
Sequential Learning of Flame Objects Sorted by Size for Early Fire Detection in Surveillance Videos



Abstract
1. Introduction
2. Related Work
3. Sequential Learning to Enhance Performance in Small Object Detection
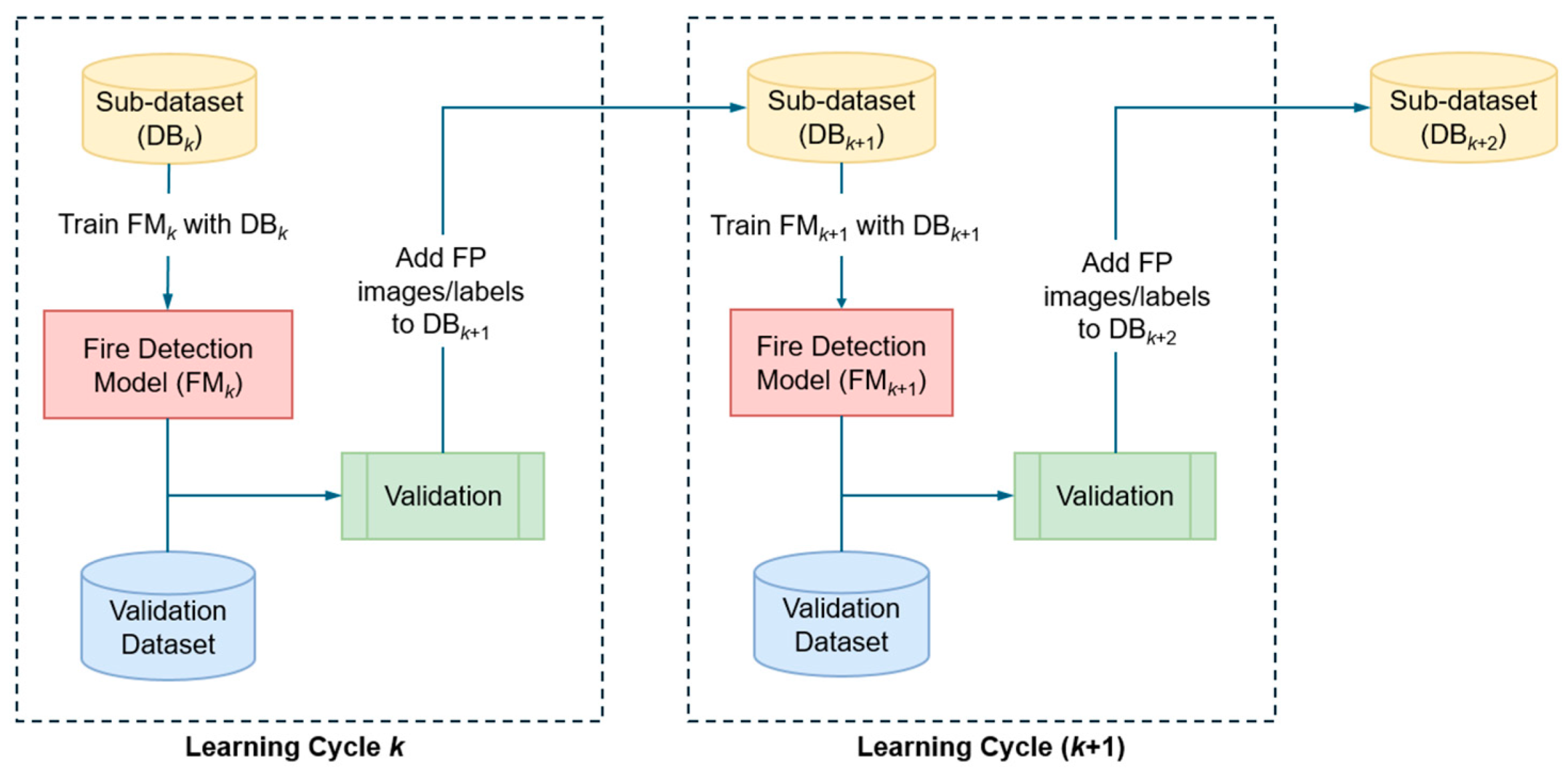
3.1. The Sequential Learning Process Pipeline
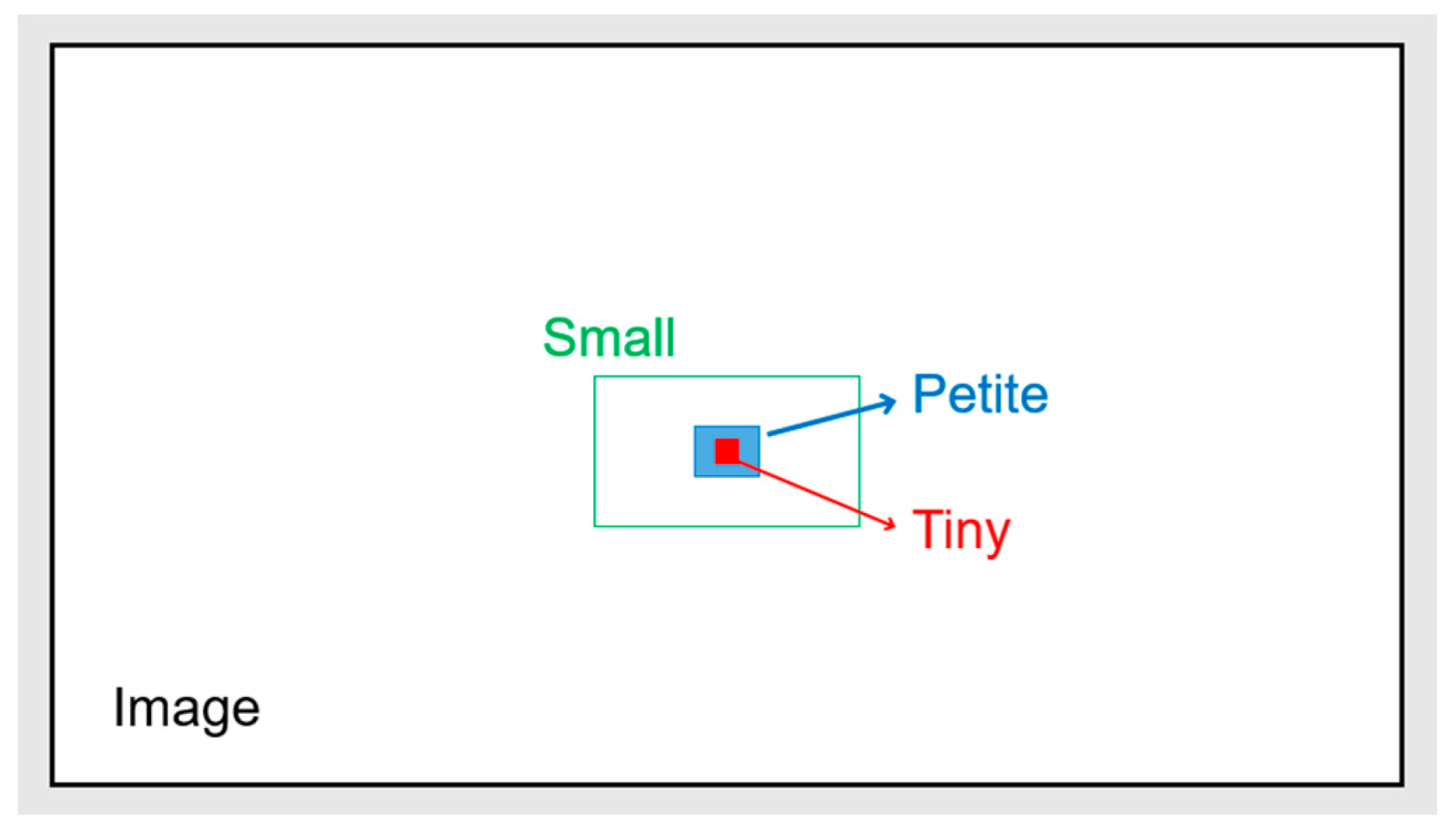
3.2. Definitions of Small Fire Flame Objects
3.3. Determining Number of Sequential Learning Cycles
3.4. Partitioning a Dataset into Multiple Sub-Datasets Sorted by Object Size
3.5. Lightweight Fire Detection Model
3.6. Model Evaluation
4. Experiment Results and Discussion
4.1. Dataset
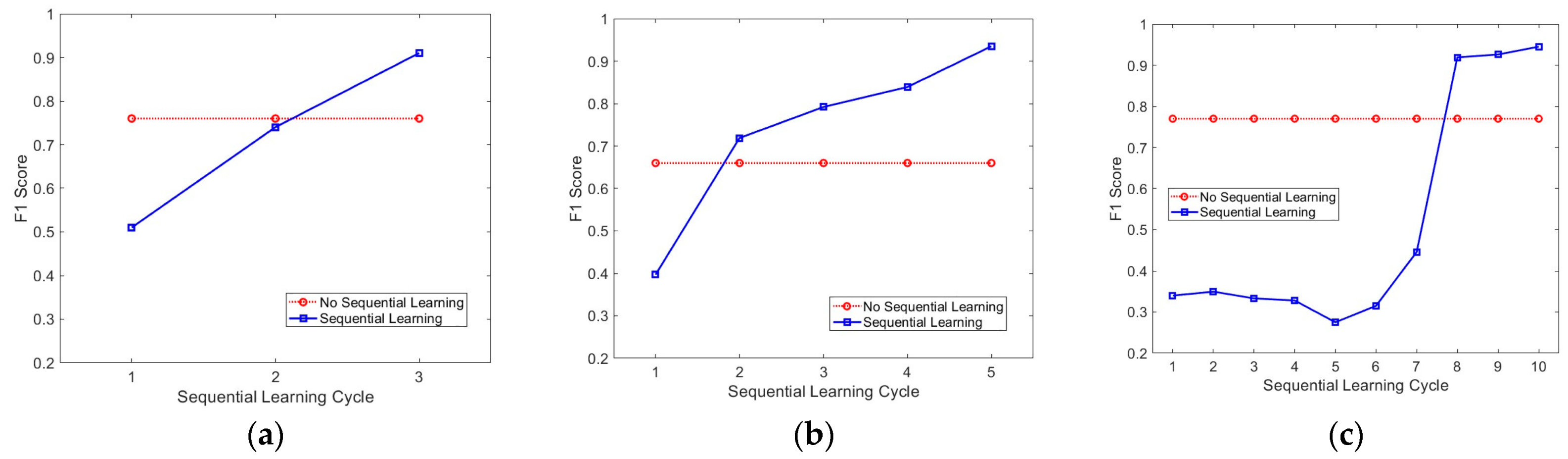
4.2. Number of Sequential Learning Cycles
4.3. Training
4.4. Small Fire Flame Object Detection Results
4.5. Fire Detection Performances for Fire Objects Regardless of Their Sizes
4.6. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Carta, F.; Zidda, C.; Putzu, M.; Loru, D.; Anedda, M.; Giusto, D. Advancements in forest fire prevention: A comprehensive survey. Sensors 2023, 23, 6635. [Google Scholar] [CrossRef] [PubMed]
- Kanakaraja, P.; Sundar, P.S.; Vaishnavi, N.; Reddy, S.G.K.; Manikanta, G.S. IoT enabled advanced forest fire detecting and monitoring on Ubidots platform. Mater. Today Proc. 2021, 46, 3907–3914. [Google Scholar] [CrossRef]
- Khan, T. A Smart Fire Detector IoT System with Extinguisher Class Recommendation Using Deep Learning. IoT 2023, 4, 558–581. [Google Scholar] [CrossRef]
- Jadon, A.; Omama, M.; Varshney, A.; Ansari, M.S.; Sharma, R. FireNet: A specialized lightweight fire & smoke detection model for real-time IoT applications. arXiv 2019, arXiv:1905.11922. [Google Scholar]
- Avazov, K.; Hyun, A.E.; Sami S, A.A.; Khaitov, A.; Abdusalomov, A.B.; Cho, Y.I. Forest Fire Detection and Notification Method Based on AI and IoT Approaches. Future Internet 2023, 15, 61. [Google Scholar] [CrossRef]
