Abstract
With the increase in the amount of images online, the whole Internet is becoming an image database. Since there are so many available images, it is difficult for users to find the desired images. Unlike text search engines, image search engines cannot fully recognize the visual meaning of an image. In addition, it is difficult to obtain the desired images from the keywords provided by the user, since a keyword may contain multiple meanings. To solve these problems, this paper proposes a psychological intention diagram of past users, if inquiring using a keyword, to predict the images that these users want. Based upon the novel psychological diagram, this paper proposes a search engine that analyzes images in the sequential probing of the current user if he/she inquires after the same keywords as previous users. Moreover, this paper also constructs a psychological intention diagram of the designers of the web pages containing the keyword. This type of psychological intention diagram is used when a query is not issued by past users. To the best of our knowledge, this paper is the first one considering the psychological viewpoint of users and web designers in guiding the retrieval of the search engine. The experimental results show that the proposed image search engine has high precision; therefore, the method of providing images can help users to find their desired image more easily.
1. Introduction
Since the amount of information is rapidly increasing and the bandwidth is widening considerably, websites are starting to embed many images into their web pages to vividly describe the topics of the web pages and attract readers’ attention. The whole Internet is becoming a huge image database [1,2,3,4]. Since there are so many images on the Internet, it is difficult for users to find their desired images. Recently, many popular search engines, such as Yahoo!, Google, and Baidu, have provided users with the service of an image search [1,5,6,7].
Unlike text search engines, an image search engine is incapable of fully recognizing the visual meaning of images. In addition, it cannot find the desired images for the keywords provided by users, since a keyword may convey multiple meanings [7,8,9]. For example, when the keyword “apple” is queried to Google’s image service (called Google Images in this paper), this search engine may reply with a variety of topics, such as apple fruit, apple tree, or Apple computer and its products, as shown in Figure 1. Since the term “apple” is polysemous, the image search engine may not correctly guess the intention of the user. For a user intending to search for an Apple computer, the user may be hampered by results for edible apples supplied by the image search engine [9,10]. To solve these problems, many strategies involving image search results clustering (ISRC) are proposed [11,12]. Most of the strategies use image analyses and text mining to derive the characteristics of the images in the retrieved web pages. The characteristics of images can be the distribution of color blocks or the semantics of the context and related text surrounding the images. With these characteristics, ISRC strategies can cluster the images into several clusters and then display them to users for easy browsing.

Figure 1.
Results after querying the keyword “apple” in Google Images.
The Gaussian mixture model (GMM), adopted by most ISRC strategies, is a method that analyzes the visual characteristics of images. The method considers the distribution of color blocks of an image as a category model [11,13,14,15]. Although GMM is efficient in analyzing the visual characteristics of images, this method lacks the ability to capture the meaning of words.
To remedy this insufficiency, most ISRC strategies also perform text mining upon the context surrounding the images, to capture the semantics of the images. The key phrases derived from the context are used as criteria to cluster the images, so that a set of images with similar semantic meanings can be clustered together [2,11,16]. Although text mining can capture the semantics of images, the clustering of images still cannot describe the content of images. For instance, when a user searches for images on the Internet with the keyword “apple fruit”, they may receive many images of apple fruit, including red apples, green apples, apple juice, and apple trees. Not all of these exactly match the requirements of the user. Therefore, the user needs to provide more information to reveal their intentions regarding the images. In addition, there are some inherent problems in text mining, such as the problems of polysemy and synonyms, which may lead to undesired results. For example, when a user queries the keyword “Pluto”, the image replies could include a planet in the solar system or a Disney figure. These two image sets would both match this keyword if no further information is provided. Another example is that “gift” is a synonym of “present”. Assume that a user intends to search for images related to the keyword “present”. The image search engine will not offer images related to “gift” if the search engine cannot identify all the synonyms of the keyword.
To solve these problems, some image search engines use the ontology to extend keywords when searching for the desired images. These extended keywords can retrieve a large number of images containing synonyms that are related to the keyword. However, the ontology of a keyword encompasses the psychological world of the public, which does not always match the psychological world of the user who queries the keyword for images. Thus, an image search engine with augmented keywords, obtained by exploring the ontology, returns abundant results but has low precision. To increase the precision of an image search engine, it is important to guess the user’s intention while querying the keywords. Thus, this paper proposes an image search engine equipped with the ability to guess the intentions of users, to increase the precision of the search results.
Generally, users input a short or vague keyword, since they are unmotivated to type or unfamiliar with the topic that they are searching. Thus, some image search engines provide an interactive searching method so that a user can click (select) one of the replied images, and then the search engine replies with another set of images related to the clicked image in the next interactive turn [17]. The user can sequentially (backward and forward) browse these images until they find their desired images or give up the search. Clearly, the sequential probes into the replied images can reveal the psychological world (or intention) of the user, as this is an important clue when searching for the desired images. However, most of the current image search engines ignore such clues, meaning that the precision of the search results is low. This paper analyzes key phases associated with images in the sequential probing of previous users and proposes a psychological intention diagram of the users (PIDU) regarding their keywords. With PIDUs, the proposed search engine can narrow down the scope of potential images using the viewpoint of past users.
Text search engines utilize the concepts of authority and hubs to find the related web pages for a keyword. The authority (hub) of a page counts the number of other important pages pointing to (being pointed by) this page. The concepts of authority and hubs are widely adopted by text search engines, but these concepts cannot be directly applied to image search engines since an image has no links pointing to or being pointed by other images. The psychological intention of the designers of web pages is another clue that might be helpful in finding the desired images. It is believed that when website designers build a website, they always arrange the information, web links and images that are related to the topics of their web pages [18,19].
This paper proposes a novel concept from the perspective of user intentions. The paper constructs a psychological intention diagram of past users (PIDU) and the intention of the designer of the web page (PIDD), both of which consist of key phases pertaining to the images in a web page and links in the web page pointing to other web pages. The PIDU can be considered a collaborative filtering strategy [20,21,22] that is used in the retrieval of images, guided by past users, while PIDD can be considered an editorially curated plan recommended by the authors of a web page [23]. Rather than augmenting the keyword via a complicated ontology, PIDD and PIDU can guide the search engine from the user’s currently viewed image to other potential images from the viewpoint of past users and web designers. The novelty of this paper is that it is the first to construct the PIDU and PIDD to guess the intentions of users and then increase the precision of the search engine.
The paper presents a number of experiments, which show that the proposed image search engine has much higher precision than others, especially for polysemous keywords. The organization of the paper is as follows. Section 2 introduces previous ISRC strategies and user intentions. Section 3 describes the proposed image search engine. In Section 4, the paper presents sets of experiments that aimed to measure the precision of the proposed system. Finally, Section 5 provides the conclusions.
2. Literature Review
2.1. Image Visual Analyses
Due to the prevalence of cameras, taking pictures and sharing them online are common daily activities for many people. An object’s images may have different visual effects if the object is composed of different textures or materials. In Figure 2, all the images are of the apple fruit, but they have a variety of visual effects due to their different materials and textures.

Figure 2.
Three images of an apple, which look different due to their different materials and textures.
The Gaussian mixture model (GMM) method is a well-known method focusing on the distribution of colors. GMM analyzes the visual characteristics of an image and then creates a category model consisting of a set of homogeneous color regions that represent the image [13,14,15,24]. For a new image, GMM creates a new category model and compares it with the existing category models to find the model that is most similar to the new one. If the measure of the similarity between the new model and the most similar one is no larger than a given threshold, the new model is grouped into the cluster of the most similar category models. Otherwise, this new model is regarded as a new category and stored in the database for the comparison of later images.
GMM clusters the images according to their color distribution, so the user can smoothly browse a set of images that have a similar color distribution. Another advantage of GMM is that the clustering of images is very fast, since GMM only compares the differences between the new image and the existing models, rather than comparing the new image with all other images. Its disadvantage is that it only represents the images at the syntax level (i.e., color, space), since understanding the semantic meaning of images directly from the images is rather difficult.
2.2. Image Semantic Analyses
Generally, the text surrounding images unveils relevant information about the semantic meaning of images [25,26], so the image search engine often retrieves the text surrounding the image to capture the semantics of the image. In the study [27], they mainly analyzed the tags, attributes written in HTML, and the texts surrounding the images to find the semantics of the images. Since the related texts were too abundant, they attempted to use 10 terms, 20 terms, 40 terms, or even the entire text from the web page as the annotation of the image contained in the web page. Clearly, not all the retrieved information is relevant to the semantics of an image. Their method first filtered the advertisements and banners by their characteristics, such as their positions (i.e., near the boundary of the web page) and their specific lengths (like a pixel or a long stripe). Then, the method performed language processing on the retrieved information. The language processing segmented the sentences to obtain meaningful phrases by locating stop words (such as prepositions and conjunctions), and it evaluated the importance of the phrases with several factors. For example, the visual effect of the phrases, such as the colors, font size, bold text, and hyperlinks in the phrase, can suggest the importance of a phrase. The length of the phrase is the second factor. Generally, the longer the phrase, the more important the phrase will be. The reason for this is that a web designer will not use a longer phrase unless the longer phrase is needed for the image. The third factor is the weight of the phrase. To obtain the weight, their method first calculated the frequency of the phrase occurring in a paragraph, and then multiplied it by the given value of the phrase. The value of a phrase is provided in a heuristic way; for example, a noun phrase is more suitable to describe an image than a verb phrase, so their method assigned a higher value to noun phrases than verb phrases.
Clearly, the annotations of an image are a clue as to whether the image is related to the keyword queried by a user. For example, the annotations in a remote sensor image are the most important way to identify the objects in the images [28,29,30]; the more accurate the annotation, the higher the precision of the search. However, the annotations cannot solve the problems of polysemy and the synonyms of a keyword. The solution may be to guess what the users desire from their querying behaviors.
2.3. User Intention
To increase the precision of text search engines, many studies [31] have incorporated the concept of user intention to guess the psychological intentions of users when they surf the web. Some studies have utilized relevant feedback from users to guess their intentions. The relevant feedback can be divided into two types, i.e., explicit and implicit feedback. To obtain the relevance of a web page that is explicitly indicated by a user, the text search engine first returns a set of paged results, each of which is associated with a checkbox. The user judges the results by ticking the check boxes to confirm which results are related to the keyword. Through collecting explicit feedback from users, the text search engine can understand what most users prefer to view with respect to a keyword. Since explicit feedback requires additional actions from users, the text search engine can only obtain a small portion of feedback from some users. To solve this problem, most studies have focused on implicit feedback instead [18,32,33]. They use the potential behaviors of users during their surfing on the web, including the clicking of documents in the received results, scrolling down a text, bookmarking of pages, printing a page, and the time that users spend on a page.
