
StarCAN-PFD: An Efficient and Simplified Multi-Scale Feature Detection Network for Small Objects in Complex Scenarios



Abstract
1. Introduction
2. Related Work
2.1. Small Object Detection
2.2. Efficient Feature Extraction Network and Attention Mechanism
2.3. Recognition of Difficult Small Target Samples
3. The Proposed StarCAN-PFD Network
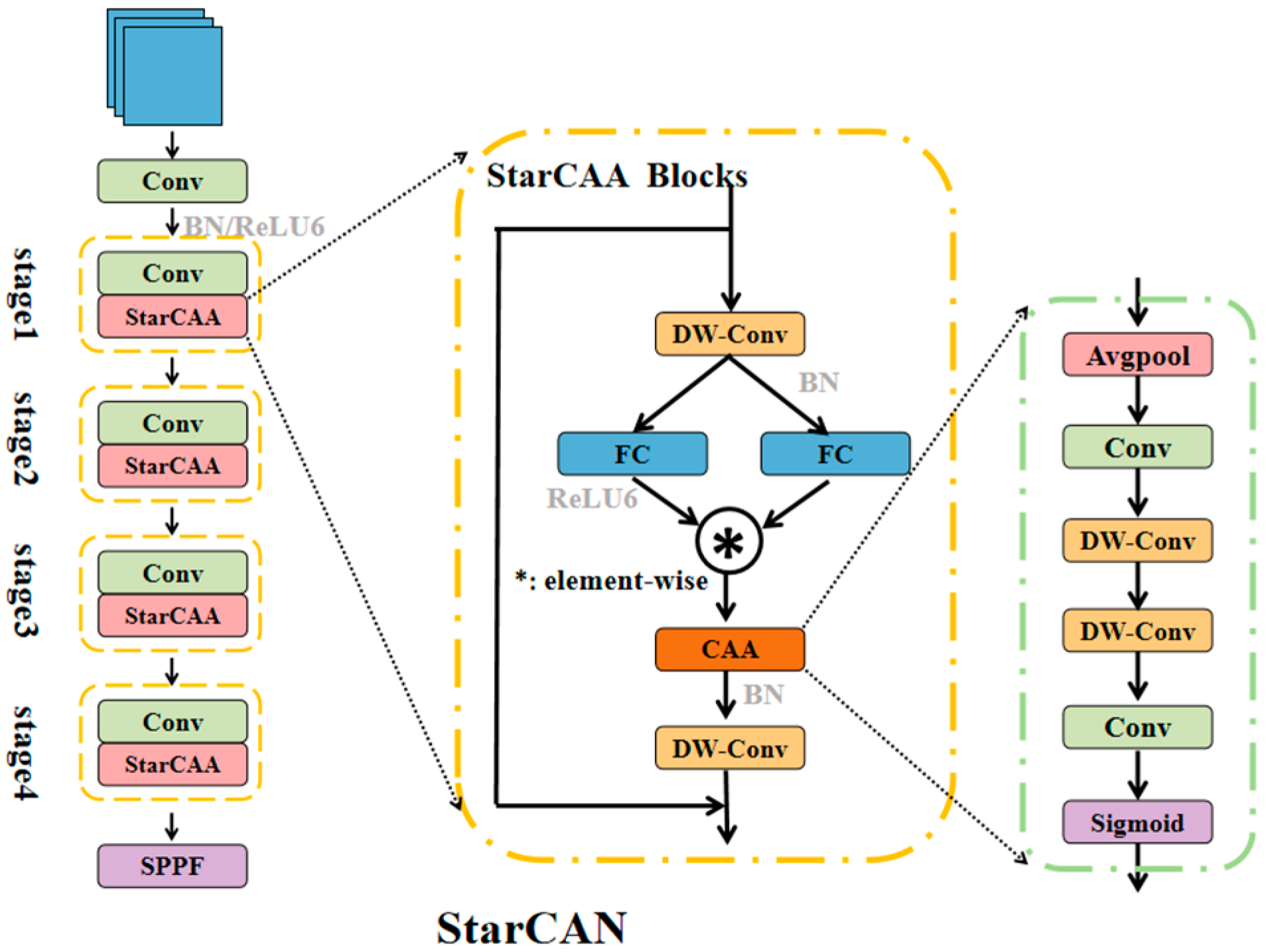
3.1. StarCAN BackBone
3.1.1. StarCAA Blocks
3.1.2. The Context Anchor Attention (CAA)
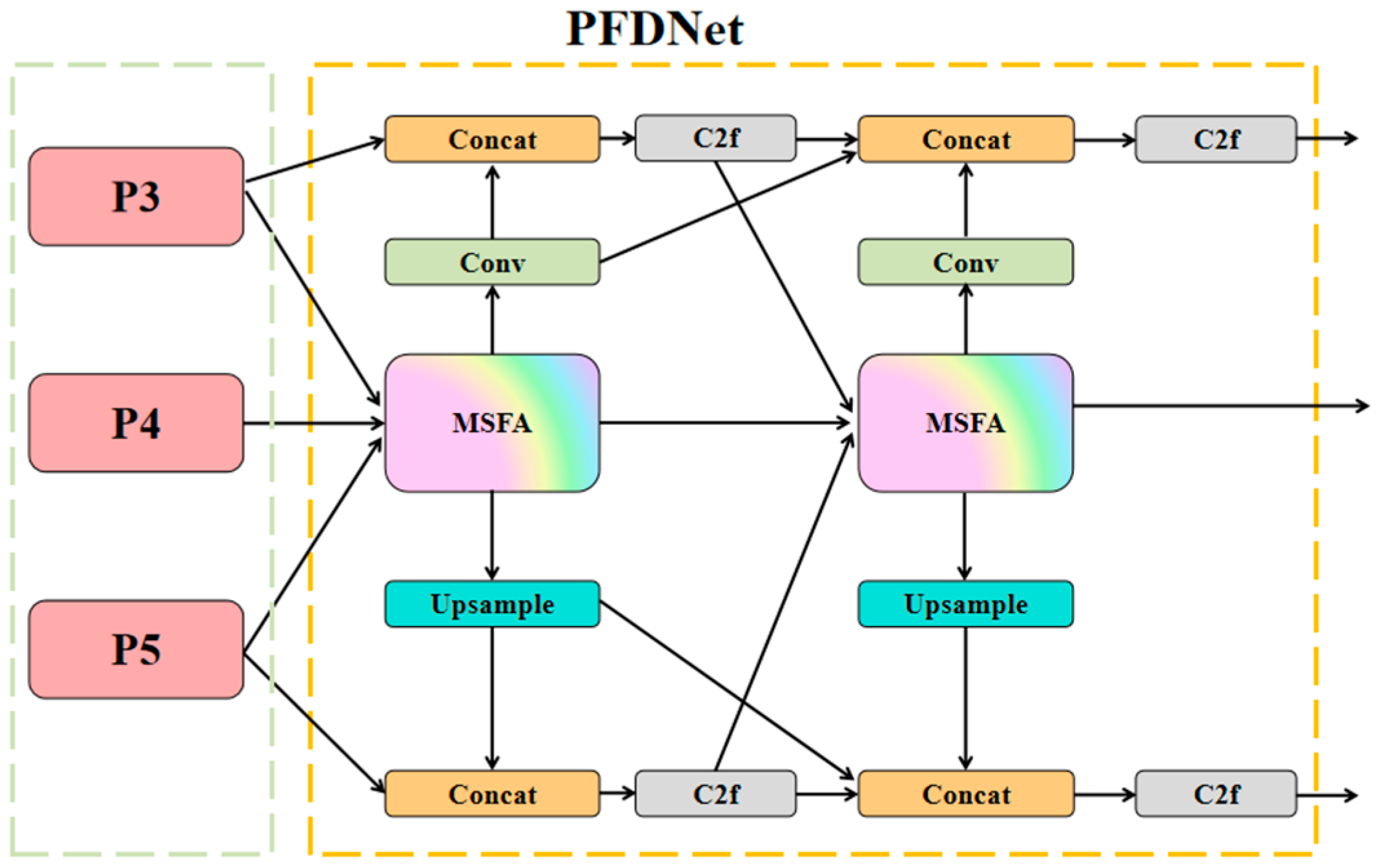
3.2. Multi-Scale Focus and Diffusion Pyramid Network
3.2.1. Multi-Scale Feature Aggregator Block
3.2.2. PFDNet
3.3. DESDetect
4. Experimental Design
4.1. Experimental Dataset
4.2. Experimental Environment and Parameters
4.3. Eval
5. Experimental Results and Analysis
5.1. Algorithm Performance Comparison
5.2. Ablation Study
5.3. Module Comparison Experiment
5.3.1. Comparison of Backbone Network Structure
5.3.2. Attention Mechanism Experiment
5.3.3. DESDetect Head Experiment
5.4. Performance on Other Datasets
6. Discussion
6.1. Further Analysis of Difficult Sample Recognition Performance
6.2. Limitations and Challenges of the Study
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abuadbba, A.; Rhodes, N.; Moore, K.; Sabir, B.; Wang, S.; Gao, Y. DeepiSign-G: Generic Watermark to Stamp Hidden DNN Parameters for Self-contained Tracking. arXiv 2024, arXiv:2407.01260. [Google Scholar]
- Barodi, A.; Bajit, A.; Zemmouri, A.; Benbrahim, M.; Tamtaoui, A. Improved deep learning performance for real-time traffic sign detection and recognition applicable to intelligent transportation systems. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 249294472. [Google Scholar] [CrossRef]
- Trappey, A.J.; Shen, O.T. A universal traffic sign detection system using a novel self-training neural network modeling approach. Adv. Eng. Inform. 2024, 62, 102674. [Google Scholar] [CrossRef]
- Bao, D.; Gao, R. YED-YOLO: An object detection algorithm for automatic driving. Signal Image Video Process. 2024, 1–9. [Google Scholar] [CrossRef]
- Agrawal, S.; Chaurasiya, R.K. Ensemble of SVM for accurate traffic sign detection and recognition. In Proceedings of the 1st International Conference on Graphics and Signal Processing, Singapore, 24–27 June 2017; pp. 10–15. [Google Scholar]
