
Revealing GLCM Metric Variations across a Plant Disease Dataset: A Comprehensive Examination and Future Prospects for Enhanced Deep Learning Applications

 ,
,  ,
, 
Abstract
1. Introduction
2. Methodology
2.1. Data Collection
- “plant_village dataset”;
- “a_database_of_leaf_images”;
- “RoCoLe dataset”;
- “FGVCx_cassava dataset” and
- “paddy_doctor dataset”.
2.2. Image Preprocessing and GLCM Metrics
2.3. Statistical Analysis
2.4. Deep Learning Model Training and Evaluation
- (i)
- Preprocessing of the Data: To improve model performance and better feature representation and guarantee uniformity before processing, the images were resized to a uniform resolution (227 × 227) and pixel values.
- (ii)
- Model Selection: The DarkNet19 architecture was chosen as the foundational model for training since it has a track record of success in image classification challenges. DarkNet19 is a deep convolutional neural network (CNN) model.
- (iii)
- Hyperparameter Tuning: To maximize classification accuracy, the DarkNet19 model’s hyperparameters—such as initial learning rate (0.0001), mini-batch size (128), maximum epoch (10), weight and bias learning rate factors (10)—were adjusted to the same values for all training trials.
3. Results and Discussion
3.1. Ideals of Image Properties and Distribution across the Datasets
3.1.1. Data Imbalance
3.1.2. Image Resolutions
3.2. Distribution of GLCM Metrics
3.2.1. Energy
3.2.2. Contrast
3.2.3. Correlation
3.2.4. Homogeneity
3.2.5. Angular Second Moment (ASM)
3.2.6. Total Variance
3.2.7. Maximum Probability
3.2.8. Difference Variance
3.2.9. Joint Entropy
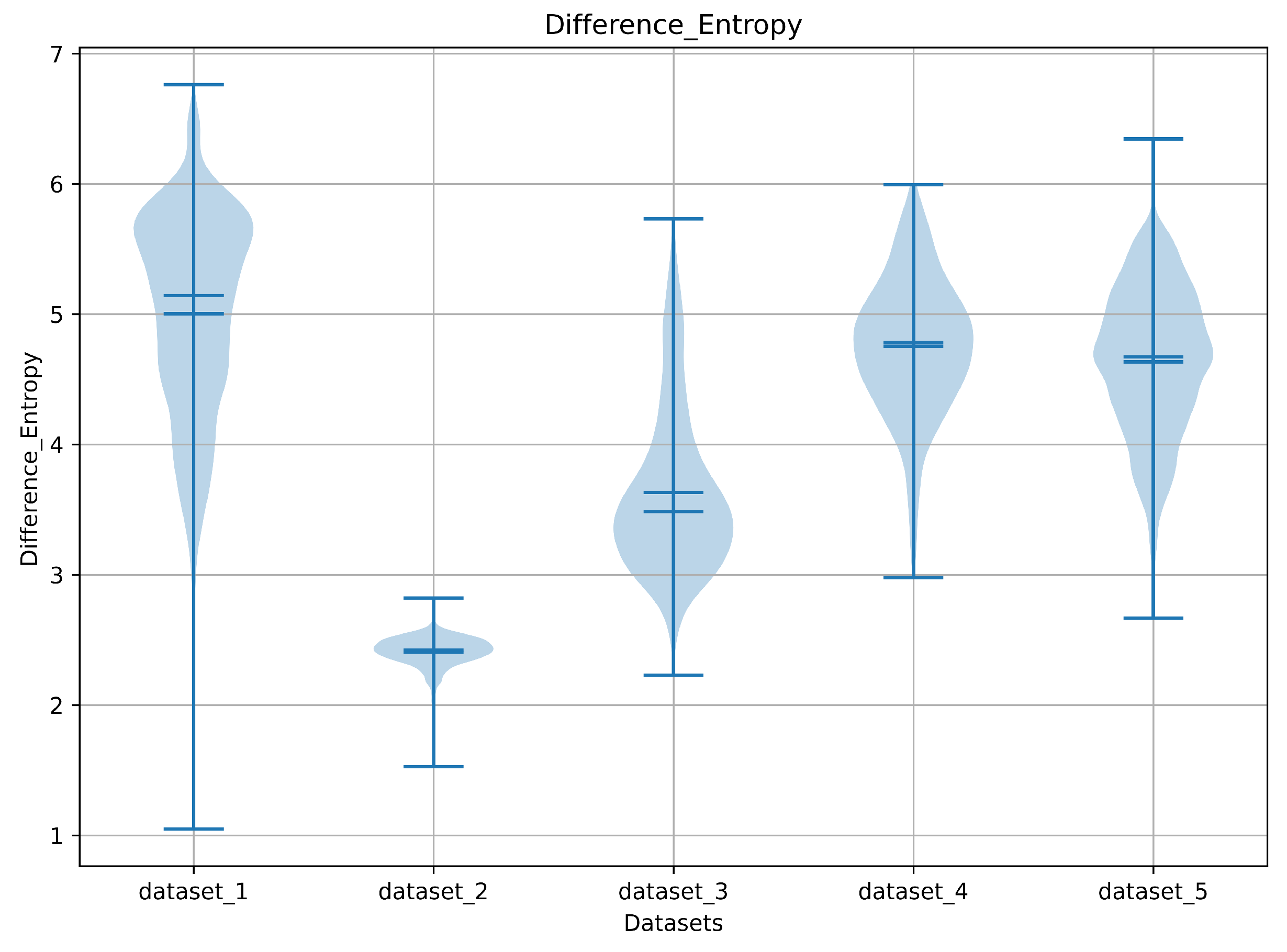
3.2.10. Difference Entropy
3.3. Highest-Lowest GLCM Metric’s Scorecard
3.4. Correlation Matrix of GLCM Metrics
3.4.1. Strong Correlations
3.4.2. Moderate Correlations
3.4.3. Weak Correlations
3.4.4. Inverse Correlation
3.4.5. Kruskal–Wallis Test of Variance
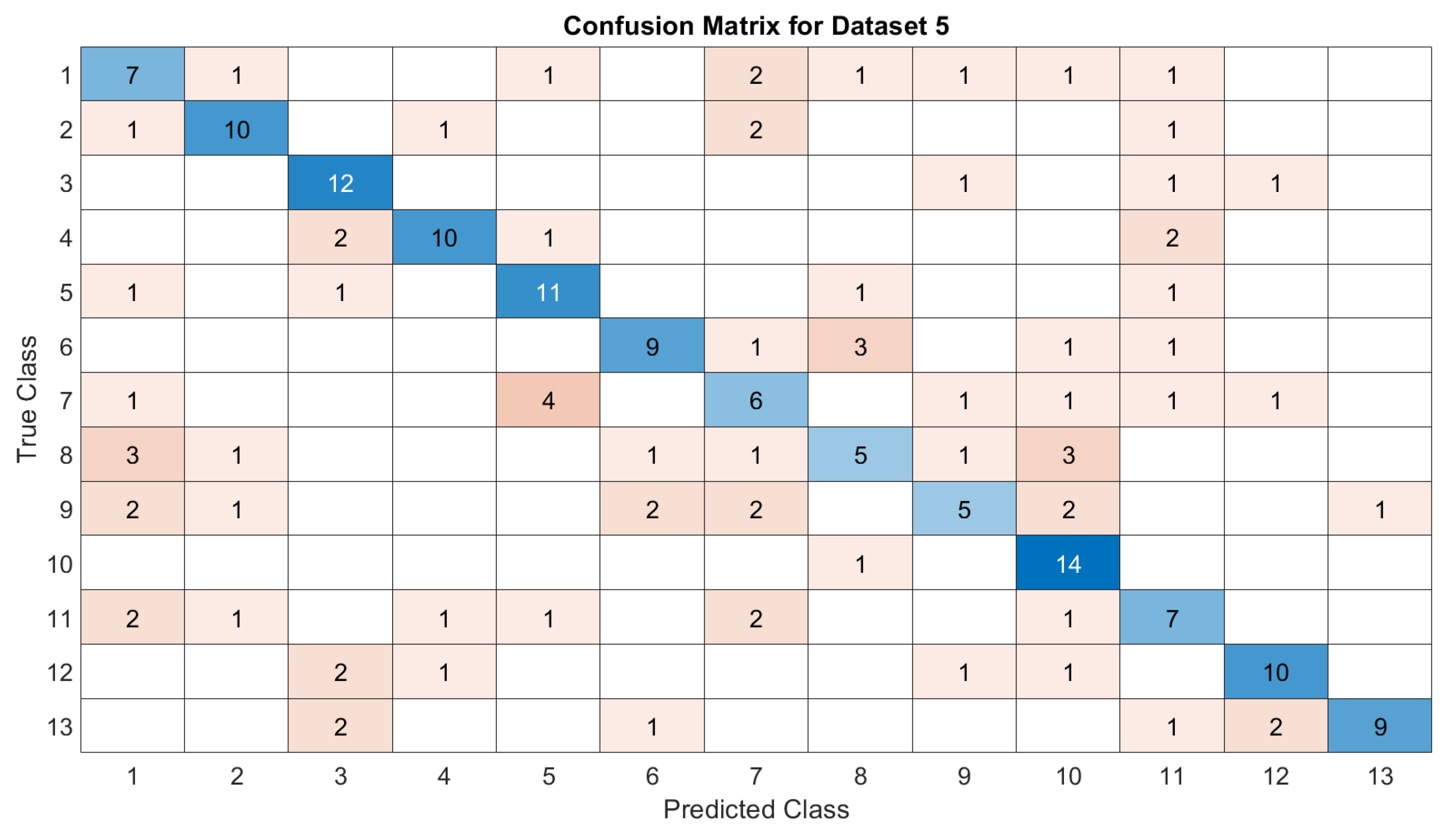
3.5. Deep Learning Model’s Development and Analysis
4. Conclusions
5. Recommendations and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- FAO. The State of Food and Agriculture, 1974. Lancet 1975, 306, 313–314. [Google Scholar] [CrossRef]
- FAO. FAO—News Article: New Standards to Curb the Global Spread of Plant Pests and Diseases; Food and Agriculture Organization of the United Nations: Roma, Italy, 2018. [Google Scholar]