Although explicit or implicit feedback can reveal the relevance of the relationship between a web page and a keyword, the information from the relevance feedback is not appreciated in text search engines since text search engines overwhelmingly use other information, like the authority and hub, to rank the importance of web pages [18,34,35]. However, the authority and hub concepts cannot be directly applied to image search engines. One reason for this is that a web page may contain many different images scattered across the web page to reinforce different issues discussed on the web page; a web page with high authority for a keyword does not imply that all the images contained in that page pertain to the keyword. The other reason is that, as an image has no links pointing to other images, the hub concept cannot be applied to image ranking. The previous method only recorded the number of times that the images were clicked with respect to a keyword. The more frequently an image is clicked for a specific keyword, the more importance for the keyword is associated with the image. When a new user queries a keyword, the image with more importance for the keyword will be prompted first. However, returning all the images related to the keyword at once is inappropriate for the image search engine, since the presentation of a large number of images may confuse the user. Thus, some image search engines provide an interactive way to browse the results. Clearly, during the processes by which users interact with the system, the psychological intentions of the users are gradually revealed, and the search engine can narrow down the scope of potential images step by step. However, the existing image search engines, as far as we know, do not record the surfing paths of past users, which is an important clue when searching for potential images for new users. The proposed image search engine records the paths of users as user intention diagrams. These diagrams and the web designer intention diagrams (discussed later) are used as guides in the proposed image search engine to search for the desired images.
3. Proposed Image Search Engine
Web page designers build a web page to share their ideas or knowledge with other users. To furnish and enhance their expression, the designers often arrange several images near suitable paragraphs to clearly delineate the topics of the paragraphs. Modern text-based image search engines, such as Google Image Search, Alta Vista Image Search, and Flickr, are widely used. Such a text-based image search engine faces the problem that, with respect to an input query, it returns an uncategorized list of images based on keyword matching algorithms; the confusion becomes severe, especially when the keyword has multiple meanings, like apple, bank, etc. The iteration of interactions between the user and search engine becomes the most promising solution for the search engine to guess the intentions of the user.
Compared to some semantic-based image retrieval methods that utilize semantic annotations surrounding the images and adopt the ontology technique to build up the semantic database, the proposed search engine, with the help of PIDD, has the advantage that the workload is light in comparison to annotating the images and building an ontology to recognize the semantic meanings of images.
3.1. Psychological Intention Diagram of the Page Designer
In general, the material that the designers are most concerned about is displayed in the context of a paragraph, while the minor material is placed as a reference pointing to other pages via links in the context of the paragraph. The psychology of web page designers of other web sites is similar; they also display the major materials in the context of their paragraphs and the minor materials as references. Thus, all the images in a paragraph and the paragraph’s propagations to other images can reveal the degree of importance of these images from the viewpoint of web page designers. Although the images have no links pointing to each other, the linking relationship mentioned previously can reveal the semantic relationships amongst the images. The proposed method stores the image relationships on the Internet as a set of tree structures, called the psychological intention diagrams of web page designers (PIDD), where each PIDD is a two-level tree. The root node denotes the image set contained in a paragraph of a web page, and the leaf nodes denote the image sets contained in the other web pages that are pointed to by the web page of the root node.
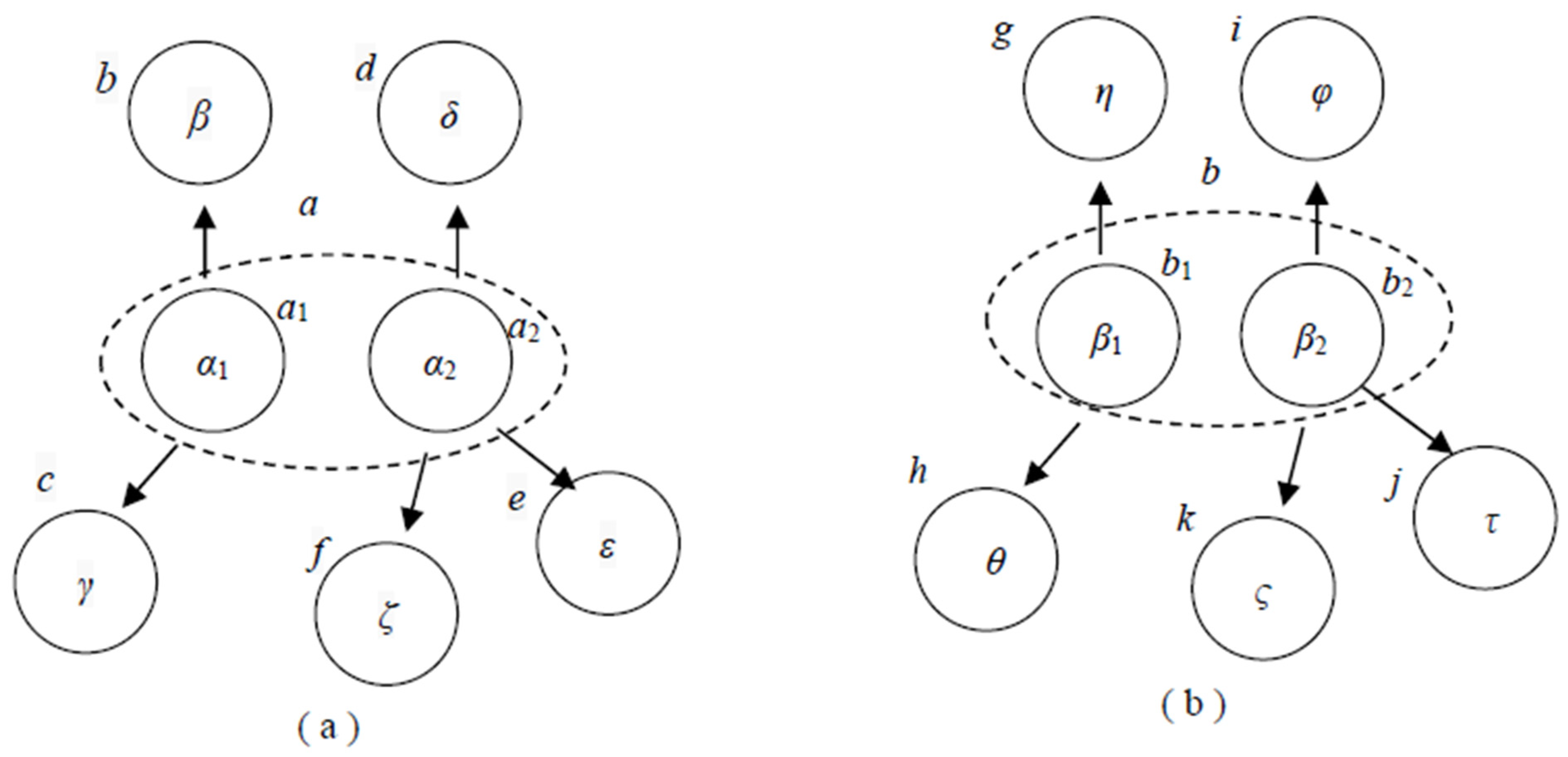
Example 1: Suppose that there is a web page A with the following assumptions: (1) all the images contained in web page A are collected as an image set α; web page A has only two paragraphs, AP1 and AP2, containing images, and the images contained in these two paragraphs are image sets α1 and α2, where α1 α, α2 α, and α1α2 = α; (2) paragraph AP1 has links pointing to two web pages, B and C, that contain image sets β and γ, respectively; (3) paragraph AP2 has links pointing to three other web pages, D, E, and F, that contain image sets δ, ε, and ζ, respectively. Figure 3a shows the two PIDDs for the above scenario, where the two root nodes a1 and a2 denote the two image sets α1 and α2, which reside in the two paragraphs AP1 and AP2 of web page A, respectively; the leaf nodes b, c, d, e, and f denote image sets β, γ, δ, ε, and ζ, respectively, residing in web pages B, C, D, E, and F; the dashed line circling the two root nodes (annotated as a) denotes that the two corresponding image sets α1 and α2 both reside in the same web page, A. From the two PIDDs in Figure 3a, we can reasonably suppose that the designer of web page A felt that image set α1 contained something related to image sets β and γ, and that image set α2 also contained something related to image sets δ, ε, and ζ. Thus, while a user selects an image in image set α1, for instance, for a keyword, there is a high probability that image sets α2, β, and γ will be browsed by the user in their next turn due to the link relationship shown in Figure 3a.
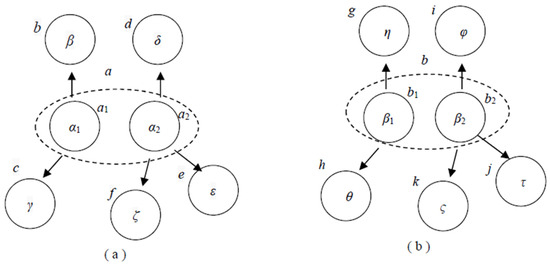
Figure 3.
PIDDs for web pages. In (a), two PIDDs show the image of two paragraphs in web page A to construct the image relationship among the images in the paragraphs; in (b), there are the two PIDDs obtained through analyzing the paragraph relationships in web pages B and C to construct the image relationships.
Note that the proposed search engine uses a PIDD consisting of only two levels of nodes. There is no need to store a larger PIDD consisting of more than two levels of nodes in the proposed search engine. The reason for this is that, after a user selects one of the images returned by the search engine in an interactive searching way, the proposed search takes its turn to suggest the next potential images that reside in the immediate child nodes of the PIDD with the root node containing the image selected by the user. The next example illustrates how the proposed search engine suggests potential images to a user if the user selects one image that resides in the immediate child node of a PIDD.
Example 2 (continuing from Example 1): We further assume that (1) web page B has only two paragraphs, BP1 and BP2, containing images, and the images in these two paragraphs are image sets β1 and β2, where image sets β1 β, β2 β, and β1β2 = β; (2) paragraph BP1 has links pointing to two web pages, G and H, that contain image sets η and θ, respectively; (3) paragraph BP2 has links pointing to three other web pages, I, J, and K, that contain image sets φ, τ, and ς, respectively. Figure 3b shows the two PIDDs with respect to image sets β1 and β2 of web page B, where the two root nodes b1 and b2 of the two PIDDs denote two image sets β1 and β2, which reside in paragraphs BP1 and BP2, respectively; the leaf nodes g, h, i, j, and k denote the image sets η, θ, φ, τ, and ς, respectively, residing in web page B; the dashed line circling nodes b1 and b2 (annotated as b) denotes the two image sets β1 and β2, residing within the same web page B. Assume that a user selects an image in image set α1 of web page A for a keyword. The proposed search engine will check the roots of all PIDDs and find the PIDD whose root node is set as α1. The search engine then suggests to the user the other images in set α1, all the images in set α2 that is contained in a sibling node of the root node, and all the images in sets β and γ that are contained in child nodes b and c. Assume that the user selects one image in image set β1; then, the proposed search engine will suggest to the user the other images in set β1, all images in set β2 that are contained in the sibling node of the root node, and all the images in sets η and θ that are contained in child nodes g and h.
