
Multitask Learning for Concurrent Grading Diagnosis and Semi-Supervised Segmentation of Honeycomb Lung in CT Images

Abstract
:1. Introduction
- (1)
- We propose a multitask model that combines disease assessment and semi-supervised segmentation for grading and segmenting honeycomb lung CT images. To the best of our knowledge, this is the first method to simultaneously grade and segment honeycomb lung CT images.
- (2)
- In order to utilize the lesion area information provided by the segmentation network, a gradient thresholding algorithm is developed and integrated into the grading network to assist in distinguishing different levels of images.
- (3)
- Considering the complex contours of the lesion area, we design a novel shape-edge constraint strategy to improve the boundary awareness of the segmentation network.
- (4)
- To alleviate the annotation burden, we design a semi-supervised network consisting of a CNN and transformer to segment the lesion areas. In addition, to improve segmentation performance, global and local contrastive learning methods are adopted to learn inherent features at different levels.
- (5)
- The results of the experiment demonstrate the superiority of our model’s segmentation using in-house honeycomb lung and public Kavsir-SEG datasets. Furthermore, our grading network also achieved promising results that are consistent with expert physician evaluations.
- (6)
- Following the principles of data sharing and community advancement, our honeycomb dataset is available at https://github.com/YangBingQ/MTGS and was accessed on 27 May 2024.
2. Related Work
2.1. Semi-Supervised Segmentation
2.2. Grading Diagnosis
2.3. Multitask Learning
3. Methodology
3.1. Overview
3.2. Semi-Supervised Segmentation
3.2.1. Cross-Learning between CNN and Transformer
3.2.2. Contrast Learning with Different Levels
3.2.3. Shape-Edge Awareness Constraint
3.3. Grading Diagnosis
3.4. Total Loss and Overall Algorithm
| Algorithm 1. Algorithm of Our Multitask Method for Semi-Supervised Segmentation and Grading Diagnosis. | |
| Input: labeled images , unlabeled images , classification labels . is the raw image, is the corresponding ground truth, represent different disease grades. | |
| Output: Predicted segmentation results and disease grades , where is the prediction of the labeled image and is the prediction of the unlabeled image. Initialize: epoch = 0, total_epoch = 150 | |
| 1. | while epoch < total_epoch: |
| 2. | # Task 1: Semi-supervised segmentation |
| 3. | Given the input , getting the prediction result, encoding features and decoding mapping of UNet and Swin-UNet, denoted as and . |
| 4. | Calculate the supervised loss and unsupervised loss for and with Equations (4) and (5). |
| 5. | Calculate the global contrastive loss between and with Equation (6). |
