
The Effect of Feature Selection on the Accuracy of X-Platform User Credibility Detection with Supervised Machine Learning


Abstract
:1. Introduction
2. Research Background
2.1. User Credibility Detection
- Interaction-based features: These features encompass a user’s engagement with other users and the level of social support they offer [9].
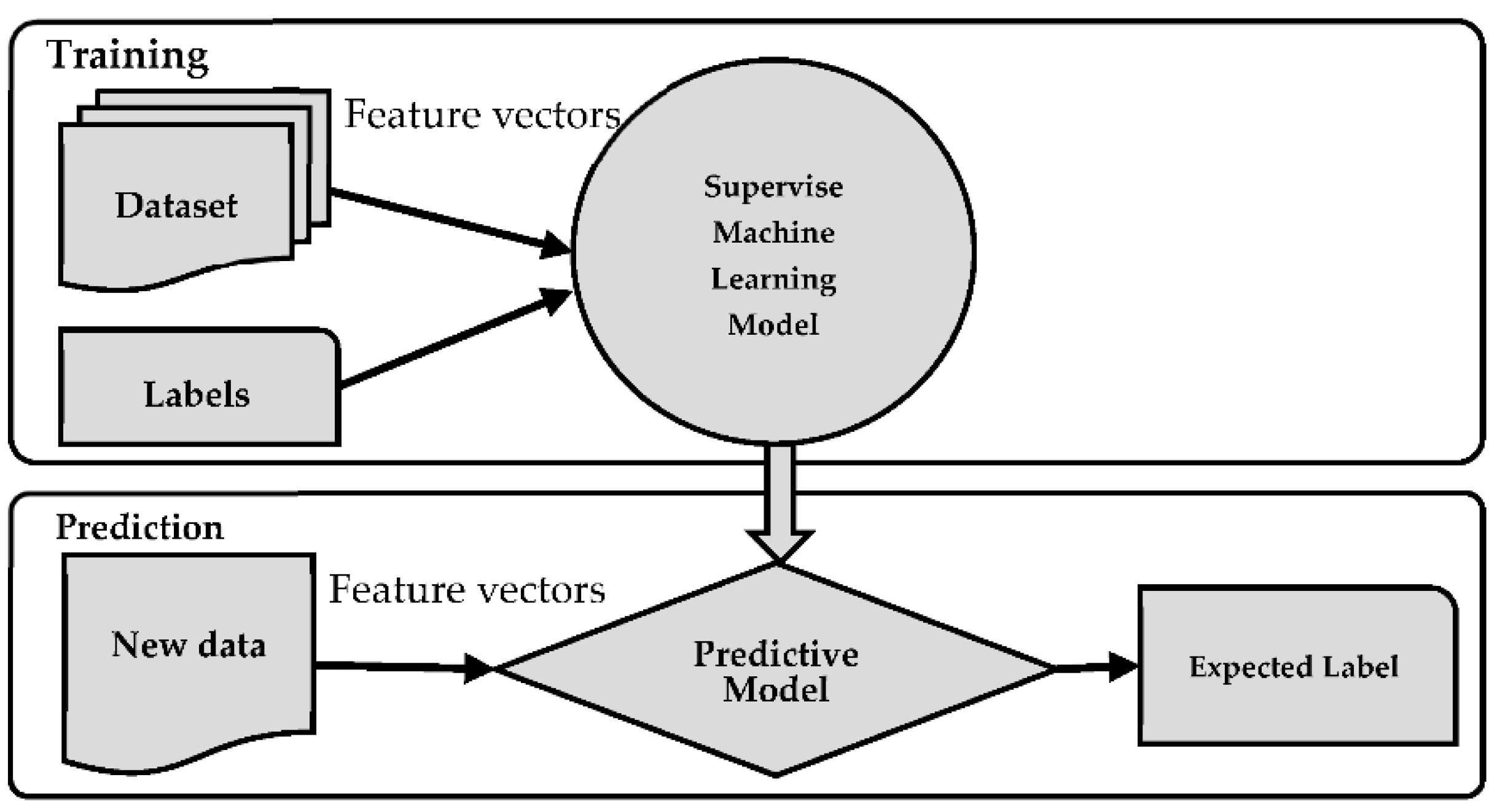
2.2. Supervised Machine Learning (SML)
2.2.1. Support Vector Machine (SVM)
2.2.2. Logistic Regression (LR)
2.2.3. Naïve Bayes (NB)
2.2.4. Decision Tree (DT)
2.2.5. Random Forest (RF)
2.2.6. Boosting Algorithms
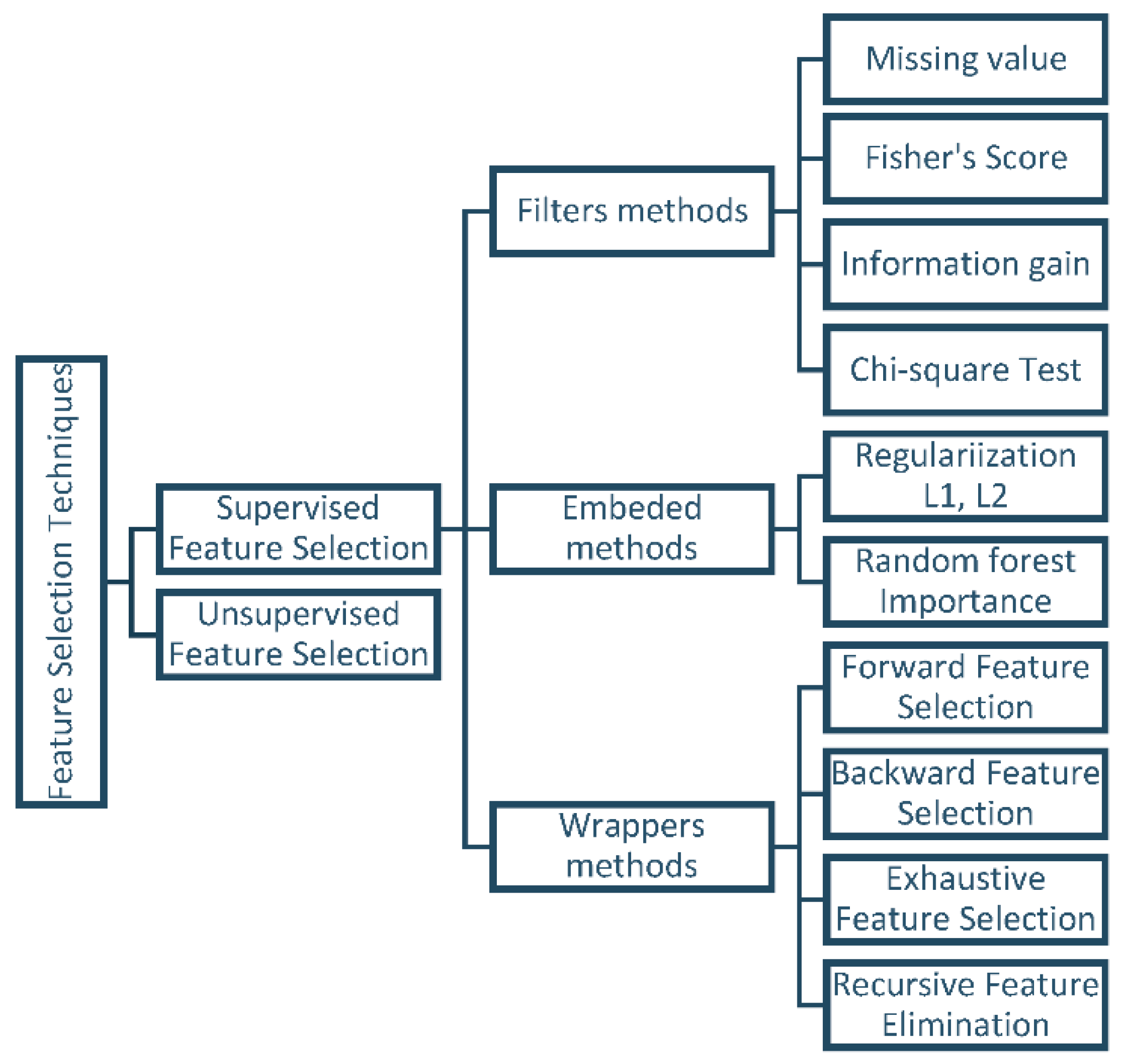
2.3. Feature Selection
- Filter methods assess features based on data characteristics, such as Pearson’s correlation and chi-square, without involving any classification algorithms. These methods are employed to rank features based on their importance and then select the top-ranked features for the model [24]. One of the main advantages of filter methods is that they do not require data alteration to fit the algorithms. However, a drawback of ranking methods is that the selected subset may not be optimal, potentially containing redundant features [27].
- Wrapper methods utilize classifiers to select a set of features and recommend an appropriate approach for feature selection, irrespective of the machine learning algorithm used [24]. Evaluating and selecting variable subsets is performed via handling the predictor as a black box and using its performance as the objective function [27]. Recursive feature elimination is a familiar example of a wrapper method [24].
- Embedded methods employ algorithms with built-in feature selection mechanisms. These methods offer advantages such as interaction with the classification model and require fewer computational resources than wrapper methods. They make use of regularization techniques like L1 or L2 regularization [24]. Examples of embedded methods include the least absolute shrinkage and selection operator (LASSO) and random forest (RF), both of which have their own unique feature selection approaches [28]. Figure 2 presents the most popular algorithms encountered in feature selection [29].
- Recursive feature elimination (RFE): RFE is a backward feature selection method that iteratively eliminates the least important feature until the desired number of features is reached [30].
