
Improving Single-Image Super-Resolution with Dilated Attention







Abstract
:1. Introduction
- We apply a dilated attention mechanism to SISR tasks to effectively capture image features at different scales and significantly improve detail and structure recovery of images. To the best of our knowledge, single-image super-resolution using a dilated attention-based transformer has not been investigated.
- We fuse low-level features and multi-scale global features to reconstruct images, which ensures high resolution and good quality in terms of the reconstructed images.
- We make a comparison with existing SISR methods to demonstrate the effectiveness and superiority of our proposed DAIR in enhancing image resolution and quality.
- We evaluate the applicability of the proposed method in real-world scenarios, using images with diverse conditions to ensure the method’s robustness and generalization capabilities.
2. Related Works
2.1. Convolutional Neural Network-Based Methods
2.2. Transformer-Based Methods
2.3. Dilated Attention
3. Proposed Method
3.1. Feature Extraction
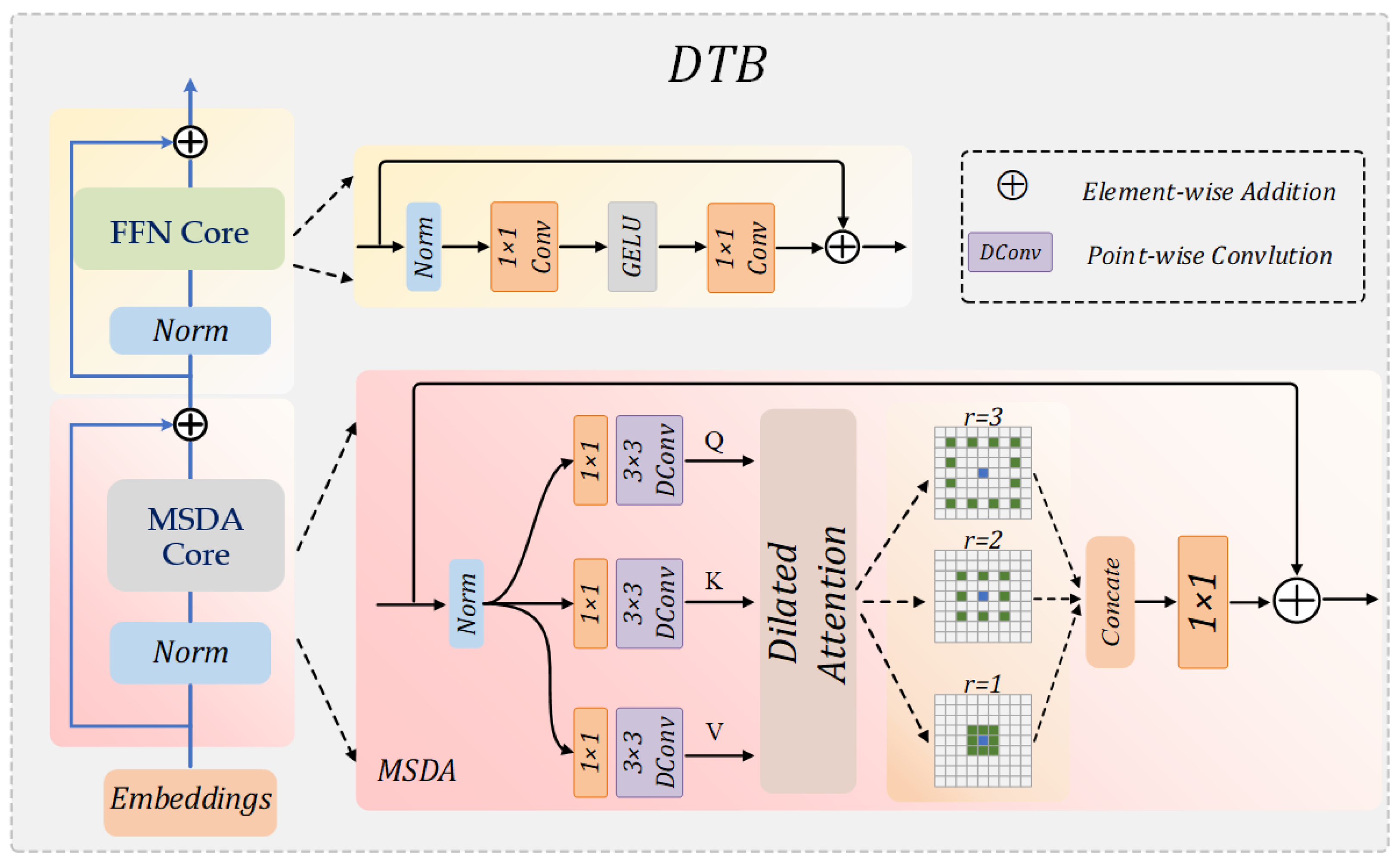
3.2. Dilated Transformer Block
3.2.1. Multi-Scale Dilation Attention (MSDA)
3.2.2. Feed-Forward Network (FFN)
3.3. Image Reconstruction
3.4. Loss Function
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Comparisons with Existing SISR Methods
4.5. Ablation Experiments
4.5.1. Impacts of MSDA and FFN
4.5.2. Influences of LFE and MDTB
4.6. Discussion
4.7. Real-World Scenario Evaluation
5. Conclusions and Outlooks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, H.; He, X.; Qing, L.; Wu, Y.; Ren, C.; Sheriff, R.E.; Zhu, C. Real-world single image super-resolution: A brief review. Inf. Fusion. 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Li, J.; Pei, Z.; Zeng, T. From beginner to master: A survey for deep learning-based single-image super-resolution. arXiv 2021, arXiv:2109.14335. [Google Scholar]
- Yu, M.; Shi, J.; Xue, C.; Hao, X.; Yan, G. A review of single image super-resolution reconstruction based on deep learning. Multimed. Tools Appl. 2023, 83, 55921–55962. [Google Scholar] [CrossRef]
- Chauhan, K.; Patel, S.N.; Kumhar, K.; Bhatia, J.; Tanwar, S.; Davidson, I.E.; Mazibuko, T.F.; Sharma, R. Deep learning-based single-image super-resolution: A comprehensive review. IEEE Access 2023, 11, 21811–21830. [Google Scholar] [CrossRef]
- Al-Mekhlafi, H.; Liu, S. Single image super-resolution: A comprehensive review and recent insight. Front. Comput. Sci. 2024, 18, 181702. [Google Scholar] [CrossRef]
- Li, J.; Pei, Z.; Li, W.; Gao, G.; Wang, L.; Wang, Y.; Zeng, T. A systematic survey of deep learning-based single-image super-resolution. ACM Comput. Surv. 2024, accepted. [Google Scholar] [CrossRef]
