
Comparison Analysis of Multimodal Fusion for Dangerous Action Recognition in Railway Construction Sites


Abstract
1. Introduction
- Proposing the fusion of unimodal action recognition models as encoders for their ability to capture useful features.
- Providing an analysis of multimodal fusion approaches, highlighting their effectiveness in recognizing dangerous actions in railway construction.
- Analyzing the contribution of depthmaps modality in terms of performance.
2. Literature Review
2.1. Multimodal Learning Definitions and Concepts
2.1.1. Multimodal Principles Definition
Heterogeneity
Interconnections
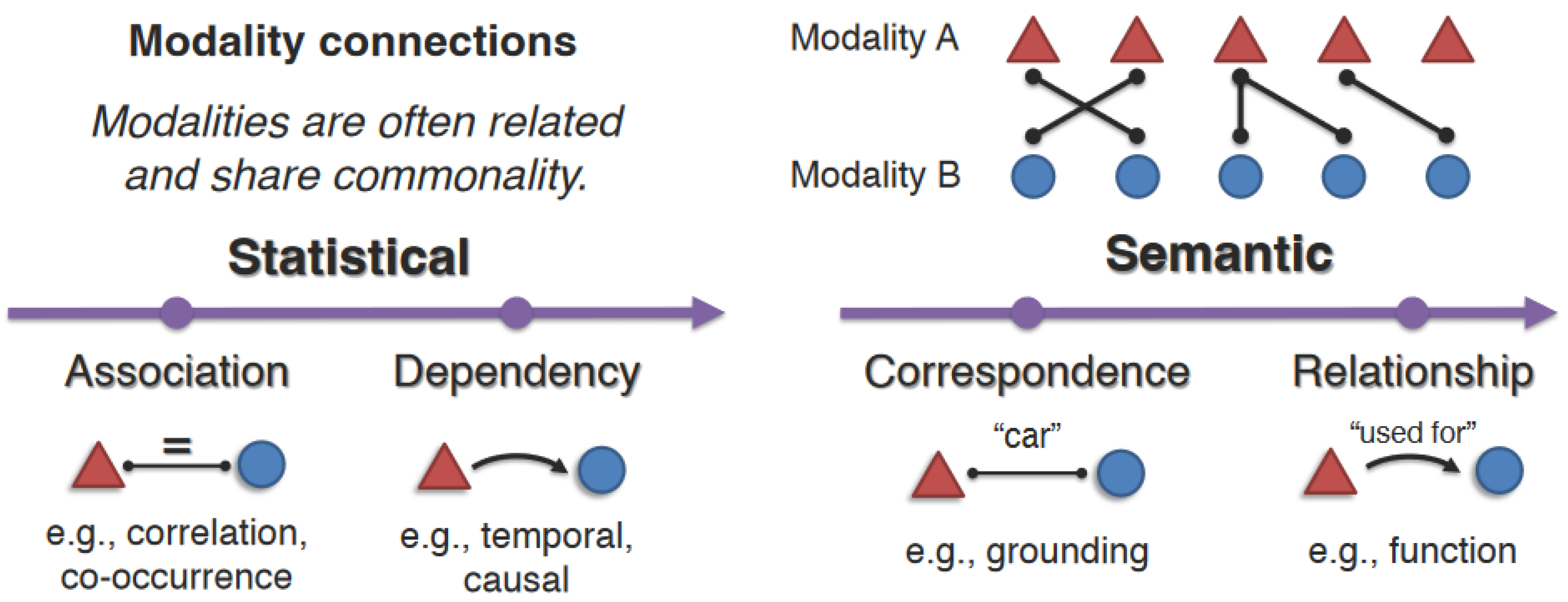
- Modality connections: Describe how modalities are often related and share commonalities, such as correspondences between the same concept in language and images or dependencies across spatial and temporal dimensions. Several dimensions of modality connections were outlined based on both statistical (association and dependency) and semantic (correspondence and relationship) perspectives (Figure 1).
- Modality interactions: Modality interactions study how modality elements interact to give rise to new information when integrated for task inference. It is important to highlight a key difference between interaction and connections: the interaction takes place when at least two modalities are involved during the learning process of a multimodal model, which helps devise a new response during inference compared to an unimodal model.
2.2. Multimodal Learning Taxonomy Overview
2.2.1. Representation Learning
2.2.2. Alignment
2.2.3. Generation
2.2.4. Co-Learning
2.2.5. Quantification
- Identifying the dimensions of heterogeneity in multimodal data and their impact on modeling and learning, such as the presence of modality bias and noise.
- Quantifying the types of connections and interactions among different modalities in datasets and trained models.
- Characterizing the learning and optimization challenges involved in heterogeneous data.
2.2.6. Fusion
- Early fusion: This is the study of learning a joint representation at an early stage (raw modalities), which was one of the first attempts to achieve representation learning [2]. This type of fusion may vary depending on the modality’s level of abstraction. In the literature, the most common methods used for multimodal fusion are concatenation, element-wise multiplication, and weighted sum [7,12].
- Intermediate fusion: Also known as feature-level fusion [13]. Contrary to the early fusion, this approach takes features at a higher level after feeding the raw modalities through shallow layers. This method is advantageous for capturing cross-modal interactions and relationships because it allows for the integration of more abstract representations of the data from each modality. It may also be more susceptible to incorporating noisy information [13] or allowing the dominance of one modality to influence the overall model’s performance negatively.
- Late fusion: Also known as decision-level fusion, late fusion is a technique where data sources are processed independently and then combined at a later stage for decision-making purposes. This approach is based on ensemble classifiers and is simpler than the early fusion method, especially when dealing with data sources with varying characteristics such as sampling rate, data dimensionality, and measurement unit. One of the most common approaches is decision aggregation by averaging [14], voting [15], or weighted-sum [16]
- Hybrid fusion: Hybrid fusion is the methodology of merging the attributes of both early and late fusion techniques within a unified architecture. Most prior research focuses on the combined representation created by Early Fusion at the feature level. This integrated representation is then combined with decision-level approaches, such as weighted voting [17], to establish a more effective fusion process.
