Abstract
Visual simultaneous localization and mapping (VSLAM) is pivotal for intelligent mobile robots. VSLAM systems can be used to identify scenes by obtaining massive amounts of redundant texture information from the environment. However, VSLAM faces a major challenge in dynamic low-light environments, in which the extraction of feature points is often difficult, leading to tracking failure with mobile robots. Therefore, we developed a method to improve the feature point extraction method used for VSLAM. We first used the contrast limited adaptive histogram equalization (CLAHE) method to increase the contrast in low-light images, allowing for the extraction of more feature points. Second, in order to increase the effectiveness of the extracted feature points, the redundant feature points were removed. We developed three conditions to filter the feature points. Finally, the proposed method was tested on popular datasets (e.g., TUM and OpenLORIS-Scene), and the results were compared with those of several traditional methods. The results of the experiments showed that the proposed method is feasible and highly robust in dynamic low-light environments.
1. Introduction
In the field of mobile robotics research, simultaneous localization and mapping (SLAM) is pivotal, particularly visual SLAM (VSLAM) [1,2]. VSLAM uses vision sensors, which are affordable, lightweight, and small. As a result, VSLAM has commonly been used in mobile robot research. Additionally, feature-based algorithms are used in VSLAM and mobile robotics because they are highly efficient and scalable. The common strategy for extracting features in VSLAM involves extracting feature points with a salient structure and the descriptor information from the image; this is known as the feature point method. Via the extraction of image feature points, a large amount of image information can be parsed, thus increasing information compression. Descriptors are extracted to describe the information surrounding the feature points, which is used for distinguishing and matching feature points.
In visual SLAM, the localization principle of the feature point method involves estimating the relative motion of the corresponding camera between the frames by extracting and matching the feature points of neighboring images. The extraction of image features directly affects the localization accuracy of a VSLAM system. The larger the number of accurately extracted feature points, the larger the number of matched feature points, and the higher the localization accuracy of mobile robotics. Therefore, the feature extraction algorithm plays a crucial role in SLAM localization accuracy. However, feature point extraction is affected by light due to the limitations of vision slam sensors. The number of feature points extracted under low-light conditions is substantially lower than that extracted under normal light. As such, the robustness of SLAM under low-light conditions still needs to be increased. The main hand-designed feature extraction methods are SIFT [3], SURF [4], FAST [5], ORB [6,7] and Shi-Tomas [8]. However, these methods cannot reliably extract and match feature points under low-light conditions. As such, many researchers have also used multi-feature fusion to improve the feature information and enhance the feature matching [9,10,11]. Reliably extracting feature points in low light environments is difficult whether using the most advanced hand-designed features or direct methods [12,13,14].
On the other hand, there is a trend of using deep learning to improve the robustness of SLAM systems [15,16,17]. However, most of the methods based on deep learning improve the localization accuracy of VSLAM by improving the extraction of descriptors or the training of matching models [18]. For example, Fast ORB-SLAM uses a two-stage keypoint matching algorithm and the UAM model to predict the initial keypoint correspondence [19]. This method uses the keypoints of neighboring frames to establish a reliable correspondence without descriptors, not only increasing keypoint matching accuracy but also reducing the computational burden required for searching for correspondences. Similarly, RTW-SLAM [20] is able to generate dense points and descriptors in low-textured scenes by modifying the LOFTR network. DFMNet uses dual-dimension feature modulation (DFM) to separately capture spatial and channel information [21]. This approach enables the adaptive combination of local features with more extensive contextual information, resulting in an enhanced feature representation that is more effective in dealing with challenging scenarios. However, these methods require training the model at an early stage, and obtaining the data to train the model is also a challenge for VSLAM. Much room for improvement remains in the extraction of feature points from low-light environments.
Therefore, considering the above problems and previous research, this paper proposes an improved feature point extraction algorithm for VSLAM when used in dynamic low-light environments. In order to avoid the failure of feature point detection due to inaccurate training model data, the proposed method in this paper is an improvement of the traditional feature detection method. Overall, feature point extraction is divided into two parts. The first part preprocesses the image. This part mainly addresses the lighting problem and prepares the image for the second part. The second part extracts and filters the feature points from the first part. The specific innovations of this algorithm are as follows:
- (1)
- Contrast-limited adaptive histogram equalization (CLAHE) is adopted in the preprocessing process to enhance the contrast in a frame, addressing the low-light problem.
- (2)
- The number of extracted feature points increases after the brightness is increased. In order to eliminate redundant feature points, three screening conditions are proposed.
- (a)
- The feature points in the dynamic region are removed to prevent interference from dynamic objects. The dynamic regions are detected using YOLOv8 during pre-processing.
- (b)
- The feature points are basically located where changes are obvious, such as on the edges. The second filter condition determines whether the feature points fall on the edge. The edge is detected using the phase congruency method during pre-processing.
- (c)
- The third screening condition involves non-local-maximum suppression to remove redundant points and retain the optimal points in a localized region.
The detailed arrangement of this article is organized as follows. Section 2 reviews the related work of extracting feature points. Section 3 provides a detailed description of the methodology proposed through two sections. Section 4 shows the experimental results. This section evaluates feature point performance, feature point matching performance and the trajectories by using different data and methods. Finally, Section 5 presents the conclusions.
2. Related Work
2.1. Traditional Method
The main feature detection algorithms commonly used in VSLAM are SIFT, SURF, FAST, ORB and so on. Each algorithm has its own advantages and disadvantages. The SIFT algorithm proposed by Lowe is used to construct the DOG pyramid by constructing the Gaussian pyramid of the image [3]. In the DOG pyramid, the extreme points that satisfy the conditions are used as feature points. Bay et al. proposed the SURF algorithm to improve the SIFT algorithm regarding the disadvantages of large computational volume [4]. Thus far, GPU acceleration has been required if SIFT features are used for VSLAM in real-time. The SURF algorithm uses a Hessian matrix to extract feature points, which reduces the time consumption of image down-sampling. However, the SIFT has high computational complexity, is extremely time-consuming and has poor real-time performance. Additionally, the SURF stability and real-time performance is also not high.
FAST is a corner point, which is mainly used to detect places where localized pixel grayscale changes significantly [5]. In other words, if the pixel gray value of the feature point differs too much from the pixel gray value of the neighborhood, then the point is a corner point. FAST is characterized by speed, but it does not have scale and rotation invariance. ORB (Oriented FAST and Rotated BRIEF) improves on the original FAST algorithm [15,16,17]. Compared with the original FAST, the principal directions of the feature points are computed in the ORB. And then a BRIEF (Binary Robust Independent Elementary Feature) description is extracted after obtaining the FAST corners. ORB feature extraction is currently very representative of factual image features. ORB not only improves the problem that FAST corner points are not directional but also employs the extremely fast binary descriptor BRIEF so that the whole process of image features extraction is greatly accelerated. However, the ORB extraction effect is still not good in low-light environments. Thus, in this paper, we propose an improved extraction method for visual image feature points based on the traditional ORB algorithm.
