
TLDM: An Enhanced Traffic Light Detection Model Based on YOLOv5


Abstract
:1. Introduction
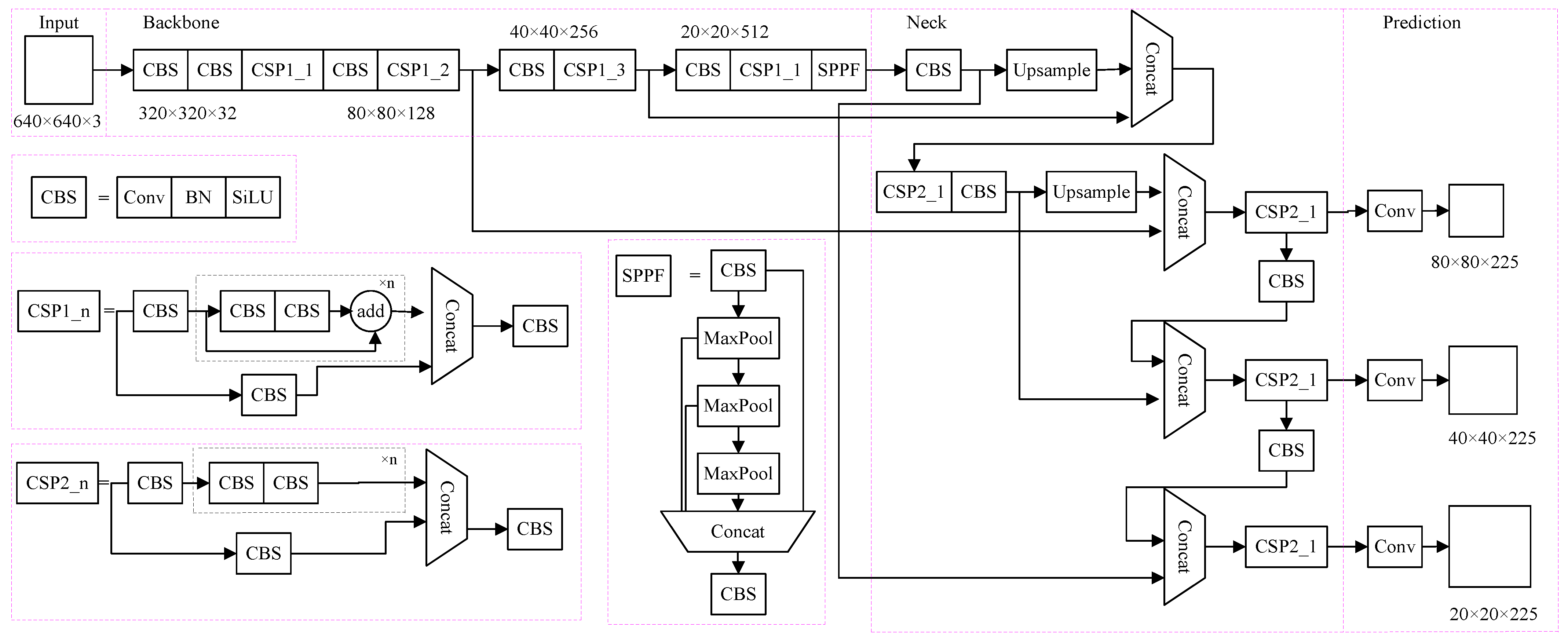
2. YOLOv5 Network Structure
2.1. Input
