
Multi-Modal Contrastive Learning for LiDAR Point Cloud Rail-Obstacle Detection in Complex Weather

Abstract
1. Introduction
- A Dual-Helix Transformer (DHT) module is proposed to extract deeper information for robust sensor fusion in complex weather through local cross-attention mechanisms.
- An adaptive contrastive learning strategy is achieved through the use of an obstacle anomaly-aware cross-modal discrimination loss, which adjusts the learning priorities according to the presence or absence of obstacles.
- Based on the proposed semantic segmentation network, a rail-obstacle detection method is implemented to identify and locate multi-class unknown obstacles (minimum size cm) in complex weather, which exhibits high accuracy and robustness.
2. Related Works
2.1. Rail-Obstacle Detection
2.2. Two-Dimensional Environmental Perception in Adverse Weather
2.3. Three-Dimensional Environmental Perception in Adverse Weather
2.4. Sensor Fusion Methods
2.5. Multi-Modal Contrastive Learning
3. Methods
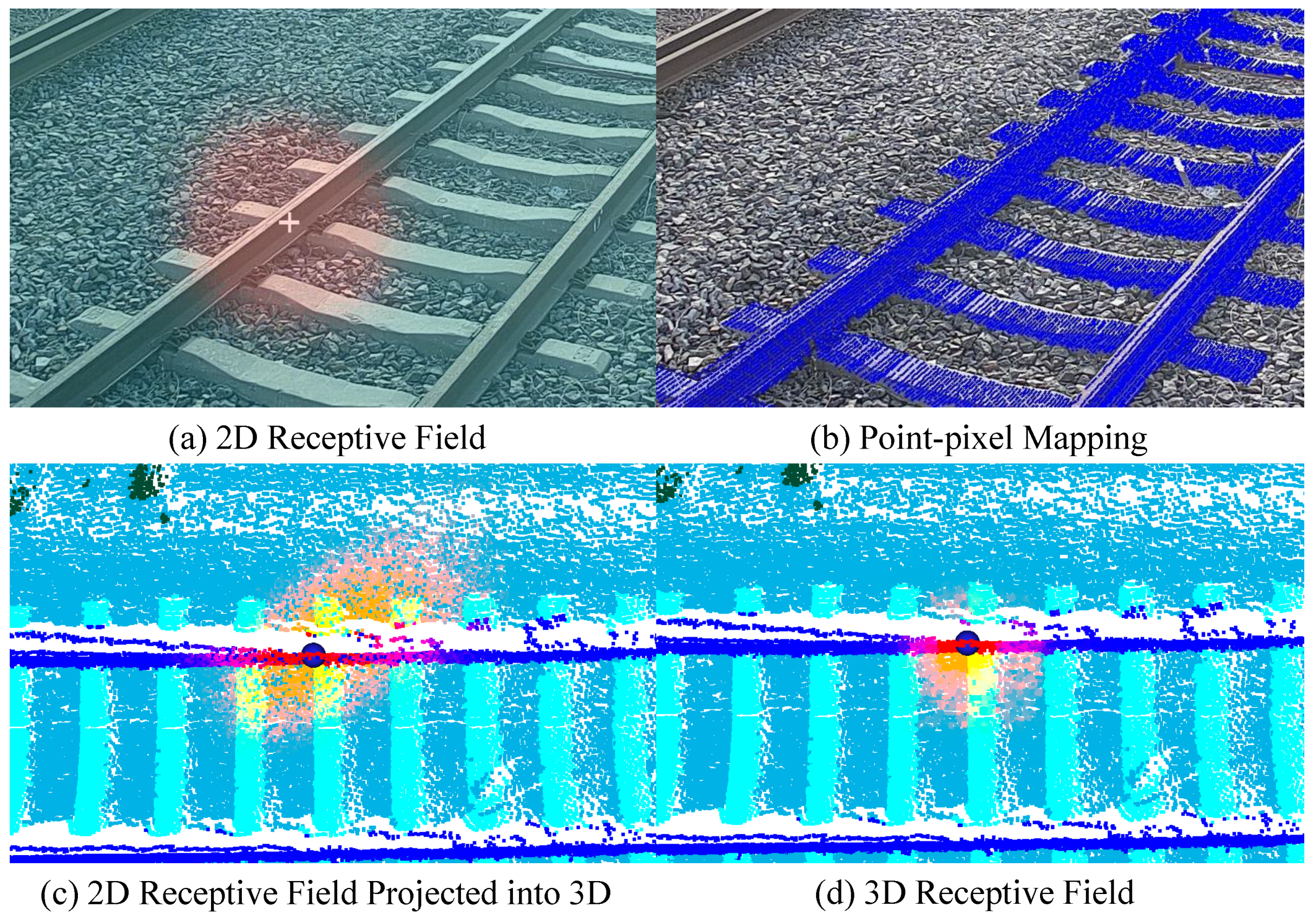
3.1. Point-Pixel Mapping
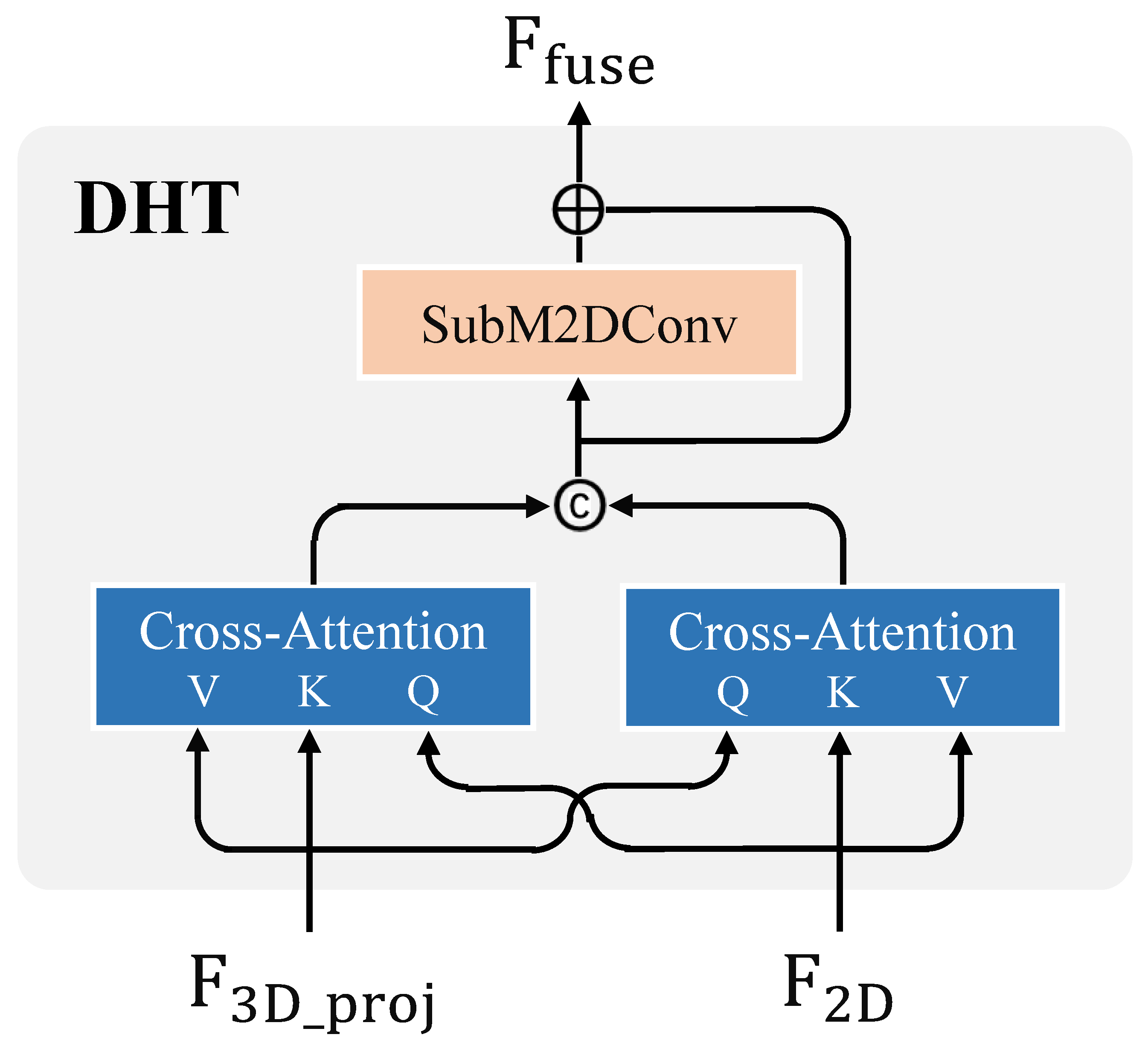
3.2. Dual-Helix Transformer
3.3. Adaptive Contrastive Learning
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Training and Inference Details
4.2. Benchmark Results
4.3. Comprehensive Analysis
4.3.1. Threats to Validity
4.3.2. Comparison with Other Multi-Modal Methods
4.3.3. Ablation Study
4.3.4. Distance-Based Evaluation
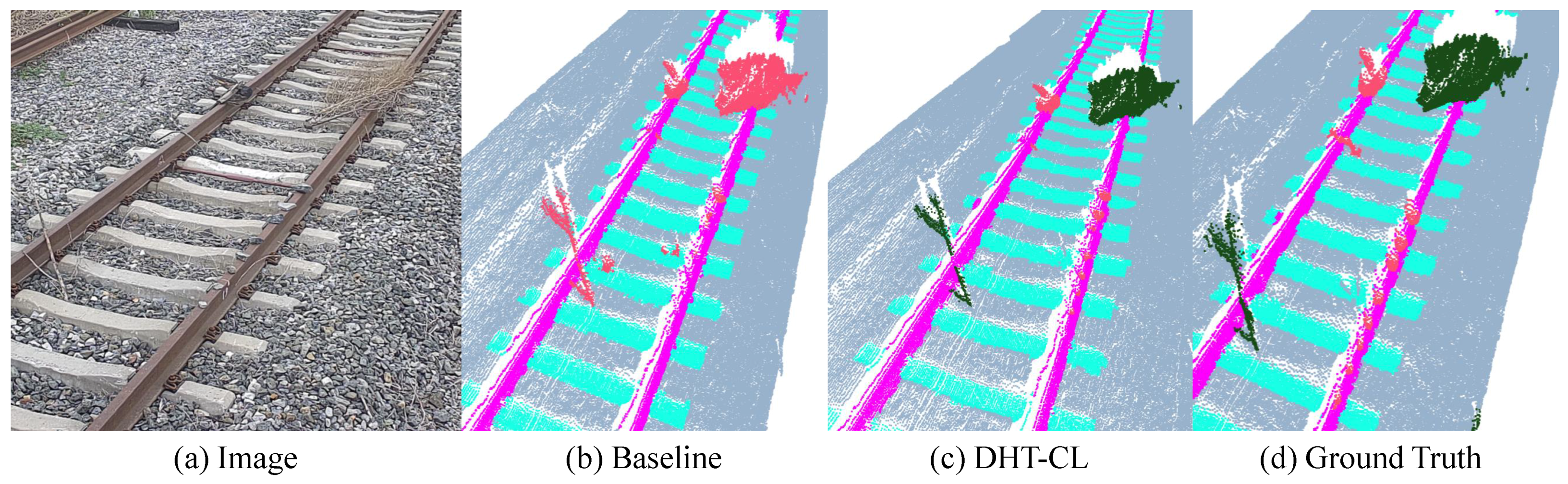
4.3.5. Visualization Results
4.3.6. Model Convergence
4.4. Rail-Obstacle Detection in Complex Weather
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3DSS | 3D semantic segmentation |
| LiDAR | Light detection and ranging |
| CL | Contrastive learning |
| DHT | Dual-Helix Transformer |
| FOV | Field of view |
| BEV | Bird’s-eye view |
| KL div. | Kullback–Leibler divergence |
| PCA | Principal component analysis |
| LDA | Linear discriminant analysis |
| SVM | Support vector machines |
| RoI | Region of interest |
| SGD | Stochastic gradient descent |
| TTA | Test-time augmentation |
| MLP | Multilayer perceptron |
Appendix A





Appendix B






References
- Zhangyu, W.; Guizhen, Y.; Xinkai, W.; Haoran, L.; Da, L. A Camera and LiDAR Data Fusion Method for Railway Object Detection. IEEE Sens. J. 2021, 21, 13442–13454. [Google Scholar] [CrossRef]
- Soilán, M.; Nóvoa, A.; Sánchez-Rodríguez, A.; Riveiro, B.; Arias, P. Semantic Segmentaion of Point Clouds with PointNet AND KPConv Architectures Applied to Railway Tunnels. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 2, 281–288. [Google Scholar] [CrossRef]