- Horst, R.K. Plant Diseases and Their Pathogens. In Westcott’s Plant Disease Handbook; Springer: Berlin/Heidelberg, Germany, 2001; pp. 65–530. [Google Scholar] [CrossRef]
- FAO. International Year of Plant Health—Final Report; FAO: Rome, Italy, 2021. [Google Scholar] [CrossRef]
- Buja, I.; Sabella, E.; Monteduro, A.G.; Chiriacò, M.S.; De Bellis, L.; Luvisi, A.; Maruccio, G. Advances in plant disease detection and monitoring: From traditional assays to in-field diagnostics. Sensors 2021, 21, 2129. [Google Scholar] [CrossRef] [PubMed]
- Strange, R.N.; Scott, P.R. Plant Disease: A Threat to Global Food Security. Annu. Rev. Phytopathol. 2005, 43, 83–116. [Google Scholar] [CrossRef] [PubMed]
- Witten, I.H.; Cunningham, S.; Holmes, G.; McQueen, R.J.; Smith, L.A. Practical Machine Learning and its Potential Application to Problems in Agriculture. In Practical Machine Learning and Its Potential Application to Problems in Agriculture; Department of Computer Science, University of Waikato: Hamilton, New Zealand, 1993; Volume 1, pp. 308–325. [Google Scholar]
- Shrivastava, V.K.; Pradhan, M.K. Rice plant disease classification using color features: A machine learning paradigm. J. Plant Pathol. 2021, 103, 17–26. [Google Scholar] [CrossRef]
- Zhou, H.; Li, Y.; Zhang, Q.; Xu, H.; Su, Y. Soft-sensing of effluent total phosphorus using adaptive recurrent fuzzy neural network with Gustafson-Kessel clustering. Expert Syst. Appl. 2022, 203, 117589. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Tibdewal, M.N.; Kulthe, Y.M.; Bharambe, A.; Farkade, A.; Dongre, A. Deep Learning Models for Classification of Cotton Crop Disease Detection. Zeich. J. 2022, 8. [Google Scholar]
- Prakash, N.; Udayakumar, E.; Kumareshan, N. Design and development of Android based Plant disease detection using Arduino. In Proceedings of the 2020 7th International Conference on Smart Structures and Systems, ICSSS 2020, Chennai, India, 23–24 July 2020. [Google Scholar] [CrossRef]
- Petchiammal, A.; Briskline Kiruba, S.; Murugan, D. Paddy Leaf diseases identification on Infrared Images based on Convolutional Neural Networks. arXiv 2022, arXiv:2208.00031. [Google Scholar] [CrossRef]