- SelectKBest: A straightforward feature selection method that selects the top K features based on a statistical test, such as chi-squared, ANOVA F test, or mutual information [30].
- Principal Component Analysis (PCA): A dimensionality reduction technique that transforms data into a lower-dimensional space while maintaining the most important information. The machine learning model can use these resulting principal components as features in the dataset [31].
2.4. User Credibility Datasets
- CredBank: A set of streaming tweets monitored from mid-October 2014 to the end of February 2015. It categorizes tweets into events or non-events and provides credibility ratings for those events [32].
- FakeNewsNet: A collection of fake news stories and X-Platform users who shared them. Users’ features include profile details, timeline content, follower counts, and the accounts they follow [33].
- ArPFN: A dataset that includes X-Platform users associated with the number of fake and true tweets they have shared on the X-Platform. Each user has 39 features separated into four files characterized into profile features, text features, emotional features, and statistical features [34].
- PHEME: A dataset consisting of tweets related to breaking news events and offering references for assessing their credibility and veracity. It encompasses a range of tweet-level features, including sentiment analysis, information sources, and retweet counts [35].
3. Literature Review
3.1. X-Platform User Credibility Detection Methods
- Naïve Bayes (NB) [38].
- Graph-based approaches: For instance, researchers use twin-bipartite graphs to model relationships among users, products, and shops (a PCS graph), calculating scores and user credibility iteratively [38]. Another approach leverages node2vec to extract features from the X-Platform followers/followed graph, considering both user features and social graph data [50].
- Behavior analysis: The CredRank algorithm is introduced to assess user credibility by clustering users based on behavioral similarities [4].
- Machine learning and deep learning: The UCred model combines machine learning and deep learning methods, integrating RoBERT (robustly optimized BERT), Bi-LSTM (bidirectional LSTM), and RF outputs through a voting classifier for enhanced XUCD accuracy [53]
