
Semantic-Based Public Opinion Analysis System

 ,
,  , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Sentiment Analysis
2.2. Proposed Method
2.2.1. Data Source Acquisition
2.2.2. JSON Database
2.2.3. Training Data
- Primary emotional feature database: This database is created through collaboration between WordNet and emotion-related words to organize emotional features. These features are stored in the database in the form of tags.
- HowNet ontology corpus: This database stores sentence formats and related tags. The sentence processor can parse the emotional feature tags between single words and sentences.
- Single-word hierarchical relationship database: This database uses data mining technology to discover the correlation between single words and sentences. It uses a word-hierarchical relational database to analyze similarity and train an SRC (Support Vector Machine Recursive Removal) classifier.
- Main Emotion Feature Database:
- 2.
- HowNet Ontology Corpus Database:
- Employer: DEF = human|human, *employ|employ
- Employee: DEF = human|human, $employ|employ
- 3.
- Lexical Hierarchy Relationship Database:
- event
- entity
- attribute
- aValue|Attribute value
- AttributeValue|Attribute and attribute value
- syntax
- qValue|Quantiity value
- SecondaryFeature|Secondary Feature
- EventRoleAndFeatures|Dynamic role and feature
2.2.4. Sentence Processor
- Analysis:
- I finally finished my paper today (I finally finished the paper today.)
- After Chinese word segmentation:
- I (Nh) finally (ADV) finished (VC) the paper (Na) today (Nd)
- Result Analysis:
- thesis (Na) [implement]
- The result is:
- text #research [implement]
2.2.5. Data Mining
- Itemset:The total number of combinations of items can be calculated using the formula 2n − 1, where ‘n’ represents the number of items. For example, if a record contains three items {A, B, C}, the total number of combinations would be {A}, {B}, {C}, {A,B}, {A,C}, {B,C}, and {A, B, C}.
- Support:Set a rule requiring minimum data points, including objects’ probability in A∩B.
