


CFE-YOLOv8s: Improved YOLOv8s for Steel Surface Defect Detection


 , ,
, ,
Abstract
1. Introduction
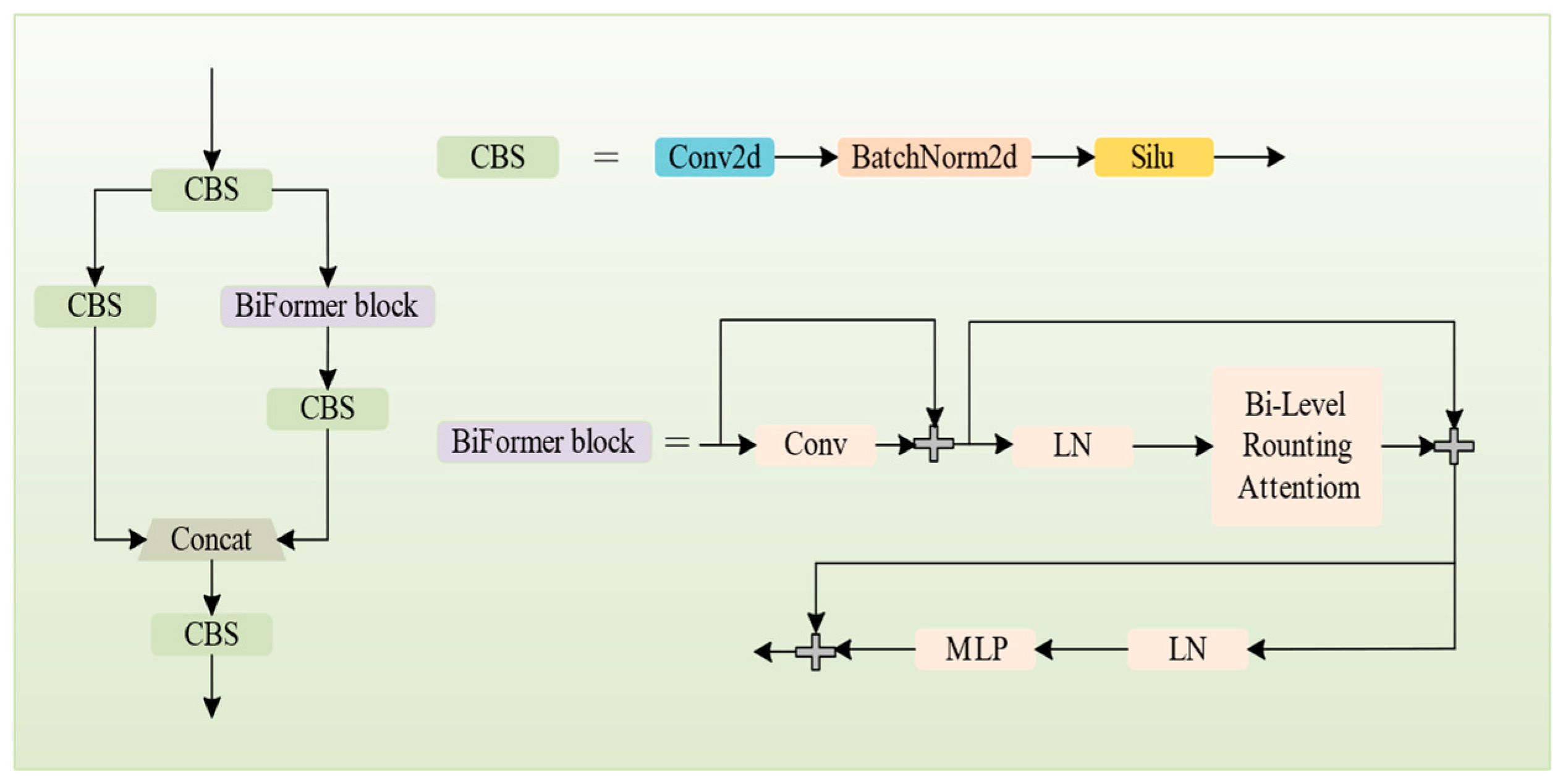
- We propose a new feature extraction module called CBS-BiFormer (CBiF) to address the issue of varied defect shapes and sizes and unclear defect boundaries. Unlike previous simple convolutional neural network (CNN) or Transformer structures, CBiF combines CNN and Transformer to fully utilize both local and global features in the image to enhance detection accuracy.