- Manier, A.; Moras, J.; Michelin, J.C.; Piet-Lahanier, H. Railway Lidar Semantic Segmentation with Axially Symmetrical Convlutional Learning. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 2, 135–142. [Google Scholar] [CrossRef]
- Dibari, P.; Nitti, M.; Maglietta, R.; Castellano, G.; Dimauro, G.; Reno, V. Semantic Segmentation of Multimodal Point Clouds from the Railway Context. In Multimodal Sensing and Artificial Intelligence: Technologies and Applications II; Stella, E., Ed.; SPIE: Bellingham, WA, USA, 2021; Volume 11785. [Google Scholar] [CrossRef]
- Le, M.H.; Cheng, C.H.; Liu, D.G. An Efficient Adaptive Noise Removal Filter on Range Images for LiDAR Point Clouds. Electronics 2023, 12, 2150. [Google Scholar] [CrossRef]
- Le, M.H.; Cheng, C.H.; Liu, D.G.; Nguyen, T.T. An Adaptive Group of Density Outlier Removal Filter: Snow Particle Removal from LiDAR Data. Electronics 2022, 11, 2993. [Google Scholar] [CrossRef]
- Wang, W.; You, X.; Chen, L.; Tian, J.; Tang, F.; Zhang, L. A Scalable and Accurate De-Snowing Algorithm for LiDAR Point Clouds in Winter. Remote Sens. 2022, 14, 1468. [Google Scholar] [CrossRef]
- Mai, N.A.M.; Duthon, P.; Khoudour, L.; Crouzil, A.; Velastin, S.A. 3D Object Detection with SLS-Fusion Network in Foggy Weather Conditions. Sensors 2021, 21, 6711. [Google Scholar] [CrossRef] [PubMed]
- Shih, Y.C.; Liao, W.H.; Lin, W.C.; Wong, S.K.; Wang, C.C. Reconstruction and Synthesis of Lidar Point Clouds of Spray. IEEE Robot. Autom. Lett. 2022, 7, 3765–3772. [Google Scholar] [CrossRef]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- El Madawi, K.; Rashed, H.; El Sallab, A.; Nasr, O.; Kamel, H.; Yogamani, S. RGB and LiDAR fusion based 3D Semantic Segmentation for Autonomous Driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 7–12. [Google Scholar] [CrossRef]
- Sun, Y.; Zuo, W.; Yun, P.; Wang, H.; Liu, M. FuseSeg: Semantic Segmentation of Urban Scenes Based on RGB and Thermal Data Fusion. IEEE Trans. Autom. Sci. Eng. 2021, 18, 1000–1011. [Google Scholar] [CrossRef]
- Genova, K.; Yin, X.; Kundu, A.; Pantofaru, C.; Cole, F.; Sud, A.; Brewington, B.; Shucker, B.; Funkhouser, T. Learning 3D Semantic Segmentation with only 2D Image Supervision. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 361–372. [Google Scholar] [CrossRef]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. PointPainting: Sequential Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4603–4611. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, S.; Wang, L.; Luo, J. SAT: 2D Semantics Assisted Training for 3D Visual Grounding. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 1836–1846. [Google Scholar] [CrossRef]