| 6. | Calculate the local contrastive loss between and with Equation (7). |
| 7. | # Task 2: Grading diagnosis |
| 8. | Get the gradient thresholding result for with Equation (9). |
| 9. | Integrate raw images and via CNN network to predict disease grade . |
| 10. | Calculate the classification loss between and with Equation (10). |
| 11. | epoch = epoch + 1 |
| 12. | end while |
| 13. | Divide into unlabeled prediction and labeled prediction . |
| 14. | Preserve and as segmentation results . |
| 15. | Preserve as grading results. |
| Refinement: Sum all the losses as the total loss and then backpropagate to optimize the model | |
4. Experiments and Results
4.1. Dataset
4.2. Training Details
4.3. Evaluation Metrics
4.4. Segmentation Results
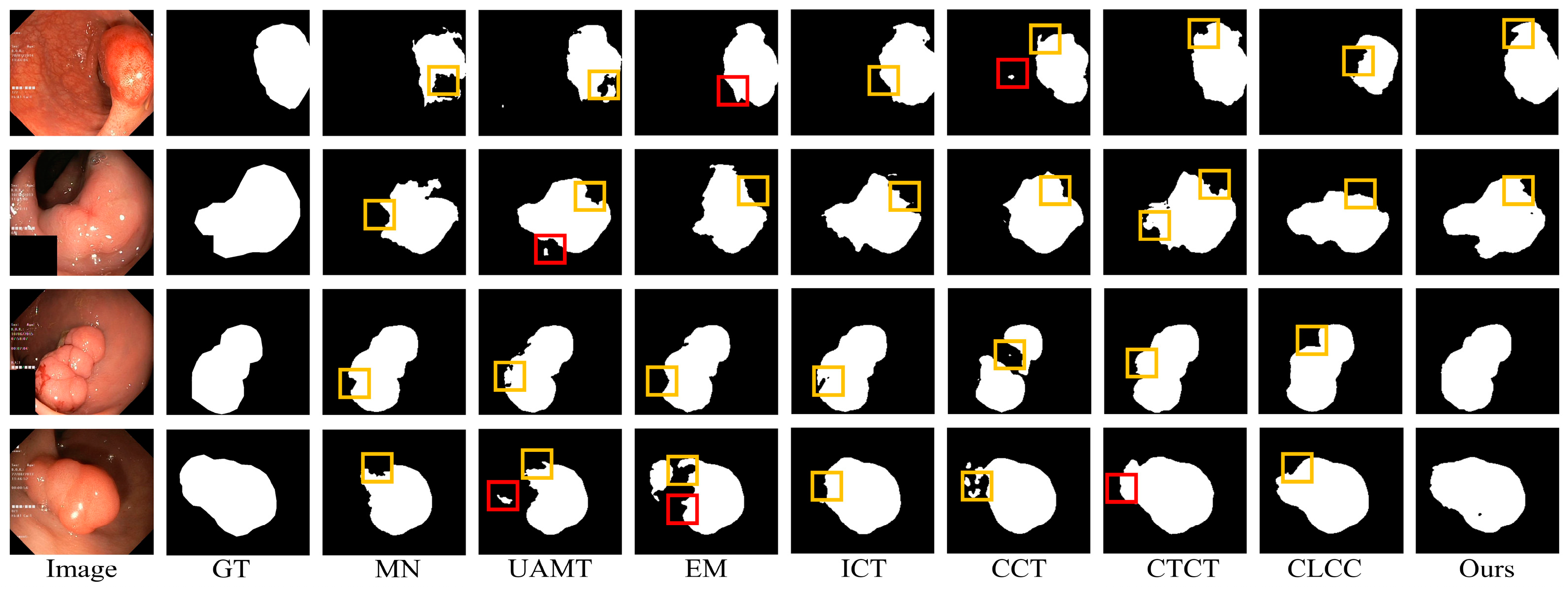
4.4.1. Comparison on the Honeycomb Dataset
4.4.2. Comparison of the Kvasir-SEG Dataset
4.5. Grading Diagnosis Results
4.6. Ablation Study
4.6.1. Ablation of Losses
4.6.2. Ablation of Shape-Edge Awareness Constraint
4.6.3. Ablation of MultiTask Architecture
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moss, B.J.; Ryter, S.W.; Rosas, I.O. Pathogenic mechanisms underlying idiopathic pulmonary fibrosis. Annu. Rev. Pathol. Mech. Dis. 2022, 17, 515–546. [Google Scholar] [CrossRef] [PubMed]
- Badyal, R.; Whalen, B.A.; Singhera, G.K.; Sahin, B.; Keen, K.J.; Ryerson, C.J.; Wilcox, P.; Dunne, J.V. Regulation of MicroRNA Expression in Scleroderma and Idiopathic Pulmonary Fibrosis: A Research Study. Undergrad. Res. Nat. Clin. Sci. Technol. J. 2023, 7, 1–12. [Google Scholar] [CrossRef]
- Obi, O.N.; Alqalyoobi, S.; Maddipati, V.; Lower, E.E.; Baughman, R.P. High-Resolution CT Scan Fibrotic Patterns in Stage 4 Pulmonary Sarcoidosis: Impact on Pulmonary Function and Survival. Chest 2023, 165, 892–907. [Google Scholar] [CrossRef] [PubMed]
- Yudin, A.L. Metaphorical Signs in Computed Tomography of Chest and Abdomen; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Hosseini, M.; Salvatore, M. Is pulmonary fibrosis a precancerous disease? Eur. J. Radiol. 2023, 160, 110723. [Google Scholar] [CrossRef]
- Kunihiro, Y.; Matsumoto, T.; Murakami, T.; Shimokawa, M.; Kamei, H.; Tanaka, N.; Ito, K. A quantitative analysis of long-term follow-up computed tomography of idiopathic pulmonary fibrosis: The correlation with the progression and prognosis. Acta Radiol. 2023, 64, 2409–2415. [Google Scholar] [CrossRef] [PubMed]
- Glass, D.S.; Grossfeld, D.; Renna, H.A.; Agarwala, P.; Spiegler, P.; DeLeon, J.; Reiss, A.B. Idiopathic pulmonary fibrosis: Current and future treatment. Clin. Respir. J. 2022, 16, 84–96. [Google Scholar] [CrossRef] [PubMed]
- Raghu, G.; Remy-Jardin, M.; Richeldi, L.; Thomson, C.C.; Inoue, Y.; Johkoh, T.; Kreuter, M.; Lynch, D.A.; Maher, T.M.; Martinez, F.J.; et al. Idiopathic pulmonary fibrosis (an update) and progressive pulmonary fibrosis in adults: An official ATS/ERS/JRS/ALAT clinical practice guideline. Am. J. Respir. Crit. Care Med. 2022, 205, e18–e47. [Google Scholar] [CrossRef]