- Ren, X.; Zhi, M. An overview of traffic sign detection and recognition algorithms. In Proceedings of the Thirteenth International Conference on Graphics and Image Processing (ICGIP 2021), Kunming, China, 18–20 August 2021; pp. 618–626. [Google Scholar]
- Yazdan, R.; Varshosaz, M. Improving traffic sign recognition results in urban areas by overcoming the impact of scale and rotation. ISPRS J. Photogramm. Remote. Sens. 2021, 171, 18–35. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, P.; Li, Z.; Li, Y.; Zhang, X.; Meng, G.; Xiang, S.; Sun, J.; Jia, J. Stitcher: Feedback-driven data provider for object detection. arXiv 2020, arXiv:2004.12432. [Google Scholar]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote. Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. FSoD-Net: Full-scale object detection from optical remote sensing imagery. IEEE TGRS 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Huang, M.; Wan, Y.; Gao, Z.; Wang, J. Real-time traffic sign detection model based on multi-branch convolutional reparameterization. J. Real-Time Image Process. 2023, 20, 57. [Google Scholar] [CrossRef]
- Geng, H.; Liu, Z.; Jiang, J.; Fan, Z.; Li, J. Embedded road crack detection algorithm based on improved YOLOv8. J. Comput. Appl. 2024, 44, 1613. [Google Scholar]
- Zeng, G.; Wu, Z.; Xu, L.; Liang, Y. Efficient Vision Transformer YOLOv5 for Accurate and Fast Traffic Sign Detection. Electronics 2024, 13, 880. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack Detection and Comparison Study Based on Faster R-CNN and Mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- Bi, X.; Hu, J.; Xiao, B.; Li, W.; Gao, X. IEMask R-CNN: Information-Enhanced Mask R-CNN. IEEE Trans. Big Data 2022, 9, 688–700. [Google Scholar] [CrossRef]
- Chen, M.; Yu, L.; Zhi, C.; Sun, R.; Zhu, S.; Gao, Z.; Ke, Z.; Zhu, M.; Zhang, Y. Improved faster R-CNN for fabric defect detection based on Gabor filter with Genetic Algorithm optimization. Comput. Ind. 2022, 134, 103551. [Google Scholar] [CrossRef]
- Bai, D.; Sun, Y.; Tao, B.; Tong, X.; Xu, M.; Jiang, G.; Chen, B.; Cao, Y.; Sun, N.; Li, Z. Improved single shot multibox detector target detection method based on deep feature fusion. Concurr. Comput. Pract. Exp. 2021, 34, e6614. [Google Scholar] [CrossRef]