PIDDs for keywords are constructed beforehand (i.e., offline). The search engine first collects a number of keywords that may be queried by users. Since the web space is huge, the proposed image search engine, similar to that in the studies [11,36,37], is built upon the global searching ability of Google Images. The proposed search engine first queries Google Images for the keywords individually (by calling subroutine Get_seed_image in Figure 4a). For each keyword, the search engine collects the top-N images presented by Google Images and uses these images as the seed images, where the value of N is in the range from 20 to 40. Then, the proposed search engine pushes each of their web addresses and the value 0 (the distance from the seed image), as a pair, into a stack. Afterward, the search engine starts to traverse the links of the web pages containing the seed images within a limited depth in a depth-first way (by calling subroutine Construct_Image_DB&PIDD in Figure 4a) to construct the image database and the PIDDs for the keyword, as is described in the following.


Figure 4.
The steps to construct the psychological intention diagram of web page designer. The algorithm for obtaining seed images from Google Images is shown in (a); the algorithm for constructing PIDD is shown in (b).
First, the proposed search engine checks whether the stack is empty (step 1 in Figure 4b). If it is empty, this means that all the images related to the keyword have been checked. The search for the potential images for the keyword stops. Otherwise, a pair of variables, webAdd and depth, which is the web address of the image to be processed and its depth away from the seed image, are popped from the stack and processed (line 2 in Figure 4b). If the popped address exists in the image database, the proposed search engine skips the construction of the image database and PIDD with respect to this popped address and pops the next pair from the stack. Otherwise, the search engine retrieves the surrounding paragraph, denoted as SPR, of this image and all the other images contained in paragraph SPR. The irrelevant images in paragraph SPR, such as banners, will be filtered. The proposed search engine then extracts the important phrases from this paragraph. Afterward, the search engine creates a PIDD with the root node containing the filtered image set and sets the extracted important phrases as the annotations for this image set. In addition, the images in the filtered image set are inserted into the image database with the above important phrases as their annotations (lines 7–9 in Figure 4b). The search engine then starts to retrieve the images in the web pages provided by the links in paragraph SPR. The search engine also needs to filter the images, and then groups them into different image sets according to the paragraphs in which they reside. The important phrases are extracted from the above paragraphs and are used as annotations for the corresponding image set. If the similarity between this new annotation and the annotation of the image set in the root node is beyond a given threshold, this means that the new image set is unrelated to the image set in the root node. This new image set is then discarded (lines 18–19 in Figure 4b); otherwise, the new image set is stored as the leaf node of the PIDD and the value of the variable depth is increased by one (lines 20–21 in Figure 4b). If the new value of the variable depth is smaller than the maximal allowable distance (i.e., the value of the variable max_depth) away from the seed image, the web address of the paragraph in which the new image set resides and the new value of the variable depth are pushed as a pair into the stack for the later while-loop to create another new PIDD; otherwise, the search engine stops the drill-down for more images from the current paragraph.
3.2. Psychological Intention Diagram of Past Users
In addition to the psychological intention of the web page designer, this paper also utilizes the psychological intentions of past users. It is believed that if a user is browsing an image for the same keyword as some previous users, the next images browsed by these users may be the desired image of the current user. Thus, for each keyword, the paper constructs a psychological intention diagram of past users (PIDU), which records the surfing paths of past users for the keyword to guess the desired images of a new user.
The PIDU is a tree structure in which each node denotes an image that some previous users have browsed; the link between two nodes is a directed one if some users browse the corresponding image of the source node and then browse the corresponding image of the sink node, and the width of the link is used to count the users who sequentially browse the two corresponding images of the two nodes. The PIDU for a keyword initially contains a dummy root node to connect all the surfing paths of past users. The surfing paths are first decomposed into segments consisting of two sequentially surfed images, and then these two-node segments are inserted into the PIDU individually. If a segment does not yet exist in the PIDU, the segment will be appended to the dummy root node and the widths of the two links; namely, the link between the dummy root node and the segment and the link of the segment itself are set as one unit; otherwise (i.e., in the segment existing in the PIDU), the widths of the above two links are increased by one unit only. The next examples illustrate the construction and usage of the PIDU.
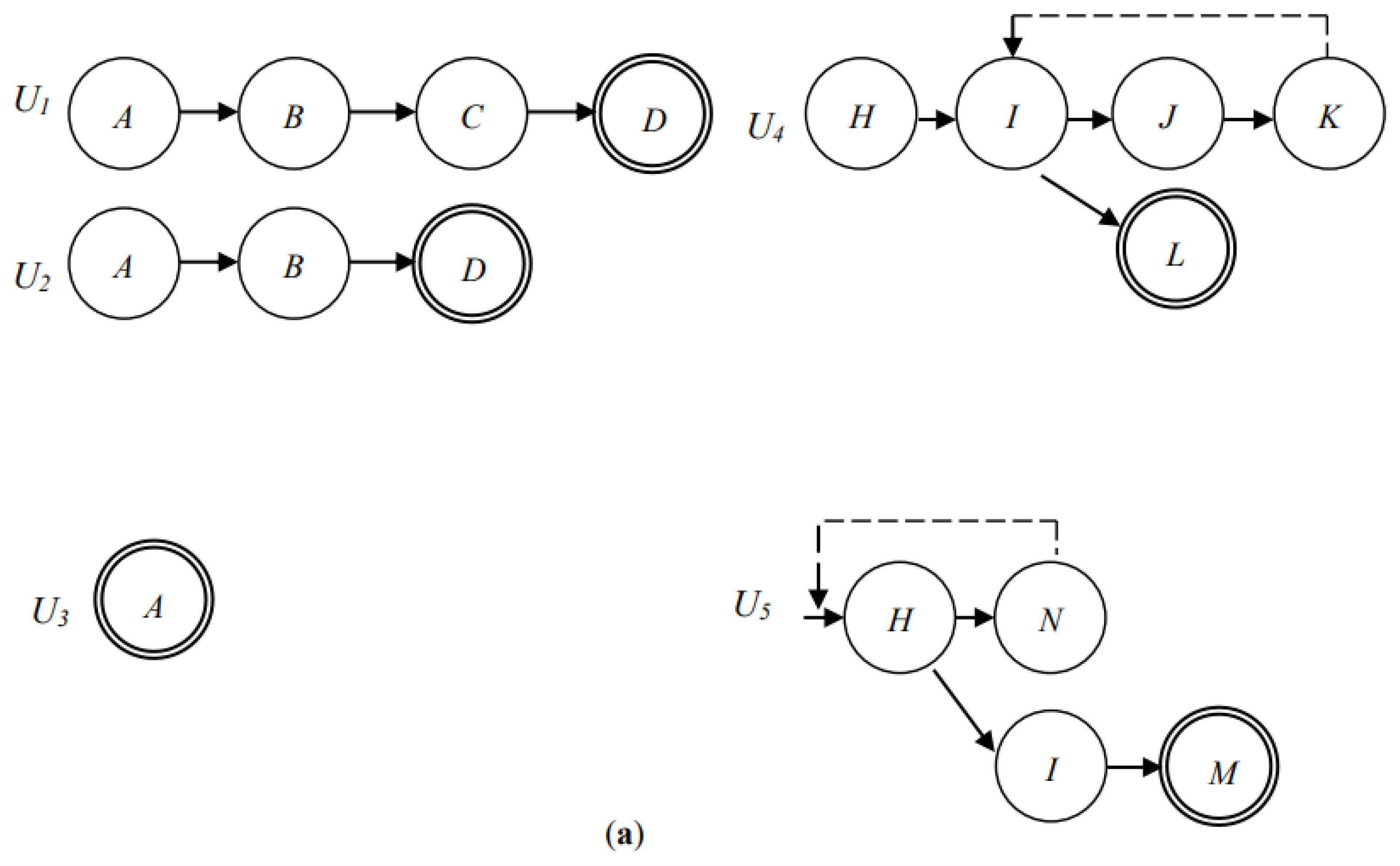
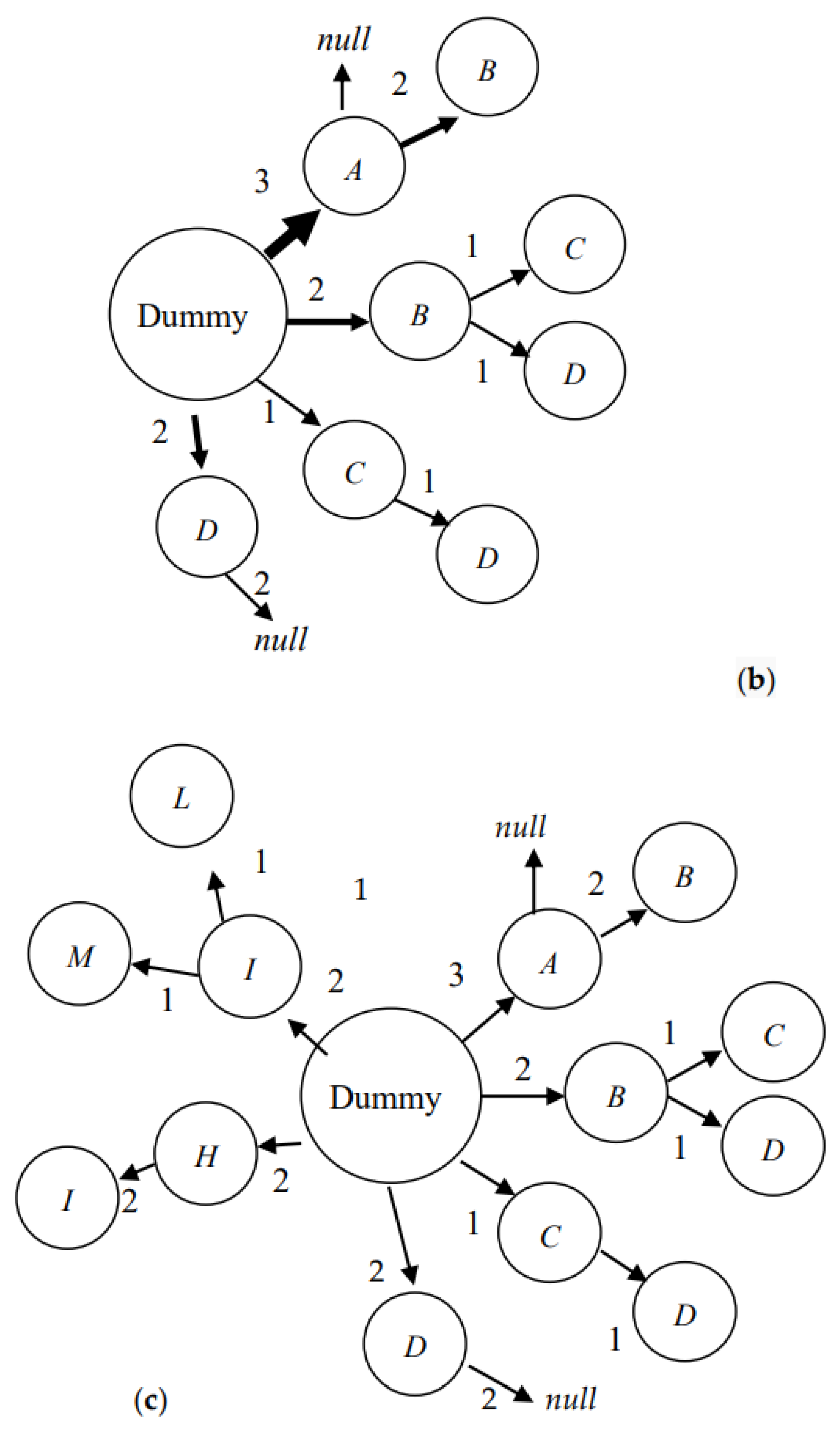
Example 3: Figure 5a shows the directed graphs of the surfing paths of five users who all search for images with the same keyword, where each node denotes a surfed image and the node with a double circle denotes the last image that was surfed by users. It can be seen that the surfing path of user U1 starts from node A, progresses through nodes B and C, and ends at node D, as this means that user U1 searches for the desired image from image to image through images and . Before inserting the surfing path into the PIDU, this surfing path is decomposed into four segments, namely, A→B, B→C, C→D, and D→null. Each of these segments consists of two adjacently surfed images. The last surfed node D of image is appended with a null node to form a segment, which denotes that no further images will be suggested via the surfing history of user U1 if a new user surfs the images . Assume that user U1 is the first user searching for images using the keyword. Clearly, the above four segments do not exist in the PIDU at this time. The four segments are appended as four branches hanging on the dummy root of the PIDU; in addition, the widths of all the links from the dummy root to each of the above four branches, and the links of the four branches, are set as one unit. Similarly, the surfing path of the second user, U2, is decomposed into three segments, namely, A→B, B→D, and D→null, and the surfing path of the third user, U3, is decomposed into a segment A→null only. Figure 5b is the PIDU obtained after sequentially inserting the segments that are decomposed from the surfing paths of these three users (i.e., users U1, U2, and U3). The widths of the two links from the dummy root node to nodes A and C, for example, are 3 and 1, since there are three current users (i.e., users U1, U2, and U3) and one past user (i.e., user U1) who surfed the images and , respectively, for the same keyword. With the PIDU in Figure 5b, when a new user queries a keyword, the potential images suggested by the search engine are images , , , and , and the probabilities of their desired degree is 3/8, 2/8, 1/8, and 2/8, since the dummy node has four links pointing to nodes A, B, C, and D, and their widths are 3, 2, 1, and 2, respectively. Assuming that the new user selects image , the next potential images suggested by the search engine are images and , and their probabilities are 1/2 and 1/2, since node B in Figure 5b has two links pointing to nodes C and D, and their widths are both one unit.
