
One-Shot Federated Learning with Label Differential Privacy


Abstract
:1. Introduction
- A method called FedGM is introduced, which utilizes iterative gradient matching to learn a surrogate function. This technique involves transmitting synthesized data to the server rather than sending local model updates, significantly enhancing communication efficiency and effectiveness. Additionally, a novel strategy for selecting the original dataset reduces the number of training rounds required while improving the training effectiveness of the distilled dataset.
- Label differential privacy is employed to protect the privacy of approximate datasets for each client. This method is found to be highly capable even with a small privacy budget and outperforms other methods.
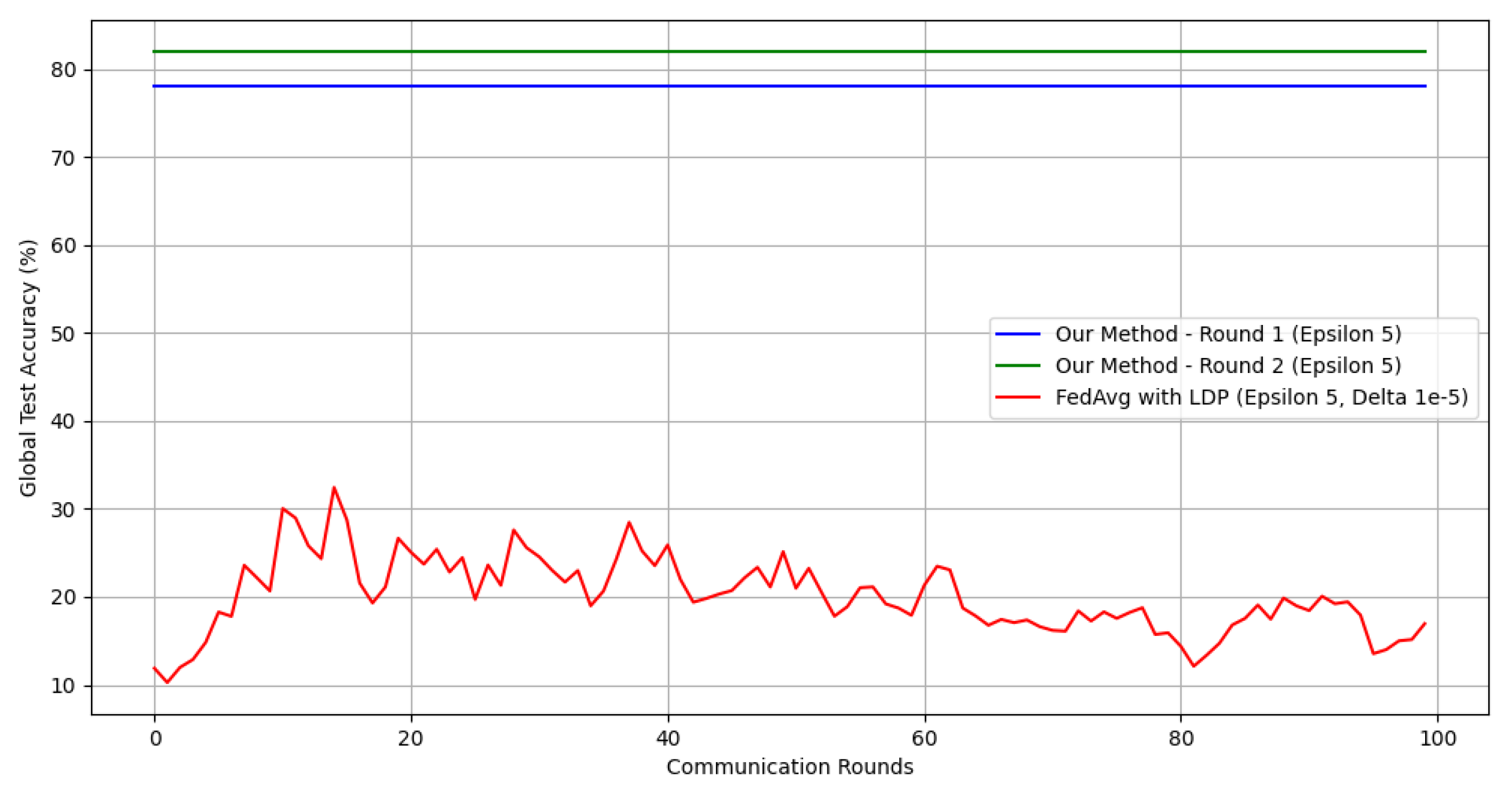
- Comprehensive experiments are conducted on three tasks and show that the proposed framework can achieve high performance with just one communication round in scenarios marked by pathological non-IID conditions.