- Wang, Y.; Wan, W.; Wang, R.; Zhou, X. An improved interpolation algorithm using nearest neighbor from VTK. In Proceedings of the 2010 International Conference on Audio, Language and Image Processing, Shanghai, China, 23–25 November 2010; pp. 1062–1065. [Google Scholar]
- Parsania, P.; Virparia, D. A review: Image interpolation techniques for image scaling. Int. J. Innov. Res. Comput. Commun. Eng. 2014, 2, 7409–7414. [Google Scholar] [CrossRef]
- Gavade, A.B.; Sane, P. Super resolution image reconstruction by using bicubic interpolation. In Proceedings of the National Conference on Advanced Technologies in Electrical and Electronic Systems, Pune, India, 19–20 February 2014; pp. 201–209. [Google Scholar]
- Irani, M.; Peleg, S. Improving resolution by image registration. Graph. Models Image Process. 1991, 53, 231–239. [Google Scholar] [CrossRef]
- Stark, H.; Oskoui, P. High-resolution image recovery from image-plane arrays, using convex projections. J. Opt. Soc. Am. A 1989, 6, 1715–1726. [Google Scholar] [CrossRef]
- Schultz, R.R.; Stevenson, R.L. Extraction of high-resolution frames from video sequences. IEEE Trans. Image Process. 1996, 5, 996–1011. [Google Scholar] [CrossRef] [PubMed]
- Lepcha, D.C.; Goyal, B.; Dogra, A.; Goyal, V. Image super-resolution: A comprehensive review, latest trends, challenges and applications. Inf. Fusion. 2023, 91, 230–260. [Google Scholar] [CrossRef]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 723–731. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4915–4924. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. arXiv 2015, arXiv:1501.00092v3. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Caballero, J.; Ferenc Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems 27, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the 2021 International Conference on Learning Representations, Virtual Event, 3–7 May 2021; pp. 1–21. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5718–5729. [Google Scholar]
- Ding, J.; Ma, S.; Dong, L.; Zhang, X.; Huang, S.; Wang, W.; Zheng, N.; Wei, F. LONGNET: Scaling transformers to 1,000,000,000 tokens. arXiv 2023, arXiv:2307.02486v2. [Google Scholar]
- Peng, Y.; Zhang, L.; Liu, S.; Wu, X.; Zhang, Y.; Wang, X. Dilated residual networks with symmetric skip connection for image denoising. Neurocomputing 2019, 345, 67–76. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep networks for image super-resolution with sparse prior. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 370–378. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, C.; Li, Z.; Shi, J. Lightweight image super-resolution with adaptive weighted learning network. arXiv 2019, arXiv:1904.02358. [Google Scholar]
