1. Introduction
Event extraction (EE), a significant branch of information extraction (IE), contains two subtasks: viz., event detection and argument extraction. Different from previous classification paradigms, some researchers have formulated EE as a machine reading comprehension (MRC) task [
1,
2,
3]. MRC-based event extraction approaches can take advantage of existing progress of MRC models and are promising for tackling zero-shot or few-shot EE [
4,
5].
Although MRC-based EE methods perform better than previous approaches, they still have some shortcomings. Existing MRC-based methods regard event detection and argument extraction as independent tasks, e.g., two-turn QA [
1,
2] or textual entailment for event detection and MRC for argument extraction [
4,
5]. These pipeline methods result in error propagation. Moreover, pre-defined correlation between event types and arguments is required. As shown on the left side of
Figure 1, when given a sentence, the pipeline models first identify its event type and then generate question–answer pairs of specific arguments that appear in this event type based on the pre-defined event ontology. These methods rely on external knowledge from experts, which is time-consuming and inflexible when transferring to new domains.
To face the challenges to the pipeline MRC framework, we tackle event detection and extraction tasks jointly with an end-to-end MRC model. Different from previous pipeline methods based on pre-defined event ontology, we propose a novel question generation mechanism using reverse thinking. As shown on the right side of
Figure 1, questions are generated for all argument roles in the dataset. Event types are backward reasoned in the MRC process by identifying whether questions for specific arguments have answers. For instance, if questions for
Attacker (Q1) or
Target (Q29) have answers, event types are probably
Attack. In turn, for the
Attack event, questions for
Giver (Q3) and
Recipient (Q31) have no answers. This backward reasoning mechanism can learn the constraint relationships between event types and argument roles automatically without external knowledge from experts.
Moreover, we introduce the JEEMRC (
Joint
Event
Extraction via end-to-end
Machine
Reading
Comprehension) model, which contains two main modules: an event classifier and a machine reader. (The code is publicly available at:
https://github.com/lisa633/JEEMRC, accessed on 30 April 2024.) Specifically, a coarse-to-fine attention mechanism is designed in the machine reader module of JEEMRC. Coarse attention is utilized for the output of the event classifier to make JEEMRC focus on the specific event types. Fine attention computes the similarity between event types and each word embedding in the given sentence. With this coarse-to-fine attention, our JEEMRC is able to extract correlations between event types and argument roles effectively. To realize joint training, state-aware weights are set for both the event classifier and the machine reader. At last, a heuristic approach is introduced to refine the results.
Overall, this article consists of three main contributions:
We propose a new paradigm to handle the task of event detection and argument extraction jointly. Different from previous pipeline methods [
1,
2,
4,
5], we formalize the task as joint machine reading comprehension, which can alleviate error propagation and improve the performance for both tasks.
An end-to-end MRC model, JEEMRC, is introduced, which is able to tackle EE without labeling event triggers. With a coarse-to-fine attention mechanism, JEEMRC can learn the correlations between event types and arguments automatically and generate reasonable results that satisfy these constraint relationships, reducing the model’s reliance on expert knowledge.
Various experiments are conducted on the ACE 2005 benchmark, and the results illustrate that our method achieves state-of-the-art performance for both a supervised condition and few-shot scenarios.
The rest of this article is organized as follows:
Section 2 introduces some related work. Our proposed JEEMRC model is described in
Section 3.
Section 4 details the dataset and experimental results, and
Section 5 analyzes the results in different dimensions. We conclude this article in
Section 6.
2. Related Work
In this section, research closely related to our work—viz., joint event extraction, few/zero-shot event extraction, and machine reading comprehension for IE—is introduced in detail.
2.1. Joint Event Extraction
Event extraction generally consists of two subtasks: event detection and argument extraction. Some traditional methods tackle these two tasks in the pipeline manner [
6,
7], which can suffer from the error propagation problem and can upgrade the performance of extracting arguments. To deal with the above challenges, joint EE approaches with deep neural models have been introduced, such as techniques using recurrent neural networks [
8,
9], convolutional neural networks [
10], graph neural networks [
11,
12], and attention mechanisms [
13,
14]. Joint EE models are able to mitigate the effect of error propagation and learn the correlations between event types and argument roles automatically without pre-defined event ontology.