- Confidence:The Apriori algorithm is the most representative algorithm that allows for discovering meaningful association rules by setting rules through the “support” stage to control their confidence strength. The algorithm then identifies association rules that satisfy the specified support and confidence thresholds. The execution steps of the Apriori algorithm are as follows:
- Set the support and confidence thresholds.
- Consider all data as candidate item sets. Calculate the occurrence frequency of each candidate item set and retain those with occurrence frequency greater than or equal to the support threshold, creating them as one-dimensional candidate item sets.
- Calculate the frequency of association combinations from the previously filtered one-dimensional candidate items and eliminate association candidate item combinations with low support using the same method. Repeat this process until the maximum number of candidate item sets in the data is calculated.
- The final remaining strongly associated candidate item sets are the main links in the entire data association. We can identify the leading associations that affect positive and negative sentiment sentences through association rules. These associations can be categorized into three types, as shown in Table 5.
- : Represents the concept feature.
- : Represents the maximum length of the shared path between two concept features.
- : Indicates the number of sub-nodes in that path.
- F: Represents the maximum depth of the concept feature tree for a given set.
- : Calculates the similarity between two concept features based on F.
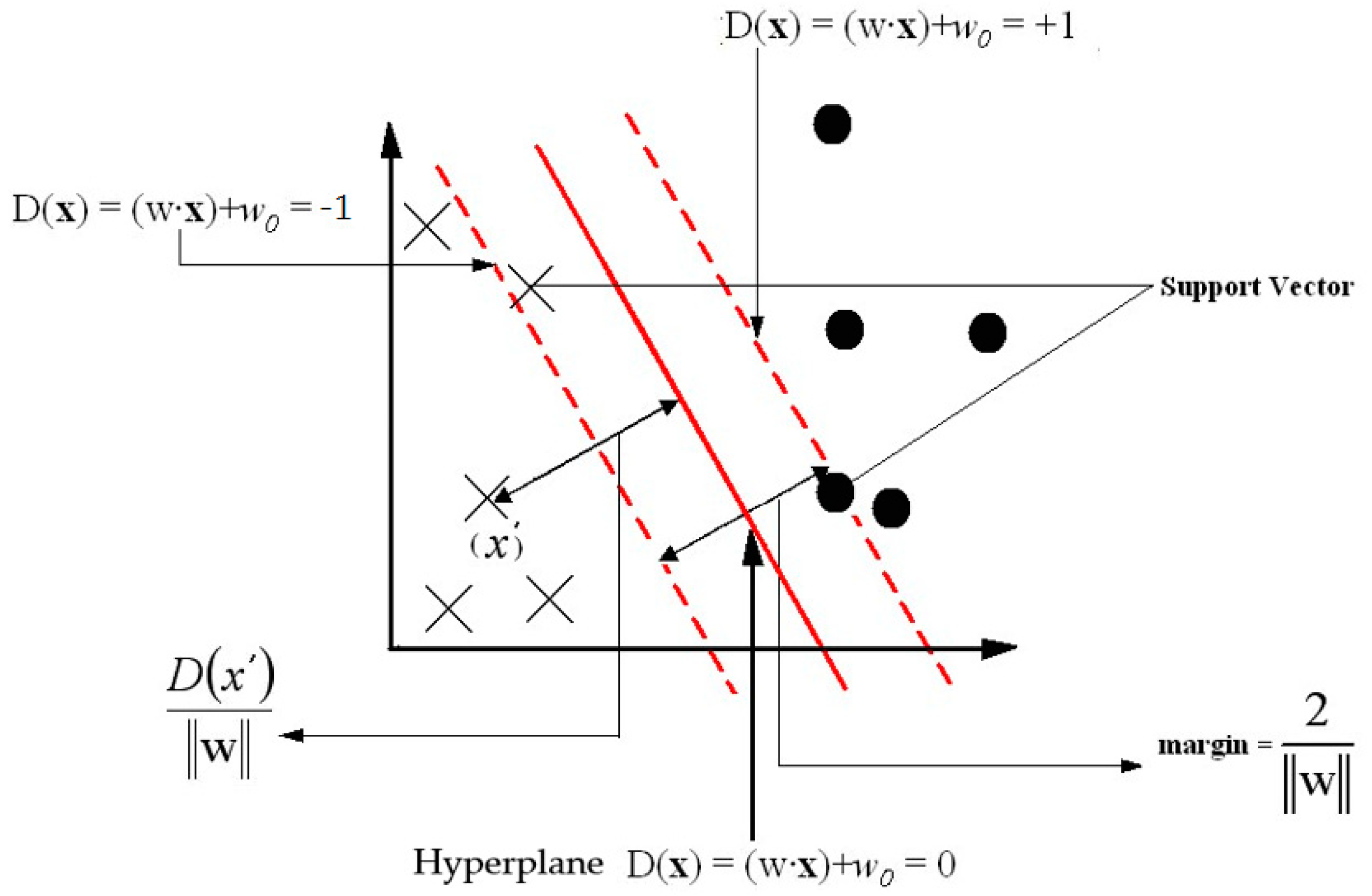
2.2.6. Sparse Representation Classification Model
2.3. Data Classification
3. Experimental Results
3.1. Experimental Setup and Environment
3.2. Experimental Corpus
3.2.1. Uber
3.2.2. Baseball Game Analysis
- The second pitch was a strike; can you believe it?
- The catcher was squatting in the left-handed batter’s box, constantly pulling the glove back, and the home plate umpire kept falling for it.
- The kids are happy playing ball and growing taller and more muscular. They’ll seek revenge when they grow up.
- The video is so biased. Except for the first pitch being a beautiful strike, the rest is a complete black box.
- Suddenly, I feel like the Chinese Professional Baseball League (CPBL) seems better.