- Khor, Y.H.; Bissell, B.; Ghazipura, M.; Herman, D.; Hon, S.M.; Hossain, T.; Kheir, F.; Knight, S.L.; Kreuter, M.; Macrea, M.; et al. Antacid medication and antireflux surgery in patients with idiopathic pulmonary fibrosis: A systematic review and meta-analysis. Ann. Am. Thorac. Soc. 2022, 19, 833–844. [Google Scholar] [CrossRef] [PubMed]
- Candia, C.; Lombardi, C.; Merola, C.; Ambrosino, P.; D’anna, S.E.; Vicario, A.; De Marco, S.; Molino, A.; Maniscalco, M. The Role of High-Flow Nasal Cannula Oxygen Therapy in Exercise Testing and Pulmonary Rehabilitation: A Review of the Current Literature. J. Clin. Med. 2023, 13, 232. [Google Scholar] [CrossRef]
- Itoh, T.; Kawasaki, T.; Kaiho, T.; Shikano, K.; Naito, A.; Abe, M.; Suzuki, H.; Ota, M.; Yoshino, I.; Suzuki, T. Long-term nintedanib treatment for progressive pulmonary fibrosis associated with Hermansky-Pudlak syndrome type 1 followed by lung transplantation. Respir. Investig. 2024, 62, 176–178. [Google Scholar] [CrossRef]
- Lee, J.H.; Song, J.W. Diagnostic approaches for idiopathic pulmonary fibrosis. Tuberc. Respir. Dis. 2024, 87, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Nam, J.G.; Choi, Y.; Lee, S.-M.; Yoon, S.H.; Goo, J.M.; Kim, H. Prognostic value of deep learning–based fibrosis quantification on chest CT in idiopathic pulmonary fibrosis. Eur. Radiol. 2023, 33, 3144–3155. [Google Scholar] [CrossRef]
- Oda, K.; Ishimoto, H.; Yatera, K.; Naito, K.; Ogoshi, T.; Yamasaki, K.; Imanaga, T.; Tsuda, T.; Nakao, H.; Kawanami, T.; et al. High-resolution CT scoring system-based grading scale predicts the clinical outcomes in patients with idiopathic pulmonary fibrosis. Respir. Res. 2014, 15, 10. [Google Scholar] [CrossRef] [PubMed]
- Gang, L.; Haixuan, Z.; Linning, E.; Ling, Z.; Yu, L.; Juming, Z. Recognition of honeycomb lung in CT images based on improved MobileNet model. Med. Phys. 2021, 48, 4304–4315. [Google Scholar] [CrossRef] [PubMed]
- Su, N.; Hou, F.; Zheng, W.; Wu, Z.; Linning, E. Computed Tomography–Based Deep Learning Model for Assessing the Severity of Patients With Connective Tissue Disease–Associated Interstitial Lung Disease. J. Comput. Assist. Tomogr. 2023, 47, 738–745. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Xie, J.; Zhang, L.; Sun, M.; Li, Z.; Sun, Y. MCAFNet: Multiscale cross-layer attention fusion network for honeycomb lung lesion segmentation. Med. Biol. Eng. Comput. 2023, 62, 1121–1137. [Google Scholar] [CrossRef] [PubMed]
- Jianjian, W.; Li, G.; He, K.; Li, P.; Zhang, L.; Wang, R. MCSC-UTNet: Honeycomb lung segmentation algorithm based on Separable Vision Transformer and context feature fusion. In Proceedings of the 2023 2nd Asia Conference on Algorithms, Computing and Machine Learning, Shanghai, China, 17–19 March 2023; pp. 488–494. [Google Scholar]
