. Materials and Methods
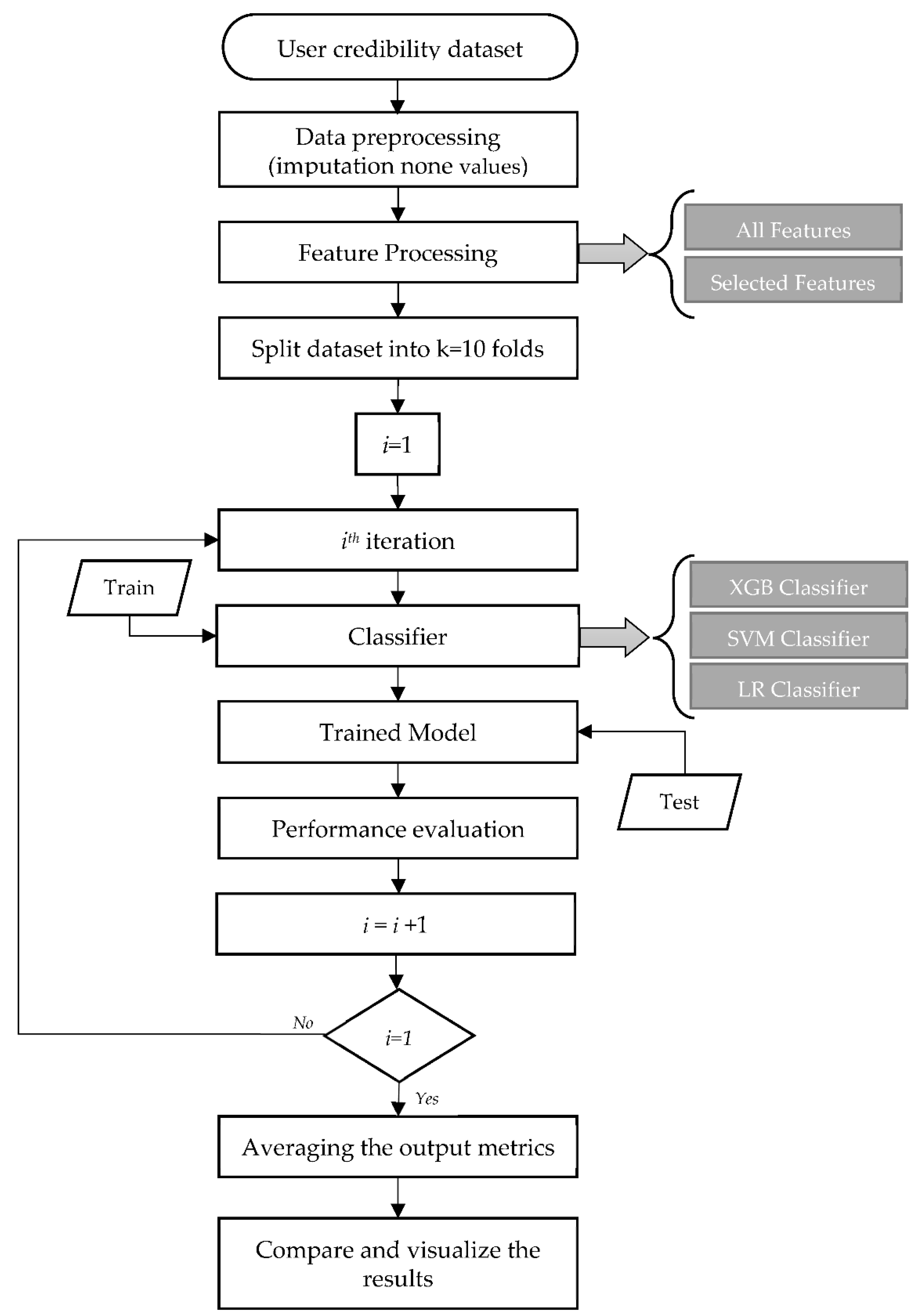
This section outlines the methodology adopted in our research. We employed various embedding methods, such as SelectKBest, correlation-based algorithms, and mutual information, to perform feature selection. This involves generating datasets with less dimensional space. Feature selection occurs between the stages of feature extraction and classification. It is a process aimed at automatically identifying more effective features to enhance predictive accuracy. Processing irrelevant features or treating all features equally can reduce the model’s performance. Additionally, feature selection can lead to a reduction in the time required for classification. Figure 3 illustrates the key stages of our research methodology.

Figure 3.
Research stages.
4.1. Dataset
As mentioned in our previous discussion in Section 2.4 regarding user credibility datasets, our experiments were conducted using the ArPFN dataset [34]. This dataset was chosen due to its recency and its extensive feature set. ArPFN is a real dataset crafted by [46], and constructed through three primary phases. Initially, a collection of verified Arabic claims was compiled from various sources. These claims were then used to identify the tweets that spread them. Subsequently, the users associated with these tweets were identified and categorized based on their likelihood to spread fake news or not, determined by the frequency of their tweets. ArPFN comprises 1546 user accounts on X-Platform, with 541 users categorized as prone to spreading fake news (non-credible), while 1005 users were not prone to spreading fake news (credible).
As indicated in Table 3, this dataset encompasses three distinct feature categories for each user:
Table 3.
ArPFN feature types [34].
- Profile Features: These include 11 features.
- Emotional Features: Comprising 11 features.
- Statistical Features: Consisting of 17 features.
In total, the ArPFN dataset offers 39 features for each user, making it a comprehensive resource for our research.
4.2. Feature Selection
In this phase, our primary focus will be on identifying the most relevant features and assessing their significance in the context of user credibility detection (UCD). We will examine each feature category individually or in combination, which provides us with seven distinct sets of features, as follows:
- Profile Features with 17 features.
- Emotional Features with 11 features.
- Statistical Features with 11 features.
- Profile Features and Emotional Features with 28 features.
- Profile Features and Statistical Features with 28 features.
- Emotional Features and Statistical Features with 22 features.
- Profile Features, Emotional Features, and Statistical Features with 39 features.
For each of these feature sets, we will consider two alternatives:
Alternative One: This involves using all raw data without feature selection.
Alternative Two: In this alternative, feature-selecting methods will be applied to selected specific sets of features based on their importance. We employed the machine learning methods SelectKBest and correlation analysis for feature selection. The process will involve the following steps:
- Running a feature selection method to compute important scores for each feature.
- Ranking features in descending order according to their importance.
- Eliminating the bottom 50% of variables with the lowest importance scores.
This comprehensive approach will help us determine the most influential features and the impact of feature selection on UCD performance.
4.3. User Credibility Detection
In this phase, we focused on designing and developing a machine learning model capable of distinguishing between credible and non-credible users on X-Platform. The choice to utilize a machine learning algorithm for a user credibility detection system was based on the findings of our literature review, which highlighted the significant accuracy achieved by machine learning in classification tasks.
To create an effective and generalized model, we employed a 10-fold cross-validation approach. This technique is well-established for mitigating overfitting issues and ensuring that the model performs well on unseen data.
To identify the most accurate classifier for our feature sets, we applied and compared several commonly used classification algorithms, including XGBoost, support vector machines (SVM), and logistic regression (LR). This comparative analysis helped us determine which algorithm was best suited for our specific dataset and feature combinations.
4.4. Implementation, Evaluation, and Interpretation of the Results
For the implementation of our model, we utilized Python, taking advantage of its extensive array of open-source libraries, including Scikit-learn for machine learning tasks and Matplotlib for data visualization.
Once the proposed system was developed, it underwent rigorous testing and evaluation to address any potential limitations. During this phase, each alternative from the previous feature selection phase was validated using a variety of evaluation metrics. These metrics included standard measures like accuracy, precision, recall, and F1 score.
The results were analyzed and visualized using Python’s data visualization tools including creating visualizations such as bar plots, heatmaps, and confusion matrices that provide a comprehensive understanding of the model’s performance. Figure 4 illustrates the flow diagram of our proposed model, showcasing the different stages of our research process.
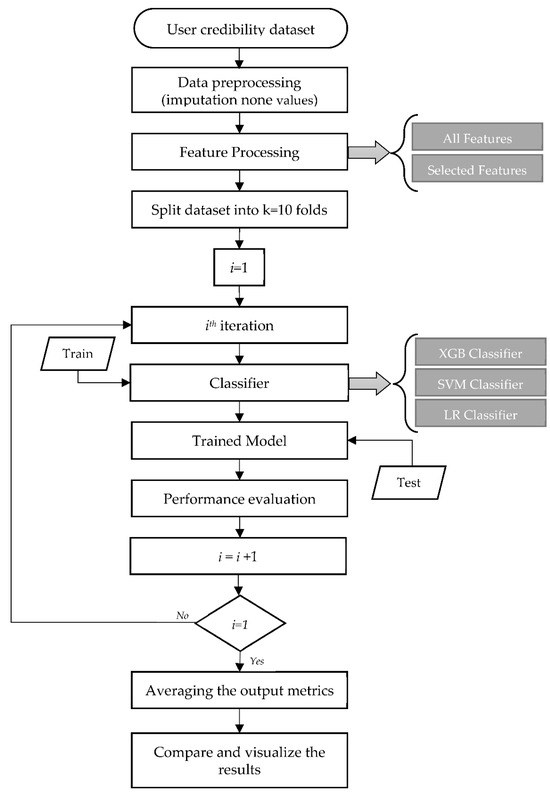
Figure 4.
Flow diagram of the proposed model.
5. Results
Applying the proposed methodology provided us with useful results to determine the impact of various feature selection methods and ML classifiers on the accuracy of XUCD, which are reviewed in the following subsections.
5.1. Feature Selection
Feature selection involves the task of identifying and eliminating irrelevant and redundant information to minimize data dimensionality. It is helpful for selecting the most effective features that lead to a more accurate model. In this study, we used SelectKBest and correlation-based algorithms for their distinct advantages.
SelectKBest is known for its simplicity and efficiency in selecting the top k features based on statistical tests, providing a straightforward approach to feature selection. This method allowed us to identify the most informative features while minimizing computational complexity. On the other hand, correlation-based algorithms excel in capturing relationships and dependencies between features. By considering the correlation between each feature and the target variable, we were able to prioritize those features that exhibit the strongest relationships with user credibility. This nuanced approach enabled us to uncover intricate patterns within the data.
Furthermore, the choice of these methods aligned with our goal of comprehensively exploring feature selection techniques without overwhelming the study with a myriad of approaches. By focusing on SelectKBest and correlation-based algorithms, we struck a balance between methodological depth and practical applicability, facilitating a more in-depth investigation into the impact of feature selection on user credibility detection.
5.1.1. SelectKBest
Scikit Learn’s SelectKBest was utilized to return the k best features for the model. This algorithm uses the score classification function to match the explanatory variable (x) against the explained variable (y), one by one, returning the highest K scores of the features. In order to execute the SelectKbest algorithm on a dataset, we need to set the (K) value. Our experiments show that selecting a K value that is greater than 50% of the total number of the features in the dataset leads to a different set of features each time, which may affect the resulting accuracy.