3.2.3. Analysis of the Demolition of Zhongxiao Bridge
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheung, K.S.; Leung, W.K.; Seto, W.K. Application of big data analysis in gastrointestinal research. World J. Gastroenterol. 2019, 25, 2990. [Google Scholar] [CrossRef] [PubMed]
- Majumdar, J.; Naraseeyappa, S.; Ankalaki, S. Analysis of agriculture data using data mining techniques: Application of big data. J. Big Data 2017, 4, 20. [Google Scholar] [CrossRef]
- Wu, J.; Wang, J.; Nicholas, S.; Maitland, E.; Fan, Q. Application of big data technology for COVID-19 prevention and control in China: Lessons and recommendations. J. Med. Internet Res. 2020, 22, e21980. [Google Scholar] [CrossRef] [PubMed]
- Ding, H.; Tian, J.; Yu, W.; Wilson, D.I.; Young, B.R.; Cui, X.; Xin, X.; Wang, Z.; Li, W. The application of artificial intelligence and big data in the food industry. Foods 2023, 12, 4511. [Google Scholar] [CrossRef] [PubMed]
- Jin, K.; Zhong, Z.Z.; Zhao, E.Y. Sustainable digital marketing under big data: An AI random forest model approach. IEEE Trans. Eng. Manag. 2024, 71, 3566–3579. [Google Scholar] [CrossRef]
- Demchenko, Y.; Belloum, A.; Los, W.; Wiktorski, T.; Manieri, A.; Brocks, H.; Becker, J.; Heutelbeck, D.; Hemmje, M.; Brewer, S. EDISON data science framework: A foundation for building data science profession for research and industry. In Proceedings of the 2016 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Luxembourg, 12–15 December 2016; pp. 620–626. [Google Scholar]
- Murphy, J.; Link, M.W.; Childs, J.H.; Tesfaye, C.L.; Dean, E.; Stern, M.; Pasek, J.; Cohen, J.; Callegaro, M.; Harwood, P. Social media in public opinion research: Executive summary of the AAPOR task force on emerging technologies in public opinion research. Public Opin. Q. 2014, 78, 788–794. [Google Scholar] [CrossRef]
- Cuadrado, A.; Cardoso, M.; Jouve, N. Physical organisation of simple sequence repeats (SSRs) in Triticeae: Structural, functional and evolutionary implications. Cytogenet. Genome Res. 2008, 120, 210–219. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Cao, Z.; Zhao, P.; Hu, P.J.H.; Zeng, D.D.; Luo, Y. A deep learning approach for semantic analysis of COVID-19-related stigma on social media. IEEE Trans. Comput. Soc. Syst. 2022, 10, 246–254. [Google Scholar] [CrossRef]
- Patano, M.; Camarda, D. Managing Complex Knowledge in Sustainable Planning: A Semantic-Based Model for Multiagent Water-Related Concepts. Sustainability 2023, 15, 11774. [Google Scholar] [CrossRef]
- Gu, Z.; He, K. Affective Prompt-Tuning-Based Language Model for Semantic-Based Emotional Text Generation. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2024, 20, 1–19. [Google Scholar] [CrossRef]
- Jotheeswaran, J.; Kumaraswamy, Y.S. Opinion mining using decision tree based feature selection through Manhattan hierarchical cluster measure. J. Theor. Appl. Inf. Technol. 2013, 58, 72–80. [Google Scholar]
- Thomas, E.H.; Galambos, N. What satisfies students? Mining student-opinion data with regression and decision tree analysis. Res. High. Educ. 2004, 45, 251–269. [Google Scholar] [CrossRef]
- Ramadhan, N.G.; Wibowo, M.; Rosely, N.F.L.M.; Quix, C. Opinion mining indonesian presidential election on twitter data based on decision tree method. J. Infotel 2022, 14, 243–248. [Google Scholar] [CrossRef]
- Sanjay, K.S.; Danti, A. Detection of fake opinions on online products using Decision Tree and Information Gain. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 372–375. [Google Scholar]
- Es-Sabery, F.; Es-Sabery, K.; Qadir, J.; Sainz-De-Abajo, B.; Hair, A.; García-Zapirain, B.; De La Torre-Díez, I. A MapReduce opinion mining for COVID-19-related tweets classification using enhanced ID3 decision tree classifier. IEEE Access 2021, 9, 58706–58739. [Google Scholar] [CrossRef]
- Tavazoee, F.; Conversano, C.; Mola, F. Recurrent random forest for the assessment of popularity in social media: 2016 US election as a case study. Knowl. Inf. Syst. 2020, 62, 1847–1879. [Google Scholar] [CrossRef]
- Elagamy, M.N.; Stanier, C.; Sharp, B. Stock market random forest-text mining system mining critical indicators of stock market movements. In Proceedings of the 2018 2nd International Conference on Natural Language and Speech Processing (ICNLSP), Algiers, Algeria, 25–26 April 2018; pp. 1–8. [Google Scholar]
- Karthika, P.; Murugeswari, R.; Manoranjithem, R. Sentiment analysis of social media network using random forest algorithm. In Proceedings of the 2019 IEEE International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), Tamilnadu, India, 11–13 April 2019; pp. 1–5. [Google Scholar]
- Wu, C.-H.; Chuang, Z.-J.; Lin, Y.-C. Emotion recognition from text using semantic labels and separable mixture models. ACM Trans. Asian Lang. Inf. Process. (TALIP) 2006, 5, 165–183. [Google Scholar] [CrossRef]
- Li, P.H.; Fu, T.J.; Ma, W.Y. Why attention? Analyze BiLSTM deficiency and its remedies in the case of NER. AAAI Conf. Artif. Intell. 2020, 34, 8236–8244. [Google Scholar] [CrossRef]
- Ding, Y.; Teng, F.; Zhang, P.; Huo, X.; Sun, Q.; Qi, Y. Research on text information mining technology of substation inspection based on improved Jieba. In Proceedings of the 2021 International Conference on Wireless Communications and Smart Grid (ICWCSG), Hangzhou, China, 13–15 August 2021; pp. 561–564. [Google Scholar]
- Wang, M.; Manning, C.D. Cross-lingual projected expectation regularization for weakly supervised learning. Trans. Assoc. Comput. Linguist. 2014, 2, 55–66. [Google Scholar] [CrossRef]
- Wiki, TF-IDF. Available online: https://zh.wikipedia.org/wiki/TF-IDF (accessed on 27 March 2024).