- Ahn, N.; Kang, B.; Kyung, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A persistent memory network for image restoration. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Zhang, X.; Gao, P.; Liu, S.; Zhao, K.; Li, G.; Yin, L.; Chen, C.W. Accurate and efficient image super-resolution via global-local adjusting dense network. IEEE Trans. Multimedia 2021, 23, 1924–1937. [Google Scholar] [CrossRef]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep Laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3867–3876. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. Lect. Notes Comput. Sci. 2018, 11212, 527–542. [Google Scholar]
- Li, J.; Fang, F.; Li, J.; Mei, K.; Zhang, G. MDCN: Multi-scale dense cross network for image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2547–2561. [Google Scholar] [CrossRef]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Pang, C.; Luo, X. MADnet: A fast and lightweight network for single-image super resolution. IEEE Trans. Cybern. 2021, 51, 1443–1453. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 294–310. [Google Scholar]
- Kim, J.H.; Choi, J.H.; Cheon, M.; Lee, J.S. Ram: Residual attention module for single image super-resolution. arXiv 2018, arXiv:1811.12043v1. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. arXiv 2019, arXiv:1903.10082v1. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2356–2365. [Google Scholar]
- Zhang, D.; Li, C.; Xie, N.; Wang, G.; Shao, J. PFFN: Progressive feature fusion network for lightweight image super-resolution. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 3682–3690. [Google Scholar]
- Anwar, S.; Barnes, N. Densely residual Laplacian super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1192–1204. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5790–5799. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Jiang, N.; Lu, J.; Jia, J. LAPAR: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond. In Proceedings of the 34th Conference on Neural Information Processing Systems, Virtual Event, 6–12 December 2020; pp. 1–13. [Google Scholar]
- Gao, G.; Wang, Z.; Li, J.; Li, W.; Yu, Y.; Zeng, T. Lightweight bimodal network for single-image super-resolution via symmetric CNN and recursive transformer. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 913–919. [Google Scholar]
- Mehri, A.; Behjati, P.; Carpio, D.; Sappa, A.D. SRFormer: Efficient yet powerful transformer network for single image super resolution. IEEE Access 2023, 11, 121457–121469. [Google Scholar] [CrossRef]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Huang, Z.; Wang, L.; Meng, G.; Pan, C. Image super-resolution via deep dilated convolutional networks. In Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 953–957. [Google Scholar]