- Zhuang, Z.; Li, R.; Jia, K.; Wang, Q.; Li, Y.; Tan, M. Perception-Aware Multi-Sensor Fusion for 3D LiDAR Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 16260–16270. [Google Scholar] [CrossRef]
- Liu, Z.; Qi, X.; Fu, C.W. 3D-to-2D Distillation for Indoor Scene Parsing. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 4462–4472. [Google Scholar] [CrossRef]
- Li, J.; Dai, H.; Han, H.; Ding, Y. MSeg3D: Multi-Modal 3D Semantic Segmentation for Autonomous Driving. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21694–21704. [Google Scholar] [CrossRef]
- Yan, X.; Gao, J.; Zheng, C.; Zheng, C.; Zhang, R.; Cui, S.; Li, Z. 2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds. arXiv 2022, arXiv:cs.CV/2207.04397. [Google Scholar]
- Mahmoud, A.; Hu, J.S.K.; Kuai, T.; Harakeh, A.; Paull, L.; Waslander, S.L. Self-Supervised Image-to-Point Distillation via Semantically Tolerant Contrastive Loss. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7102–7110. [Google Scholar] [CrossRef]
- Hou, Y.; Zhu, X.; Ma, Y.; Loy, C.C.; Li, Y. Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8469–8478. [Google Scholar] [CrossRef]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation. arXiv 2020, arXiv:cs.CV/2008.01550. [Google Scholar]
- Liu, Z.; Tang, H.; Zhao, S.; Shao, K.; Han, S. PVNAS: 3D Neural Architecture Search With Point-Voxel Convolution. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8552–8568. [Google Scholar] [CrossRef] [PubMed]
- Choy, C.; Gwak, J.; Savarese, S. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3070–3079. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9296–9306. [Google Scholar] [CrossRef]
- Xu, H.; Qiao, J.; Zhang, J.; Han, H.; Li, J.; Liu, L.; Wang, B. A High-Resolution Leaky Coaxial Cable Sensor Using a Wideband Chaotic Signal. Sensors 2018, 18, 4154. [Google Scholar] [CrossRef]
- Catalano, A.; Bruno, F.A.; Galliano, C.; Pisco, M.; Persiano, G.V.; Cutolo, A.; Cusano, A. An optical fiber intrusion detection system for railway security. Sens. Actuators A Phys. 2017, 253, 91–100. [Google Scholar] [CrossRef]
- SureshKumar, M.; Malar, G.P.P.; Harinisha, N.; Shanmugapriya, P. Railway Accident Prevention Using Ultrasonic Sensors. In Proceedings of the 2022 International Conference on Power, Energy, Control and Transmission Systems (ICPECTS), Chennai, India, 8–9 December 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, Y.; He, Y.; Que, Y.; Wang, Y. Millimeter wave radar denoising and obstacle detection in highly dynamic railway environment. In Proceedings of the 2023 IEEE 6th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 24–26 February 2023; Volume 6, pp. 1149–1153. [Google Scholar] [CrossRef]