- Krishna, H.; Jawahar, C.V. Improving small object detection. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 340–345. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhang, J.; Zou, X.; Kuang, L.-D.; Wang, J.; Sherratt, R.S.; Yu, X. CCTSDB 2021: A more comprehensive traffic sign detection benchmark. Hum.-Centric Comput. Inf. Sci. 2022, 12, 23. [Google Scholar] [CrossRef]
- He, X.; Li, T.; Yang, Y. Improved traffic sign detection algorithm based on improved YOLOv8s. J. Comput. Electron. Inf. Manag. 2024, 12, 38–45. [Google Scholar] [CrossRef]
- Wu, T.; Dong, Y. YOLO-SE: Improved YOLOv8 for remote sensing object detection and recognition. Appl. Sci. 2023, 13, 12977. [Google Scholar] [CrossRef]
- Li, S.; Shi, T.; Well, F. Improved road damage detection algorithm of YOLOv8. Comput. Eng. Appl. 2023, 59, 165–174. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Bi, C.; Wang, J.; Duan, Y.; Fu, B.; Kang, J.-R.; Shi, Y. MobileNet Based Apple Leaf Diseases Identification. Mob. Netw. Appl. 2020, 27, 172–180. [Google Scholar] [CrossRef]
- Nan, Y.; Ju, J.; Hua, Q.; Zhang, H.; Wang, B. A-MobileNet: An approach of facial expression recognition. Alex. Eng. J. 2022, 61, 4435–4444. [Google Scholar] [CrossRef]
- Wang, W.; Li, Y.; Zou, T.; Wang, X.; You, J.; Luo, Y. A Novel Image Classification Approach via Dense-MobileNet Models. Mob. Inf. Syst. 2020, 2020, 7602384. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef]
- Hao, J.; Yang, J.; Han, S.; Wang, Y. YOLOv4 highway pavement crack detection method using Ghost module and ECA. J. Comput. Appl. 2023, 43, 1284. [Google Scholar]
- Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Tzimiropoulos, G.; Martinez, B. Edgevits: Competing light-weight cnns on mobile devices with vision transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 294–311. [Google Scholar]
- Chen, J.; Kao, S.-h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 5694–5703. [Google Scholar]
- Li, J.; Wang, H.; Xu, Y.; Liu, F. Road Object Detection of YOLO Algorithm with Attention Mechanism. Front. Signal Process. 2021, 5, 9–16. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Chanussot, J.; Zhou, H.; Yang, J. Rotation Equivariant Feature Image Pyramid Network for Object Detection in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, X.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C. Mmrotate: A rotated object detection benchmark using pytorch. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 7331–7334. [Google Scholar]
