
Predicting the Characteristics of High-Speed Serial Links Based on a Deep Neural Network (DNN)—Transformer Cascaded Model


Abstract
:1. Introduction
- (1)
- Based on the key physical parameters of channels, neural network models are used to directly analyze link performance, and this obviates the time-consuming processes of EMF solving and circuit system simulation.
- (2)
- Through neural network models, the accurate prediction of multiple SI indicators and equalizer parameters is achieved. Additionally, we show that SI analysis and link optimization can also be rapidly achieved.
- (3)
- A DNN–Transformer cascaded model is proposed, Bayesian optimization is used to tune the hyperparameters of this model, and its superior performance is demonstrated by comparing it with other models.
2. Fundamental Methods
2.1. Signal Integrity and S-Parameters
2.2. Channel Operating Margin
3. Dataset Construction
3.1. Channel Design and Dataset Splitting
3.2. COM Configuration and Equalizer Setting
3.3. Dataset Splitting
4. Construction of the Cascaded Model and Training
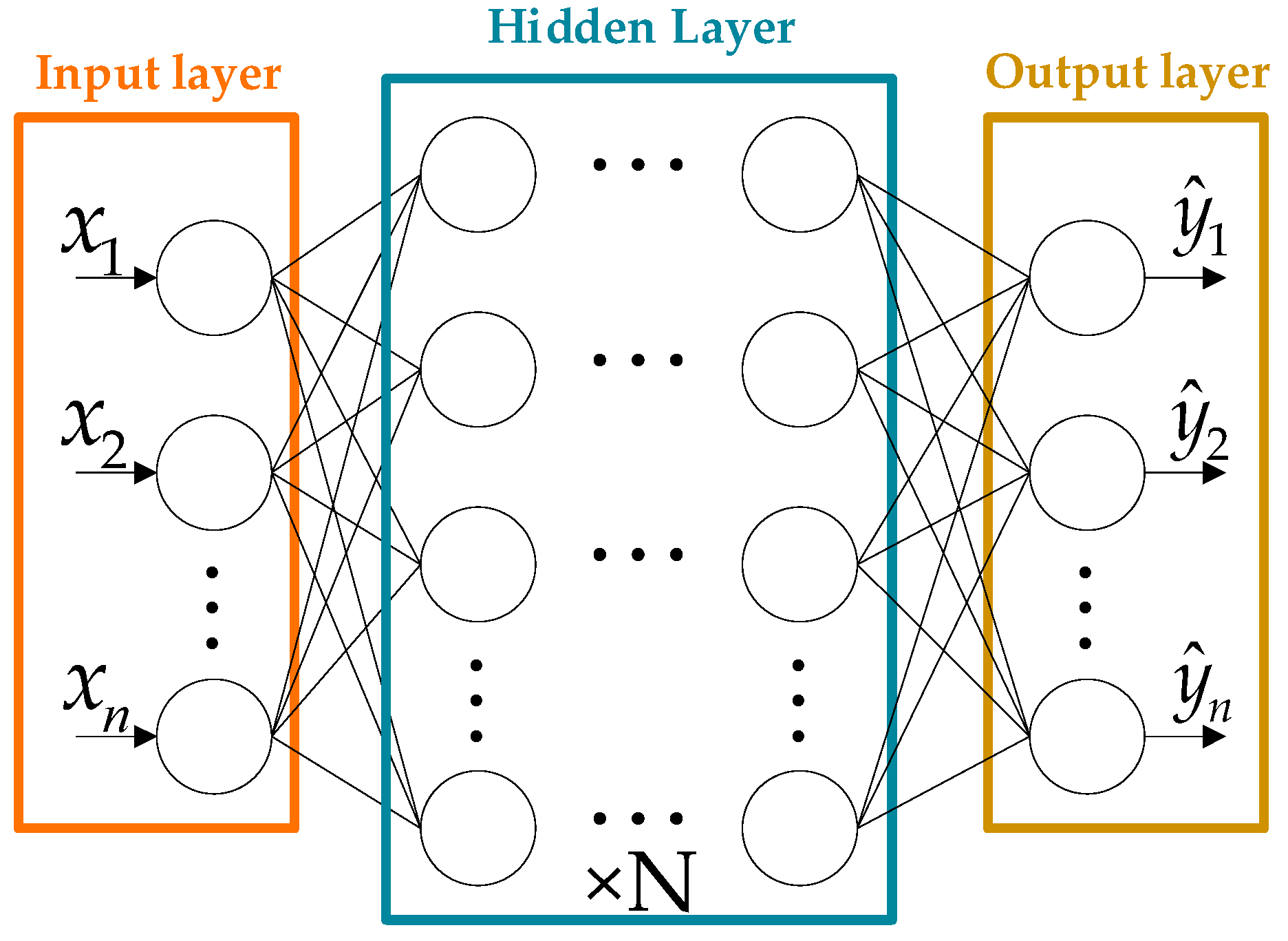
4.1. DNN
4.2. Transformer for Regression
4.3. Cascaded Model and Training
5. Numerical Results
5.1. IL and RL
5.2. EH/EW of the Eye Diagrams
5.3. COM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DNN | Deep Neural Network; |
| LSTM | Long Short-Term Memory Neural Network; |
| SBR | Single-Bit Response; |
| SI | signal integrity |
| COM | channel operating margin; |
| eCOM | enhanced channel operating margin; |
| GP | Gaussian process; |
| HPO | hyperparameter optimization; |
| EM | electromagnetic; |
| EMFS | electromagnetic field solver; |
| IBIS-AMI | Input/Output Buffer Information Specification Algorithmic Model Interface; |
| EH | eye height; |
| EW | eye width; |
| RL | return loss; |
| IL | insertion loss; |
| TD | time domain; |
| FD | frequency domain; |
| ML | machine learning; |
| SVM | Support Vector Machine; |
| LS-SVM | Least-Squares Support Vector Machine; |
| FNN | Feedforward Neural Network; |
| RFR | Random Forest Regression; |
| RNN | Recurrent Neural Network; |
| FFE | feedforward equalizer; |
| DFE | decision feedback equalizer; |
| CTLE | continuous-time linear equalizer; |
| ILD | insertion loss deviation; |
| ICR | insertion loss-to-crosstalk ratio; |
| ISI | inter-symbol interference; |
| FOM | figure of merit. |
References
- Hall, S.H.; Heck, H.L. Advanced Signal Integrity for High-Speed Digital Designs; John Wiley & Sons: Hoboken, NJ, USA, 2009; pp. 201–206. [Google Scholar]
- Yan, J.; Zargaran-Yazd, A. IBIS-AMI modelling of high-speed memory interfaces. In Proceedings of the 2015 IEEE 24th Electrical Performance of Electronic Packaging and Systems (EPEPS), San Jose, CA, USA, 25–28 October 2015; pp. 73–76. [Google Scholar]