- Feature-hybrid approaches: Some studies, like the one presented in [46], combine sentiment analysis with social network features to identify attributes useful for XUCD. This approach assigns sentiment scores based on user history, employing reputation-based techniques.
- Reputation features: A probabilistic reputation feature model, as suggested in [45], surpasses raw reputation features in enhancing overall accuracy in user trust detection in OSNs.
- Domain-based analysis: The integration of semantic and sentiment analyses in domain-based credibility estimation and prediction is demonstrated in [47].
- Sentiment analysis and machine learning: The study located as reference [40] employs sentiment analysis and machine learning to determine both the credibility of users’ profiles and the credibility of the content.
3.2. Feature Selection
- Correlation-based feature selection: In [13], this technique was used to reduce the number of features from thirty-four to seven which are crucial for classifying Facebook users as credible. The study in [55] employs this method to identify the most discriminatory features for user credibility classification and remove irrelevant and biased ones. Meanwhile, the authors of [60] measured X-Platform users’ credibility in the stock market using the correlation between each user’s credibility and his or her social interaction features.
- Extra-trees classifier: The authors of [57] used the extra-trees classifier to eliminate irrelevant features, selecting only the top three breast cancer features that maximize model accuracy.
- SelectKBest algorithm: The authors of [10] utilized the k-best method for selecting the final feature set in their research for detecting false news on the X-Platform.
- Multiple feature selection methods: The researchers in [56] applied five feature selection methods, namely information gain, chi-square, RELIEF, correlation, and significance, to enhance spam detection.
- Dynamic feature selection technique: The study in [58] introduced a dynamic feature selection technique by grouping similar X-Platform users using k-means clustering to adapt features for each user group, enhancing the classification of spam users on the X-Platform.