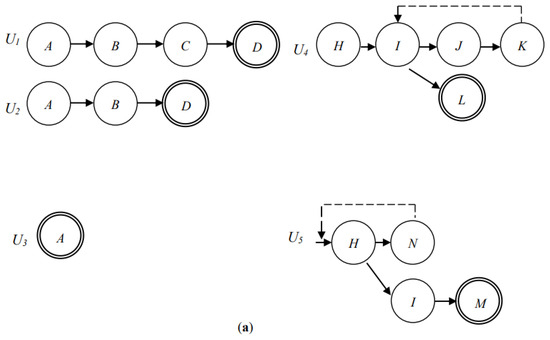
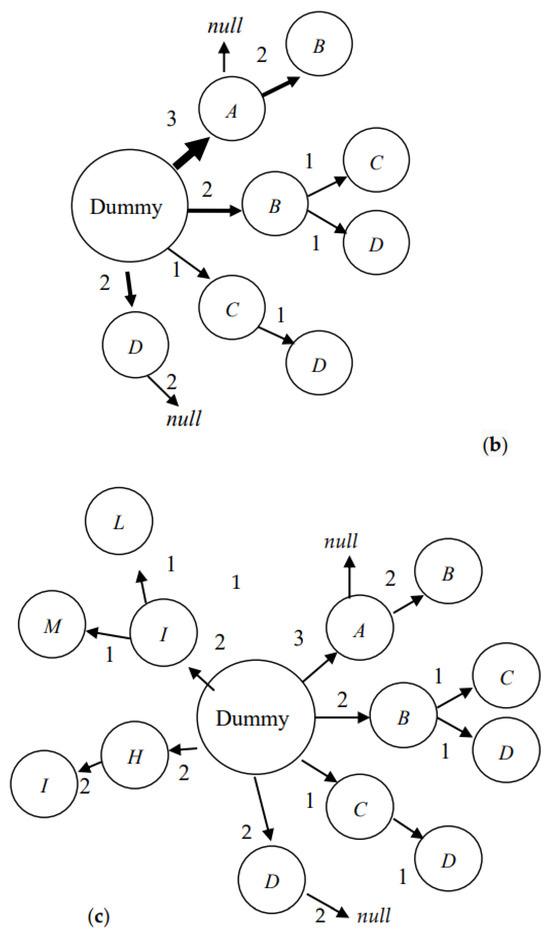
Figure 5.
A set of surfing paths travelled by five users. The surfing paths of these five users are shown in (a). The PIDU after the coalescence of the surfing paths of users U1, U2, and U3 is shown in (b). The PIDU after the coalescence of the surfing paths of all users is shown in (c).
Compared with the PIDD, which suggests the next potential images from the perspective of the web page designer, the PIDU is another clue that can suggest the next potential images from the perspective of past users. The two-node segments are used as guides for a new user in the proposed search engine; that is, when a new user surfs an image serving as the corresponding image of the source node of some segment, the corresponding image of the sink node of the segment has a high probability of being one that the new user requires. This clue is useful, especially when a user does not drill down along the links according to the arrangement of the web page designer. It is worth noting that, for a particular keyword, a user may surf some images and then backtrack if the user finds that drilling down has no possibility of obtaining the desired image. In this backtracking situation, the surfing path of the user contains a circle, denoting the user backtracking their surfing to some previous images. This backtracking reflects that the user is not satisfied with the images residing along the circle of the surfing path. Thus, this circle of the surfing path should be excluded in the PIDU.
Example 4: Consider Figure 5a; the surfing path of the fourth user, U4, shows that the user drilled down from node H, through nodes I and J, to node K, and then backtracked two nodes to node I, and finally stopped at node L, where the backtracking path is denoted by a dashed line. Since the circle of the surfing path should be excluded from the PIDU, the surfing path of user U4 that is to be recorded in the PIDU is nodes H, I, and L, skipping the backtracking sequence (i.e., nodes J and K). Similarly, the surfing path of the fifth user U5 to be included in the PIDU is the path consisting of nodes H, I, and M only. Figure 5c shows the final PIDU, which coalesced with the two more surfing paths travelled by users U4 and U5.
During the construction of the PIDU for a keyword, the proposed image search engine needs to know when the users stop surfing for the desired images. Two heuristics are adopted in this paper. The first is to check whether the user closes the web page or whether the user stays on an image for too long (for example, for more than five minutes). In most cases, these two conditions imply that the user has found the desired image. The second heuristic is to check whether the user starts a new search session. Two conditions exist for the new search: the first one is that the user starts a new search with a brand new keyword that is unrelated to the previous keyword. Generally, this condition implies that the user has found the desired image and started a new search for other topics. Thus, the surfing path of the previous search should be included in the PIDU. The second condition is that the user has started a new search with a new keyword that is related to the previous keyword. This condition generally implies that the user is gradually becoming aware or gaining more of a sense of what they want after interacting with the results provided by the image search engine. For this condition, the surfing path of the previous search is discarded; only the surfing path of the new search is inserted into the PIDU. Note that the image search engine begins a session that will record the surfing path of a user when the user types a keyword and closes the session when the user stops the search for the images. Before the construction of the PIDU, the surfing path in a session is filtered by deleting the backtracking circle(s) and is decomposed into segments consisting of two nodes.
The details of the algorithm used to construct the PIDU are described in Figure 4. First, the search engine checks whether past users queried the search engine for the keyword. If this record does not exist, the search engine will carry out an additional task; namely, it will create a new PIDU for the keyword with a dummy node as its root node. Then, for each segment, the search engine checks whether there is a branch of the PIDU for the keyword that matches the segment. If no such branch exists, a new branch, consisting of two nodes of the segment, is attached to the dummy node to host the segment, and the widths of the two links—namely, the link in the branch and the link from the dummy root to the branch—are both set as one unit. However, if the segment exists in the PIDU, the above widths of the two links are widened by one unit.
3.3. Image Searching
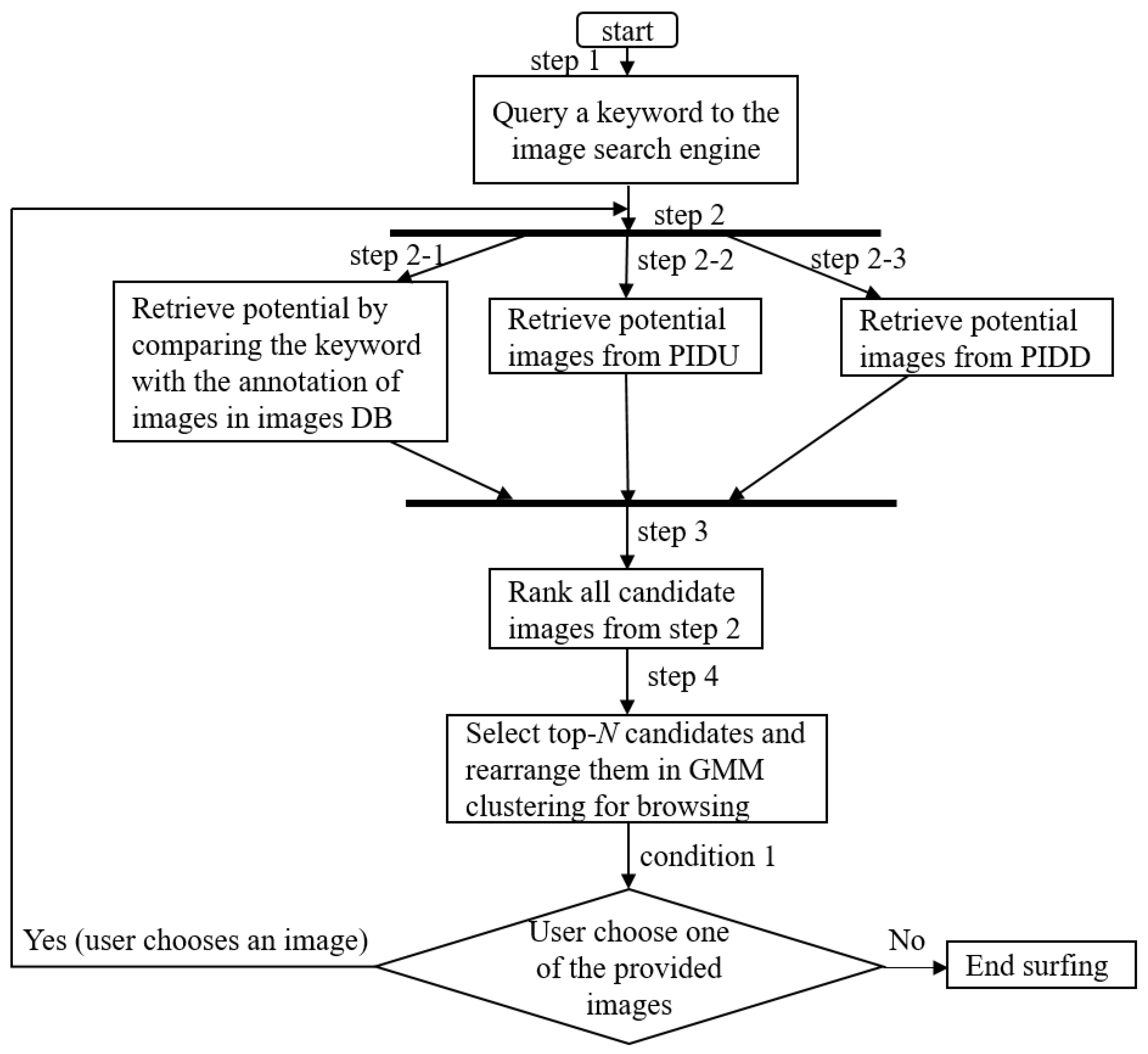
The proposed image search engine uses three methods to obtain the potential images. The first method, the traditional one, obtains the potential images from the image database, while the second and third methods obtain the potential images through the perspectives of the web page designer and past users, respectively, as discussed in Section 3.2 and Section 3.3. The steps showing how the proposed image search engine uses the above three methods to obtain the potential images for a keyword are presented in the flowchart, as shown in Figure 6.