Despite many advances, most previous joint models formulate EE as a classification task and suffer from data scarcity problems. MRC-based EE does well with dealing with few-shot scenarios and new event types. However, existing MRC-based EE models are all in a pipeline manner, which cannot avoid the effect of error propagation. Different from the above two approaches, our JEEMRC is able to tackle the data scarcity problem and the error propagation problem simultaneously.
2.2. Few/Zero-Shot Event Extraction
Event extraction, the goal of which is to extract arguments from sentences that describe events, has been modeled as a classification task previously and has been tackled by supervised approaches [
6,
8,
10,
15,
16]. However, these methods are data-hungry and cannot identify new types without manual annotations. EE in low-resource scenarios has given rise to unsupervised models. Peng et al. [
17] proposed a method to detect events by measuring the similarities between event structures, which are generated by semantic role labeling and requires minimal supervision. Likewise, structure information of event ontology was applied by Huang et al. [
18], who projected event mentions and types into a low-dimension space with abstract meaning representation and transferred knowledge of annotated events to unseen types. For few-shot event detection, Lai et al. [
19] employed matching information from given seen types with introducing two extra factors to the loss function, while Deng et al. [
20] encoded contextual information of event mentions with a dynamic memory network to enhance robustness in data-scarce scenarios. Owing to the abundance of labeled data for other NLP tasks, e.g., MNLI [
21] for text entailment and SQuAD2.0 [
22] for MRC, Lyu et al. [
4] and Feng et al. [
5] conducted zero-shot or few-shot EE by modeling event detection as textual entailment or yes/no QA and argument identification as extractive MRC.
Inspired by previous work, our proposed model makes full use of annotated MRC samples for pre-training and transfers knowledge of QA to EE by transforming event detection and argument extraction into joint MRC.
2.3. Machine Reading Comprehension for IE
Owing to the flourishing development of deep learning, a number of neural MRC models, such as Bi-DAF [
23], QANet [
24], R-Trans [
25], and R-Net [
26], have been proposed and even outperform human beings on specific MRC tasks. As a common way for humans to understand things, MRC, an important branch of question answering (QA), can be analogized to the field of information extraction (IE): it entails obtaining relevant information by asking questions. Changing IE into an MRC framework allows us to apply the existing achievements of MRC and tackle the challenges of few-shot scenarios, e.g., the finding of new types.
In 2017, Levy et al. [
27] first transformed relation extraction (RE) into an MRC task, in which questions were generated by the template with given head entities and relations, while corresponding tail entities were required to be extracted from the context as answers to questions. Afterwards, Li et al. [
28] employed MRC to named entity recognition (NER) to introduce prior knowledge of event types and deal with overlapping entities. Xiong et al. [
29] and Sun et al. [
30] used an MRC framework to identify entities in biomedicine and medicine. Both of them chose a BERT-based MRC model, but they generated questions according to specific domains and corpora. MRC-based methods have also been applied to joint entity and relation extraction. Li et al. [
31] regarded entity and relation extraction as multi-turn QA. Firstly, they generated questions for head entities. Then, relations were questioned based on head entities to find out tail entities. Reinforcement learning was employed to optimize the process of multi-turn QA.
Event extraction, as a significant subtask of IE, can also be tackled by an MRC framework. For sentence-level EE, Du and Cardie [
1] questioned triggers and arguments through two turns of QA. Question words adjusted different argument types. In order to break through the limitation of question templates, Liu et al. [
2] denoted question generation as unsupervised translation, which obtained more natural questions for EE tasks.
Existing MRC-based EE methods regard event detection and event argument extraction as two independent tasks and transform them into multi-turn QA. However, these two tasks are sequentially related, and the results of event detection influence the extraction of event arguments. Pipeline methods like multi-turn QA not only result in error propagation, but they also rely on external knowledge of event ontology. However, our joint model can train event classification and argument extraction jointly, which can alleviate the effects of error propagation and can improve the accuracy of two tasks mutually.
3. Methodology
In this section, firstly, we introduce the entire process of how to transform event detection and extraction as joint machine reading comprehension. Then, each step in our approach is decomposed and illustrated in detail.