- Gasparini, R.; D’Eusanio, A.; Borghi, G.; Pini, S.; Scaglione, G.; Calderara, S.; Fedeli, E.; Cucchiara, R. Anomaly Detection, Localization and Classification for Railway Inspection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3419–3426. [Google Scholar] [CrossRef]
- Fonseca Rodriguez, L.A.; Uribe, J.A.; Vargas Bonilla, J.F. Obstacle detection over rails using hough transform. In Proceedings of the 2012 XVII Symposium of Image, Signal Processing, and Artificial Vision (STSIVA), Medellin, Colombia, 12–14 September 2012; pp. 317–322. [Google Scholar] [CrossRef]
- Uribe, J.A.; Fonseca, L.; Vargas, J.F. Video based system for railroad collision warning. In Proceedings of the 2012 IEEE International Carnahan Conference on Security Technology (ICCST), Newton, MA, USA, 15–18 October 2012; pp. 280–285. [Google Scholar] [CrossRef]
- Kano, G.; Andrade, T.; Moutinho, A. Automatic Detection of Obstacles in Railway Tracks Using Monocular Camera. In Computer Vision Systems; Tzovaras, D., Giakoumis, D., Vincze, M., Argyros, A., Eds.; Springer: Cham, Switzerland, 2019; pp. 284–294. [Google Scholar]
- Lu, J.; Xing, Y.; Lu, J. Intelligent Video Surveillance and Early Alarms Method for Railway Tunnel Collapse. In Proceedings of the 19th COTA International Conference of Transportation Professionals (CICTP 2019), Nanjing, China, 6–8 July 2019; pp. 1914–1925. [Google Scholar] [CrossRef]
- Guan, L.; Jia, L.; Xie, Z.; Yin, C. A Lightweight Framework for Obstacle Detection in the Railway Image Based on Fast Region Proposal and Improved YOLO-Tiny Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–16. [Google Scholar] [CrossRef]
- Pan, H.; Li, Y.; Wang, H.; Tian, X. Railway Obstacle Intrusion Detection Based on Convolution Neural Network Multitask Learning. Electronics 2022, 11, 2697. [Google Scholar] [CrossRef]
- Cao, Y.; Pan, H.; Wang, H.; Xu, X.; Li, Y.; Tian, Z.; Zhao, X. Small Object Detection Algorithm for Railway Scene. In Proceedings of the 2022 7th International Conference on Image, Vision and Computing (ICIVC), Xi’an, China, 26–28 July 2022; pp. 100–105. [Google Scholar] [CrossRef]
- He, D.; Li, K.; Chen, Y.; Miao, J.; Li, X.; Shan, S.; Ren, R. Obstacle detection in dangerous railway track areas by a convolutional neural network. Meas. Sci. Technol. 2021, 32, 105401. [Google Scholar] [CrossRef]