2.3. Multimodal Fusion Techniques
2.3.1. Tensor-Based Fusion:
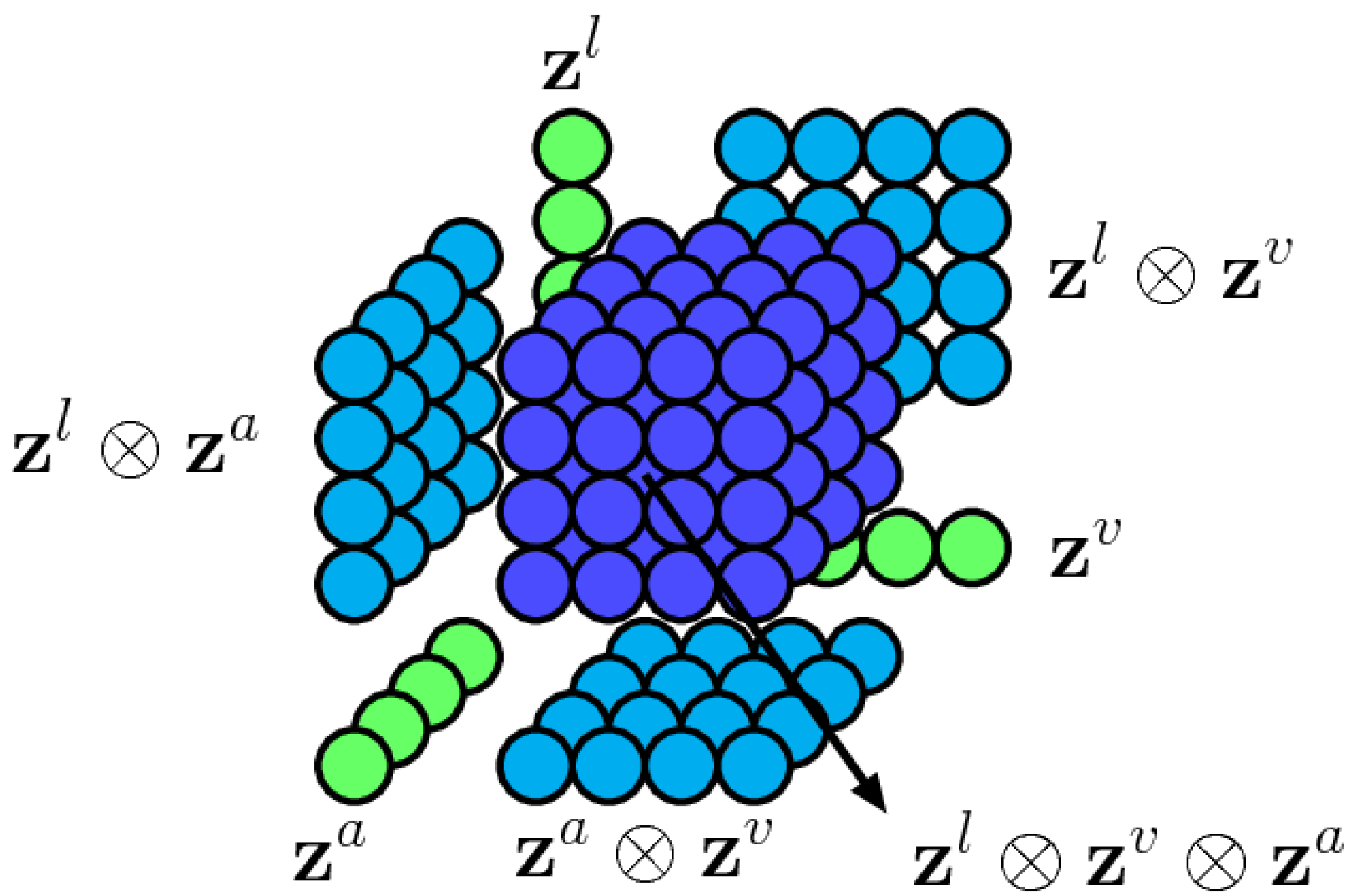
- Tensor fusion: The main idea behind this technique is to capture complex interactions and complementary information between modalities’ embeddings. To do so, in [19], they suggested performing a 3-fold Cartesian multiplication between all modalities (see Figure 4). The particularity of this technique is that it preserves the unimodal characteristics as well as the trimodal and bimodal ones. Despite the advantages of being non-parametric, it comes with a high computation cost, which increases the model complexity and might not be adapted for real-world applications.
- Low-rank tensor fusion: To mitigate the computation cost without compromising the performance, [20] divides the tensor fusion multiplication into low-factor weights that reduce the number of parameters (see Figure 5). Their work shows prominent results in terms of linear scalability with the number of modalities being used.
2.3.2. Transformers-Based
- VisualBert: [23] a single-stream approach that uses self-attention integrated into a transformer layer for an implicit alignment between image and text inputs (see Figure 6). The image features were generated from a ResNeXt-based Faster RCNN pre-trained on Visual Genome [24] and text tokens using a BERT tokenizer [25]. The main contribution of this architecture is the ability to capture cross-modal interactions by aligning visual and textual information; in addition, it can generate a joint representation by leveraging the transformer architecture to learn contextualized embeddings for words and image regions.
- LXMERT: [26] LXMERT (learning cross-modality encoder representations from transformers) is a two-stream approach introduced for understanding and reasoning across both visual and textual modalities. The architecture leverages the powerful Transformer architecture and employs a cross-modality attention mechanism to learn the joint representations of image and text data. The latter are implemented through a series of co-attention layers that consist of three attention sub-modules: self-attention for the visual modality, self-attention for the textual modality, and cross-attention between the two modalities. The self-attention sub-modules focus on learning relationships within each modality, while the cross-attention sub-module learns to align and relate the information across the visual and textual domains. LXMERT is pre-trained on large-scale datasets to extract general features from images and text and is then fine-tuned for specific tasks such as a visual question answering image-caption matching, and visual reasoning.
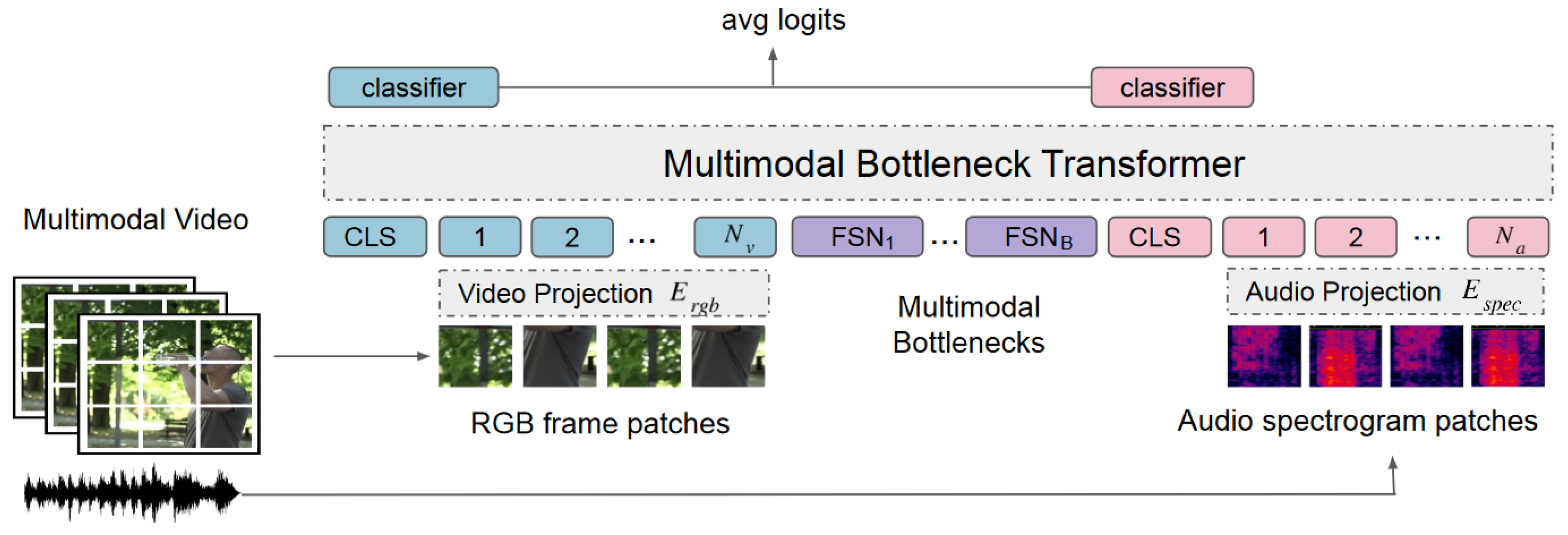
- Multimodal attention bottleneck: [27] A single-stream approach that comes with a novel way of fusing modalities using attention bottleneck fusion. The intuition behind this technique is to condense and capture the most important complementary information between modalities and omit what is unnecessary. It has been proven that it is computationally efficient and performs better than classical self-attention fusions. As illustrated in Figure 7, They achieved this by adding a set of B extra fusion bottleneck tokens to the input sequence and then used to condense all the cross-modal interaction of modalities through bottleneck tokens.