3.1. Overview
In this article, event detection and extraction tasks are defined as joint machine reading comprehension. As shown in
Figure 2, the inputs for our method contain the role set (which consists of all pre-defined event arguments), documents (which include several sentences, some of which describe events, while others do not), and the pre-designed question template (which is designed for each event argument and has appropriate question words). The first step is question generation, in which sentences in the given document are changed to question–answer pairs based on the role set and question template. Then, the question–answer pairs are fed to our JEEMRC model, where event classification and machine reading comprehension are trained jointly with state-aware weights. Also, the correlation between event types and argument roles guides the output of the model. Finally, each sentence is identified based on whether it describes events or not. If it does, our model outputs the event type and corresponding argument roles. Otherwise,
None is output as the result, and the answer list is null.
3.2. Question Generation
The generation of question–answer pairs is an indispensable step when formulating EE as an MRC task. Following previous work [
1], we generate questions based on well-designed templates. As some examples in
Table 1 show, question words change according to different types of arguments, e.g.,
When for
Time and
Who for
Victim. Moreover, prior knowledge of argument roles can be introduced to the MRC models as clues to improve the performance of EE.
Different from previous approaches, which regard event detection and argument extraction as two independent subtasks and just generate questions for arguments that appear in the given sentence, questions are generated for all argument roles in the dataset in our joint model. As presented in Algorithm 1, when given a sentence, we first identify whether it describes events or not. If it does, we go through all argument roles in the dataset and generate corresponding questions based on templates. Then, if the provided sentence contains the argument, the mention of that argument is labeled as the answer; otherwise, the answer list is null. If the sentence does not describe events, we randomly select a pre-defined number of argument roles to generate questions, and answer lists to those questions are null.
| Algorithm 1 Question Generation Method |
| Require: QuesTemplates; RolesList; Sentence S; k |
| Ensure: a list of list QA = [ ] |
| 1: if S is event, then |
| 2: for argument_role in RolesList, do |
| 3: if argument_role in S, then |
| 4: q = GenQues(QuesTemplates,argument_role) |
| 5: a = argument_role |
| 6: QA = QA + {q,a} |
| 7: else |
| 8: q = GenQues(QuesTemplates,argument_role) |
| 9: a = [ ] |
| 10: QA = QA + {q,a} |
| 11: end if |
| 12: end for |
| 13: else |
| 14: count = 0 |
| 15: while count <k do |
| 16: q = GenQues(QuesTemplates,argument_role) |
| 17: a = [ ] |
| 18: QA = QA + {q,a} |
| 19: count += 1 |
| 20: end while |
| 21: end if |