- Ahmad, A.; Saraswat, D.; El Gamal, A. A survey on using deep learning techniques for plant disease diagnosis and recommendations for development of appropriate tools. Smart Agric. Technol. 2023, 3, 100083. [Google Scholar] [CrossRef]
- Hughes, D.P.; Salathe, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar]
- Pardede, H.F.; Suryawati, E.; Zilvan, V.; Ramdan, A.; Kusumo, R.B.S.; Heryana, A.; Yuwana, R.S.; Krisnandi, D.; Subekti, A.; Fauziah, F.; et al. Plant diseases detection with low resolution data using nested skip connections. J. Big Data 2020, 7, 57. [Google Scholar] [CrossRef]
- Thakur, P.S.; Sheorey, T.; Ojha, A. VGG-ICNN: A Lightweight CNN model for crop disease identification. Multimed. Tools Appl. 2023, 82, 497–520. [Google Scholar] [CrossRef]
- Nagi, R.; Tripathy, S.S. Plant disease identification using fuzzy feature extraction and PNN. Signal Image Video Process. 2023, 17, 2809–2815. [Google Scholar] [CrossRef]
- Hanh, B.T.; Van Manh, H.; Nguyen, N.V. Enhancing the performance of transferred efficientnet models in leaf image-based plant disease classification. J. Plant Dis. Prot. 2022, 129, 623–634. [Google Scholar] [CrossRef]
- Wiesner-Hanks, T.; Stewart, E.L.; Kaczmar, N.; Dechant, C.; Wu, H.; Nelson, R.J.; Lipson, H.; Gore, M.A. Image set for deep learning: Field images of maize annotated with disease symptoms. BMC Res. Notes 2018, 11, 440. [Google Scholar] [CrossRef] [PubMed]
- Barbedo, J.G.A. Impact of dataset size and variety on the effectiveness of deep learning and transfer learning for plant disease classification. Comput. Electron. Agric. 2018, 153, 46–53. [Google Scholar] [CrossRef]
- Pérez-Enciso, M.; Zingaretti, L.M. A Guide for Using Deep Learning for Complex Trait Genomic Prediction. Genes 2019, 10, 553. [Google Scholar] [CrossRef]
- Singh, D.; Jain, N.; Jain, P.; Kayal, P.; Kumawat, S.; Batra, N. PlantDoc: A dataset for visual plant disease detection. In Proceedings of the ACM International Conference Proceeding Series, Association for Computing Machinery, Dhaka, Bangladesh, 10–12 January 2020; pp. 249–253. [Google Scholar] [CrossRef]
- Oyewola, D.O.; Dada, E.G.; Misra, S.; Damaševičius, R. Detecting cassava mosaic disease using a deep residual convolutional neural network with distinct block processing. Peerj Comput. Sci. 2021, 7, e352. [Google Scholar] [CrossRef] [PubMed]