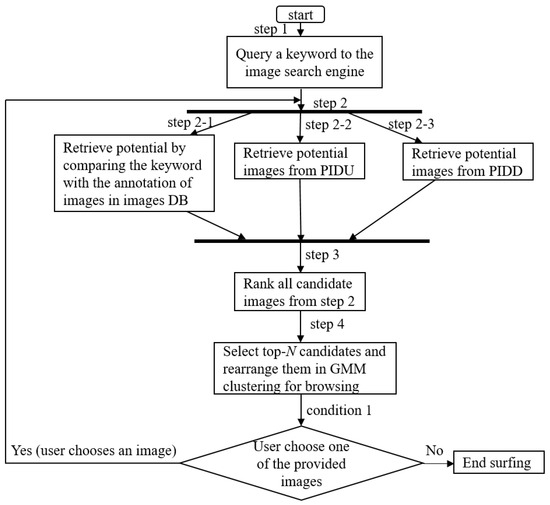
Figure 6.
The flowchart of the proposed image search engine.
First, a user queries the keyword using the image search engine (step 1 in Figure 6). The first method to obtain the potential images uses the image database (steps 2-1 in Figure 6). Through comparing the keyword with the annotations of images in the image database, the method obtains a group of potential images, denoted as GIMDB, with similar annotations to the keyword (or the extended keywords (discussed later)). The content of GIMDB is continuously renewed during the period of time that a user spends surfing the term. In other words, in the moment after a user queries the keyword, the method uses the keyword as a probe to obtain potential images from the image database; after the user interacts with the resulting images and selects an image, the method extends the keyword with the annotation of the newly selected image (called extended keyword) as a new probe to search for the next potential images. This method retrieves a set of images with similar annotations to the extended keywords, and then replaces the content of GIMDB with a new set of images for the next round of potential images.
The second method to obtain the potential images is from the perspective of past users (i.e., from PIDU) (step 2 in Figure 6). If no past users have queried a keyword that is similar to the keyword queried by the current user, no candidate images are generated by this method. Otherwise, the second method replies with a group of potential images, denoted as GPIDU, through exploring the PIDU to find the keyword. The content of GPIDU is also continuously updated. In the moment after a user queries the keyword, GPIDU contains images of the immediate child nodes of the dummy root node of that PIDU (seen in Example 3); meanwhile, in the moment after a user selects one of the resulting images, the method will first find a node at level one of the PIDU whose corresponding image is the same as the selected image. If no such child node exists, GPIDU will not change; otherwise (when such a child node exists), the content of CPIDU will be replaced with the corresponding images of the child nodes of the obtained node (seen in Example 3).
The third method to obtain the potential images is from the perspective of the web page designer (i.e., from PIDD) (steps 2-3 in Figure 6). The method does not suggest potential images until the user selects an image during their interaction with the search engine. Once the user has selected an image (denoted as image s), the method will first check whether there is a PIDD whose root node contains image s. If no such PIDD exists, no potential images are suggested; otherwise, the method will suggest a group of potential images, called GPIDD, from three sources. The content of GPIDD contains the other images (except image s) in the root of the PIDD, all the images in the sibling node(s) of the root node, and all the images in the child nodes of the root node (as shown in Example 2). The content of GPIDD is shown to the user. If the user selects an image during their interaction with the replied images, the content of GPIDD is updated. This update is similar to the above discussion, except that the PIDD being changed is the one whose root node contains the newly selected image.
The above three methods retrieve their own group of potential images using different philosophies. The proposed search engine sorts and combines the images in the three groups in a particular manner, arranges them in pages for easy browsing, and then displays them to the user (step 4 in Figure 6). The simplest way to sort and combine them is to sort the images in each group according to their own criterion and then combine them together. The images in GIMDB are sorted according to the degree of similarity between the annotations of the images in GIMDB and the (extended) keyword; the images in GPIDD are sorted according to the degree of similarity between the annotations of the images in GPIDD and the keyword; the images in GPIDU are sorted according to the widths of the related segments (as shown in Example 3).
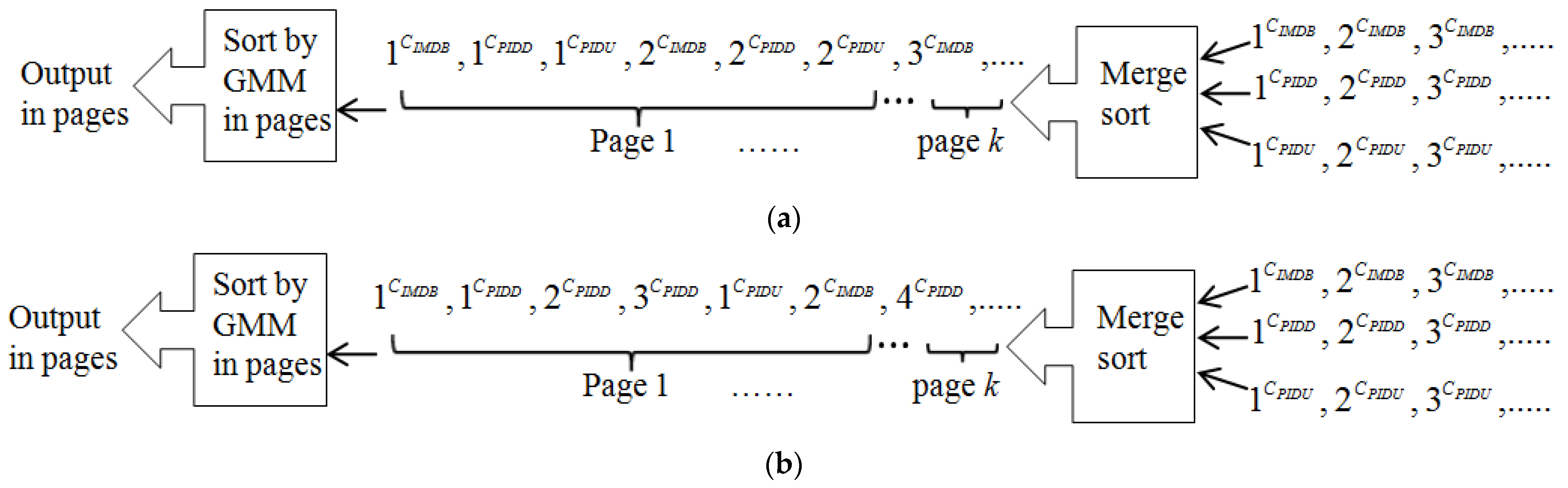
The proposed search engine can use simple three-way merge sorting to combine the three sorted groups of images in the order of their group ranking. Specifically, the images in the final combined results are arranged in such a manner that the images with the rank of k in each of the three sorted groups are always placed before the images with the rank of (k + 1), in their own sorted group, in the final combined results, where k 1. Figure 7a shows the images of the three sorted groups, merged in the order of their individual group ranking, where denotes an image with rank k in group Gx, Gx GIMDB, GPIDD, GPIDU}. For example, denotes the image with rank 2 in group GPIDD. Furthermore, Figure 7a also shows that the merged results need to be segmented in pages and then rearranged in the order of their GMM clustering before being shown to the user. After combining the candidates from the three sets, the search engine selects the top-N candidate images and rearranges them in GMM clusters for the user, for easy browsing (step 4 in Figure 6). Note that GMM, adopted by most ISRC strategies, can efficiently analyze the visual characteristics of images. The proposed search engine uses GMM to organize the results into visually consistent clusters in order to facilitate user navigation.
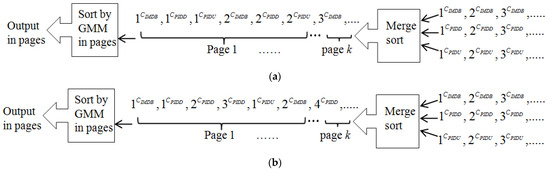
Figure 7.
Merging the images in groups GIMDB, GPIDD, and GPIDU. The sorted images in three groups are merged into one group and then re-sorted in the order of GMM clusters. (a) The three groups contribute the same amount of potential images in each page of replied images; (b) the group GPIDD contributes triple the amount of images in each page of replied images.
Suppose that the user selects one of the provided images in his/her turn. The selection is considered new feedback from the user about the provided images. With this feedback, the proposed image search engine suggests the next potential images from the image database, PIDD, and then PIDU in the next turn. This loop continues until the user finds the desired image or gives up their search.