| 22: return QA |
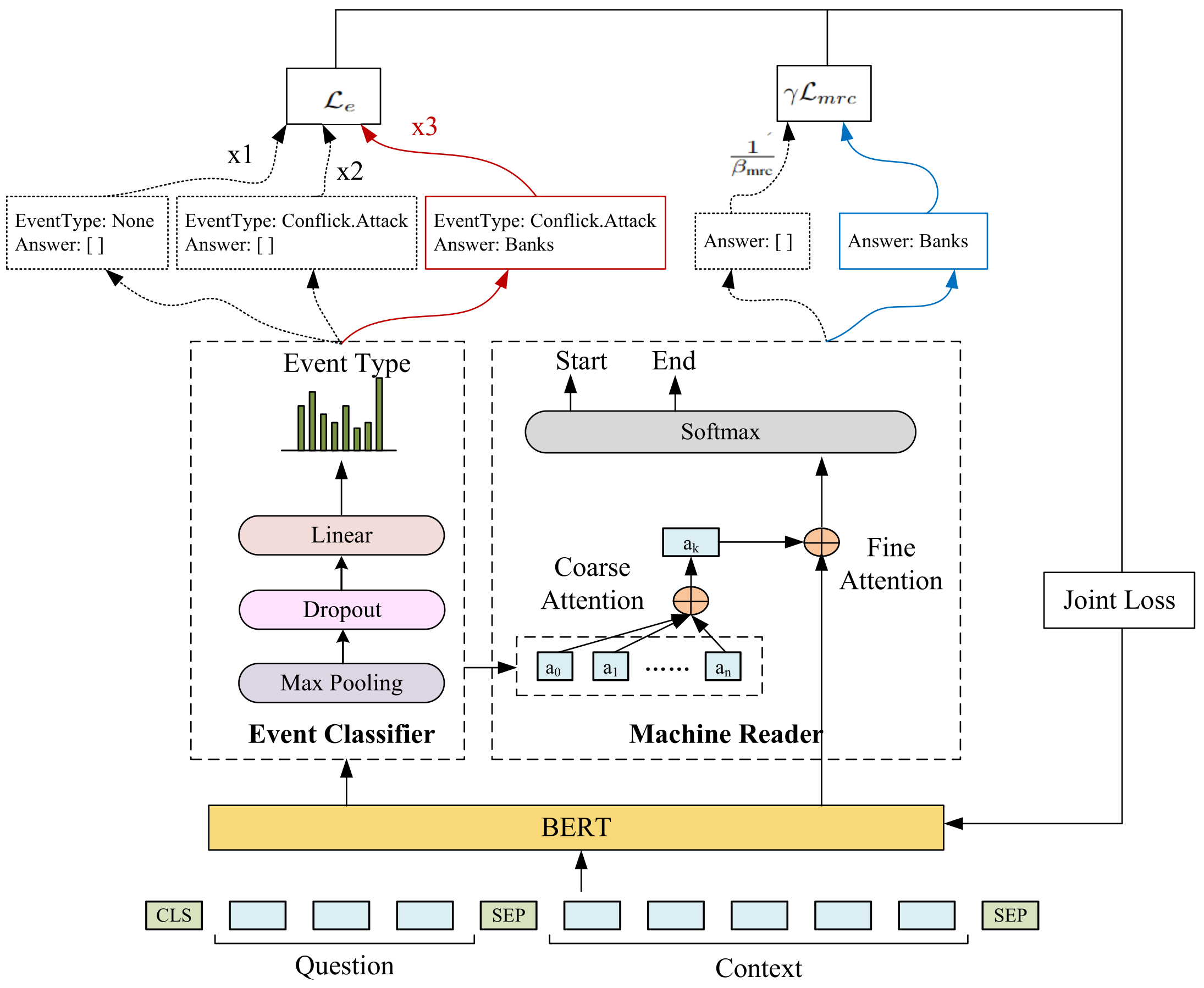
3.3. JEEMRC
As shown in
Figure 3, our proposed JEEMRC (
Joint
Event
Extraction via end-to-end
Machine
Reading
Comprehension) model consists of four modules: viz., encoding, event classifier, machine reader, and joint training.
3.3.1. Encoding
The inputs of the JEEMRC model are the given sentence
S and the question
Q generated in the question generation step. As pre-trained language models have been shown to be superior in most natural language processing (NLP) tasks, we choose BERT [
32] as the basic encoder. The architecture of BERT contains several stacked transformer layers. Its pre-training regimen unfolds in two phases. Phase one, known as masked language modeling (MLM), involves concealing select token positions with the [MASK] token. The model then endeavors to recover the original tokens at these masked sites, grounded on the contextual cues from the rest of the sequence. Proceeding to phase two, next sentence prediction (NSP), the model confronts pairs of sentences that are demarcated by the [SEP] token with the objective of discerning whether they sequentially follow each other in the original text or not. This dual-stage pre-training strategy equips BERT with a profound understanding of linguistic context, enabling its adept application across diverse natural language processing tasks.
The vocabulary of BERT encompasses three special tokens: [CLS], [SEP], and [MASK]. The [CLS] and [SEP] tokens, respectively, denote the beginnings and ends of sequences or act as separators, whereas [MASK] plays a pivotal role in the pre-training phase. When BERT is utilized as an encoder for MRC tasks, question
Q and sentence
S are concatenated with the special tokens [CLS] and [SEP] as
and fed to the BERT model as input. The transformer blocks in the BERT model receive the element-wise addition of token embeddings, segment embeddings, and position embeddings as input and compute the semantic representations as follows:
where
T is the number of transformer blocks.
3.3.2. Event Classifier
The aim of the event classifier module is to predict the event type for the input sentence (
None for the sentence, which does not describe events). To achieve this goal, the output of the BERT encoder is fed to a max pooling layer and a dropout layer in sequence, followed by which, the output is passed through a linear classifier and softmax layer to obtain the logits of event type
:
where
and
are trainable parameters,
is the output of the linear layer, and
e is the total number of event types.
Let
be the set of parameters employed in the event classifier module; we use the negative log probabilities as the loss function:
where
N is the number of training samples, and
is the golden event type.
3.3.3. Machine Reader
In the machine reader module, the correlations between event types and argument roles are first computed by a coarse-to-fine attention mechanism. Based on its result, the module predicts the answer spans, which can be changed into argument mentions.