- Hybrid approaches: The authors of [41] proposed a hybrid approach that combined logistic regression with dimensional reduction using principal component analysis (LR-PCA) to extract specific features from a high-dimension dataset. This approach increased classification accuracy in different machine learning classifiers.
- Recursive feature elimination (RFE): The study in [59] employed RFE to evaluate the optimal features that improve classification accuracy in detecting spammers on X-Platform. The top 10 features were selected from a larger set including 31 features, resulting in improved accuracy.
- Random forest feature importance: Some machine learning methods, such as random forest, intrinsically measure feature importance. In [42], the top features identified by random forest were analyzed and over 90% accuracy was achieved using fewer than 20 features to detect online bots on the X-Platform.
- Gradient-boosting models: In [50], a light gradient-boosting machine (light-GBM) model was used to assess the importance of each of their dataset features and eliminated the least important ones under specific conditions.
- Hybrid Harris hawk algorithm: In the context of Arabic tweet credibility, the authors of [7] adapted a binary variant of the hybrid Harris hawk (HHO) algorithm for feature selection, categorizing features into content, user profiles, and word features.
- Ant colony optimization (ACO): The authors of [51] applied an ant colony optimization (ACO) algorithm for feature selection, significantly reducing the number of features from eighteen to five and enhancing classification accuracy in distinguishing credible from fake OSN content.
- Mean decrease accuracy and Gini graphs: In [43], these graphs were employed to select the top 10 features out of 26 based on content, user, emotion, polarity, and sentiment characteristics, concluding that sentiment and polarity of tweets were the most critical variables in determining tweet credibility.
3.3. Credibility Detection in the Literature
4. Materials and Methods
4.1. Dataset
- Profile Features: These include 11 features.
- Emotional Features: Comprising 11 features.
- Statistical Features: Consisting of 17 features.
4.2. Feature Selection
- Profile Features with 17 features.
- Emotional Features with 11 features.
- Statistical Features with 11 features.
