
FOLD: Low-Level Image Enhancement for Low-Light Object Detection Based on FPGA MPSoC



Abstract
:1. Introduction
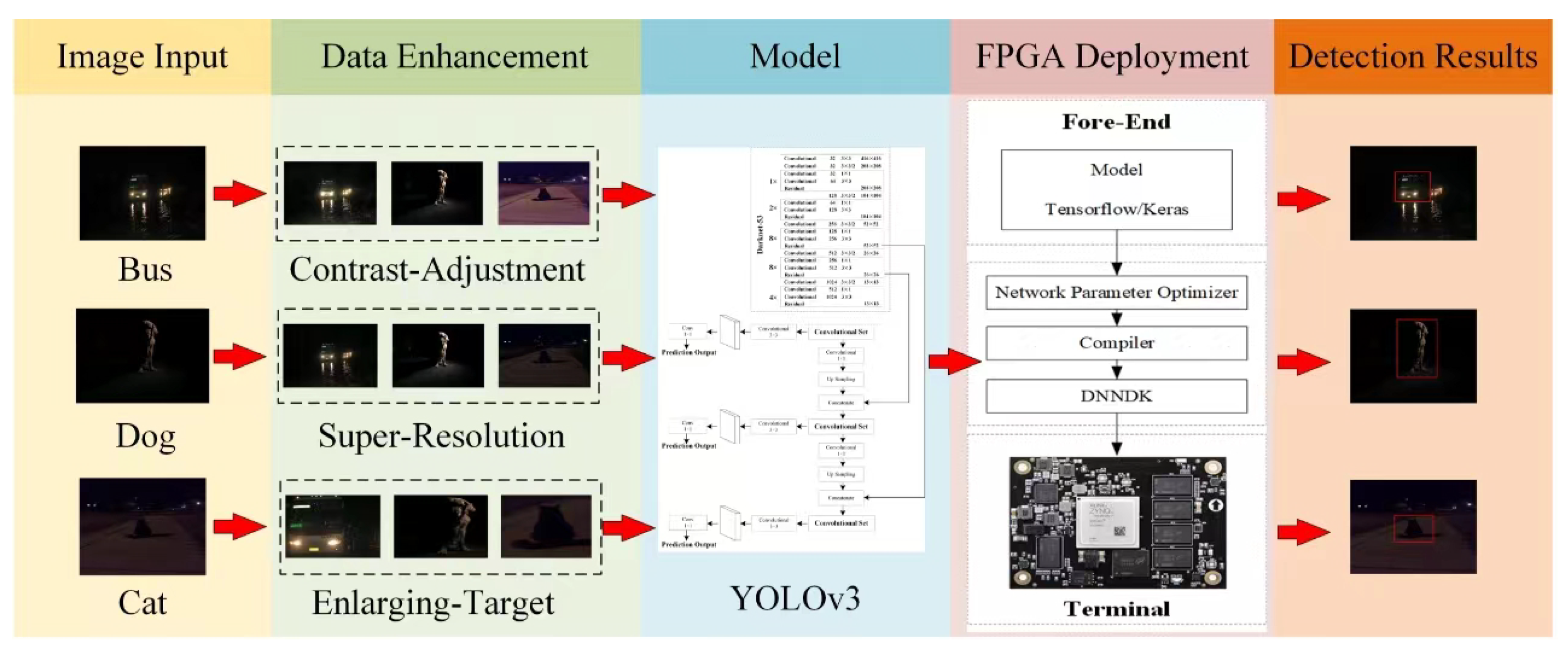
- Three low-order data augmentation techniques were used to augment ExDark and realistically acquired low-light image data to expand the training dataset.
- The YOLOv3 target detection model based on PyTorch was deployed on FPGA MPSoC for improving target detection performance.
- Low-light image enhancement and target detection models have been combined to solve the target detection problem in low-light scenes.
