


Enhancing Edge-Assisted Federated Learning with Asynchronous Aggregation and Cluster Pairing

Abstract
1. Introduction
- We propose a novel semi-asynchronous training and aggregation strategy to significantly improve the convergence speed at the edge for the three-layer federated learning architecture. In each training round, the clients in the coverage area of the same edge server are asynchronously trained with the subglobal model obtained after the edge aggregation. This strategy effectively trades the waiting time with local model training to accelerate the convergence.
- We design an edge–client matching strategy to adapt to the semi-asynchronous architecture. Based on the similarity of the local models, the clients are selected to have as far away a distance represented by their data distribution as possible so that the asynchronous training results in each edge cluster are more close to the global model and thus achieve a faster convergence speed.
- We design a new loss function by integrating the concept of personalized federated learning into model-contrastive FL aimed at preserving the historical local information in the local training process, learning both global and local representations, and further accelerating the convergence process to enhance the accuracy of the global model.
2. Related Work
2.1. Edge-Assisted FL
2.2. Non-IID Data
2.3. Cluster Pairing
3. Problem Formulation and Motivations
3.1. Problem Formulation
3.2. Motivation
- Edge-NIID: The data labels owned by clients under each edge are similar (i.e., each edge only contains samples from 3–4 classes).
- Edge-IID: The data labels owned by clients under each edge are different (i.e., each edge contains samples from 8–9 classes).
- Edge-random: The matching between edge servers and clients is performed entirely at random, and the data distribution is random.
4. Method
4.1. EEFL Design
4.2. Crosslayer Asynchronous Aggregation in Federated Learning
4.3. Data Distribution Feature Extraction
| Algorithm 1: Data feature extraction |
 |
4.4. Improvement on Model-Contrastive Federated Learning
5. Experiment
5.1. Experiment Setup
- MNIST [34]: The MNIST dataset consists of 70,000 grayscale images of handwritten digits, with each sized 28 × 28 and divided into 10 classes. Each class contains 7000 images. The dataset is further divided into 60,000 training images and 10,000 test images.
- CIFAR10 [35]: CIFAR10 is a dataset of 60,000 color images, with each being 32 × 32 pixels in size and divided into 10 classes. It has 6000 images per class, with a training set of 50,000 images and a test set of 10,000 images. Unlike the grayscale images in MNIST and FashionMNIST, CIFAR10 contains color images, which adds an additional dimension to the data.
- FahionMNIST [36]: This dataset consists of 70,000 grayscale images of fashion products, with each image sized 28 × 28. The dataset is categorized into 10 different categories, with 7000 images in each category. Similar to the MNIST dataset, Fashion-MNIST also includes a training set of 60,000 images and a test set of 10,000 images.
5.2. Evaluation and Baseline
- Test accuracy: The top accuracy of the global model after 200 communication rounds.
- Rounds with the cloud sever: Communication rounds to achieve the target accuracy.
- Time and energy consumption: Total time and energy consumed to achieve target accuracy.
- Centralized learning: This scheme collects all the raw data to the cloud for training and provides an upper bound for model accuracy.
- FedAVG [1]: A traditional cloud-based FL scheme with synchronous aggregation.
- FedProx [12]: A cloud-based FL scheme with synchronous aggregation, which adds a proximal term in the local training process.
- MOON [14]: A cloud-based FL scheme with synchronous aggregation, which adds extra model-contrasitive loss in the local training process.
- HierFAVG [5]: A cloud–edge–client hierarchical FL scheme that performs synchronous update in both client–edge aggregation and edge–cloud aggregation.