2.3.3. Adaptive Fusion
- Auto-fusion: In this work [28], an adaptive fusion is proposed that allows for effective multimodal fusion. Instead of using static techniques such as concatenation, it lets the network decide how to combine a given set of multimodal features more effectively. The main idea behind the auto-fusion is to maximize the correlation between multimodal inputs and use a reconstruction strategy to obtain a novel fusion layer that is minimized using an Euclidean distance between the original and reconstructed concatenated vector.
- MFAS: “Multimodal Fusion Architecture Search” [29] is a research study focused on developing a method for automatically discovering optimal fusion architectures for multimodal data. The central idea is to utilize neural architecture search (NAS) [30,31] techniques to search for the best fusion strategy that combines information from multiple modalities. This approach aims to address the challenge of designing effective fusion strategies for multimodal tasks by employing NAS techniques to automatically learn the most suitable architecture for a given task. They suggested picking a modalities representation at the different stages/layers of each encoder and nonlinear transformation to come up with the optimized combination that takes into account the appropriate abstraction level of the modality representation and the fusion technique used.
2.4. RGB-D Fusion Methods
2.4.1. Fusion Strategies for Action Recognition
2.4.2. Deep Learning-Based Solutions
2.4.3. Machine Learning-Based Solutions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fusion Methods | Fusion Inputs | Encoders | Datasets |
|---|---|---|---|
| SKPDE-ELM (hybrid) [44] | Depth motion map (DMM), local binary pattern (LBP) | ELM optimized by SKPDE | MSRAction3D [48], MSRDaily Activity3D [49], MSRGesture3D [50], UTD-MHAD [51] |
| Deep autoencoder based (intermediate) [36] | RGB and depth features | Not specified | Online RGBD action [52], MSRDaily Activity3D [49], NTU RGB+D [53], 3D action pairs [54], RGBD-HuDaAct [55] |
| Multi-modal contextualization unit (intermediate) [43] | RGB and depth embeddings | ResNet-18 | NTU RGB+D 60 [53], NTU RGB+D 120 [56], NW-UCLA [57] |
| Mutual-attentional fusion block (intermediate) [39] | RGB and depth embeddings | ResNet-34 and Transformer encoder | THU-READ [58], FPHA [59], WCVS [60] |
| Attention mechanism (Intermediate) [38] | RGB and depth | Densely connected 3D CNN | Real-set, SBU-Kinect, MSR-action-3D |
| CCA-based feature fusion [37] | RGB and depth | 3D ConvLSTM, weighted dynamic images | ChaLearn LAP IsoGD [61], NTU RGB+D [53], multi-modal and multi-view and interactive benchmark [62] |