- Rampriya, R.S.; Suganya, R.; Nathan, S.; Perumal, P.S. A Comparative Assessment of Deep Neural Network Models for Detecting Obstacles in the Real Time Aerial Railway Track Images. Appl. Artif. Intell. 2022, 36, 2018184. [Google Scholar] [CrossRef]
- Li, X.; Zhu, L.; Yu, Z.; Guo, B.; Wan, Y. Vanishing Point Detection and Rail Segmentation Based on Deep Multi-Task Learning. IEEE Access 2020, 8, 163015–163025. [Google Scholar] [CrossRef]
- Šilar, Z.; Dobrovolný, M. The obstacle detection on the railway crossing based on optical flow and clustering. In Proceedings of the 2013 36th International Conference on Telecommunications and Signal Processing (TSP), Rome, Italy, 2–4 July 2013; pp. 755–759. [Google Scholar] [CrossRef]
- Gong, T.; Zhu, L. Edge Intelligence-based Obstacle Intrusion Detection in Railway Transportation. In Proceedings of the GLOBECOM 2022—2022 IEEE Global Communications Conference (GLOBECOM), Rio de Janeiro, Brazil, 4–8 December 2022; pp. 2981–2986. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Soilán, M.; Nóvoa, A.; Sánchez-Rodríguez, A.; Justo, A.; Riveiro, B. Fully automated methodology for the delineation of railway lanes and the generation of IFC alignment models using 3D point cloud data. Autom. Constr. 2021, 126, 103684. [Google Scholar] [CrossRef]
- Sahebdivani, S.; Arefi, H.; Maboudi, M. Rail Track Detection and Projection-Based 3D Modeling from UAV Point Cloud. Sensors 2020, 20, 5220. [Google Scholar] [CrossRef] [PubMed]
- Cserép, M.; Demján, A.; Mayer, F.; Tábori, B.; Hudoba, P. Effective railroad fragmentation and infrastructure recognition based on dense lidar point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 2, 103–109. [Google Scholar] [CrossRef]
- Karunathilake, A.; Honma, R.; Niina, Y. Self-Organized Model Fitting Method for Railway Structures Monitoring Using LiDAR Point Cloud. Remote Sens. 2020, 12, 3702. [Google Scholar] [CrossRef]
- Han, F.; Liang, T.; Ren, J.; Li, Y. Automated Extraction of Rail Point Clouds by Multi-Scale Dimensional Features From MLS Data. IEEE Access 2023, 11, 32427–32436. [Google Scholar] [CrossRef]
- Sánchez-Rodríguez, A.; Riveiro, B.; Soilán, M.; González-deSantos, L. Automated detection and decomposition of railway tunnels from Mobile Laser Scanning Datasets. Autom. Constr. 2018, 96, 171–179. [Google Scholar] [CrossRef]