2. Related Work
2.1. Low-Light Image Enhancement
2.2. Deployment of Object Detection Models at the Edge
3. Training Datasets and Enhancement Technology
3.1. Low-Light Image Training Datasets
3.2. Low-Level Image Enhancement
4. Implementation of Model Deployment on MPSoC
5. Experiment Results and Analysis
5.1. Experiment Setup
5.2. Datasets and Evaluation Indicators
5.2.1. Datasets
5.2.2. Evaluation Indicators
5.3. Experimental Results and Analysis
5.3.1. Comparison of Detection Performance
5.3.2. Comparison of Computational Performance
5.3.3. Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X.; et al. T-CNN: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2896–2907. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Liao, Y.; Ding, X.; Paisley, J. A fusion-based enhancing method for weakly illuminated images. Signal Process. 2016, 129, 82–96. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; Xie, X. LLCNN: A convolutional neural network for low-light image enhancement. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Wang, D.; Niu, X.; Dou, Y. A piecewise-based contrast enhancement framework for low lighting video. In Proceedings of the 2014 IEEE International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Wuhan, China, 18–19 October 2014; pp. 235–240. [Google Scholar]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef] [PubMed]
- Godard, C.; Matzen, K.; Uyttendaele, M. Deep burst denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 538–554. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W. Deep Retinex decomposition for low-light enhancement. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–12. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. EEMEFN: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13106–13113. [Google Scholar]
- da Costa, G.B.P.; Contato, W.A.; Nazare, T.S.; Neto, J.E.S.B.; Ponti, M. An empirical study on the effects of different types of noise in image classification tasks. arXiv 2016, arXiv:1609.02781. [Google Scholar]
- Yuan, C.; Hu, W.; Tian, G.; Yang, S.; Wang, H. Multi-task sparse learning with Beta process prior for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 423–429. [Google Scholar]
- Kvyetnyy, R.; Maslii, R.; Harmash, V.; Bogach, I.; Kotyra, A.; Gradz, Z.; Zhanpeisova, A.; Askarova, N. Object Detection in Images with Low Light Condition. In Photonics Applications in Astronomy Communications Industry and High Energy Physics Experiments, International Society for Optics and Photonics; SPIE: Bellingham, WA, USA, 2017; Volume 10445, p. 104450W. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Ovtcharov, K.; Ruwase, O.; Kim, J.-Y.; Fowers, J.; Strauss, K.; Chung, E.S. Accelerating deep convolutional neural networks using specialized hardware. Microsoft Res. Whitepap. 2015, 2, 1–4. [Google Scholar]
- Nurvitadhi, E.; Venkatesh, G.; Sim, J.; Marr, D.; Huang, R.; Ong Gee Hock, J.; Liew, Y.; Srivatsan, K.; Moss, D.; Subhaschandra, S.; et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks? In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), Monterey, CA, USA, 22–24 February 2017; pp. 5–14. [Google Scholar]
- Zhao, R.; Song, W.; Zhang, W.; Xing, T.; Lin, J.-H.; Srivastava, M.; Gupta, R.; Zhang, Z. Accelerating binarized convolutional neural networks with software-programmable FPGAs. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 15–24. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the exclusively dark dataset. Comput. Vis. Image Understand. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, P.; Li, M.; Ren, S. FPGA Implementation of Video Enhancement Algorithm in Low Illumination Conditions. Bandaoti Guangdian/Semiconduct. Optoelectron. 2017, 38, 754–757. [Google Scholar]
- Rubinstein, M.; Shamir, A.; Avidan, S. Improved seam carving for video retargeting. Proc. ACM SIGGRAPH Pap. 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.T.; Cao, Y.; Hu, H.; Guo, B.N. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Xilinx: Vitis AI User Guide (UG1414). Available online: https://docs.xilinx.com/r/en-US/ug1414-vitis-ai/Vitis-AI-Overview/ (accessed on 13 March 2023).
- FLIR: Flir Thermal Dataset for Algorithm Training. Available online: https://www.flir.in/oem/adas/adas-dataset-form/ (accessed on 29 December 2023).
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- Chen, C.; Mo, J.; Hou, J.; Wu, H.; Liao, L.; Sun, W.; Yan, Q.; Weisi Lin, W. TOPIQ: A Top-down Approach from Semantics to Distortions for Image Quality Assessment. arXiv 2023, arXiv:2308.03060. [Google Scholar]