| Naive Bayes combination (late fusion) [35] | RGB and depth | SIFT (RGB) and SURF (depth) | UTKinect-Action3D [63], CAD-60 [64,65], LIRIS human activities |
| Product score fusion (late fusion) [34] | Visual (RGB) and depth dynamic images | c-ConvNet | ChaLearn LAP IsoGD [61], NTU RGB+D [53] |
| Fusion score (late fusion) [33] | RGB and depth frames | Pre-trained VGG networks | MSRDaily activity 3D [49], UTD-MHAD [51], CAD-60 [64,65] |
| early, intermediate, and late fusion [13] | RGB, depth, skeleton | I3D and shift-GCN | NTU RGB+D [53], SBU interaction [66] |
| Cross-modality compensation block (intermediate) [42] | RGB and depth | ResNet and VGG with CMCB | NTU RGB+D 120 [56], THU-READ [58], PKU-MMD [67] |
| SlowFast multimodality compensation block (intermediate) [40] | RGB & Depth features | Swin transformer | NTU RGB+D 120 [56], NTU RGB+D 60 [53], THU-READ [58], PKU-MMD [67] |
| Cross-modality fusion transformer (intermediate) [41] | RGB and depth features | Restnet50 feature extractors | NTU RGB+D 120 [56], THU-READ [58], PKU-MMD [67] |
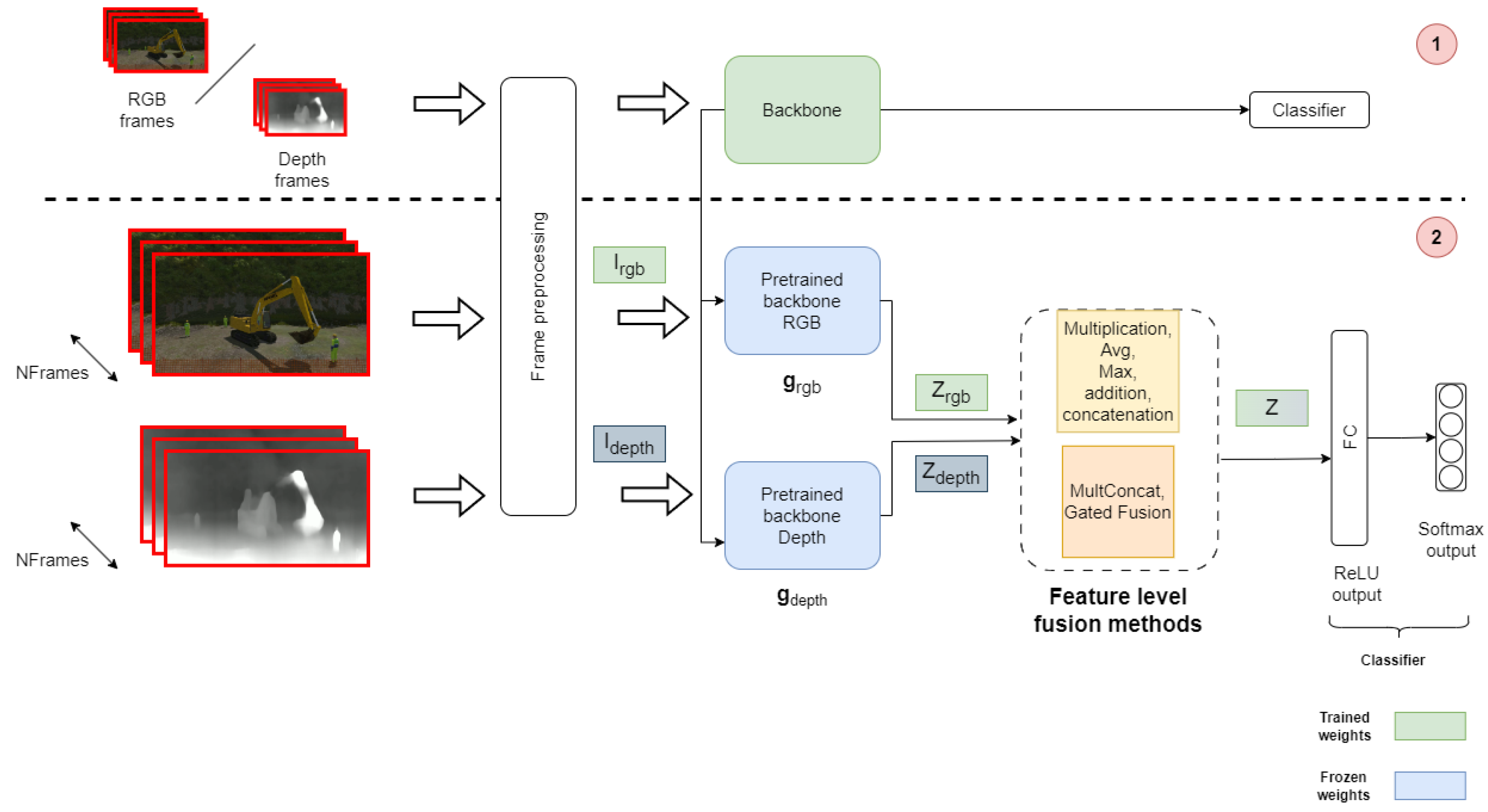
3. Proposed Approach for RGB-D Dangerous Action Recognition
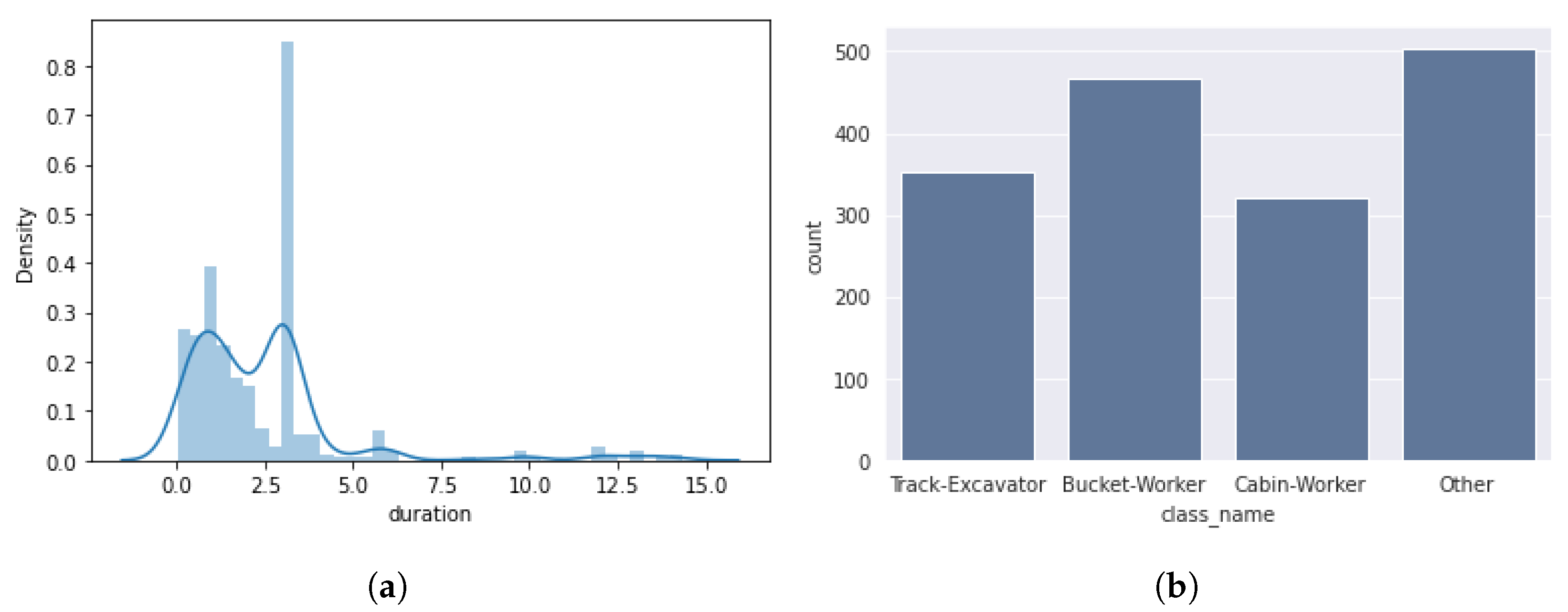
3.1. Dataset
3.2. Problem Formulation
3.3. Modality Encoders
- Slowfast: [71] SlowFast networks are designed for video recognition using RGB frames. It is divided into two main components: a slow and a fast pathway(see Figure 11). The slow pathway, operating at a low frame rate, allows one to capture spatial semantics, and the Fast pathway, operating at a high frame rate, is used to capture motion at fine temporal resolution. It was tested to achieve strong performance for both action classification and detection in video, large contribution, and state-of-the-art accuracy are reported on major video recognition benchmarks: kinetics [72], charades [73], and AVA [74]
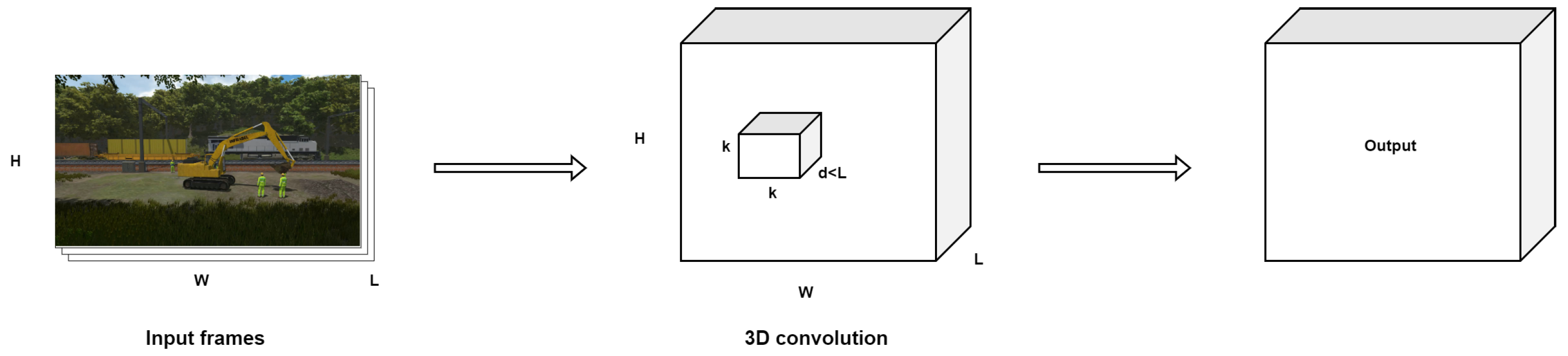
- C3D: introduced by [75], utilizes 3D convolutional layers (3D ConvNets) to analyze video data, capturing spatial and temporal information simultaneously. This model processes video clips by applying filters across three dimensions (width, height, and time), enabling it to extract features from the sequences of frames for action recognition (see Figure 12). The architecture is straightforward, comprising repeated blocks of 3D convolutions followed by pooling layers, designed to work with fixed-length video segments, typically 16 frames. Despite its simplicity, C3D has shown effectiveness in various video analysis tasks compared to 2D ConvNets, benefiting from the ability to be pre-trained on large video datasets and fine-tuned for specific tasks.