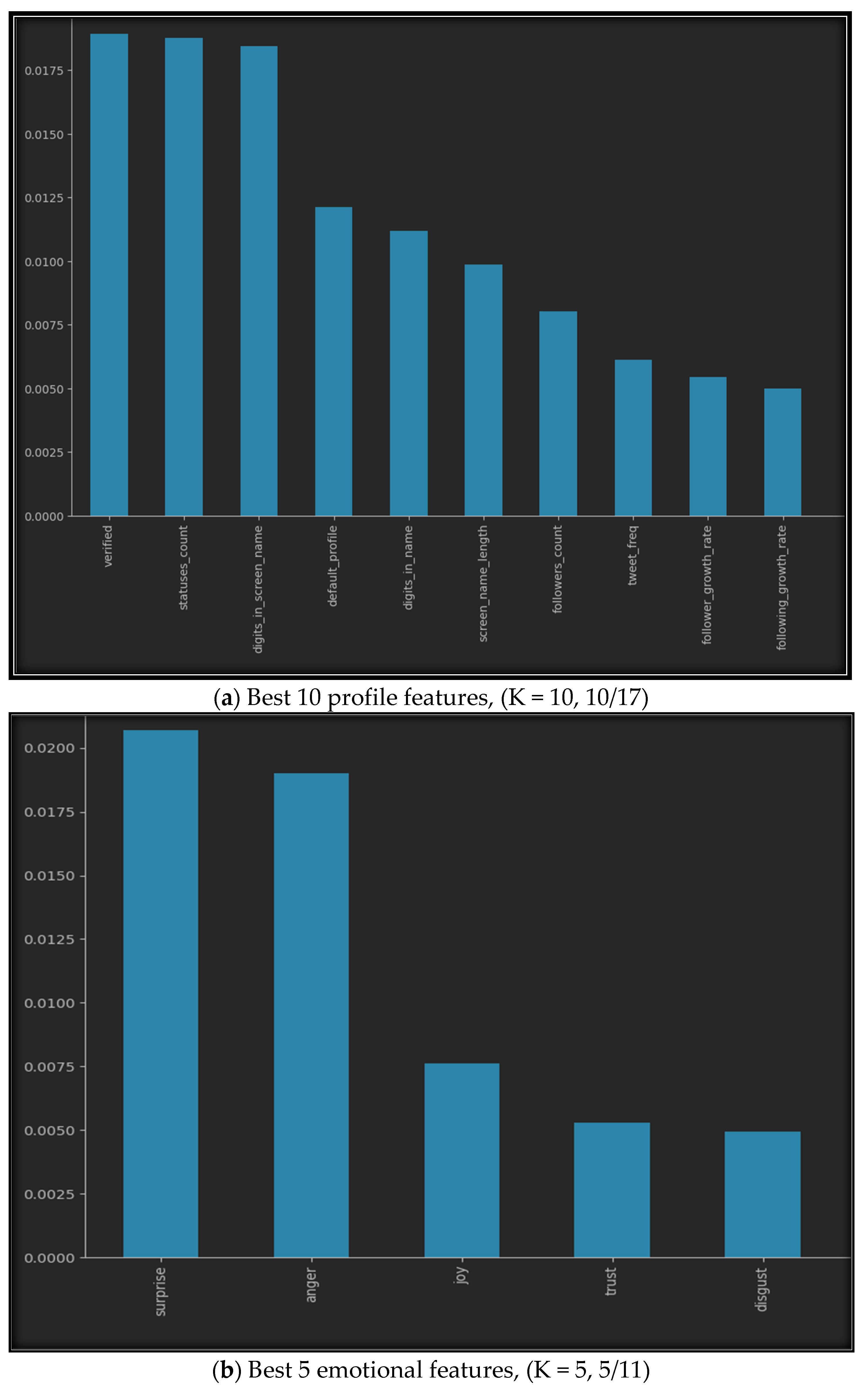
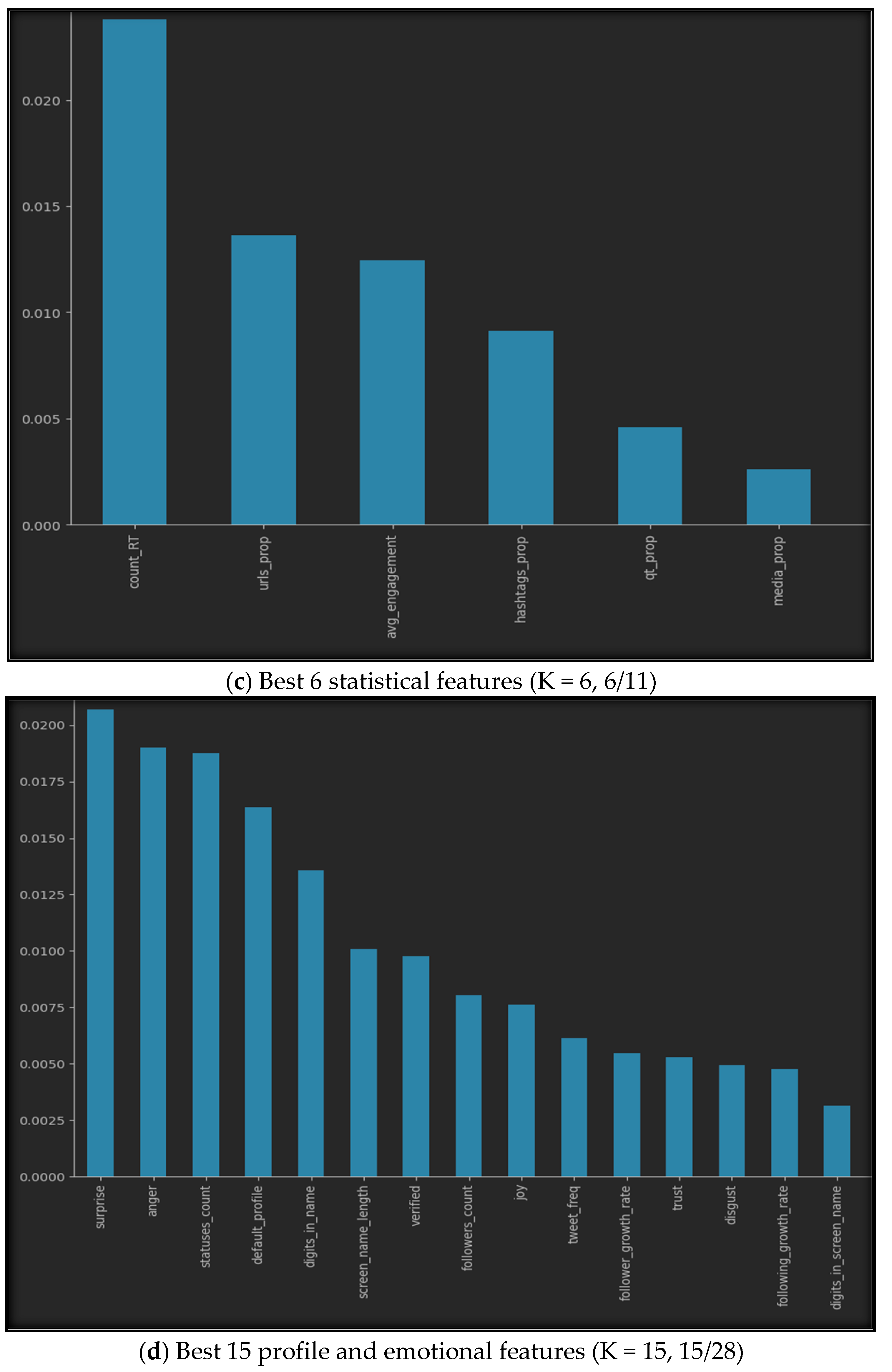
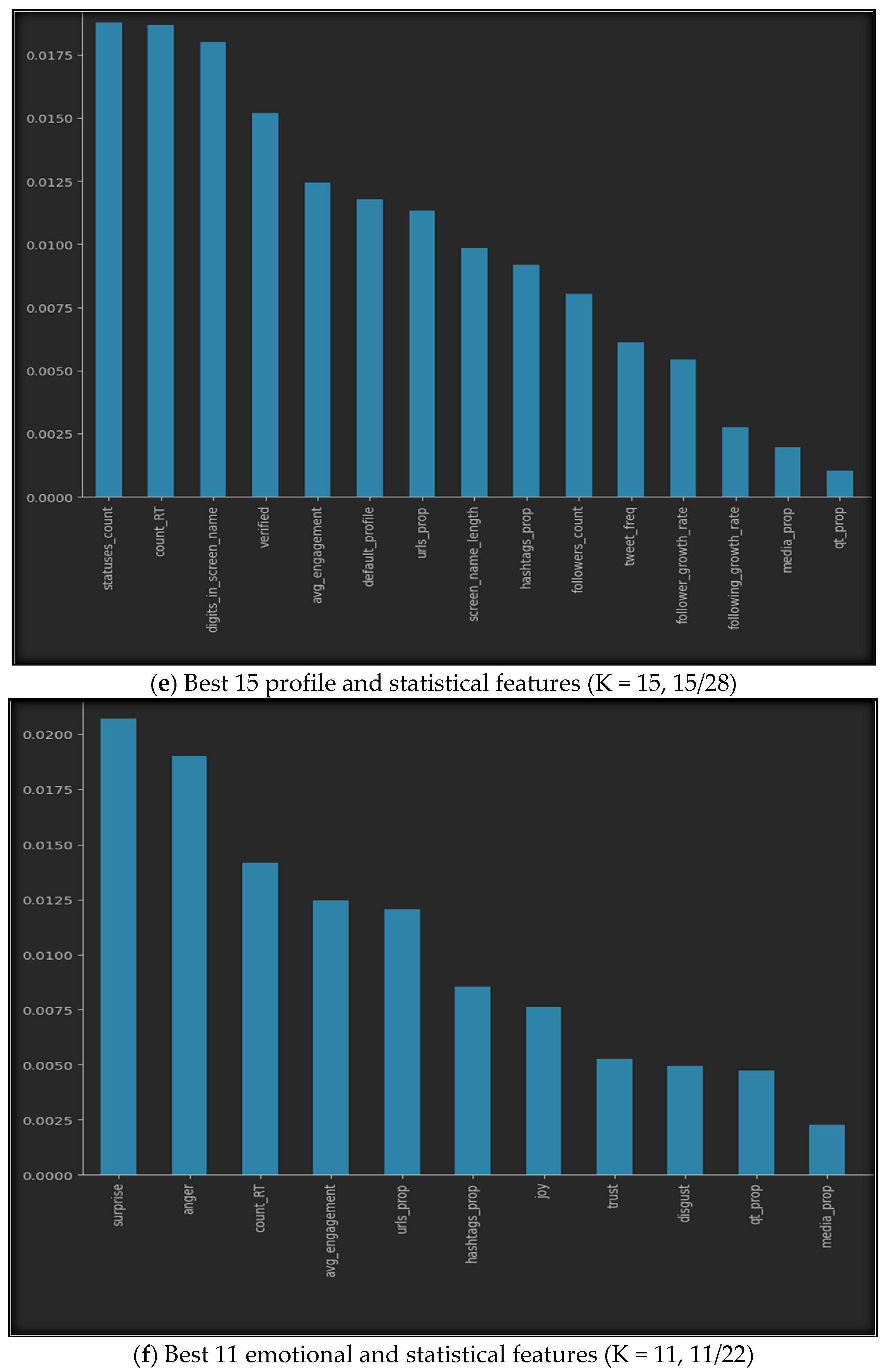
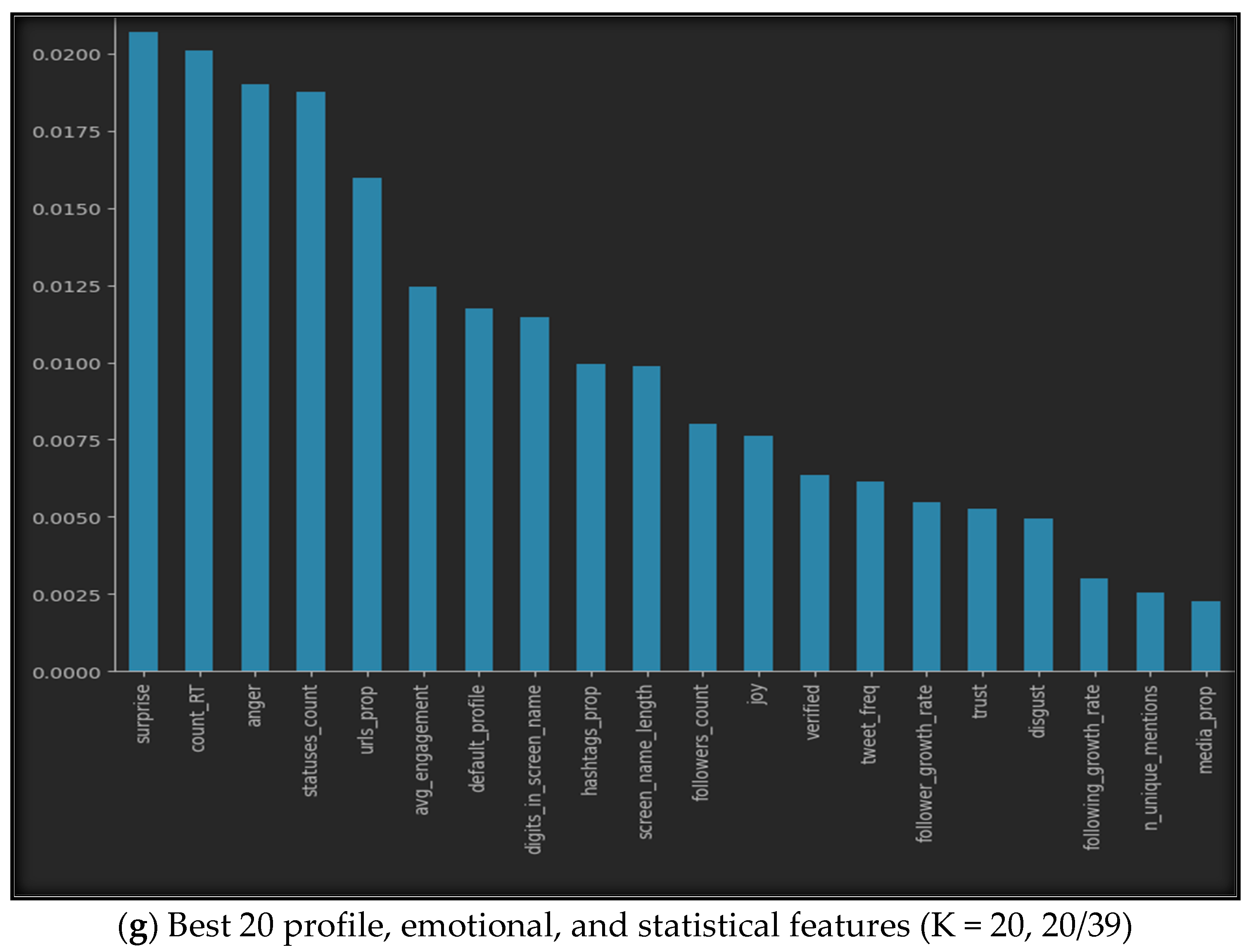
Using SelectKbest with our datasets provides us with the best features, as shown in Figure 5. The figure illustrates the best K features for all seven datasets, where (a) represents the top ten features of the profile features dataset, (b) represents the five best features of the emotional features, (c) shows the finest six features of the statistical features, while (d) provides the fifteen best features from both the profile and emotional features, (e) gives us the top fifteen features of the profile and statistical dataset, (f) highlights the best eleven features of the emotional and statistical features, and finally, (g) represents the best twenty features from all profile, emotional, and statistical datasets.