- Han, K.; Sheng, V.S.; Song, Y.; Liu, Y.; Qiu, C.; Ma, S.; Liu, Z. Deep semi-supervised learning for medical image segmentation: A review. Expert Syst. Appl. 2024, 245, 123052. [Google Scholar] [CrossRef]
- Jiao, R.; Zhang, Y.; Ding, L.; Xue, B.; Zhang, J.; Cai, R.; Jin, C. Learning with limited annotations: A survey on deep semi-supervised learning for medical image segmentation. Comput. Biol. Med. 2023, 169, 107840. [Google Scholar] [CrossRef] [PubMed]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.E.; McGuinness, K. Pseudo-labeling and confirmation bias in deep semi-supervised learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar]
- Wu, J.; Fan, H.; Zhang, X.; Lin, S.; Li, Z. Semi-supervised semantic segmentation via entropy minimization. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Fan, Y.; Kukleva, A.; Dai, D.; Schiele, B. Revisiting consistency regularization for semi-supervised learning. Int. J. Comput. Vis. 2023, 131, 626–643. [Google Scholar] [CrossRef]
- Wang, K.; Zhan, B.; Zu, C.; Wu, X.; Zhou, J.; Zhou, L.; Wang, Y. Semi-supervised medical image segmentation via a tripled-uncertainty guided mean teacher model with contrastive learning. Med. Image Anal. 2022, 79, 102447. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, F.; Wang, Y.; Yang, M.; Pan, X. FedCL: Federated Contrastive Learning for Multi-center Medical Image Classification. Pattern Recognit. 2023, 143, 109739. [Google Scholar] [CrossRef]
- Liu, P.; Zheng, G. Context-aware voxel-wise contrastive learning for label efficient multi-organ segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 653–662. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-supervised semantic segmentation with cross pseudo supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar]
- Liu, J.; Desrosiers, C.; Zhou, Y. Semi-supervised medical image segmentation using cross-model pseudo-supervision with shape awareness and local context constraints. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2022; pp. 140–150. [Google Scholar]
- Sarkar, S.; Min, K.; Ikram, W.; Tatton, R.W.; Riaz, I.B.; Silva, A.C.; Bryce, A.H.; Moore, C.; Ho, T.H.; Sonpavde, G.; et al. Performing Automatic Identification and Staging of Urothelial Carcinoma in Bladder Cancer Patients Using a Hybrid Deep-Machine Learning Approach. Cancers 2023, 15, 1673. [Google Scholar] [CrossRef] [PubMed]
- Dinesh, M.G.; Bacanin, N.; Askar, S.S.; Abouhawwash, M. Diagnostic ability of deep learning in detection of pancreatic tumour. Sci. Rep. 2023, 13, 9725. [Google Scholar] [CrossRef]