- Valikhujaev, Y.; Abdusalomov, A.; Cho, Y.I. Automatic fire and smoke detection method for surveillance systems based on dilated CNNs. Atmosphere 2020, 11, 1241. [Google Scholar] [CrossRef]
- Nallakaruppan, M.K.; Pillai, S.; Bharadwaj, G.; Balusamy, B. Early Detection of Forest Fire using Deep Image Neural Networks. In Proceedings of the 2023 IEEE IAS Global Conference on Emerging Technologies (GlobConET), London, UK, 19–21 May 2023; pp. 1–5. [Google Scholar]
- Dilli, B.; Suguna, M. Early Thermal Forest Fire Detection using UAV and Saliency map. In Proceedings of the 2022 5th International Conference on Contemporary Computing and Informatics (IC3I), Uttar Pradesh, India, 14–16 December 2022; pp. 1523–1528. [Google Scholar]
- Yang, C.; Pan, Y.; Cao, Y.; Lu, X. CNN-Transformer Hybrid Architecture for Early Fire Detection. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2022; pp. 570–581. [Google Scholar]
- Mohnish, S.; Kannan, B.D.; Vasuhi, S. Vision Transformer based Forest Fire Detection for Smart Alert Systems. In Proceedings of the 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 4–6 May 2023; pp. 891–896. [Google Scholar]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A small target object detection method for fire inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Xu, H.; Li, B.; Zhong, F. Light-YOLOv5: A lightweight algorithm for improved YOLOv5 in complex fire scenarios. Appl. Sci. 2022, 12, 12312. [Google Scholar] [CrossRef]
- Tsalera, E.; Papadakis, A.; Voyiatzis, I.; Samarakou, M. CNN-based, contextualized, real-time fire detection in computational resource-constrained environments. Energy Rep. 2023, 9, 247–257. [Google Scholar] [CrossRef]
- Wang, T.; Cao, R.; Wang, L. FE-YOLO: An Efficient and Lightweight Feature-Enhanced Fire Detection Method. In Proceedings of the 2022 3rd International Conference on Electronics, Communications and Information Technology (CECIT), Sanya, China, 23–25 December 2022. [Google Scholar]