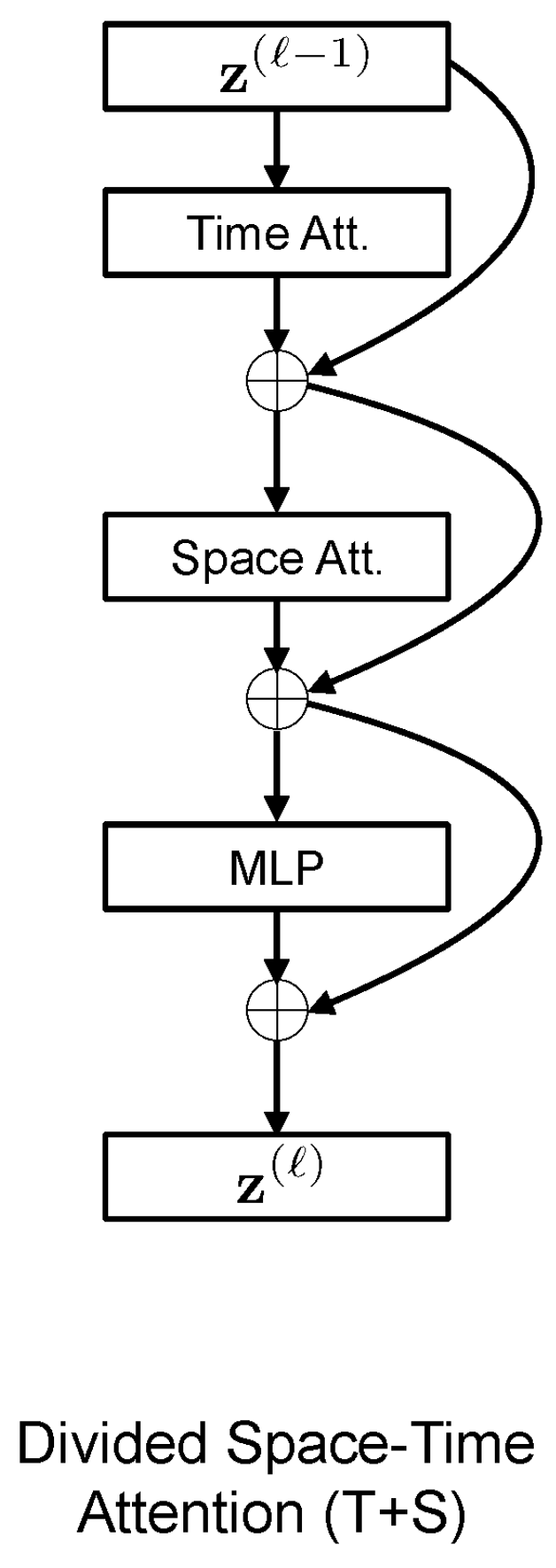
- TimesFormer: [76] a convolution-free approach for video classification that is built exclusively on self-attention over space and time. This architecture, which is based on Transformers, enables spatiotemporal feature learning directly from frame-level patches(see Figure 13). The authors claim that, despite the radically new design, TimeSformer achieves state-of-the-art results on several action recognition benchmarks such as Kinetics-400 [72] and Kinetics-600 [77].
