
Microservices-Based Resource Provisioning for Multi-User Cloud VR in Edge Networks


Abstract
:1. Introduction
1.1. Motivations
1.2. Contributions
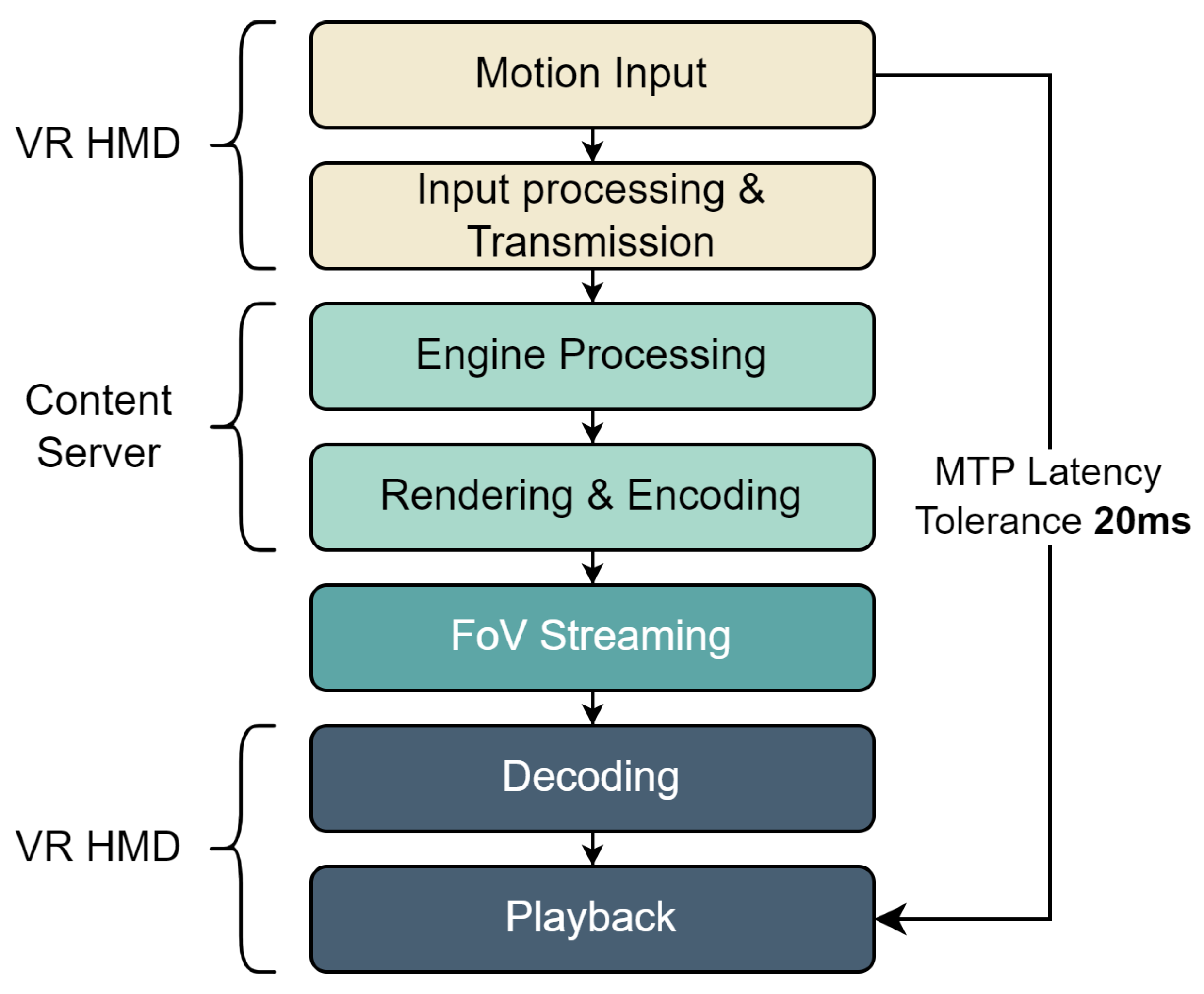
- The rendering load of the edge server inevitably increases linearly with the number of users. Continuing to respond with a single server creates a scalability issue, so we aim to solve the problem by applying MSA. The adoption of a microservices architecture yields several benefits, that are crucial for optimizing system performance and enhancing operational efficiency [24]. Tasks that require single-point processing are configured with a single microservice called an engine service. The engine service mainly aggregates multiple user inputs (actions and motions) based on timestamps and computes the results to be reflected in the next frame of the content. Tasks such as user FoV rendering are configured with a render service for each user.
- As the number of users increases, resources in the edge network might become insufficient due to the high computing resource demand of the render service, which may be placed far from the user and may not satisfy the MTP for all users. To address this, we propose a strategy to separate the microservices responsible for the rendering process into render and motion services. The render service performs most of the rendering tasks, while the motion service provides fast response times by performing only simple processing such as motion input-based video cropping on the rendered video stream. With this separation, the motion service has a relatively low computing load and is more likely to be deployed close to users, which allows for motion input processing to be performed quickly.
