Automatic Modulation Recognition Method Based on Phase Transformation and Deep Residual Shrinkage Network

Abstract
:1. Introduction
- (1)
- This paper proposes an AMR model based on phase transformation and deep residual shrinkage network. A series of experiments demonstrate that the proposed model can improve recognition accuracy better than other state-of-the-art models, especially under low SNR conditions, and has fewer parameters.
- (2)
- The improved deep residual shrinkage network is added after the CNN, which can generate corresponding thresholds for convolutional feature maps of different channels. Using a soft threshold function to preserve or eliminate convolutional features, the impact of noise-related feature maps on modulation recognition will be reduced to a certain extent, thereby effectively improving recognition accuracy under low SNR conditions.
2. Signal Model and the Proposed Model
2.1. Signal Model
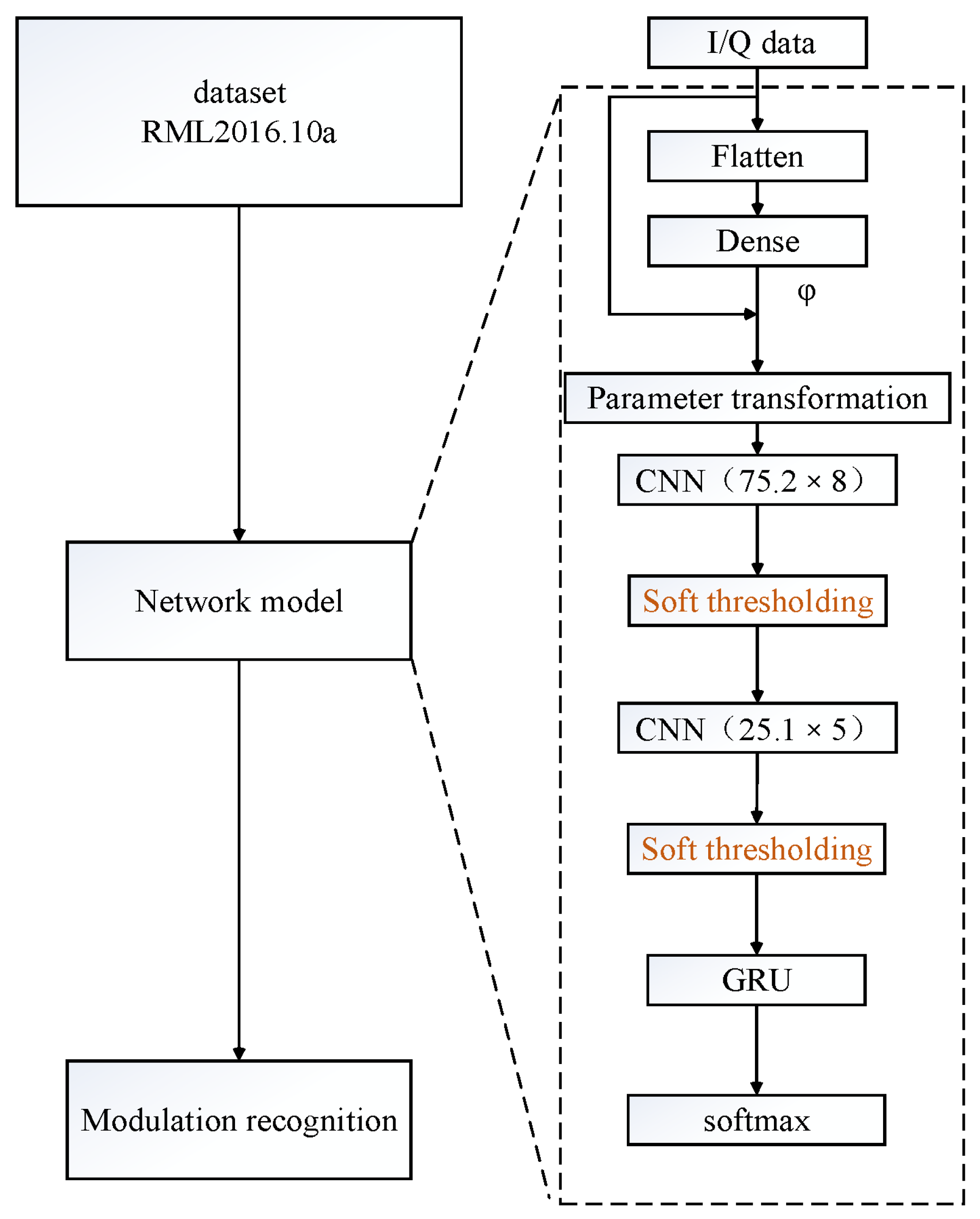
2.2. Proposed Model
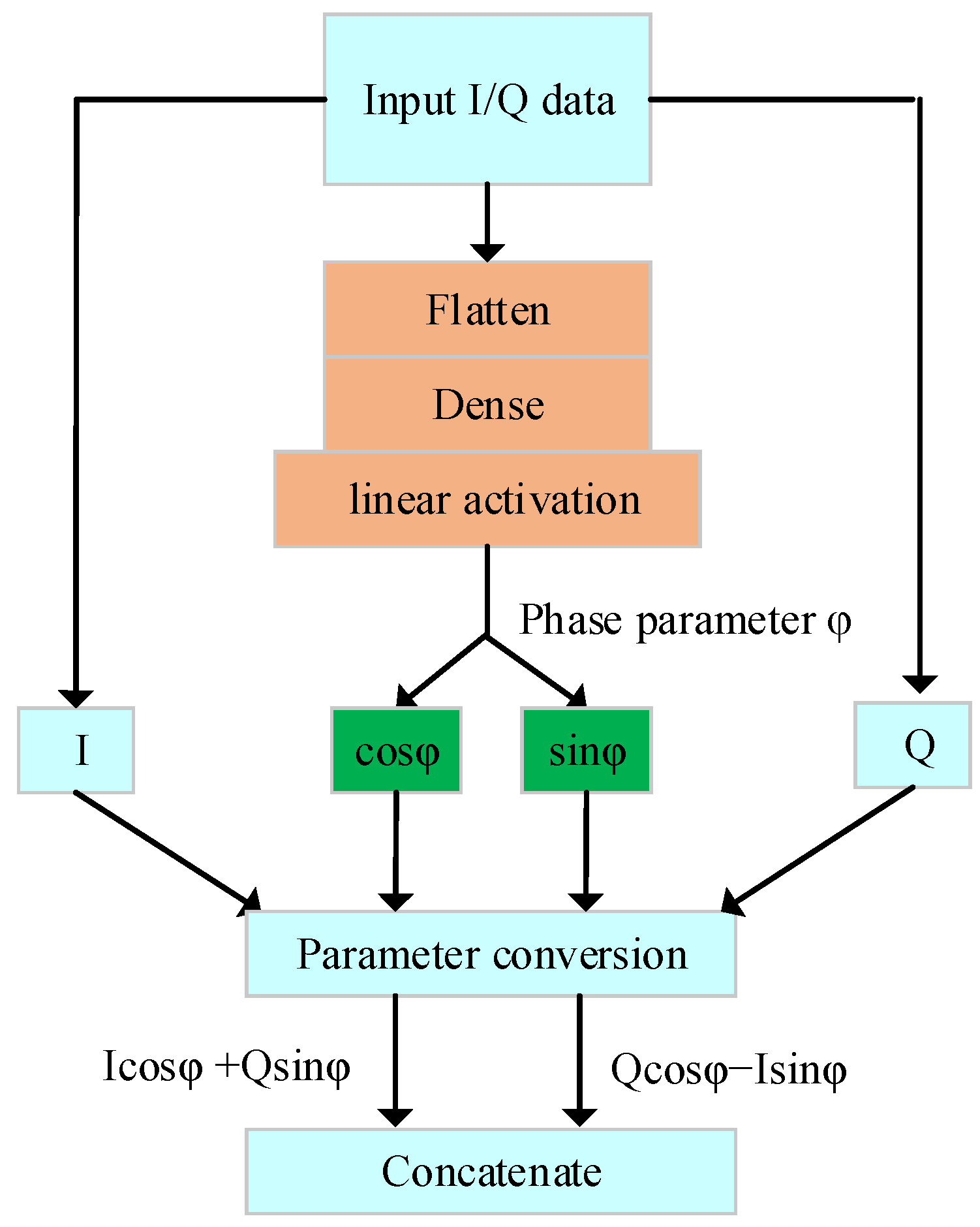
2.2.1. Phase Transformation