2. Related Works
2.1. Federated Learning
2.2. One-Shot Federated Learning
2.3. Local Differential Privacy
2.4. Dataset Distillation
2.5. Dataset Distillation in Federated Learning
3. Methodology
3.1. Differences between FedGM and the Traditional Iterative Minimization Framework in FL
3.2. FL with Efficient Local Gradient Matching
3.2.1. Local Gradient Matching
3.2.2. Local Gradient Matching with Training Efficiency
3.3. One-Shot FL with Label Differential Privacy
| Algorithm 1 Federated learning with efficient local gradient matching |
|
3.3.1. Visual Privacy of Distilled Images
3.3.2. Implementation of Label Differential Privacy
| Algorithm 2 RRTop-k |
|
| Algorithm 3 RRWithPrior |
|
| Algorithm 4 One-Shot Federated Learning with Label Differential Privacy |
|
3.3.3. Proof of Differential Privacy
4. Experiments
4.1. Experimental Settings
4.2. Comparison with Other One-Shot FL Methods
4.3. Efficient and Robust Training on Heterogeneous Data
4.4. Performance with DP Guarantee
4.5. Analyzing the Efficiency Brought by Matching Representative Images
4.6. Comparison with Transmitting Real Images
5. Conclusions and Limitation
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zeadally, S.; Javed, M.A.; Hamida, E.B. Vehicular communications for ITS: Standardization and challenges. IEEE Commun. Stand. Mag. 2020, 4, 11–17. [Google Scholar] [CrossRef]
- Karlstetter, R.; Raoofy, A.; Radev, M.; Trinitis, C.; Hermann, J.; Schulz, M. Living on the edge: Efficient handling of large scale sensor data. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3347–3366. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. arXiv 2019, arXiv:1906.08935. [Google Scholar]
- Wei, W.; Liu, L.; Loper, M.; Chow, K.H.; Gursoy, M.E.; Truex, S.; Wu, Y. A framework for evaluating gradient leakage attacks in federated learning. arXiv 2020, arXiv:2004.10397. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Zhang, C.; Li, S.; Xia, J.; Wang, W.; Yan, F.; Liu, Y. {BatchCrypt}: Efficient homomorphic encryption for {Cross-Silo} federated learning. In Proceedings of the 2020 USENIX annual technical conference (USENIX ATC 20), Boston, MA, USA, 15–17 July 2020; pp. 493–506. [Google Scholar]
- Truex, S.; Liu, L.; Chow, K.H.; Gursoy, M.E.; Wei, W. LDP-Fed: Federated learning with local differential privacy. In Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking, Heraklion, Greece, 27 April 2020; pp. 61–66. [Google Scholar]
- Hu, R.; Guo, Y.; Li, H.; Pei, Q.; Gong, Y. Personalized federated learning with differential privacy. IEEE Internet Things J. 2020, 7, 9530–9539. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 1–26 June 2016; pp. 770–778. [Google Scholar]
- Ghazi, B.; Golowich, N.; Kumar, R.; Manurangsi, P.; Zhang, C. Deep learning with label differential privacy. Adv. Neural Inf. Process. Syst. 2021, 34, 27131–27145. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Huang, X.; Li, P.; Li, X. Stochastic Controlled Averaging for Federated Learning with Communication Compression. arXiv 2023, arXiv:2308.08165. [Google Scholar]
- Guha, N.; Talwalkar, A.; Smith, V. One-shot federated learning. arXiv 2019, arXiv:1902.11175. [Google Scholar]
- Kasturi, A.; Ellore, A.R.; Hota, C. Fusion learning: A one shot federated learning. In Proceedings of the Computational Science–ICCS 2020: 20th International Conference, Amsterdam, The Netherlands, 3–5 June 2020; Proceedings, Part III 20. Springer: Berlin, Germany, 2020; pp. 424–436. [Google Scholar]