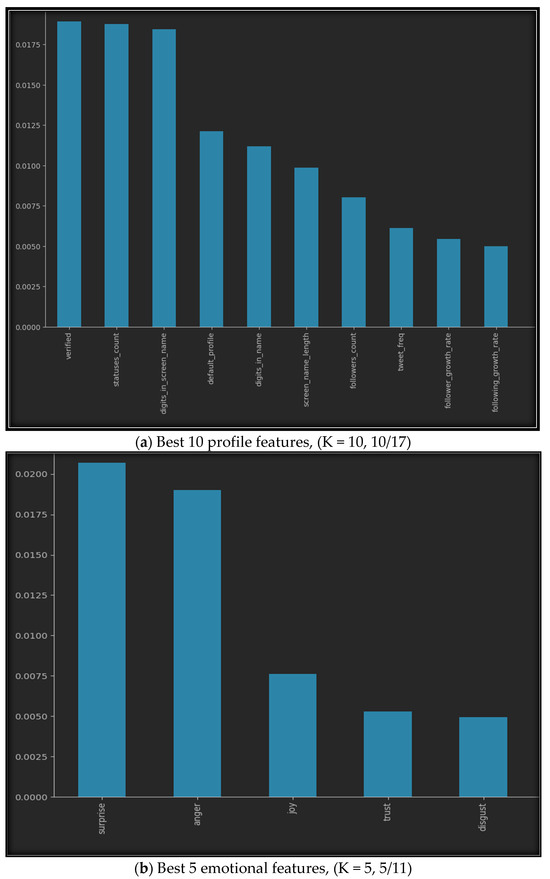
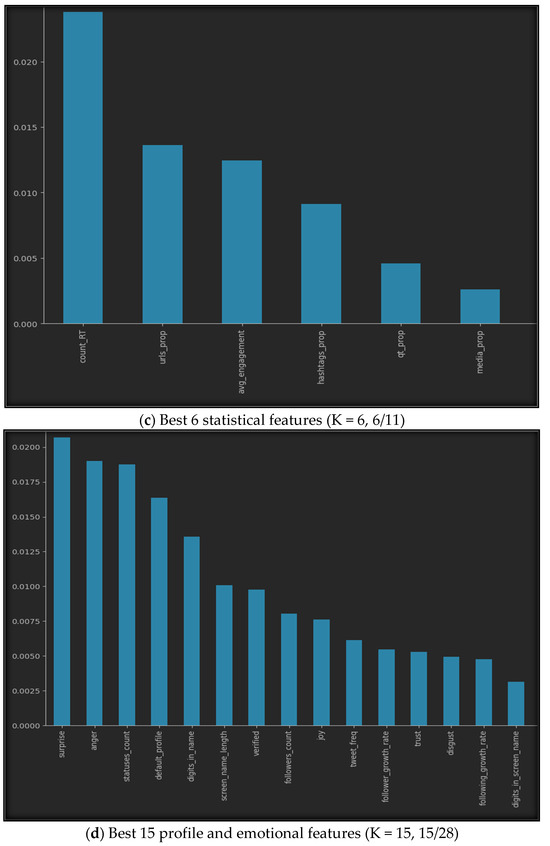
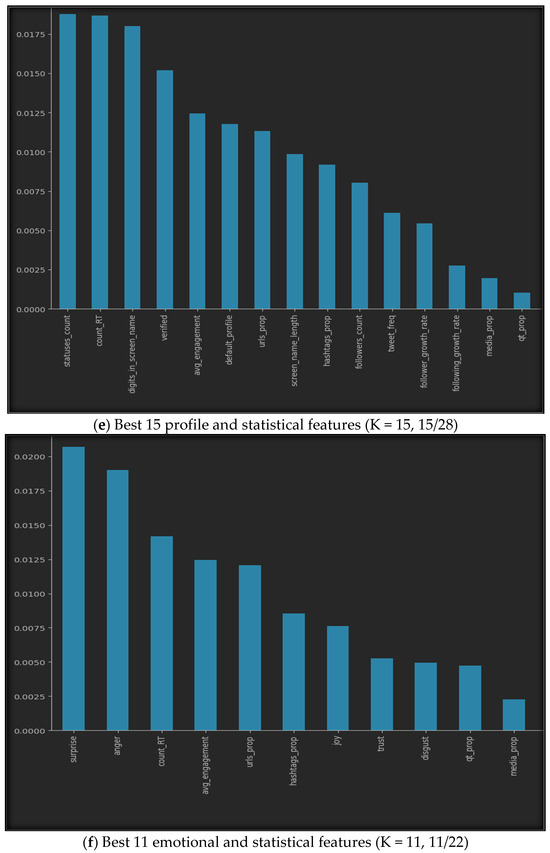
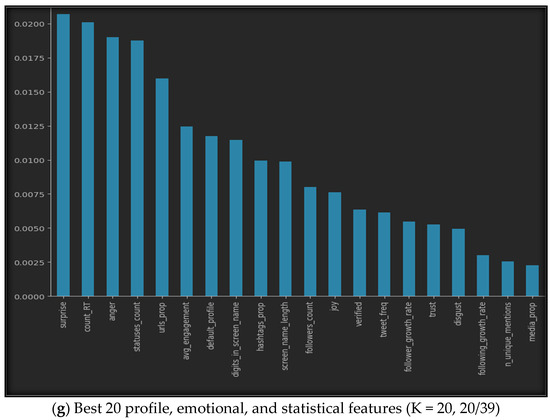
Figure 5.
Best K features in the seven sub-datasets.