- Zhu, R.M.; Wang, F.Y.; Hirata, I.; Katsu, K.I.; Xiao, S.D.; Yu, Z.L.; Zhang, Z.H.; Xu, Z.M. Differences in endoscopic classification of early colorectal carcinoma between China and Japan: A comparative study. World J. Gastroenterol. 2003, 9, 1985. [Google Scholar] [CrossRef]
- Guo, G.; Neagu, D. Fuzzy kNNmodel applied to predictive toxicology data mining. Int. J. Comput. Intell. Appl. 2005, 5, 321–333. [Google Scholar] [CrossRef]
- Campbell, W.M.; Campbell, J.P.; Reynolds, D.A.; Singer, E.; Torres-Carrasquillo, P.A. Support vector machines for speaker and language recognition. Comput. Speech Lang. 2006, 20, 210–229. [Google Scholar] [CrossRef]
- LIBSVM. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvmH (accessed on 27 March 2024).
- Wang, J.-C.; Lin, C.-H.; Chen, B.-W.; Tsai, M.-K. Gabor-Based Nonuniform Scale-Frequency Map for Environmental Sound Classification in Home Automation. IEEE Trans. Autom. Sci. Eng. 2014, 17, 607–613. [Google Scholar] [CrossRef]
- Wang, J.-C.; Lee, Y.-S.; Lin, C.-H.; Siahaan, E.; Yang, C.-H. Robust Environmental Sound Recognition With Fast Noise Suppression for Home Automation. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1235–1242. [Google Scholar] [CrossRef]
- Ma, C.M.; Yang, W.S.; Cheng, B.W. How the parameters of k-nearest neighbor algorithm impact on the best classification accuracy: In case of parkinson dataset. J. Appl. Scie Nces 2014, 14, 171–176. [Google Scholar] [CrossRef]
- Wang, J.C.; Chin, Y.H.; Chen, B.W.; Lin, C.H.; Wu, C.H. Speech emotion verification using emotion variance modeling and discriminant scale-frequency maps. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1552–1562. [Google Scholar] [CrossRef]
- Chin, Y.-H.; Wang, J.-C.; Huang, C.-L.; Wang, K.-Y.; Wu, C.-H. Speaker Identification Using Discriminative Features and Sparse Representation. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1979–1987. [Google Scholar] [CrossRef]
- JavaScript Object Notation. Available online: http://www.JSON.org/ (accessed on 27 March 2024).