5.3. Experimental Results
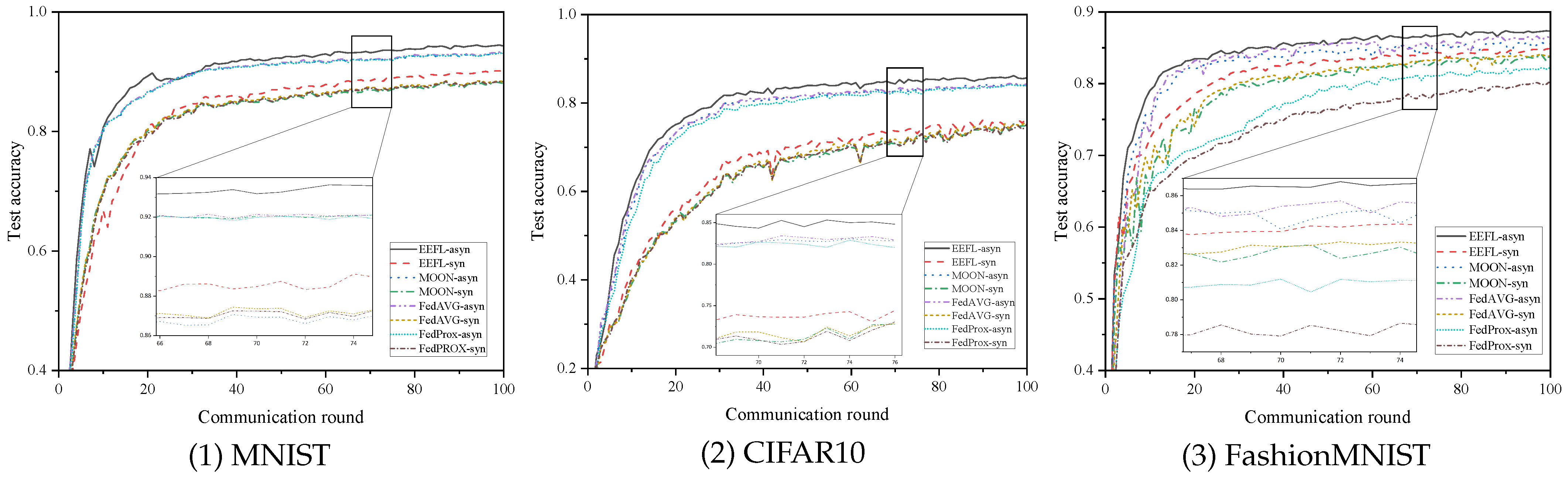
5.3.1. Test Accuracy and Iterations
5.3.2. Similarity Pairing Strategy
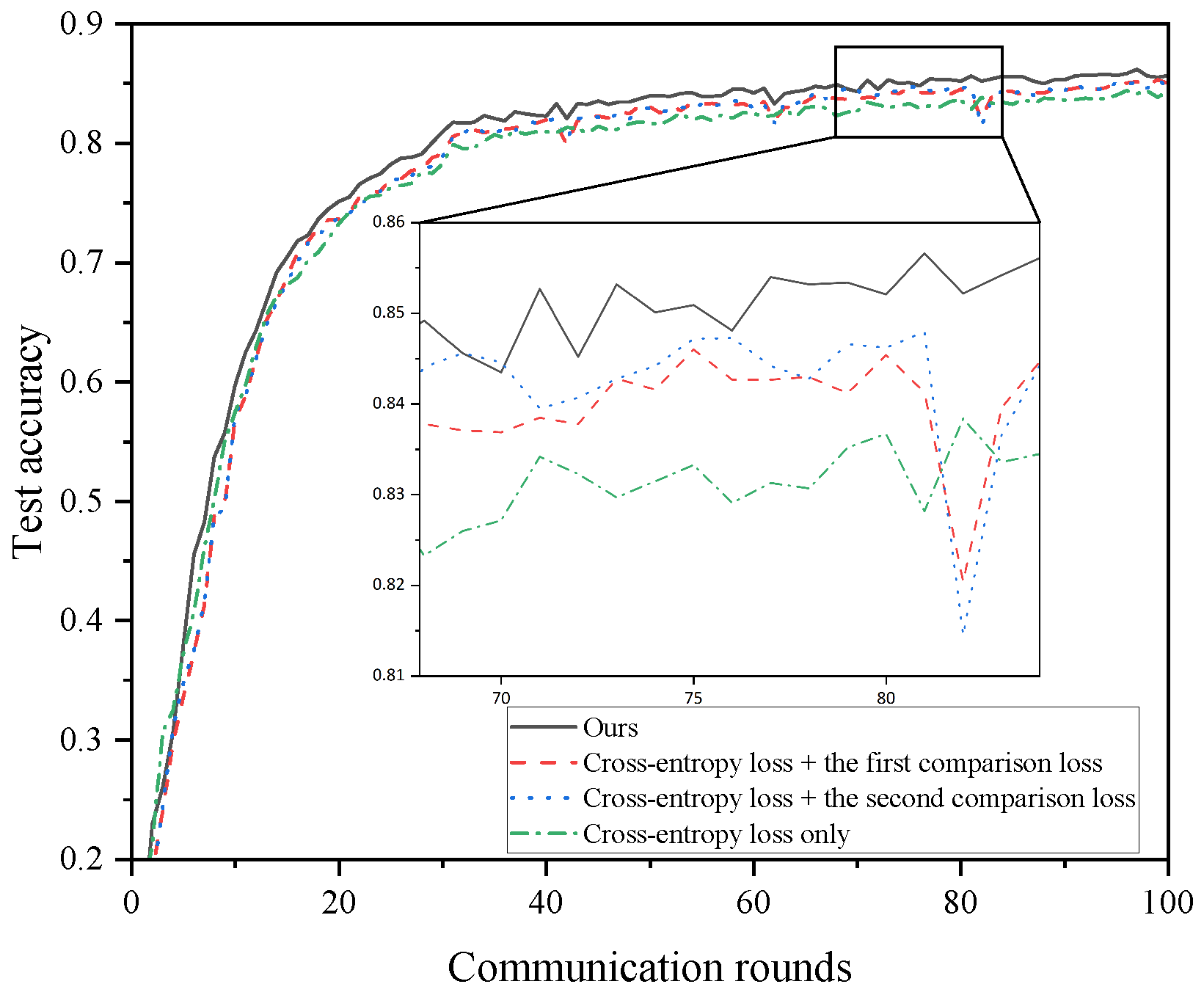
5.3.3. Loss Function
- Our design.