- Liao, L.; Xiao, J.; Wang, Z.; Lin, C.W.; Satoh, S. Guidance and Evaluation: Semantic-Aware Image Inpainting for Mixed Scenes. In Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; ECCV 2020, Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12372. [Google Scholar] [CrossRef]
- Fang, Q.; Han, D.; Wang, Z. Cross-modality fusion transformer for multispectral object detection. arXiv 2021, arXiv:2111.00273. [Google Scholar] [CrossRef]
- Yan, C.; Zhang, H.; Li, X.; Yang, Y.; Yuan, D. Cross-modality complementary information fusion for multispectral pedestrian detection. Neural Comput. Appl. 2023, 35, 10361–10386. [Google Scholar] [CrossRef]
- Shu, Z.; Zhang, Z.; Song, Y. Low light image object detection based on improved YOLOv5. Prog. Laser Optoelectron. 2023, 60, 8. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Data | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| YOLOv3 | DarkNet | RGB | 0.834 | 0.373 | 0.421 |
| YOLOv5 | CSPDarkNet | RGB | 0.893 | 0.507 | 0.503 |
| CFT | CSPDarkNet | RGB+T | 0.955 | 0.717 | 0.628 |
| CCIFNet | ResNet50 | RGB+T | 0.969 | 0.736 | 0.651 |
| LIME + YOLOv3 | DarkNet | RGB | 0.959 | 0.741 | 0.659 |
| LIME + YOLOv5 | CSPDarkNet | RGB | 0.961 | 0.743 | 0.660 |
| DCE_ZERO + YOLOv3 | DarkNet | RGB | 0.955 | 0.738 | 0.656 |
| DCE_ZERO + YOLOv5 | CSPDarkNet | RGB | 0.951 | 0.732 | 0.654 |
| FOLD | DarkNet | RGB | 0.971 | 0.743 | 0.662 |
| Method | Backbone | Data | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| YOLOv3 | DarkNet | RGB | 0.850 | 0.369 | 0.431 |
| YOLOv5 | CSPDarkNet | RGB | 0.897 | 0.524 | 0.502 |
| CFT | CSPDarkNet | RGB + T | 0.971 | 0.722 | 0.638 |
| CCIFNet | ResNet50 | RGB + T | 0.970 | 0.728 | 0.631 |
| LIME + YOLOv3 | DarkNet | RGB | 0.963 | 0.761 | 0.621 |
| LIME + YOLOv5 | CSPDarkNet | RGB | 0.970 | 0.758 | 0.603 |
| DCE_ZERO + YOLOv3 | DarkNet | RGB | 0.961 | 0.752 | 0.591 |
| DCE_ZERO + YOLOv5 | CSPDarkNet | RGB | 0.943 | 0.697 | 0.593 |
| FOLD | DarkNet | RGB | 0.972 | 0.773 | 0.651 |
| Method | Backbone | Data | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| YOLOv3 | DarkNet | RGB | 0.839 | 0.368 | 0.429 |
| YOLOv5 | CSPDarkNet | RGB | 0.918 | 0.539 | 0.525 |
| CFT | CSPDarkNet | RGB + T | 0.972 | 0.727 | 0.638 |
| CCIFNet | ResNet50 | RGB + T | 0.974 | 0.727 | 0.645 |
| LIME + YOLOv3 | DarkNet | RGB | 0.966 | 0.756 | 0.684 |
| LIME + YOLOv5 | CSPDarkNet | RGB | 0.976 | 0.760 | 0.688 |
| DCE_ZERO + YOLOv3 | DarkNet | RGB | 0.969 | 0.750 | 0.677 |
| DCE_ZERO + YOLOv5 | CSPDarkNet | RGB | 0.971 | 0.752 | 0.674 |
| FOLD | DarkNet | RGB | 0.977 | 0.753 | 0.681 |
| Method | Backbone | Data | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| YOLOv3 | DarkNet | RGB | 0.869 | 0.380 | 0.434 |
| YOLOv5 | CSPDarkNet | RGB | 0.910 | 0.521 | 0.511 |
| CFT | CSPDarkNet | RGB + T | 0.968 | 0.723 | 0.632 |
| CCIFNet | ResNet50 | RGB + T | 0.965 | 0.719 | 0.632 |
| LIME + YOLOv3 | DarkNet | RGB | 0.969 | 0.764 | 0.671 |
| LIME + YOLOv5 | CSPDarkNet | RGB | 0.971 | 0.776 | 0.674 |
| DCE_ZERO + YOLOv3 | DarkNet | RGB | 0.962 | 0.767 | 0.669 |
| DCE_ZERO + YOLOv5 | CSPDarkNet | RGB | 0.968 | 0.769 | 0.672 |
| FOLD | DarkNet | RGB | 0.976 | 0.776 | 0.678 |
| Datasets | FLIR | LLVIP | ExDark | Real-Image | Avg. | |
|---|---|---|---|---|---|---|
| Onboard | ||||||
| FPGA MPSoC | 92 | 89 | 85 | 83 | 87.25 | |
| RK3588 | 49 | 46 | 45 | 43 | 45.75 | |
| Raspberry Pi | 12 | 11 | 11 | 8 | 10.5 | |
| Atlas | 18 | 16 | 16 | 15 | 16.25 | |
| Onboard | CE | PT (ms) | PC (W) |
|---|---|---|---|
| FPGA MPSoC | 12.46 | 11.45 | 7.0 |
| RK3588 | 6.35 | 21.86 | 7.2 |
| Raspberry Pi | 1.64 | 95.23 | 6.4 |
| Atlas | 2.95 | 61.54 | 5.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Li, Z.; Zhou, L.; Huang, Z. FOLD: Low-Level Image Enhancement for Low-Light Object Detection Based on FPGA MPSoC. Electronics 2024, 13, 230. https://doi.org/10.3390/electronics13010230
Li X, Li Z, Zhou L, Huang Z. FOLD: Low-Level Image Enhancement for Low-Light Object Detection Based on FPGA MPSoC. Electronics. 2024; 13(1):230. https://doi.org/10.3390/electronics13010230
Chicago/Turabian StyleLi, Xiang, Zeyu Li, Lirong Zhou, and Zhao Huang. 2024. "FOLD: Low-Level Image Enhancement for Low-Light Object Detection Based on FPGA MPSoC" Electronics 13, no. 1: 230. https://doi.org/10.3390/electronics13010230
APA StyleLi, X., Li, Z., Zhou, L., & Huang, Z. (2024). FOLD: Low-Level Image Enhancement for Low-Light Object Detection Based on FPGA MPSoC. Electronics, 13(1), 230. https://doi.org/10.3390/electronics13010230