- Russell, J.A.; Pratt, G. A description of the affective quality attributed to environments. J. Personal. Soc. Psychol. 1980, 38, 311. [Google Scholar] [CrossRef]
- Larsen, R.J.; Diener, E. Promises and Problems with the Circumplex Model of Emotion; Sage Publications, Inc.: Thousand Oaks, CA, USA, 1992. [Google Scholar]
- Posner, J.; Russell, J.A.; Peterson, B.S. The circumplex model of affect: An integrative approach to affective neuroscience, cognitive development, and psychopathology. Dev. Psychopathol. 2005, 17, 715–734. [Google Scholar] [CrossRef]
- Chin, Y.-H.; Wang, J.-C.; Wang, J.-C.; Yang, Y.-H. Predicting the Probability Density Function of Music Emotion using Emotion Space Mapping. IEEE Trans. Affect. Comput. 2016, 9, 541–549. [Google Scholar] [CrossRef]
- Chauhan, H.; Chauhan, A. Implementation of the Apriori algorithm for association rule mining. Compusoft 2014, 3, 699. [Google Scholar]
- Chawla, A.; Dhindsa, K.S. Implementation of association rule mining using reverse apriori algorithmic approach. Int. J. Comput. Appl. 2014, 93, 24–28. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Example Sentences: 今天天氣晴朗 (The weather is sunny today) | |
| CKIP tool kit | 今天 (today) 天氣 (weather) 晴朗 (sunny) |
| Jieba tool kit | 今天天氣 (today weather) 晴朗 (sunny) |
| Stanford Word Segmenter | 今天 (today) 天氣 (weather) 晴朗 (sunny) |
| Key | Instruction |
|---|---|
| article_id | The ID of the article |
| article_title | The title of the article |
| board | PTT message board name |
| content | Content of the article |
| message_count | Number of messages |
| messages | Save all messages |
| NO. = 058773 W_C = delicious G_C = ADJ E_C = W_E = dainty G_E = ADJ E_E = DEF = aValue, taste, good, desired |
| Terms | Conceptual features |
| Delicious | aValue, taste, good, desired |
| Not bad | aValue, GoodBad, good, desired |
| Good | result, #estimate, good |
| Expert | human, able, desired |
| [implement] -> text research | primary emotional word -> conceptual feature |
| fact -> night | conceptual feature -> conceptual feature |
| [achieve] -> [obtain] | primary emotional word -> primary emotional word |
| First level | @ |
| Second level | *, $ |
| Third level | %, &, ? |
| Fourth level | # |
| Conditions for Judging Emotions | ||||||
| All Comments | Tweet Comments | Downvote Comments | -> Comments | |||
| Uber | 683 | 282 | 73 | 328 | ||
| Experimental Results | ||||||
| Uber | All | Emotion Tagging | Positive | Negative | Accuracy | |
| Tweet Comments | 282 | 189 | 112 | 77 | 59% | |
| Downvote Comments | 73 | 52 | 14 | 38 | 73% | |
| Correct Categorization | 241 | 112 | 38 | 62% | ||
| The accuracy rate is 62 | ||||||
| Conditions for Judging Emotions | ||||||
| All Comments | Tweet Comments | Downvote Comments | -> Comments | |||
| Baseball | 1284 | 578 | 208 | 498 | ||
| Experimental Results | ||||||
| Baseball | All | Emotion Tagging | Positive | Negative | Accuracy | |
| Tweet Comments | 578 | 336 | 255 | 81 | 75% | |
| Downvote Comments | 208 | 64 | 46 | 18 | 28% | |
| Correct Categorization | 400 | 255 | 18 | 68% | ||
| The accuracy rate is 68 | ||||||
| Emotional Evaluation Criteria | ||||||
| All Comments | Tweet Comments | Downvote Comments | -> Comments | |||
| Zhongxiao Bridge | 1535 | 1163 | 56 | 316 | ||
| Experimental Results | ||||||
| Baseball | All | Emotion Tagging | Positive | Negative | Accuracy | |
| Tweet Comments | 1163 | 395 | 286 | 109 | 72% | |
| Downvote Comments | 56 | 34 | 8 | 26 | 76% | |
| Correct Categorization | 429 | 286 | 26 | 72.8% | ||
| The accuracy rate is 72 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.-H.; Su, M.-H.; Zeng, Y.-Z.; Chu, V.C.-M.; Le, P.T.; Pham, T.; Lu, X.; Li, Y.-H.; Wang, J.-C. Semantic-Based Public Opinion Analysis System. Electronics 2024, 13, 2015. https://doi.org/10.3390/electronics13112015
Wang J-H, Su M-H, Zeng Y-Z, Chu VC-M, Le PT, Pham T, Lu X, Li Y-H, Wang J-C. Semantic-Based Public Opinion Analysis System. Electronics. 2024; 13(11):2015. https://doi.org/10.3390/electronics13112015
Chicago/Turabian StyleWang, Jian-Hong, Ming-Hsiang Su, Yu-Zhi Zeng, Vivian Ching-Mei Chu, Phuong Thi Le, Tuan Pham, Xin Lu, Yung-Hui Li, and Jia-Ching Wang. 2024. "Semantic-Based Public Opinion Analysis System" Electronics 13, no. 11: 2015. https://doi.org/10.3390/electronics13112015
APA StyleWang, J.-H., Su, M.-H., Zeng, Y.-Z., Chu, V. C.-M., Le, P. T., Pham, T., Lu, X., Li, Y.-H., & Wang, J.-C. (2024). Semantic-Based Public Opinion Analysis System. Electronics, 13(11), 2015. https://doi.org/10.3390/electronics13112015