- Shamsolmoali, P.; Li, X.; Wang, R. Single image resolution enhancement by efficient dilated densely connected residual network. Signal Process. Image Commun. 2019, 79, 13–23. [Google Scholar] [CrossRef]
- Yang, J.; Jiang, J. Dilated-CBAM: An efficient attention network with dilated convolution. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems, Nanjing, China, 30 October–1 November 2021; pp. 11–15. [Google Scholar]
- Dai, R.; Das, S.; Minciullo, L.; Garattoni, L.; Francesca, G.; Bremond, F. PDAN: Pyramid dilated attention network for action detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 2969–2978. [Google Scholar]
- Hassani, A.; Shi, H. Dilated neighborhood attention transformer. arXiv 2022, arXiv:2209.15001v3. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE2017 Challenge on single image super-resolution: Dataset and study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1122–1131. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga 109 dataset. arXiv 2017, arXiv:1510.04389v1. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. Lect. Notes Comput. Sci. 2010, 6920, 1–20. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Marco, B.; Roumy, A.; Guillemot, C.M.; Alberi-Morel, M.-L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 1–10. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the 2017 International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | Params | Set5 | BSD100 | Set14 | Manga109 | Urban100 |
|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |||
| IDN [17] | ×3 | 553 K | 34.11/0.9253 | 28.95/0.8013 | 29.99/0.8354 | 32.71/0.9381 | 27.42/0.8359 |
| IMDN [18] | ×3 | 703 K | 34.36/0.9270 | 29.09/0.8046 | 30.32/0.8417 | 33.61/0.9445 | 28.17/0.8519 |
| VDSR [19] | ×3 | 665 K | 33.66/0.9213 | 28.82/0.7976 | 29.77/0.8314 | 32.01/0.9310 | 27.14/0.8279 |
| SMSR [20] | ×3 | 993 K | 34.40/0.9270 | 29.10/0.8050 | 30.33/0.8412 | 33.68/0.9445 | 28.25/0.8536 |
| AWSRN m [31] | ×3 | 1143 K | 34.42/0.9275 | 29.13/0.8059 | 30.32/0.8419 | 33.64/0.9450 | 28.26/0.8545 |
| CARN [32] | ×3 | 1592 K | 34.29/0.9255 | 29.06/0.8034 | 30.29/0.8407 | 33.43/0.9427 | 28.06/0.8493 |
| DRCN [33] | ×3 | 1774 K | 33.82/0.9226 | 28.80/0.7963 | 29.76/0.8311 | 32.31/0.9328 | 27.15/0.8276 |
| DRRN [34] | ×3 | 297 K | 34.03/0.9244 | 28.95/0.8004 | 29.96/0.8349 | 32.74/0.9390 | 27.53/0.8378 |
| MemNet [35] | ×3 | 678 K | 34.09/0.9248 | 28.96/0.8001 | 30.00/0.8350 | 32.51/0.9369 | 27.56/0.8376 |
| GLADSR [38] | ×3 | 821 K | 34.41/0.9272 | 29.08/0.8050 | 30.37/0.8418 | - | 28.24/0.8537 |
| MADNet [43] | ×3 | 930 K | 34.16/0.9253 | 28.98/0.8023 | 30.21/0.8398 | - | 27.77/0.8439 |
| LAPAR-A [52] | ×3 | 594 K | 34.36/0.9267 | 29.11/0.8054 | 30.34/0.8421 | 33.51/0.9441 | 28.15/0.8523 |