2.2. Deep Learning Method
The process of extracting feature points through deep learning is obtained through training and inference of a convolutional neural network, rather than relying on hand-designed algorithms. In recent years, the improvement of feature points based on deep learning has been divided into two aspects: the improvement of corner point extraction and improvement of descriptors. For example, D2-net [22], R2D2 [23], SuperPoint [24] and SuperGlue [25] are all improvements in descriptor extraction. In general, extraction of feature points involves firstly extracting corner points, and then the descriptor information is extracted based on these corner points. Therefore, the detection of corner points is primary. In this paper, we focus on the detection of corner points. HE-SLAM has amalgamated Histogram Equalization (HE) with ORB feature extraction methodologies to extract feature points. Histogram Equalization (HE) can enhance image contrast, thereby facilitating the extraction of valid feature points in images plagued by low contrast [26]. This amalgamation marks a significant stride over traditional ORB-SLAM2, demonstrating heightened robustness in adverse environmental conditions. Nonetheless, the susceptibility of HE to background noise emerges as a conspicuous limitation, potentially undermining the system’s robustness. To improve the robustness of the HE-SLAM, Yang et al. adopted the Contrast-Limited Adaptive Histogram Equalization (CLAHE) algorithm to the ORB-SLAM2 framework [27]. However, the author does not consider that redundant points will be generated after the adaptive histogram equalization algorithm. Parallelly, Gu, Q. et al. proposed Dim light Robust Monocular SLAM (DRMS) [28]. DRMS is a new method of image preprocessing applied to Monocular SLAM systems. The method extracts feature points by combining the linear transformation and CLAHE. However, this method is computationally extensive. Inspired by the above methods, this paper proposes an improved feature point extraction algorithm of VSLAM in low-light dynamic environments.
3. Methodology
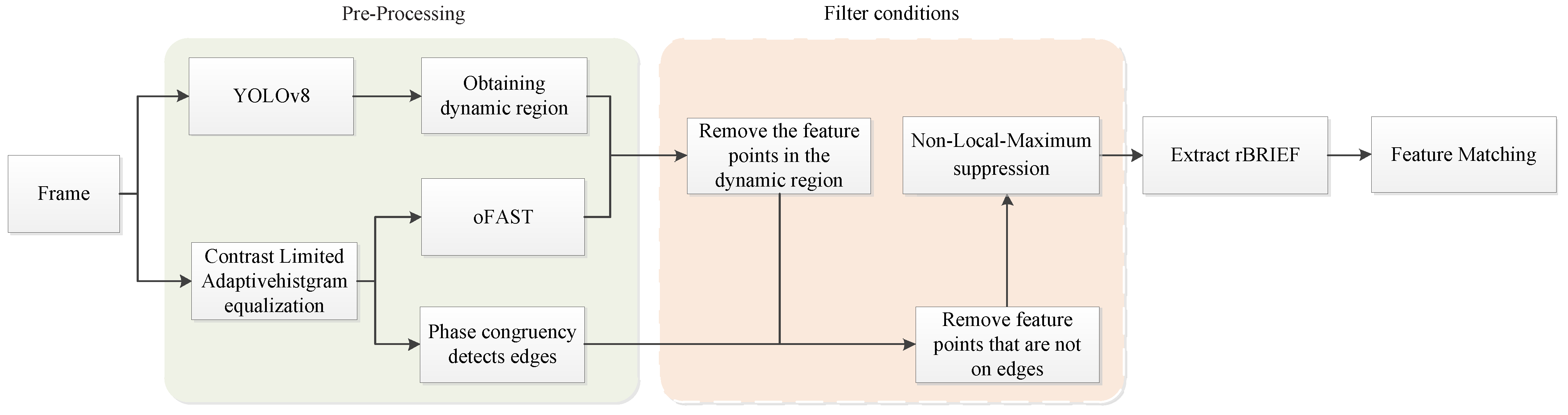
Our algorithm is based on ORB feature points. In this section, we first introduce the pre-processing of the original frame. The most important part of the pre-processing is that we use the CLAHE to enhance the contrast in a frame, addressing the low-light problem. Meanwhile, the YOLOv8 object detection algorithm and the phase congruency edge extraction technique were employed, which primarily aim to prepare for the subsequent screening of feature points. Then, the filter conditions of feature points are introduced in detail. The main purpose of screening feature points is to filter the redundant points generated by using CLAHE technique in the pre-processing process. The design framework of the method in this paper is shown in Figure 1.
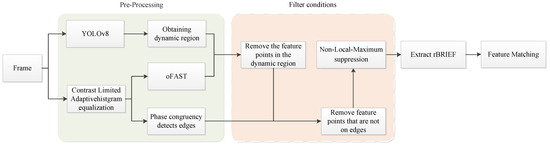
Figure 1.
The framework of the method.
3.1. Pre-Processing
3.1.1. YOLOv8
In this study, we decided to introduce the YOLOv8n network for semantic segmentation to obtain dynamic regions. YOLOv8 is a robust and efficient model for detecting target objects in images. The YOLOv8 model was optimized and upgraded on the basis of YOLOv5, including n, s, m, l, and x, for five versions in total. The network structure of YOLOv8 is mainly composed of three layers: the backbone feature extraction network, feature fusion, and detection header layers. The lightweight YOLOv8n object detection model uses a lighter C2F module instead of the original C3 module in the backbone feature extraction network layer, and the downsampling layer in the feature fusion layer is reduced. Additionally, the feature fusion network in the YOLOv8n model is composed of two parts: the feature pyramid network (FPN) and path aggregation (PAN). As such, the YOLOv8n model is more accurate and provides better real-time performance than other models.