- Crossentropy loss and the first comparison loss.
- Crossentropy loss and the second comparison loss.
- Crossentropy loss only.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 20–22 April 2017; PMLR: New York, NY, USA, 2017; pp. 1273–1282. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 739–753. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.T.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2019, 22, 2031–2063. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.H.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Wu, Q.; Chen, X.; Ouyang, T.; Zhou, Z.; Zhang, X.; Yang, S.; Zhang, J. Hiflash: Communication-efficient hierarchical federated learning with adaptive staleness control and heterogeneity-aware client-edge association. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 1560–1579. [Google Scholar] [CrossRef]
- Xu, M.; Fu, Z.; Ma, X.; Zhang, L.; Li, Y.; Qian, F.; Wang, S.; Li, K.; Yang, J.; Liu, X. From cloud to edge: A first look at public edge platforms. In Proceedings of the 21st ACM Internet Measurement Conference, Virtual, 2–4 November 2021; pp. 37–53. [Google Scholar]
- Tran, N.H.; Bao, W.; Zomaya, A.Y.; Nguyen, M.N.H.; Hong, C.S. Federated Learning over Wireless Networks: Optimization Model Design and Analysis. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1387–1395. [Google Scholar]
- Chen, M.; Shlezinger, N.; Poor, H.V.; Eldar, Y.C.; Cui, S. Communication-efficient federated learning. Proc. Natl. Acad. Sci. USA 2021, 118, e2024789118. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Wang, Z.; Dou, Q. HarmoFL: Harmonizing Local and Global Drifts in Federated Learning on Heterogeneous Medical Images. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 1087–1095. [Google Scholar]
- Li, Q.; Diao, Y.; Chen, Q.; He, B. Federated Learning on Non-IID Data Silos: An Experimental Study. In Proceedings of the IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 965–978. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5132–5143. [Google Scholar]
- Li, Q.; He, B.; Song, D.X. Model-Contrastive Federated Learning. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10708–10717. [Google Scholar]
- Ghosh, A.; Hong, J.; Yin, D.; Ramchandran, K. Robust federated learning in a heterogeneous environment. arXiv 2019, arXiv:1906.06629. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An Efficient Framework for Clustered Federated Learning. IEEE Trans. Inf. Theory 2020, 68, 8076–8091. [Google Scholar] [CrossRef]
- Gong, B.; Xing, T.; Liu, Z.; Xi, W.; Chen, X. Adaptive client clustering for efficient federated learning over non-iid and imbalanced data. IEEE Trans. Big Data 2022, 99, 1–15. [Google Scholar] [CrossRef]
- Liu, B.; Guo, Y.; Chen, X. PFA: Privacy-preserving federated adaptation for effective model personalization. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 923–934. [Google Scholar]
- Xia, W.; Wen, W.; Wong, K.; Quek, T.Q.S.; Zhang, J.; Zhu, H. Federated-Learning-Based Client Scheduling for Low-Latency Wireless Communications. IEEE Wirel. Commun. 2021, 28, 32–38. [Google Scholar] [CrossRef]
- Dinh, T.Q.; Nguyen, D.N.; Hoang, D.T.; Pham, T.V.; Dutkiewicz, E. In-Network Computation for Large-Scale Federated Learning Over Wireless Edge Networks. IEEE Trans. Mob. Comput. 2021, 22, 5918–5932. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and Communication-Efficient Federated Learning from Non-i.i.d. Data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Yu, G.; Yin, R.; Yuan, J.; Shen, L.; Liu, C. Joint Model Pruning and Device Selection for Communication-Efficient Federated Edge Learning. IEEE Trans. Commun. 2022, 70, 231–244. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Mokhtari, A.; Hassani, H.; Jadbabaie, A.; Pedarsani, R. FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 2021–2031. [Google Scholar]
- Qu, Z.; Duan, R.; Chen, L.; Xu, J.; Lu, Z.; Liu, Y. Context-Aware Online Client Selection for Hierarchical Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 4353–4367. [Google Scholar] [CrossRef]
