

Improving Object Detection Accuracy with Self-Training Based on Bi-Directional Pseudo Label Recovery





Abstract
1. Introduction
- We explore the impact of recovered pseudo labels which become lost due to distortion or occlusion of the target objects, leading to poor confidence.
- We make a use of a bi-directional object tracker to be able to utilize past and future frames to recover the lost pseudo labels.
2. Related Work
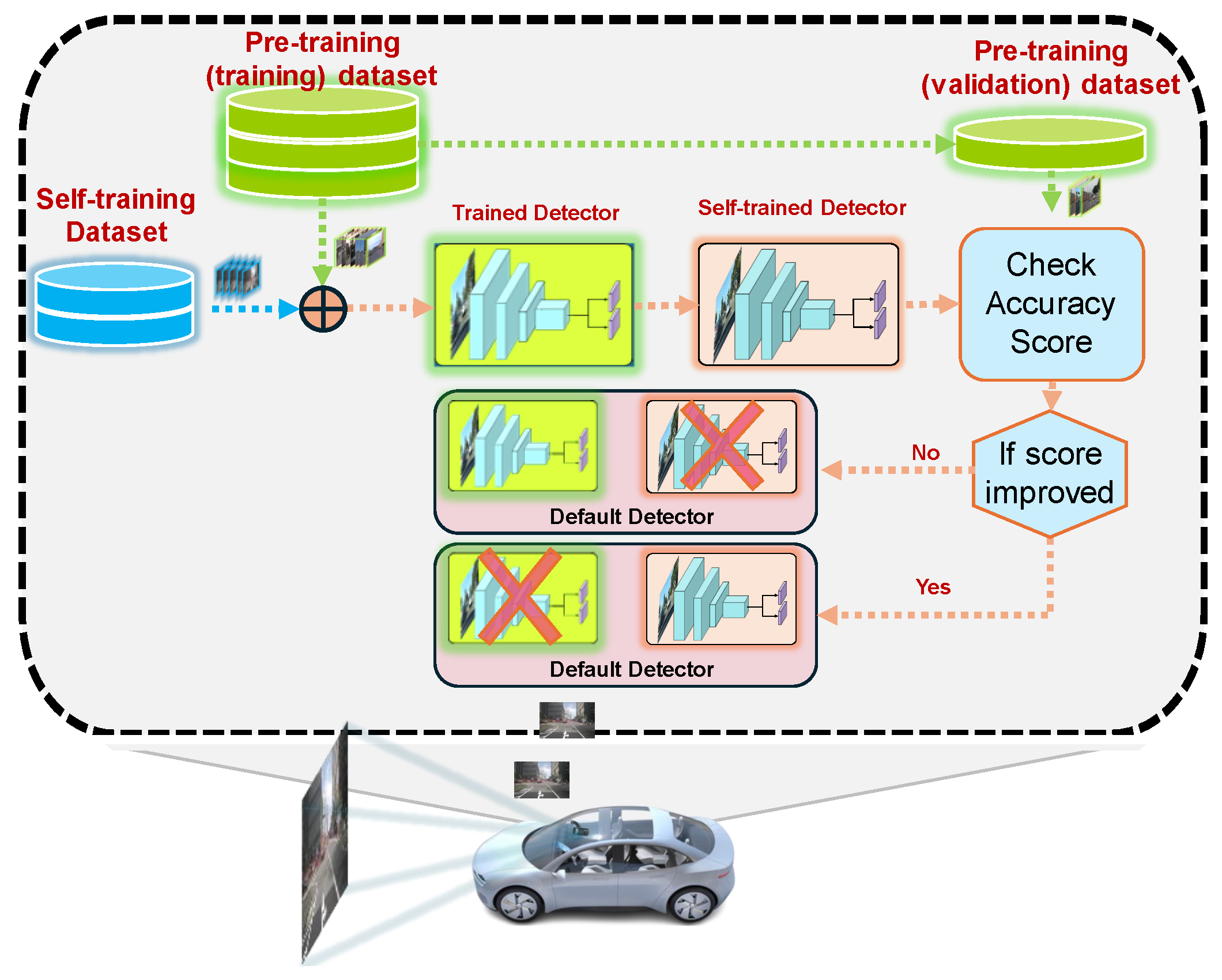
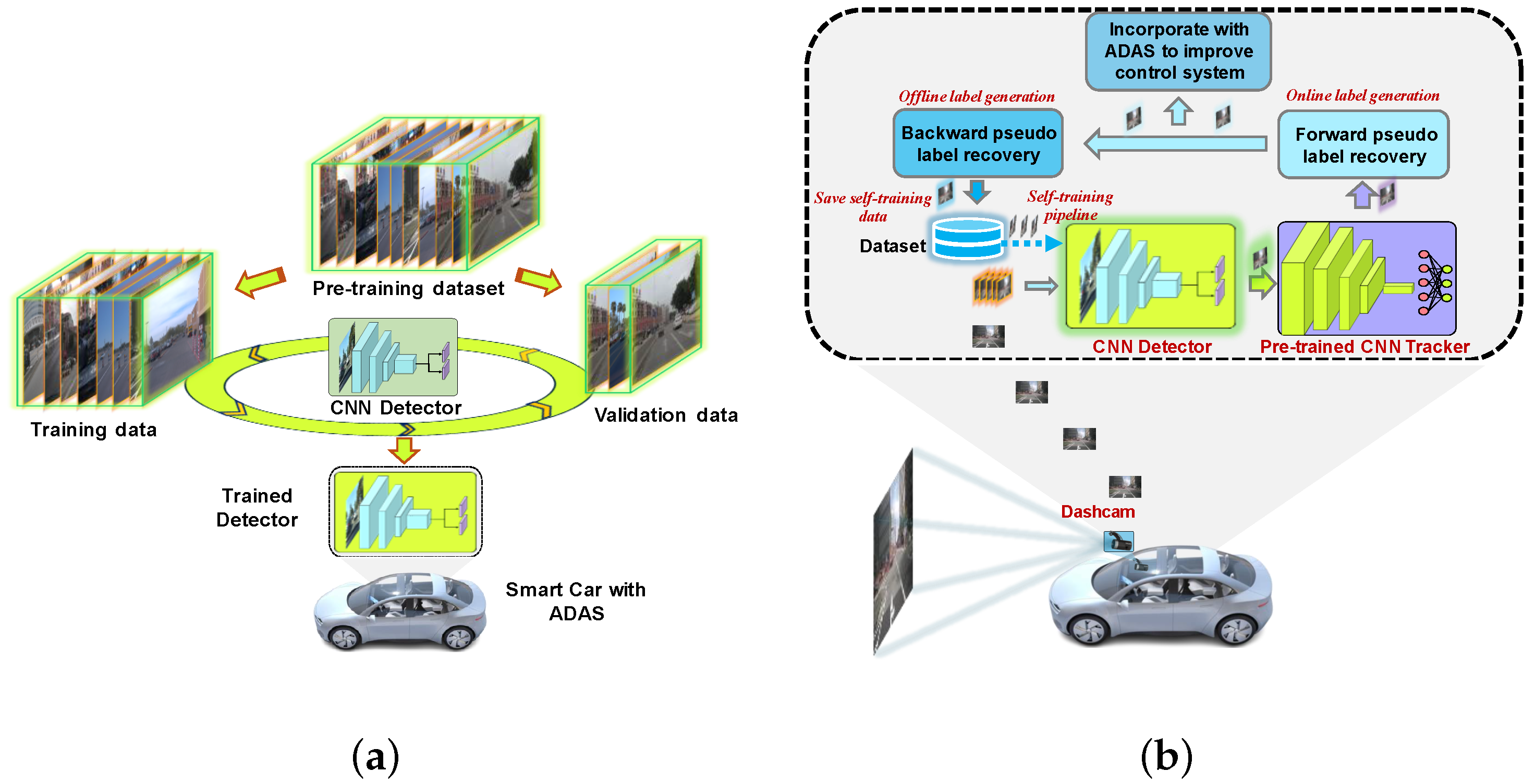
3. Proposed Method
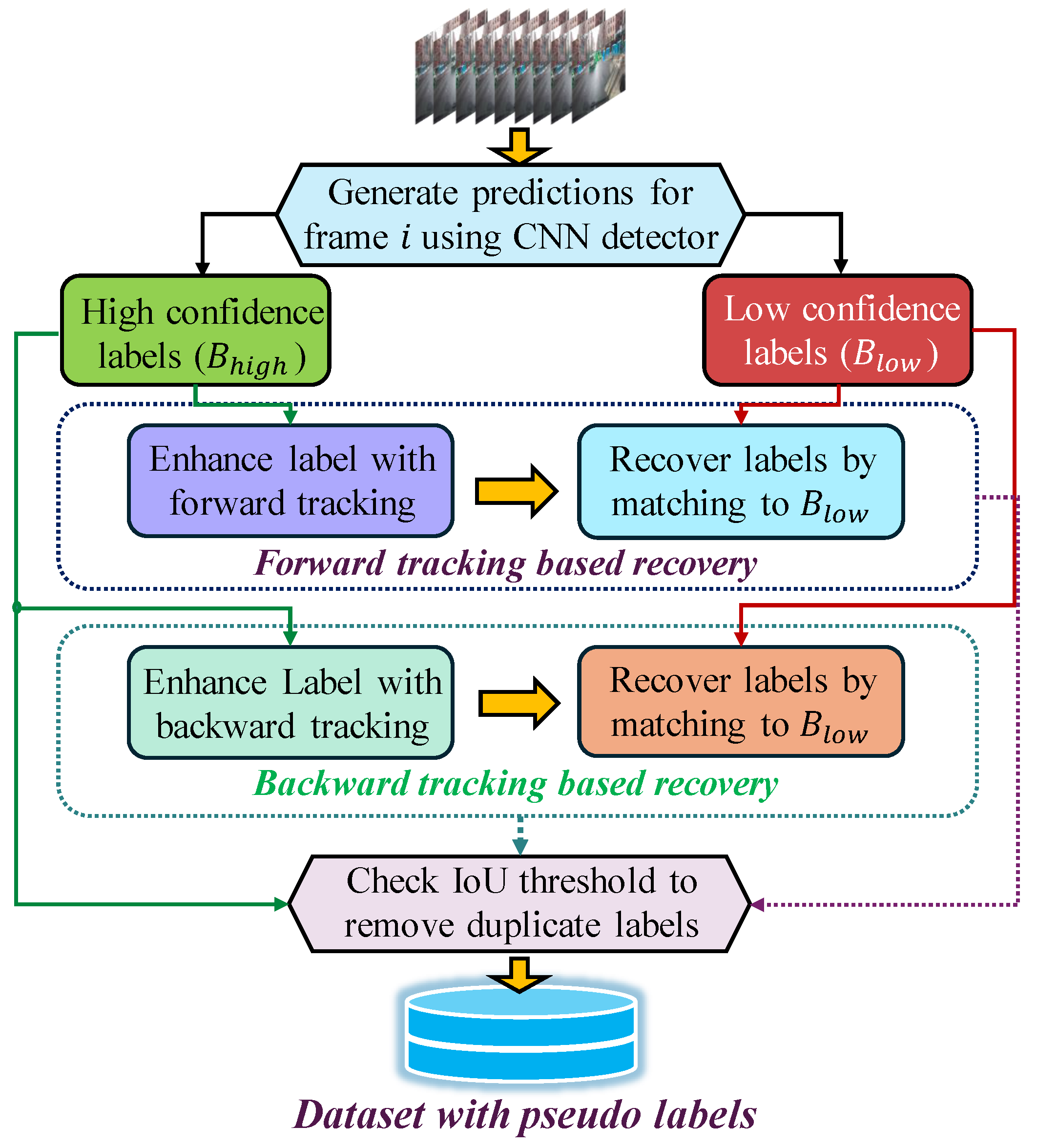
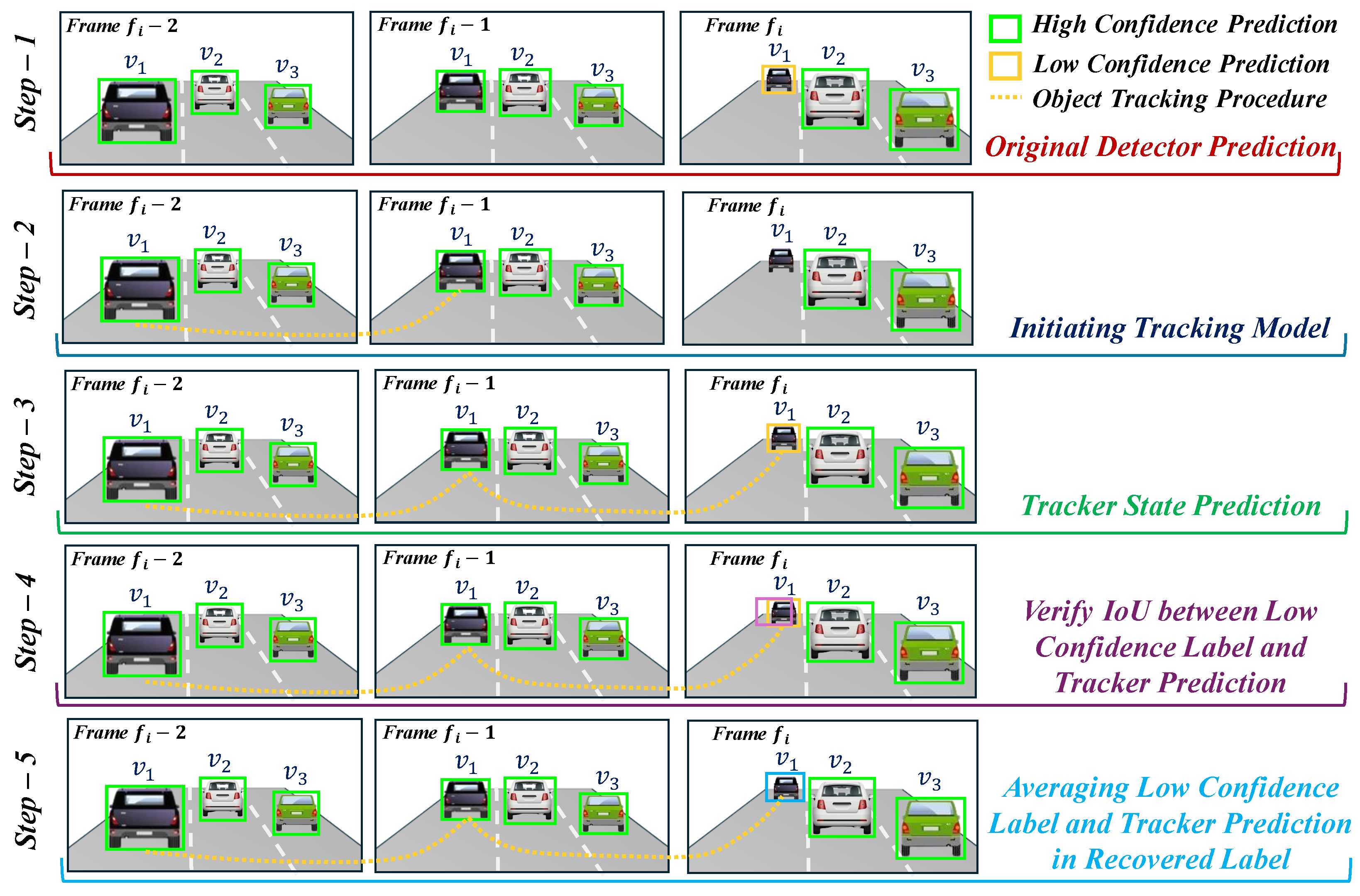
3.1. Bi-Directional Pseudo Label Recovery
3.2. Improved Pseudo Labels with Tracking
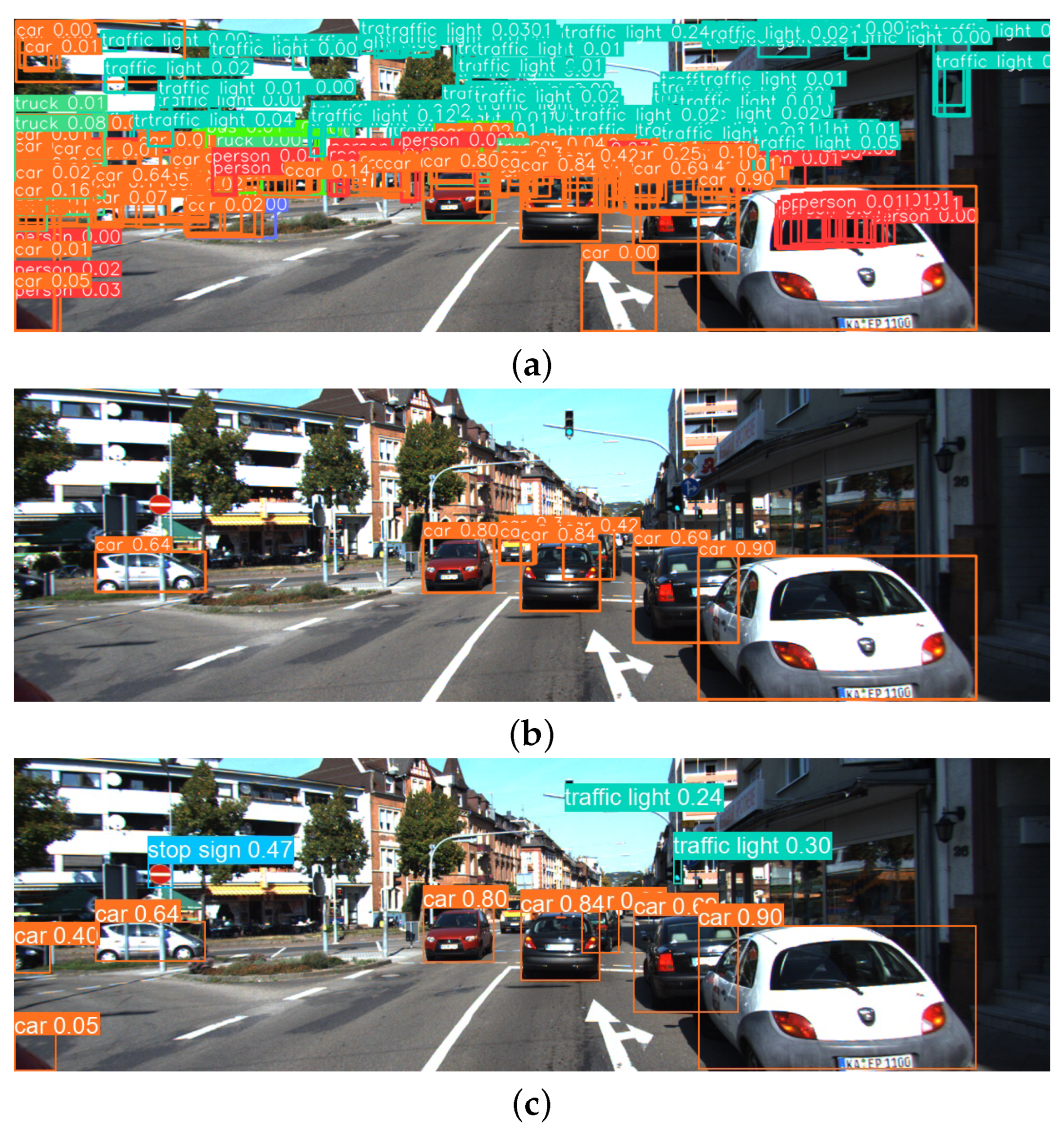
3.2.1. Essence of Tracking in Pseudo Label Generation
3.2.2. Track Association
3.2.3. Example for Label Recovery
| Algorithm 1 Bi-directional recovery of lost labels. |
| Require: Video Data IOU threshold Number of previous n and future m frames Ensure: The lists of pseudo labels recovered by forward and backward tracking , A list of the final recovered labels |
▹ sort labels according to confidence value
|
3.2.4. Bi-Directional Label Recovery Algorithm
4. Experiment Results
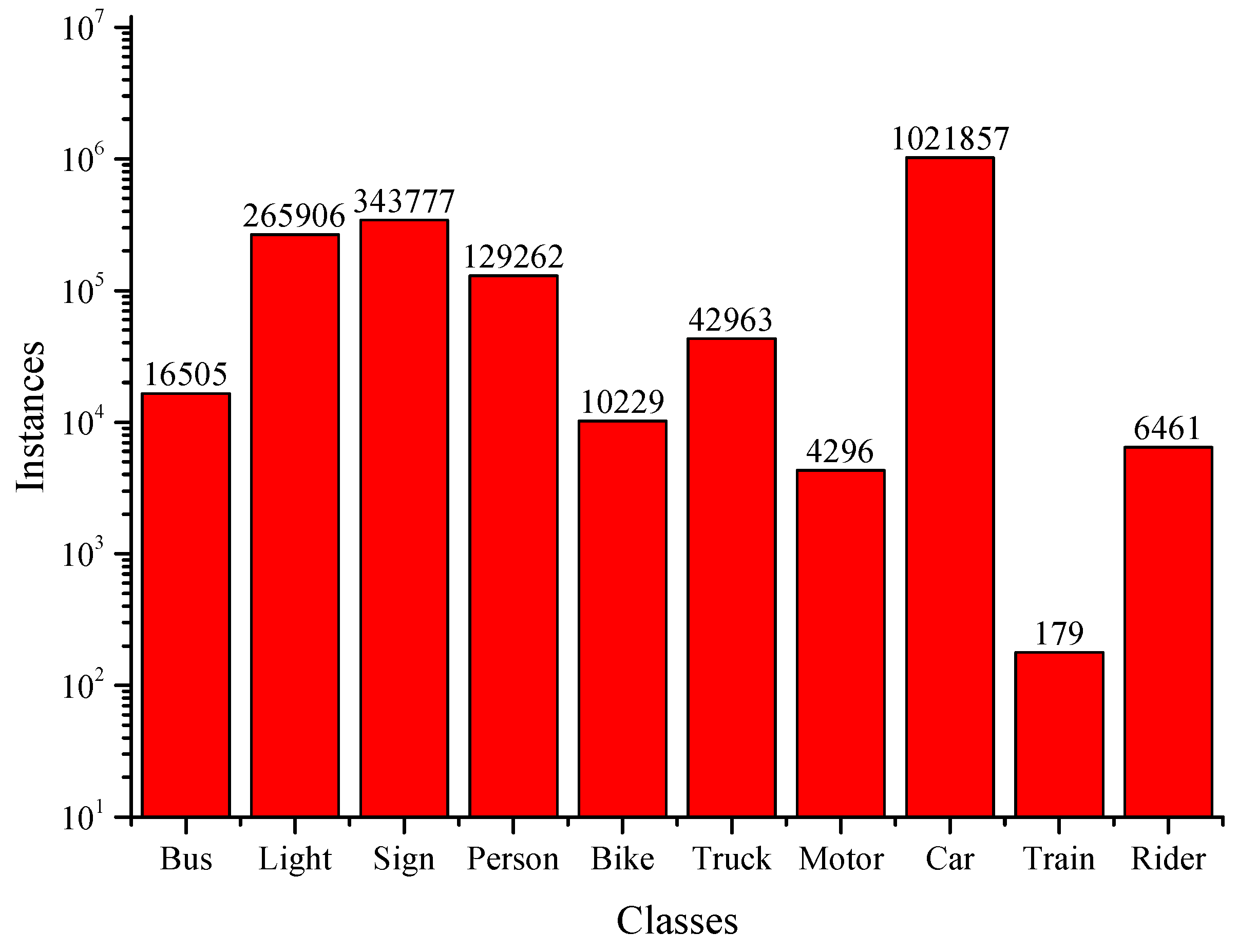
4.1. Datasets
4.2. Self-Training Scenarios
4.3. Object Tracker Selected for Experiment
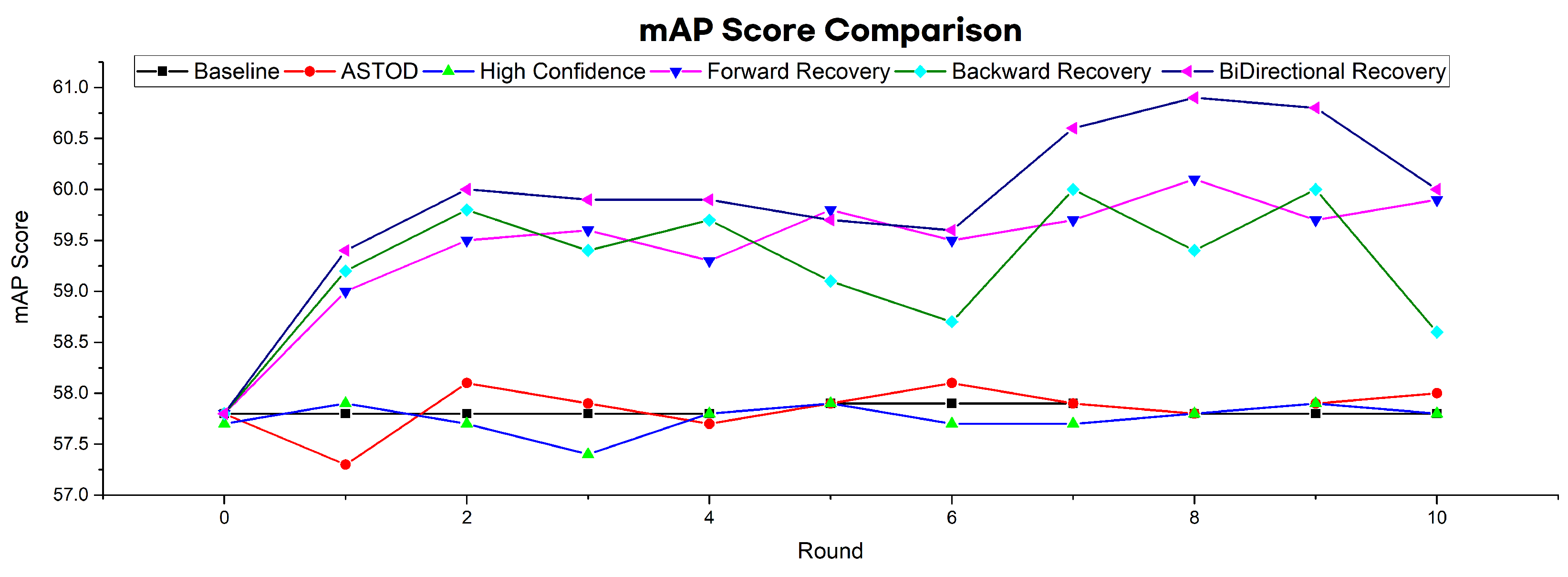