- Parraga-Alava, J.; Cusme, K.; Loor, A.; Santander, E. RoCoLe: A robusta coffee leaf images dataset for evaluation of machine learning based methods in plant diseases recognition. Data Brief 2019, 25, 104414. [Google Scholar] [CrossRef]
- Zhang, X.; Han, L.; Dong, Y.; Shi, Y.; Huang, W.; Han, L.; González-Moreno, P.; Ma, H.; Ye, H.; Sobeih, T. A Deep Learning-Based Approach for Automated Yellow Rust Disease Detection from High-Resolution Hyperspectral UAV Images. Remote Sens. 2019, 11, 1554. [Google Scholar] [CrossRef]
- Bhakta, I.; Phadikar, S.; Majumder, K. Thermal Image Augmentation with Generative Adversarial Network for Agricultural Disease Prediction. In Lecture Notes in Networks and Systems; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2022; Volume 480, pp. 345–354. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 215232. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; French, A.P.; Gao, L.; Ramcharan, A.; Hughes, D.P.; Mccloskey, P.; Baranowski, K.; Mbilinyi, N.; Mrisho, L.; Ndalahwa, M.; et al. A Mobile-Based Deep Learning Model for Cassava Disease Diagnosis. Front. Plant Sci. 2019, 10, 272. [Google Scholar] [CrossRef]
- Johannes, A.; Picon, A.; Alvarez-Gila, A.; Echazarra, J.; Rodriguez-Vaamonde, S.; Navajas, A.D.; Ortiz-Barredo, A. Automatic plant disease diagnosis using mobile capture devices, applied on a wheat use case. Comput. Electron. Agric. 2017, 138, 200–209. [Google Scholar] [CrossRef]
- Ahmad, J.; Jan, B.; Farman, H.; Ahmad, W.; Ullah, A. Disease detection in plum using convolutional neural network under true field conditions. Sensors 2020, 20, 5569. [Google Scholar] [CrossRef]
- Petchiammal; Kiruba, B.; Murugan; Arjunan, P. Paddy Doctor: A Visual Image Dataset for Automated Paddy Disease Classification and Benchmarking. In Proceedings of the 6th Joint International Conference on Data Science and Management of Data (10th ACM IKDD CODS and 28th COMAD), Mumbai, India, 4–7 January 2023; pp. 203–207. [Google Scholar] [CrossRef]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop, IIPhDW 2018, Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar] [CrossRef]