- Wolfrath, J.; Sreekumar, N.; Kumar, D.; Wang, Y.; Chandra, A. HACCS: Heterogeneity-Aware Clustered Client Selection for Accelerated Federated Learning. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Lyon, France, 30 May–3 June 2022; pp. 985–995. [Google Scholar]
- Wang, K.; He, Q.; Chen, F.; Jin, H.; Yang, Y. FedEdge: Accelerating Edge-Assisted Federated Learning. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 2895–2904. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Collins, L.; Hassani, H.; Mokhtari, A.; Shakkottai, S. Exploiting Shared Representations for Personalized Federated Learning. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 2089–2099. [Google Scholar]
- Duan, Q.; Huang, J.; Hu, S.; Deng, R.; Lu, Z.; Yu, S. Combining federated learning and edge computing toward ubiquitous intelligence in 6G network: Challenges, recent advances, and future directions. IEEE Commun. Surv. Tutor. 2023, 25, 2892–2950. [Google Scholar] [CrossRef]
- Dennis, D.K.; Li, T.; Smith, V. Heterogeneity for the win: One-shot federated clustering. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: New York, NY, USA, 2021; pp. 2611–2620. [Google Scholar]
- Long, G.; Xie, M.; Shen, T.; Zhou, T.; Wang, X.; Jiang, J. Multi-center federated learning: Clients clustering for better personalization. World Wide Web 2023, 26, 481–500. [Google Scholar] [CrossRef]
- Duan, M.; Liu, D.; Ji, X.; Liu, R.; Liang, L.; Chen, X.; Tan, Y. FedGroup: Efficient Federated Learning via Decomposed Similarity-Based Clustering. In Proceedings of the 2021 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), New York, NY, USA, 30 September–3 October 2021; pp. 228–237. [Google Scholar]
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. Handb. Syst. Autoimmune Dis. 2009, 1, 1–60. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Yurochkin, M.; Agarwal, M.; Ghosh, S.; Greenewald, K.; Hoang, N.; Khazaeni, Y. Bayesian nonparametric federated learning of neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 7252–7261. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MNIST | CIFAR10 | FashionMNIST | |
|---|---|---|---|
| batch size | 20 | 25 | 32 |
| learning rate | 0.1 | 0.01 | 0.1 |
| hyperparameter | 10 | 0.05 | 0.01 |
| hyperparameter | 0.1 | 10 | 1 |
| total parameters | 21,840 | 3,493,197 | 421,642 |
| EEFL (OURS) | FEDAVG [1] | MOON [14] | FEDPROX [12] | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Top Acc | Rounds to Target | Top Acc | Rounds to Target | Top Acc | Rounds to Target | Top Acc | Rounds to Target | ||
| MNIST | asyn | 0.9446 | 30 | 0.9328 | 33 | 0.9309 | 31 | 0.932 | 32 |
| syn | 0.9043 | 85 | 0.8831 | 100+ | 0.8832 | 100+ | 0.8836 | 100+ | |
| Cifar10 | asyn | 0.862 | 29 | 0.8443 | 35 | 0.842 | 33 | 0.8417 | 44 |
| syn | 0.769 | 161 | 0.7572 | 171 | 0.7526 | 165 | 0.7523 | 177 | |
| FashionMNIST | asyn | 0.8736 | 31 | 0.8579 | 61 | 0.8568 | 76 | 0.8232 | 100+ |
| syn | 0.8487 | 113 | 0.8441 | 127 | 0.8335 | 139 | 0.8034 | 200+ | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sha, X.; Sun, W.; Liu, X.; Luo, Y.; Luo, C. Enhancing Edge-Assisted Federated Learning with Asynchronous Aggregation and Cluster Pairing. Electronics 2024, 13, 2135. https://doi.org/10.3390/electronics13112135
Sha X, Sun W, Liu X, Luo Y, Luo C. Enhancing Edge-Assisted Federated Learning with Asynchronous Aggregation and Cluster Pairing. Electronics. 2024; 13(11):2135. https://doi.org/10.3390/electronics13112135
Chicago/Turabian StyleSha, Xiaobao, Wenjian Sun, Xiang Liu, Yang Luo, and Chunbo Luo. 2024. "Enhancing Edge-Assisted Federated Learning with Asynchronous Aggregation and Cluster Pairing" Electronics 13, no. 11: 2135. https://doi.org/10.3390/electronics13112135
APA StyleSha, X., Sun, W., Liu, X., Luo, Y., & Luo, C. (2024). Enhancing Edge-Assisted Federated Learning with Asynchronous Aggregation and Cluster Pairing. Electronics, 13(11), 2135. https://doi.org/10.3390/electronics13112135