Coarse-to-fine attention: The correlations between event types and argument roles play a significant role in the EE task. Event types give cues for identifying corresponding arguments, and in turn, arguments make contributions to classifying events. Previous pipeline methods usually utilized these correlations explicitly. They identified the event type first and just generated questions for argument roles for this event type. In this way, the paradigms between event types and argument roles have to be defined in advance by professional experts. Different from that, our proposed JEEMRC is able to learn this mutual influence automatically by the coarse-to-fine attention mechanism.
As questions are generated for all arguments in the dataset, the model will be misled by questions which have no answers: for example, questions about
Giver (Q3) and
Recipient (Q31) in the
Attack event shown in
Figure 1. Coarse attention is utilized to guide JEEMRC to focus on the event type. To be specific, the output of the event classifier is fed to a linear layer to realize this goal. Let
be the output of the event classifier module; the coarse attention can be denoted as:
where
and
are trainable parameters.
Following coarse attention, fine attention is applied to extract the mutual information between event types and arguments. With this information, JEEMRC can identify event types by whether questions about specific arguments have answers. For instance, our proposed model can identify the event type is
Attack by detecting that questions about
Attacker and
Target have answers in the example in
Figure 1. Specifically, the output of coarse attention
and the semantic representations encoded by BERT are fed to the fine attention module to compute the similarity between event types and each word embedding in the given sentence:
where
is the trainable parameter,
is the weight coefficient calculated by the attention mechanism,
M is the number of tokens in the given sentence,
is the activate function, and
is the j-th word representation encoded by the BERT encoder.
Answer predictor: When the EE task is formulated as machine reading comprehension, event arguments are extracted from sentences by answering corresponding questions. As Liu et al. [
33] summarized, the prevalent method to predict answers in MRC is to predict the probabilities of start and end positions. Therefore, our answer predictor applies the softmax function to compute the final output. The loss function of the machine reader module is cross entropy loss. The loss of MRC can be computed as follows:
where
N is the number of training samples, and
and
refer to the golden start and end positions, respectively, of example
i.
3.3.4. Joint Training with State-Aware Weights
To avoid error propagation and also make full use of the correlations between event types and argument roles, the event classifier module and the machine reader module are trained jointly.
Different from previous MRC-based EE methods, we generate questions in reverse thinking, by which questions are generated for all arguments roles in the dataset. However, only questions of arguments in the sentence have answers, which results in us having far more negative samples than positive ones while training. To keep balance in the training data distribution, state-aware weights are set for the event classifier and the machine reader.
When computing event classification loss, we set different weights for these three different conditions in the dataset: 1 for sentences which do not describe events, 2 for sentences that describe events but for which the question about the argument has no answer, and 3 for sentences that describe events and for which the question about the argument has an answer. These state-aware weights can guide JEEMRC to pay more attention to questions that have answers.
In terms of machine reading comprehension loss, the weight parameter of the cross entropy loss function is set as
to reduce the probability of JEEMRC predicting that there is no answer to the question. We compare the performance for different values of
in
Section 5.
Overall, let
be the loss of the event classifier and
represent the loss of the machine reader; the joint loss is calculated as:
where
is a parameter to control the weight of the MRC loss. We conduct experiments using different values of
in
Section 5.
3.4. Post-Processing
By analyzing EE datasets, it can be found that event arguments fall into two categories: event-type-irrelevant and event-type-related. Event-type-irrelevant arguments generally play roles such as place and time, while event-type-related ones are constrained by event types: in other words, some arguments only appear in certain types of event sentences. As per the examples presented in
Table 2, event arguments such as
attacker,
victim, and
instrument are more possibly present in an event about
conflict. However, if the type of event is
movement, it contains arguments like
origin,
destination, and
vehicle.
In order to make arguments extracted by our proposed JEEMRC model satisfy the constraint relationship with the event types, a heuristic approach is introduced to refine the arguments. Firstly, we summarize all event subtypes and their corresponding arguments. Then, when transforming the answer spans extracted by the MRC model into the arguments required by the EE task, we discard spans that do not meet the event type constraint.
In addition, when given a sentence, the question generation module generates questions for all possible event argument types, which are fed to our joint model later. Each input context–question pair is classified into one specific type by the event type classifier. However, one sentence may be judged to be multiple event types because of questions about different arguments. In such cases, the most judged event type is chosen as the final type.