- Almeida, J.S.; Huang, C.; Nogueira, F.G.; Bhatia, S.; de Albuquerque, V.H.C. EdgeFireSmoke: A Novel Lightweight CNN Model for Real-Time Video Fire–Smoke Detection. IEEE Trans. Ind. Inform. 2022, 18, 7889–7898. [Google Scholar] [CrossRef]
- Xu, Z.; Hong, X.; Chen, T.; Yang, Z.; Shi, Y. Scale-Aware Squeeze-and-Excitation for Lightweight Object Detection. IEEE Robot. Autom. Lett. 2022, 8, 49–56. [Google Scholar] [CrossRef]
- Xie, F.; Li, J.; Wang, Y.; Yang, J. Smoke/Fire Detection with an Improved YOLOX Model. In Proceedings of the 2023 42nd Chinese Control Conference (CCC), Tianjin, China, 24–26 July 2023. [Google Scholar]
- Li, L.; Yi, J. Real-time Fire Detection for Urban Tunnels Based on Multi-Source Data and Transfer Learning. In Proceedings of the 4th International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Nanjing, China, 18–20 August 2023. [Google Scholar]
- Nenakhov, I.; Mazhitov, R.; Artemov, K.; Zabihifar, S.H.; Semochkin, A.; Kolyubin, S. Continuous Learning with Random Memory for Object Detection in Robotic Applications. In Proceedings of the 2021 International Conference “Nonlinearity, Information and Robotics” (NIR), Innopolis, Russia, 26–29 August 2021; pp. 1–6. [Google Scholar]
- Luo, Y.; Yin, L.; Bai, W.; Mao, K. An Appraisal of Incremental Learning Methods. Entropy 2020, 22, 1190. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Chen, Y.; Wang, L.; Ye, Y.; Liu, Z.; Guo, Y.; Fu, Y. Large scale incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hasan, M.; Roy-Chowdhury, A.K. A Continuous Learning Framework for Activity Recognition Using Deep Hybrid Feature Models. IEEE Trans. Multimed. 2015, 17, 1909–1922. [Google Scholar] [CrossRef]