- Song, R.; Liu, D.; Chen, D.Z.; Festag, A.; Trinitis, C.; Schulz, M.; Knoll, A. Federated learning via decentralized dataset distillation in resource-constrained edge environments. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–10. [Google Scholar]
- Dwork, C. Differential privacy. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Venice, Italy, 10–14 July 2006; pp. 1–12. [Google Scholar]
- Arachchige, P.C.M.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S.; Atiquzzaman, M. Local differential privacy for deep learning. IEEE Internet Things J. 2019, 7, 5827–5842. [Google Scholar] [CrossRef]
- Sachdeva, N.; McAuley, J. Data distillation: A survey. arXiv 2023, arXiv:2301.04272. [Google Scholar]
- Nguyen, T.; Chen, Z.; Lee, J. Dataset meta-learning from kernel ridge-regression. arXiv 2020, arXiv:2011.00050. [Google Scholar]
- Nguyen, T.; Novak, R.; Xiao, L.; Lee, J. Dataset distillation with infinitely wide convolutional networks. Adv. Neural Inf. Process. Syst. 2021, 34, 5186–5198. [Google Scholar]
- Wang, T.; Zhu, J.Y.; Torralba, A.; Efros, A.A. Dataset distillation. arXiv 2018, arXiv:1811.10959. [Google Scholar]
- Sucholutsky, I.; Schonlau, M. Soft-label dataset distillation and text dataset distillation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Zhao, B.; Bilen, H. Dataset Condensation with Gradient Matching. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Guo, Z.; Wang, K.; Cazenavette, G.; Li, H.; Zhang, K.; You, Y. Towards Lossless Dataset Distillation via Difficulty-Aligned Trajectory Matching. arXiv 2023, arXiv:2310.05773. [Google Scholar]
- Du, J.; Shi, Q.; Zhou, J.T. Sequential Subset Matching for Dataset Distillation. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Sajedi, A.; Khaki, S.; Amjadian, E.; Liu, L.Z.; Lawryshyn, Y.A.; Plataniotis, K.N. DataDAM: Efficient Dataset Distillation with Attention Matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 17097–17107. [Google Scholar]
- Zhao, G.; Li, G.; Qin, Y.; Yu, Y. Improved Distribution Matching for Dataset Condensation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17 June–24 June 2023; pp. 7856–7865. [Google Scholar]
- Cazenavette, G.; Wang, T.; Torralba, A.; Efros, A.A.; Zhu, J.Y. Generalizing Dataset Distillation via Deep Generative Prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 3739–3748. [Google Scholar]
- Wang, K.; Gu, J.; Zhou, D.; Zhu, Z.; Jiang, W.; You, Y. DiM: Distilling Dataset into Generative Model. arXiv 2023, arXiv:2303.04707. [Google Scholar]
- Yu, R.; Liu, S.; Wang, X. A Comprehensive Survey to Dataset Distillation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 17–32. [Google Scholar]
- Xiong, Y.; Wang, R.; Cheng, M.; Yu, F.; Hsieh, C.J. Feddm: Iterative distribution matching for communication-efficient federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16323–16332. [Google Scholar]
- Dong, T.; Zhao, B.; Liu, L. Privacy for Free: How does Dataset Condensation Help Privacy? In Proceedings of the International Conference on Machine Learning (ICML), Baltimore, MD, USA, 17–23 July 2022; pp. 5378–5396. [Google Scholar]
- Tsilivis, N.; Su, J.; Kempe, J. Can we achieve robustness from data alone? In Proceedings of the International Conference on Machine Learning (ICML), Workshop, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Liu, Y.; Gu, J.; Wang, K.; Zhu, Z.; Jiang, W.; You, Y. DREAM: Efficient Dataset Distillation by Representative Matching. arXiv 2023, arXiv:2302.14416. [Google Scholar]