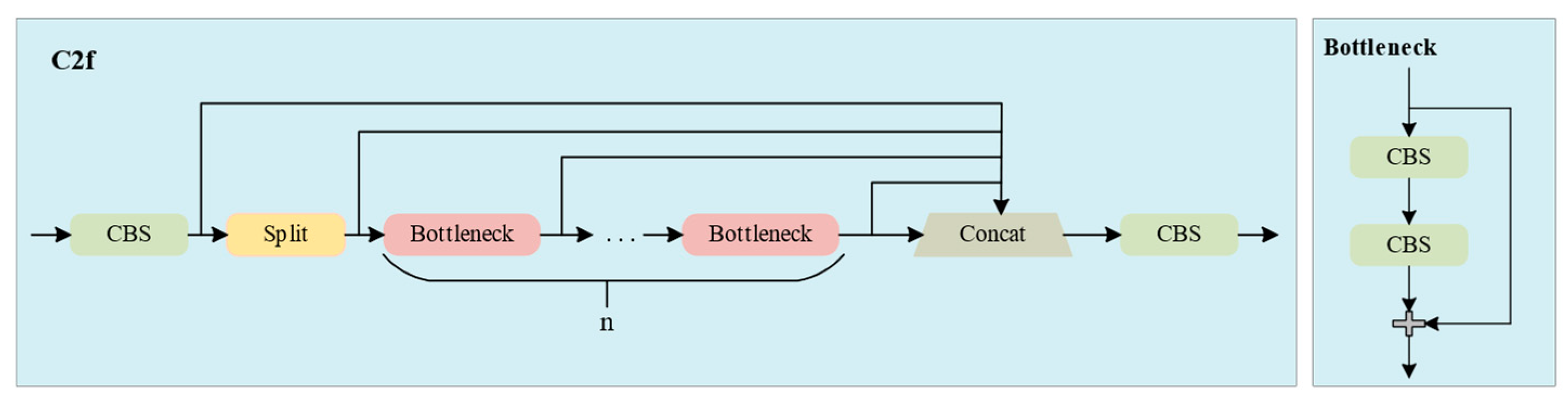
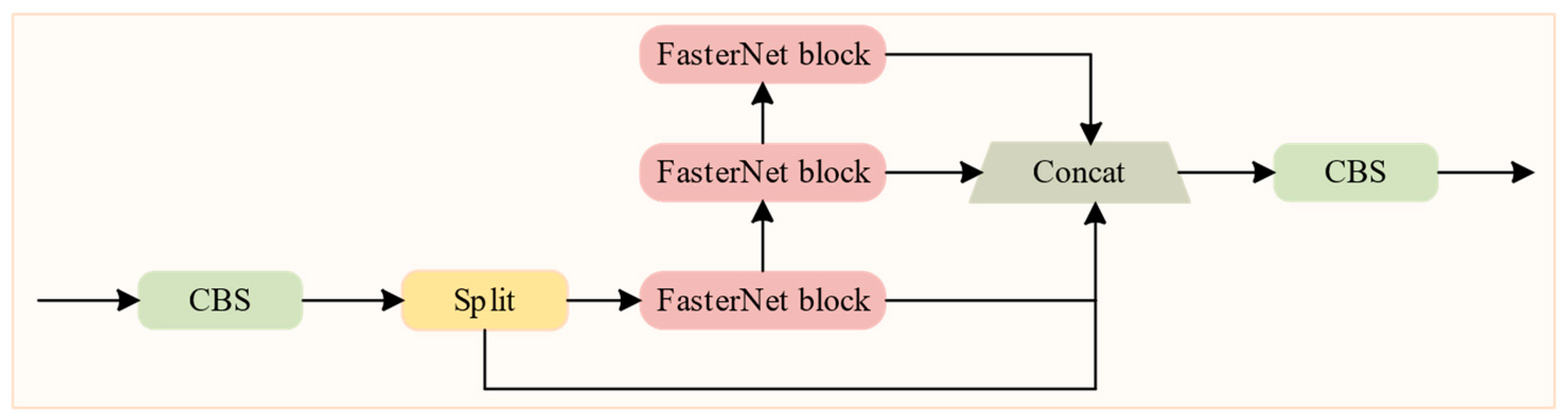
- We propose a lightweight Faster-C2f (FC) module based on the primary feature extraction module of YOLOv8s, C2f, and the FasterNet block. It reduces redundant computation and memory accesses, achieving a lightweight model while ensuring detection accuracy.
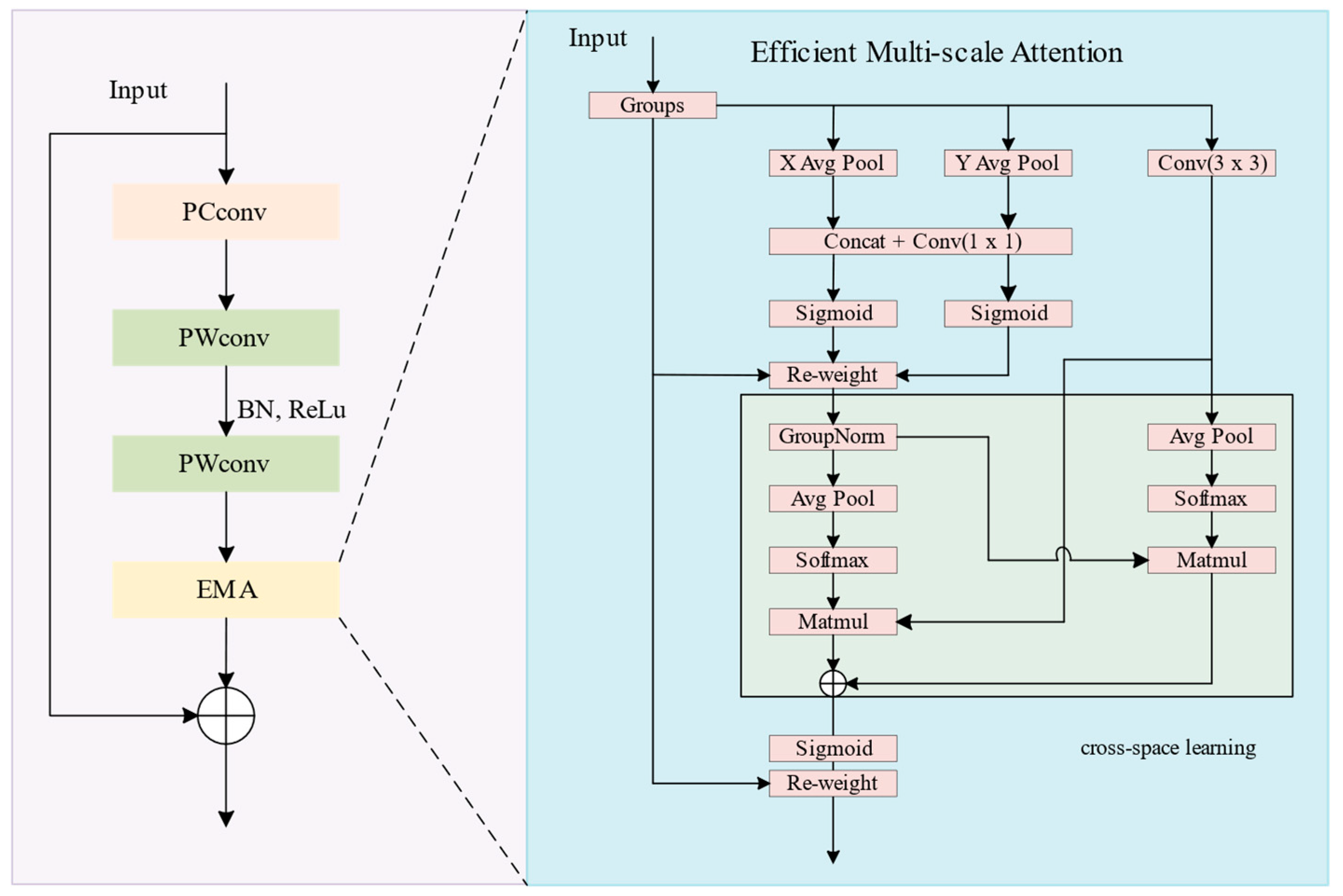
- To further enhance the detection accuracy, efficient multi-scale attention (EMA) is applied to the lightweight module FC, resulting in the proposal of the EMA-Faster-C2f (EFC) module. By introducing the attention mechanism, the model is assisted in learning the importance of different features. While ensuring the model is lightweight, EFC enhances the capability of feature fusion.