- Zhang, W.; Jiao, L.; Li, Y.; Huang, Z.; Wang, H. Laplacian Feature Pyramid Network for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Zhang, K.; Bello, I.M.; Su, Y.; Wang, J.; Maryam, I. Multiscale depthwise separable convolution based network for high-resolution image segmentation. Int. J. Remote. Sens. 2022, 43, 6624–6643. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Cai, X.; Lai, Q.; Wang, Y.; Wang, W.; Sun, Z.; Yao, Y. Poly kernel inception network for remote sensing detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 27706–27716. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Guo, C.-L.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3d position embedding. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.-M. DEA-Net: Single Image Dehazing Based on Detail-Enhanced Convolution and Content-Guided Attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Parameters | Value | Data Augmentation Parameters | Value |
|---|---|---|---|
| Initial Learning Rate | 0.01 | hsv_h (Hue Adjustment) | 0.015 |
| Minimum Learning Rate | 0.0001 | hsv_s (Saturation Adjustment) | 0.7 |
| Epoch | 300 | hsv_v (Brightness Adjustment) | 0.4 |
| Batch size | 16 | Translate (Translation Range) | 0.1 |
| Momentum | 0.937 | Scale (Scaling Range) | 0.5 |
| Weight Decay | 0.0005 | Mosaic (Mosaic Probability) | 1 |
| Works | 8 | Erasing (Random Erasing Probability) | 0.4 |
| Algorithm | Backbone | mAP@0.5 | mAP@0.5:0.95 | P | R | FPS | Size |
|---|---|---|---|---|---|---|---|
| SSD | VGG16 | 0.846 | 0.564 | 0.863 | 0.821 | 92.3 | 13.2 |
| YOLOv5 | CPSDarknet53 | 0.905 | 0.622 | 0.93 | 0.827 | 246.3 | 5.0 |
| YOLOv8 | CPSDarknet | 0.905 | 0.611 | 0.921 | 0.825 | 279.4 | 5.9 |
| YOLOv8-mobilenetv4 | MobileNetv4 | 0.927 | 0.697 | 0.929 | 0.879 | 279.6 | 11.2 |
| YOLOv8-Ghost | GhostNet | 0.907 | 0.692 | 0.911 | 0.876 | 274.0 | 3.6 |
| YOLOv8-EficientViT-CBAM | EficientViT | 0.897 | 0.668 | 0.908 | 0.854 | 67.7 | 8.4 |
| YOLOv8-StarNet | Starnet | 0.912 | 0.639 | 0.930 | 0.836 | 334.6 | 6.0 |
| StarCAN-PFD(Ours) | StarCAN | 0.945 | 0.723 | 0.946 | 0.879 | 278.6 | 2.9 |