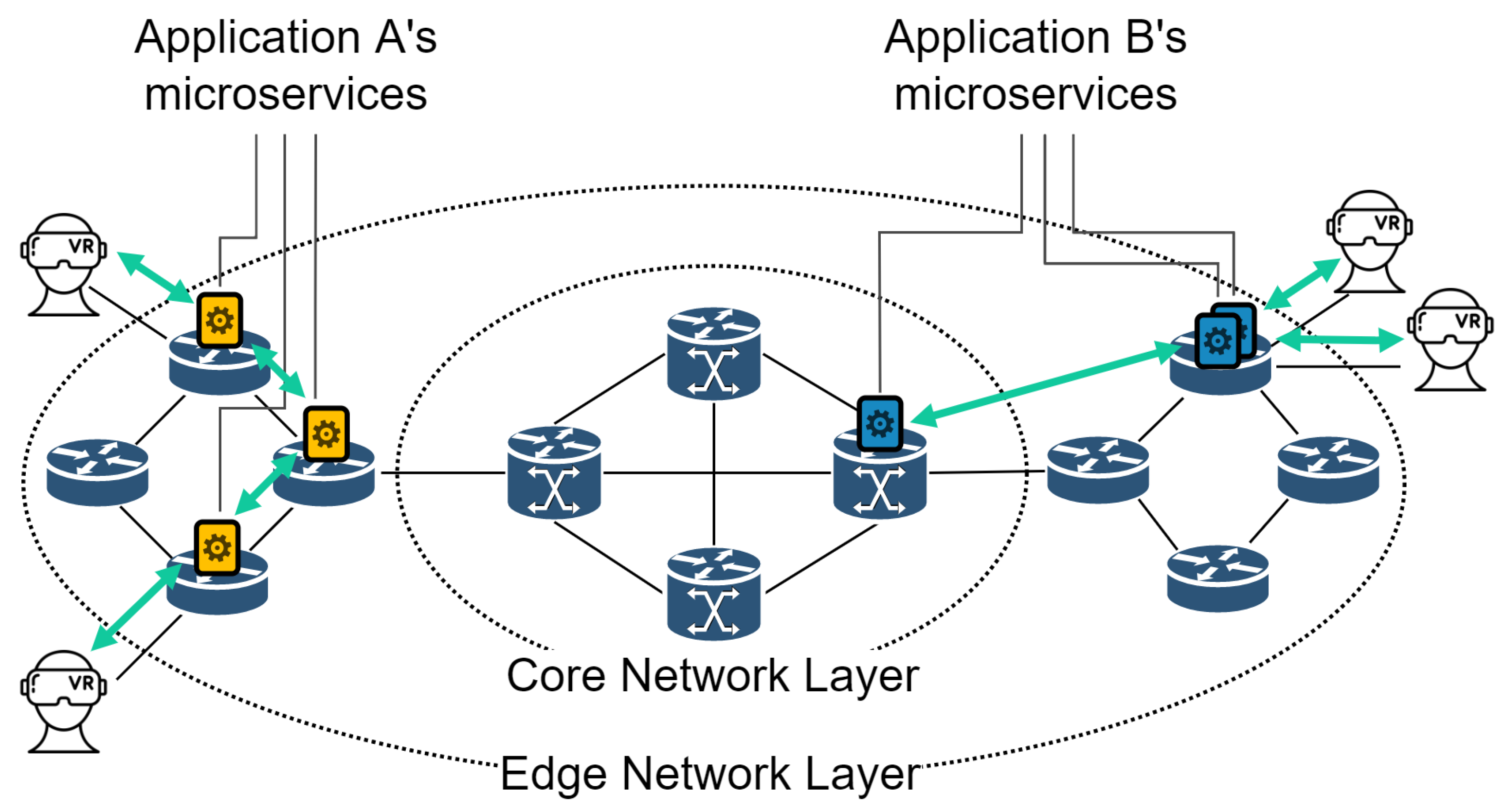
- The cloud VR application proposed in this study is assumed to be composed of microservices such as engine services, render services, and motion services. The engine service can be deployed anywhere in the network due to low CPU and GPU loads and low network bandwidth requirements. The render service typically has a high CPU and GPU load and can have high network bandwidth requirements for streaming because it carries additional information in addition to the video stream to support the motion service’s work alone. The motion service has a relatively low computational load, and the resulting FoV stream also has a relatively low network bandwidth load. The proposed scheme develops a placement plan that reflects these microservice-specific workload characteristics. We propose a strategy that allows as many users as possible to operate within the edge while balancing resources and considering the service’s characteristics as well.
2. Related Works
3. Main Algorithm
3.1. Organizing Microservices for Multi-User Cloud VR Applications
3.2. Microservice Deployment Algorithm for User MTP Latency and Computer Resource Balancing
| Algorithm 1 Microservice deployment on the edge network. |
|
3.2.1. Motion Deployment Plan Algorithm
| Algorithm 2 CreateMotionDeploymentPlan |
|
3.2.2. Render Deployment Plan Algorithm
| Algorithm 3 CreateRenderDeploymentPlan(Partial) |
|
3.2.3. Engine Deployment Plan Algorithm
| Algorithm 4 CreateEngineDeploymentPlan(Partial) |
|
4. Simulation Results
4.1. Environmental Setup
4.2. Evaluation and Discussion
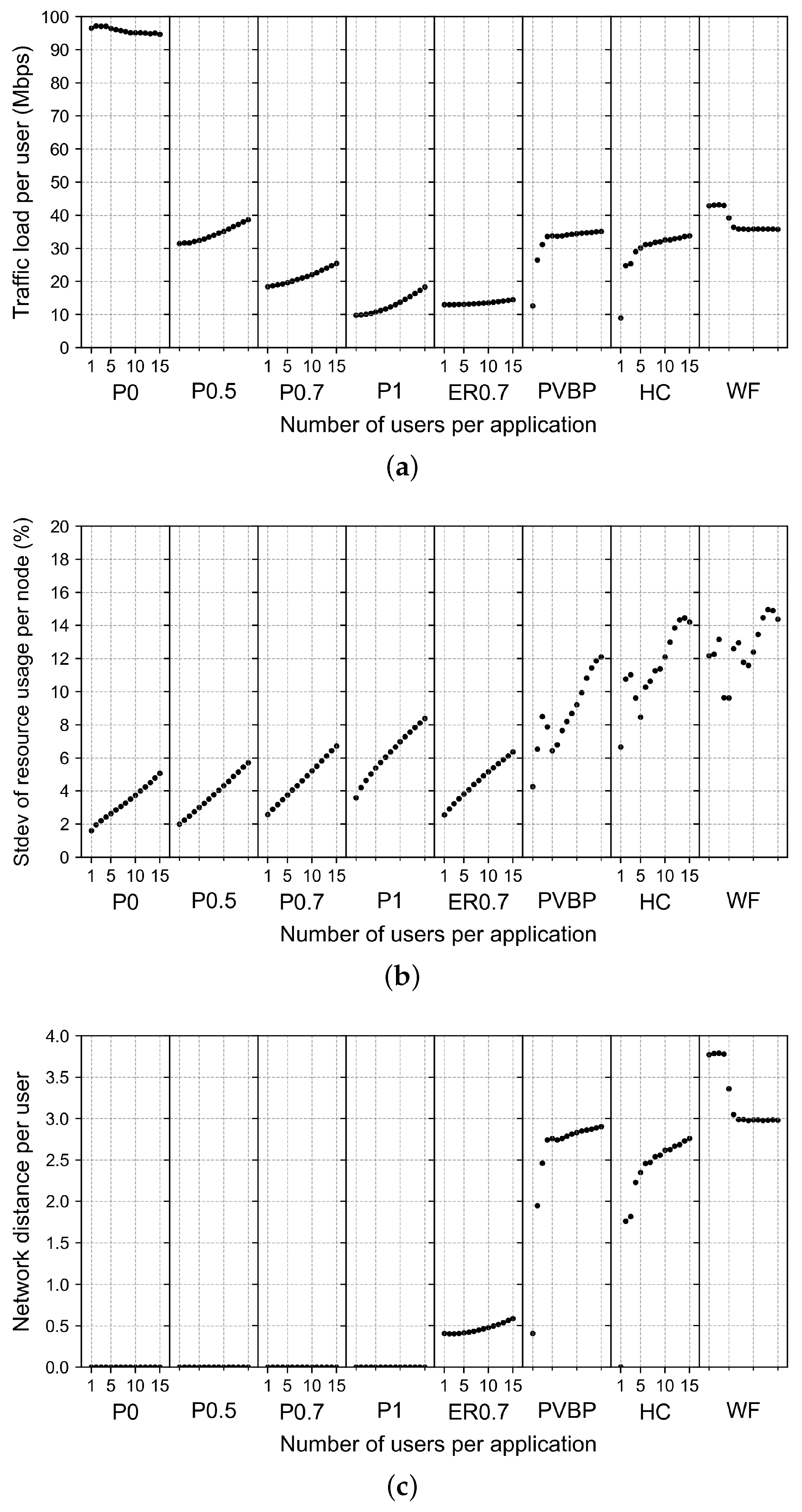
4.2.1. Effect of Changes in the Number of Users per Application
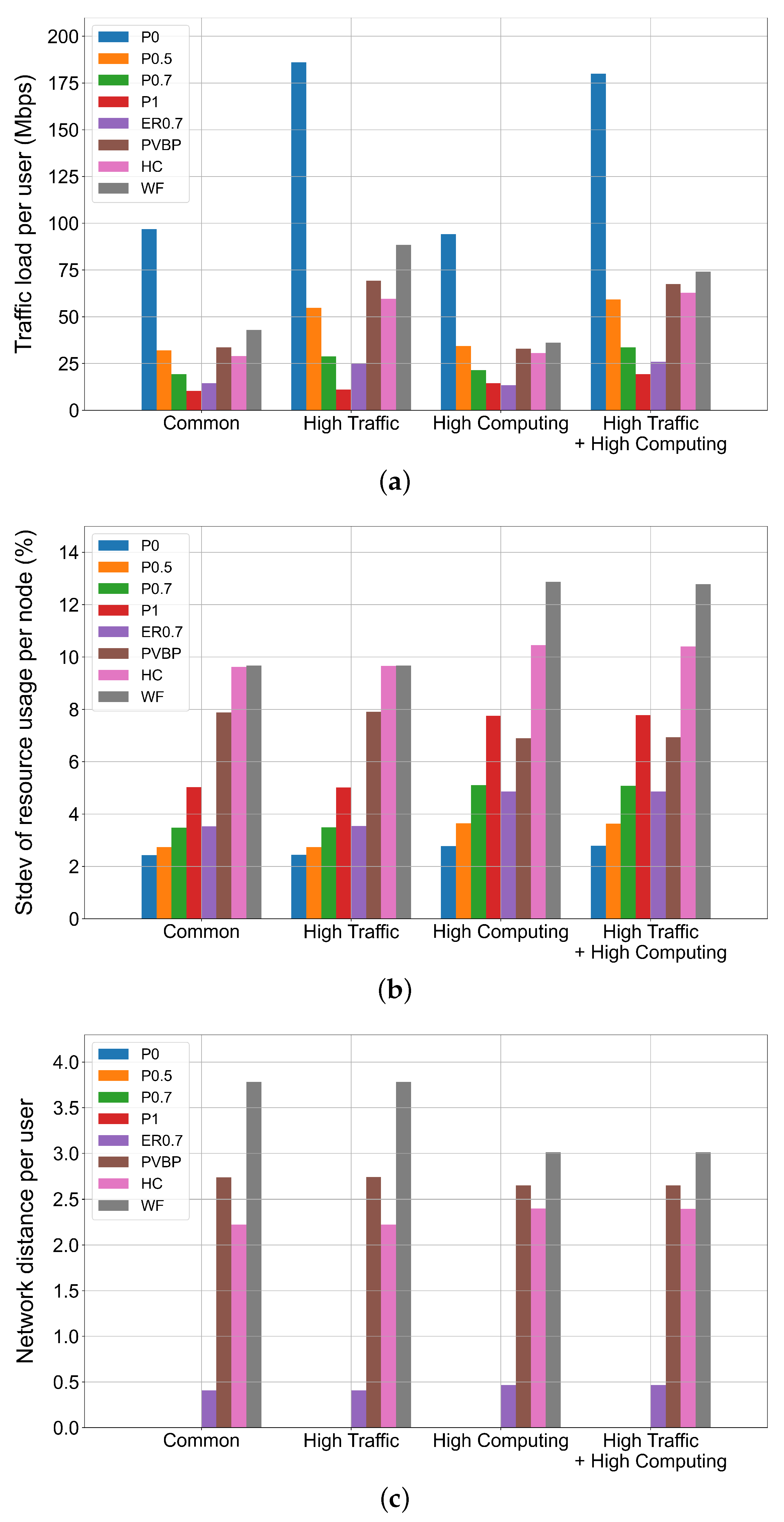
4.2.2. Effects of Resource Usage Types of Applications
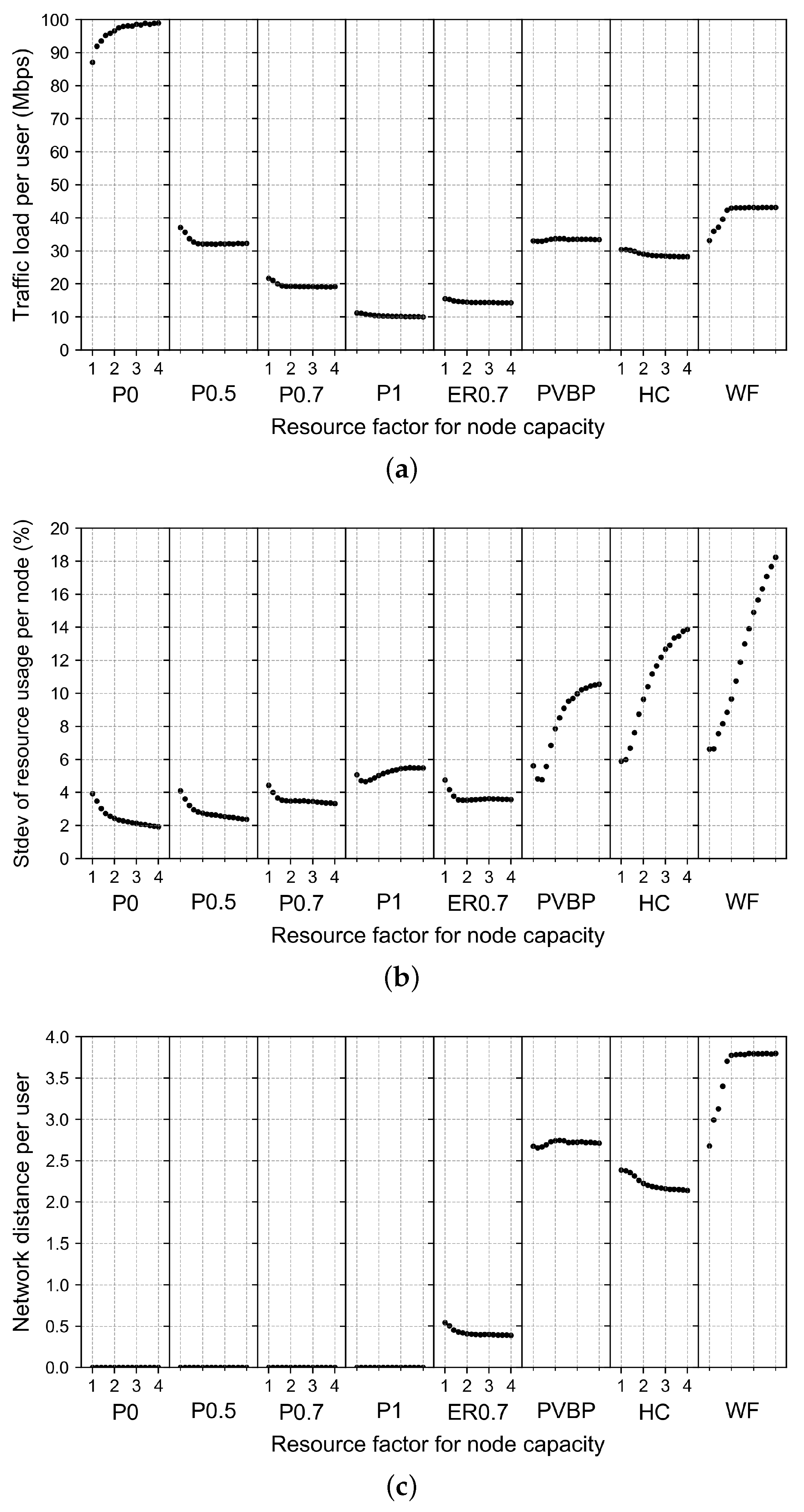