- Yang, B.; Deng, X.; Shi, H.; Li, C.; Zhang, G.; Xu, H.; Zhao, S.; Lin, L.; Liang, X. Continual object detection via prototypical task correlation guided gating mechanism. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Menezes, A.; de Moura, G.; Alves, C.; de Carvalho, A. Continual object detection: A review of definitions, strategies, and challenges. Neural Netw. 2023, 161, 476–493. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Hassan, B.; Khan, S.; Ahmed, R.; Abuassba, A. DeepFire: A novel dataset and deep transfer learning benchmark for forest fire detection. Mob. Inf. Syst. 2022, 2022, 5358359. [Google Scholar] [CrossRef]
- Reis, H.C.; Turk, V. Detection of forest fire using deep convolutional neural networks with transfer learning approach. Appl. Soft Comput. 2023, 143, 110362. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Chen, G.; Wang, H.; Chen, K.; Li, Z.; Song, Z.; Liu, Y.; Chen, W.; Knoll, A. A survey of the four pillars for small object detection: Multiscale representation, contextual information, super-resolution, and region proposal. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 936–953. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Wang, Y.; Yang, D.; Chen, H.; Wang, L.; Gao, Y. Pig Counting Algorithm Based on Improved YOLOv5n Model with Multiscene and Fewer Number of Parameters. Animals 2023, 13, 3411. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Wang, C.; Wang, L.; Wang, J.; Liao, J.; Li, Y.; Lan, Y. A Lightweight Cherry Tomato Maturity Real-Time Detection Algorithm Based on Improved YOLOV5n. Agronomy 2023, 13, 2106. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, C.; Xiao, Z. Object Detection in Security Inspection Scenarios Based on YOLOv5s: Exploring Experiments. J. Phys. Conf. Ser. 2023, 2560, 012018. [Google Scholar] [CrossRef]
- AI Hub. Fire Prediction Video. AI Hub. 2021. Available online: https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=176 (accessed on 20 July 2023).