- Zheng, Y.-M.; Che, J.-Y.; Yuan, M.-G.; Wu, Z.-J.; Pang, J.; Zhou, R.-Z.; Li, X.-L.; Dong, C. A CT-based deep learning radiomics nomogram to predict histological grades of head and neck squamous cell carcinoma. Acad. Radiol. 2023, 30, 1591–1599. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Yin, M.; Fu, L.; Yang, F. Uncertainty-aware pseudo-label and consistency for semi-supervised medical image segmentation. Biomed. Signal Process. Control 2023, 79, 104203. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Li, S.; Zhang, Y.; Yang, X. Semi-supervised cardiac mri segmentation based on generative adversarial network and variational auto-encoder. In 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM); IEEE: Piscataway, NJ, USA, 2021; pp. 1402–1405. [Google Scholar]
- Zhang, J.; Zhang, S.; Shen, X.; Lukasiewicz, T.; Xu, Z. Multi-ConDoS: Multimodal contrastive domain sharing generative adversarial networks for self-supervised medical image segmentation. IEEE Trans. Med. Imaging 2023, 43, 76–95. [Google Scholar] [CrossRef]
- Fu, S.; Liu, W.; Zhang, K.; Zhou, Y.; Tao, D. Semi-supervised classification by graph p-Laplacian convolutional networks. Inf. Sci. 2021, 560, 92–106. [Google Scholar] [CrossRef]
- Luo, X.; Hu, M.; Song, T.; Wang, G.; Zhang, S. XLuo; Hu, M.; Song, T.; Wang, G.; Zhang, S. Semi-supervised medical image segmentation via cross teaching between cnn and transformer. In Proceedings of the International Conference on Medical Imaging with Deep Learning, PMLR, Zurich, Switzerland, 6–8 July 2022; pp. 820–833. [Google Scholar]
- Lai, X.; Tian, Z.; Jiang, L.; Liu, S.; Zhao, H.; Wang, L.; Jia, J. Semi-supervised semantic segmentation with directional context-aware consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1205–1214. [Google Scholar]
- Abramovich, O.; Pizem, H.; Van Eijgen, J.; Oren, I.; Melamed, J.; Stalmans, I.; Blumenthal, E.Z.; Behar, J.A. FundusQ-Net: A regression quality assessment deep learning algorithm for fundus images quality grading. Comput. Methods Programs Biomed. 2023, 239, 107522. [Google Scholar] [CrossRef]
- Liawrungrueang, W.; Kim, P.; Kotheeranurak, V.; Jitpakdee, K.; Sarasombath, P. Automatic detection, classification, and grading of lumbar intervertebral disc degeneration using an artificial neural network model. Diagnostics 2023, 13, 663. [Google Scholar] [CrossRef]
- Rastogi, D.; Johri, P.; Tiwari, V.; Elngar, A.A. Multi-class classification of brain tumour magnetic resonance images using multi-branch network with inception block and five-fold cross validation deep learning framework. Biomed. Signal Process. Control 2024, 88, 105602. [Google Scholar] [CrossRef]
- Batra, K.; Adams, T.N. Imaging features of idiopathic interstitial lung diseases. J. Thorac. Imaging 2023, 38, S19–S29. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 2021, 34, 5586–5609. [Google Scholar] [CrossRef]
- Wu, W.; Yan, J.; Zhao, Y.; Sun, Q.; Zhang, H.; Cheng, J.; Liang, D.; Chen, Y.; Zhang, Z.; Li, Z.-C. Multi-task learning for concurrent survival prediction and semi-supervised segmentation of gliomas in brain MRI. Displays 2023, 78, 102402. [Google Scholar] [CrossRef]