4.2.3. Effects of Changes in Computing Resource Capacity
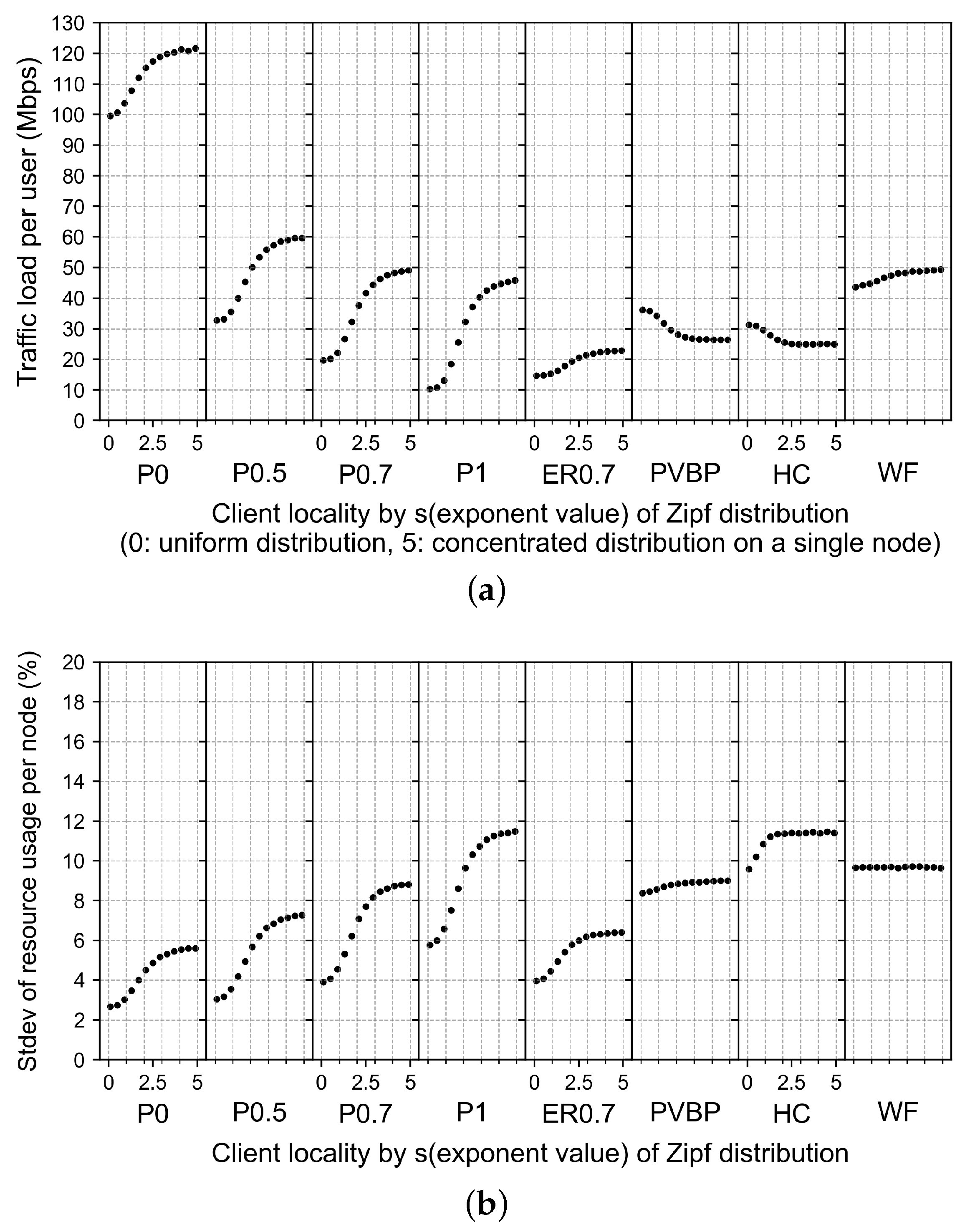
4.2.4. Effects of Changes in Client Locality
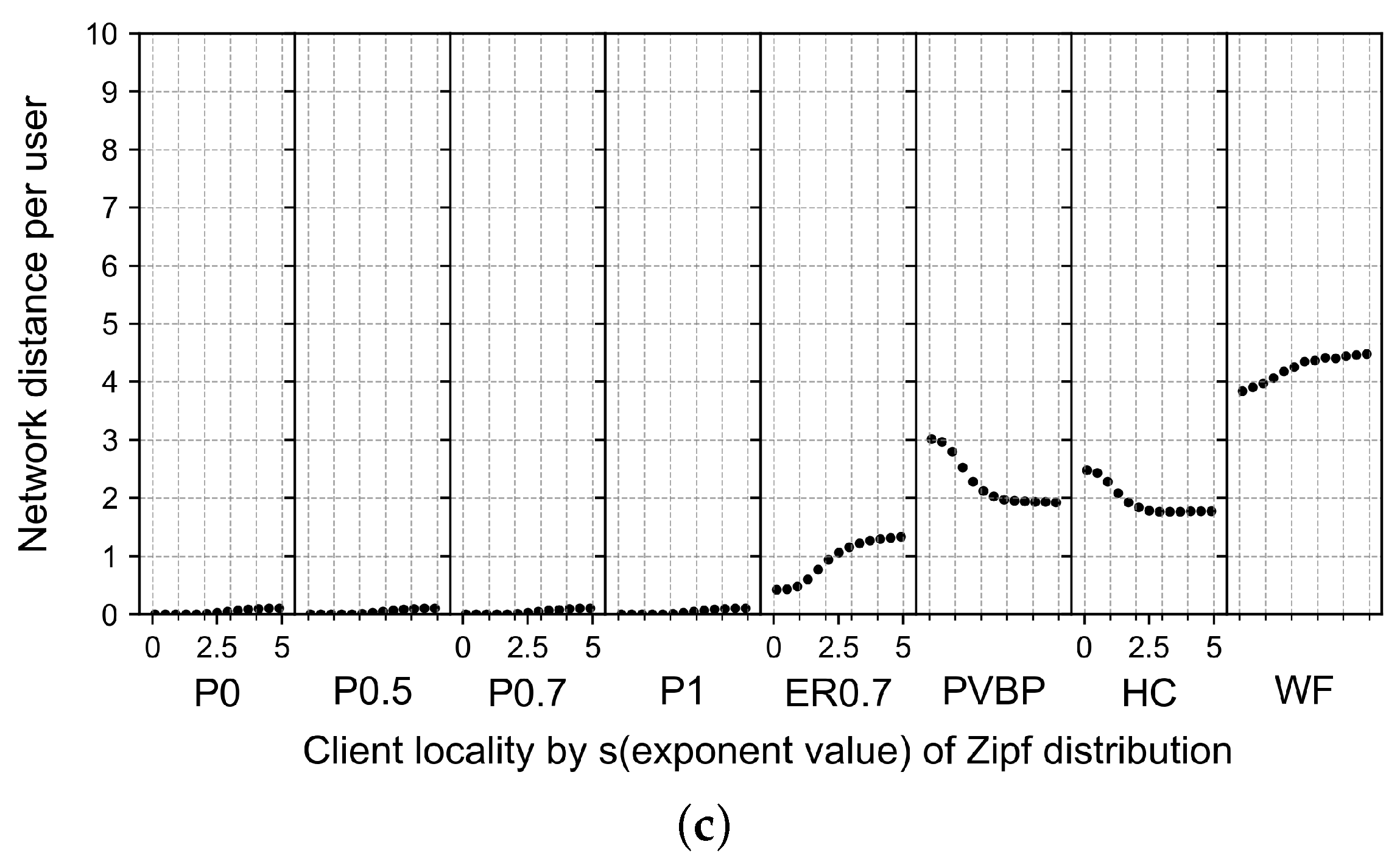
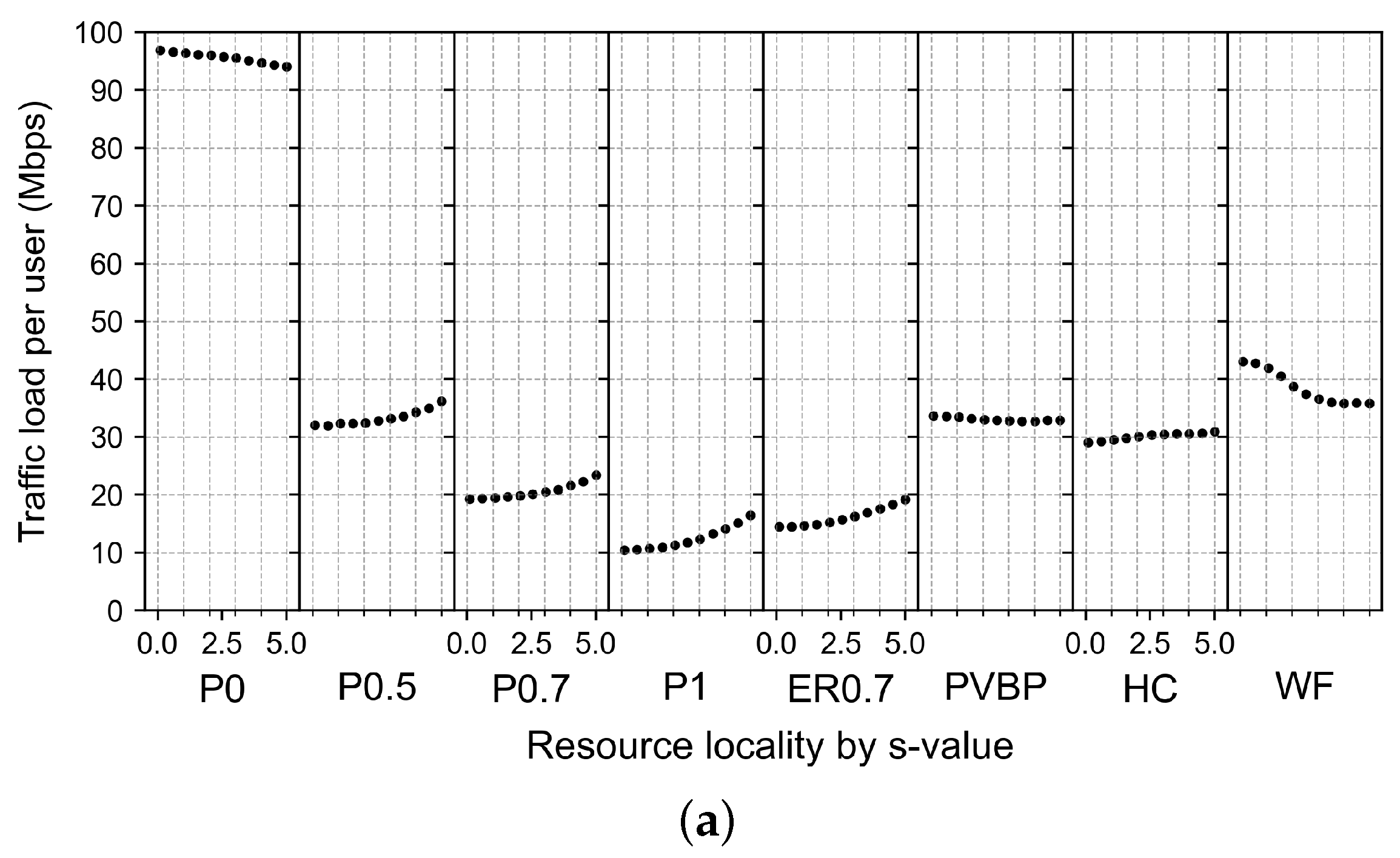
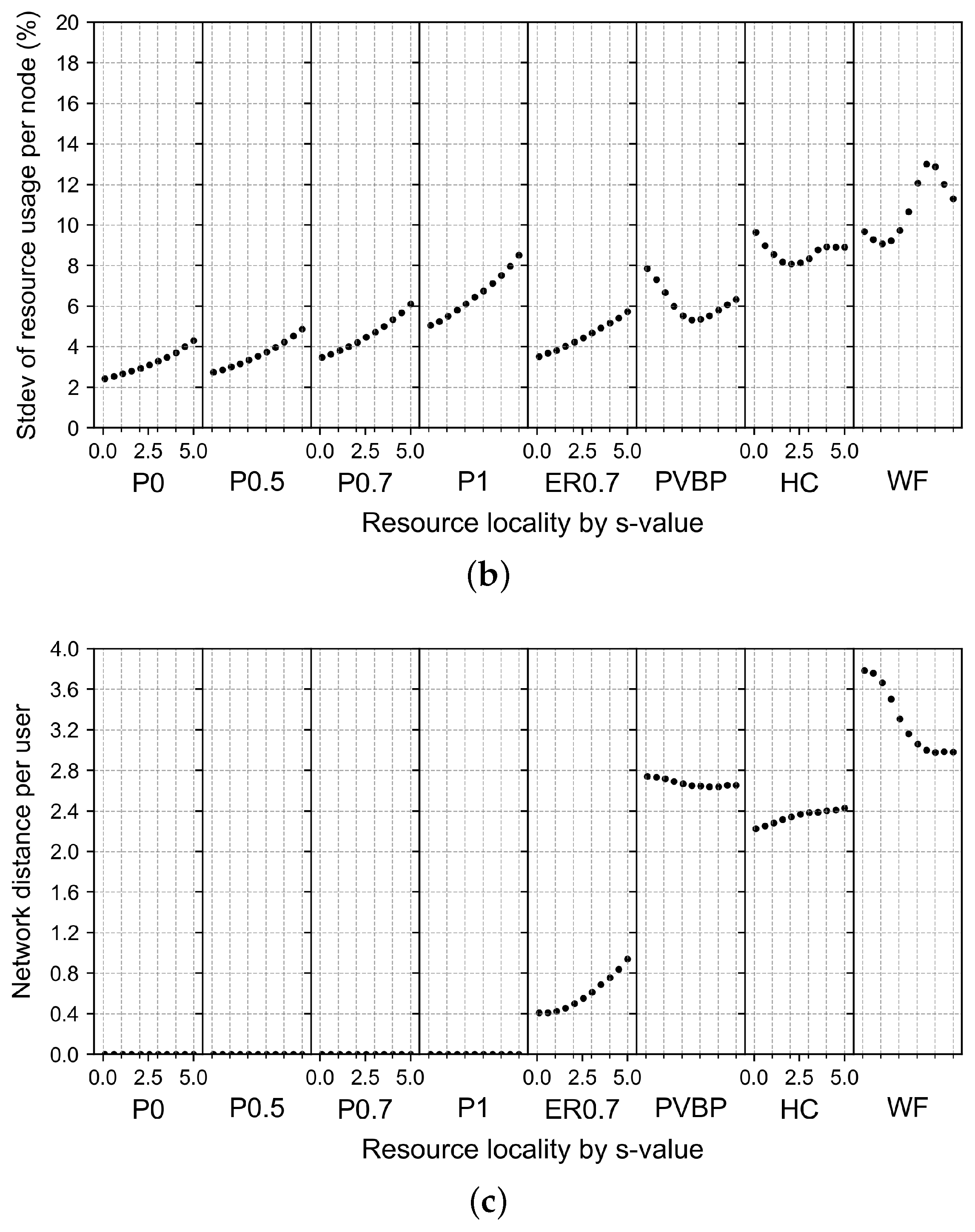
4.2.5. Effects of Changes in Computing Resource Locality
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wohlgenannt, I.; Simons, A.; Stieglitz, S. Virtual reality. Bus. Inf. Syst. Eng. 2020, 62, 455–461. [Google Scholar] [CrossRef]
- Zhao, S.; Abou-zeid, H.; Atawia, R.; Manjunath, Y.S.K.; Sediq, A.B.; Zhang, X.P. Virtual reality gaming on the cloud: A reality check. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Zou, W.; Feng, S.; Mao, X.; Yang, F.; Ma, Z. Enhancing quality of experience for cloud virtual reality gaming: An object-aware video encoding. In Proceedings of the 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, H.; Zhang, J.; Yin, X.; Zhou, K.; Pan, Z.; El Rhalibi, A. Cloud-to-end rendering and storage management for virtual reality in experimental education. Virtual Real. Intell. Hardw. 2020, 2, 368–380. [Google Scholar] [CrossRef]
- Shea, R.; Liu, J.; Ngai, E.C.H.; Cui, Y. Cloud gaming: Architecture and performance. IEEE Netw. 2013, 27, 16–21. [Google Scholar] [CrossRef]
- Kim, H.K.; Park, J.; Choi, Y.; Choe, M. Virtual reality sickness questionnaire (VRSQ): Motion sickness measurement index in a virtual reality environment. Appl. Ergon. 2018, 69, 66–73. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Jiao, L.; He, T.; Li, J.; Mühlhäuser, M. Service entity placement for social virtual reality applications in edge computing. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 468–476. [Google Scholar]
- Ahmed, E.; Rehmani, M.H. Mobile Edge Computing: Opportunities, solutions, and challenges. Future Gener. Comput. Syst. 2017, 70, 59–63. [Google Scholar] [CrossRef]