5.1.2. Correlation-Based Algorithms
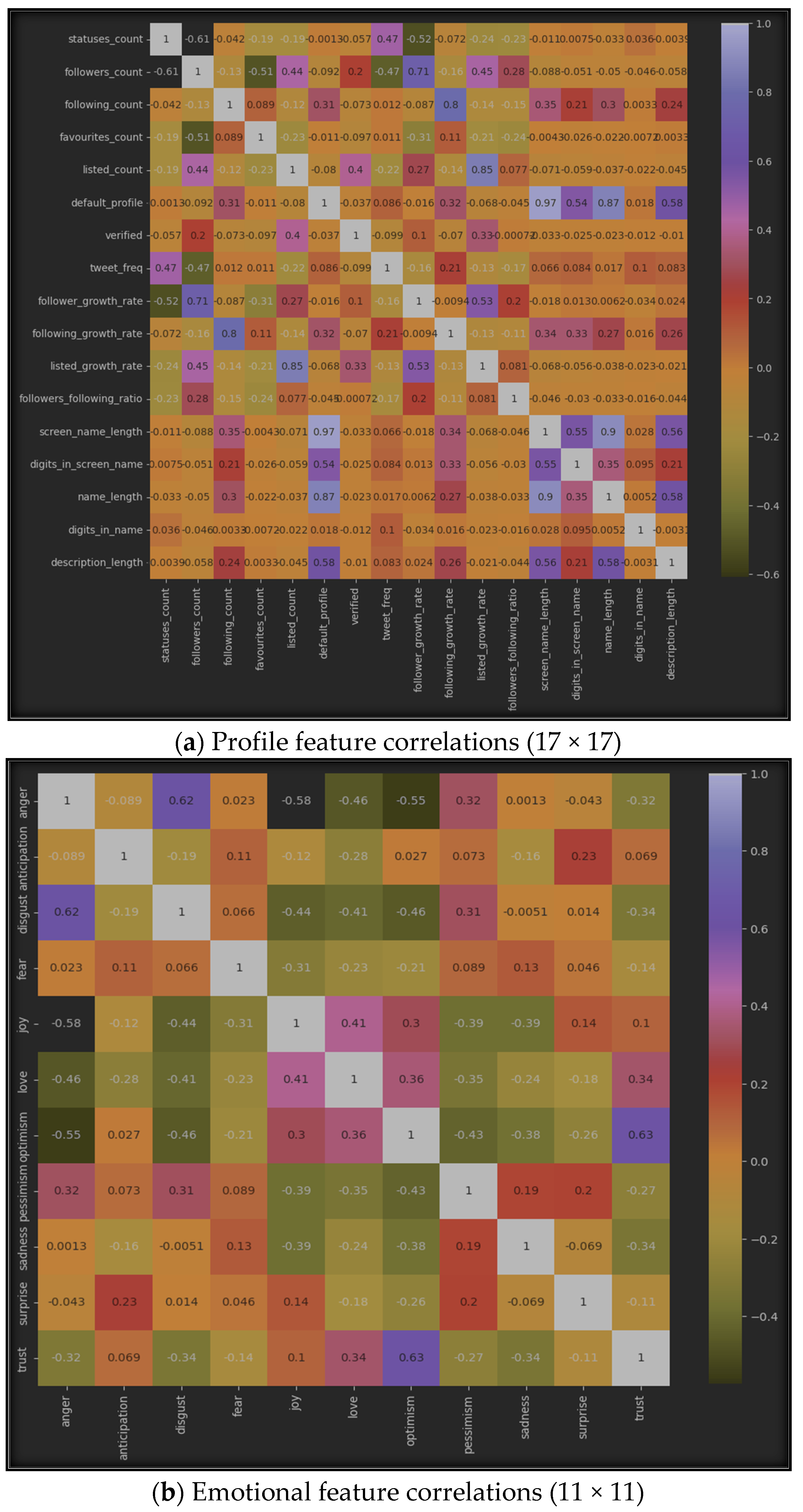
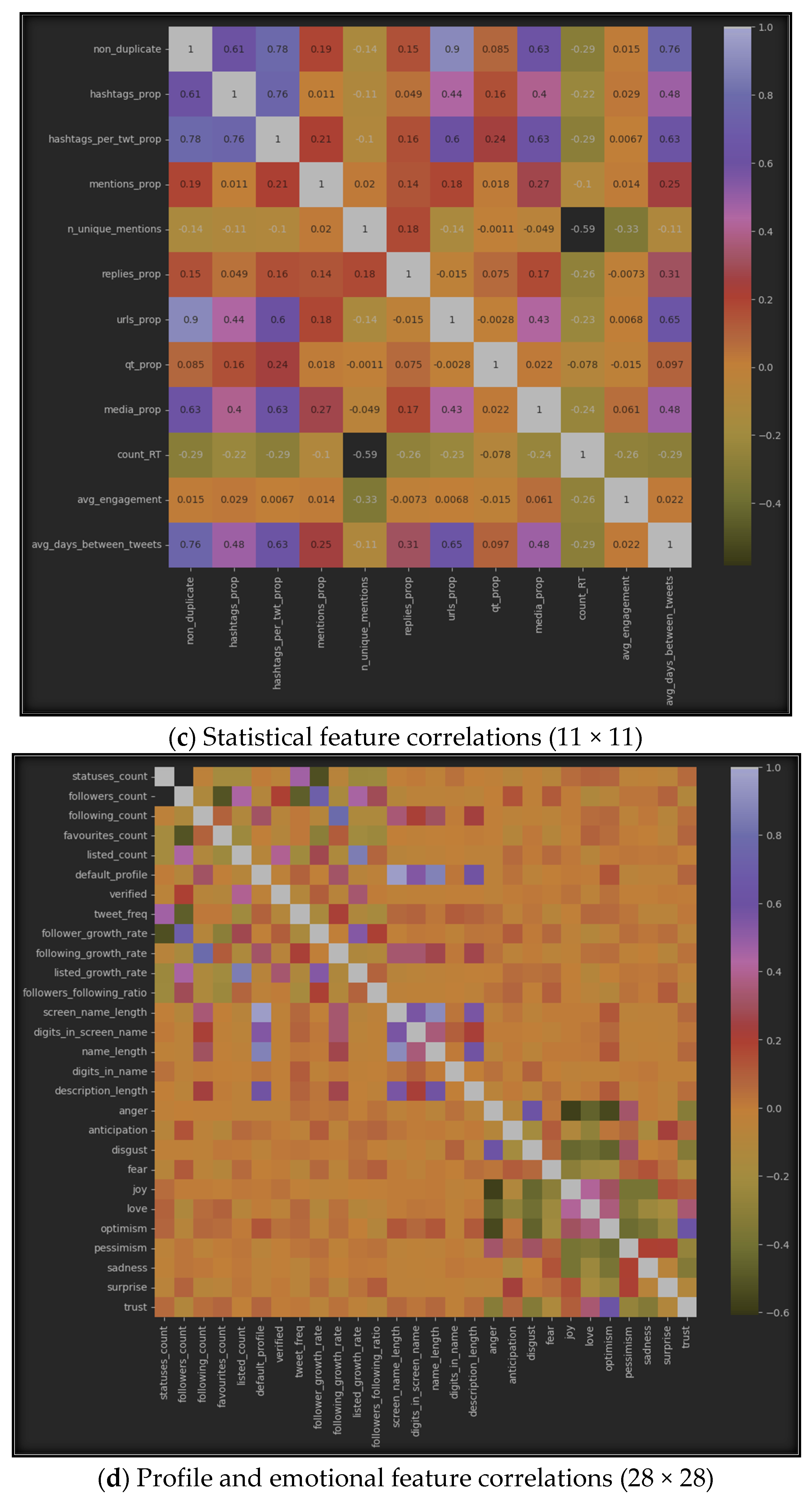
A correlation-based algorithm provides a straightforward filtering mechanism that orders features based on a heuristic evaluation function reliant on correlation. This evaluation function prioritizes features strongly correlated with the target class while minimizing inter-feature correlations. Features lacking correlation with the class are considered insignificant and are thus disregarded.
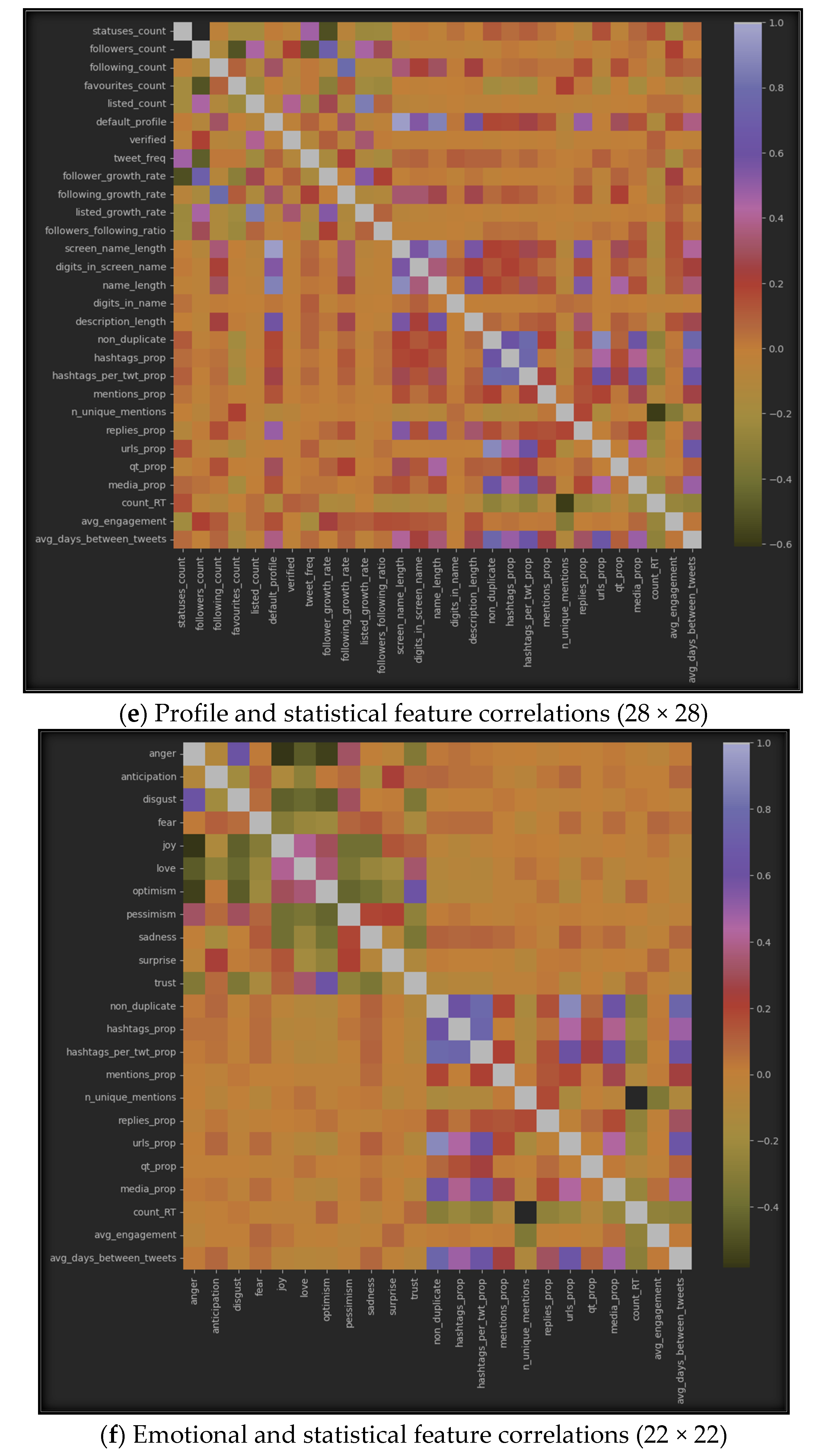
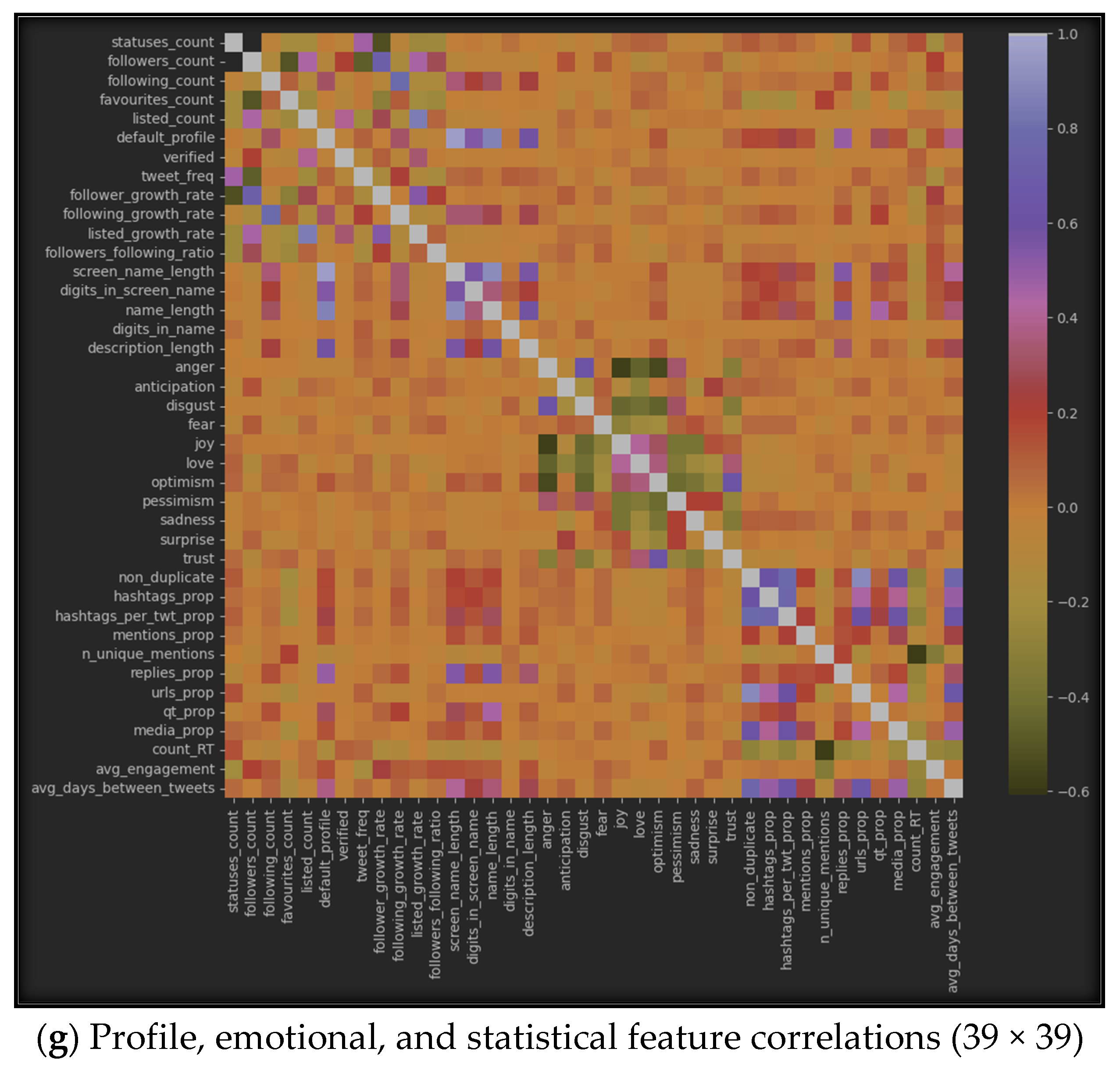
The results of using correlation algorithms among the seven datasets can be represented by Figure 6, which displays the correlation between inter-features in each of the seven sub-datasets. Specifically, (a) represents the correlation in the profile dataset, (b) shows it in the emotional dataset, (c) highlights the correlation in the statistical dataset, (d) provides the correlation between all features from the profile and emotional datasets, (e) emphasizes the correlations between features from the profile and statistical datasets, (f) represents the correlations between emotional and statistical features, and finally, (g) provides the correlations among all features from the three datasets: profile, emotional, and statistical.
