
Digital Self-Interference Cancellation for Full-Duplex Systems Based on CNN and GRU
Abstract
:1. Introduction
- Combining CNN and GRU (conv_GRU) leverages the strengths of both architectures. CNN excels at capturing local features and spatial correlations, enabling it to extract detailed patterns and structures from sequential data. On the other hand, GRU is proficient at capturing long-range dependencies within sequences, allowing it to discern trends in data evolution over time or spatial locations. Compared to traditional LSTM, GRU features a more streamlined architecture with fewer parameters, thereby diminishing model complexity and computational costs while facilitating easier training. By combining both architectures, the temporal relationships between these features can be further analyzed. This integration builds upon local feature extraction capabilities, enabling a more comprehensive understanding of complex data patterns;
- The introduction of residual networks involves the implementation of shortcut connections, allowing information to flow directly from shallower network layers to deeper ones. This approach reduces gradient attenuation during backpropagation in deeper networks, addressing issues such as gradient vanishing and explosion. In the presence of complex signals, including self-interference, this method ensures effective gradient propagation, thereby stabilizing model training and accelerating convergence.
- Adding the self-attention mechanism enables the model to directly compare each element within a sequence and weight the information based on their correlations. Simultaneously, these weights dynamically adjust according to the importance of different input segments, automatically focusing on the most relevant parts while disregarding less crucial information. This capability enhances the model’s capacity to comprehend and capture long-range dependencies, reducing information loss and alleviating the challenges associated with long-distance information transfer in traditional RNNs or CNNs.
2. System Model
3. Proposed Solution
3.1. CNN Module
- The preprocessed input data first pass through a one-dimensional convolution layer with convolution kernel length of 3, generating 32 different feature maps. The convolution layer, the core of the CNN, can locally sense the input data and extract local features by using a sliding window approach, making it highly effective for local pattern recognition in sequence data, which is crucial for our study. Additionally, the convolution layer is locally connected rather than fully connected, with the characteristic of parameter sharing. This ensures the sparsity of the network and helps prevent overfitting.
- Furthermore, the data go into the normalization layer. We use Layer Normalization (LN) instead of Batch Normalization (BN). LN normalizes the input using the mean and variance of each sample independently within the feature dimension. This approach maintains the sequential information of the data along the temporal axis, ensuring that the temporal dependencies of the sequence are not disrupted by the normalization process. Additionally, compared to BN, LN has a shorter training time and is more suitable for the small batch data used in this paper, yielding better results.
- Finally, the activation layer is used to introduce nonlinearity into the network to enhance its representation capability, with the activation function typically being a ReLU. Its implementation is very simple; the mathematical expression is ReLU(x) = max(0,x). In simple terms, the ReLU function is a blend of linear and nonlinear features. When the input value is negative, ReLU behaves as a nonlinear function and directly outputs 0, while when the input value is positive, ReLU behaves as a linear function. This form allows the ReLU function to mitigate the problem of gradient vanishing to some extent during the training process of deep learning [17]. At the same time, this property can lead to only a portion of the hidden layer neurons in the network being activated, creating a sparse activation phenomenon, which can improve the expressiveness of the network and reduce the risk of overfitting, making the model more robust. Compared to the traditional sigmoid and tanh activation functions, the implementation of ReLU involves only threshold judgment and does not involve any exponential operations, which makes it computationally very efficient and the network converges faster.
- After the data pass through the first convolution module, they enter the second convolution module whose convolution layer is a one-dimensional convolution layer with a convolution kernel of length 1. The rest of the parts remain the same.