3.4. Setup
4. Results and Discussion
4.1. Embedding Visualization
4.2. Modalities Contribution
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mahmoudi, S.A.; Amel, O.; Stassin, S.; Liagre, M.; Benkedadra, M.; Mancas, M. A Review and Comparative Study of Explainable Deep Learning Models Applied on Action Recognition in Real Time. Electronics 2023, 12, 2027. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Liang, P.P.; Zadeh, A.; Morency, L.P. Foundations and recent trends in multimodal machine learning: Principles, challenges, and open questions. arXiv 2022, arXiv:2209.03430. [Google Scholar]
- Huang, Y.; Du, C.; Xue, Z.; Chen, X.; Zhao, H.; Huang, L. What makes multi-modal learning better than single (provably). Adv. Neural Inf. Process. Syst. 2021, 34, 10944–10956. [Google Scholar]
- Liang, P.P.; Lyu, Y.; Fan, X.; Wu, Z.; Cheng, Y.; Wu, J.; Chen, L.; Wu, P.; Lee, M.A.; Zhu, Y.; et al. Multibench: Multiscale benchmarks for multimodal representation learning. arXiv 2021, arXiv:2107.07502. [Google Scholar]
- Rahate, A.; Walambe, R.; Ramanna, S.; Kotecha, K. Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions. Inf. Fusion 2022, 81, 203–239. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Lin, A.S.; Rao, S.; Celikyilmaz, A.; Nouri, E.; Brockett, C.; Dey, D.; Dolan, B. A recipe for creating multimodal aligned datasets for sequential tasks. arXiv 2020, arXiv:2005.09606. [Google Scholar]
- Botach, A.; Zheltonozhskii, E.; Baskin, C. End-to-end referring video object segmentation with multimodal transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4985–4995. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. In Proceedings of the International Conference on Machine Learning, Virtual, 8–24 July 2021. [Google Scholar]
- Garcia, N.C.; Morerio, P.; Murino, V. Modality distillation with multiple stream networks for action recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–118. [Google Scholar]
- Joshi, G.; Walambe, R.; Kotecha, K. A review on explainability in multimodal deep neural nets. IEEE Access 2021, 9, 59800–59821. [Google Scholar] [CrossRef]
- Boulahia, S.Y.; Amamra, A.; Madi, M.R.; Daikh, S. Early, intermediate and late fusion strategies for robust deep learning-based multimodal action recognition. Mach. Vis. Appl. 2021, 32, 121. [Google Scholar] [CrossRef]
- Shutova, E.; Kiela, D.; Maillard, J. Black holes and white rabbits: Metaphor identification with visual features. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 160–170. [Google Scholar]
- Fränti, P.; Brown, G.; Loog, M.; Escolano, F.; Pelillo, M. Structural, Syntactic, and Statistical Pattern Recognition: Joint IAPR International Workshop, S+ SSPR 2014, Joensuu, Finland, 20–22 August 2014; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8621. [Google Scholar]
- Li, G.; Li, N. Customs classification for cross-border e-commerce based on text-image adaptive convolutional neural network. Electron. Commer. Res. 2019, 19, 779–800. [Google Scholar] [CrossRef]
- Che, C.; Wang, H.; Ni, X.; Lin, R. Hybrid multimodal fusion with deep learning for rolling bearing fault diagnosis. Measurement 2021, 173, 108655. [Google Scholar] [CrossRef]
- Wang, W.; Tran, D.; Feiszli, M. What makes training multi-modal classification networks hard? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–16 June 2020; pp. 12695–12705. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient low-rank multimodal fusion with modality-specific factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Xu, P.; Zhu, X.; Clifton, D.A. Multimodal learning with transformers: A survey. arXiv 2022, arXiv:2206.06488. [Google Scholar] [CrossRef] [PubMed]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. Visualbert: A simple and performant baseline for vision and language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Jiang, Y.; Natarajan, V.; Chen, X.; Rohrbach, M.; Batra, D.; Parikh, D. Pythia v0. 1: The winning entry to the vqa challenge 2018. arXiv 2018, arXiv:1807.09956. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Nagrani, A.; Yang, S.; Arnab, A.; Jansen, A.; Schmid, C.; Sun, C. Attention Bottlenecks for Multimodal Fusion. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34, pp. 14200–14213. [Google Scholar]
- Sahu, G.; Vechtomova, O. Adaptive fusion techniques for multimodal data. arXiv 2019, arXiv:1911.03821. [Google Scholar]
- Pérez-Rúa, J.M.; Vielzeuf, V.; Pateux, S.; Baccouche, M.; Jurie, F. Mfas: Multimodal fusion architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6966–6975. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–34. [Google Scholar]
- Perez-Rua, J.M.; Baccouche, M.; Pateux, S. Efficient progressive neural architecture search. arXiv 2018, arXiv:1808.00391. [Google Scholar]
- Morshed, M.G.; Sultana, T.; Alam, A.; Lee, Y.K. Human action recognition: A taxonomy-based survey, updates, and opportunities. Sensors 2023, 23, 2182. [Google Scholar] [CrossRef]