- Zeng, L.-L.; Gao, K.; Hu, D.; Feng, Z.; Hou, C.; Rong, P.; Wang, W. SS-TBN: A Semi-Supervised Tri-Branch Network for COVID-19 Screening and Lesion Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10427–10442. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Wang, W.; Luo, G.; Wang, K.; Li, S. A contrastive consistency semi-supervised left atrium segmentation model. Comput. Med Imaging Graph. 2022, 99, 102092. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1196–1205. [Google Scholar]
- Yu, L.; Wang, S.; Li, X.; Fu, C.-W.; Heng, P.-A. Uncertainty-aware self-ensembling model for semi-supervised 3D left atrium segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; pp. 605–613. [Google Scholar]
- Grandvalet, Y.; Bengio, Y. Semi-supervised learning by entropy minimization. Adv. Neural Inf. Process. Syst. 2004, 17. [Google Scholar]
- Verma, V.; Lamb, A.; Kannala, J.; Bengio, Y.; Lopez-Paz, D. Interpolation consistency training for semi-supervised learning. Neural Netw. 2022, 145, 90–106. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, L.; Chen, J.; Fredericksen, M.; Hughes, D.P.; Chen, D.Z. Deep adversarial networks for biomedical image segmentation utilizing unannotated images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; pp. 408–416. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-supervised semantic segmentation with cross-consistency training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12674–12684. [Google Scholar]
- Zhao, X.; Fang, C.; Fan, D.-J.; Lin, X.; Gao, F.; Li, G. Cross-level contrastive learning and consistency constraint for semi-supervised medical image segmentation. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process Syst. 2012, 2, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Shin, S.; King, C.S.; Puri, N.; Shlobin, O.A.; Brown, A.W.; Ahmad, S.; Weir, N.A.; Nathan, S.D. Pulmonary artery size as a predictor of outcomes in idiopathic pulmonary fibrosis. Eur. Respir. J. 2016, 47, 1445–1451. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | IoU (%) | Dice (%) | HD95 | ASSD |
|---|---|---|---|---|
| MN | 59.0 | 71.1 | 12.88 | 2.02 |
| UAMT | 55.8 | 67.5 | 16.11 | 1.21 |
| EM | 58.5 | 71.1 | 14.38 | 2.99 |
| DAN | 57.9 | 70.1 | 17.43 | 4.95 |
| ICT | 63.1 | 75.2 | 8.60 | 1.81 |
| CCT | 56.6 | 70.1 | 22.60 | 6.06 |
| CTCT | 71.0 | 82.0 | 7.04 | 1.00 |
| CLCC | 58.8 | 71.9 | 14.80 | 3.42 |
| Ours | 75.6 | 85.5 | 4.95 | 0.77 |
| Methods | IoU (%) | Dice (%) | HD95 | ASSD |
|---|---|---|---|---|
| MN | 53.3 | 65.5 | 16.40 | 2.48 |
| UAMT | 48.6 | 60.0 | 16.74 | 1.78 |
| EM | 44.7 | 56.1 | 14.92 | 1.28 |
| DAN | 51.6 | 63.4 | 15.24 | 3.48 |
| ICT | 52.6 | 64.2 | 17.77 | 2.29 |
| CCT | 50.4 | 62.4 | 14.42 | 2.21 |