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.; Blasch, E. The FLAME dataset: Aerial Imagery Pile burn detection using drones (UAVs). Comput. Netw. 2020, 193, 108001. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Balaji, K.; Gowri, S. A Real-Time Face Mask Detection Using SSD and MobileNetV2. In Proceedings of the 4th International Conference on Computing and Communications Technologies (ICCCT), Chennai, India, 16–17 December 2021. [Google Scholar]
- An, Y.; Tang, J.; Li, Y. A Mobilenet SSDLite model with improved FPN for forest fire detection. In Chinese Conference on Image and Graphics Technologies; Springer Nature: Singapore, 2022. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F1 Score (%) | |||||
|---|---|---|---|---|---|
| 0.016 (Small) | 83.4 | 90.8 | 85.5 | 86.1 | 85.1 |
| 0.006 (Petite) | 84.1 | 90.3 | 93.1 | 86.2 | 85.8 |
| 0.0016 (Tiny) | 76.6 | 52.2 | 75.1 | 79.6 | 94.5 |
| Dataset | Source | Number of Images | Number of Instances |
|---|---|---|---|
| Training (17,812) | Internet | 12,999 | 24,845 |
| AI Hub | 4305 | 4329 | |
| IEEE | 508 | 715 | |
| Validation (5441) | Internet | 3722 | 6999 |
| AI Hub | 1580 | 1571 | |
| IEEE | 139 | 170 | |
| Test (2618) | AI Hub | 2514 | 2613 |
| IEEE | 104 | 219 | |
| Total | 25,871 | 41,461 | |
| N | Partitioning a Dataset into Multiple Sub-Datasets Based on Object Size Ratio | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | >0.07 | 0.07~0.01 | <0.016 | - | - | - | - | - | - | - |
| 5 | >0.15 | 0.051~0.15 | 0.021~0.051 | 0.006~0.021 | <0.006 | - | - | - | - | - |
| 10 | >0.34 | 0.15~0.34 | 0.08~0.15 | 0.05~0.08 | 0.03~0.05 | 0.02~0.03 | 0.01~0.02 | 0.006~0.01 | 0.0016~0.006 | <0.0016 |
| N | Sequential Learning Cycle | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 3 | 1954 | 1327 | 1131 | - | - | - | - | - | - | - |
| 5 | 1716 | 1116 | 920 | 867 | 793 | - | - | - | - | - |
| 10 | 2055 | 2034 | 1883 | 1554 | 1460 | 1352 | 1152 | 1091 | 857 | 811 |
| Model | N | Sequential Learning | No Sequential Learning |
|---|---|---|---|
| YOLOv5n | 3 | 90.8 | 75.6 |
| 5 | 93.1 | 66.1 | |
| 10 | 94.5 | 77.0 | |
| SSD + MobileNet + FPNLite | 3 | 72.1 | 52.7 |
| 5 | 60.4 | 54.7 | |
| 10 | 76.6 | 54.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samosir, W.A.; Nguyen, D.B.; Kong, S.G. Sequential Learning of Flame Objects Sorted by Size for Early Fire Detection in Surveillance Videos. Electronics 2024, 13, 2232. https://doi.org/10.3390/electronics13122232
Samosir WA, Nguyen DB, Kong SG. Sequential Learning of Flame Objects Sorted by Size for Early Fire Detection in Surveillance Videos. Electronics. 2024; 13(12):2232. https://doi.org/10.3390/electronics13122232
Chicago/Turabian StyleSamosir, Widia A., Duy B. Nguyen, and Seong G. Kong. 2024. "Sequential Learning of Flame Objects Sorted by Size for Early Fire Detection in Surveillance Videos" Electronics 13, no. 12: 2232. https://doi.org/10.3390/electronics13122232
APA StyleSamosir, W. A., Nguyen, D. B., & Kong, S. G. (2024). Sequential Learning of Flame Objects Sorted by Size for Early Fire Detection in Surveillance Videos. Electronics, 13(12), 2232. https://doi.org/10.3390/electronics13122232