3.2. Residual Module
3.3. GRU Module
3.4. Self-Attention Module
3.5. Proposed SIC Scheme
4. Results and Discussion
4.1. Data Preprocessing
4.2. Experimental Parameter Setting
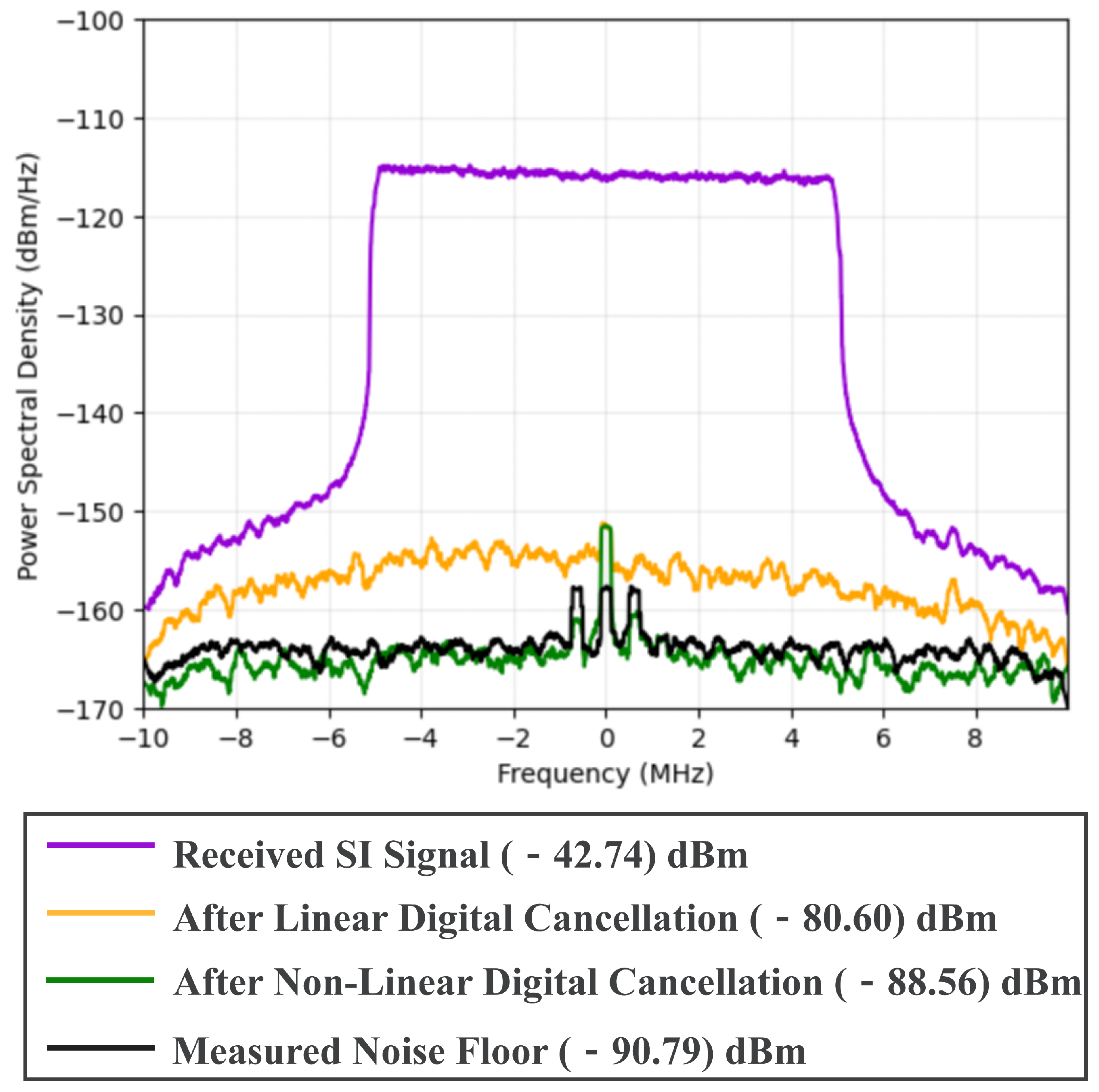
4.3. SIC Results and Analysis
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shammaa, M.; Mashaly, M.; El-mahdy, A. A deep learning-based adaptive receiver for full-duplex systems. AEU-Int. J. Electron. Commun. 2023, 170, 154822. [Google Scholar] [CrossRef]
- Li, H.; Van Kerrebrouck, J.; Caytan, O.; Rogier, H.; Bauwelinck, J.; Demeester, P.; Torfs, G. Self-Interference Cancellation Enabling High-Throughput Short-Reach Wireless Full-Duplex Communication. IEEE Trans. Wirel. Commun. 2018, 17, 6475–6486. [Google Scholar] [CrossRef]
- Hu, C.; Chen, Y.; Wang, Y.; Li, Y.; Wang, S.; Yu, J.; Lu, F.; Fan, Z.; Du, H.; Ma, C. Digital self-interference cancellation for full-duplex systems based on deep learning. AEU-Int. J. Electron. Commun. 2023, 168, 154707. [Google Scholar] [CrossRef]
- Nguyen, H.V.; Nguyen, V.-D.; Dobre, O.A.; Sharma, S.K.; Chatzinotas, S.; Ottersten, B.; Shin, O.-S. On the spectral and energy efficiencies of full-duplex cell-free massive mimo. IEEE J. Sel. Areas Commun. 2020, 38, 1698–1718. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, M.; Qin, F. Neural-network-based nonlinear self-interference cancelation scheme for mobile stations with dual-connectivity. IEEE Access 2021, 9, 53566–53575. [Google Scholar] [CrossRef]
- Balatsoukas-Stimming, A. Non-linear digital self-interference cancellation for in-band full-duplex radios using neural networks. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Elsayed, M.; El-Banna, A.A.A.; Dobre, O.A.; Shiu, W.; Wang, P. Low complexity neural network structures for self-interference cancellation in full-duplex radio. IEEE Commun. Lett. 2021, 25, 181–185. [Google Scholar] [CrossRef]
- Kong, D.H.; Kil, Y.-S.; Kim, S.-H. Neural network aided digital self-interference cancellation for full-duplex communication over time-varying channels. IEEE Trans. Veh. Technol. 2022, 71, 6201–6213. [Google Scholar] [CrossRef]
- Zheng, W.; Chen, G. An accurate gru-based power time-series prediction approach with selective state updating and stochastic optimization. IEEE Trans. Cybern. 2022, 52, 13902–13914. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Jin, B.; Wang, L.; Xu, L. Sea surface height prediction with deep learning based on attention mechanism. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Ren, X.; Mosavat-Jahromi, H.; Cai, L.; Kidston, D. Spatio-temporal spectrum load prediction using convolutional neural network and resnet. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 502–513. [Google Scholar] [CrossRef]