| CTCT | 68.5 | 78.3 | 9.95 | 1.23 |
| CLCC | 55.7 | 65.1 | 26.26 | 4.46 |
| Ours | 72.9 | 81.2 | 8.88 | 1.46 |
| Data | Methods | IoU (%) | Dice (%) | HD95 | ASSD |
|---|---|---|---|---|---|
| 10% Labeled | MN | 53.5 | 64.3 | 31.30 | 7.22 |
| UAMT | 49.9 | 60.5 | 36.06 | 9.09 | |
| EM | 49.4 | 61.4 | 41.16 | 11.24 | |
| DAN | 51.7 | 63.6 | 37.17 | 10.32 | |
| ICT | 55.9 | 67.1 | 32.62 | 7.79 | |
| CCT | 50.9 | 61.6 | 33.45 | 6.62 | |
| CTCT | 57.2 | 67.8 | 31.95 | 7.24 | |
| CLCC | 53.4 | 64.5 | 55.25 | 16.98 | |
| Ours | 70.0 | 79.3 | 20.72 | 4.34 | |
| 20% Labeled | MN | 63.7 | 73.9 | 24.41 | 5.38 |
| UAMT | 62.6 | 72.9 | 30.66 | 8.58 | |
| EM | 64.9 | 75.0 | 25.56 | 6.83 | |
| DAN | 62.3 | 73.0 | 29.14 | 8.14 | |
| ICT | 67.0 | 76.9 | 24.86 | 6.47 | |
| CCT | 65.1 | 74.9 | 24.14 | 5.41 | |
| CTCT | 68.7 | 77.8 | 20.12 | 4.13 | |
| CLCC | 59.8 | 71.3 | 53.94 | 17.09 | |
| Ours | 71.1 | 80.3 | 20.498 | 3.22 |
| Methods | Acc (%) | Pre (%) | Sen (%) | F1 (%) |
|---|---|---|---|---|
| AlexNet | 68.48 | 70.77 | 68.55 | 66.80 |
| VGG19 | 87.17 | 84.54 | 86.43 | 84.33 |
| ResNet18 | 87.86 | 85.06 | 85.80 | 84.87 |
| MobileNetV2 | 87.59 | 85.05 | 87.08 | 84.86 |
| DenseNet121 | 87.73 | 87.06 | 8.60 | 85.14 |
| Ours | 89.68 | 87.35 | 89.45 | 87.34 |
| Grades | Ours | Physician |
|---|---|---|
| I | 31 | 25 |
| II | 104 | 109 |
| III | 57 | 65 |
| IV | 18 | 11 |
| IoU (%) | Dice (%) | HD95 | ASSD | |||||
|---|---|---|---|---|---|---|---|---|
| √ | 66.8 | 78.7 | 9.12 | 1.14 | ||||
| √ | √ | 71.0 | 82.0 | 7.04 | 1.00 | |||
| √ | √ | √ | 72.2 | 83.0 | 6.30 | 0.98 | ||
| √ | √ | √ | 72.8 | 83.2 | 6.41 | 0.83 | ||
| √ | √ | √ | √ | 73.7 | 84.1 | 6.35 | 0.84 | |
| √ | √ | √ | √ | √ | 75.6 | 85.5 | 4.95 | 0.77 |
| Methods | IoU (%) | Dice (%) | HD95 | ASSD |
|---|---|---|---|---|
| single-seg | 73.7 | 84.1 | 6.35 | 0.84 |
| multitask | 75.6 | 85.5 | 4.95 | 0.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Yang, B.; Feng, X. Multitask Learning for Concurrent Grading Diagnosis and Semi-Supervised Segmentation of Honeycomb Lung in CT Images. Electronics 2024, 13, 2115. https://doi.org/10.3390/electronics13112115
Dong Y, Yang B, Feng X. Multitask Learning for Concurrent Grading Diagnosis and Semi-Supervised Segmentation of Honeycomb Lung in CT Images. Electronics. 2024; 13(11):2115. https://doi.org/10.3390/electronics13112115
Chicago/Turabian StyleDong, Yunyun, Bingqian Yang, and Xiufang Feng. 2024. "Multitask Learning for Concurrent Grading Diagnosis and Semi-Supervised Segmentation of Honeycomb Lung in CT Images" Electronics 13, no. 11: 2115. https://doi.org/10.3390/electronics13112115
APA StyleDong, Y., Yang, B., & Feng, X. (2024). Multitask Learning for Concurrent Grading Diagnosis and Semi-Supervised Segmentation of Honeycomb Lung in CT Images. Electronics, 13(11), 2115. https://doi.org/10.3390/electronics13112115