Note that this three-way merge sorting (called simple merge sorting in this paper) considers each sorted group of images to make an equal contribution to the final combined results. In other words, the ranking of the images in a sorted group is not re-ranked before the images are combined with the images of another sorted group. The equal contribution of each group of potential images may not be suitable for different keywords. The proposed search engine can dynamically tune the contribution of the potential images from the three sorted groups, according to the feedback (i.e., the selected image) of the user. For example, if a user U selects an image from group GPIDD in his/her turn when interacting with the replied images, it is reasonable to guess that the intention of user U has the highest probability of matching the intention of the web page designer regarding the web page containing the selected image. Thus, the proposed search engine should accommodate more images from group GPIDD in each page provided to the user. To achieve the dynamical tuning requirement, the proposed search engine assigns an integer coefficient to each group of potential images. The search engine assigns integer coefficients IIMDB, IPIDD, and IPIDU to groups GIMDB, GPIDD, and GPIDU, respectively. Then, the proposed search engine divides the ranks of images in their group by their individual coefficients before merging the images in the three groups. For example, suppose that the values of the coefficients IIMDB, IPIDD, and IPIDU are assigned as 1, 3, and 1, reflecting their importance from the perspective of the web page designer in providing potential images to users. Figure 7b shows that each page of images accommodates triple the amount of images from group GPIDD. Note that the proposed search engine initially assigns the values of the integer coefficients IIMDB, IPIDD, and IPIDU as 1, 1, and 1, reflecting the equal contributions of the three groups of potential images. Suppose that a user selects an image that is suggested by some groups. If the coefficients for the other groups are larger than one, the proposed search engine decreases these coefficients by one; otherwise, the search engine increases the coefficients for the groups containing the selected image by one. The tuning of their values can change the contributions of the three groups of potential images. The next example illustrates how the proposed search engine dynamically tunes the suggestion of the potential images obtained from the different philosophies.
Example 5: If a user queries a keyword when searching for related images, the proposed search engine obtains the potential images from the image databases, PIDD, and PIDU. Since the initial values of coefficients IIMDB, IPIDD, and IPIDU are 1, 1, and 1, the three groups GIMDB, GPIDD, and GPIDU contribute an equal number of potential images in each page of the first presented images. Suppose that the user selects an image suggested from group GIMDB. Since the coefficients IPIDD and IPIDU for groups GPIDD and GPIDU are not larger than one, the coefficient IIMDB is then increased by one; that is, the coefficients of IIMDB, IPIDD, and IPIDU are 2, 1, and 1 after the first turn of this interaction. In this turn, the user does not select the images suggested from groups GPIDD and GPIDU, which means that the viewpoint of the user does not match the viewpoints of the web page designers and previous users who searched for the keyword. With the new coefficient values, each page of the second round of images will contain twice the number of images from group GIMDB compared with groups GPIDD and GPIDU. Suppose that the user selects an image that is suggested by groups GIMDB and GPIDD in the second interaction. Since the coefficient IPIDU for groups GPIDU is still not larger than one, the two coefficients IIMDB and IPIDD are both increased by one; that is, the coefficients of IIMDB, IPIDD, and IPIDU are 3, 2, and 1 after the second turn of the interaction. Thus, each page of the third round of replied images will contain triple and twice the number of images from groups GIMDB and GPIDD compared with the number of images from group GPIDU. Suppose that the user selects an image that is suggested by both groups GPIDD and GPIDU in the third round of the interaction. Since the coefficient IIMDB for group GIMDB is larger than one, this coefficient IIMDB is decreased by one; that is, the coefficients of IIMDB, IPIDD, and IPIDU are 2, 2, and 1. With the new coefficient values, each page of the third round of replied images will contain twice the number of images from groups GIMDB and GPIDD compared with group GPIDU.
4. Experiments
To demonstrate the effectiveness of the proposed image search engine, we built an image search engine written in the Java language to conduct sets of experiments. As discussed above, the proposed search engine utilizes the services provided by Google Images instead of obtaining the seed images for each keyword by itself. Using the seed images, the proposed image search engine starts to crawl in order to construct the image database and PIDDs for keywords. In other words, the proposed search engine runs as a plug-in to the general search engine, such as Google or Bing, and, based on the results of the general search engine, the proposed search engine provides the user with refined retrieval images. According to the six-degree phenomenon existing in social networks [38,39], any two related web pages should be connected to each other through a path of no more than six hops. Thus, to prepare the image database and PIDDs, the proposed search engine traced the web pages to within, at most, six hops from the seed images.
4.1. Constructing the Proposed Image Search Engine
In the first set of five experiments, each one queries a different keyword for the proposed search engine. The first three keywords are polysemous words—namely, apple, Pluto, and rice; the remaining two are general words—namely, tiger and desert. Generally, the user types a short or vague keyword, since they are unmotivated to type or unfamiliar with the topic that they are searching. Phrases that are too long or a whole sentence can easily be used to identify the desired term, meaning that most search engines work well. Thus, the experiments use short probing terms to evaluate the performance of the proposed search engine. For the first experiment, the term “apple” can be a round, edible fruit produced by an apple tree; however, the term frequently refers to Apple Inc., which is a well-known multinational technology company. For the second experiment, the term “pluto” can refer to a planet in the solar system or a cartoon character created by the Walt Disney Company. For the third experiment, the term “rice” is a shortened term for the small seeds of a grass, a cooked and eaten food, etc. A search engine will return various images, such as the apple fruit, apple tree, or Apple’s products for the polysemous word “apple”, according to the intention of the user, but their intention can be guessed more precisely if the user interacts with the results of the search engine after several rounds of searching. For the fourth experiment, using the term “tiger”, the majority of users will intend to retrieve images of the predator animal rather than the Tiger Corporation, a Japanese manufacturer of consumer electronic appliances. In the last experiment, with the term “desert”, the term, in most cases, means a dry terrain with less moisture. These two experiments aim to show the performance of the proposed search engine and the general image search images for queries with less ambiguous terms.
Table 1 shows the results retrieved by the proposed image search engine for the above five keywords. Without loss of generality, the proposed search engine retrieves the top 40 images from Google Images as the seed images, as shown in the first row of Table 1. The second row of Table 1 shows the number of crawled web pages that are within six hops of the web pages containing the seed images. The third row shows the number of images contained in the web pages in the second row. From the second and third rows, it can be seen that the keywords “apple” and “rice”, respectively, have the largest and smallest quantities of web pages and images that are crawled by the proposed search engine. These quantities match the idea that the keyword “apple” is the most active issue, but the keyword “rice” is the least popular among the five keywords.

Table 1.
The number of images and web pages crawled by the proposed search engine.
Not all the crawled web pages and images are related to the keywords. A lot of the retrieved web pages are advertisements, portals, and unrelated pages; similarly, many of the retrieved images are slogans, icons, and unrelated images. The fourth row of Table 1 shows the number of relevant images in the crawled images, where the annotations of these images are similar to those of the seed images; the fifth row of Table 1 is the number of relevant web pages containing one or more relevant images. We can see that the numbers of relevant images and web pages pertaining to the keyword “apple” are the highest, while the numbers pertaining to the term “desert” are the lowest. The reason for this may be that Apple products are a hot topic on the Internet, while “the desert” is a rare topic on the Internet.
After crawling the relevant web pages and images for each keyword, an image database and PIDDs for the five keywords were also constructed. Afterward, we asked 92 users to use the proposed search engine to construct the PIDUs. These 92 users acted as knowledge finders, remembering their intentions regarding the keywords. The intentions for the three keywords “apple”, “Pluto”, and “rice” were divided into Apple computer and apple fruit, planet and Disney figure, and uneatable rice (such as grains and seeds) and eatable rice (such as fried rice, steamed rice, and porridge), respectively. The user was asked not to select images of the apple tree, apple fruit, and other noisy images. For the last two keywords, “tiger” and “desert”, the intentions for the keywords were not distinguished. Specifically, the returned images were considered relevant if the images were relevant to the terms “tiger” or “desert”, regardless of whether they pertained to a Sumatran Tiger or Bengal Tiger, or the Sahara Desert or Arabian Desert, respectively. The proposed search engine works in an interactive way, in that it replies with a set of images and waits for the returned images to be selected by users.
4.2. Simulation Results
We conducted sets of experiments that aimed to evaluate the effectiveness of the proposed system in comparison with Google Images. To the authors’ knowledge, this paper is the first one considering the viewpoints of users and web designers psychologically in order to guide the retrieval of the proposed search engine. The novelty is that this paper constructs the psychological intention diagram of the past users (PIDU) and designers of the web pages (PIDD) for the search engine. The proposed search engine is a stateful search engine, which works in the manner of a sequence of iterations with the user to automatically narrow down the searching scope. In contrast, other search engines are stateless ones, although they may use the ontology to guide the search. Thus, only the comparison with the Google Images search engine as the baseline is presented.