2. Related Works
2.1. Conventional Machine Learning Approaches
2.2. Deep Learning Approaches
3. The Proposed Method
3.1. Overview of YOLOv8
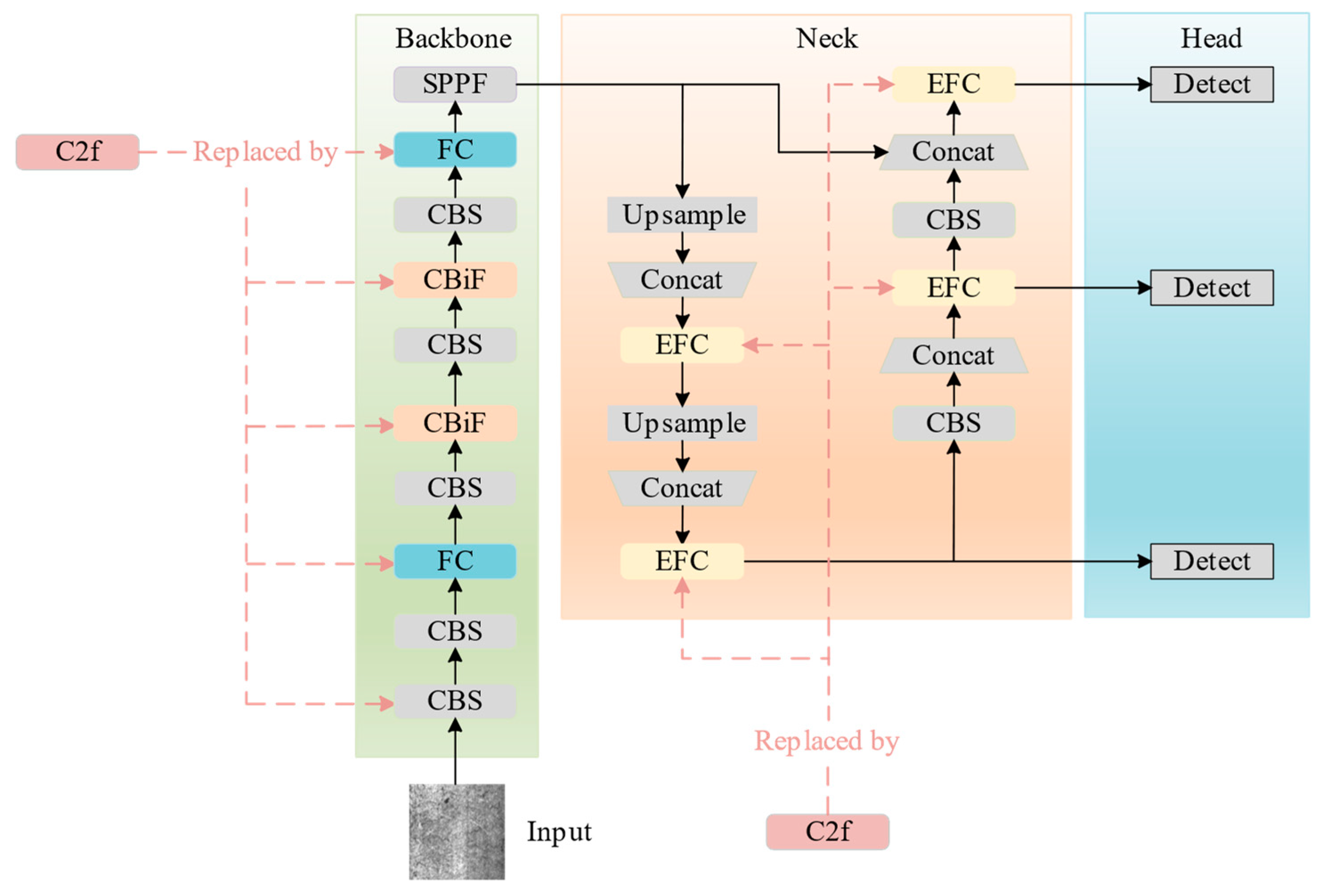
3.2. The Overall Framework of CFE-YOLOv8s
- The intermediate two C2f modules within the backbone are replaced with CBiF;
- The initial and final C2f modules within the backbone are supplanted with FC;
- All instances of C2f within the neck segment are substituted with EFC.