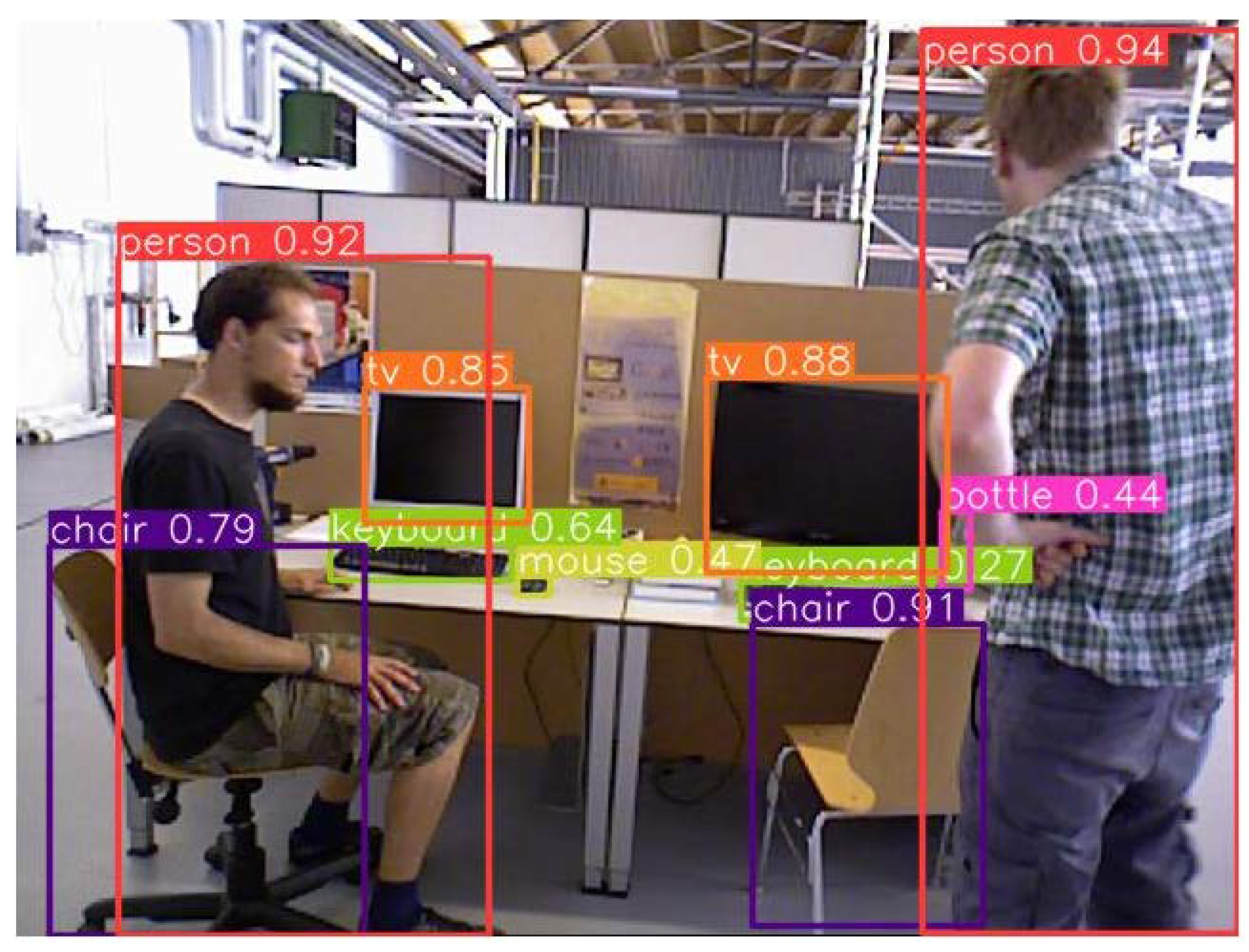
In order to segment the images more accurately, we trained the YOLOv8n model with the Microsoft Common Objects in Context (MS COCO) dataset [29]. The classes of MS COCO are more than 80 different objects, which basically fulfills the use of VSLAM in dynamic environments. The TUM image is semantically segmented by YOLOv8n, and the result is shown in Figure 2. A simple classification was made according to the motion states of different categories of objects in daily life. The classification results are shown in Table 1. The detection results show that YOLOv8n can not only successfully segment large objects (e.g., people, chairs, etc.) but also successfully detect relatively small objects (e.g., keyboards, mice, books, etc.). Therefore, the semantic segmentation of targets using the YOLOv8n method is consistent with the needs of VSLAM applications.
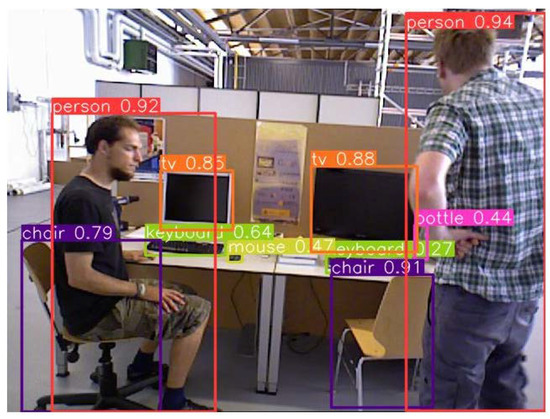
Figure 2.
The result of the object detection using YOLOv8n.

Table 1.
Classification of the dynamic properties of common objects in life.
3.1.2. Contrast-Limited Adaptive Histogram Equalization
To solve the low-light problem, contrast-limited adaptive histogram equalization (CLAHE) [30] is adopted in the preprocessing stage to enhance the contrast in a frame. CLAHE increases the clarity of the textures and structures inside the frame. The difference between CLAHE and AHE is contrast limitation, which prevents AHE from causing noise amplification problems [31,32].
During the experiment, AHE and CLAHE were used separately to preprocess the images. The results are shown in Figure 3. Figure 3a depicts an original low-light image from the rgbd_freiburg3_walking_rpy series. The results of applying AHE and CLAHE to the original images are shown in Figure 3b,c, respectively. The image brightness was increased by both methods, but the details were distorted when using the AHE method. For example, the image in Figure 3c is more detailed than that in Figure 3b in the background area. The reason for this is that the two methods work on different principles. The AHE method performs histogram enhancement for each pixel by calculating a transform function for each pixel neighborhood. This method works well for images that have a uniform pixel distribution, but enhancement is insufficient for images that contain notably brighter or darker areas. The largest difference between AHE and CLAHE is that the latter limits contrast, which is also applied to global histogram equalization.

Figure 3.
The processing results of AHE and CLAHE methods. (a) The original image. (b) The results of AHE on the original images. (c) The results of CLAHE on the original images.
3.1.3. Phase Concurrency Edge Detection
For edge detection, an algorithm is used to extract the boundary line between the object and the background in an image. An edge is defined as the boundary of a region in an image where the gray level sharply changes. This is consistent with our requirements for extracting feature points. Therefore, one of the conditions determines whether the feature points are on an edge. The theoretical basis of traditional edge detection methods is the change in grayscale. Additionally, the law of directional derivative change is used to localize edges. The common feature among these traditional methods is that neighborhood edges of the image are constructed based on pixels. For phase congruency edge detection, the edge features in the image are expressed at the phase where the Fourier wave components overlap the most. The phase congruency method has two main advantages: detecting a large range of features and being invariant to localized smooth illumination variations.
Therefore, in this study, the phase coherence method was used to detect the edges of the image. The edge detection result is shown in Figure 4a. We also extracted image edges using other methods to demonstrate the superiority of the proposed phase coherence method. For example, Figure 4b–d depict the results of experiments by Roberts, Sobel, and Prewitt, respectively. In addition, we combined a Gaussian filter and the Canny method to extract the edge, with the results shown in Figure 4e,f. The analysis of the results showed that the outcomes produced via Canny and Gaussian filtering for edge detection were better. However, some details were not detected. The proposed method better preserved the edge information of the original. Thus, image edges can be extracted using the phase coherence method.