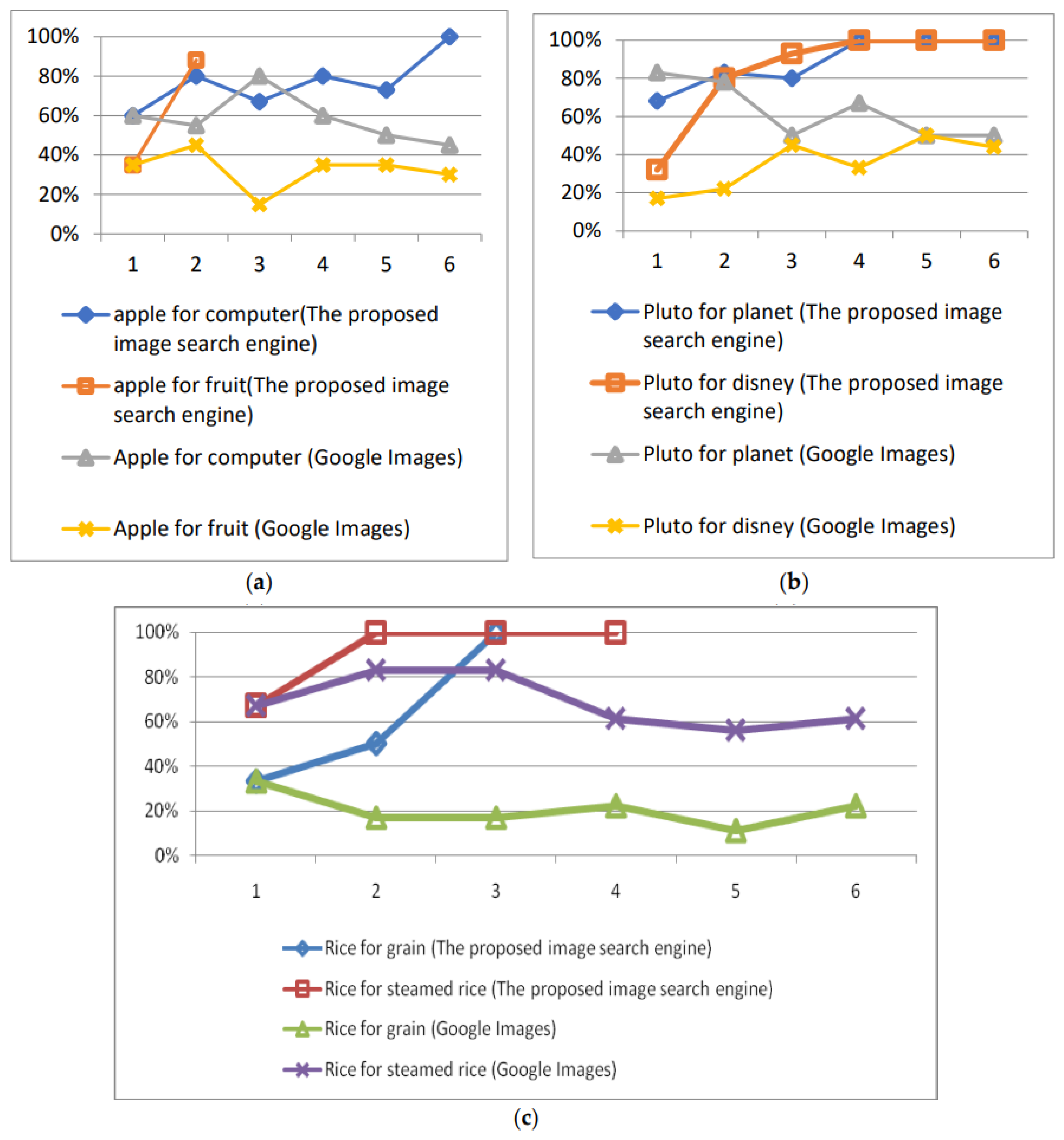
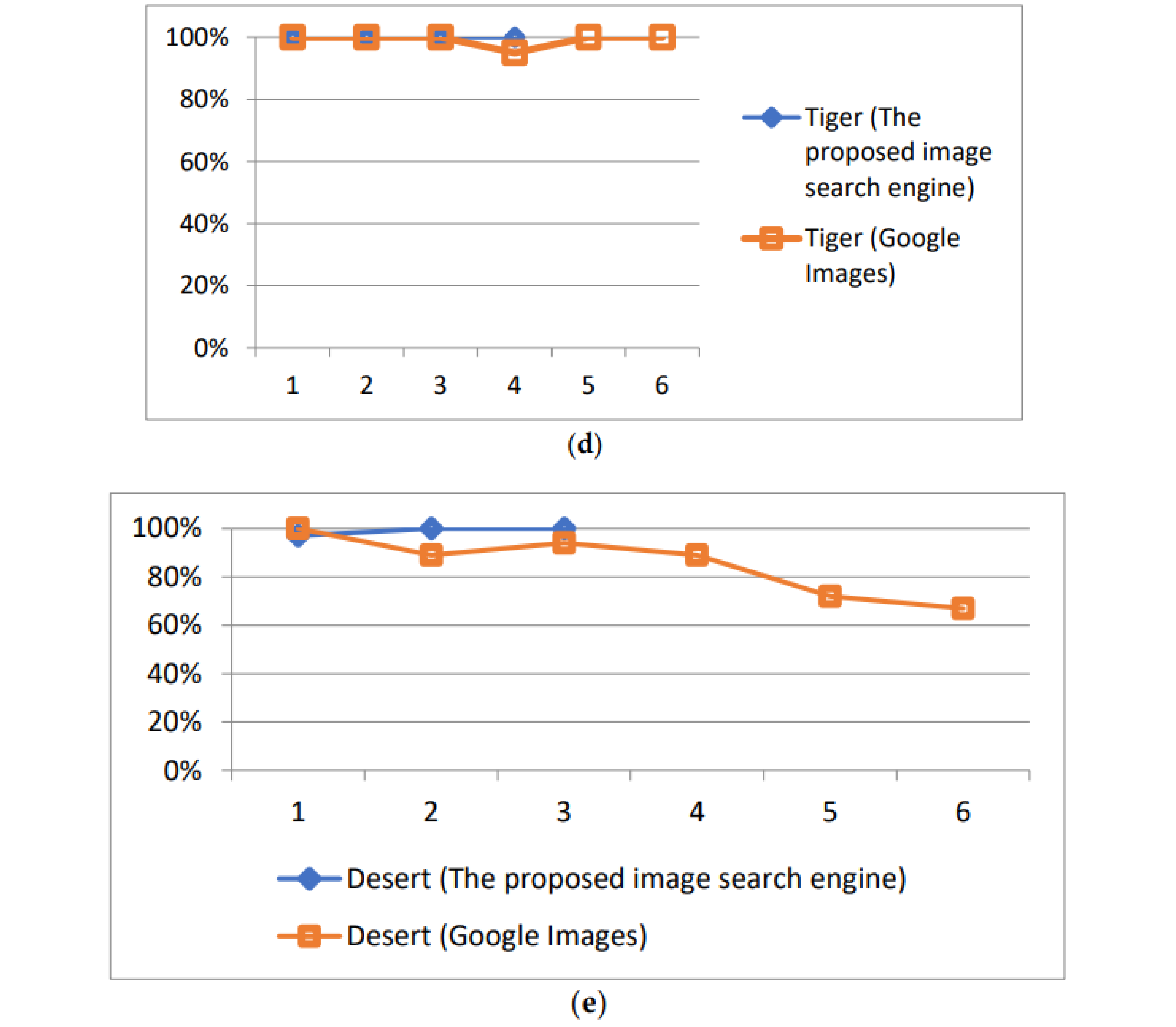
We asked 20 users to perform the experiments, querying the two image search engines using the above five keywords. Among these 20 users, 15 users were Master’s students, consisting of 5 students majoring in computer science (CS), 4 students majoring in the management of information systems (MIS), and 6 students majoring in business administration (BA). The remaining 5 users consisted of different professionals: 2 were professors, 1 was a nurse, and 2 were managers of a company. Similar to the pre-experiments, these users were assigned at least three images that they could search for. The surfing record and the images presented by the two search engines were recorded if possible. We used the precision rate (shown as the y-axis in Figure 8) to evaluate the effectiveness of this system. Since the two search engines returned many images, the precision ratio was defined as the percentage of the relevant images in the first 100 images returned by the system in each round of interaction.
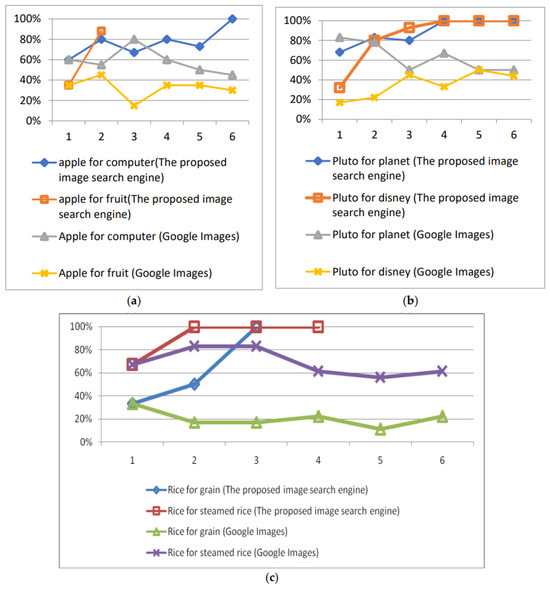
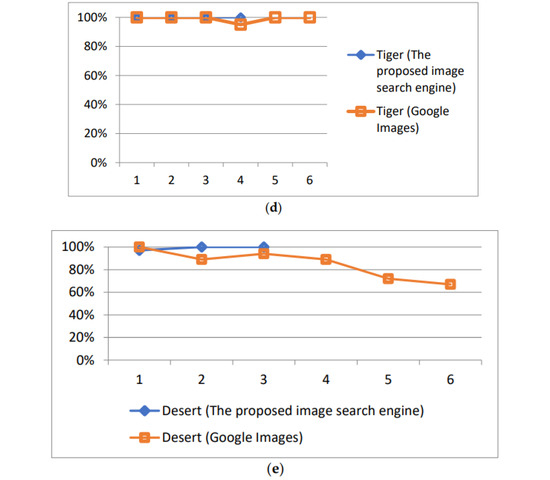
Figure 8.
The precision of UISRC.
As discussed in Section 3.3, the images presented to the users were retrieved from three groups (i.e., GIMDB, GPIDD, and GPIDU). The first set of experiments adopted simple merge sorting to combine the three groups of images. Specifically, the three groups of images were combined together under the consideration of equal contributions for the final images to users. Figure 8 shows the precision rates of the above two search engines, namely the proposed one and Google Images. Along with an increase in the rounds of interactions (shown as the x-axis in Figure 8), the precision of the proposed search engine for all keywords gradually increased, especially for the three polysemous keywords (seen in Figure 8a–c).
We used the precision rate to evaluate the effectiveness of this system. The rate is defined as the ratio of the number of relevant images to the total images that are returned by the system in each round of interaction. This paper does not adopt the R@k evaluation used in the literature [40,41] to evaluate the precision of the search engine, where R denotes the set of retrieval images, and k denotes the kth order of images in the set matching the desired result of users, k > 0. The reason for this is that the search processing was performed via interactions between the user and search engine. During each interaction, a set of images is returned to the user, and the user will use their next move to reflect their desired results. In other words, the user will choose the image closest to his/her desired result for the next surfing instance (or interaction). The R@k is one prompted set of results without user interaction to express their intention; thus, this method is not used in this paper. In addition, since the experiments are performed during subsequent interactions between the user and search engine, a set of images will be returned to the users, and the users will then evaluate the precision of the results and whether they match the users’ desired results in each round of interaction. The evaluation of the system is performed by experts during these interactions. The metric precision rate is a ratio showing whether the resulting images match the users’ desires. Some other metrics, such as the recall rate, were not adopted in the experiments since the search space on the Internet was too large to collect all related images during the experiments.
We compared the proposed search engine with Google Images using the five keywords. After constructing the PIDUs, we asked another 10 different users to query the search engine using the same five keywords. The first three and last two experiments were designed to show whether user feedback regarding their intended images can influence the precision of the returned images if the keywords are polysemous and general words.
As discussed in Section 3.3, the proposed image search engine retrieves the potential images using three methods, which generate three groups (i.e., GIMDB, GPIDD, and GPIDU) of potential images. The first set of experiments adopts simple merge sorting to combine the three groups of images. Specifically, the three groups of images are combined together under the consideration that they make an equal contribution of final images to the user. As shown in Figure 8, the precision of the proposed image search engine for the first set of five experiments was not as high as those provided by Google Images at the beginning (i.e., when the user starts their search). Along with the increase in the rounds of interaction, the precision of the proposed search engine for all keywords gradually increases, especially for the three polysemous keywords (as shown in Figure 8a,c). The accuracy of these three keywords in the proposed search engine can reach up to 90% after two or three rounds of interaction. However, the corresponding precision of Google Images remains unchanged, or even decreases when the users browse more and more images. The reason for this may be that Google Images only compares the input keywords with the annotations of images in its image database; it does not guess the intentions of users. In contrast, the proposed search engine utilizes PIDD and PIDU to guess the user intention using the perspectives of past users and web page designers during the surfing process. As expected, the guides provided by these perspectives are useful when the keywords convey multiple meanings.
However, for the two general keywords, tiger and desert, each of whose meaning is very clarified and monotonous, the search engine has few possibilities when crawling different image topics. Figure 8d,e show that the precision of the images provided by Google Images and the proposed search engine is similar and remains stable after each interaction. The reason for this may be that Google Images cannot retrieve off-topic images since there is no ambiguity for such keywords.