2.2.2. Soft Thresholding
3. Dataset and Implementation Details
3.1. Dataset
3.2. Implementation Detail
4. Experimental Results and Discussion
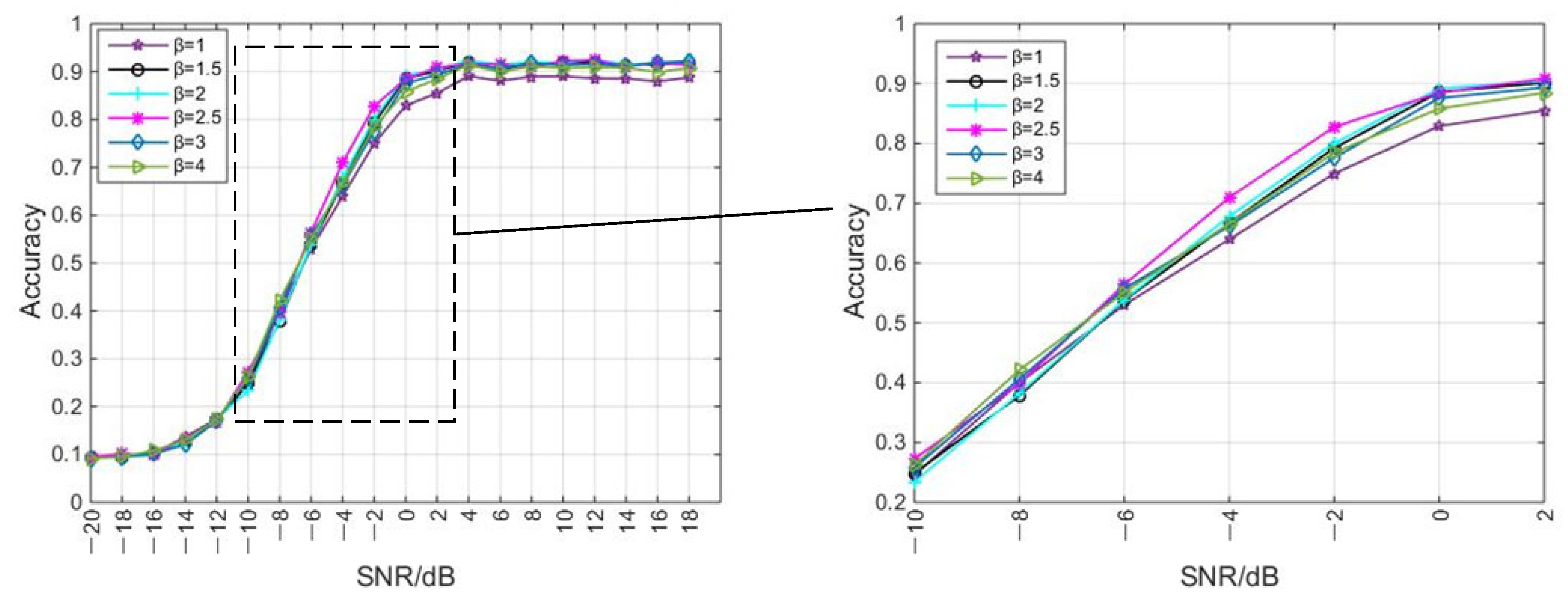
4.1. Scale Factor
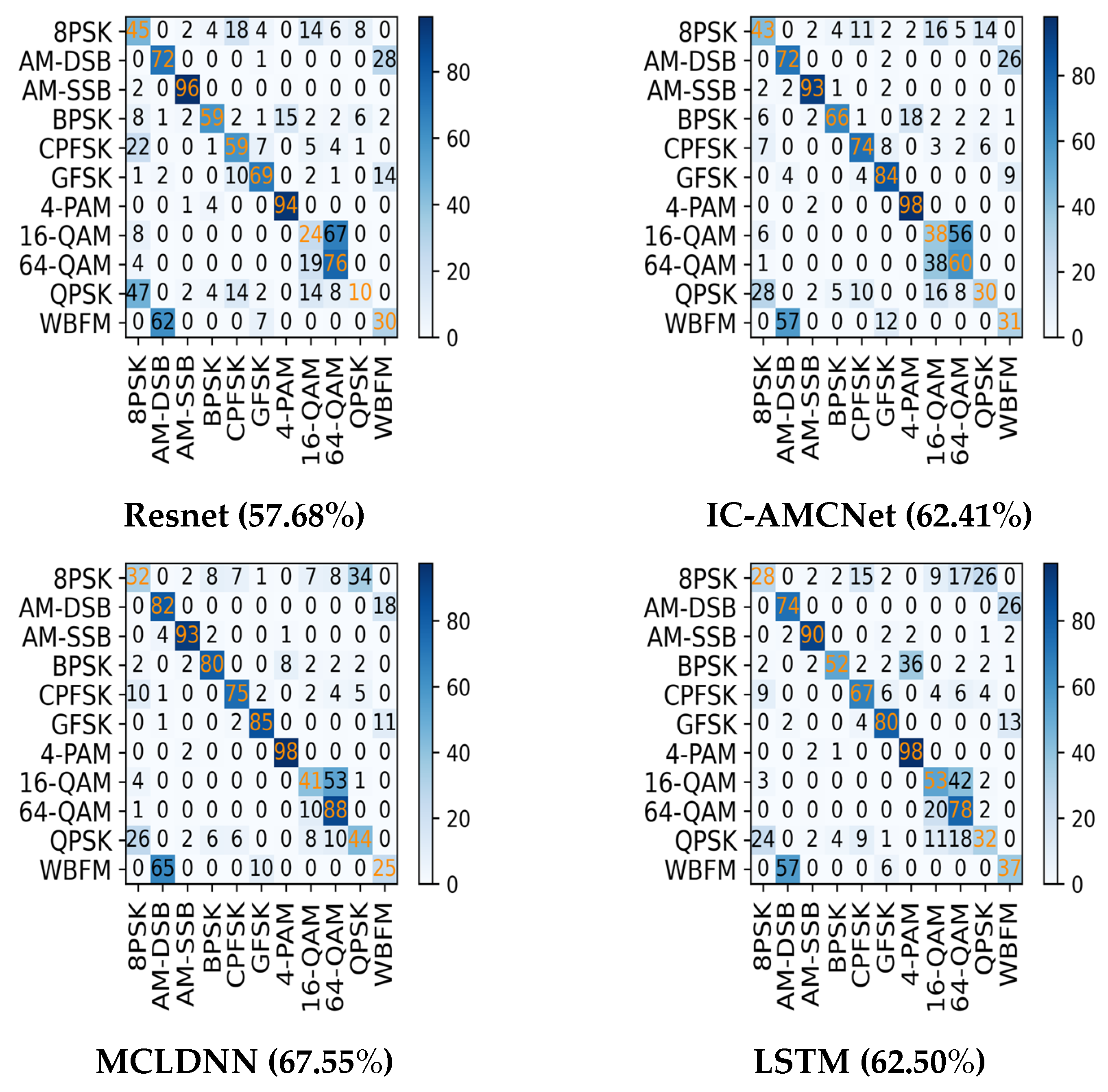
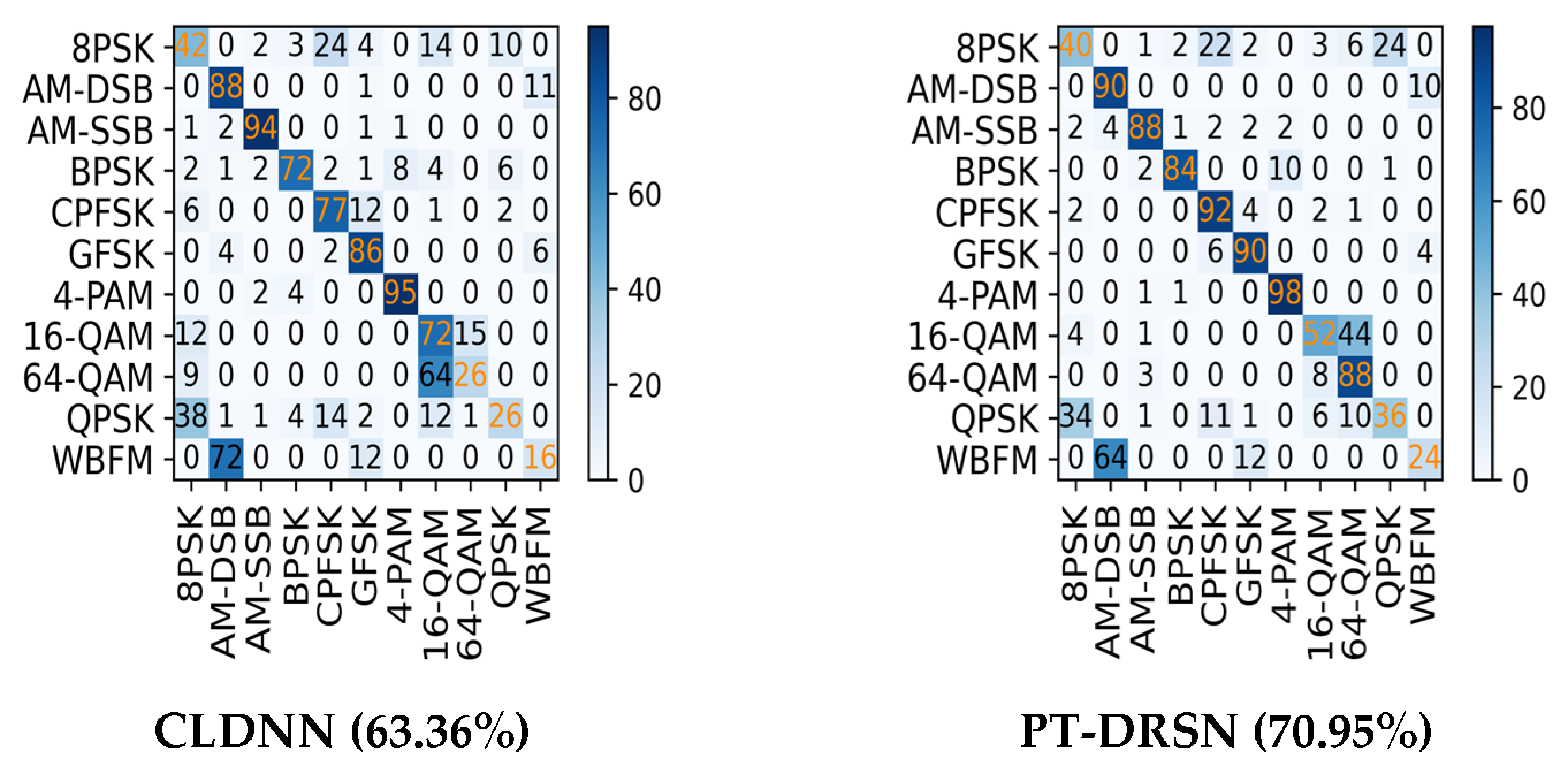
4.2. Recognition Accuracy of Different Models
4.3. Model Complexity
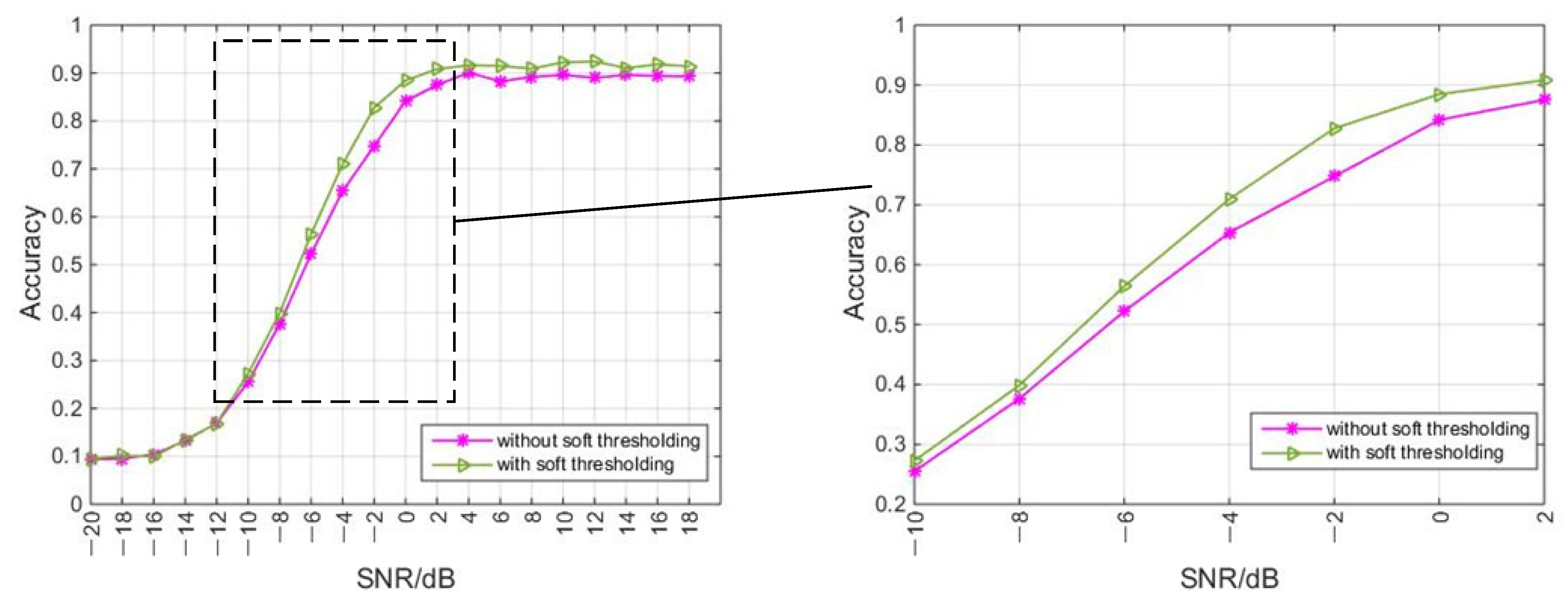
4.4. Module Effectiveness
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, J.; Luo, C.; Parr, G.; Luo, Y. A Spatiotemporal Multi-Channel Learning Framework for Automatic Modulation Recognition. IEEE Wirel. Commun. Lett. 2020, 9, 1629–1632. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y. An Efficient Deep Learning Model for Automatic Modulation Recognition Based on Parameter Estimation and Transformation. IEEE Commun. Lett. 2021, 25, 3287–3290. [Google Scholar] [CrossRef]
- Xu, J.L.; Su, W.; Zhou, M. Likelihood-Ratio Approaches to Automatic Modulation Classification. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 41, 455–469. [Google Scholar] [CrossRef]