- Al-Shuwaili, A.; Simeone, O. Energy-efficient resource allocation for mobile edge computing-based augmented reality applications. IEEE Wirel. Commun. Lett. 2017, 6, 398–401. [Google Scholar] [CrossRef]
- Upadhyay, M.K.; Alam, M. Edge Computing: Architecture, Application, Opportunities, and Challenges. In Proceedings of the 2023 3rd International Conference on Technological Advancements in Computational Sciences (ICTACS), Tashkent, Uzbekistan, 1–3 November 2023; pp. 695–702. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Lähderanta, T.; Leppänen, T.; Ruha, L.; Lovén, L.; Harjula, E.; Ylianttila, M.; Riekki, J.; Sillanpää, M.J. Edge computing server placement with capacitated location allocation. J. Parallel Distrib. Comput. 2021, 153, 130–149. [Google Scholar] [CrossRef]
- Wang, L.; Jiao, L.; He, T.; Li, J.; Bal, H. Service placement for collaborative edge applications. IEEE/ACM Trans. Netw. 2020, 29, 34–47. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Wang, X.; Wang, S.; Hu, X.; Guo, S.; Qiu, T.; Hu, B.; Kwok, R.Y. Distributed and dynamic service placement in pervasive edge computing networks. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1277–1292. [Google Scholar] [CrossRef]
- He, S.; Lyu, X.; Ni, W.; Tian, H.; Liu, R.P.; Hossain, E. Virtual service placement for edge computing under finite memory and bandwidth. IEEE Trans. Commun. 2020, 68, 7702–7718. [Google Scholar] [CrossRef]
- Farhadi, V.; Mehmeti, F.; He, T.; La Porta, T.F.; Khamfroush, H.; Wang, S.; Chan, K.S.; Poularakis, K. Service placement and request scheduling for data-intensive applications in edge clouds. IEEE/ACM Trans. Netw. 2021, 29, 779–792. [Google Scholar] [CrossRef]
- Li, Y.; Gao, W. MUVR: Supporting multi-user mobile virtual reality with resource constrained edge cloud. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; pp. 1–16. [Google Scholar]