Figure 4.
The results of edge detection using different methods. (a) The edge detection result of phase congruency. (b–f) The edge detection result of Roberts, Sobel, prewitt, Gaussian filter and Canny.
3.2. Feature Points Filtering
ORB-SLAM is a mainstream solution in VSLAM applications, where ORB feature point extraction consists of two steps: oriented FAST (oFAST) feature point detection and rotation BRIEF (rBRIEF) descriptor computation. In this study, traditional ORB extraction was adopted after the above pre-processing. We first extracted the oFAST feature points and then applied rBRIEF to the feature points. The contrast of the frame can be increased after CLAHE pretreatment. However, a large number of feature points were extracted from the frame. A comparison of the results of feature point detection is shown in Figure 5. Figure 5a,b show the feature point results for the original image and after CLAHE pretreatment, respectively. The experimental results showed that the results of CLAHE were substantially better than those obtained using the original images. However, redundant feature points were also generated.

Figure 5.
The result of feature point detection. (a) The detection results of feature points on original image. (b) The detection results of feature points after CLAHE pretreatment.
Redundant feature points not only increase the computational effort required for feature matching but also interfere with matching. Therefore, some screening conditions were proposed to eliminate redundant feature points after extracting the FAST feature points to increase the matching efficiency and odometer accuracy.
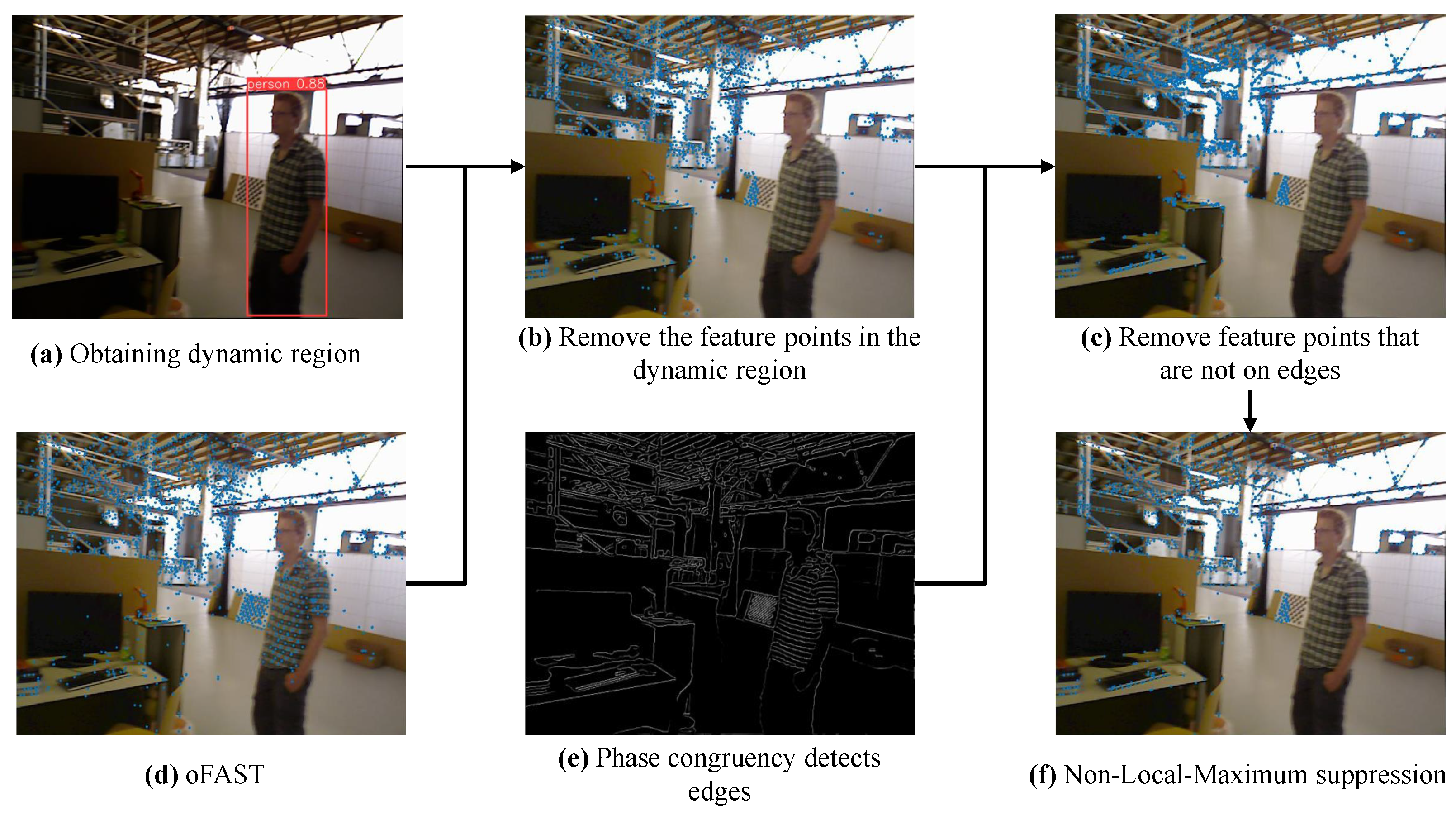
The process of filtering feature points is shown in Figure 6. The filter conditions are as follows:
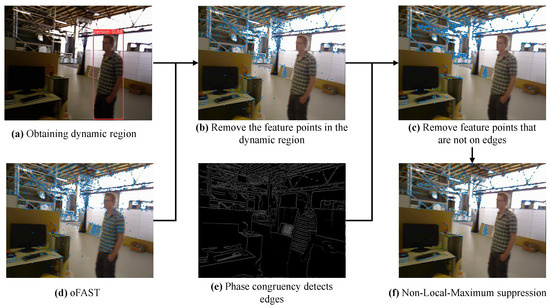
Figure 6.
The filter process of feature points.
- (1)
- Remove the feature points in the dynamic region.The feature points on dynamic objects can interfere with the localization of mobile robots. Therefore, the first screening involves removing the feature points in the dynamic region. The dynamic regions are detected using YOLOv8n during the pre-processing stage. After extracting the oFAST feature points, the feature points in the dynamic region are removed by combining them with the results of object detection (Figure 6a). The results are shown in Figure 6b.
- (2)
- Determine whether the FAST feature points fall on the edge.In general, the gray values of the pixel point p will be compared to 16 pixel points in the surrounding neighborhood. If the difference is large, this pixel point p is a FAST point. Therefore, the FAST corner points are generally in places where changes are obvious, such as on the edges. Therefore, one of the screening conditions is to determine whether the FAST points are on the edge of the phase coherence extraction. We combined the results of phase concurrency edge detection (Figure 6e) to retain only the feature points on the edge, and the results are shown in Figure 6c.