- Wei, W.; Mendel, J.M. Maximum-Likelihood Classification for Digital Amplitude-Phase Modulations. IEEE Trans. Commun. 2000, 48, 189–193. [Google Scholar] [CrossRef]
- Dulek, B. Online Hybrid Likelihood Based Modulation Classification Using Multiple Sensors. IEEE Trans. Wirel. Commun. 2017, 16, 4984–5000. [Google Scholar] [CrossRef]
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An Overview of Feature-Based Methods for Digital Modulation Classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–6. [Google Scholar]
- Chan, Y.; Gadbois, L.; Yansouni, P. Identification of the Modulation Type of a Signal. In Proceedings of the ICASSP ’85, IEEE International Conference on Acoustics, Speech, and Signal Processing, Tampa, FL, USA, 26–29 April 1985; Volume 10, pp. 838–841. [Google Scholar]
- Hong, L.; Ho, K.C. Identification of Digital Modulation Types Using the Wavelet Transform. In Proceedings of the MILCOM 1999, IEEE Military Communications, Conference Proceedings (Cat. No.99CH36341), Atlantic City, NJ, USA, 31 October–3 November 1999; Volume 1, pp. 427–431. [Google Scholar]
- Swami, A.; Sadler, B.M. Hierarchical Digital Modulation Classification Using Cumulants. IEEE Trans. Commun. 2000, 48, 416–429. [Google Scholar] [CrossRef]
- Nandi, A.K.; Azzouz, E.E. Algorithms for Automatic Modulation Recognition of Communication Signals. IEEE Trans. Commun. 1998, 46, 431–436. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, J.; Zhang, X. Automatic Modulation Classification Based on Novel Feature Extraction Algorithms. IEEE Access 2020, 8, 16362–16371. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhang, Z.-Y.; Qiu, P.-L. Modulation Classification of Communication Signals. In Proceedings of the IEEE MILCOM 2004, Military Communications Conference, Monterey, CA, USA, 31 October–3 November 2004; Volume 3, pp. 1470–1476. [Google Scholar]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the Engineering Applications of Neural Networks, EANN 2016; Jayne, C., Iliadis, L., Eds.; Springer International Publishing AG: Cham, Switzerland, 2016; Volume 629, pp. 213–226. [Google Scholar]