| DAIR | ×3 | 875 K | 34.71/0.9297 | 29.18/0.8084 | 30.68/0.8490 | 33.95/0.9465 | 28.36/0.8544 |
| IDN [17] | ×4 | 553 K | 31.82/0.8903 | 27.41/0.7297 | 28.25/0.7730 | 29.41/0.8942 | 25.41/0.7632 |
| IMDN [18] | ×4 | 703 K | 32.21/0.8948 | 27.56/0.7353 | 28.58/0.7811 | 30.45/0.9075 | 26.04/0.7838 |
| VDSR [19] | ×4 | 665 K | 23.13/0.8838 | 27.29/0.7251 | 28.01/0.7674 | 28.83/0.8809 | 25.18/0.7524 |
| SMSR [20] | ×4 | 993 K | 32.15/0.8944 | 27.61/0.7366 | 28.61/0.7818 | 30.42/0.9074 | 26.14/0.7871 |
| AWSRN m [31] | ×4 | 1143 K | 32.21/0.8954 | 27.60/0.7368 | 28.65/0.7832 | 30.56/0.9093 | 26.15/0.7884 |
| CARN [32] | ×4 | 1592 K | 32.13/0.8937 | 27.58/0.7349 | 28.60/0.7806 | 30.42/0.9070 | 26.07/0.7837 |
| DRCN [33] | ×4 | 1774 K | 31.53/0.8854 | 27.23/0.7233 | 28.02/0.7670 | 28.98/0.8816 | 25.14/0.7510 |
| DRRN [34] | ×4 | 297 K | 31.68/0.8888 | 27.38/0.7284 | 28.21/0.7720 | 29.46/0.8960 | 25.44/0.7638 |
| MemNet [35] | ×4 | 678 K | 31.74/0.8893 | 27.4/0.7281 | 28.26/0.7723 | 29.42/0.8942 | 25.50/0.7630 |
| GLADSR [38] | ×4 | 821 K | 32.14/0.8940 | 27.59/0.7361 | 28.62/0.7813 | - | 26.12/0.7851 |
| MADNet [43] | ×4 | 930 K | 31.95/0.8917 | 27.47/0.7327 | 28.44/0.7780 | - | 25.76/0.7746 |
| LAPAR-A [52] | ×4 | 594 K | 32.12/0.8932 | 27.55/0.7351 | 28.55/0.7808 | 30.54/0.9085 | 26.11/0.7868 |
| DAIR | ×4 | 875 K | 32.62/0.9007 | 27.64/0.7358 | 28.96/0.7904 | 30.77/0.9117 | 26.25/0.7875 |
| Methods | Scale | Set5 | Set14 | ||
|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | ||
| Original model | ×4 | 32.62 | 0.9007 | 28.96 | 0.7904 |
| w/o FFN | ×4 | 32.59 | 0.9004 | 28.94 | 0.7900 |
| w/o MSDA | ×4 | 32.51 | 0.8998 | 28.90 | 0.7899 |
| Methods | Set5 | Set14 | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| Original model | 32.62 | 0.9007 | 28.96 | 0.7904 |
| w/o LFE | 32.58 | 0.9002 | 28.95 | 0.7901 |
| w/o MDTB | 32.41 | 0.8990 | 28.83 | 0.7891 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Cheng, B.; Yang, X.; Xiao, Z.; Zhang, J.; You, L. Improving Single-Image Super-Resolution with Dilated Attention. Electronics 2024, 13, 2281. https://doi.org/10.3390/electronics13122281
Zhang X, Cheng B, Yang X, Xiao Z, Zhang J, You L. Improving Single-Image Super-Resolution with Dilated Attention. Electronics. 2024; 13(12):2281. https://doi.org/10.3390/electronics13122281
Chicago/Turabian StyleZhang, Xinyu, Boyuan Cheng, Xiaosong Yang, Zhidong Xiao, Jianjun Zhang, and Lihua You. 2024. "Improving Single-Image Super-Resolution with Dilated Attention" Electronics 13, no. 12: 2281. https://doi.org/10.3390/electronics13122281
APA StyleZhang, X., Cheng, B., Yang, X., Xiao, Z., Zhang, J., & You, L. (2024). Improving Single-Image Super-Resolution with Dilated Attention. Electronics, 13(12), 2281. https://doi.org/10.3390/electronics13122281