- Singh, R.; Khurana, R.; Kushwaha, A.K.S.; Srivastava, R. Combining CNN streams of dynamic image and depth data for action recognition. Multimed. Syst. 2020, 26, 313–322. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Wan, J.; Ogunbona, P.; Liu, X. Cooperative training of deep aggregation networks for RGB-D action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Avola, D.; Bernardi, M.; Foresti, G.L. Fusing depth and colour information for human action recognition. Multimed. Tools Appl. 2019, 78, 5919–5939. [Google Scholar] [CrossRef]
- Shahroudy, A.; Ng, T.T.; Gong, Y.; Wang, G. Deep multimodal feature analysis for action recognition in rgb+ d videos. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1045–1058. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Song, Z.; Li, W.; Wang, P. A hybrid network for large-scale action recognition from rgb and depth modalities. Sensors 2020, 20, 3305. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Gao, H.; Yang, W.; Jiang, Y.; Chin, W.; Kubota, N.; Ju, Z. A discriminative deep model with feature fusion and temporal attention for human action recognition. IEEE Access 2020, 8, 43243–43255. [Google Scholar] [CrossRef]
- Li, X.; Hou, Y.; Wang, P.; Gao, Z.; Xu, M.; Li, W. Trear: Transformer-based rgb-d egocentric action recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 246–252. [Google Scholar] [CrossRef]
- Xiao, X.; Ren, Z.; Li, H.; Wei, W.; Yang, Z.; Yang, H. SlowFast Multimodality Compensation Fusion Swin Transformer Networks for RGB-D Action Recognition. Mathematics 2023, 11, 2115. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, J.; Liu, L.; Ren, Z.; Zhang, Q.; Song, C. Dual-stream cross-modality fusion transformer for RGB-D action recognition. Knowl.-Based Syst. 2022, 255, 109741. [Google Scholar] [CrossRef]
- Cheng, J.; Ren, Z.; Zhang, Q.; Gao, X.; Hao, F. Cross-modality compensation convolutional neural networks for RGB-D action recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1498–1509. [Google Scholar] [CrossRef]
- Lee, S.; Woo, S.; Park, Y.; Nugroho, M.A.; Kim, C. Modality mixer for multi-modal action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 3298–3307. [Google Scholar]
- Pareek, P.; Thakkar, A. RGB-D based human action recognition using evolutionary self-adaptive extreme learning machine with knowledge-based control parameters. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 939–957. [Google Scholar] [CrossRef]
- Kumar, R.; Kumar, S. Survey on artificial intelligence-based human action recognition in video sequences. Opt. Eng. 2023, 62, 023102. [Google Scholar] [CrossRef]
- Wang, C.; Yan, J. A comprehensive survey of rgb-based and skeleton-based human action recognition. IEEE Access 2023, 11, 53880–53898. [Google Scholar] [CrossRef]
- Shaikh, M.B.; Chai, D. RGB-D Data-Based Action Recognition: A Review. Sensors 2021, 21, 4246. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time human action recognition based on depth motion maps. J. Real-Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Zhang, H.; Parker, L.E. 4-dimensional local spatio-temporal features for human activity recognition. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 2044–2049. [Google Scholar]
- Kurakin, A.; Zhang, Z.; Liu, Z. A real time system for dynamic hand gesture recognition with a depth sensor. In Proceedings of the 2012 Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Piscataway, NJ, USA, 27–31 August 2012; pp. 1975–1979. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Yu, G.; Liu, Z.; Yuan, J. Discriminative orderlet mining for real-time recognition of human-object interaction. In Proceedings of the Computer Vision–ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Revised Selected Papers, Part V 12. Springer: Berlin/Heidelberg, Germany, 2015; pp. 50–65. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Oreifej, O.; Liu, Z. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Ni, B.; Wang, G.; Moulin, P. Rgbd-hudaact: A color-depth video database for human daily activity recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1147–1153. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-view action modeling, learning and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar]
- Tang, Y.; Wang, Z.; Lu, J.; Feng, J.; Zhou, J. Multi-stream deep neural networks for rgb-d egocentric action recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3001–3015. [Google Scholar] [CrossRef]
- Garcia-Hernando, G.; Yuan, S.; Baek, S.; Kim, T.K. First-person hand action benchmark with rgb-d videos and 3d hand pose annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 409–419. [Google Scholar]
- Moghimi, M.; Azagra, P.; Montesano, L.; Murillo, A.C.; Belongie, S. Experiments on an rgb-d wearable vision system for egocentric activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 597–603. [Google Scholar]