- LAN/MAN Standards Committee of the IEEE Computer Society. IEEE Standard for Ethernet. 2012. Available online: https://ieeexplore.ieee.org/document/6419735 (accessed on 26 June 2024).
- Wang, Y.; Hu, Q.S. A COM Based High Speed Serial Link Optimization Using Machine Learning. IEICE Trans. Electron. 2022, 105, 684–691. [Google Scholar] [CrossRef]
- Gore, B.; Richard, M. An excerise in applying channel operating margin (COM) for 10GBASE-KR channel design. In Proceedings of the 2014 IEEE International Symposium on Electromagnetic Compatibility (EMC), Raleigh, NC, USA, 4–8 August 2014; pp. 653–658. [Google Scholar]
- Ambasana, N.; Gope, B.; Mutnury, B.; Anand, G. Application of artificial neural networks for eye-height/width prediction from S-parameters. In Proceedings of the IEEE 23rd Conference on Electrical Performance of Electronic Packaging and Systems, Portland, OR, USA, 26–29 October 2014; pp. 99–102. [Google Scholar]
- Ambasana, N.; Anand, G.; Mutnury, B.; Gope, D. Eye Height/Width Prediction From S-Parameters Using Learning-Based Models. IEEE Trans. Compon. Packag. Manuf. Technol. 2016, 6, 873–885. [Google Scholar] [CrossRef]
- Ambasana, N.; Anand, G.; Gope, D.; Mutnury, B. S-Parameter and Frequency Identification Method for ANN-Based EyeHeight/Width Prediction. IEEE Trans. Compon. Packag. Manuf. Technol. 2017, 7, 698–709. [Google Scholar] [CrossRef]
- Lu, T.; Sun, J.; Wu, K.; Yang, Z. High-Speed Channel Modeling with Machine Learning Methods for Signal Integrity Analysis. IEEE Trans. Electromagn. Compat. 2018, 60, 1957–1964. [Google Scholar] [CrossRef]
- Lho, D.; Park, J.; Park, H.; Kang, H.; Park, S.; Kim, J. Eye-width and Eye-height Estimation Method based on Artificial Neural Network (ANN) for USB 3.0. In Proceedings of the 2018 IEEE 27th Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), San Jose, CA, USA, 14–17 October 2018; pp. 209–211. [Google Scholar]
- Sánchez-Masís, A.; Rimolo-Donadio, R.; Roy, K.; Sulaiman, M.; Schuster, C. FNNs Models for Regression of S-Parameters in Multilayer Interconnects with Different Electrical Lengths. In Proceedings of the 2023 IEEE MTT-S Latin America Microwave Conference (LAMC), San Jose, CA, USA, 6–8 December 2023; pp. 82–85. [Google Scholar]
- Li, X.; Hu, Q. A Machine Learning based Channel Modeling for High-speed Serial Link. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1511–1515. [Google Scholar]
- Trinchero, R.; Canavero, F.G. Modeling of eye diagram height in high-speed links via support vector machine. In Proceedings of the 2018 IEEE 22nd Workshop on Signal and Power Integrity (SPI), Brest, France, 22–25 May 2018; pp. 1–4. [Google Scholar]
- Cao, Y.; Zhang, Q.J. A New Training Approach for Robust Recurrent Neural-Network Modeling of Nonlinear Circuits. IEEE Trans. Microw. Theory Tech. 2009, 57, 1539–1553. [Google Scholar] [CrossRef]