- (3)
- Non-Local-Maximum suppression.Non-local-maximum suppression is used as the third screening condition to obtain the best feature. During non-local-maximum suppression, we choose a detection box of size 3 to traverse the FAST feature points. Then, the FAST feature point with the largest response value in the detection box is reserved. This screening condition not only preserves the best point in the detection box but also ensures spare FAST feature points. The final results are shown in Figure 6f.
After passing the above three screening conditions, the problem is avoided in which the number of feature points increases after CLAHE. The BRIEFs of the feature points are extracted after screening, which also reduces the computational effort required to extract feature points. The experimental results are shown in Figure 7. Figure 7a shows the feature points obtained after screening with the above three conditions. Figure 7b compares the feature points obtained with the proposed (yellow points) and original (red points) methods. The experimental results showed that the proposed method is substantially better than the original method.

Figure 7.
The experimental results. (a) The result of feature points after screening by the above three conditions; (b) the comparison of figure point between the proposed method and the original method. The red points are the ORB feature points extracted from the original graph; the yellow points are the feature points extracted by the proposed method.
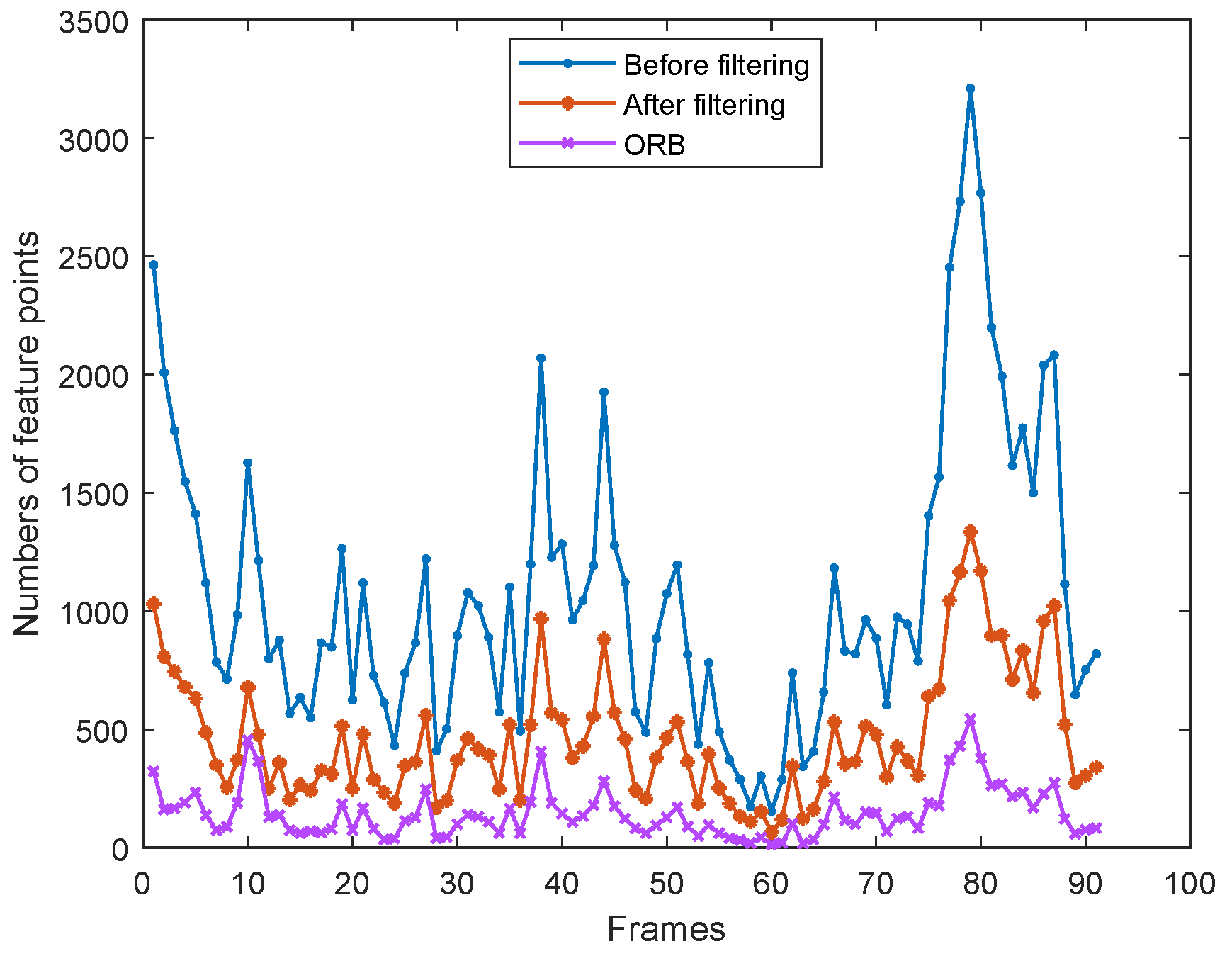
To better illustrate the importance of feature point filtering, we have counted the number of feature points before and after filtering on the ‘fre3_w_rpy’ dataset from the TUM datasets. The dataset contains a total of 910 frames. Therefore, in order to facilitate the plotting of the curve graph, we take the average of the number of feature points every 10 frames. The statistical results of average values are shown in Figure 8. From Figure 8, it can be seen that the original ORB method extracts a small number of feature points in low-light dynamic environments. The highest number of feature points was extracted after improving the contrast by CLAHE. While the number of feature points after filtering is significantly reduced, it is still better than the original ORB results. Therefore, it is necessary to filter feature points, which not only ensures the quality of the feature points but also reduces the computation time at a later stage.
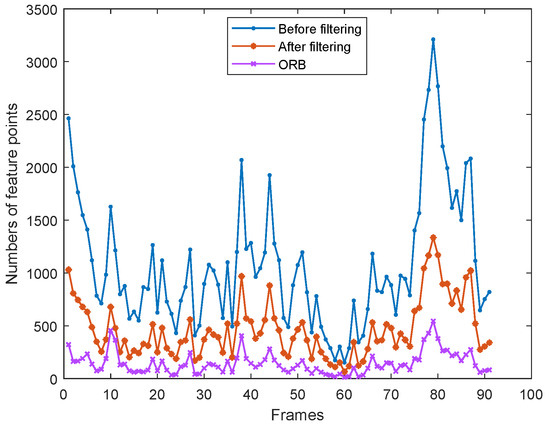
Figure 8.
Comparison of the number of feature points before and after filtering.