3.3. CBiF Module
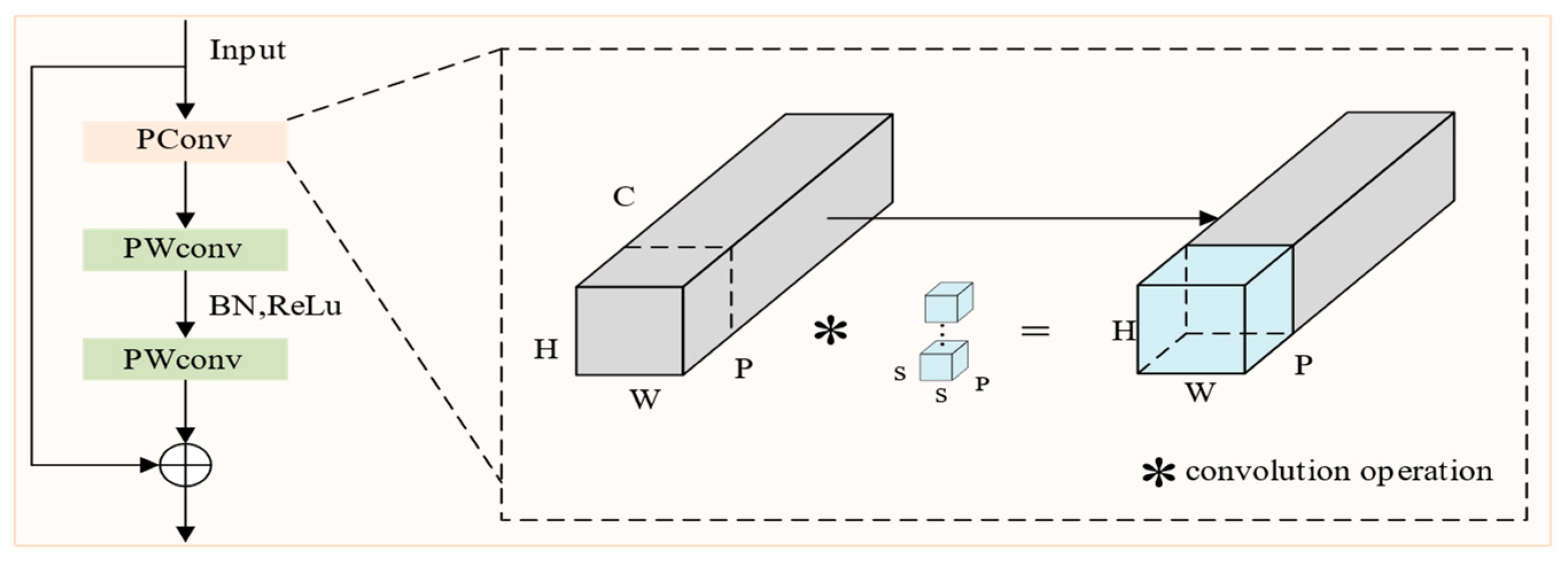
3.4. FC Module
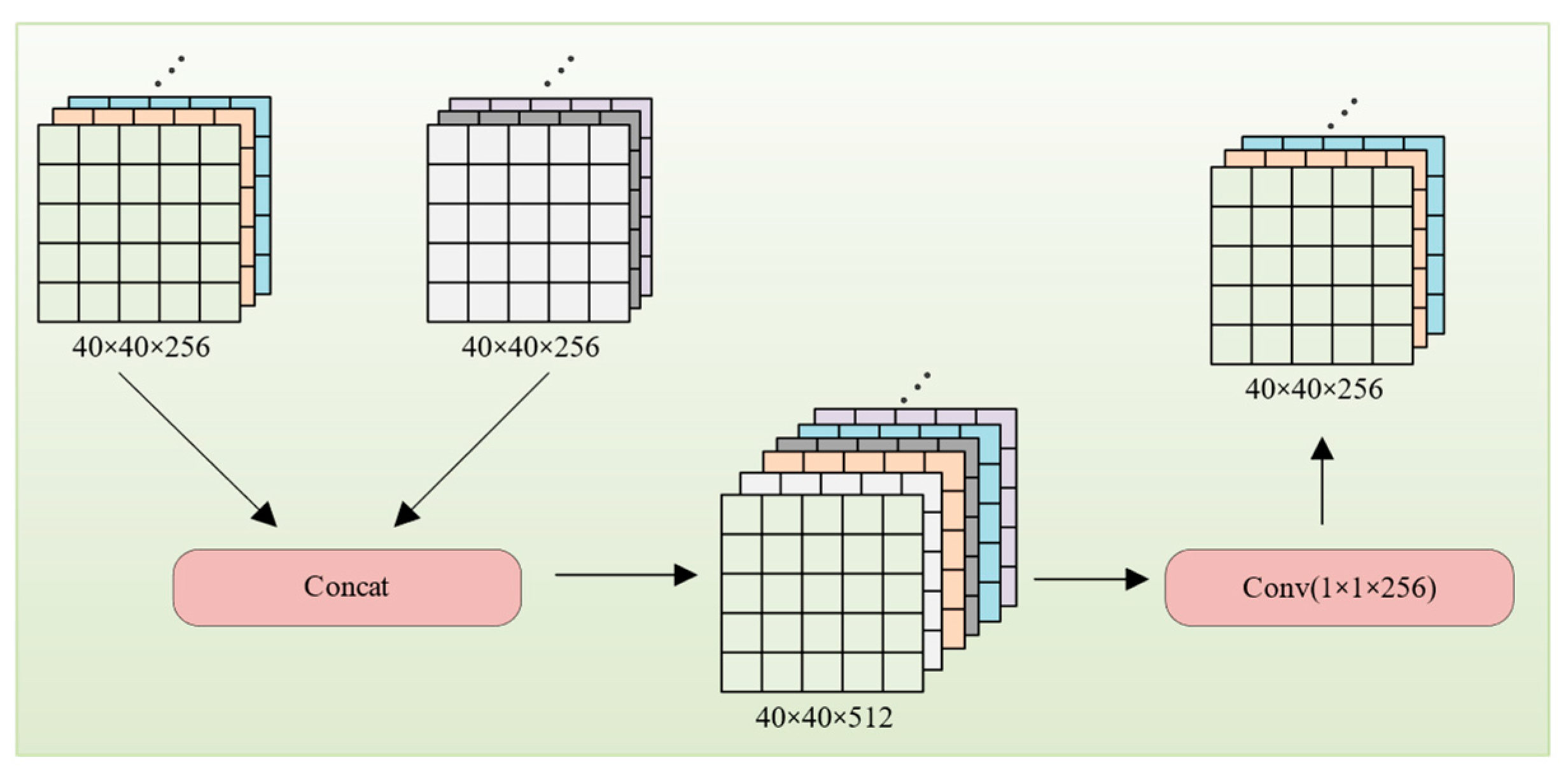
3.5. EFC Module
4. Experiments
4.1. Experimental Setup
4.2. Dataset
- NEU-DET [36]: This public dataset, which Northeastern University produced, includes 1800 photos that highlight six common surface flaws in hot-rolled steel strips. The six defect categories are the roll-in scale, pitted surface, inclusion, patches, crazing, and scratches.
- GC10-DET [37]: This publicly available dataset includes surface flaws on steel plates gathered in industrial settings. It includes ten defects: crescent gap, rolling pit, waist folding, crease, water spot, oil spot, inclusion, welding line, punched hole, and silk spot.