- Liu, X.; Yang, D.; Gamal, A.E. Deep Neural Network Architectures for Modulation Classification. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 915–919. [Google Scholar]
- Zeng, Y.; Zhang, M.; Han, F.; Gong, Y.; Zhang, J. Spectrum Analysis and Convolutional Neural Network for Automatic Modulation Recognition. IEEE Wirel. Commun. Lett. 2019, 8, 929–932. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, H.; Wang, H.; Alwageed, H.; Zhou, Y.; Sebdani, M.M.; Yao, Y.-D. Modulation Classification Based on Signal Constellation Diagrams and Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 718–727. [Google Scholar] [CrossRef] [PubMed]
- He, P.; Zhang, Y.; Yang, X.; Xiao, X.; Wang, H.; Zhang, R. Deep Learning-Based Modulation Recognition for Low Signal-to-Noise Ratio Environments. Electronics 2022, 11, 4026. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, L.; Zhao, Y.; Yang, J.; Adebisi, B.; Gacanin, H.; Gui, G. Distributed Learning for Automatic Modulation Classification in Edge Devices. IEEE Wirel. Commun. Lett. 2020, 9, 2177–2181. [Google Scholar] [CrossRef]
- Cheng, Q.; Wang, H.; Zhu, B.; Shi, Y.; Xie, B. A Real-Time UAV Target Detection Algorithm Based on Edge Computing. Drones 2023, 7, 95. [Google Scholar] [CrossRef]
- Hermawan, A.P.; Ginanjar, R.R.; Kim, D.-S.; Lee, J.-M. CNN-Based Automatic Modulation Classification for Beyond 5G Communications. IEEE Commun. Lett. 2020, 24, 1038–1041. [Google Scholar] [CrossRef]
- Rajendran, S.; Meert, W.; Giustiniano, D.; Lenders, V.; Pollin, S. Deep Learning Models for Wireless Signal Classification With Distributed Low-Cost Spectrum Sensors. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 433–445. [Google Scholar] [CrossRef]
- Njoku, J.N.; Morocho-Cayamcela, M.E.; Lim, W. CGDNet: Efficient Hybrid Deep Learning Model for Robust Automatic Modulation Recognition. IEEE Netw. Lett. 2021, 3, 47–51. [Google Scholar] [CrossRef]