- Velásquez, A.C.; Castroverde, C.D.M.; He, S.Y. Plant–Pathogen Warfare under Changing Climate Conditions. Curr. Biol. 2018, 28, R619–R634. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; He, G.; Li, F.; Zhang, H. A novel database for plant diseases and pests classification. In Proceedings of the ICSPCC 2020—IEEE International Conference on Signal Processing, Communications and Computing, Proceedings, Macau, China, 21–24 August 2020. [Google Scholar] [CrossRef]
- Gadkari, D. Image Quality Analysis Using GLCM. In Electronic Theses and Dissertations; University of Central Florida: Orlando, FL, USA, 2004; pp. 1–120. [Google Scholar]
- Hall-Beyer, M. Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- Mall, P.K.; Singh, P.K.; Yadav, D. GLCM based feature extraction and medical X-RAY image classification using machine learning techniques. In Proceedings of the 2019 IEEE Conference on Information and Communication Technology, CICT 2019, Allahabad, India, 6–8 December 2019. [Google Scholar] [CrossRef]
- Kadir, A. A Model of Plant Identification System Using GLCM, Lacunarity And Shen Features. Publ. Res. J. Pharm. Biol. Chem. Sci. 2014, 5, 1–10. [Google Scholar]
- Shoaib, M.; Shah, B.; EI-Sappagh, S.; Ali, A.; Ullah, A.; Alenezi, F.; Gechev, T.; Hussain, T.; Ali, F. An advanced deep learning models-based plant disease detection: A review of recent research. Front. Plant Sci. 2023, 14, 1158933. [Google Scholar] [CrossRef] [PubMed]
- Gupta, H.P.; Chopade, S.; Dutta, T. Computational Intelligence in Agriculture. In Emerging Computing Paradigms; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2022; pp. 125–142. [Google Scholar] [CrossRef]
- Wang, G.; Sun, Y.; Wang, J. Automatic Image-Based Plant Disease Severity Estimation Using Deep Learning. Comput. Intell. Neurosci. 2017, 2017, 2917536. [Google Scholar] [CrossRef]
- Barbedo, J.G.A.; Koenigkan, L.V.; Halfeld-Vieira, B.A.; Costa, R.V.; Nechet, K.L.; Godoy, C.V.; Junior, M.L.; Patricio, F.R.A.; Talamini, V.; Chitarra, L.G.; et al. Annotated plant pathology databases for image-based detection and recognition of diseases. IEEE Lat. Am. Trans. 2018, 16, 1749–1757. [Google Scholar] [CrossRef]
- Barbedo, J.G. Factors influencing the use of deep learning for plant disease recognition. Biosyst. Eng. 2018, 172, 84–91. [Google Scholar] [CrossRef]
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 16 May 2024).