- Profile Features and Emotional Features with 28 features.
- Profile Features and Statistical Features with 28 features.
- Emotional Features and Statistical Features with 22 features.
- Profile Features, Emotional Features, and Statistical Features with 39 features.
- Running a feature selection method to compute important scores for each feature.
- Ranking features in descending order according to their importance.
- Eliminating the bottom 50% of variables with the lowest importance scores.
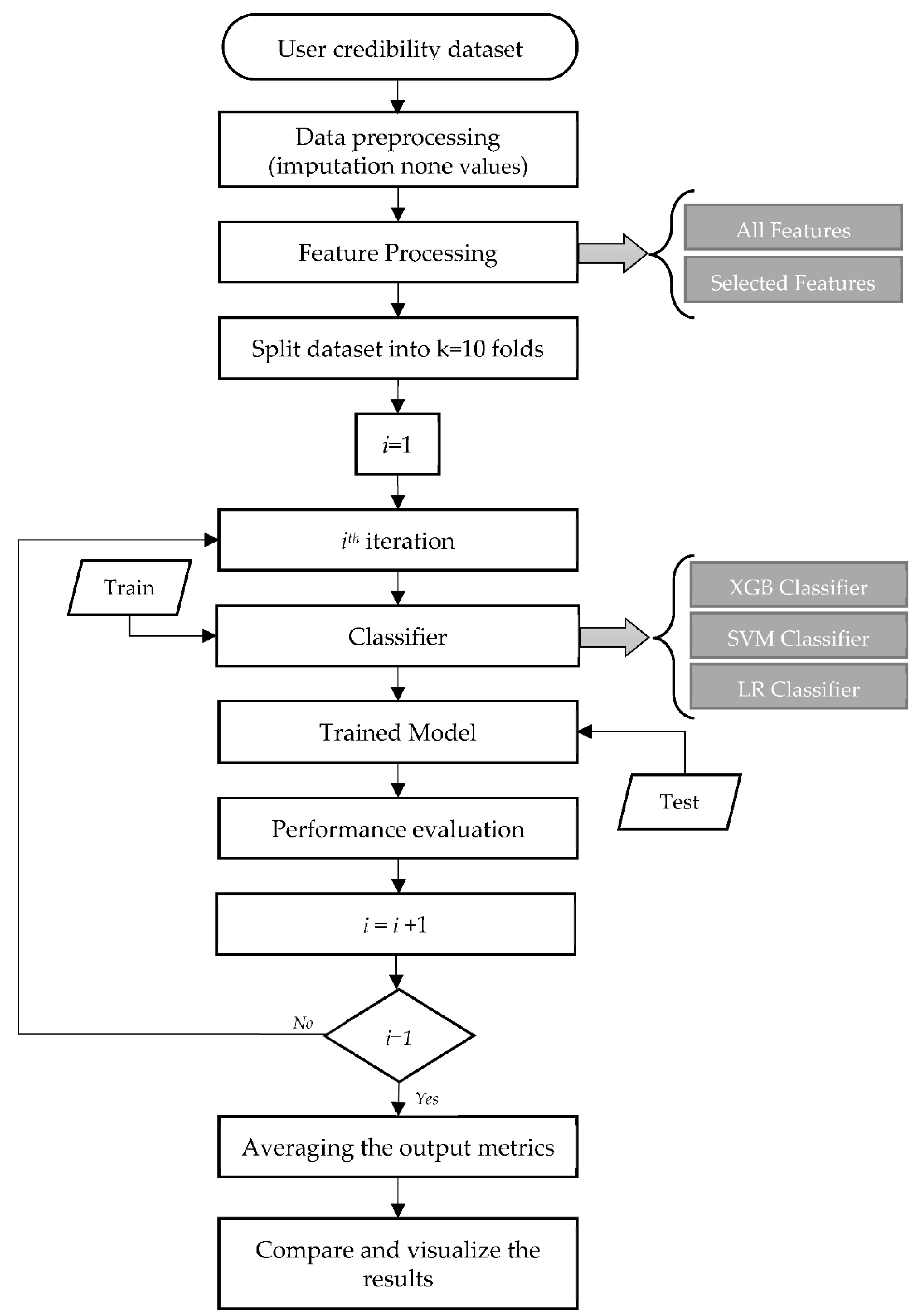
4.3. User Credibility Detection
4.4. Implementation, Evaluation, and Interpretation of the Results
5. Results
5.1. Feature Selection
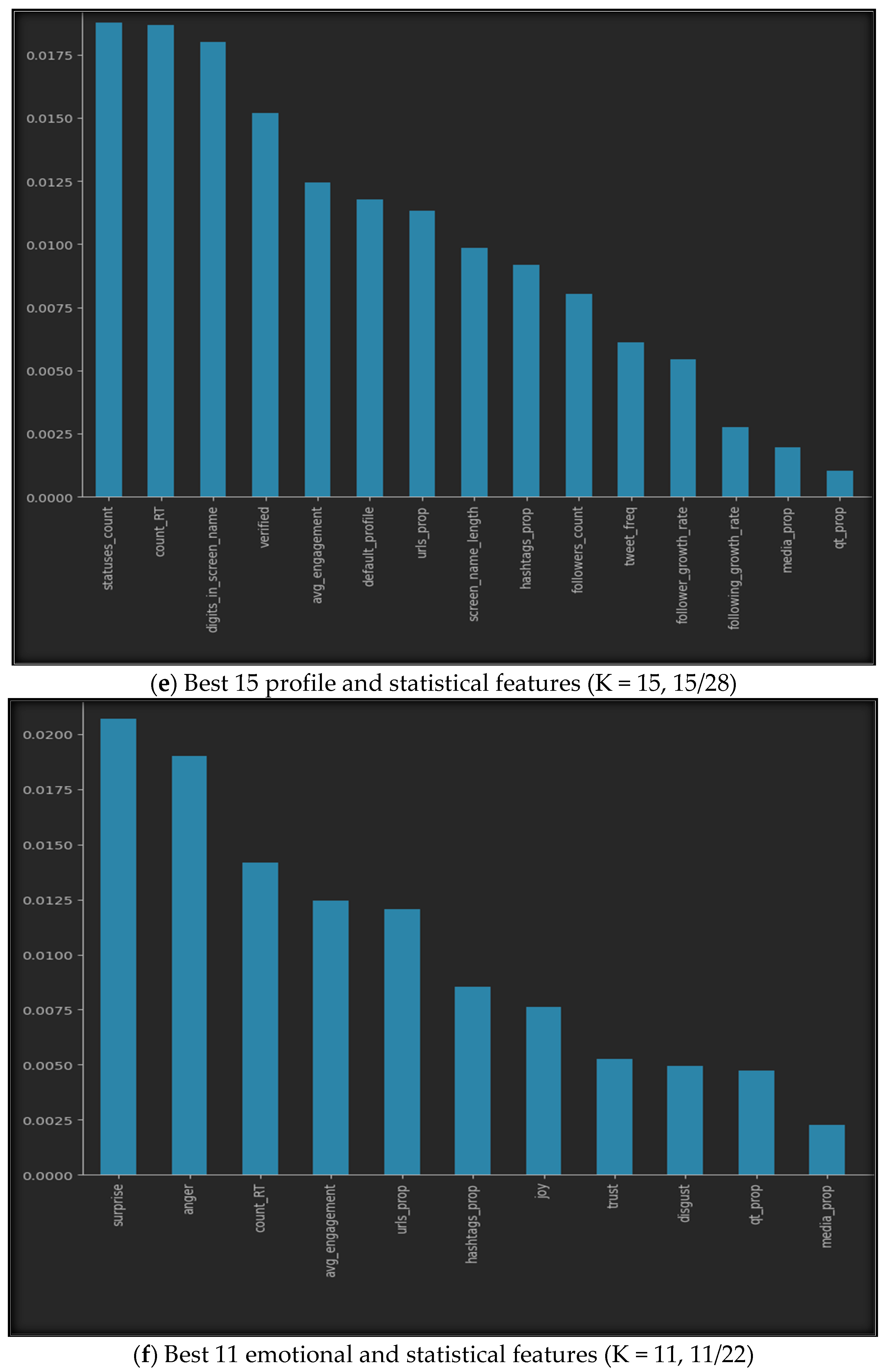
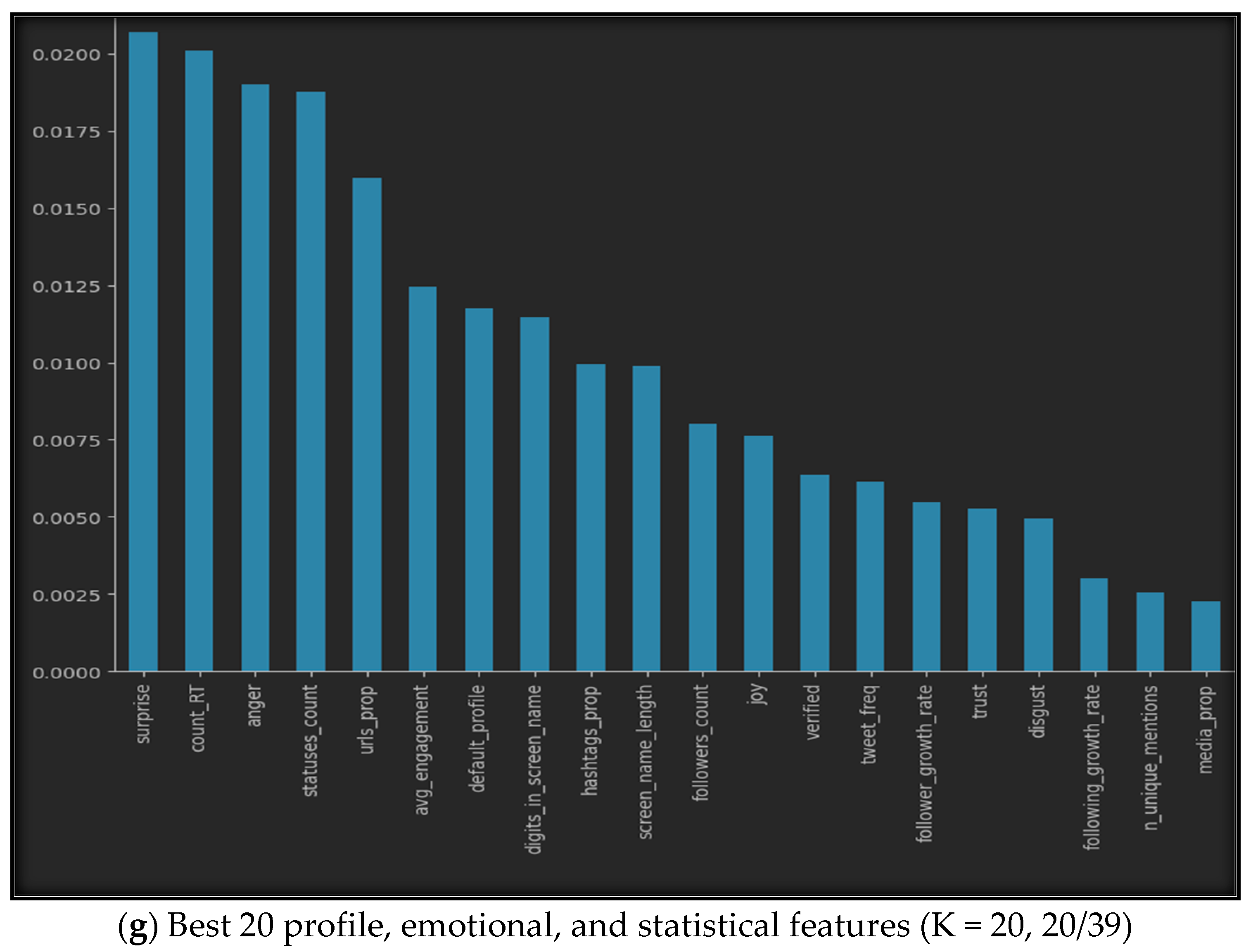
5.1.1. SelectKBest
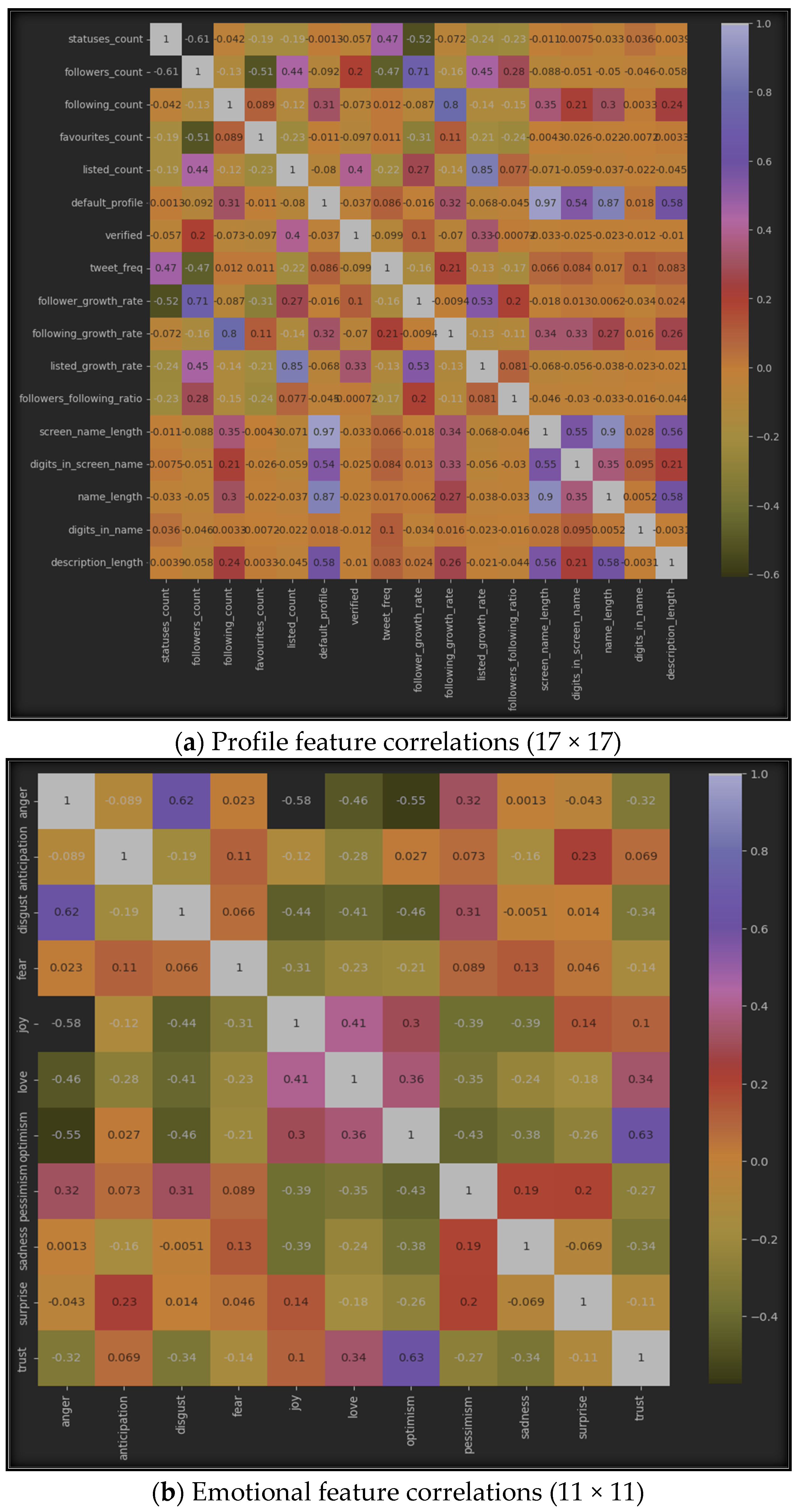
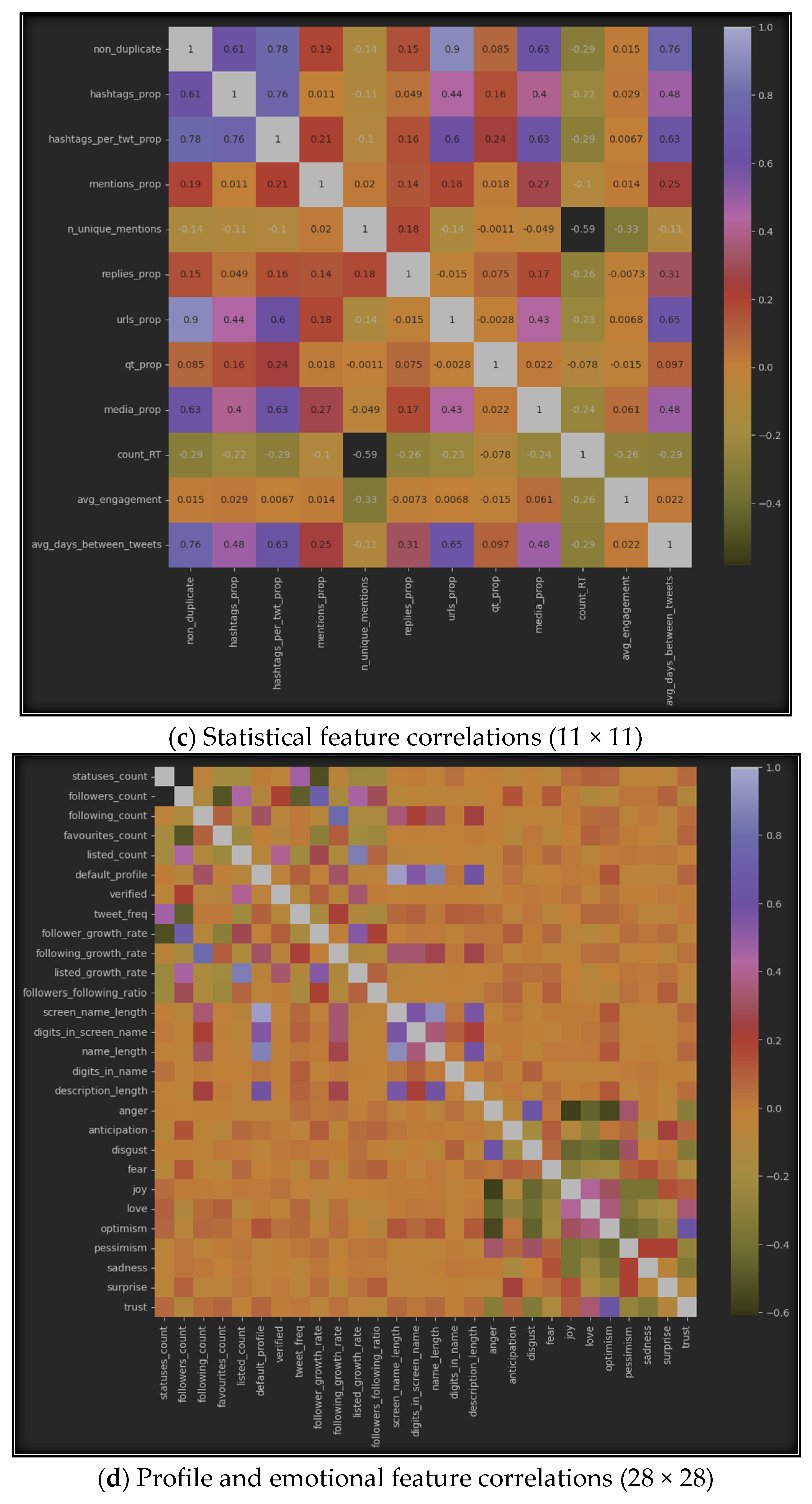
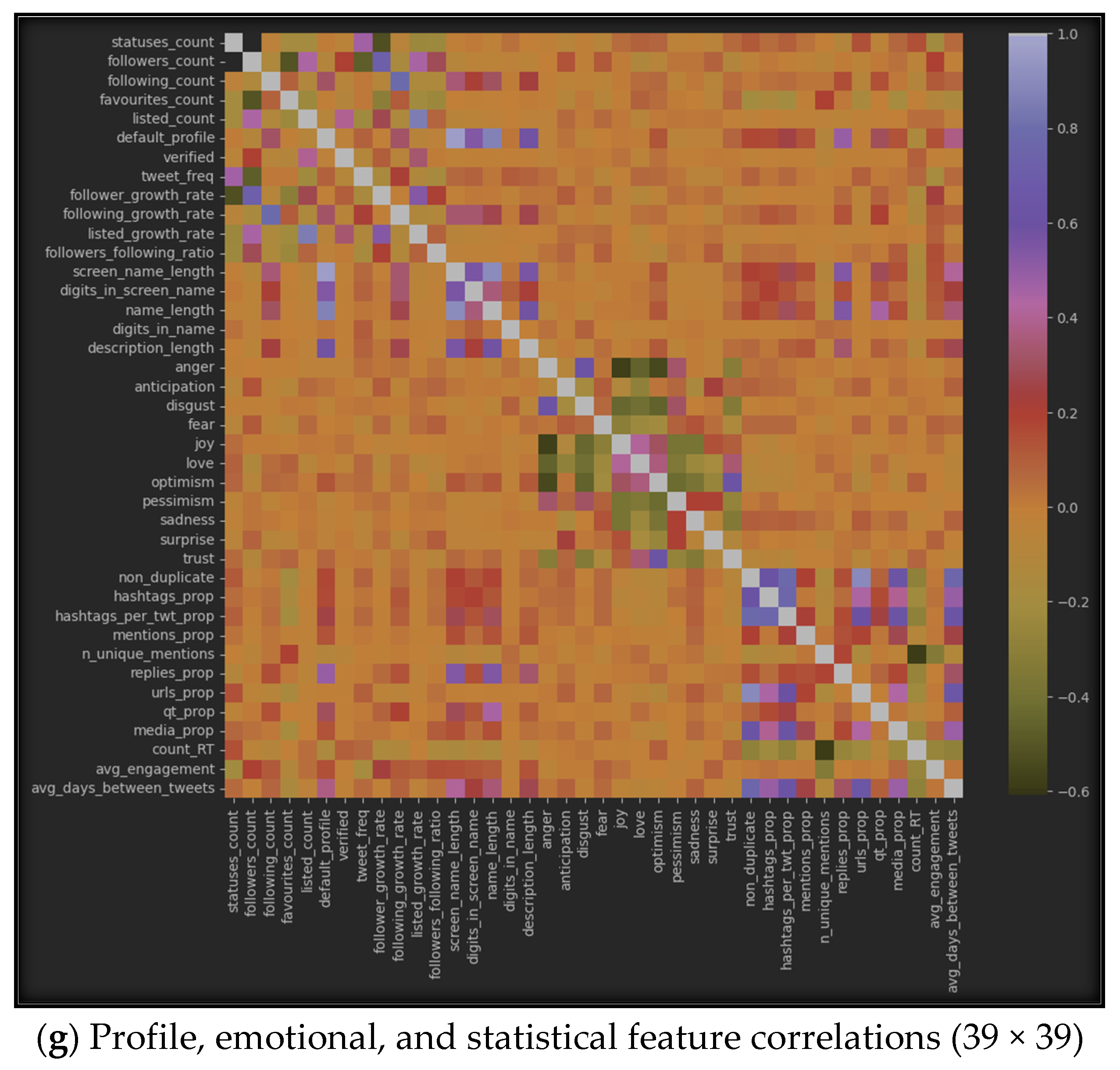
5.1.2. Correlation-Based Algorithms
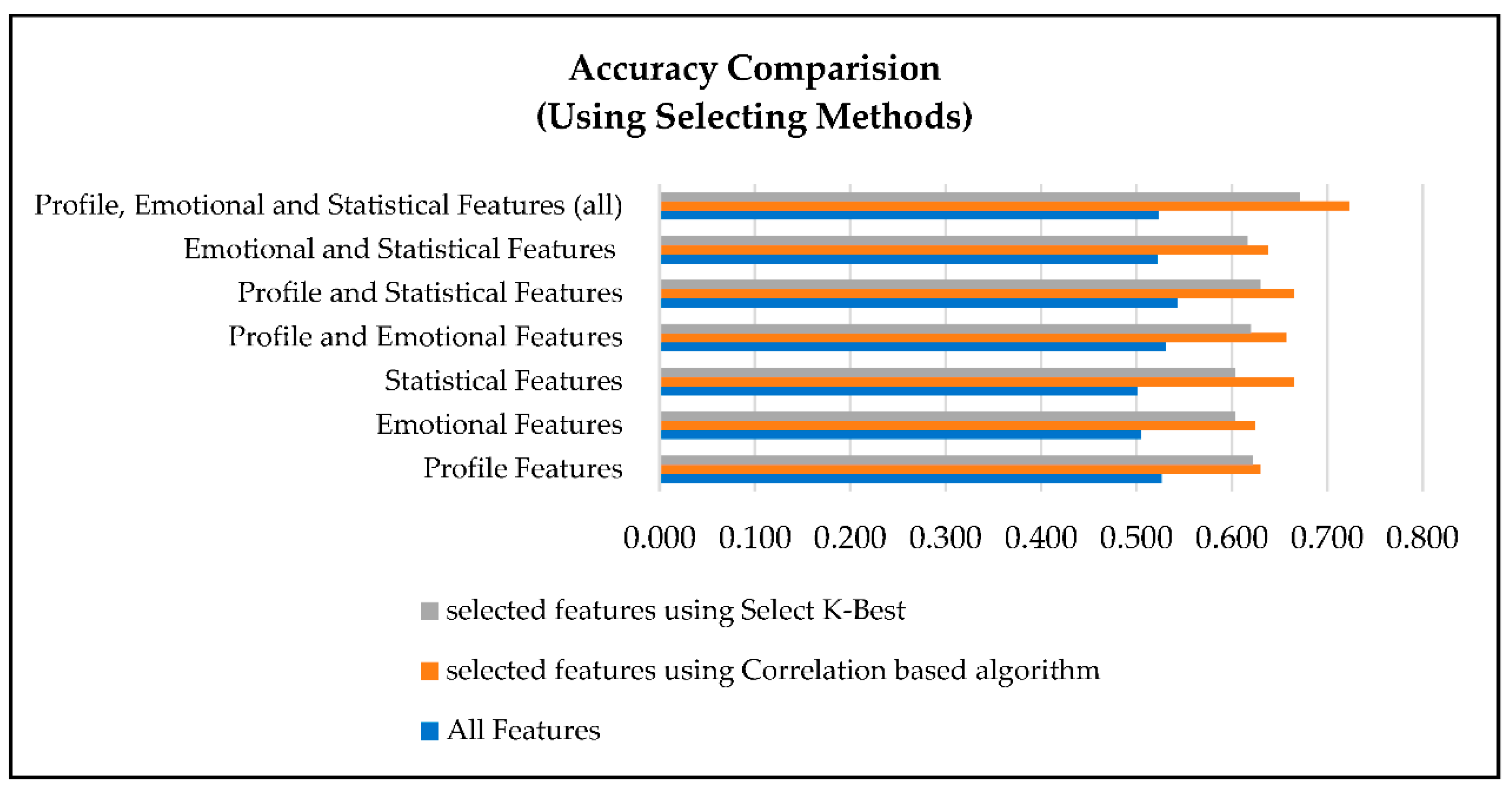
5.1.3. Accuracy of Selection Methods
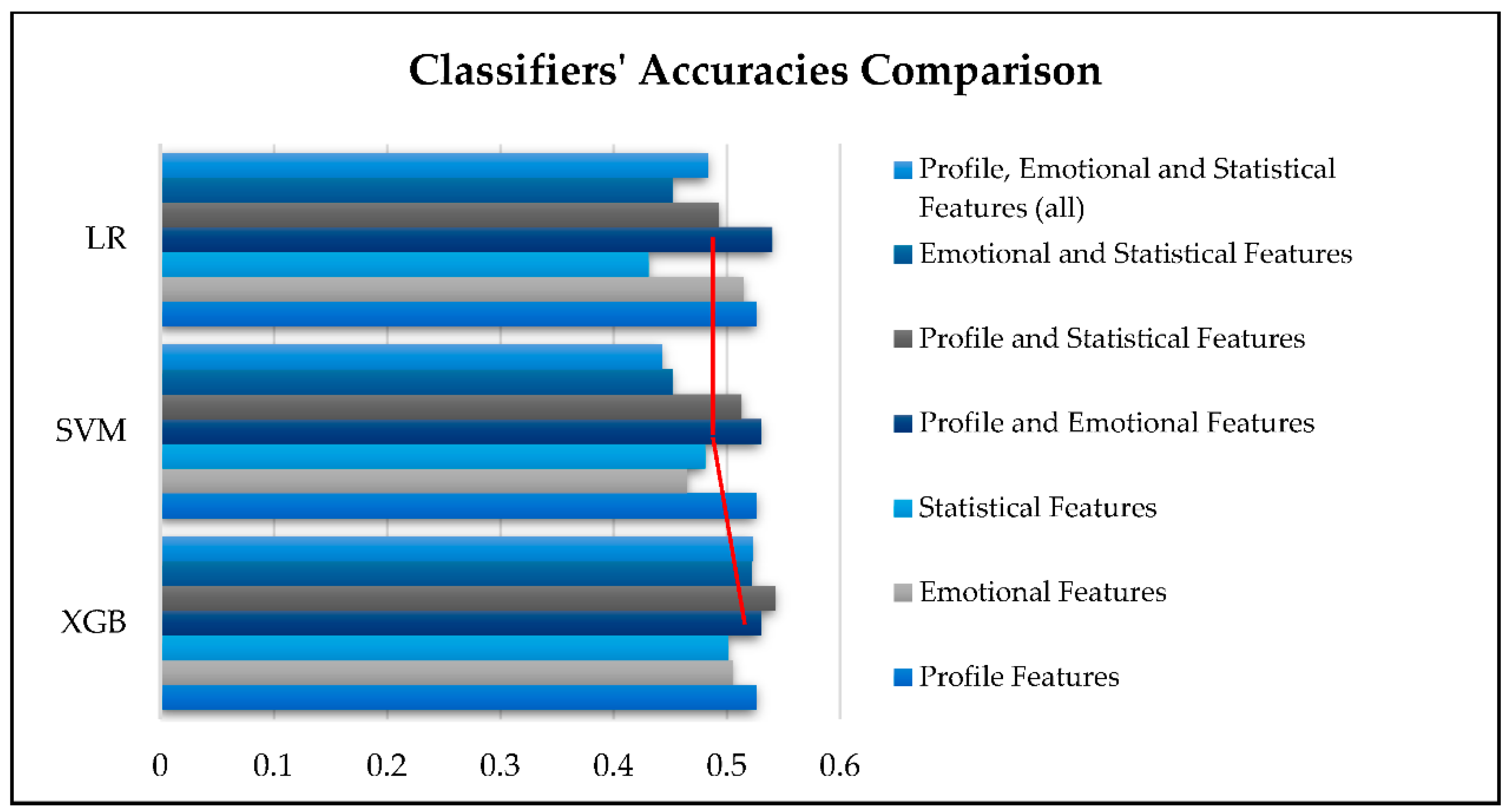
5.2. XUCD Using SML Classifiers
6. Discussion
6.1. Feature Selection
- Effectiveness of the Method: Feature selection methods, such as SelectKBest and correlation-based algorithms, proved to be generally effective in improving XUCD accuracy. This observation underscores the importance of reducing the dimensionality of the feature space by eliminating irrelevant and redundant features, ultimately resulting in more precise models. Notably, correlation-based algorithms were more effective than SelectKBest, consistently providing higher XUCD accuracy in all the sub-datasets used in our research.
- Feature Category Influence: Despite the overall improvement in XUCD accuracy achieved with feature selection methods, the impact of feature selection varied among the different feature categories. The combination of all three feature categories (profile, emotional, and statistical) benefited the most from feature selection methods. In contrast, the statistical and emotional feature datasets demonstrated less significant improvement when compared to the complete dataset. This discrepancy highlights the importance of tailoring feature selection techniques to specific feature types, as not all categories respond equally to feature selection methods.