- Alhilal, A.; Braud, T.; Han, B.; Hui, P. Nebula: Reliable low-latency video transmission for mobile cloud gaming. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 3407–3417. [Google Scholar]
- Gül, S.; Podborski, D.; Buchholz, T.; Schierl, T.; Hellge, C. Low-latency cloud-based volumetric video streaming using head motion prediction. In Proceedings of the 30th ACM Workshop on Network and Operating Systems Support for Digital Audio and Video, Istanbul, Turkey, 10–11 June 2020; pp. 27–33. [Google Scholar]
- Saleem, U.; Liu, Y.; Jangsher, S.; Li, Y.; Jiang, T. Mobility-aware joint task scheduling and resource allocation for cooperative mobile edge computing. IEEE Trans. Wirel. Commun. 2020, 20, 360–374. [Google Scholar] [CrossRef]
- Zhang, Q.; Gui, L.; Hou, F.; Chen, J.; Zhu, S.; Tian, F. Dynamic task offloading and resource allocation for mobile-edge computing in dense cloud RAN. IEEE Internet Things J. 2020, 7, 3282–3299. [Google Scholar] [CrossRef]
- Alencar, D.; Both, C.; Antunes, R.; Oliveira, H.; Cerqueira, E.; Rosário, D. Dynamic Microservice Allocation for Virtual Reality Distribution with QoE Support. IEEE Trans. Netw. Serv. Manag. 2022, 19, 729–740. [Google Scholar] [CrossRef]
- Rigazzi, G.; Kainulainen, J.P.; Turyagyenda, C.; Mourad, A.; Ahn, J. An edge and fog computing platform for effective deployment of 360 video applications. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference Workshop (WCNCW), Marrakech, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar]
- Rodríguez-Alonso, C.; Pena-Regueiro, I.; García, Ó. Digital Twin Platform for Water Treatment Plants Using Microservices Architecture. Sensors 2024, 24, 1568. [Google Scholar] [CrossRef] [PubMed]
- Kim, W.S. Progressive Traffic-Oriented Resource Management for Reducing Network Congestion in Edge Computing. Entropy 2021, 23, 532. [Google Scholar] [CrossRef]