- Theodoridis, S. Machine Learning: A Bayesian and Optimization Perspective, 2nd ed.; Academic Press: Cambridge, MA, USA, 2020; pp. 1–1131. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annotation | Name | Total Images | Image Resolutions | Setting | Disease Classes | Plants Involved |
|---|---|---|---|---|---|---|
| dataset_1 | plant village dataset | 54,303 | [256 × 256] throughout | Lab | 38 | Apple, Cherry, Corn, grape, Peach, Pepper, Potato, Strawberry, and Tomato |
| dataset_2 | a database of leaf images | 4503 | [6000 × 4000] throughout | Lab | 22 | Mango, Arjun, Alstonia Scholaris, Guava, Bael, Jamun, Jatropha, Pongamia Pinnata, Basil, Pomegranate, Lemon, and Chinar |
| dataset_3 | RoCoLe dataset | 1560 | [2048 × 1152], 768 images, [1280 × 720], 479 images, [4128 × 2322], 313 images | Field | 5 | Coffee |
| dataset_4 | FGVCx cassava dataset | 537 | Variable between [213 × 231] to [960 × 540] | Field | 5 | Cassava |
| dataset_5 | paddy doctor dataset | 16,225 | [1080 × 1440], 16,219 images, [1440 × 1080], 6 images | Field | 13 | Paddy |
| Factors | Effects | Source |
|---|---|---|
| External factors such as uneven lighting, extensive occlusion, and fuzzy details. | Variations in the visual characteristics of affected plants. | [42] |
| Variations in the presence of illness and the growth of a pest. | Subtle differences in the characterization of the same diseases and pests in different regions, resulting in “intra-class distinctions”. | [43] |
| Similarities in the biological morphology and lifestyles of subclasses of diseases and pests. | Problem of “inter-class resemblance”. | [40] |
| Background disturbances. | Makes it harder to detect plant pests and diseases In actual agricultural settings. | [44] |
| GLCM Metrics | Highest in GLCM | Lowest in GLCM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| Energy | x | x | ||||||||
| Contrast | x | x | x | |||||||
| Correlation | x | x | ||||||||
| Homogeneity | x | x | ||||||||
| Angular Second Moment | x | x | x | |||||||
| Total Variance | x | x | ||||||||
| Maximum Probability | x | x | ||||||||
| Joint Entropy | x | x | ||||||||
| Difference Variance | x | x | ||||||||
| Difference Entropy | x | x | ||||||||
| Sum of scores: | 4 | 4 | 0 | 0 | 4 | 2 | 5 | 0 | 2 | 1 |
| Table Analyzed | GLCM 10 Parameters |
|---|---|
| p-value | <0.0001 |
| Exact or approximate p-value? | Approximate |
| p-value summary | **** (Highly significant differences among the medians) |
| Do the medians vary significantly (p < 0.05)? | Yes |
| Number of groups | 10 |
| Kruskal–Wallis statistic | 619,192 |
| Data summary | |
| Number of treatments (columns) | 10 |
| Number of values (total) | 637,010 |
| Datasets | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| D1 | 0.9122 | 0.9141 | 0.9123 | 0.9111 |
| D2 | 0.9060 | 0.9116 | 0.9061 | 0.9056 |
| D3 | 0.6666 | 0.7329 | 0.6667 | 0.6411 |
| D4 | 0.5866 | 0.5885 | 0.5867 | 0.5867 |
| D5 | 0.5897 | 0.5996 | 0.5897 | 0.5852 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabir, M.; Unal, F.; Akinci, T.C.; Martinez-Morales, A.A.; Ekici, S. Revealing GLCM Metric Variations across a Plant Disease Dataset: A Comprehensive Examination and Future Prospects for Enhanced Deep Learning Applications. Electronics 2024, 13, 2299. https://doi.org/10.3390/electronics13122299
Kabir M, Unal F, Akinci TC, Martinez-Morales AA, Ekici S. Revealing GLCM Metric Variations across a Plant Disease Dataset: A Comprehensive Examination and Future Prospects for Enhanced Deep Learning Applications. Electronics. 2024; 13(12):2299. https://doi.org/10.3390/electronics13122299
Chicago/Turabian StyleKabir, Masud, Fatih Unal, Tahir Cetin Akinci, Alfredo A. Martinez-Morales, and Sami Ekici. 2024. "Revealing GLCM Metric Variations across a Plant Disease Dataset: A Comprehensive Examination and Future Prospects for Enhanced Deep Learning Applications" Electronics 13, no. 12: 2299. https://doi.org/10.3390/electronics13122299
APA StyleKabir, M., Unal, F., Akinci, T. C., Martinez-Morales, A. A., & Ekici, S. (2024). Revealing GLCM Metric Variations across a Plant Disease Dataset: A Comprehensive Examination and Future Prospects for Enhanced Deep Learning Applications. Electronics, 13(12), 2299. https://doi.org/10.3390/electronics13122299