4.4. Self-Training Evaluation with Waymo Dataset
4.5. Self-Training Evaluation with BDD Dataset
4.6. Self-Training Evaluation with YouTube Videos
4.7. Inference Performance Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the KITTI Vision Benchmark Suite, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 3 June 2024).
- Shah, S.; Tembhurne, J. Object detection using convolutional neural networks and transformer-based models: A review. J. Electr. Syst. Inf. Technol. 2023, 10, 54. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; You, Y.; Li, L.E.; Hariharan, B.; Campbell, M.; Weinberger, K.Q.; Chao, W.L. Train in germany, test in the usa: Making 3d object detectors generalize. In Proceedings of the Making 3D Object Detectors Generalize, Seattle, WA, USA, 14–19 June 2020; pp. 11713–11723. [Google Scholar]
- Brophy, T.; Mullins, D.; Parsi, A.; Horgan, J.; Ward, E.; Denny, P.; Eising, C.; Deegan, B.; Glavin, M.; Jones, E. A Review of the Impact of Rain on Camera-Based Perception in Automated Driving Systems. IEEE Access 2023, 11, 67040–67057. [Google Scholar] [CrossRef]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Schwall, M.; Daniel, T.; Victor, T.; Favaro, F.; Hohnhold, H. Waymo public road safety performance data. arXiv 2020, arXiv:2011.00038. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the COLT: Annual Workshop on Computational Learning Theory, New York, NY, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. arXiv 2018, arXiv:1705.07115. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2018, arXiv:1703.01780. [Google Scholar]