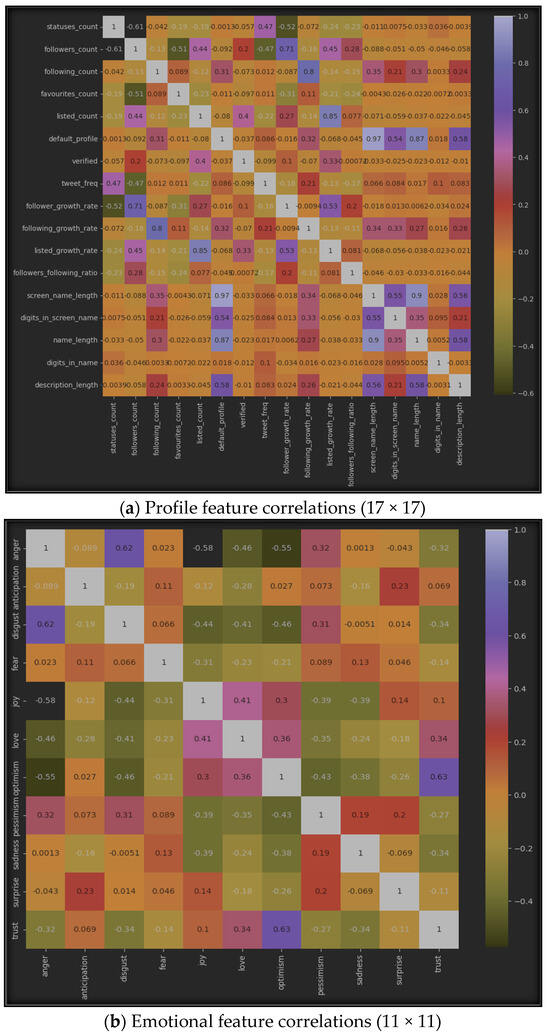
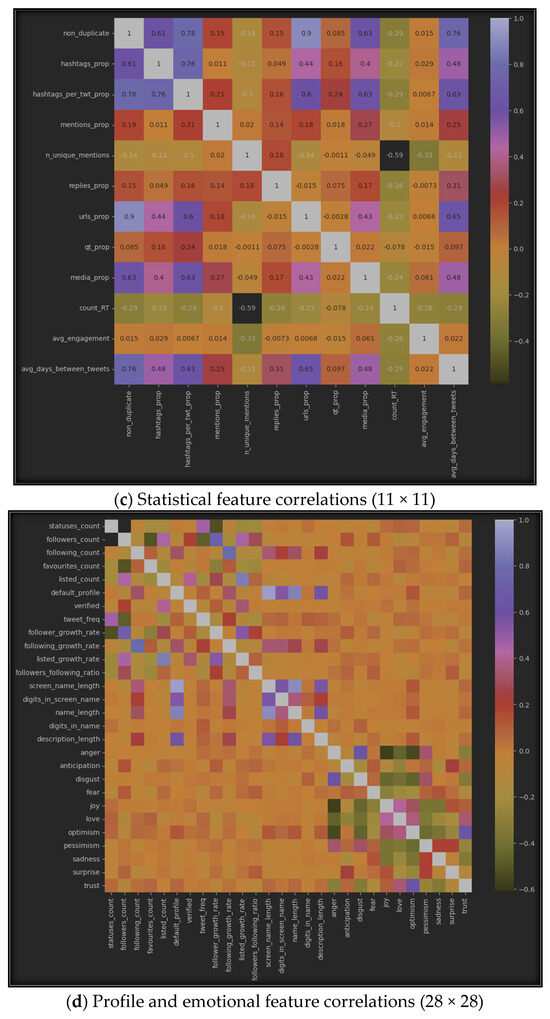
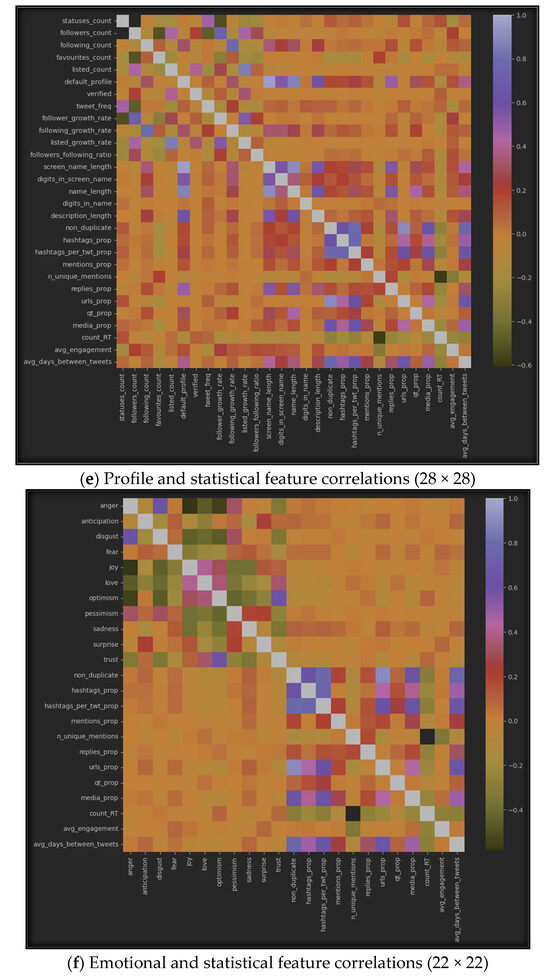
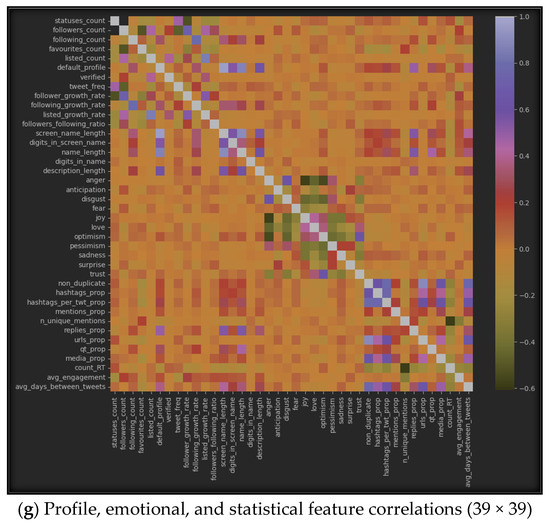
Figure 6.
Features’ intra-correlations in the seven sub-datasets.
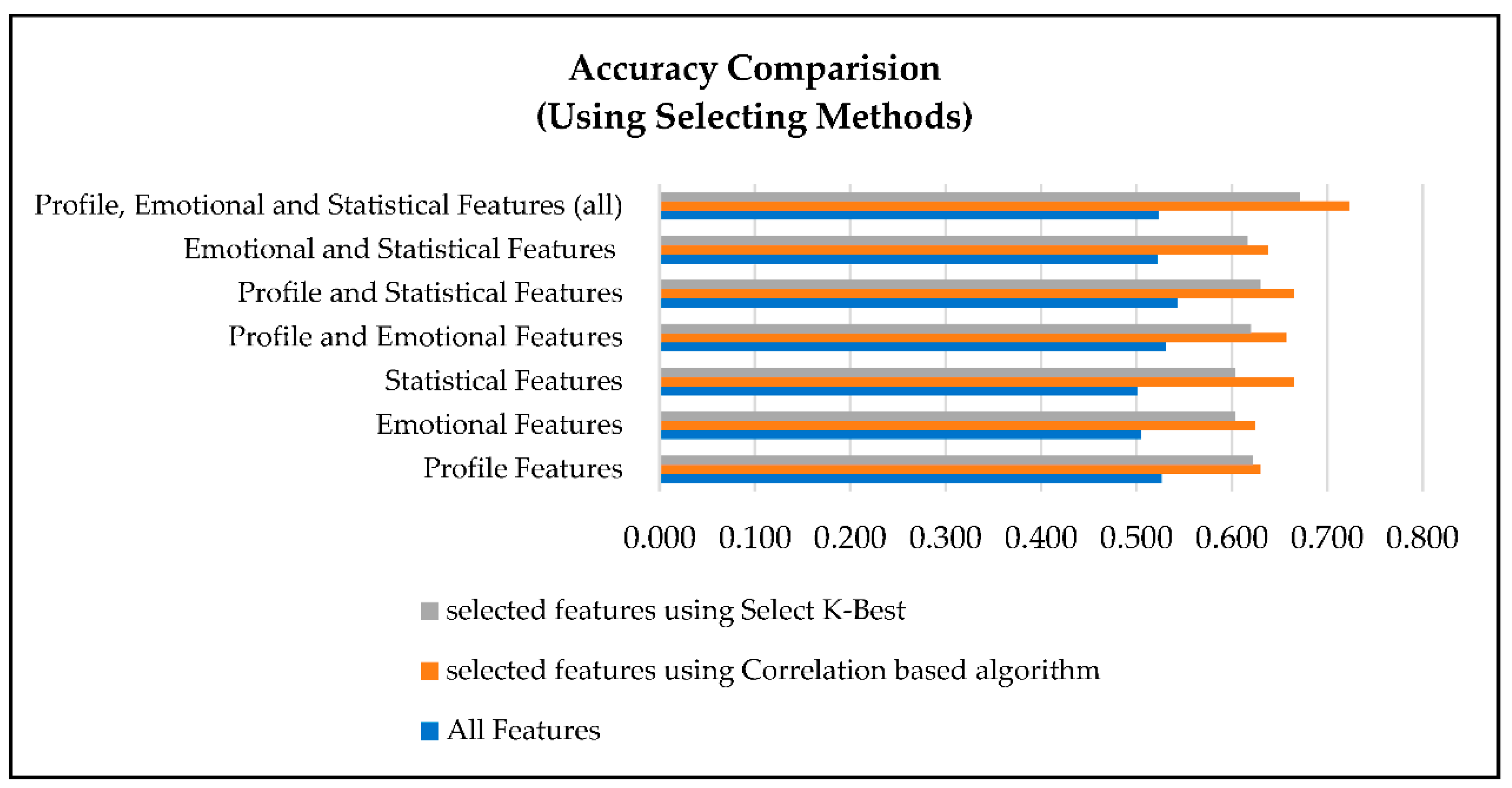
5.1.3. Accuracy of Selection Methods
The results of applying feature selection methods to our datasets affirmed the effectiveness of these techniques through enhancing the accuracy of XUCD, as demonstrated in Table 4 and Figure 7.