4.3. Experimental Metrics
4.4. Result and Analysis
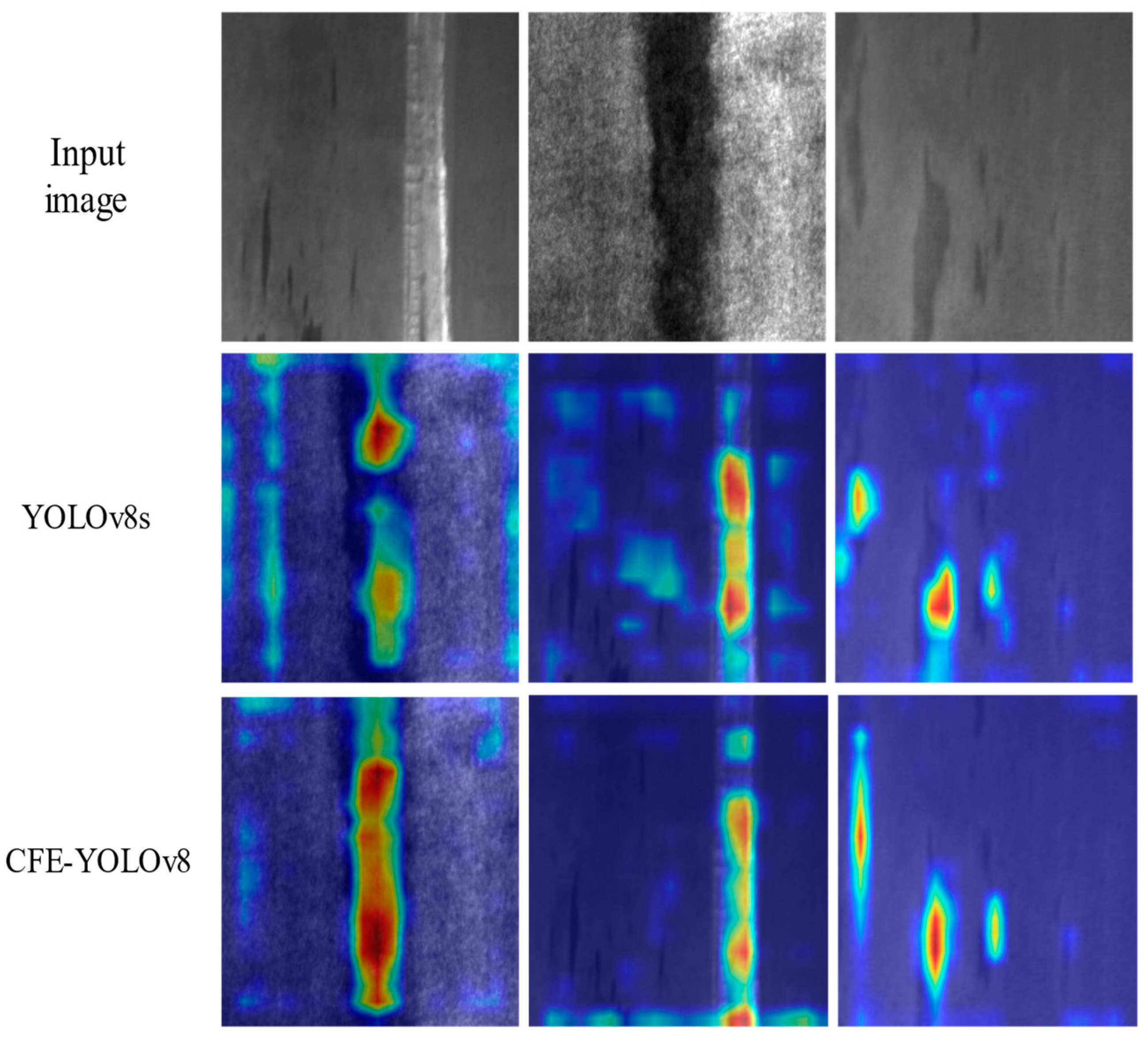
4.4.1. Experimental Analysis of CBiF Module
4.4.2. Ablation Study
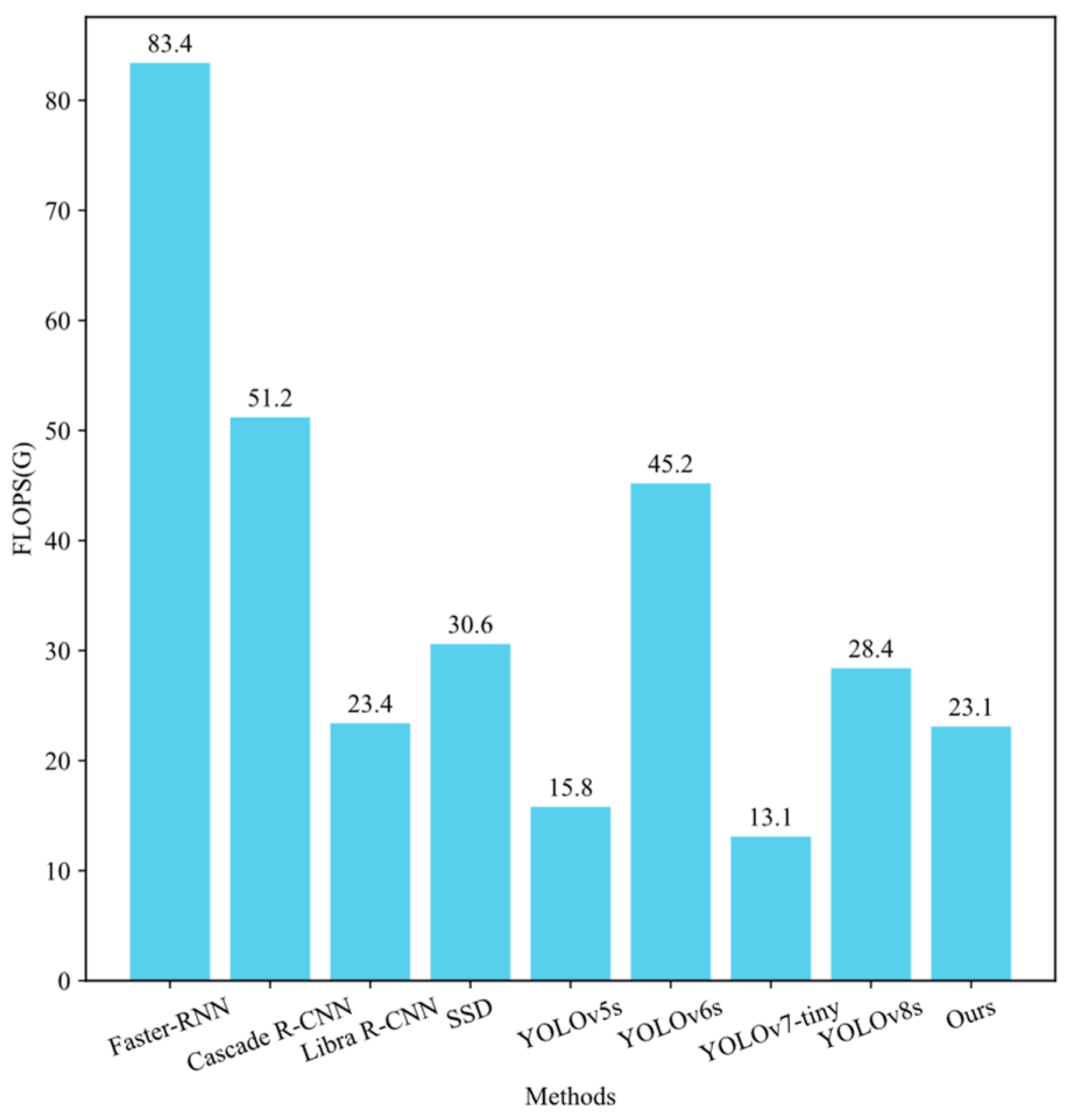
- Experiment one serves as the baseline, as shown in the first row of Table 3, with a mAP@0.5 of 74.7%, 11.1 M parameters, 28.4 G FLOPS, and an FPS of 89.6.
- Experiment two introduces CBiF into the backbone of YOLOv8s, as depicted in the second row of Table 3. The mAP@0.5 increases by 2.2%, the parameters decrease by 0.3 M, and the FLOPS decreases by 1.3 G. The improvement in mAP@0.5 suggests that the CBiF, constructed by combining CNN and Transformer, can effectively enhance the feature extraction capability of the backbone without increasing the parameter and computational complexity. However, adopting a Transformer layer in CBiF, utilizing self-attention mechanisms for global feature extraction and fully connected layers for processing self-attention outputs, decreases FPS by 6.4.
- Experiment three involves the simultaneous use of CBiF and FC in the backbone, as shown in the third row of Table 3. Despite a marginal decrease of 0.2% in mAP@0.5, the number of parameters and FLOPS decrease by 2.3 M and 4.4 G, respectively, and FPS increases by 5.9. The decrease in the number of parameters and computational complexity, along with the increase in FPS, validates that incorporating faster blocks in C2f can effectively aid in achieving a lightweight model and eliminate the adverse impact of CBiF on detection speed.
- Experiment four replaces all C2fs in the neck with EFC based on experiment three. As indicated in the fourth row of Table 3, the mAP@0.5 increases by 1.1%, while the FPS only decreases by 1.6. The improvement in mAP@0.5 suggests that enhancing feature fusion by adding attention mechanisms in the neck can improve detection accuracy without significantly slowing detection speed. Although there was a slight increase in the number of parameters and computational complexity after introducing EFC, they still decreased by 2.5 M and 5.3 G compared to the baseline.