4. Experimental
4.1. Experimental Datasets
In this study, the effect of the proposed algorithm was evaluated using the Technical University of Munich (TUM) RGB-D datasets and OpenLORIS-Scene datasets. The TUM datasets were recorded at full frame rate (30 Hz) using a Microsoft Kinect sensor, which has a high-accuracy motion capture system. The TUM datasets also provided a variety of data information, including RGB-D images, depth images and ground-truth trajectories. Therefore, the TUM datasets are the most used SLAM data in the literature. In addition, the RGB-D images of TUM include high and low dynamic office sequences [33,34]. This paper mainly focuses on the low-light dynamic environment, so the data of “rgbd_dataset_freiburg3_walking_rpy” series in TUM are mainly used during the experiment. In particular, a total of 60 frames from 151 to 210 of “rgbd_dataset_freiburg3_ walking_rpy” were selected for the experiment. To differentiate, we will simply refer to “rgbd_dataset_freiburg3_walking_rpy” as “fre3_w_rpy” and the selected 60 frames as “fre3_w_rpy_60”.
OpenLORIS-Scene datasets are new datasets designed and published by Xuesong Shi et al. [35]. On the one hand, these datasets not only provide multiple experimental scenes, including office, cafe, supermarket, etc., but also provide richer scene information, which includes RGB-D, depth map and real trajectory. On the other hand, the datasets contain images with significant environmental changes in low light. Therefore, OpenLORIS-Scene datasets have many challenging factors, which is also in line with the research context of this paper. For these reasons, we evaluated the proposed algorithm mainly using data from the Office-7 series of the OpenLORIS-Scene datasets. We specifically chose sequences containing dynamic objects (persons) in a dimly lit university office from these two datasets. The Office-7 series has a total of 1140 images. There are 76 images containing dynamic people. The images from the TUM RGBD datasets and OpenLORIS-Scene datasets are shown in Figure 9.

Figure 9.
Experimental datasets. (a) The image from the TUM RGBD datasets; (b) the image from the OpenLORIS-Scene datasets.
4.2. Feature Point Performance
According to the constraints of state estimation, the SLAM system outputs accurate positional estimation data only when it matches a sufficient number of interior points. And when the number of interior points is too small, the VSLAM system will fail to complete the positional estimation. Therefore, the number and accuracy of feature points extracted will be related to the positioning accuracy of the mobile robot.
4.2.1. Feature Points Detection Performance
The efficacy of feature point detection is crucial, as it directly influences the matching rate of features and the localization precision of mobile robots. Notably, low-light environments pose a substantial challenge to the accurate extraction of feature points. Therefore, to validate the efficacy of a system regarding feature point extraction in a low-light environment, we conducted feature point detection experiments. We used four different methods, including FAST, SURF, SIFT and the proposed method, respectively, and applied them to the dataset fre3_w_rpy_60 to detect the feature points. The detection results are shown in Figure 10. The results depicted in the figure clearly demonstrate that the method proposed in this study achieves superior feature detection performance. It also proves that the proposed method is feasible.

Figure 10.
Feature point detection results by FAST, SURF, SIFT and Ours.
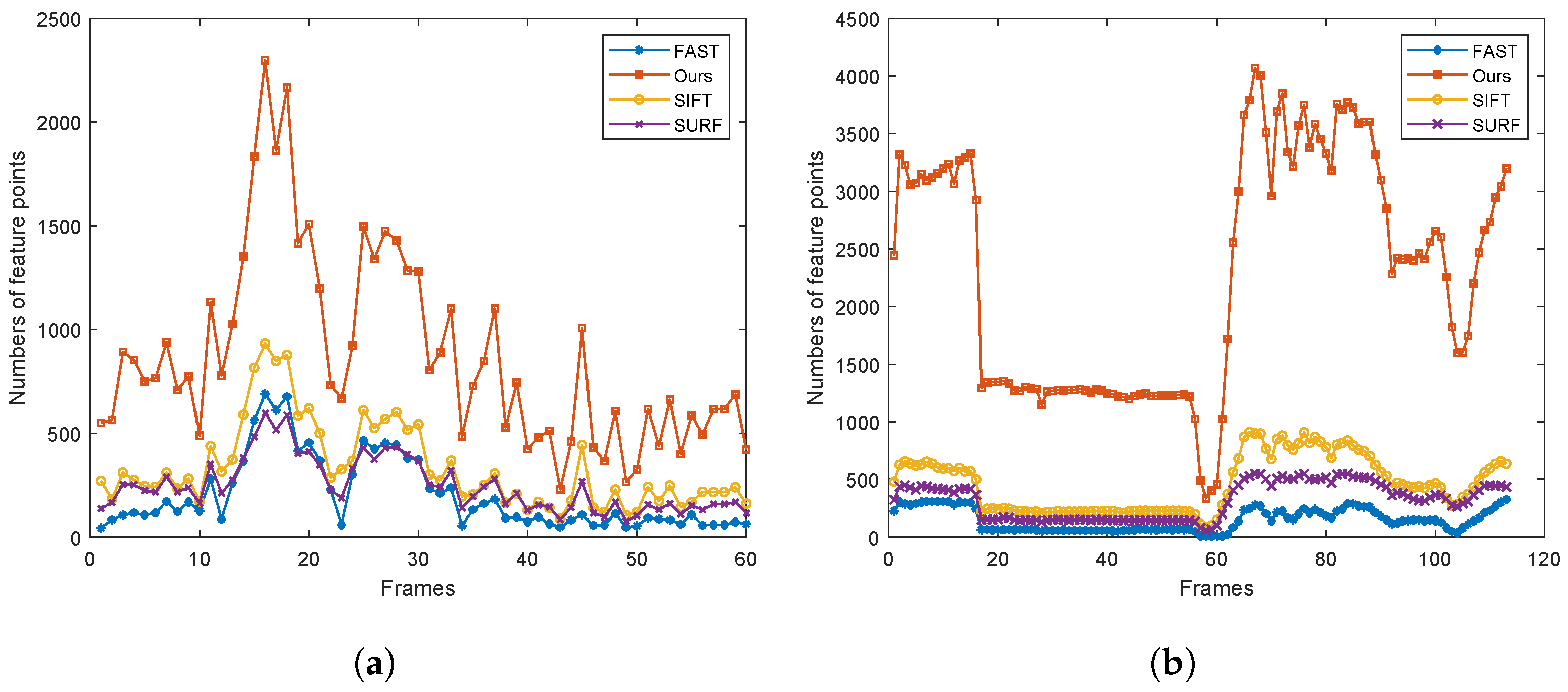
In addition, four methods were also used to detect feature points of Office-7 data. The number of feature points in each frame of fre3_w_rpy_60 and Office-7 were counted, respectively. The data for fre3_w_rpy_60 contain 60 frames, and the statistical results are shown in Figure 11a. The data for Office-7 contains 1141 frames. In order to show the results easily, we recorded the average value every 10 frames. Therefore, the results shown in Figure 11b contain 114 data points. It can be seen that the feature points extracted by FAST are the lowest in the low-light environment, followed by SURF. And the results of the proposed method are optimal in both sets of data.