- Englesson, E.; Azizpour, H. Consistency Regularization Can Improve Robustness to Label Noise. arXiv 2021, arXiv:2110.01242. [Google Scholar]
- Fan, Y.; Kukleva, A.; Schiele, B. Revisiting Consistency Regularization for Semi-Supervised Learning. arXiv 2021, arXiv:2112.05825. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4L: Self-Supervised Semi-Supervised Learning. arXiv 2019, arXiv:1905.03670. [Google Scholar]
- Vesdapunt, N.; Rundle, M.; Wu, H.; Wang, B. JNR: Joint-based Neural Rig Representation for Compact 3D Face Modeling. arXiv 2020, arXiv:2007.06755. [Google Scholar]
- Zhou, Z.H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Yu, J.; Yin, H.; Gao, M.; Xia, X.; Zhang, X.; Hung, N.Q.V. Socially-Aware Self-Supervised Tri-Training for Recommendation. arXiv 2021, arXiv:2106.03569. [Google Scholar]
- Kang, K.; Li, H.; Xiao, T.; Ouyang, W.; Yan, J.; Liu, X.; Wang, X. Object Detection in Videos with Tubelet Proposal Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 17–26 July 2017; pp. 889–897. [Google Scholar]
- Crawshaw, M. Multi-Task Learning with Deep Neural Networks: A Survey. arXiv 2020, arXiv:2009.09796. [Google Scholar]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Gal, Y.; Islam, R.; Ghahramani, Z. Deep Bayesian Active Learning with Image Data. arXiv 2017, arXiv:1703.02910. [Google Scholar]