- Mutnury, B.; Swaminathan, M.; Libous, J.P. Macromodeling of Nonlinear Digital I/O Drivers. IEEE Trans. Adv. Packag. 2006, 29, 102–113. [Google Scholar] [CrossRef]
- Cao, Y.; Erdin, I.; Zhang, Q.J. Transient Behavioral Modeling of Nonlinear I/O Drivers Combining Neural Networks and Equivalent Circuits. IEEE Microw. Wirel. Compon. Lett. 2010, 20, 645–647. [Google Scholar] [CrossRef]
- Yu, H.; Michalka, T.; Larbi, M.; Swaminathan, M. Behavioral Modeling of Tunable I/O Drivers with Preemphasis Including Power Supply Noise. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 233–242. [Google Scholar] [CrossRef]
- Yu, H.; Chalamalasetty, H.; Swaminathan, M. Modeling of Voltage-Controlled Oscillators Including I/O Behavior Using Augmented Neural Networks. IEEE Access 2019, 7, 38973–38982. [Google Scholar] [CrossRef]
- Faraji, A.; Noohi, M.; Sadrossadat, S.A.; Mirvakili, A.; Na, W.C.; Feng, F. Batch-Normalized Deep Recurrent Neural Network for High-Speed Nonlinear Circuit Macromodeling. IEEE Trans. Microw. Theory Tech. 2022, 70, 4857–4868. [Google Scholar] [CrossRef]
- Moradi, M.; Sadrossadat, A.; Derhami, V. Long Short-Term Memory Neural Networks for Modeling Nonlinear Electronic Components. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 1, 840–847. [Google Scholar] [CrossRef]
- Li, Z.; Li, C.X.; Wu, Z.M.; Zhu, Y.; Mao, J.F. Surrogate Modeling of High-Speed Links Based on GNN and RNN for Signal Integrity Applications. IEEE Trans. Microw. Theory Tech. 2023, 71, 3784–7796. [Google Scholar] [CrossRef]
- Lho, D.; Park, H.; Park, S.; Kim, S.; Kang, H.; Sim, B.; Kim, S.; Park, J.; Cho, K.; Song, J.; et al. Channel Characteristic-Based Deep Neural Network Models for Accurate Eye Diagram Estimation in High Bandwidth Memory (HBM) Silicon Interposer. IEEE Trans. Electromagn. Compat. 2021, 64, 196–208. [Google Scholar] [CrossRef]
- Li, G.S.; Mao, C.S.; Zhao, W.S. Semi-supervised Regression Model for Eye Diagram Estimation of High Bandwidth Memory (HBM) Silicon Interposer. In Proceedings of the 2023 International Applied Computational Electromagnetices Society Symposium, Hangzhou, China, 15–18 August 2023; pp. 1–3. [Google Scholar]
- Goay, C.H.; Ahmad, N.S.; Goh, P. Temporal Convolutional Networks for Transient Simulation of High-Speed Channels. Alex. Eng. J. 2023, 74, 643–663. [Google Scholar] [CrossRef]
- Li, B.W.; Jiao, B.; Chou, C.H.; Mayder, R.; Franzon, P. Self-Evolution Cascade Deep Learning Model for High-Speed Receiver Adaptation. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 1043–1053. [Google Scholar] [CrossRef]