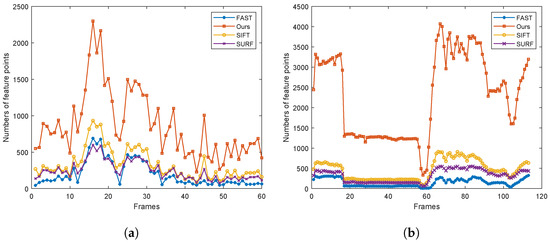
Figure 11.
The number of feature points. (a) The number of feature points in fre3_w_rpy_60; (b) the number of feature points in Office-7.
4.2.2. Feature Point Matching Performance
Feature matching performance is also one of the criteria for evaluating feature point detection. We chose the K-Nearest Neighbor to match the images. The matching results are shown in Figure 12. Figure 12a–d show the matching results of FAST, SURF, SIFT and Ours, respectively. The image on the left is the current frame image, and the image on the right is the 20th frame behind the current frame image. It can be seen that the matching results of the four methods on brighter regions are all better in Figure 12. However, the number of feature points extracted by the FAST and SURF methods is less in low-light regions. Although the number of feature points extracted by the SIFT method is more than FAST and SURF, there are also many wrong feature point matches. The method proposed in this paper has the largest number of feature points detected, but the smallest number of false matches. It can be seen that the method proposed in this paper not only improves the number of feature points but also increases the correct matching rate.

Figure 12.
The matching results of different methods. The red and green points in the figure represent the feature points of the current frame and the 20th frame respectively. And the yellow lines represent the matching results.
To better validate the experimental results, we use the correct matching rate to measure the experimental results. The total number of feature points m and the number of correctly matched feature points n are obtained by manual statistics. Then the formula is used to calculate the correct matching rate. The correct matching rates are shown in Table 2. The analysis from Table 2 shows that the correct matching rate of the proposed method is optimal in two different datasets. Therefore, the statistics of the correct matching rate further prove that the proposed method is superior in low-light dynamic environments.
Table 2.
The correct matching rate of four different methods.
In summary, we have conducted a series of tests by applying FAST, SURF, SIFT, and the novel method proposed to different datasets. We have focused on the number of feature points extracted and the success rate of feature matching. The experimental results show that under low-light dynamic environments, compared to the other three techniques, our new method can more effectively capture a greater number of feature points. This enhancement not only increases the number of feature points but also indirectly improves the success rate of feature matching. Furthermore, due to the selection of feature points in our method, the accuracy rate in the matching process has been further improved. Therefore, it is evident that our new method not only proves feasible but also demonstrates significant superiority in low-light dynamic environments.
4.3. Scene Testing
In this study, to validate the effectiveness of the proposed method, we performed experiments in real scenarios. During the experiment, the Intel RealSense D435I depth camera was used as the visual sensor for data acquisition. This camera adopts the latest depth-sensing technology, which not only performs high-precision depth measurements in indoor and outdoor environments but also supports application scenarios such as dynamic object tracking and gesture recognition.
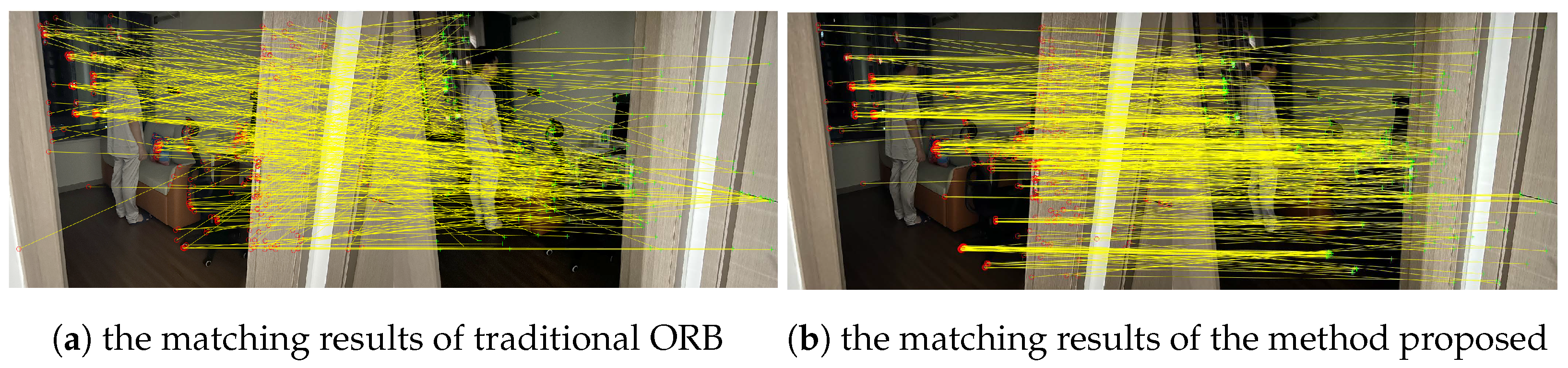
We first used a depth camera for image acquisition and then employed the method proposed in this paper for feature recognition and feature matching, with the results shown in Figure 13. Figure 13a represents the feature points extracted and matching results with traditional ORB, and Figure 13b represents the results of the method proposed in this paper. To better illustrate the superiority of the method proposed in this paper, we statistically counted the correct matching rate in the figures manually. Among them, traditional ORB matched 328 feature points with a correct matching rate of 15.3%. The method proposed in this paper matched 819 feature points with a correct matching rate of 69.4%.
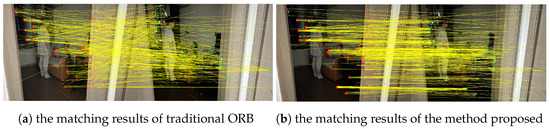
Figure 13.
The matching results of different methods. The red and green points in the figure represent the feature points of the current frame and the matching frame respectively. And the yellow lines represent the matching results.
During the experiment, the proposed method was time-consuming in the pre-processing stage, resulting in poor real-time performance. However, from the final experimental results, the method proposed in this paper can improve the extraction of feature points in low-light environments and increase the feature matching rate.
4.4. Vslam Performance
To verify the effectiveness of the method proposed in VSLAM, we tested the fre3_w_rpy datasets and Office-7 datasets using different methods, respectively. We provide the values of RMSE (Root Mean Square Error), mean error, median error, and S.D. (Standard Deviation) for ATE (Absolute Trajectory Error). Among these, RMSE and S.D. are of more interest because they better represent the robustness and stability of the system. The test results are shown in Table 3. The trajectory error is large because the traditional method cannot extract the feature points effectively in the low-light environment. The proposed method improves the extraction quality of feature points, so the trajectory error is finally reduced.
Table 3.