- Du, J.; Shi, Y.; Zou, Z.; Zhao, D. CoVR: Cloud-based multiuser virtual reality headset system for project communication of remote users. J. Constr. Eng. Manag. 2018, 144, 04017109. [Google Scholar] [CrossRef]
- Hou, X.; Lu, Y.; Dey, S. Wireless VR/AR with edge/cloud computing. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–8. [Google Scholar]
- Hu, P.; Ning, H.; Qiu, T.; Zhang, Y.; Luo, X. Fog computing based face identification and resolution scheme in internet of things. IEEE Trans. Ind. Inform. 2016, 13, 1910–1920. [Google Scholar] [CrossRef]
- Xu, Y.; Mahendran, V.; Radhakrishnan, S. SDN docker: Enabling application auto-docking/undocking in edge switch. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 864–869. [Google Scholar]
- Alam, M.; Rufino, J.; Ferreira, J.; Ahmed, S.H.; Shah, N.; Chen, Y. Orchestration of microservices for iot using docker and edge computing. IEEE Commun. Mag. 2018, 56, 118–123. [Google Scholar] [CrossRef]
- Velasquez, K.; Abreu, D.P.; Curado, M.; Monteiro, E. Service placement for latency reduction in the internet of things. Ann. Telecommun. 2017, 72, 105–115. [Google Scholar] [CrossRef]
- Taneja, M.; Davy, A. Resource aware placement of IoT application modules in Fog-Cloud Computing Paradigm. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 1222–1228. [Google Scholar]
- Zhang, J.; Li, X.; Zhang, X.; Xue, Y.; Srivastava, G.; Dou, W. Service offloading oriented edge server placement in smart farming. Softw. Pract. Exp. 2021, 51, 2540–2557. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, Y.; Xu, J.; Yuan, J.; Hsu, C.H. Edge server placement in mobile edge computing. J. Parallel Distrib. Comput. 2019, 127, 160–168. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S. An energy-aware edge server placement algorithm in mobile edge computing. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018; pp. 66–73. [Google Scholar]