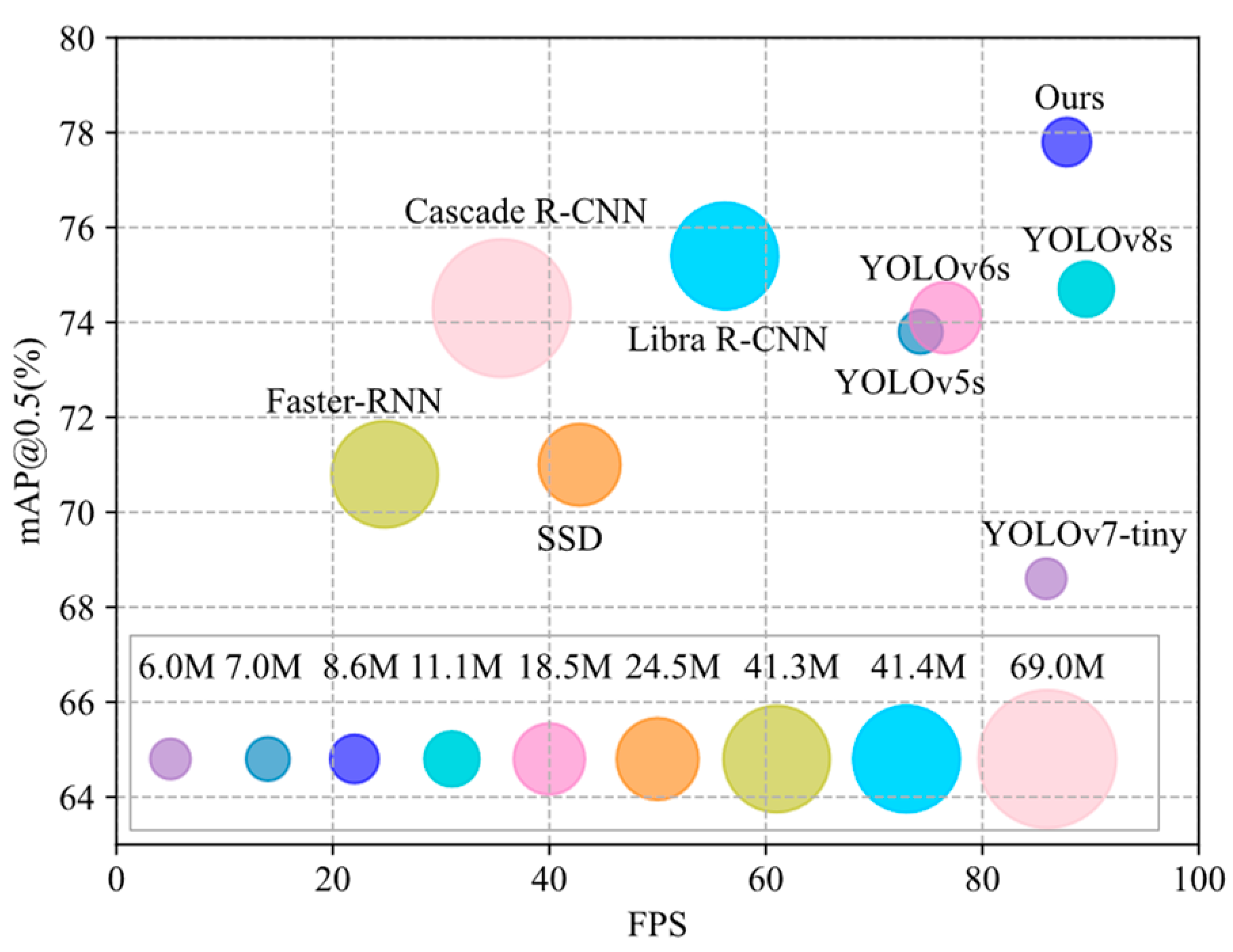
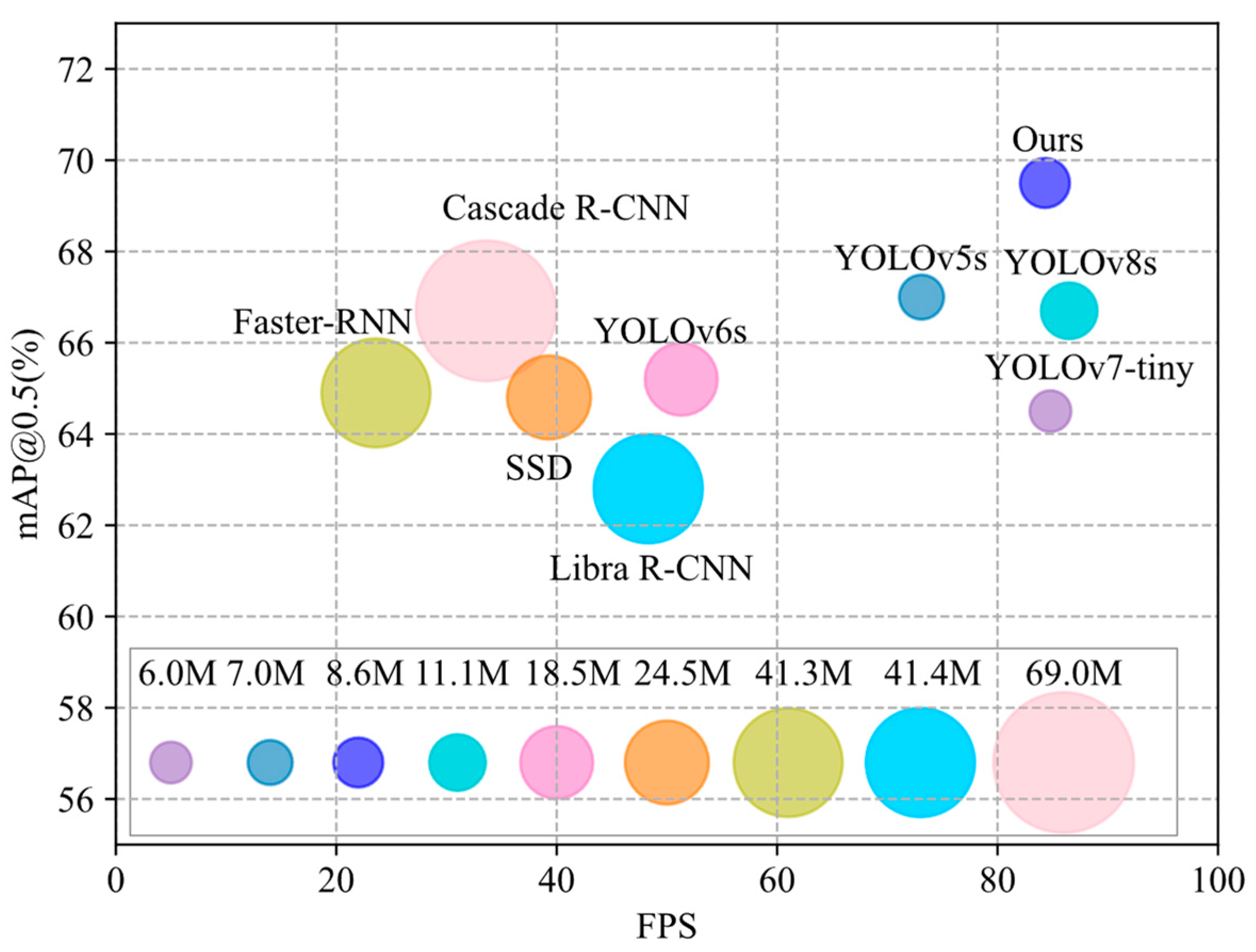
4.4.3. Comparisons with Other Methods on NEU-DET
4.4.4. Comparisons with Other Methods on GC10-DET
4.4.5. Comparison and Analysis of Detection Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Park, J.-K.; Kwon, B.-K.; Park, J.-H.; Kang, D.-J. Machine learning-based imaging system for surface defect inspection. Int. J. Precis. Eng. Manuf.-Green Technol. 2016, 3, 303–310. [Google Scholar] [CrossRef]
- Zhang, D.; Hao, X.; Wang, D.; Qin, C.; Zhao, B.; Liang, L.; Liu, W. An efficient lightweight convolutional neural network for industrial surface defect detection. Artif. Intell. Rev. 2023, 56, 10651–10677. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 25 July 2005; pp. 886–893. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Smadja, D.; Touboul, D.; Cohen, A.; Doveh, E.; Santhiago, M.R.; Mello, G.R.; Krueger, R.R.; Colin, J. Detection of subclinical keratoconus using an automated decision tree classification. Am. J. Ophthalmol. 2013, 156, 237–246. [Google Scholar] [CrossRef]
- Luo, Q.; Sun, Y.; Li, P.; Simpson, O.; Tian, L.; He, Y. Generalized completed local binary patterns for time-efficient steel surface defect classification. IEEE Trans. Instrum. Meas. 2018, 68, 667–679. [Google Scholar] [CrossRef]
- Zhang, J.W.; Wang, H.Y.; Tian, Y.; Liu, K. An accurate fuzzy measure-based detection method for various types of defects on strip steel surfaces. Comput. Ind. 2020, 122, 12. [Google Scholar] [CrossRef]
- Wang, J.; Li, Q.; Gan, J.; Yu, H.; Yang, X. Surface defect detection via entity sparsity pursuit with intrinsic priors. IEEE Trans. Ind. Inform. 2019, 16, 141–150. [Google Scholar] [CrossRef]
- Zhao, C.; Shu, X.; Yan, X.; Zuo, X.; Zhu, F. RDD-YOLO: A modified YOLO for detection of steel surface defects. Measurement 2023, 214, 112776. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wang, S.; Xia, X.; Ye, L.; Yang, B. Automatic detection and classification of steel surface defect using deep convolutional neural networks. Metals 2021, 11, 388. [Google Scholar] [CrossRef]