- Yu, X.; He, W.; Qian, X.; Yang, Y.; Zhang, T.; Ou, L. Real-time rail recognition based on 3D point clouds. Meas. Sci. Technol. 2022, 33, 105207. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, G.; Chen, P.; Zhou, B.; Yang, S. FarNet: An Attention-Aggregation Network for Long-Range Rail Track Point Cloud Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 13118–13126. [Google Scholar] [CrossRef]
- Qu, J.; Li, S.; Li, Y.; Liu, L. Research on Railway Obstacle Detection Method Based on Developed Euclidean Clustering. Electronics 2023, 12, 1175. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar] [CrossRef]
- Hussain, M.; Ali, N.; Hong, J.E. DeepGuard: A framework for safeguarding autonomous driving systems from inconsistent behaviour. Autom. Softw. Eng. 2022, 29, 1. [Google Scholar] [CrossRef]
- Liu, Z.; Cai, Y.; Wang, H.; Chen, L.; Gao, H.; Jia, Y.; Li, Y. Robust Target Recognition and Tracking of Self-Driving Cars With Radar and Camera Information Fusion Under Severe Weather Conditions. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6640–6653. [Google Scholar] [CrossRef]
- Stocco, A.; Tonella, P. Towards Anomaly Detectors that Learn Continuously. In Proceedings of the 2020 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Coimbra, Portugal, 12–15 October 2020; pp. 201–208. [Google Scholar] [CrossRef]
- Alexiou, E.; Ebrahimi, T. Towards a Point Cloud Structural Similarity Metric. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Meynet, G.; Nehmé, Y.; Digne, J.; Lavoué, G. PCQM: A Full-Reference Quality Metric for Colored 3D Point Clouds. In Proceedings of the 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX), Athlone, Ireland, 26–28 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Meynet, G.; Digne, J.; Lavoué, G. PC-MSDM: A quality metric for 3D point clouds. In Proceedings of the 2019 Eleventh International Conference on Quality of Multimedia Experience (QoMEX), Berlin, Germany, 5–7 June 2019; pp. 1–3. [Google Scholar] [CrossRef]
- Lu, Z.; Huang, H.; Zeng, H.; Hou, J.; Ma, K.K. Point Cloud Quality Assessment via 3D Edge Similarity Measurement. IEEE Signal Process. Lett. 2022, 29, 1804–1808. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, W.; Min, X.; Wang, T.; Lu, W.; Zhai, G. No-Reference Quality Assessment for 3D Colored Point Cloud and Mesh Models. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7618–7631. [Google Scholar] [CrossRef]
- Liu, Q.; Yuan, H.; Su, H.; Liu, H.; Wang, Y.; Yang, H.; Hou, J. PQA-Net: Deep No Reference Point Cloud Quality Assessment via Multi-View Projection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4645–4660. [Google Scholar] [CrossRef]
- Viola, I.; Cesar, P. A Reduced Reference Metric for Visual Quality Evaluation of Point Cloud Contents. IEEE Signal Process. Lett. 2020, 27, 1660–1664. [Google Scholar] [CrossRef]