- Wang, L.; Deng, X.; Gui, J.; Chen, X.; Wan, S. Microservice-Oriented Service Placement for Mobile Edge Computing in Sustainable Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10012–10026. [Google Scholar] [CrossRef]
- Ma, X.; Zhou, A.; Zhang, S.; Wang, S. Cooperative service caching and workload scheduling in mobile edge computing. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 2076–2085. [Google Scholar]
- Yang, M.; Zhang, J.; Yu, L. Perceptual tolerance to motion-to-photon latency with head movement in virtual reality. In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; pp. 1–5. [Google Scholar]
- Mangiante, S.; Klas, G.; Navon, A.; GuanHua, Z.; Ran, J.; Silva, M.D. Vr is on the edge: How to deliver 360 videos in mobile networks. In Proceedings of the Workshop on Virtual Reality and Augmented Reality Network, Los Angeles, CA, USA, 25 August 2017; pp. 30–35. [Google Scholar]
- Navrotsky, Y.; Patsei, N. Zipf’s distribution caching application in named data networks. In Proceedings of the 2021 IEEE Open Conference of Electrical, Electronic and Information Sciences (Estream), Vilnius, Lithuania, 22 April 2021; pp. 1–4. [Google Scholar]
- Wu, Z.; Deng, Y.; Feng, H.; Zhou, Y.; Min, G.; Zhang, Z. Blender: A container placement strategy by leveraging zipf-like distribution within containerized data centers. IEEE Trans. Netw. Serv. Manag. 2021, 19, 1382–1398. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Works | Subject | Limitations |
|---|---|---|
| Alencar et al. [22] Rigazzi et al. [23] | Microservice-based VR system | Insufficient consideration of the computing resource requirements |
| Zhao et al. [2] Du et al. [26] Hou et al. [27] | Cloud-based VR headset system | A single user or a small number of users |