- Duan, J.; Wei, X.; Zhou, J.; Wang, T.; Ge, X.; Wang, Z. Latency compensation and prediction for wireless train to ground communication network based on hybrid lstm model. IEEE Trans. Intell. Transp. Syst. 2024, 25, 1637–1645. [Google Scholar] [CrossRef]
- Zou, J.; Tao, Y.; Fang, Y.; Ma, H.; Yang, Z. Receiver design for ici-csk system: A new perspective based on gru neural network. IEEE Commun. Lett. 2023, 27, 2983–2987. [Google Scholar] [CrossRef]
- Jiang, Z.; Ma, Z.; Wang, Y.; Shao, X.; Yu, K.; Jolfaei, A. Aggregated decentralized down-sampling-based resnet for smart healthcare systems. Neural Comput. Appl. 2023, 35, 14653–14665. [Google Scholar] [CrossRef]
- Wang, Q.; He, F.; Meng, J. Performance comparison of real and complex valued neural networks for digital self-interference cancellation. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1193–1199. [Google Scholar]
- Wang, B.; Xu, K.; Zheng, S.; Zhou, H.; Liu, Y. A deep learning based intelligent receiver for improving the reliability of the mimo wireless communication system. IEEE Trans. Reliab. 2022, 71, 1104–1115. [Google Scholar] [CrossRef]
- Dittmer, S.; King, E.J.; Maass, P. Singular Values for ReLU Layers. IEEE Trans. Neural Netw. Learn. Systems. 2019, 31, 3594–3605. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Chen, S.; Li, Q.; Wright, S.J. Overparameterization of deep resnet: Zero loss and mean-field analysis. J. Mach. Learn. Res. 2022, 23, 1–65. [Google Scholar]
- Zeng, C.; Ma, C.; Wang, K.; Cui, Z. Parking occupancy prediction method based on multi factors and stacked gru-lstm. IEEE Access 2022, 10, 47361–47370. [Google Scholar] [CrossRef]
- Wei, S.; Qu, Q.; Zeng, X.; Liang, J.; Shi, J.; Zhang, X. Self-attention bilstm networks for radar signal modulation recognition. IEEE Trans. Microw. Theory Tech. 2021, 69, 5160–5172. [Google Scholar] [CrossRef]
- Albarakati, H.M.; Khan, M.A.; Hamza, A.; Khan, F.; Kraiem, N.; Jamel, L.; Almuqren, L.; Alroobaea, R. A novel deep learning architecture for agriculture land cover and land use classification from remote sensing images based on network-level fusion of self-attention architecture. IEEE J. Sel. Top. Appl. Earth Obs. Remote 2024, 17, 6338–6353. [Google Scholar] [CrossRef]
- Korpi, D.; Anttila, L.; Valkama, M. Nonlinear self-interference cancellation in mimo full-duplex transceivers under crosstalk. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 24. [Google Scholar] [CrossRef]