4. Experiments
In this section, the dataset and metrics are introduced in brief at first. Following that, we describe baseline models and experiment settings. Then, experimental results for full supervision and few-shot scenarios are illustrated.
4.1. Dataset and Metrics
We conduct experiments on a widely-used dataset for event extraction, ACE 2005 [
34], which contains articles crawled from various fields, e.g., broadcast conversations, broadcast news, newswire and weblogs, and has been annotated carefully by human with event mentions, triggers, arguments, and co-reference. A total of 33 event subtypes, grounded into 8 event types (Life, Conflict, Movement, Justice, Personnel, Transaction, Business, and Contact) and 35 argument roles are defined in ACE 2005. In particular, roles that represent time, such as
time after, time before, time within, time at beginning, and time at end, are combined as
time in our experiments to avoid perplexing the MRC model, which results in 31 argument roles actually. The dataset is split into three parts—viz., training, validating, and testing sets—according to prior work [
35]. For few-shot training, we extract samples from the whole training set in proportion to event subtypes to guarantee the data distribution remains unchanged.
Following previous research, precision (P), recall (R), and F1 scores are chosen as metrics to evaluate the performance of event detection, argument identification, and classification.
4.2. Baselines
Our proposed model is compared with some baselines to illustrate its effectiveness:
dbRNN [
9]: an RNN-based model for EE proposed by Sha et al. in 2018. Besides RNN, dependency bridges are utilized to enhance the model by extracting syntactic information.
GAIL [
36]: based on generative adversarial imitation learning, Zhang et al. introduce this new framework for joint entities and EE. A novel inverse reinforcement learning approach that utilizes generative adversarial networks is applied in this framework.
DYGIE++ [
35]: based on contextualized span representations such as BERT, Wadden et al. introduce a unified framework that can learn named entity recognition, relation extraction, and event extraction jointly.
BART-GEN [
37]: Li et al. formulate EE as conditional text generation based on event templates and choose BART [
38] as the base encoder–decoder language model.
TEXT2EVENT [
39]: Lu et al. introduce a sequence-to-sequence generation approach to detect events and extract arguments in an end-to-end manner.
TANL [
40]: Paolini et al. transform event extraction to a translation task and propose the TANL model to extract task-relevant information.
GTEE-DYNPREF [
41]: Liu et al. propose a generative event extraction model that can generate type-specific prefixes for each context. GTEE-DYNPREF is able to reduce the influence of suboptimal prompts.
EEQA [
1]: Du et al. formulate EE as two-turn question answering. The first QA extracts event triggers and classifies event types, followed by which, EEQA extracts argument roles during the second turn of QA.
MQAEE [
3]: MQAEE is another QA-based EE method proposed by Li et al. that extracts triggers and arguments by multi-turn QA with answer history embeddings.
BERTEE [
2]: the baseline model, which is applied by Liu et al., only uses BERT as a word representation encoder. For event extraction tasks, classification strategies are adopted.
DMCNN [
10]: an event extraction method utilizes a dynamic multi-pooling CNN for event extraction and was proposed by Chen et al. in 2015.
4.3. Experimental Settings
4.4. Results
Experiments are conduct for two conditions: viz., with full supervision and for few-shot scenarios. The results are presented in the following sections.
4.4.1. Results with Full Supervision
The experimental results on ACE 2005 with full supervision are shown in
Table 4. The first column gives the names of models. The precisions (P), recalls (R), and F1 scores (F1) for event classification (EC), argument identification (AI), and argument classification (AC) are presented in the following columns. The last column is the average of the F1 scores for the three tasks.
As shown in
Table 4, Rows 1 to 4 are the results of some EE models in the classification framework, while Rows 5 and 8 are EE methods in the generation manner. EEQA in Row 9, MQAEE in Row 10, and our proposed model JEEMRC formulated EE models as QA tasks. Different from EEQA and MQAEE, our JEEMRC utilizes the end-to-end MRC model to train event detection and argument extraction jointly. Moreover, our question generation approach is equivalent to data augmentation, which generates more training QA samples for the MRC model. This method does not increase the time complexity of the MRC model. In terms of recall for the three tasks, our JEEMRC outperforms the other baselines except GTEE-DYNPREF. This is because our model, which generates questions for all argument roles in the dataset, is prone to extract arguments from the given sentences as fully as possible. Though high recall scores mean that the precision of our JEEMRC for the three tasks is lower than that of some baselines, our JEEMRC gains the highest F1 scores for the event classification and argument identification tasks. In the argument classification task, the F1 score of JEEMRC is also competitive. Overall, the average score in the last column shows that our JEEMRC model has a more balanced performance in all of the three tasks by training event classification and machine reading comprehension jointly.