- Shi, X.; Zhou, S.; Tai, Y.; Wang, J.; Wu, S.; Liu, J.; Xu, K.; Peng, T.; Zhang, Z. An improved faster R-CNN for steel surface defect detection. In Proceedings of the 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP), Shanghai, China, 26–28 September 2022; pp. 1–5. [Google Scholar]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 2021, 5592878. [Google Scholar] [CrossRef]
- Yang, J.; Wang, W.; Lin, G.; Li, Q.; Sun, Y.; Sun, Y. Infrared thermal imaging-based crack detection using deep learning. IEEE Access 2019, 7, 182060–182077. [Google Scholar] [CrossRef]
- Wang, L.; Liu, X.; Ma, J.; Su, W.; Li, H. Real-time steel surface defect detection with improved multi-scale YOLO-v5. Processes 2023, 11, 1357. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. Msft-yolo: Improved yolov5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef]
- Zhou, C.; Lu, Z.; Lv, Z.; Meng, M.; Tan, Y.; Xia, K.; Liu, K.; Zuo, H. Metal surface defect detection based on improved YOLOv5. Sci. Rep. 2023, 13, 20803. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xin, Z. Efficient detection model of steel strip surface defects based on YOLO-V7. IEEE Access 2022, 10, 133936–133944. [Google Scholar] [CrossRef]
- Li, M.; Wang, H.; Wan, Z. Surface defect detection of steel strips based on improved YOLOv4. Comput. Electr. Eng. 2022, 102, 108208. [Google Scholar] [CrossRef]
- Wang, W.; Mi, C.; Wu, Z.; Lu, K.; Long, H.; Pan, B.; Li, D.; Zhang, J.; Chen, P.; Wang, B. A Real-Time Steel Surface Defect Detection Approach with High Accuracy. IEEE Trans. Instrum. Meas. 2022, 71, 5005610. [Google Scholar] [CrossRef]
- Yeung, C.-C.; Lam, K.-M. Efficient fused-attention model for steel surface defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 2510011. [Google Scholar] [CrossRef]
- Liu, R.; Huang, M.; Gao, Z.; Cao, Z.; Cao, P. MSC-DNet: An efficient detector with multi-scale context for defect detection on strip steel surface. Measurement 2023, 209, 112467. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 649–667. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 2019, 69, 1493–1504. [Google Scholar] [CrossRef]