- Emam, Z.A.S.; Chu, H.M.; Chiang, P.Y.; Czaja, W.; Leapman, R.; Goldblum, M.; Goldstein, T. Active Learning at the ImageNet Scale. arXiv 2021, arXiv:2111.12880. [Google Scholar]
- Wang, H.; Wang, Q.; Yang, F.; Zhang, W.; Zuo, W. Data Augmentation for Object Detection via Progressive and Selective Instance-Switching. arXiv 2019, arXiv:1906.00358. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. arXiv 2021, arXiv:2012.07177. [Google Scholar]
- Ayub, A.; Kim, H. GAN-Based Data Augmentation with Vehicle Color Changes to Train a Vehicle Detection CNN. Electronics 2024, 13, 1231. [Google Scholar] [CrossRef]
- Vandeghen, R.; Louppe, G.; Van Droogenbroeck, M. Adaptive Self-Training for Object Detection. arXiv 2023, arXiv:2212.05911. [Google Scholar]
- Liang, X.; Liu, S.; Wei, Y.; Liu, L.; Lin, L.; Yan, S. Towards Computational Baby Learning: A Weakly-Supervised Approach for Object Detection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 999–1007. [Google Scholar]
- Osep, A.; Voigtlaender, P.; Luiten, J.; Breuers, S.; Leibe, B. Large-Scale Object Mining for Object Discovery from Unlabeled Video. arXiv 2019, arXiv:1903.00362. [Google Scholar]
- Misra, I.; Shrivastava, A.; Hebert, M. Watch and Learn: Semi-Supervised Learning of Object Detectors from Videos. arXiv 2015, arXiv:1505.05769. [Google Scholar]