Table 4.
Accuracy after applying the feature selection method 1.
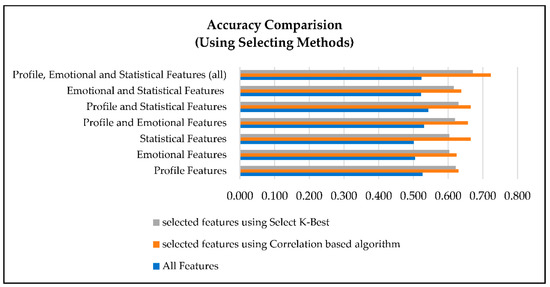
Figure 7.
Accuracy comparison after feature selection.
5.2. XUCD Using SML Classifiers
Three SML classifiers, namely SVM, LR, and XGB, were employed with the same training method and datasets, and their metrics for detecting the credibility of X-Platform users are shown in Table 5.
Table 5.
ML classifier metrics for XUCD 1.
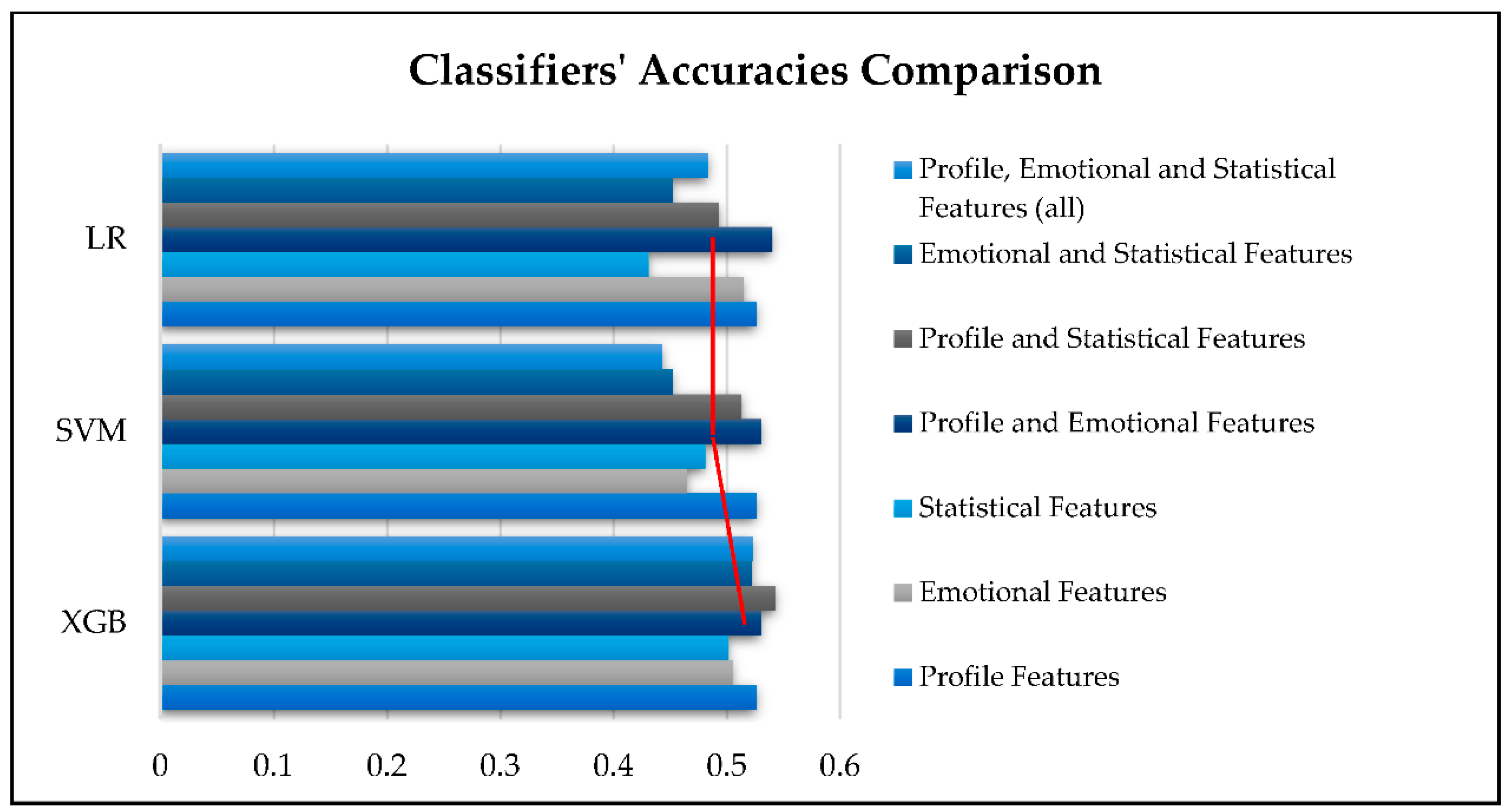
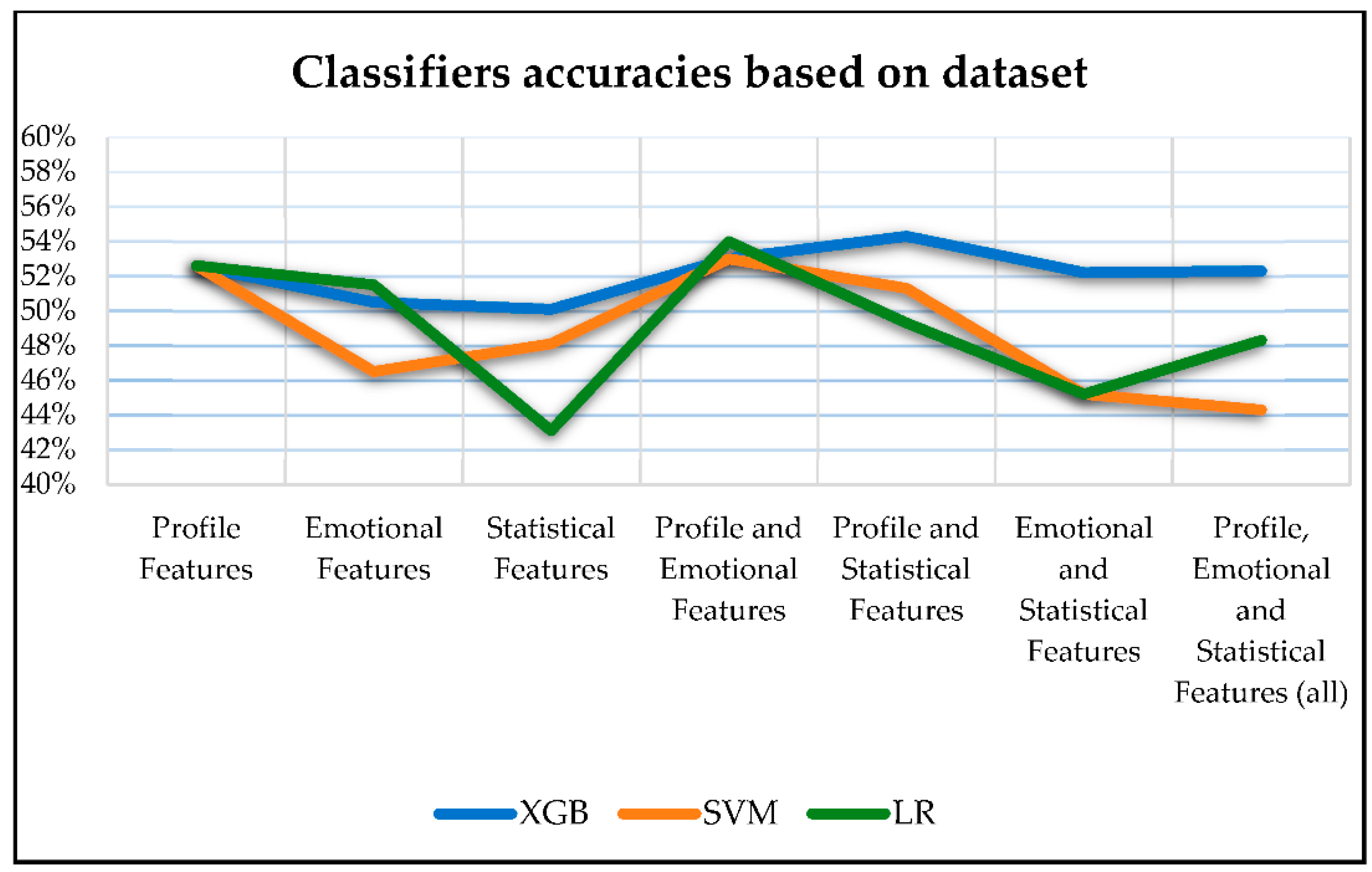
Table 6 and Figure 8 provide a comparison of the accuracy achieved by these three classifiers. XGB outperforms the others with the highest accuracy of 0.543 when using the combination of profile and statistical features. LR follows closely with an accuracy of 0.540 when processing the dataset that includes the combination of profile and emotional features. In the last position is SVM, with its best accuracy reaching 0.530, which was obtained when using profile and emotional features.
Table 6.
Comparison of classifiers’ accuracies 1.
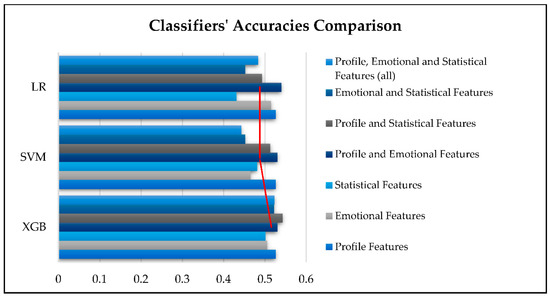
Figure 8.
Comparison of classifiers’ accuracies.
Regarding the best performance of the examined SML classifiers, our experiments confirmed that on average, XGB achieves the best performance, with 0.521 accuracy in XUCD, as shown in Figure 8.
The accuracy outcomes of the classifiers exhibited variations depending on the processed dataset. Figure 9 provides a visual representation of how different dataset categories influence the detection accuracy of the three classifiers. This graphical representation underscores the influence of dataset category choice on classifier performance.
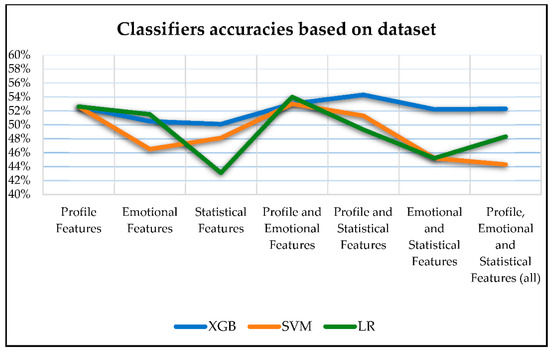
Figure 9.
Influence of dataset on classifiers.
6. Discussion
In this section, we provide an in-depth discussion of the findings from our research on feature selection for XUCD. We examined the impact of various feature selection methods, including SelectKBest, and correlation-based algorithms, as well as the performance of three SML classifiers, LR, SVM, and XGB, on XUCD accuracy using the ArPFN dataset, which includes profile, emotional, and statistical features. The key findings and their implications are as follows:
6.1. Feature Selection
- Effectiveness of the Method: Feature selection methods, such as SelectKBest and correlation-based algorithms, proved to be generally effective in improving XUCD accuracy. This observation underscores the importance of reducing the dimensionality of the feature space by eliminating irrelevant and redundant features, ultimately resulting in more precise models. Notably, correlation-based algorithms were more effective than SelectKBest, consistently providing higher XUCD accuracy in all the sub-datasets used in our research.