- Zhou, W.; Yue, G.; Zhang, R.; Qin, Y.; Liu, H. Reduced-Reference Quality Assessment of Point Clouds via Content-Oriented Saliency Projection. IEEE Signal Process. Lett. 2023, 30, 354–358. [Google Scholar] [CrossRef]
- Kim, J.; Park, B.j.; Kim, J. Empirical Analysis of Autonomous Vehicle’s LiDAR Detection Performance Degradation for Actual Road Driving in Rain and Fog. Sensors 2023, 23, 2972. [Google Scholar] [CrossRef]
- Montalban, K.; Reymann, C.; Atchuthan, D.; Dupouy, P.E.; Riviere, N.; Lacroix, S. A Quantitative Analysis of Point Clouds from Automotive Lidars Exposed to Artificial Rain and Fog. Atmosphere 2021, 12, 738. [Google Scholar] [CrossRef]
- Piroli, A.; Dallabetta, V.; Kopp, J.; Walessa, M.; Meissner, D.; Dietmayer, K. Energy-Based Detection of Adverse Weather Effects in LiDAR Data. IEEE Robot. Autom. Lett. 2023, 8, 4322–4329. [Google Scholar] [CrossRef]
- Li, Y.; Duthon, P.; Colomb, M.; Ibanez-Guzman, J. What Happens for a ToF LiDAR in Fog? IEEE Trans. Intell. Transp. Syst. 2021, 22, 6670–6681. [Google Scholar] [CrossRef]
- Delecki, H.; Itkina, M.; Lange, B.; Senanayake, R.; Kochenderfer, M.J. How Do We Fail? Stress Testing Perception in Autonomous Vehicles. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 5139–5146. [Google Scholar] [CrossRef]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:abs/1503.02531. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, X.; Hong, X.; Zhang, F. Pixel-Level Extrinsic Self Calibration of High Resolution LiDAR and Camera in Targetless Environments. IEEE Robot. Autom. Lett. 2021, 6, 7517–7524. [Google Scholar] [CrossRef]
- Jaritz, M.; Vu, T.H.; de Charette, R.; Wirbel, E.; Pérez, P. xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12602–12611. [Google Scholar] [CrossRef]
- Xiong, R.; Yang, Y.; He, D.; Zheng, K.; Zheng, S.; Xing, C.; Zhang, H.; Lan, Y.; Wang, L.; Liu, T.Y. On Layer Normalization in the Transformer Architecture. arXiv 2020, arXiv:cs.LG/2002.04745. [Google Scholar]
- Graham, B.; Engelcke, M.; Maaten, L.v.d. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9224–9232. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Wang, F.; Liu, H. Understanding the Behaviour of Contrastive Loss. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 2495–2504. [Google Scholar] [CrossRef]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The Lovasz-Softmax Loss: A Tractable Surrogate for the Optimization of the Intersection-Over-Union Measure in Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4413–4421. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIoU | Rail | Sleeper | Gravel | Plant | Person | Building | Pole | Obstacle |