- Singh, K.K.; Xiao, F.; Lee, Y.J. Track and Transfer: Watching Videos to Simulate Strong Human Supervision for Weakly-Supervised Object Detection. arXiv 2016, arXiv:1604.05766. [Google Scholar]
- Tang, K.; Ramanathan, V.; Fei-fei, L.; Koller, D. Shifting Weights: Adapting Object Detectors from Image to Video. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Glasgow, UK, 2012; Volume 25. [Google Scholar]
- Liu, G.; Zhang, F.; Pan, T.; Wang, B. Low-Confidence Samples Mining for Semi-supervised Object Detection. arXiv 2023, arXiv:2306.16201. [Google Scholar]
- Qi, C.R.; Zhou, Y.; Najibi, M.; Sun, P.; Vo, K.; Deng, B.; Anguelov, D. Offboard 3D Object Detection from Point Cloud Sequences. arXiv 2021, arXiv:2103.05073. [Google Scholar]
- Yang, B.; Bai, M.; Liang, M.; Zeng, W.; Urtasun, R. Auto4D: Learning to Label 4D Objects from Sequential Point Clouds. arXiv 2021, arXiv:2101.06586. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. arXiv 2017, arXiv:1703.07402. [Google Scholar]
- Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; Van Gool, L. Robust tracking-by-detection using a detector confidence particle filter. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1515–1522. [Google Scholar]
- Hua, Y.; Alahari, K.; Schmid, C. Online Object Tracking with Proposal Selection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3092–3100. [Google Scholar]
- Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; Van Gool, L. Online Multiperson Tracking-by-Detection from a Single, Uncalibrated Camera. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1820–1833. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking Objects as Points. arXiv 2020, arXiv:2004.01177. [Google Scholar]
- Mclachlan, G. Mahalanobis Distance. Resonance 1999, 4, 20–26. [Google Scholar] [CrossRef]
- SeoulWalker. SeoulWalker YouTube Channel. 8 May 2024. Available online: https://www.youtube.com/watch?v=ujIy2cFcapY (accessed on 3 June 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pre-Training Data | Recovery Method | Self-Training Data | mAP@50 |
|---|---|---|---|---|
| 10% Waymo (13,800) | N/A | - | 44.6% | |
| Pretrained Model | 20% Waymo (27,600) | 52.5% | ||
| ASTOD [30] | 10% Waymo (13,800) | N/A | Waymo—100 k | 52.7 (+8.1)% |
| 20% Waymo (27,600) | 54.2 (+1.7)% | |||
| High Confidence | 10% Waymo (13,800) | N/A | Waymo—100 k | 52.3 (+7.7)% |
| Pseudo Labels | 20% Waymo (27,600) | 54.1 (+1.6)% | ||
| Forward Recovery | 10% Waymo (13,800) | Forward | Waymo—100 k | 53.3 (+8.7)% |
| (Proposed Method) | 20% Waymo (27,600) | 54.6 (+2.1)% | ||
| Backward Recovery | 10% Waymo (13,800) | Backward | Waymo—100 k | 53.8 (+9.2)% |
| (Proposed Method) | 20% Waymo (27,600) | 54.8 (+2.3)% | ||