6.2. Feature Category
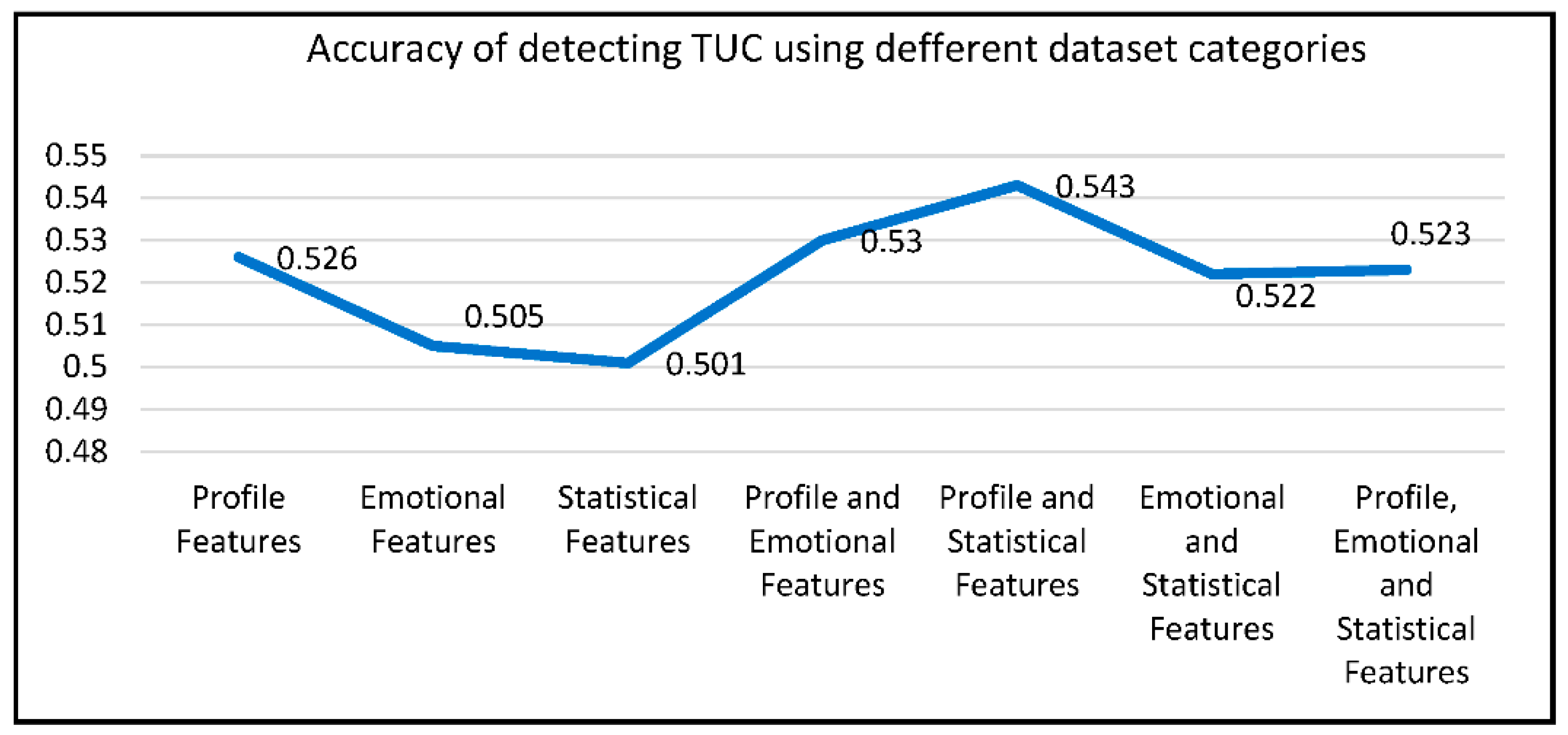
- Combined Feature Categories: Our research demonstrated that combining all feature categories (profile, emotional, and statistical) resulted in the highest accuracy for XUCD. This finding underscores the importance of using diverse feature sets to capture different aspects of user credibility.
- Individual Feature Categories: Using feature categories individually had the lowest accuracy results, as seen in Figure 10. This suggests that a holistic approach, leveraging multiple feature categories, is essential for accurate XUCD.
6.3. Classifier Effectiveness
7. Conclusions
- The correlation-based algorithm outperformed the SelectKBest approach for enhancing the accuracy of XUCD results.
- Among the tested classifiers (SVM, LR, and XGB), XGB mostly delivered the highest accuracy results.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Raouf, I.; Lee, H.; Noh, Y.R.; Youn, B.D.; Kim, H.S. Prognostic health management of the robotic strain wave gear reducer based on variable speed of operation: A data-driven via deep learning approach. J. Comput. Des. Eng. 2022, 9, 1775–1788. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, L.; Zheng, Y. Predict pairwise trust based on machine learning in online social networks: A survey. IEEE Access 2018, 6, 51297–51318. [Google Scholar] [CrossRef]
- Credibility, Cambridge Dictionary Entry. Available online: https://dictionary.cambridge.org/dictionary/english/credibility (accessed on 5 March 2023).
- Abbasi, M.-A.; Liu, H. Measuring user credibility in social media. In Proceedings of the Social Computing, Behavioral-Cultural Modeling and Prediction: 6th International Conference, Washington, DC, USA, 2–5 April 2013. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblet, B. Information credibility on twitter. In Proceedings of the Proceedings of the 20th international conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011. [Google Scholar]
- Wijesekara, M.; Ganegoda, G.U. Source credibility analysis on Twitter users. In Proceedings of the 2020 International Research Conference on Smart Computing and Systems Engineering (SCSE), Colombo, Sri Lanka, 24 September 2020; pp. 96–102. [Google Scholar]
- Thaher, T.; Saheb, M.; Turabieh, H.; Chantar, H. Intelligent detection of false information in arabic tweets utilizing hybrid harris hawks based feature selection and machine learning models. Symmetry 2021, 13, 556. [Google Scholar] [CrossRef]
- Setiawan, E.B.; Widyantoro, D.H.; Sur, K. Measuring information credibility in social media using combination of user profile and message content dimensions. Int. J. Electr. Comput. Eng. 2020, 10, 3537. [Google Scholar]
- Geetika, S.; Bhatia, M.P.S. Content based approach to find the credibility of user in social networks: An application of cyberbullying. Int. J. Mach. Learn. Cybern. 2017, 8, 677–689. [Google Scholar]
- Azer, M.; Taha, M.; Zayed, H.H.; Gadallah, M. Credibility Detection on Twitter News Using. I.J. Intell. Syst. Appl. 2021, 3, 1–10. [Google Scholar]
- Kurniati, R.; Widyantoro, D.H. Identification of Twitter user credibility using machine learning. In Proceedings of the 5th International Conference on Instrumentation Communications, Information Technology, and Biomedical Engineering (ICICI-BME), Bandung, Indonesia, 6–7 November 2017. [Google Scholar]
- Alrubaian, M.; Al-Qurishi, M.; Al-Rakhami, M.; Hassan, M.M. Reputation-based credibility analysis of Twitter social network users. Concurr. Comput. Pract. Exp. 2017, 29, 7. [Google Scholar] [CrossRef]
- Afify, E.A.; Eldin, A.S.; Khedr, A.E. Facebook profile credibility detection using machine and deep learning techniques based on user’s sentiment response on status message. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 12. [Google Scholar] [CrossRef]
- Hassan, N.Y.; Gamaa, W.H.; Khoriba, G.A.; Haggag, M.H. Supervised learning approach for twitter credibility detection. In In Proceedings of the 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018. [Google Scholar]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Amin, S.; Uddin, I.; Al-Baity, H.H.; Zeb, A.; Khan, A. Machine learning approach for COVID-19 detection on twitter. Comput. Mater. Contin. 2021, 68, 2231–2247. [Google Scholar]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G. An introduction to logistic regression analysis and reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Liu, B.; Blasch, E.; Chen, Y.; Shen, D.; Chen, G. Scalable sentiment classification for big data analysis using naive bayes classifier. In Proceedings of the IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013. [Google Scholar]
- Webb, G.I.; Keogh, E.; Miikkulainen, R. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 7013–7714. [Google Scholar]
- Mienyea, D.; Sun, Y.; Wang, Z. Prediction performance of improved decision tree-based algorithms: A review. Procedia Manuf. 2019, 35, 698–703. [Google Scholar] [CrossRef]
- Amrani, Y.A.L.; Lazaar, M.; Kadiri, K.E.E.L. Random forest and support vector machine based hybrid approach to sentiment analysis. Procedia Comput. Sci. 2018, 127, 511–520. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Jozdani, S.E.; Johnson, B.A.; Chen, D. Comparing deep neural networks, ensemble classifiers, and support vector machine algorithms for object-based urban land use/land cover classification. Remote Sens. 2019, 11, 1713. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Rais, H.M.; Abdulkadir, S.J.; Mirjalili, S.; Alhussain, H. A review of grey wolf optimizer-based feature selection methods for classification. In Evolutionary Machine Learning Techniques: Algorithms and Applications; Springer: Singapore, 2020; pp. 273–286. [Google Scholar]
- Elavarasan, D.; Vincent, P.M.D.R.; Srinivasan, K.; Chang, C.-Y. A hybrid CFS filter and RF-RFE wrapper-based feature extraction for enhanced agricultural crop yield prediction modeling. Agriculture 2020, 10, 400. [Google Scholar] [CrossRef]
- Gray, B. Collaborating: Finding Common Ground for Multiparty Problems; Jossey-Bass: San Francisco, CA, USA, 1989. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Rahman, M.; Usman, L.; Muniyandi, R.C.; Sahran, S.; Mohamed, S.; Razak, R.A. A review of machine learning methods of feature selection and classification for autism spectrum disorder. Brain Sci. 2020, 10, 949. [Google Scholar] [CrossRef]
- Gary, T. How Feature Selection Techniques for Machine Learning Are Important? Knoldus. 22 February 2022. Available online: https://blog.knoldus.com/how-feature-selection-techniques-for-machine-learning-are-important/ (accessed on 5 January 2023).