4.4.2. Results for Few-Shot Scenarios
Experimental results on ACE 2005 for few-shot scenarios are shown in
Table 5. To simulate data-scarce scenarios, 1%, 5%, 10%, and 20% of the examples from that dataset are selected randomly as the training set. Columns 3 to 6 are the F1 scores for argument extraction for different training sets. Rows 1 to 3 show the results for baseline models, while Rows 4 and 5 are the results for our JEEMRC. The difference between Rows 4 and 5 is that JEEMRC in Row 4 directly applies BERT as the encoder without other training data, while in Row 5, the BERT encoder is first trained on SQuAD 2.0 [
22], which is a dataset for MRC with unanswerable questions.
The results in
Table 5 illustrate that our proposed JEEMRC model outperforms CNN-based, RNN-based, and BERT-based EE methods in few-shot scenarios: for instance, by obtaining a 41.0% F1 score with 20% of the training examples, which is higher than the F1 score of BERTEE by 12.4%. This improvement comes from the MRC framework. By transforming argument extraction into question answering, our model can learn from successful cases in MRC and reduce dependency on labeled data. The results in Rows 4 and 5 illustrate the advantages of transfer learning. In extremely data-scare scenarios, just utilizing BERT as the encoder without other training data does not perform well, e.g., a 0.6% F1 score with 1% of the training examples and a 1.7% F1 score with 5% of the training examples. Compared with that, when the BERT encoder is first trained on SQuAD 2.0, the F1 scores increase to 6.2% and 16.3% with 1% and 5% of the training examples, respectively. By training on SQuAD 2.0 at first, our model learns knowledge from MRC and transfers the knowledge to few-shot EE successfully. This illustrates that the performance of EE in few-shot scenarios can be improved by transferring knowledge of MRC effectively.
5. Analysis
To further analyze the performance of our JEEMRC, various experiments are conducted in this section: viz., an ablation study and comparisons using different attention sizes, state-aware weights, and joint training parameters.
5.1. Ablation Study
In order to verify the contributions of different components to our JEEMRC, ablation experiments are conducted in this section, and the results are presented in
Table 6.
As shown in
Table 6, the second column is components, and Columns 3 to 5 present the F1 scores for event classification, argument classification, and argument identification, respectively. The experimental results for our JEEMRC can be seen in the first row, while the results for ablations are in the following rows. We mainly study the contributions of the heuristic post processing mechanism, the coarse-to-fine attention mechanism, and the weight parameter for cross entropy loss of MRC. Without the heuristic post processing mechanism, the F1 scores for the three tasks decline 1.9%, 0.3%, and 5.7%, respectively. This illustrates that our post processing mechanism, which is mainly based on the constraint relationship between event types and argument roles, is able to improving the performances of event classification and argument classification but has little effect on argument identification. For coarse-to-fine attention, we remove coarse attention and fine attention separately to analyze their contributions. As the results in Rows 3 and 4 show, both coarse and fine attention make contributions to the three tasks, but fine attention is more important. Without fine attention, the F1 scores for the three tasks decrease 3.6%, 8.7%, and 6.6%, respectively. This implies that it is not enough to just pay attention to event types. The interactions between event types and arguments play a significant role in the argument extraction task. When loss weight is removed, namely, the weight parameter for cross entropy loss of MRC is set to 1, the F1 scores for all three tasks drop dramatically: by 15.4%, 18.9%, and 14.4%, respectively. The reason might be that when given a sentence, questions are generated for all argument roles in the dataset. Only questions of arguments in the sentence have answers, which results in the number of negative samples being far more than the number of positive ones in the training data. Therefore, without the loss wight, the machine reader module inclines to predict that there is no answer to the question, and in turn, the performances for event detection and argument extraction are influenced. When the coarse-to-fine attention mechanism and the loss weight are removed together, the performance of JEEMRC is the worst, which demonstrates that both of these components make contributions, and they can complement each other.