| Bi-directional Recovery | 10% Waymo (13,800) | Bi-directional | Waymo—100 k | 54.5 (+9.9)% |
| (Proposed Method) | 20% Waymo (27,600) | 55.4 (+2.9)% |
| Method | Pre-Training Data | Recovery Method | Self-Training Data | mAP@50 |
|---|---|---|---|---|
| Pretrained Model | Waymo (138,000) | N/A | - | 57.8% |
| ASTOD [30] | Waymo (138,000) | N/A | BDD—100 k | 58.1 (+0.3)% |
| High Confidence Pseudo Labels | Waymo (138,000) | N/A | BDD—100 k | 57.9 (+0.1)% |
| Forward Recovery (Proposed Method) | Waymo (138,000) | Forward | BDD—100 k | 60.1 (+2.3)% |
| Backward Recovery (Proposed Method) | Waymo (138,000) | Backward | BDD—100 k | 60.0 (+2.2)% |
| Bi-directional Recovery (Proposed Method) | Waymo (138,000) | Bi-directional | BDD—100 k | 60.9 (+3.1)% |
| Method | Pre-Training Data | Recovery Method | Self-Training Data | mAP@50 |
|---|---|---|---|---|
| Pretrained Model | Waymo (138,000) | N/A | - | 57.8% |
| ASTOD [30] | Waymo (138,000) | N/A | YouTube Videos [45] | 57.7 (−0.1)% |
| High Confidence Pseudo Labels | Waymo (138,000) | N/A | YouTube Videos [45] | 57.3 (−0.5)% |
| Forward Recovery (Proposed Method) | Waymo (138,000) | Forward | YouTube Videos [45] | 59.8 (+2.0)% |
| Backward Recovery (Proposed Method) | Waymo (138,000) | Backward | YouTube Videos [45] | 59.5 (+1.7)% |
| Bi-directional Recovery (Proposed Method) | Waymo (138,000) | Bi-directional | YouTube Videos [45] | 60.2 (+2.4)% |