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. 2018, 19, 1–6. [Google Scholar] [CrossRef]
- Omuya, E.O.; Okeyo, G.O.; Kimwele, M.W. Feature selection for classification using principal component analysis and information gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- CREDBANK-Data. Github, 10 10 2016. Available online: https://github.com/compsocial/CREDBANK-data (accessed on 11 December 2022).
- FakeNewsNet. Github, 23 9 2021. Available online: https://github.com/KaiDMML/FakeNewsNet (accessed on 5 December 2022).
- ArPFN. Gitlab, 9 9 2022. Available online: https://gitlab.com/bigirqu/ArPFN (accessed on 27 December 2022).
- PHEME_Dataset_of_Rumours_and_Non-Rumours. Figshare, 24 10 2016. Available online: https://figshare.com/articles/dataset/PHEME_dataset_of_rumours_and_non-rumours/4010619 (accessed on 25 December 2022).
- Al-Khalifa, H.S.; Al-Eidan, R.M. An experimental system for measuring the credibility of news content in Twitter. Int. J. Web Inf. Syst. 2011, 7, 130–151. [Google Scholar] [CrossRef]
- Hassan, N.Y.; Gomaa, W.H.; Khoriba, G.A.; Haggag, M.H. Credibility detection in twitter using word n-gram analysis and supervised machine learning techniques. Int. J. Intell. Eng. Syst. 2020, 13, 291–300. [Google Scholar]
- Zhang, R.; Gao, M.; He, X. Learning user credibility for product ranking. Knowl. Inf. Syst. 2016, 46, 679–705. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Fahrurrozi, I.; Fitriyan, N.L.; Tatas, F.; Atmaji, D.; Widodo, T.; Bahiyah, N.; Benes, F.; Rhee, J. Predicting breast cancer from risk factors using SVM and extra-trees-based feature selection method. Computers 2022, 11, 136. [Google Scholar] [CrossRef]
- Wickramarathna, N.C.; Jayasiriwardena, T.D.; Wijesekara, M.; Munasinghe, P.B.; Ganegoda, G.U. A framework to detect twitter platform manipulation and computational propaganda. In Proceedings of the 20th International Conference on Advances in ICT for Emerging Regions (ICTer) IEEE, Colombo, Sri Lanka, 4–7 November 2020. [Google Scholar]
- Murugan, S.N.; Devi, U.G. Feature extraction using LR-PCA hybridization on twitter data and classification accuracy using machine learning algorithms. Clust. Comput. 2019, 22, 13965–13974. [Google Scholar] [CrossRef]
- Varol, O.; Davis, C.A.; Menczer, F.; Flammini, A. Feature engineering for social bot detection. In Feature Engineering for Machine Learning and Data Analytics, 1st ed.; CRC Press: Boca Raton, FL, USA, 2018; pp. 311–334. [Google Scholar] [CrossRef]
- Ahmad, F.; Rizvi, S.A.M. Features Identification for Filtering Credible Content on Twitter Using Machine Learning Techniques. In Proceedings of the Social Networking and Computational Intelligence: Proceedings of SCI-2018, Singapore, 23 March 2020. [Google Scholar]
- Khan, T.; Michalas, A. Seeing and Believing: Evaluating the Trustworthiness of Twitter Users. IEEE Access 2021, 9, 110505–110516. [Google Scholar] [CrossRef]
- Buda, J.; Bolonyai, F. An Ensemble Model Using N-grams and Statistical Features to Identify Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Ali, Z.S.; Al-Ali, A.; Elsayed, T. Detecting Users Prone to Spread Fake News on Arabic Twitter. In Proceedings of the 5th Workshop on Open-Source Arabic Corpora and Processing Tools with Shared Tasks on Qur’an QA and Fine-Grained Hate Speech Detection, Marseille, France, 20 June 2022. [Google Scholar]
- Abu-Salih, B.; Chan, K.Y.; Al-Kadi, O.; Al-Tawil, M.; Wongthongtham, P.; Issa, T.; Saadeh, H.; Al-Hassan, M.; Bremie, B.; Albahlal, A. Time-aware domain-based social influence prediction. J. Big Data 2020, 7, 1–37. [Google Scholar] [CrossRef]
- Jain, P.K.; Pamula, R.; Ansari, S. A supervised machine learning approach for the credibility assessment of user-generated content. Wirel. Pers. Commun. 2021, 118, 2469–2485. [Google Scholar] [CrossRef]
- Raj, E.D.; Babu, L.D. RAN enhanced trust prediction strategy for online social networks using probabilistic reputation features. Neurocomputing 2017, 219, 412–421. [Google Scholar] [CrossRef]
- Hamdi, T.; Slimi, H.; Bounhas, I.; Slimani, Y. A hybrid approach for fake news detection in twitter based on user features and graph embedding. In Proceedings of the Distributed Computing and Internet Technology: 16th International Conference, ICDCIT, Bhubaneswar, India, 9–12 January 2020. [Google Scholar]
- Sharma, U.; Kumar, S. Feature-based comparative study of machine learning algorithms for credibility analysis of online social media content. In Proceedings of the Data Engineering for Smart Systems: Proceedings of SSIC, Singapore, 22–23 January 2021. [Google Scholar]
- Saeed, U.; Fahim, H.; Shirazi, F. Profiling Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Verma, P.K.; Agrawal, P.; Madaan, V.; Gupta, C. UCred: Fusion of machine learning and deep learning methods for user credibility on social media. Soc. Netw. Anal. Min. 2022, 12, 54. [Google Scholar] [CrossRef]
- Raouf, I.; Lee, H.; Kim, H.S. Mechanical fault detection based on machine learning for robotic RV reducer using electrical current signature analysis: A data-driven approach. J. Comput. Des. Eng. 2022, 9, 417–433. [Google Scholar] [CrossRef]
- Bahassine, S.; Madani, A.; Al-Sarem, M.; Kissi, M. Feature selection using an improved Chi-square for Arabic text classification. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 225–231. [Google Scholar] [CrossRef]
- Al-Zoubi, M.; Alqatawna, J.; Faris, H.; Hassonah, M.A. Spam profiles detection on social networks using computational intelligence methods: The effect of the lingual context. J. Inf. Sci. 2021, 47, 58–81. [Google Scholar] [CrossRef]
- Sharaff, A.; Gupta, H. Extra-tree classifier with metaheuristics approach for email classification. In Proceedings of the Advances in Computer Communication and Computational Sciences: Proceedings of IC4S 2018, Singapore, 20–21 October 2018. [Google Scholar]
- Karakaşlı, M.S.; Aydin, M.A.; Yarkan, S.; Boyaci, A. Dynamic feature selection for spam detection in Twitter. In Proceedings of the International Telecommunications Conference: Proceedings of the ITelCon, Istanbul, Turkey, 28–29 December 2017. [Google Scholar]
- Jayashree, P.; Laila, K.; Kumar, K.S.; Udayavannan, A. Social Network Mining for Predicting Users’ Credibility with Optimal Feature Selection. In Intelligent Sustainable Systems: Proceedings of ICISS; Springer: Singapore, 2021. [Google Scholar]
- Kamkarhaghighi, M.; Chepurna, I.; Aghababaei, S.; Makrehchi, M. Discovering credible Twitter users in stock market domain. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI), Omaha, NE, USA, 13–16 October 2016. [Google Scholar]
- Gayakwad, M.; Patil, S.; Kadam, A.; Joshi, S.; Kotecha, K.; Joshi, R.; Pandya, S.; Gonge, S.; Rathod, S.; Kadam, K.; et al. Credibility analysis of user-designed content using machine learning techniques. Appl. Syst. Innov. 2022, 5, 43. [Google Scholar] [CrossRef]
- Maria, G.H.; Aguilera, A.; Dongo, I.; Cornejo-Lupa, J.M.; Cardinale, Y. Credibility Analysis on Twitter Considering Topic Detection. Appl. Sci. (Work. Notes) 2022, 12, 9081. [Google Scholar]
- Kang, Z.; Xing, L.; Wu, H. S3UCA: Soft-Margin Support Vector Machine-Based Social Network User Credibility Assessment Method. Mob. Inf. Syst. 2021, 2021, 7993144. [Google Scholar]
- Espinosa, M.S.; Centeno, R.; Rodrigo, Á. Analyzing User Profiles for Detection of Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Duan, X.; Naghizade, E.; Spina, D.; Zhang, X. RMIT at PAN-CLEF 2020: Profiling Fake News Spreaders on Twitter. In Proceedings of the CLEF, Thessaloniki, Greece, 22–25 September 2020. [Google Scholar]
- Iftikhar, A.; Muhammad, Y.; Suhail, Y.; Ovais, M. Fake news detection using machine learning ensemble methods. Complexity 2020, 2020, 8885861. [Google Scholar]
- Sabeeh, V.; Zohdy, M.; Mollah, A.; Al Bashaireh, R. Fake news detection on social media using deep learning and semantic knowledge sources. Int. J. Comput. Sci. Inf. Secur. (IJCSIS) 2020, 15, 45–68. [Google Scholar]
- Dongo, I.; Cardinale, Y.; Aguilera, A. Credibility analysis for available information sources on the web: A review and a contribution. In Proceedings of the 4th International Conference on System Reliability and Safety (ICSRS), Rome, Italy, 20–22 November 2019. [Google Scholar]