5.2. Comparison of Attention Sizes
Table 7 presents the results of different attention sizes. Here, attention sizes mean the number of hidden layers.
From the results shown in
Table 7, when the attention size is set to 454, our model reaches the highest F1 scores for all of the three tasks. Combining the results for all three tasks, 454 is a more appropriate value for JEEMRC, with the highest average score of 61.6%. Overall, the number of hidden layers should not be too much or too few. If the attention size is too small, the model cannot learn the interactive information of event types and argument roles sufficiently. In turn, when the size is too large, the model is too complicated to train well.
5.3. Comparison of State-Aware Weights
To avoid the effect of negative samples and keep balance in training data distribution, state-aware weights are set for the event classifier and the machine reader. In this section, we conduct experiments using different state-aware weights.
5.3.1. State-Aware Weight for Event Classifier
When given a sentence, there are three situations: ① sentence does not describe events; ② sentence describes events, but the question about the argument has no answer; ③ sentence describes events, and the question about the argument has the answer. Different weights are set for these three situations in the event classifier module, and the results are shown in
Table 8.
We can see from
Table 8 that our JEEMRC gains the highest F1 scores for the three tasks and the highest average score of 61.6% when the weights for the three situations are set as 1:2:3. With these weights, the model can pay more attention to questions that have answers in order to improve the performance of joint training, and it is also able to identify event types as
None. When the weight is 1:1:2, it means that we only distinguish whether the question has the answer or not. In this case, JEEMRC does not performs well at event classification tasks. In contrast, when the weight is 1:2:2, we just pay attention to whether the sentence describes events or not, and the performance of JEEMRC for argument classification declines significantly. Moreover, when we assign the same weight for the three cases—namely, the weight is set as 1:1:1—the average score is the lowest compared with the other settings. Experimental results show that to perform well at both event detection and argument extraction, JEEMRC should pay different attention to the three situations above and should focus on those questions that have answers.
5.3.2. Loss Weight for Machine Reader
In our ablation study, the effectiveness of the loss weight is verified, and in this section, experiments are conducted using different values for the loss weight.
It can be seen from the line chart in
Figure 4 that the F1 scores for event classification first increase from 71.9% to 72.5% with the value of the loss weight increasing from 10 to 20; then the F1 scores for event classification show a trend of declining when the loss weight continues to increase after peaking at 73.3%. For argument extraction, a loss weight of 60 gains the highest F1 scores for argument classification and argument identification. Before the value of the loss weight reaches 80, the trends between the F1 scores for all three tasks are roughly the same. When the value of loss weight is 90, our model performs well at event detection, but the F1 score for argument extraction is unsatisfactory. In contrast, the F1 scores for argument identification and classification increase greatly when the value of the loss weight increases to 100, while the performance for event classification declines. On the whole, 60 is a more appropriate value for the loss weight, at which our model can keep balance between event detection and argument extraction.
5.4. Comparison of Joint Training Parameter
In the joint training process, the parameter
is set to control the weight of the MRC loss.
Table 9 presents comparison results using different values of
.
From the results shown in
Table 9, our JEEMRC gains the highest F1 scores for all of the three tasks when the value of the joint training parameter
is set to 4. When the value of
increase from 1 to 4, the trend of the average scores increases. After peaking at 61.6%, the average score begins to decrease when the value of
continues to increase. The experimental results illustrate that 4 is a suitable value for the joint training parameter in order to obtain the best joint training performance.
6. Conclusions
In this article, event detection and argument extraction are formulated as joint machine reading comprehension. To learn these two tasks jointly, the JEEMRC model is introduced. Consisting of two main modules, an event classifier and a machine reader with a coarse-to-fine attention mechanism, JEEMRC can identify event types and extract arguments by answering questions simultaneously without labeling triggers. Our method is able to not only alleviate error propagation but can also utilize the success of previous MRC models, showing competitive performance in data-scarce scenarios. In the future, we will adopt our approach to other transfer learning tasks, i.e., cross-language event detection and extraction.
However, there are still some limitations. We acknowledge that our approach relies on pre-designed question templates, so expert knowledge is required, and when transferring to new datasets, question templates need to be reconstructed. Moreover, our method results in an imbalance between positive and negative samples in the training set. More effective question generation methods should be proposed to tackle these problems in future studies.







{kind=link}
{kind=link}
{kind=link}
{kind=link}