|---|---|---|---|---|---|---|---|---|---|
| PVKD [21] | 61.1 | 71.9 | 56.3 | 82.3 | 28.8 | 65.1 | 47.9 | 80.5 | 56.8 |
| Cylinder3D [22] | 67.2 | 81.6 | 75.1 | 88.9 | 50.1 | 49.2 | 48.4 | 78.8 | 65.4 |
| SPVCNN [23] | 83.5 | 87.3 | 78.7 | 92.5 | 82.2 | 78.9 | 85.1 | 87.2 | 76.3 |
| MinkowskiNet [24] | 80.3 | 86.7 | 76.6 | 91.8 | 80.2 | 76.6 | 69.7 | 89.8 | 68.3 |
| DHT-CL * | 87.3 | 89.4 | 83.7 | 94.4 | 90.2 | 83.2 | 80.4 | 94.2 | 83.3 |
| Method | Memory (MB) | Speed (ms) |
|---|---|---|
| PVKD [21] | 15,606 | 542 |
| Cylinder3D [22] | 17,436 | 540 |
| SPVCNN [23] | 4064 | 205 |
| MinkowskiNet [24] | 3308 | 196 |
| DHT-CL * | 4064 | 205 |
| Method | mIoU | Rail | Sleeper | Gravel | Plant | Person | Building | Pole | Obstacle |
|---|---|---|---|---|---|---|---|---|---|
| xMUDA [76] | 84.2 | 88.5 | 81.8 | 93.6 | 86.7 | 79.6 | 78.6 | 87.2 | 77.3 |
| 2DPASS [19] | 85.4 | 89.1 | 82.0 | 93.8 | 88.2 | 79.4 | 84.0 | 88.8 | 77.7 |
| DHT-CL * | 87.3 | 89.4 | 83.7 | 94.4 | 90.2 | 83.2 | 80.4 | 94.2 | 83.3 |
| Baseline | 2D Naive Contrast Learning | DHT Module | Adaptive Scaling Factor | mIoU | mAcc | IoU of “Unknown Obstacle” |
|---|---|---|---|---|---|---|
| √ | 83.57 | 93.96 | 76.34 | |||
| √ | √ | 85.07 | 94.72 | 77.30 | ||
| √ | √ | √ | 86.24 | 94.97 | 81.35 | |
| √ | √ | √ | √ | 87.38 | 95.15 | 83.33 |
| LiDAR Only | LiDAR + Camera | |
|---|---|---|
| Missed alarm (MA) rate | 1.72% | 0.00% |
| False alarm (FA) rate | 2.67% | 0.48% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, L.; Peng, Y.; Lin, M.; Gan, N.; Tan, R. Multi-Modal Contrastive Learning for LiDAR Point Cloud Rail-Obstacle Detection in Complex Weather. Electronics 2024, 13, 220. https://doi.org/10.3390/electronics13010220
Wen L, Peng Y, Lin M, Gan N, Tan R. Multi-Modal Contrastive Learning for LiDAR Point Cloud Rail-Obstacle Detection in Complex Weather. Electronics. 2024; 13(1):220. https://doi.org/10.3390/electronics13010220
Chicago/Turabian StyleWen, Lu, Yongliang Peng, Miao Lin, Nan Gan, and Rongqing Tan. 2024. "Multi-Modal Contrastive Learning for LiDAR Point Cloud Rail-Obstacle Detection in Complex Weather" Electronics 13, no. 1: 220. https://doi.org/10.3390/electronics13010220
APA StyleWen, L., Peng, Y., Lin, M., Gan, N., & Tan, R. (2024). Multi-Modal Contrastive Learning for LiDAR Point Cloud Rail-Obstacle Detection in Complex Weather. Electronics, 13(1), 220. https://doi.org/10.3390/electronics13010220