- Li, B.W.; Jiao, B.; Chou, C.H.; Mayder, R.; Franzon, P. CTLE Adaptation Using Deep Learning in High-Speed SerDes Link. In Proceedings of the IEEE 70th Electronic Components and Technology Conference (ECTC), Orlando, FL, USA, 3–30 June 2020; pp. 952–955. [Google Scholar]
- Zhang, H.H.; Xue, Z.S.; Liu, X.Y.; Li, P.; Jiang, L.J.; Shi, G.M. Optimization of High-Speed Channel for Signal Integrity with Deep Genetic Algorithm. IEEE Trans. Electromagn. Compat. 2022, 64, 1270–1274. [Google Scholar] [CrossRef]
- Shan, G.; Li, G.; Wang, Y.; Xing, C.; Zheng, Y.; Yang, Y. Application and Prospect of Artificial Intelligence Methods in Signal Integrity Prediction and Optimization of Microsystems. Micromachines 2023, 14, 344. [Google Scholar] [CrossRef]
- Mellitz, R.; Ran, A.; Li, M.P.; Ragavassamy, V. Channel Operating Margin (COM): Evolution of Channel Specifications for 25 Gbps and Beyond. In Proceedings of the DesignCon 2013, Santa Clara, CA, USA, 28–31 January 2013. [Google Scholar]
- Pu, B.; He, J.; Harmon, A.; Guo, Y.; Liu, Y.; Cai, Q. Signal Integrity Design Methodology for Package in Co-packaged Optics Based on Figure of Merit as Channel Operating Margin. In Proceedings of the 2021 IEEE International Joint EMC/SI/PI and EMC Europe Symposium, Raleigh, NC, USA, 26 July–13 August 2021; pp. 492–497. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Bono, F.M.; Radicioni, L.; Cinquemani, S. A Novel Approach for Quality Control of Automated Production Lines Working under Highly Inconsistent Conditions. Eng. Appl. Artif. Intell. 2023, 122, 106149. [Google Scholar] [CrossRef]
- Steel, R.G.D.; Torrie, J.H. Principles and Procedures of Statistics; McGraw Hill: New York, NJ, USA, 1960. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Frazier, P.I. A Tutorial on Bayesian Optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Variable | Input | Output |
|---|---|---|
| Er | PCB sheet permittivity real part and TanD | Eye diagrams COM values Equalizer parameters |
| Df | PCB sheet dissipation factor | |
| Trace | PCB trace length | |
| PCB trace width | ||
| Differential line space | ||
| PCB trace thickness | ||
| PCB trace conductivity | ||
| PCB trace structure (profile) | ||
| Zd | Differential impedance | |
| PCB Type | Stripline is 1 and microstrip is 0 |
| Parameter | Symbol | Setting | Unit |
|---|---|---|---|
| Symbol rate | 20 | GBd | |
| Number of signal levels | L | 4 | |
| Samples per UI | M | 32 | |
| Target detector error ratio | |||
| Transmitter output voltage, victim | 0.4 | V | |
| CTLE DC gain | [−12:1:0] | dB | |
| CTLE DC gain2 | [−6:1:0] | dB | |
| CTLE HP pole | 0.25 | GHz | |
| CTLE zero | GHz | ||
| CTLE pole1 | GHz | ||
| CTLE pole2 | |||
| FFE main cursor | c (0) | 0.62 | |
| FFE pre-cursor | c (−1) | [−0.18:0.02:0] | |
| FFE post-cursor | c (1) | [−0.38:0.02:0] | |
| DFE length | 12 | UI | |
| DFE magnitude limit | 0.75 | ||
| 0.2 | |||