- Etaiwi, W.; Awajan, A. The effects of features selection methods on spam review detection performance. In Proceedings of the International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | Size | # Of Features | Feature Types | Labels | |||
|---|---|---|---|---|---|---|---|---|
| Content-Based | User-Based | Interaction-Based | Sentiment-Based | |||||
| CredBank [32] | Real-world events | 1300 events 80 M tweets | 4 | √ |
| |||
| FakeNewsNet [33] | Tweets from two domains: politics and entertainment and the corresponding images | 510 users | 16 | √ | √ | √ |
| |
| ArPFN [34] | Arabic tweets including articles related to politics, health, and other topics. | 1546 users | 39 | √ | √ | √ | √ |
|
| PHEME [35] | Tweets related to five breaking news stories | 5802 tweets | 5 | √ | √ |
| ||
| Ref | Year | Purpose | Classifier | Selection | Data Categories | Performance |
|---|---|---|---|---|---|---|
| [61] | 2022 | Content credibility | ensemble regression algorithm | - | - | 96.29% by Ensemble model |
| [59] | 2022 | Spam detection | DT, SVM, RF | √ | √ | 93% by All features and RF |
| [62] | 2022 | Content credibility | KMEANS, LSI, NMF, LDA | - | - | 74% by NMF |
| [53] | 2022 | User credibility | RoBERT, Bi-LSTM, RF | - | - | 98.96% |
| [51] | 2022 | Content credibility | DT, KNN, RF, SVM | √ | - | Best improvement after Feature Selection with DT approximately 21% |
| [46] | 2022 | User credibility | XGB, RF, LR, NN | - | √ | 79% by All features and XGB |
| [10] | 2021 | Content credibility | NB, SVM, KNN, LR, RF, ME, CRF | √ | √ | 83.4% by All features and RF |
| [63] | 2021 | User credibility | SVM | - | - | 93.5% |
| [56] | 2021 | Spam detection | KNN, RF, NB, DT, MLP | √ | - | An average of 97.1% by KNN |
| [48] | 2021 | Spam detection | DT, SVM, KNN, LR, AdaBoost, NB | - | - | 88% by LR |
| [7] | 2021 | Content credibility | RF, SVM, LR, DT, XGB, KNN, NB, LDA | √ | √ | 77% by All features and LR |
| [44] | 2021 | User credibility | RF, MLP, SVM, LR | √ | - | 96% by RF |
| [64] | 2020 | User credibility | LR, KNN, RF, DT, SVM | - | √ | 68% by All features and DT |
| [65] | 2020 | User credibility | SVM, LR, RF | - | √ | 72% by All features and SVM |
| [66] | 2020 | Content credibility | LR, SVM, MLP, KNN, DT, LSVM, XGB, AdaBoost | - | - | On average, individual learners achieved an accuracy of 85%, but ensemble learners achieved an accuracy of 88.16% |
| [67] | 2020 | Content credibility | RNN | √ | - | 97% |
| [52] | 2020 | User credibility | LR, SVM, DT, MLP, KNN LSTM, Bi-LSTM | - | - | 70% |
| [8] | 2020 | Content credibility | NB, SVM, LR, DT | - | √ | 88.4% by All features and DT |
| [50] | 2020 | User credibility | DT, RF, KNN, Bayes, QDA, SVM, LR, LDA | √ | √ | 98% by All features and LDA |
| [49] | 2020 | User credibility | LR, SVM, RF, XGB | - | - | 77.75% by ensemble model |
| [47] | 2020 | User credibility | NB, LR, DT, RF, XGB, GLM | - | - | GLM achieves the best results |
| [43] | 2020 | Content credibility | RF, NB, SVM | √ | √ | 97.7% by RF |
| [6] | 2020 | User credibility | NB, DT, SVM, KNN | - | - | 68% by SVM |
| [40] | 2020 | User credibility | SVM, N, DT | - | - | 68% by SVM |
| [37] | 2020 | User credibility | SVM, LR, RF, NB, KNN | - | √ | 84.9% |
| [55] | 2020 | Content credibility | DT, NB, SVM | √ | - | 85.29% by SVM with Chi-square feature selection |
| [13] | 2020 | User credibility | DT, RF, LR, KNN, NB, SVM, NN | √ | - | 94% by NN |
| [68] | 2019 | Content credibility | - | - | - | - |
| [58] | 2019 | Spam detection | KNN, SVM | √ | - | 87.6% by KNN |
| [41] | 2019 | Spam detection | RF, DT, BN, KNN, SVM | √ | - | 91.2% RF |
| [14] | 2018 | Content credibility | SVM, LR, RF, KNN, NB | - | √ | 78.4% by All features and RF |
| [11] | 2017 | User credibility | LR, SVM, NB, RF, NN | - | √ | 78.42% by All features and NN |
| [69] | 2017 | Spam detection | SVM, DT, NB, RF | √ | - | 64.84% by NB |
| [12] | 2017 | User credibility | NB, LR | - | - | 82.91% |
| [38] | 2015 | User credibility | SVM, NB | - | √ | 90.8% by Base + Emotion features |
| [4] | 2013 | User credibility | CredRank algorithm | - | - | - |
| [5] | 2011 | Content credibility | SVM, DT, DR, NB | - | √ | 86% by All features and DT |
| Feature Type | Number of Features | Description |
|---|---|---|
| Profile Features | 17 | Includes features found in the user profile such as the user’s identifier, verification status, follower and following counters, and the frequency of the user’s tweets. |
| Emotional Features | 11 | Emotional signals were extracted from the text of each user’s recent 100 tweets. These include anger, anticipation, disgust, fear, joy, love, optimism, pessimism, sadness, surprise, and trust. |
| Statistical Features | 11 | This category of features is derived from users’ recent 3200 tweets. It includes features that describe the users’ impact and activities, which include the ratio of user tweets that contain hashtags, the average number of hashtags per tweet, the ratio of user tweets that are replies, the ratio of user tweets that contain URLs or media such as images or videos, and the number of tweets that are retweets. |
| Dataset Category | Accuracy of All Features | Accuracy of Selected Features | |
|---|---|---|---|
| Correlation | Select K-Best | ||
| Profile Features | 0.526 | 0.630 | 0.622 |
| Emotional Features | 0.505 | 0.624 | 0.603 |
| Statistical Features | 0.501 | 0.665 | 0.603 |
| Profile and Emotional Features | 0.530 | 0.657 | 0.620 |
| Profile and Statistical Features | 0.543 | 0.665 | 0.630 |
| Emotional and Statistical Features | 0.522 | 0.638 | 0.616 |
| Profile, Emotional, and Statistical Features (all) | 0.523 | 0.723 | 0.671 |
| Dataset Category | Accuracy | F1_Score | Recall | Precision | |
|---|---|---|---|---|---|
| XGB | Profile Features | 0.526 | 0.346 | 0.356 | 0.336 |
| Emotional Features | 0.505 | 0.345 | 0.355 | 0.325 | |
| Statistical Features | 0.501 | 0.331 | 0.361 | 0.311 | |
| Profile and Emotional | 0.530 | 0.300 | 0.290 | 0.320 | |
| Profile and Statistical | 0.543 | 0.333 | 0.333 | 0.343 | |
| Emotional and Statistical | 0.522 | 0.312 | 0.302 | 0.332 | |
| Profile, Emotional, and Statistical | 0.523 | 0.333 | 0.333 | 0.343 | |
| SVM | Profile Features | 0.526 | 0.506 | 0.526 | 0.526 |
| Emotional Features | 0.465 | 0.455 | 0.465 | 0.475 | |
| Statistical Features | 0.481 | 0.471 | 0.481 | 0.481 | |
| Profile and Emotional | 0.530 | 0.530 | 0.530 | 0.530 | |
| Profile and Statistical | 0.513 | 0.503 | 0.513 | 0.513 | |
| Emotional and Statistical | 0.452 | 0.452 | 0.452 | 0.462 | |
| Profile, Emotional, and Statistical | 0.443 | 0.443 | 0.443 | 0.443 | |
| LR | Profile Features | 0.526 | 0.526 | 0.526 | 0.526 |
| Emotional Features | 0.515 | 0.515 | 0.515 | 0.515 | |
| Statistical Features | 0.431 | 0.431 | 0.431 | 0.431 | |
| Profile and Emotional | 0.540 | 0.540 | 0.540 | 0.540 | |
| Profile and Statistical | 0.493 | 0.493 | 0.493 | 0.493 | |
| Emotional and Statistical | 0.452 | 0.452 | 0.452 | 0.452 | |
| Profile, Emotional, and Statistical | 0.483 | 0.483 | 0.483 | 0.483 |
| Dataset Category | XGB | SVM | LR |
|---|---|---|---|
| Profile Features | 0.526 | 0.526 | 0.526 |
| Emotional Features | 0.505 | 0.465 | 0.515 |
| Statistical Features | 0.501 | 0.481 | 0.431 |
| Profile and Emotional Features | 0.530 | 0.530 | 0.540 |
| Profile and Statistical Features | 0.543 | 0.513 | 0.493 |
| Emotional and Statistical Features | 0.522 | 0.452 | 0.452 |
| Profile, Emotional, and Statistical Features (all) | 0.523 | 0.443 | 0.483 |
| Average | 0.521 | 0.487 | 0.491 |
| Range | 0.042 | 0.087 | 0.109 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abid-Althaqafi, N.R.; Alsalamah, H.A. The Effect of Feature Selection on the Accuracy of X-Platform User Credibility Detection with Supervised Machine Learning. Electronics 2024, 13, 205. https://doi.org/10.3390/electronics13010205
Abid-Althaqafi NR, Alsalamah HA. The Effect of Feature Selection on the Accuracy of X-Platform User Credibility Detection with Supervised Machine Learning. Electronics. 2024; 13(1):205. https://doi.org/10.3390/electronics13010205
Chicago/Turabian StyleAbid-Althaqafi, Nahid R., and Hessah A. Alsalamah. 2024. "The Effect of Feature Selection on the Accuracy of X-Platform User Credibility Detection with Supervised Machine Learning" Electronics 13, no. 1: 205. https://doi.org/10.3390/electronics13010205