- Bohdal, O.; Yang, Y.; Hospedales, T. Flexible dataset distillation: Learn labels instead of images. arXiv 2020, arXiv:2006.08572. [Google Scholar]
- Forgy, E.W. Cluster analysis of multivariate data: Efficiency versus interpretability of classifications. Biometrics 1965, 21, 768–769. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning; NIPS: San Diego, CA, USA, 2011. [Google Scholar]
- Gidaris, S.; Komodakis, N. Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4367–4375. [Google Scholar]
- Amari, S.i. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Li, Q.; Diao, Y.; Chen, Q.; He, B. Federated learning on non-iid data silos: An experimental study. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 965–978. [Google Scholar]
- Zhang, J.; Chen, C.; Li, B.; Lyu, L.; Wu, S.; Ding, S.; Shen, C.; Wu, C. Dense: Data-free one-shot federated learning. Adv. Neural Inf. Process. Syst. 2022, 35, 21414–21428. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Partitioning | FedAvg | FedProx | SCAFFOLD | FedNova | FedGM |
|---|---|---|---|---|---|---|
| MNIST | 98.9% ± 0.1% | 98.9% ± 0.1% | 99.0% ± 0.1% | 98.9% ± 0.1% | 96.1% ± 0.1% | |
| #C = 1 | 29.8% ± 7.9% | 40.9% ± 23.1% | 39.9% ± 0.2% | 39.2% ± 22.1% | 99.3% ± 0.1% | |
| #C = 2 | 97.0% ± 0.4% | 96.4% ± 0.3% | 95.9% ± 0.2% | 94.5% ± 1.5% | 99.2% ± 0.1% | |
| IID | 99.1% ± 0.1% | 99.1% ± 0.1% | 99.1% ± 0.2% | 99.1% ± 0.2% | 99.2% ± 0.1% | |
| FMNIST | 88.1% ± 0.1% | 88.1% ± 0.4% | 88.1% ± 0.5% | 88.6% ± 0.3% | 89.6% ± 0.3% | |
| #C = 1 | 10.2% ± 0.1 | 28.8% ± 0.3% | 11.8% ± 0.2% | 15.8% ± 0.2% | 85.7% ± 0.1% | |
| #C = 2 | 74.3% ± 0.1% | 71.3% ± 0.1% | 42.8% ± 28.7% | 69.5% ± 5.7% | 85.3% ± 0.1% | |
| IID | 89.3% ± 0.1% | 89.1% ± 0.2% | 89.8% ± 0.1% | 89.4% ± 0.3% | 87% ± 0.0% | |
| CIFAR-10 | 68.4% ± 0.3% | 65.9% ± 0.5% | 65.8% ± 0.9% | 65.3% ± 1.5% | 61.4% ± 0.3% | |
| #C = 1 | 10.3% ± 0.5% | 12.3% ± 2.0% | 10.0% ± 0.0% | 10.0% ± 0.0% | 74.5% ± 0.1% | |
| #C = 2 | 49.8% ± 3.3% | 50.7% ± 1.7% | 49.1% ± 1.7% | 46.5% ± 3.5% | 75.5% ± 0.2% | |
| IID | 72.4% ± 0.2% | 70.2% ± 0.1% | 71.5% ± 0.3% | 69.5% ± 1.0% | 62.4% ± 0.4% | |
| SVHN | 86.1% ± 0.7% | 86.6% ± 0.9% | 86.8% ± 0.3% | 86.4% ± 0.6% | 86.5% ± 0.3% | |
| #C = 1 | 11.1% ± 0.1% | 18.6% ± 0.2% | 6.8% ± 0.0% | 10.6% ± 0.2% | 85.3% ± 0.2% | |
| #C = 2 | 79.2% ± 0.5% | 80.3% ± 0.5% | 64% ± 10.6% | 72.4% ± 3.8% | 85.7% ± 0.4% | |
| IID | 87.5% ± 0.3% | 85.5% ± 0.7% | 88.5% ± 0.2% | 87.4% ± 0.4% | 87.9% ± 0.4% |
| Dataset | Partitioning | FedGM (Ours) | FedDM | FedDF | FedD3 | DENSE |
|---|---|---|---|---|---|---|
| MNIST | IID | 99.21% | 98.01% | 96.13% | 94.71% | 99.13% |
| 96.13% | 99.01% | 92.23% | 94.1% | 95.82% | ||
| CIFAR10 | IID | 62.41% | 58.12% | 54.12% | 49.31% | 64.1% |
| 62.93% | 61.83% | 53.56% | 40.15% | 62.19% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhou, C.; Jiang, Z. One-Shot Federated Learning with Label Differential Privacy. Electronics 2024, 13, 1815. https://doi.org/10.3390/electronics13101815
Chen Z, Zhou C, Jiang Z. One-Shot Federated Learning with Label Differential Privacy. Electronics. 2024; 13(10):1815. https://doi.org/10.3390/electronics13101815
Chicago/Turabian StyleChen, Zikang, Changli Zhou, and Zhenyu Jiang. 2024. "One-Shot Federated Learning with Label Differential Privacy" Electronics 13, no. 10: 1815. https://doi.org/10.3390/electronics13101815
APA StyleChen, Z., Zhou, C., & Jiang, Z. (2024). One-Shot Federated Learning with Label Differential Privacy. Electronics, 13(10), 1815. https://doi.org/10.3390/electronics13101815