The equal contribution made by each group to the final potential images may not be suitable for different keywords. The next set of experiments will dynamically tune the contributions of the potential images from the three groups. Similar to the first set of experiments, the second set of experiments will also use the above five keywords, but the combination of the three groups will be dynamically modified (as shown in Example 5). The proposed search engine will check the group of retrieved images from which a user selects an image. If the selected image is from a particular group(s), the proposed search engine should include more potential images from that group in a page to display to the user.
In sum, we can see that the proposed search engine can provide more accurate and desired images to the user if the user chooses the images step by step. In the experiments using general keywords (as shown in Figure 8d,e), the precision of the images provided by the proposed search engine is the same as or higher than the precision of Google Images. In the experiments using polysemous keywords, correct guesses of user intentions will seriously influence the precision of the returned images. The accuracy of the images provided by the proposed search engine is initially similar to that of Google Images, but the accuracy improves after several rounds of interaction. The results of the experiment agree with the expectations regarding the effectiveness of the proposed algorithm.
5. Conclusions
In this paper, the proposed image search engine incorporates two innovative methods to retrieve potential images from the perspectives of past users and web page designers. We utilized the psychological intentions of web page designers to construct the PIDD and the psychological intentions of past users to construct the PIDU. The proposed image search engine implements these two diagrams to construct an image search engine, which can solve the problem of polysemous keywords as well as general keywords. We compared the precision of the proposed image search engine to that of Google Images. From the results of the experiment, it is revealed that if the keyword is polysemous, the precision of the proposed image search engine is higher than that of Google Images. When the user types a general keyword, the precision of the proposed search engine is as high as that of Google Images. The proposed search engine adopts GMM, used by most ISRC strategies, to efficiently organize the results into visually consistent clusters to facilitate user navigation. The proposed search engine does not involve a new syntax-level clustering strategy or adopt a cutting-edge strategy, which could be a future research topic.
Author Contributions
Conceptualization, M.-Q.A.W. and F.W.; methodology, M.-Q.A.W. and W.-B.L.; software, W.-B.L.; validation, F.W. and W.-B.L.; formal analysis, M.-Q.A.W.; investigation, W.-B.L.; writing—F.W. and W.-B.L.; writing—M.-Q.A.W.; supervision, F.W.; project administration, M.-Q.A.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Derived data supporting the findings of this study are available from the corresponding author on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Datta, R.; Joshi, D.; Li, J.; Wang, J.Z. Image retrieval: Ideas, influences, and trends of the new age. ACM Comput. Surv. 2008, 40, 1–60. [Google Scholar] [CrossRef]
- Gillis, N.; Kuang, D.; Park, H. Hierarchical clustering of hyperspectral images using rank-two nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2066–2078. [Google Scholar] [CrossRef]
- Hameed, I.M.; Abdulhussain, S.H.; Mahmmod, B.M. Content-based image retrieval: A review of recent trends. Cogent Eng. 2021, 8, 1927469. [Google Scholar] [CrossRef]
- Chugh, H.; Gupta, S.; Garg, M.; Gupta, D.; Mohamed, H.G.; Noya, I.D.; Singh, A.; Goyal, N. An Image Retrieval Framework Design Analysis Using Saliency Structure and Color Difference Histogram. Sustainability 2022, 14, 10357. [Google Scholar] [CrossRef]
- Nguyen, H.L.; Woon, Y.K.; Ng, W.K. A survey on data stream clustering and classification. Knowl. Inf. Syst. 2015, 45, 535–569. [Google Scholar] [CrossRef]
- Marine-Roig, E. Measuring Destination Image through Travel Reviews in Search Engines. Sustainability 2017, 9, 1425. [Google Scholar] [CrossRef]
- Duka, M.; Sikora, M.; Strzelecki, A. From Web Catalogs to Google: A Retrospective Study of Web Search Engines Sustainable Development. Sustainability 2023, 15, 6768. [Google Scholar] [CrossRef]
- Bouchakwa, M.; Ayadi, Y.; Amous, I. Multi-level diversification approach of semantic-based image retrieval results. Prog. Artif. Intell. 2020, 9, 1–30. [Google Scholar] [CrossRef]
- Nandanwar, A.K.; Choudhary, J. Contextual Embeddings-Based Web Page Categorization Using the Fine-Tune BERT Model. Symmetry 2023, 15, 395. [Google Scholar] [CrossRef]
- Wang, S.; Jing, F.; He, J.; Du, Q.; Zhang, L. IGroup: Presenting Web Image Search Results in Semantic Clusters. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 28 April–3 May 2007. [Google Scholar]
- Tekli, J. An overview of cluster-based image search result organization: Background, techniques, and ongoing challenges. Knowl. Inf. Syst. 2022, 64, 589–642. [Google Scholar] [CrossRef]
- Shi, J.; Zheng, X.; Yang, W. Robust Sparse Representation for Incomplete and Noisy Data. Information 2015, 6, 287–299. [Google Scholar] [CrossRef]
- Carson, C.; Belongie, S.; Greenspan, H.; Malik, J. Blobworld: Image segmentation using expectation-maximization and its application to image querying. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1026–1038. [Google Scholar] [CrossRef]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef] [PubMed]
- Jardim, S.; António, J.; Mora, C. Graphical image region extraction with k-means clustering and watershed. J. Imaging 2022, 8, 163. [Google Scholar] [CrossRef] [PubMed]
- Alomoush, W.; Khashan, O.A.; Alrosan, A.; Houssein, E.H.; Attar, H.; Alweshah, M.; Alhosban, F. Fuzzy Clustering Algorithm Based on Improved Global Best-Guided Artificial Bee Colony with New Search Probability Model for Image Segmentation. Sensors 2022, 22, 8956. [Google Scholar] [CrossRef] [PubMed]
- Shen, D.; Pan, R.; Sun, J.T.; Pan, J.J.; Wu, K.; Yin, J.; Yang, Q. Query enrichment for web-query classification. ACM Trans. Inf. Syst. (TOIS) 2006, 24, 320–352. [Google Scholar] [CrossRef]
- Hsu, C.-C.; Wu, F. Topic-specific crawling on the Web with the measurements of the relevancy context graph. Inf. Syst. 2006, 31, 232–246. [Google Scholar] [CrossRef]
- Ziakis, C.; Vlachopoulou, M.; Kyrkoudis, T.; Karagkiozidou, M. Important Factors for Improving Google Search Rank. Future Internet 2019, 11, 32. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Hong, M.-S.; Jung, J.J.; Sohn, B.-S. Cognitive Similarity-Based Collaborative Filtering Recommendation System. Appl. Sci. 2020, 10, 4183. [Google Scholar] [CrossRef]
- Sardianos, C.; Papadatos, G.B.; Varlamis, I. Optimizing parallel collaborative filtering approaches for improving recommendation systems performance. Information 2019, 10, 155. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, Q.; Zhang, L.; Wang, B.; Ho, W.H. Diversity balancing for two-stage collaborative filtering in recommender systems. Appl. Sci. 2020, 10, 1257. [Google Scholar] [CrossRef]
- Kunert, J.; Thurman, N. The form of content personalisation at mainstream, transatlantic news outlets: 2010–2016. J. Pract. 2019, 13, 759–780. [Google Scholar] [CrossRef]
- Sudhir, R.; Baboo, S.S. A Efficient Content based Image Retrieval System using GMM and Relevance Feedback. Int. J. Comput. Appl. 2013, 72, 22. [Google Scholar]
- Wang, X.J.; Zhang, L.; Li, X.; Ma, W.Y. Annotating images by mining image search results. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1919–1932. [Google Scholar] [CrossRef] [PubMed]
- Ligocki, A.; Jelinek, A.; Zalud, L.; Rahtu, E. Fully Automated DCNN-Based Thermal Images Annotation Using Neural Network Pretrained on RGB Data. Sensors 2021, 21, 1552. [Google Scholar] [CrossRef] [PubMed]
- Coelho, T.A.; Calado, P.P.; Souza, L.V.; Ribeiro-Neto, B.; Muntz, R. Image retrieval using multiple evidence ranking. IEEE Trans. Knowl. Data Eng. 2004, 16, 408–417. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Tian, C.; Rong, X.; Zhang, Z.; Wang, H.; Fu, K.; Sun, X. Remote sensing cross-modal text-image retrieval based on global and local information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Zhang, W.; Li, J.; Li, S.; Chen, J.; Zhang, W.; Gao, X.; Sun, X. Hypersphere-based Remote Sensing Cross-Modal Text-Image Retrieval via Curriculum Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Tian, C.; Mao, Y.; Zhou, R.; Wang, H.; Fu, K.; Sun, X. MCRN: A Multi-source Cross-modal Retrieval Network for remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103071. [Google Scholar] [CrossRef]
- Jansen, B.J.; Booth, D.L.; Spink, A. Determining the informational, navigational, and transactional intent of Web queries. Inf. Process. Manag. 2008, 44, 1251–1266. [Google Scholar] [CrossRef]
- Keyvan, K.; Huang, J.X. How to Approach Ambiguous Queries in Conversational Search: A Survey of Techniques, Approaches, Tools, and Challenges. ACM Comput. Surv. 2022, 55, 1–40. [Google Scholar] [CrossRef]
- Nasir, J.A.; Varlamis, I.; Ishfaq, S. A knowledge-based semantic framework for query expansion. Inf. Process. Manag. 2019, 56, 1605–1617. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual Web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Yeh, W.-C.; Zhu, W.; Huang, C.-L.; Hsu, T.-Y.; Liu, Z.; Tan, S.-Y. A New BAT and PageRank Algorithm for Propagation Probability in Social Networks. Appl. Sci. 2022, 12, 6858. [Google Scholar] [CrossRef]
- Vu, X.S.; Vu, T.; Nguyen, H.; Ha, Q.T. Improving text-based image search with textual and visual features combination. In Knowledge and Systems Engineering, Proceedings of the Sixth International Conference KSE 2014, Hanoi, Vietnam, 9–11 October 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 233–245. [Google Scholar]
- Mei, T.; Rui, Y.; Li, S.; Tian, Q. Multimedia search reranking: A literature survey. ACM Comput. Surv. (CSUR) 2014, 46, 1–38. [Google Scholar] [CrossRef]
- Stephen, A.T.; Toubia, O. Explaining the power-law degree distribution in a social commerce network. Soc. Netw. 2009, 31, 262–270. [Google Scholar] [CrossRef]
- Sollberger, D.; Igel, H.; Schmelzbach, C.; Edme, P.; van Manen, D.-J.; Bernauer, F.; Yuan, S.; Wassermann, J.; Schreiber, U.; Robertsson, J.O.A. Seismological Processing of Six Degree-of-Freedom Ground-Motion Data. Sensors 2020, 20, 6904. [Google Scholar] [CrossRef]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked cross attention for image-text matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 201–216. [Google Scholar]
- Yuan, Z.; Zhang, W.; Rong, X.; Li, X.; Chen, J.; Wang, H.; Fu, K.; Sun, X. A Lightweight Multi-Scale Crossmodal Text-Image Retrieval Method in Remote Sensing. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).