| Model | StarCAN | PFDN | DESDect | mAP@0.5 | P | R | FPS | Params/106 | GLOPs |
|---|---|---|---|---|---|---|---|---|---|
| 0 | — | — | — | 0.905 | 0.921 | 0.825 | 279.4 | 3.01 | 8.1 |
| 1 | √ | — | — | 0.924 | 0.942 | 0.851 | 322.6 | 2.21 | 6.5 |
| 2 | — | √ | — | 0.912 | 0.941 | 0.827 | 274.9 | 3.04 | 9.4 |
| 3 | — | — | √ | 0.937 | 0.944 | 0.865 | 312.0 | 2.36 | 6.5 |
| 4 | √ | √ | — | 0.927 | 0.946 | 0.848 | 264.9 | 1.73 | 6.2 |
| 5 | √ | — | √ | 0.935 | 0.938 | 0.871 | 270.9 | 1.57 | 4.9 |
| 6 | — | √ | √ | 0.942 | 0.946 | 0.879 | 252.4 | 2.36 | 7.4 |
| 7 | √ | √ | √ | 0.945 | 0.962 | 0.882 | 278.6 | 1.20 | 4.7 |
| Attention Position | mAP@0.5 | Params/106 | GLOPs |
|---|---|---|---|
| Starblock | 0.924 | 2.21 | 6.5 |
| Backbone | 0.920 | 2.30 | 6.7 |
| Head | 0.916 | 2.69 | 8.1 |
| Module | mAP@0.5 | Params/106 | GLOPs |
|---|---|---|---|
| Shared Conv | 0.914 | 2.21 | 6.5 |
| DEConv | 0.931 | 3.10 | 8.4 |
| Shared Conv + DEConv | 0.937 | 2.69 | 6.5 |
| Dataset | YOLOv8 | StarCAN-PFD | ||||
|---|---|---|---|---|---|---|
| mAP@0.5 | P | R | mAP@0.5 | P | R | |
| TT100k | 0.875 | 0.894 | 0.795 | 0.912 | 0.907 | 0.834 |
| GTSDB | 0.744 | 0.905 | 0.674 | 0.801 | 0.946 | 0.700 |
| Roadsign | 0.866 | 0.920 | 0.809 | 0.908 | 0.919 | 0.878 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, Z.; Zheng, T.; Lu, F. StarCAN-PFD: An Efficient and Simplified Multi-Scale Feature Detection Network for Small Objects in Complex Scenarios. Electronics 2024, 13, 3076. https://doi.org/10.3390/electronics13153076
Chai Z, Zheng T, Lu F. StarCAN-PFD: An Efficient and Simplified Multi-Scale Feature Detection Network for Small Objects in Complex Scenarios. Electronics. 2024; 13(15):3076. https://doi.org/10.3390/electronics13153076
Chicago/Turabian StyleChai, Zongxuan, Tingting Zheng, and Feixiang Lu. 2024. "StarCAN-PFD: An Efficient and Simplified Multi-Scale Feature Detection Network for Small Objects in Complex Scenarios" Electronics 13, no. 15: 3076. https://doi.org/10.3390/electronics13153076
APA StyleChai, Z., Zheng, T., & Lu, F. (2024). StarCAN-PFD: An Efficient and Simplified Multi-Scale Feature Detection Network for Small Objects in Complex Scenarios. Electronics, 13(15), 3076. https://doi.org/10.3390/electronics13153076