| COM pass threshold | 3 | dB |
| Number of Channels | ||
|---|---|---|
| Datasets | A: 280 | B: 215 (170 from A) |
| Training Set | 184 | 140 |
| Validation Set | 40 | 40 |
| Testing Set | 56 | 40 (5 from the validation set) |
| Total | 325 | |
| Eye | Modulation | RMSE | MAE | MAPE | MRE (%) |
|---|---|---|---|---|---|
| EH (mV) | PAM3 | 4.8 × 10−1 | 3.3 × 10−1 | 5.7 × 10−3 | 2.5 |
| PAM4 | 4.0 × 10−1 | 2.9 × 10−1 | 8.1 × 10−3 | 2.8 | |
| EW (UI) | PAM3 | 4.4 × 10−3 | 3.4 × 10−3 | 9.3 × 10−3 | 2.7 |
| PAM4 | 4.4 × 10−3 | 3.6 × 10−3 | 1.2 × 10−2 | 3.5 |
| COM | RMSE | MAE | MAPE | MRE (%) |
|---|---|---|---|---|
| 3-taps FFE + CTLE + 12-taps DFE | 4.5 × 10−2 | 3.5 × 10−2 | 5.1 × 10−3 | 1.6% |
| 3-taps FFE + CTLE + 8-taps DFE | 5.0 × 10−2 | 3.7 × 10−2 | 5.6 × 10−3 | 2.0% |
| 3-taps FFE + CTLE + 4-taps DFE | 4.2 × 10−2 | 3.2 × 10−2 | 4.1 × 10−3 | 1.7% |
| CTLE + 12-taps DFE | 9.6 × 10−2 | 7.1 × 10−2 | 1.4 × 10−2 | 5.7% |
| 12-taps DFE | 1.6 × 10−1 | 1.1 × 10−1 | 3.0 × 10−2 | 17.5% |
| Model | RMSE | MAE | MAPE | MRE (%) |
|---|---|---|---|---|
| DNN | 6.9 × 10−2 | 4.3 × 10−2 | 7.8 × 10−3 | 6.5 |
| LSTM | 5.3 × 10−2 | 4.4 × 10−2 | 6.4 × 10−3 | 2.0 |
| DNN-LSTM | 5.0 × 10−2 | 4.1 × 10−2 | 6.0 × 10−3 | 1.8 |
| Transformer | 4.7 × 10−2 | 3.7 × 10−2 | 5.5 × 10−3 | 1.7 |
| DNN–Transformer | 4.6 × 10−2 | 3.5 × 10−2 | 5.1 × 10−3 | 1.6 |
| Model | Physical Parameters Variable | Transient Waveform Prediction | FD Prediction | Link Optimization | GPU/CPU Time (ms) | RMSE | MAE |
|---|---|---|---|---|---|---|---|
| SVM [13] | Yes | No | No | No | <5 * | 3.8 × 10−1 | 3.1 × 10−1 |
| RFR [12] | Yes | No | Yes | No | <5 * | 4.8 × 10−1 | 3.8 × 10−1 |
| DNN [9] | Yes | No | No | No | <5 | 6.9 × 10−2 | 4.3 × 10−2 |
| LSTM [20] | No | Yes | No | No | <5 | 5.3 × 10−2 | 4.4 × 10−2 |
| GNN-RNN [21] | Yes | Yes | No | No | 567.1 | \ | \ |
| DNN–Transformer | Yes | Yes | Yes | Yes | 792.8 * | 4.6 × 10−2 | 3.5 × 10−2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, L.; Zhou, J.; Jiang, H.; Yang, X.; Zhan, Y.; Zhang, Y. Predicting the Characteristics of High-Speed Serial Links Based on a Deep Neural Network (DNN)—Transformer Cascaded Model. Electronics 2024, 13, 3064. https://doi.org/10.3390/electronics13153064
Wu L, Zhou J, Jiang H, Yang X, Zhan Y, Zhang Y. Predicting the Characteristics of High-Speed Serial Links Based on a Deep Neural Network (DNN)—Transformer Cascaded Model. Electronics. 2024; 13(15):3064. https://doi.org/10.3390/electronics13153064
Chicago/Turabian StyleWu, Liyin, Jingyang Zhou, Haining Jiang, Xi Yang, Yongzheng Zhan, and Yinhang Zhang. 2024. "Predicting the Characteristics of High-Speed Serial Links Based on a Deep Neural Network (DNN)—Transformer Cascaded Model" Electronics 13, no. 15: 3064. https://doi.org/10.3390/electronics13153064