- Wan, J.; Zhao, Y.; Zhou, S.; Guyon, I.; Escalera, S.; Li, S.Z. Chalearn looking at people rgb-d isolated and continuous datasets for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 56–64. [Google Scholar]
- Xu, N.; Liu, A.; Nie, W.; Wong, Y.; Li, F.; Su, Y. Multi-modal & multi-view & interactive benchmark dataset for human action recognition. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1195–1198. [Google Scholar]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3d joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Human activity detection from RGBD images. In Proceedings of the Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011. [Google Scholar]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Unstructured human activity detection from rgbd images. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St Paul, MI, USA, 14–18 May 2012; pp. 842–849. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person interaction detection using body-pose features and multiple instance learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 28–35. [Google Scholar]
- Liu, J.; Song, S.; Liu, C.; Li, Y.; Hu, Y. A benchmark dataset and comparison study for multi-modal human action analytics. ACM Trans. Multimed. Comput. Commun. Appl. (Tomm) 2020, 16, 1–24. [Google Scholar] [CrossRef]
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular Depth Estimation Using Deep Learning: A Review. Sensors 2022, 22, 5353. [Google Scholar] [CrossRef] [PubMed]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 510–526. [Google Scholar]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6047–6056. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the ICML, Online, 18–24 July 2021; Volume 2, p. 4. [Google Scholar]
- Carreira, J.; Noland, E.; Banki-Horvath, A.; Hillier, C.; Zisserman, A. A short note about kinetics-600. arXiv 2018, arXiv:1808.01340. [Google Scholar]
- Contributors, M. OpenMMLab’s Next Generation Video Understanding Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmaction2 (accessed on 7 May 2024).
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Amel, O.; Stassin, S. Multimodal Approach for Harmonized System Code Prediction. In Proceedings of the 31st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 4–6 October 2023; pp. 181–186. [Google Scholar] [CrossRef]
- Arevalo, J.; Solorio, T.; Montes-y Gómez, M.; González, F.A. Gated multimodal units for information fusion. arXiv 2017, arXiv:1702.01992. [Google Scholar]





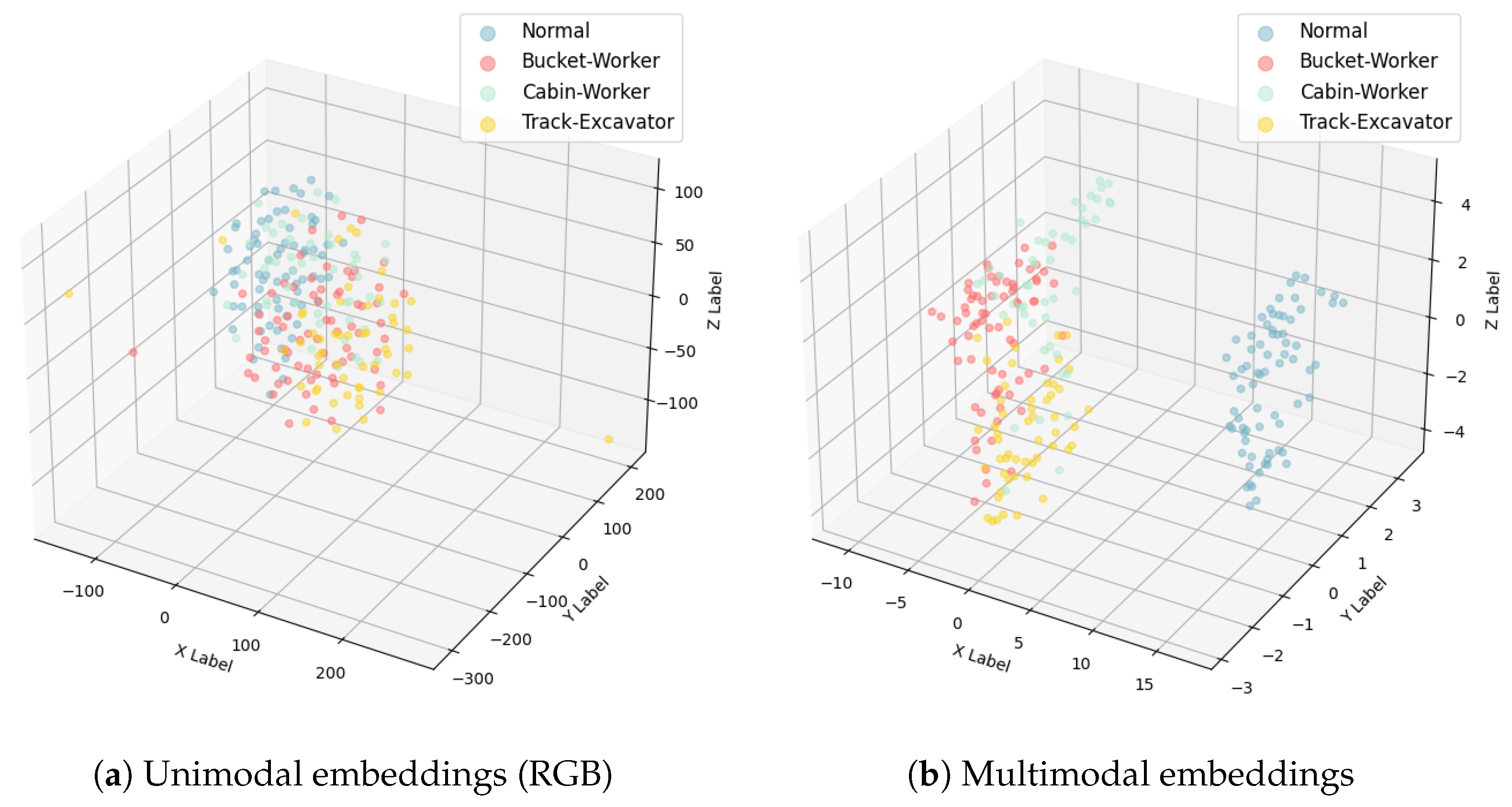
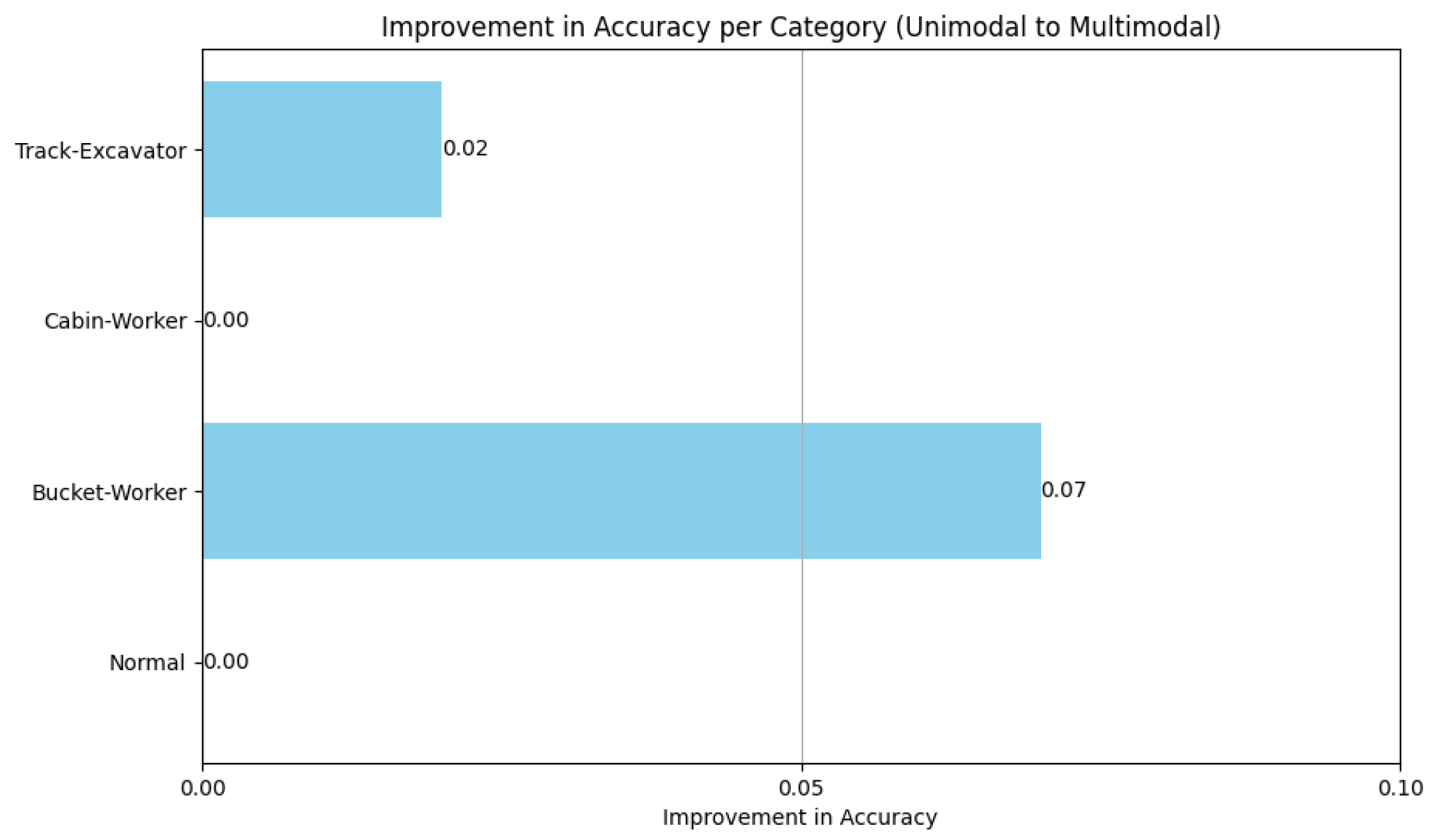
| Actions | Definition |
|---|---|
| Other | No dangerous actions to be notified |
| Cabin-Worker | Worker moving too close to the cabin while the excavator is being operated |
| Bucket-Worker | Worker moving under the bucket, in danger of getting hit, or materials may fall from the bucket |
| Track-Excavator | The excavator moving forward to the tracks (active railway line or electric wires) |
| Backbone | Fusion Method | Modalities | Test Accuracy |
|---|---|---|---|
| C3d | Addition | RGB-D | 0.741 |
| Concatenation | RGB-D | 0.728 | |
| Max | RGB-D | 0.663 | |
| Product | RGB-D | 0.683 | |
| Average | RGB-D | 0.720 | |
| GatedFusion [82] | RGB-D | 0.22 | |
| / | rgb only | 0.806 | |
| / | depth only | 0.786 | |
| MultConcat [81] | RGB-D | 0.675 | |
| Timesformer | Addition | RGB-D | 0.296 |
| Concatenation | RGB-D | 0.296 | |
| Max | RGB-D | 0.399 | |
| Product | RGB-D | 0.428 | |
| Average | RGB-D | 0.383 | |
| GatedFusion [82] | RGB-D | 0.3868 | |
| / | depth only | 0.7572 | |
| / | rgb only | 0.7901 | |
| MultConcat [81] | RGB-D | 0.465 | |
| Slowfast | Addition | RGB-D | 0.868 |
| Concatenation | RGB-D | 0.860 | |
| Max | RGB-D | 0.860 | |
| Product | RGB-D | 0.860 | |
| Average | RGB-D | 0.876 | |
| GatedFusion [82] | RGB-D | 0.8477 | |
| / | depth only | 0.7984 | |
| / | rgb only | 0.8601 | |
| MultConcat [81] | RGB-D | 0.893 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amel, O.; Siebert, X.; Mahmoudi, S.A. Comparison Analysis of Multimodal Fusion for Dangerous Action Recognition in Railway Construction Sites. Electronics 2024, 13, 2294. https://doi.org/10.3390/electronics13122294
Amel O, Siebert X, Mahmoudi SA. Comparison Analysis of Multimodal Fusion for Dangerous Action Recognition in Railway Construction Sites. Electronics. 2024; 13(12):2294. https://doi.org/10.3390/electronics13122294
Chicago/Turabian StyleAmel, Otmane, Xavier Siebert, and Sidi Ahmed Mahmoudi. 2024. "Comparison Analysis of Multimodal Fusion for Dangerous Action Recognition in Railway Construction Sites" Electronics 13, no. 12: 2294. https://doi.org/10.3390/electronics13122294
APA StyleAmel, O., Siebert, X., & Mahmoudi, S. A. (2024). Comparison Analysis of Multimodal Fusion for Dangerous Action Recognition in Railway Construction Sites. Electronics, 13(12), 2294. https://doi.org/10.3390/electronics13122294