- Lv, X.; Duan, F.; Jiang, J.-J.; Fu, X.; Gan, L. Deep metallic surface defect detection: The new benchmark and detection network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Learning rate | 0.02 |
| Decay strategy | cosine |
| Optimizer | SGD |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Total epochs | 200 |
| Close mosaic | 10 |
| Batch size | 16 |
| Dataset | Total Images | Defects Type | Size | Train Images | Validation Images |
|---|---|---|---|---|---|
| NEU-DET | 1800 | 6 | 200 × 200 | 1440 | 360 |
| GC10-DET | 2280 | 10 | 2048 × 1000 | 2052 | 228 |
| Methods | mAP@0.5 | Parameters/M | FLOPS/G | FPS | |
|---|---|---|---|---|---|
| Experiment one | Baseline (YOLOv8s) | 74.7 | 11.1 | 28.4 | 89.6 |
| Experiment two | +CBiF | 76.9 (+2.2) | 10.8 (−0.3) | 27.1 (−1.3) | 83.2 (−6.4) |
| Experiment three | +CBiF, FC | 76.7 (−0.2) | 8.5 (−2.3) | 22.7 (−4.4) | 89.1 (+5.9) |
| Experiment four | +CBiF, FC, EFC | 77.8 (+1.1) | 8.6 (+0.1) | 23.1 (+0.4) | 87.5 (−1.6) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Xie, Y.; Wu, J.; Huang, W.; Yan, H.; Wang, J.; Wang, B.; Yu, X.; Wu, Q.; Xie, F. CFE-YOLOv8s: Improved YOLOv8s for Steel Surface Defect Detection. Electronics 2024, 13, 2771. https://doi.org/10.3390/electronics13142771
Yang S, Xie Y, Wu J, Huang W, Yan H, Wang J, Wang B, Yu X, Wu Q, Xie F. CFE-YOLOv8s: Improved YOLOv8s for Steel Surface Defect Detection. Electronics. 2024; 13(14):2771. https://doi.org/10.3390/electronics13142771
Chicago/Turabian StyleYang, Shuxin, Yang Xie, Jianqing Wu, Weidong Huang, Hongsheng Yan, Jingyong Wang, Bi Wang, Xiangchun Yu, Qiang Wu, and Fei Xie. 2024. "CFE-YOLOv8s: Improved YOLOv8s for Steel Surface Defect Detection" Electronics 13, no. 14: 2771. https://doi.org/10.3390/electronics13142771
APA StyleYang, S., Xie, Y., Wu, J., Huang, W., Yan, H., Wang, J., Wang, B., Yu, X., Wu, Q., & Xie, F. (2024). CFE-YOLOv8s: Improved YOLOv8s for Steel Surface Defect Detection. Electronics, 13(14), 2771. https://doi.org/10.3390/electronics13142771