- Feature Category Influence: Despite the overall improvement in XUCD accuracy achieved with feature selection methods, the impact of feature selection varied among the different feature categories. The combination of all three feature categories (profile, emotional, and statistical) benefited the most from feature selection methods. In contrast, the statistical and emotional feature datasets demonstrated less significant improvement when compared to the complete dataset. This discrepancy highlights the importance of tailoring feature selection techniques to specific feature types, as not all categories respond equally to feature selection methods.
These findings emphasize the effectiveness of feature selection in enhancing XUCD accuracy, with correlation-based algorithms being a particularly strong choice. Additionally, the results underscore the importance of considering feature category influences when designing feature selection strategies.
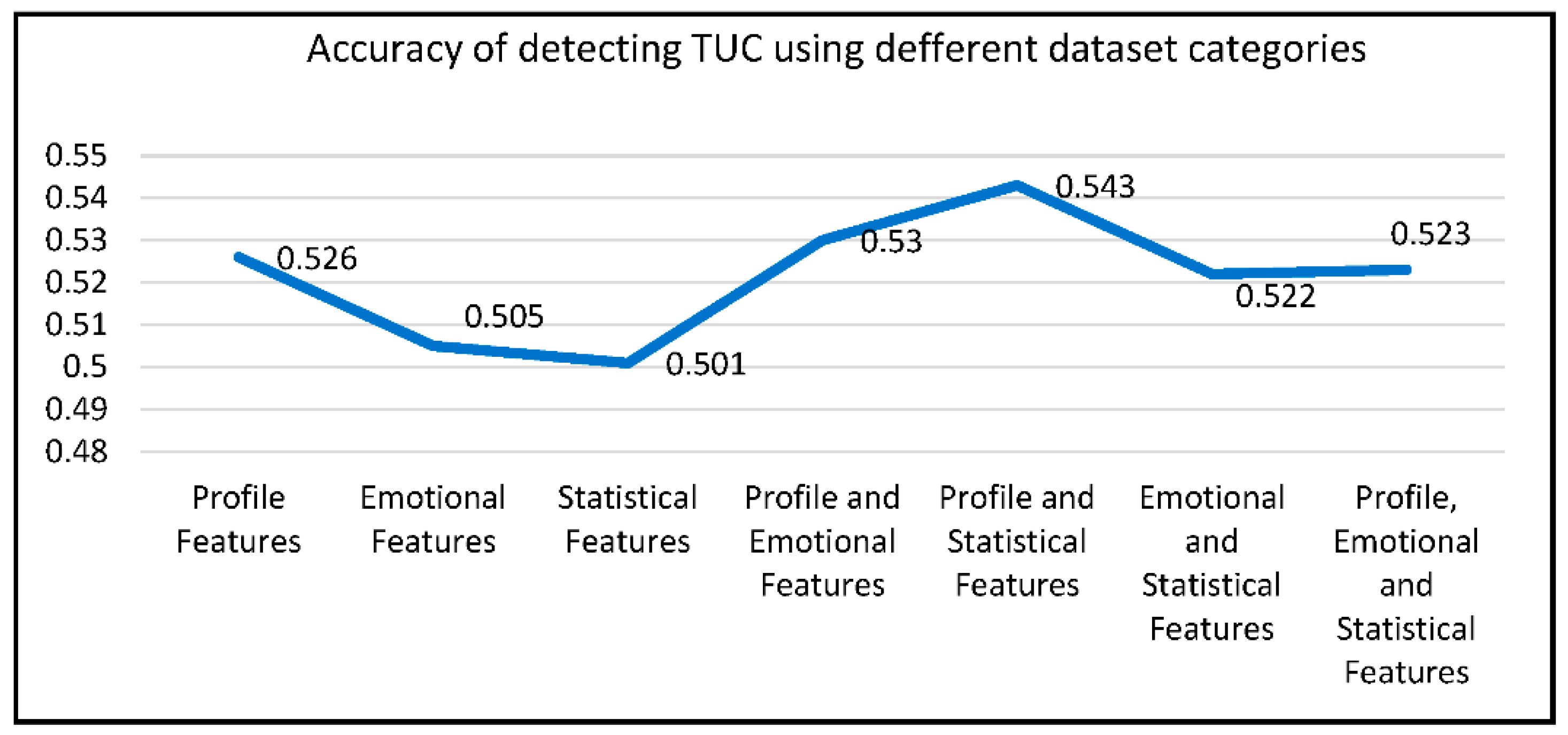
6.2. Feature Category
- Combined Feature Categories: Our research demonstrated that combining all feature categories (profile, emotional, and statistical) resulted in the highest accuracy for XUCD. This finding underscores the importance of using diverse feature sets to capture different aspects of user credibility.
- Individual Feature Categories: Using feature categories individually had the lowest accuracy results, as seen in Figure 10. This suggests that a holistic approach, leveraging multiple feature categories, is essential for accurate XUCD.
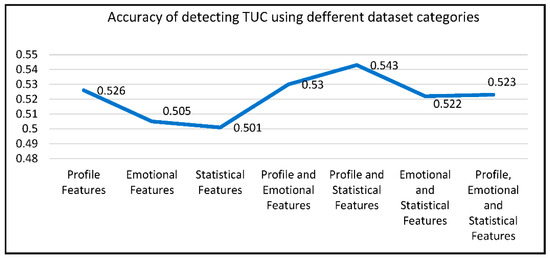 Figure 10. Accuracy based on dataset category.
Figure 10. Accuracy based on dataset category.
6.3. Classifier Effectiveness
Referring to Section 4.2, Table 6, and Figure 8, XGB was the most effective classifier for detecting X-Platform user credibility by offering the highest accuracy score with an average of 0.521. Additionally, when considering the impact of dataset category on the accuracy of each classifier’s detection, some interesting insights emerged. The XGB classifier was found to be less affected by variations in feature categories, with accuracy results exhibiting a relatively small range of around 4%, followed by SVM with a range of 8.7%. In contrast, LR was more influenced by the dataset category, with accuracy results varying up to almost 11%.
In summary, the findings presented in this study hold significant implications for the fields of supervised machine learning, feature selection, and social media analysis. Our exploration of feature selection methods, particularly SelectKBest and correlation-based algorithms, alongside various feature types, provides an understanding of their impact on the accuracy of X-platform user credibility detection.
The identification of key features and their impact on credibility detection provides valuable insights into user behavior dynamics, contributing to the refinement of existing theories in digital communication.
Managerially, the research offers practical guidance for combating misinformation and enhancing credibility detection systems, aiding organizations in targeted strategies for content moderation and user engagement. The study’s methodological contributions influence both theoretical frameworks and managerial practices, laying a foundation for further explorations in the evolving landscape of user credibility within the digital platforms, in addition to its contribution to the academic discourse in this area.
7. Conclusions
In summary, our research provides valuable insights into the use of selection methods for improving the accuracy of XUCD. By comparing the accuracy results obtained from two feature selection methods and three machine learning classifiers, we were able to draw several key conclusions:
- The correlation-based algorithm outperformed the SelectKBest approach for enhancing the accuracy of XUCD results.
- Among the tested classifiers (SVM, LR, and XGB), XGB mostly delivered the highest accuracy results.
These findings have practical implications for developing more accurate XUCD systems and highlight the importance of choosing the right combination of feature selection methods and classifiers for the task at hand.
In addition, it is essential to acknowledge the limitations and challenges that are inherent in our research. One notable limitation is the reliance on a specific dataset, ArPFN, which, while carefully chosen for its relevance, may not fully capture the diversity of user behaviors across all online platforms. Additionally, the dynamic nature of social media introduces challenges in ensuring the longevity and adaptability of the proposed models over time. Furthermore, the subjective nature of credibility labels and the evolving landscape of online information dissemination pose challenges to obtaining ground truth data.
To address these limitations, future research efforts should aim to expand the scope of datasets, encompassing a broader range of platforms and user demographics. The development of more robust models should consider the evolving nature of online platforms and explore adaptive strategies to maintain effectiveness over time. Furthermore, collaboration with domain experts and the integration of user feedback can enhance the accuracy and relevance of credibility labels. By addressing these challenges and pursuing these avenues, we can contribute to the refinement and applicability of user credibility detection systems within online platforms.
Author Contributions
Conceptualization, H.A.A.; Methodology, N.R.A.-A.; Validation, N.R.A.-A.; Formal analysis, N.R.A.-A.; Writing—original draft, N.R.A.-A.; Writing—oreview & editing, H.A.A.; Supervision, H.A.A.; Funding acquisition, H.A.A.. All authors have read and agreed to the published version of the manuscript.
Funding
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project no. (IFKSUOR3–409–1).
Data Availability Statement
The data that support the findings of this study are openly available in Gitlab at https://gitlab.com/bigirqu/ArPFN, reference number [34], (accessed on 5 January 2023).
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Raouf, I.; Lee, H.; Noh, Y.R.; Youn, B.D.; Kim, H.S. Prognostic health management of the robotic strain wave gear reducer based on variable speed of operation: A data-driven via deep learning approach. J. Comput. Des. Eng. 2022, 9, 1775–1788. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, L.; Zheng, Y. Predict pairwise trust based on machine learning in online social networks: A survey. IEEE Access 2018, 6, 51297–51318. [Google Scholar] [CrossRef]
- Credibility, Cambridge Dictionary Entry. Available online: https://dictionary.cambridge.org/dictionary/english/credibility (accessed on 5 March 2023).