- Elsayed, M.; Aziz El-Banna, A.A.; Dobre, O.A.; Shiu, W.; Wang, P. Full-duplex self-interference cancellation using dual-neurons neural networks. IEEE Commun. Lett. 2022, 26, 557–561. [Google Scholar] [CrossRef]
- Pourdaryaei, A.; Mohammadi, M.; Mubarak, H.; Abdellatif, A.; Karimi, M.; Gryazina, E.; Terzija, V. A new framework for electricity price forecasting via multi-head self-attention and cnn-based techniques in the competitive electricity market. Expert Syst. Appl. 2024, 235, 121207. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | CGRSA-Net |
|---|---|
| Optimizer | Adam |
| Loss | MSE |
| Self-interference channel length | 16.000 |
| trainingRatio | 0.900 |
| nEpochs | 20.000 |
| nHidden | 32.000 |
| learningRate | 0.001 |
| batchSize | 32.000 |
| pamaxordercanc | 7.000 |
| samplingFreqMHz | 20.000 |
| dataOffset | 14.000 |
| Network | Linear Canc (LC)/dB | Nonlinear Canc (NC)/dB | Total Canc (TC)/dB | P (%) |
|---|---|---|---|---|
| RVNN | 37.86 | 6.23 | 44.09 | 27.61% |
| LWGS | 37.86 | 6.69 | 44.55 | 18.83% |
| MWGS | 37.86 | 6.53 | 44.39 | 21.75% |
| DN-2HLNN (2-7) | 37.86 | 6.72 | 44.58 | 18.30% |
| DN-3HLNN (2-4-5) | 37.86 | 6.80 | 44.66 | 16.92% |
| Feed-forward NN | 37.86 | 6.61 | 44.47 | 20.27% |
| CGRSA-Net | 37.86 | 7.95 | 45.81 | —— |
| Non-SIC /dB | PSD /dBm | Loss | |
|---|---|---|---|
| CGRSA-Net (epoch = 20) | 7.95 | −88.56 | 0.080650 |
| CGRSA-Net (epoch = 30) | 7.76 | −88.37 | 0.077114 |
| GRU | 6.70 | −87.31 | 0.091677 |
| GRU-CNN | 6.92 | −87.53 | 0.090060 |
| GRU-ResNet | 6.84 | −87.46 | 0.091901 |
| GRU-SA | 6.97 | −87.59 | 0.085331 |
| GRU-Res-SA | 7.09 | −87.70 | 0.088003 |
| GRU-CNN-SA | 7.48 | −88.09 | 0.087609 |
| GRU-CNN-Res | 7.06 | −87.67 | 0.088769 |
| CGRSA-Net (BN) | 7.53 | −88.14 | 0.079407 |
| CGRSA-Net (GN) | 7.70 | −88.31 | 0.083285 |
| CGRSA-Net (Attention) | 7.61 | −88.22 | 0.083818 |
| CGRSA-Net (multi-head attention) | 7.68 | −88.29 | 0.089990 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Ding, T. Digital Self-Interference Cancellation for Full-Duplex Systems Based on CNN and GRU. Electronics 2024, 13, 3041. https://doi.org/10.3390/electronics13153041
Liu J, Ding T. Digital Self-Interference Cancellation for Full-Duplex Systems Based on CNN and GRU. Electronics. 2024; 13(15):3041. https://doi.org/10.3390/electronics13153041
Chicago/Turabian StyleLiu, Jun, and Tian Ding. 2024. "Digital Self-Interference Cancellation for Full-Duplex Systems Based on CNN and GRU" Electronics 13, no. 15: 3041. https://doi.org/10.3390/electronics13153041