- Xu, Z.; Hou, S.; Fang, S.; Hu, H.; Ma, Z. A Novel Complex-Valued Hybrid Neural Network for Automatic Modulation Classification. Electronics 2023, 12, 4380. [Google Scholar] [CrossRef]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep Residual Shrinkage Networks for Fault Diagnosis. IEEE Trans. Ind. Inf. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Donoho, D.L. De-Noising by Soft-Thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Isogawa, K.; Ida, T.; Shiodera, T.; Takeguchi, T. Deep Shrinkage Convolutional Neural Network for Adaptive Noise Reduction. IEEE Signal Process. Lett. 2018, 25, 224–228. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale Factor | Average Recognition Accuracy (−20 dB–18 dB) |
|---|---|
| 1 | 59.69% |
| 1.5 | 61.65% |
| 2 | 61.85% |
| 2.5 | 62.46% |
| 3 | 61.64% |
| 4 | 61.40% |
| Model | Resnet | IC-AMCNet | MCLDNN | LSTM | CLDNN | PT-DRSN |
|---|---|---|---|---|---|---|
| Average recognition accuracy ([−14 dB, −2 dB]) | 35.83% | 37.86% | 41.51% | 39.57% | 38.44% | 43.93% |
| Model | Parameters | Training Time (per Epoch) |
|---|---|---|
| Resnet | 3,098,283 | 91 s |
| IC-AMCNet | 1,264,011 | 19 s |
| MCLDNN | 406,199 | 51 s |
| LSTM | 201,099 | 30 s |
| CLDNN | 517,643 | 64 s |
| PT-DRSN | 84,571 | 20 s |
| Model | Parameters | Training Time (per Epoch) | Average Recognition Accuracy | |
|---|---|---|---|---|
| (−20 dB–18 dB) | (−10 dB–2 dB) | |||
| With soft thresholding | 84,571 | 20 s | 62.46% | 65.22% |
| Without soft thresholding | 71,871 | 16 | 60.05% | 61.02% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Guo, W.; Kang, K.; Hu, G. Automatic Modulation Recognition Method Based on Phase Transformation and Deep Residual Shrinkage Network. Electronics 2024, 13, 2141. https://doi.org/10.3390/electronics13112141
Chen H, Guo W, Kang K, Hu G. Automatic Modulation Recognition Method Based on Phase Transformation and Deep Residual Shrinkage Network. Electronics. 2024; 13(11):2141. https://doi.org/10.3390/electronics13112141
Chicago/Turabian StyleChen, Hao, Wenpu Guo, Kai Kang, and Guojie Hu. 2024. "Automatic Modulation Recognition Method Based on Phase Transformation and Deep Residual Shrinkage Network" Electronics 13, no. 11: 2141. https://doi.org/10.3390/electronics13112141