- Abbasi, M.-A.; Liu, H. Measuring user credibility in social media. In Proceedings of the Social Computing, Behavioral-Cultural Modeling and Prediction: 6th International Conference, Washington, DC, USA, 2–5 April 2013. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblet, B. Information credibility on twitter. In Proceedings of the Proceedings of the 20th international conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011. [Google Scholar]
- Wijesekara, M.; Ganegoda, G.U. Source credibility analysis on Twitter users. In Proceedings of the 2020 International Research Conference on Smart Computing and Systems Engineering (SCSE), Colombo, Sri Lanka, 24 September 2020; pp. 96–102. [Google Scholar]
- Thaher, T.; Saheb, M.; Turabieh, H.; Chantar, H. Intelligent detection of false information in arabic tweets utilizing hybrid harris hawks based feature selection and machine learning models. Symmetry 2021, 13, 556. [Google Scholar] [CrossRef]
- Setiawan, E.B.; Widyantoro, D.H.; Sur, K. Measuring information credibility in social media using combination of user profile and message content dimensions. Int. J. Electr. Comput. Eng. 2020, 10, 3537. [Google Scholar]
- Geetika, S.; Bhatia, M.P.S. Content based approach to find the credibility of user in social networks: An application of cyberbullying. Int. J. Mach. Learn. Cybern. 2017, 8, 677–689. [Google Scholar]
- Azer, M.; Taha, M.; Zayed, H.H.; Gadallah, M. Credibility Detection on Twitter News Using. I.J. Intell. Syst. Appl. 2021, 3, 1–10. [Google Scholar]
- Kurniati, R.; Widyantoro, D.H. Identification of Twitter user credibility using machine learning. In Proceedings of the 5th International Conference on Instrumentation Communications, Information Technology, and Biomedical Engineering (ICICI-BME), Bandung, Indonesia, 6–7 November 2017. [Google Scholar]
- Alrubaian, M.; Al-Qurishi, M.; Al-Rakhami, M.; Hassan, M.M. Reputation-based credibility analysis of Twitter social network users. Concurr. Comput. Pract. Exp. 2017, 29, 7. [Google Scholar] [CrossRef]
- Afify, E.A.; Eldin, A.S.; Khedr, A.E. Facebook profile credibility detection using machine and deep learning techniques based on user’s sentiment response on status message. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 12. [Google Scholar] [CrossRef]
- Hassan, N.Y.; Gamaa, W.H.; Khoriba, G.A.; Haggag, M.H. Supervised learning approach for twitter credibility detection. In In Proceedings of the 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018. [Google Scholar]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Amin, S.; Uddin, I.; Al-Baity, H.H.; Zeb, A.; Khan, A. Machine learning approach for COVID-19 detection on twitter. Comput. Mater. Contin. 2021, 68, 2231–2247. [Google Scholar]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G. An introduction to logistic regression analysis and reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Liu, B.; Blasch, E.; Chen, Y.; Shen, D.; Chen, G. Scalable sentiment classification for big data analysis using naive bayes classifier. In Proceedings of the IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013. [Google Scholar]
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 7013–7714. [Google Scholar]
- Mienyea, D.; Sun, Y.; Wang, Z. Prediction performance of improved decision tree-based algorithms: A review. Procedia Manuf. 2019, 35, 698–703. [Google Scholar] [CrossRef]
- Amrani, Y.A.L.; Lazaar, M.; Kadiri, K.E.E.L. Random forest and support vector machine based hybrid approach to sentiment analysis. Procedia Comput. Sci. 2018, 127, 511–520. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Jozdani, S.E.; Johnson, B.A.; Chen, D. Comparing deep neural networks, ensemble classifiers, and support vector machine algorithms for object-based urban land use/land cover classification. Remote Sens. 2019, 11, 1713. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Rais, H.M.; Abdulkadir, S.J.; Mirjalili, S.; Alhussain, H. A review of grey wolf optimizer-based feature selection methods for classification. In Evolutionary Machine Learning Techniques: Algorithms and Applications; Springer: Singapore, 2020; pp. 273–286. [Google Scholar]
- Elavarasan, D.; Vincent, P.M.D.R.; Srinivasan, K.; Chang, C.-Y. A hybrid CFS filter and RF-RFE wrapper-based feature extraction for enhanced agricultural crop yield prediction modeling. Agriculture 2020, 10, 400. [Google Scholar] [CrossRef]
- Gray, B. Collaborating: Finding Common Ground for Multiparty Problems; Jossey-Bass: San Francisco, CA, USA, 1989. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Rahman, M.; Usman, L.; Muniyandi, R.C.; Sahran, S.; Mohamed, S.; Razak, R.A. A review of machine learning methods of feature selection and classification for autism spectrum disorder. Brain Sci. 2020, 10, 949. [Google Scholar] [CrossRef]
- Gary, T. How Feature Selection Techniques for Machine Learning Are Important? Knoldus. 22 February 2022. Available online: https://blog.knoldus.com/how-feature-selection-techniques-for-machine-learning-are-important/ (accessed on 5 January 2023).
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. 2018, 19, 1–6. [Google Scholar] [CrossRef]
- Omuya, E.O.; Okeyo, G.O.; Kimwele, M.W. Feature selection for classification using principal component analysis and information gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- CREDBANK-Data. Github, 10 10 2016. Available online: https://github.com/compsocial/CREDBANK-data (accessed on 11 December 2022).
- FakeNewsNet. Github, 23 9 2021. Available online: https://github.com/KaiDMML/FakeNewsNet (accessed on 5 December 2022).
- ArPFN. Gitlab, 9 9 2022. Available online: https://gitlab.com/bigirqu/ArPFN (accessed on 27 December 2022).
- PHEME_Dataset_of_Rumours_and_Non-Rumours. Figshare, 24 10 2016. Available online: https://figshare.com/articles/dataset/PHEME_dataset_of_rumours_and_non-rumours/4010619 (accessed on 25 December 2022).
- Al-Khalifa, H.S.; Al-Eidan, R.M. An experimental system for measuring the credibility of news content in Twitter. Int. J. Web Inf. Syst. 2011, 7, 130–151. [Google Scholar] [CrossRef]
- Hassan, N.Y.; Gomaa, W.H.; Khoriba, G.A.; Haggag, M.H. Credibility detection in twitter using word n-gram analysis and supervised machine learning techniques. Int. J. Intell. Eng. Syst. 2020, 13, 291–300. [Google Scholar]
- Zhang, R.; Gao, M.; He, X. Learning user credibility for product ranking. Knowl. Inf. Syst. 2016, 46, 679–705. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Fahrurrozi, I.; Fitriyan, N.L.; Tatas, F.; Atmaji, D.; Widodo, T.; Bahiyah, N.; Benes, F.; Rhee, J. Predicting breast cancer from risk factors using SVM and extra-trees-based feature selection method. Computers 2022, 11, 136. [Google Scholar] [CrossRef]
- Wickramarathna, N.C.; Jayasiriwardena, T.D.; Wijesekara, M.; Munasinghe, P.B.; Ganegoda, G.U. A framework to detect twitter platform manipulation and computational propaganda. In Proceedings of the 20th International Conference on Advances in ICT for Emerging Regions (ICTer) IEEE, Colombo, Sri Lanka, 4–7 November 2020. [Google Scholar]
- Murugan, S.N.; Devi, U.G. Feature extraction using LR-PCA hybridization on twitter data and classification accuracy using machine learning algorithms. Clust. Comput. 2019, 22, 13965–13974. [Google Scholar] [CrossRef]
- Varol, O.; Davis, C.A.; Menczer, F.; Flammini, A. Feature engineering for social bot detection. In Feature Engineering for Machine Learning and Data Analytics, 1st ed.; CRC Press: Boca Raton, FL, USA, 2018; pp. 311–334. [Google Scholar] [CrossRef]
- Ahmad, F.; Rizvi, S.A.M. Features Identification for Filtering Credible Content on Twitter Using Machine Learning Techniques. In Proceedings of the Social Networking and Computational Intelligence: Proceedings of SCI-2018, Singapore, 23 March 2020. [Google Scholar]
- Khan, T.; Michalas, A. Seeing and Believing: Evaluating the Trustworthiness of Twitter Users. IEEE Access 2021, 9, 110505–110516. [Google Scholar] [CrossRef]
- Buda, J.; Bolonyai, F. An Ensemble Model Using N-grams and Statistical Features to Identify Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Ali, Z.S.; Al-Ali, A.; Elsayed, T. Detecting Users Prone to Spread Fake News on Arabic Twitter. In Proceedings of the 5th Workshop on Open-Source Arabic Corpora and Processing Tools with Shared Tasks on Qur’an QA and Fine-Grained Hate Speech Detection, Marseille, France, 20 June 2022. [Google Scholar]
- Abu-Salih, B.; Chan, K.Y.; Al-Kadi, O.; Al-Tawil, M.; Wongthongtham, P.; Issa, T.; Saadeh, H.; Al-Hassan, M.; Bremie, B.; Albahlal, A. Time-aware domain-based social influence prediction. J. Big Data 2020, 7, 1–37. [Google Scholar] [CrossRef]
- Jain, P.K.; Pamula, R.; Ansari, S. A supervised machine learning approach for the credibility assessment of user-generated content. Wirel. Pers. Commun. 2021, 118, 2469–2485. [Google Scholar] [CrossRef]
- Raj, E.D.; Babu, L.D. RAN enhanced trust prediction strategy for online social networks using probabilistic reputation features. Neurocomputing 2017, 219, 412–421. [Google Scholar] [CrossRef]
- Hamdi, T.; Slimi, H.; Bounhas, I.; Slimani, Y. A hybrid approach for fake news detection in twitter based on user features and graph embedding. In Proceedings of the Distributed Computing and Internet Technology: 16th International Conference, ICDCIT, Bhubaneswar, India, 9–12 January 2020. [Google Scholar]
- Sharma, U.; Kumar, S. Feature-based comparative study of machine learning algorithms for credibility analysis of online social media content. In Proceedings of the Data Engineering for Smart Systems: Proceedings of SSIC, Singapore, 22–23 January 2021. [Google Scholar]
- Saeed, U.; Fahim, H.; Shirazi, F. Profiling Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Verma, P.K.; Agrawal, P.; Madaan, V.; Gupta, C. UCred: Fusion of machine learning and deep learning methods for user credibility on social media. Soc. Netw. Anal. Min. 2022, 12, 54. [Google Scholar] [CrossRef]
- Raouf, I.; Lee, H.; Kim, H.S. Mechanical fault detection based on machine learning for robotic RV reducer using electrical current signature analysis: A data-driven approach. J. Comput. Des. Eng. 2022, 9, 417–433. [Google Scholar] [CrossRef]
- Bahassine, S.; Madani, A.; Al-Sarem, M.; Kissi, M. Feature selection using an improved Chi-square for Arabic text classification. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 225–231. [Google Scholar] [CrossRef]
- Al-Zoubi, M.; Alqatawna, J.; Faris, H.; Hassonah, M.A. Spam profiles detection on social networks using computational intelligence methods: The effect of the lingual context. J. Inf. Sci. 2021, 47, 58–81. [Google Scholar] [CrossRef]
- Sharaff, A.; Gupta, H. Extra-tree classifier with metaheuristics approach for email classification. In Proceedings of the Advances in Computer Communication and Computational Sciences: Proceedings of IC4S 2018, Singapore, 20–21 October 2018. [Google Scholar]
- Karakaşlı, M.S.; Aydin, M.A.; Yarkan, S.; Boyaci, A. Dynamic feature selection for spam detection in Twitter. In Proceedings of the International Telecommunications Conference: Proceedings of the ITelCon, Istanbul, Turkey, 28–29 December 2017. [Google Scholar]
- Jayashree, P.; Laila, K.; Kumar, K.S.; Udayavannan, A. Social Network Mining for Predicting Users’ Credibility with Optimal Feature Selection. In Intelligent Sustainable Systems: Proceedings of ICISS; Springer: Singapore, 2021. [Google Scholar]
- Kamkarhaghighi, M.; Chepurna, I.; Aghababaei, S.; Makrehchi, M. Discovering credible Twitter users in stock market domain. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI), Omaha, NE, USA, 13–16 October 2016. [Google Scholar]
- Gayakwad, M.; Patil, S.; Kadam, A.; Joshi, S.; Kotecha, K.; Joshi, R.; Pandya, S.; Gonge, S.; Rathod, S.; Kadam, K.; et al. Credibility analysis of user-designed content using machine learning techniques. Appl. Syst. Innov. 2022, 5, 43. [Google Scholar] [CrossRef]
- Maria, G.H.; Aguilera, A.; Dongo, I.; Cornejo-Lupa, J.M.; Cardinale, Y. Credibility Analysis on Twitter Considering Topic Detection. Appl. Sci. (Work. Notes) 2022, 12, 9081. [Google Scholar]
- Kang, Z.; Xing, L.; Wu, H. S3UCA: Soft-Margin Support Vector Machine-Based Social Network User Credibility Assessment Method. Mob. Inf. Syst. 2021, 2021, 7993144. [Google Scholar]
- Espinosa, M.S.; Centeno, R.; Rodrigo, Á. Analyzing User Profiles for Detection of Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Duan, X.; Naghizade, E.; Spina, D.; Zhang, X. RMIT at PAN-CLEF 2020: Profiling Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Iftikhar, A.; Muhammad, Y.; Suhail, Y.; Ovais, M. Fake news detection using machine learning ensemble methods. Complexity 2020, 2020, 8885861. [Google Scholar]
- Sabeeh, V.; Zohdy, M.; Mollah, A.; Al Bashaireh, R. Fake news detection on social media using deep learning and semantic knowledge sources. Int. J. Comput. Sci. Inf. Secur. (IJCSIS) 2020, 15, 45–68. [Google Scholar]
- Dongo, I.; Cardinale, Y.; Aguilera, A. Credibility analysis for available information sources on the web: A review and a contribution. In Proceedings of the 4th International Conference on System Reliability and Safety (ICSRS), Rome, Italy, 20–22 November 2019. [Google Scholar]
- Etaiwi, W.; Awajan, A. The effects of features selection methods on spam review detection performance. In Proceedings of the International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).