| Object Detector | Recovery Algorithm | Computation Time (3090 RTX) | Computation Time (Nvidia Jetson) | mAP@50 |
|---|---|---|---|---|
| Yolov5-m (baseline) | N/A | 30 ms/Image | 97 ms/Image | 47.32% |
| Yolov5-m | Forward | 33 ms/Image | 107 ms/Image | 47.64% (+0.32) |
| Yolov5-m | Backward | 33 ms/Image | 107 ms/Image | 47.80% (+0.48) |
| Yolov5-m | Bi-Directional | 40 ms/Image | 129 ms/Image | 47.84% (+0.52) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sajid, S.; Aziz, Z.; Urmonov, O.; Kim, H. Improving Object Detection Accuracy with Self-Training Based on Bi-Directional Pseudo Label Recovery. Electronics 2024, 13, 2230. https://doi.org/10.3390/electronics13122230
Sajid S, Aziz Z, Urmonov O, Kim H. Improving Object Detection Accuracy with Self-Training Based on Bi-Directional Pseudo Label Recovery. Electronics. 2024; 13(12):2230. https://doi.org/10.3390/electronics13122230
Chicago/Turabian StyleSajid, Shoaib, Zafar Aziz, Odilbek Urmonov, and HyungWon Kim. 2024. "Improving Object Detection Accuracy with Self-Training Based on Bi-Directional Pseudo Label Recovery" Electronics 13, no. 12: 2230. https://doi.org/10.3390/electronics13122230
APA StyleSajid, S., Aziz, Z., Urmonov, O., & Kim, H. (2024). Improving Object Detection Accuracy with Self-Training Based on Bi-Directional Pseudo Label Recovery. Electronics, 13(12), 2230. https://doi.org/10.3390/electronics13122230