| Hu et al. [28] | Edge-based face recognition system | Only focuses on applications |
| Xu et al. [29] Alam et al. [30] | Fog server deployment | Insufficient consideration of edge server deployment location |
| Velasquez et al. [31] Taneja et al. [32] Zhang et al. [33] Wang et al. [34] Li et al. [35] | Service placement architecture for IoT environments | Insufficient consideration of the computing resource requirements |
| Wang et al. [36] Ma et al. [37] | Microservice-oriented service placement mechanism | Insufficient consideration of the latency requirements |
| Subject | Consideration | |
| Current work | Microservice-based cloud VR microservice deployment | Consideration of the latency requirements, the computing resources, and the multiple users |
| Type | CPU | Memory | GPU | Traffic |
|---|---|---|---|---|
| Engine | [10, 20] | [10, 40] | [10, 20] | [0.1, 1] |
| Render | [50, 80] | [40, 80] | [80, 160] | [20, 30] |
| Motion | [10, 20] | [10, 40] | [10, 20] | [7, 10] |
| Type | CPU | Memory | GPU |
|---|---|---|---|
| Common | [200, 400] | [250, 500] | [400, 800] |
| High-end | [800, 1600] | [1000, 2000] | [1600, 3200] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.-J.; Komuro, N.; Kim, W.-S. Microservices-Based Resource Provisioning for Multi-User Cloud VR in Edge Networks. Electronics 2024, 13, 3077. https://doi.org/10.3390/electronics13153077
Choi H-J, Komuro N, Kim W-S. Microservices-Based Resource Provisioning for Multi-User Cloud VR in Edge Networks. Electronics. 2024; 13(15):3077. https://doi.org/10.3390/electronics13153077
Chicago/Turabian StyleChoi, Ho-Jin, Nobuyoshi Komuro, and Won-Suk Kim. 2024. "Microservices-Based Resource Provisioning for Multi-User Cloud VR in Edge Networks" Electronics 13, no. 15: 3077. https://doi.org/10.3390/electronics13153077