Results of Metrics—Absolute Trajectory Error (ATE).
5. Conclusions
In this paper, an improved feature point extraction algorithm of VSLAM was proposed. We aimed to more reliably extract feature points from frames in dynamic low-light environments compared with other VSLAM methods. To realize this goal, the contrast of the frames was firstly increased using CLAHE. Secondly, in order to prevent the interference of dynamic feature points, we adopted YOLOv8 for object detection and removed the feature points in the dynamic region. Then, we filtered the feature points by edge detection and non-maximum suppression. Finally, we performed some experiments on public datasets (i.e., fre3_w_rpy (TUM) and Office-7 (OpenLORIS-Scene)) to validate our proposed method. The results show that the proposed method can accurately extract feature points and increase the matching rate. Moreover, the localization performance was also effectively improved.
However, we found that there are still some mismatches in feature matching. This is because the core of feature matching mainly depends on the descriptor of the feature point and the matching algorithm. Furthermore, the proposed method only improves the extraction quality of feature points and does not change the extraction method of descriptors and the matching algorithm. The improvement of the quality of feature points can improve the matching rate appropriately but cannot completely avoid the phenomenon of mismatching. Therefore, in future experiments, we will improve the matching algorithm to reduce the mismatching problem and, finally, improve the positioning accuracy. In addition, the pre-processing process involves the steps of image processing, which improves the detection and matching of feature points but also affects the real-time performance of the method. Therefore, improving the real-time performance of the method is also something we need to improve in the future.
Author Contributions
Conceptualization, Y.W. and Y.Z.; methodology, Y.W.; software, Y.W.; validation, L.H., G.G. and W.W.; formal analysis, S.T.; investigation, G.G.; resources, Y.W.; data curation, W.W.; writing—original draft preparation, Y.W.; writing—review and editing, Y.W.; visualization, L.H.; supervision, Y.Z.; project administration, Y.Z.; funding acquisition, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Doctoral Talent Train Project of Chongqing University of Posts and Telecommunications (grant number BYJS202115).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Shi, J. Good features to track. In Proceedings of the 1994 Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 593–600. [Google Scholar]
- Zhou, W.; Zhou, R. Vision SLAM algorithm for wheeled robots integrating multiple sensors. PLoS ONE 2024, 19, e0301189. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Shang, G.; Hu, K.; Zhou, C.; Wang, X.; Fang, G.; Ji, A. A Monocular-Visual SLAM System with Semantic and Optical-Flow Fusion for Indoor Dynamic Environments. Micromachines 2022, 13, 2006. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, Y.; Chen, P. TSG-SLAM: SLAM Employing Tight Coupling of Instance Segmentation and Geometric Constraints in Complex Dynamic Environments. Sensors 2023, 23, 9807. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2014; pp. 834–849. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]
- Qiao, C.; Bai, T.; Xiang, Z.; Qian, Q.; Bi, Y. Superline: A robust line segment feature for visual slam. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 5664–5670. [Google Scholar]
- Li, Y.; Brasch, N.; Wang, Y.; Navab, N.; Tombari, F. Structure-slam: Low-drift monocular slam in indoor environments. IEEE Robot. Autom. Lett. 2020, 5, 6583–6590. [Google Scholar] [CrossRef]
- Yang, Z.; He, Y.; Zhao, K.; Lang, Q.; Duan, H.; Xiong, Y.; Zhang, D. Research on Inter-Frame Feature Mismatch Removal Method of VSLAM in Dynamic Scenes. Sensors 2024, 24, 1007. [Google Scholar] [CrossRef] [PubMed]
- Fu, Q.; Yu, H.; Wang, X.; Yang, Z.; He, Y.; Zhang, H.; Mian, A. Fast ORB-SLAM without keypoint descriptors. IEEE Trans. Image Process. 2021, 31, 1433–1446. [Google Scholar] [CrossRef] [PubMed]
- Peng, Q.; Xiang, Z.; Fan, Y.; Zhao, T.; Zhao, X. RWT-SLAM: Robust visual SLAM for highly weak-textured environments. arXiv 2022, arXiv:2207.03539. [Google Scholar]
- Lin, S.; Zhuo, X.; Qi, B. Accuracy and efficiency stereo matching network with adaptive feature modulation. PLoS ONE 2024, 19, e0301093. [Google Scholar] [CrossRef] [PubMed]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint detection and description of local features. arXiv 2019, arXiv:1905.03561. [Google Scholar]
- Revaud, J.; De Souza, C.; Humenberger, M.; Weinzaepfel, P. R2d2: Reliable and repeatable detector and descriptor. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 12414–12424. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Vancouver, BC, Canada, 17–24 June 2018; pp. 224–236. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Fang, Y.; Shan, G.; Wang, T.; Li, X.; Liu, W.; Snoussi, H. He-slam: A stereo slam system based on histogram equalization and orb features. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4272–4276. [Google Scholar]
- Yang, W.; Zhai, X. Contrast limited adaptive histogram equalization for an advanced stereo visual slam system. In Proceedings of the 2019 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Guilin, China, 17–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 131–134. [Google Scholar]
- Gu, Q.; Liu, P.; Zhou, J.; Peng, X.; Zhang, Y. Drms: Dim-light robust monocular simultaneous localization and mapping. In Proceedings of the 2021 International Conference on Computer, Control and Robotics (ICCCR), Shanghai, China, 8–10 January 2021; IEEE: lPiscataway, NJ, USA, 2021; pp. 267–271. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Yadav, G.; Maheshwari, S.; Agarwal, A. Contrast limited adaptive histogram equalization based enhancement for real time video system. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2392–2397. [Google Scholar]
- Cherian, A.K.; Poovammal, E.; Philip, N.S.; Ramana, K.; Singh, S.; Ra, I.H. Deep learning based filtering algorithm for noise removal in underwater images. Water 2021, 13, 2742. [Google Scholar] [CrossRef]
- Kryjak, T.; Blachut, K.; Szolc, H.; Wasala, M. Real-Time CLAHE Algorithm Implementation in SoC FPGA Device for 4K UHD Video Stream. Electronics 2022, 11, 2248. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 573–580. [Google Scholar]
- Sturm, J.; Burgard, W.; Cremers, D. Evaluating Egomotion and Structure-from-Motion Approaches Using the TUM RGB-D Benchmark. In Proceedings of the Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RJS International Conference on Intelligent Robot Systems (IROS), Portugal, 2012; Volume 13. Available online: https://cvg.cit.tum.de/_media/spezial/bib/sturm12iros_ws.pdf (accessed on 1 January 2012).
- Shi, X.; Li, D.; Zhao, P.; Tian, Q.; Tian, Y.; Long, Q.; Zhu, C.; Song, J.; Qiao, F.; Song, L.; et al. Are we ready for service robots? The openloris-scene datasets for lifelong slam. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3139–3145. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).