2.2. Backbone
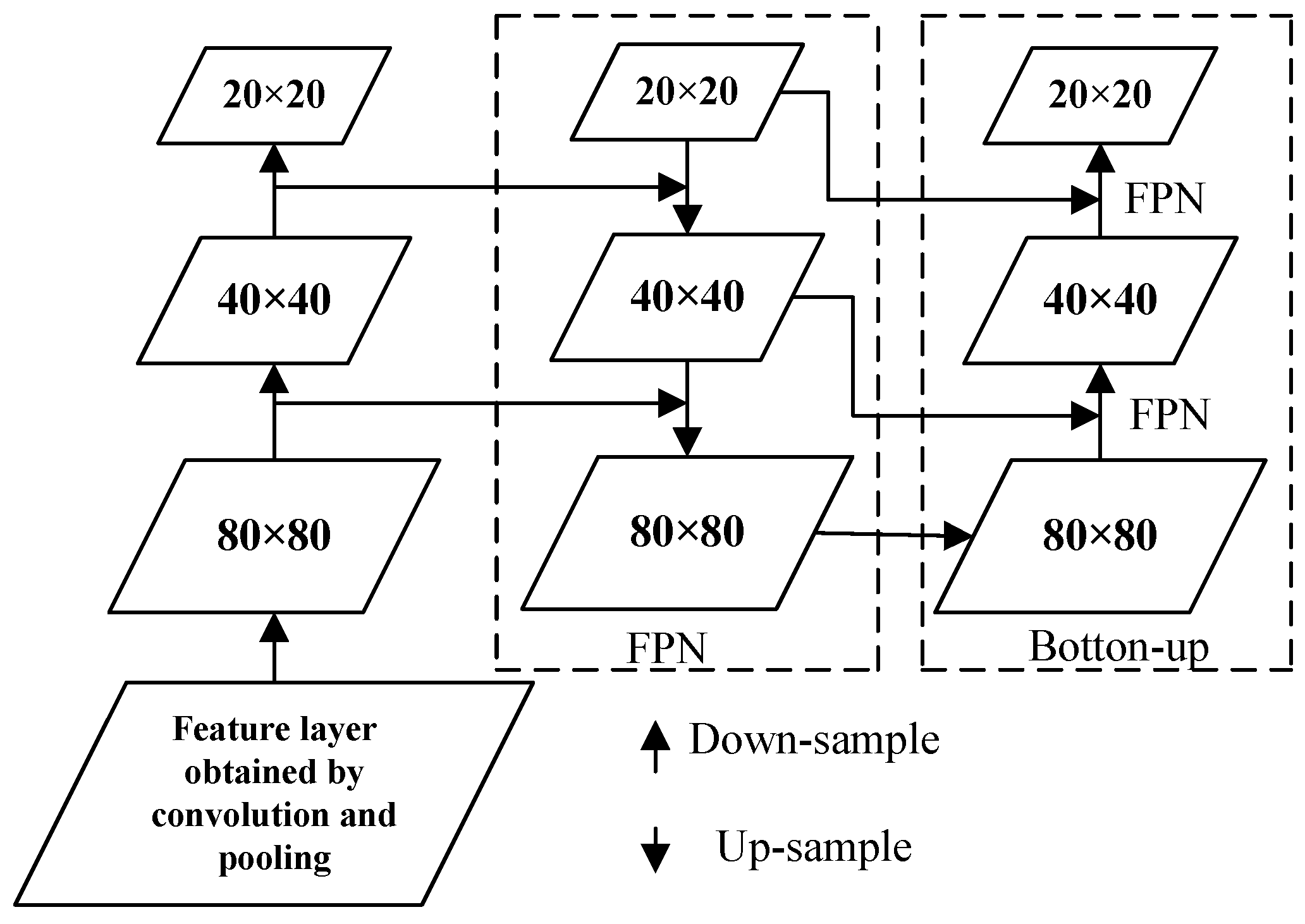
2.3. Neck
2.4. Prediction
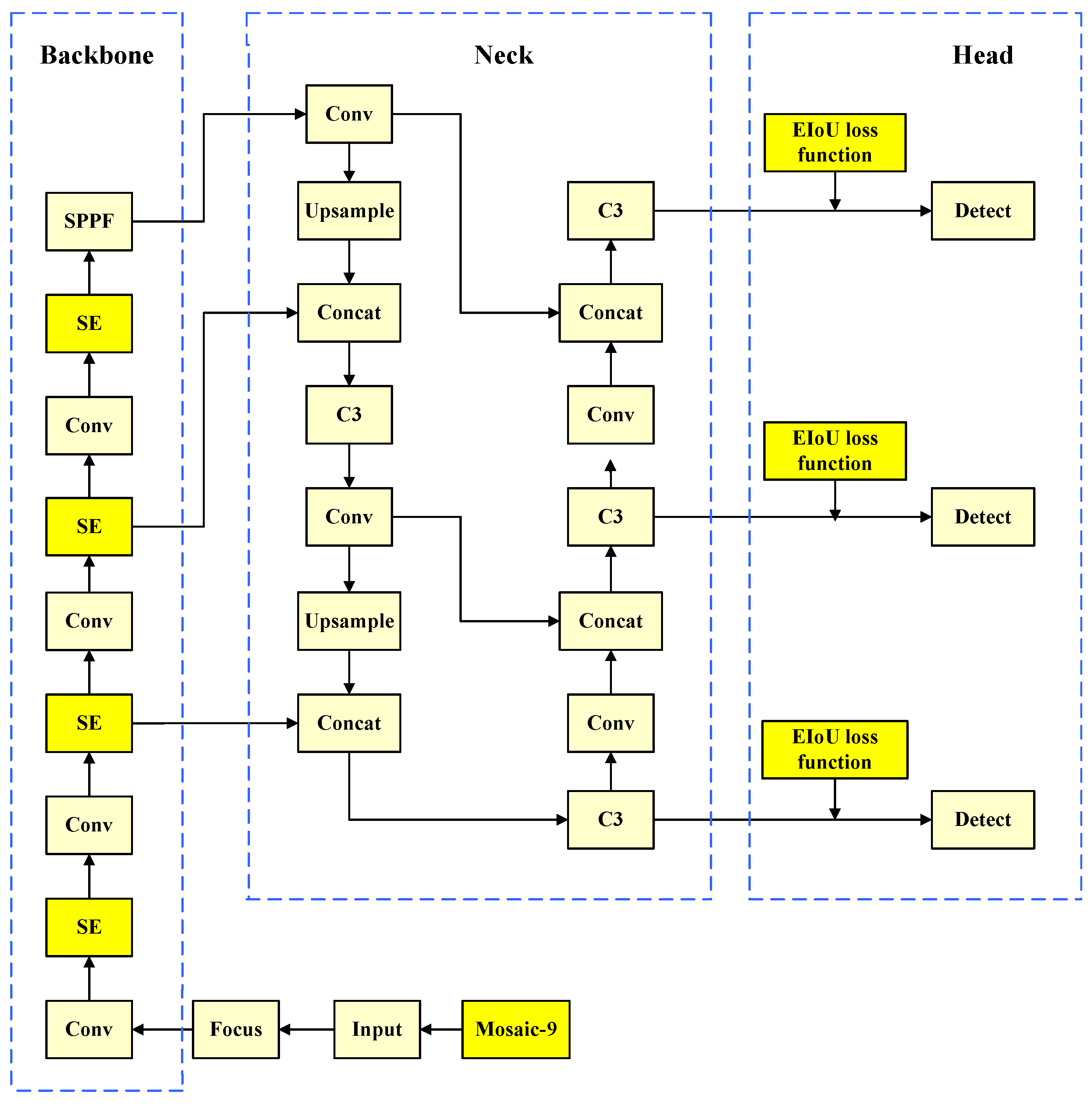
3. Improved YOLOv5 Model
3.1. Data Enhancement
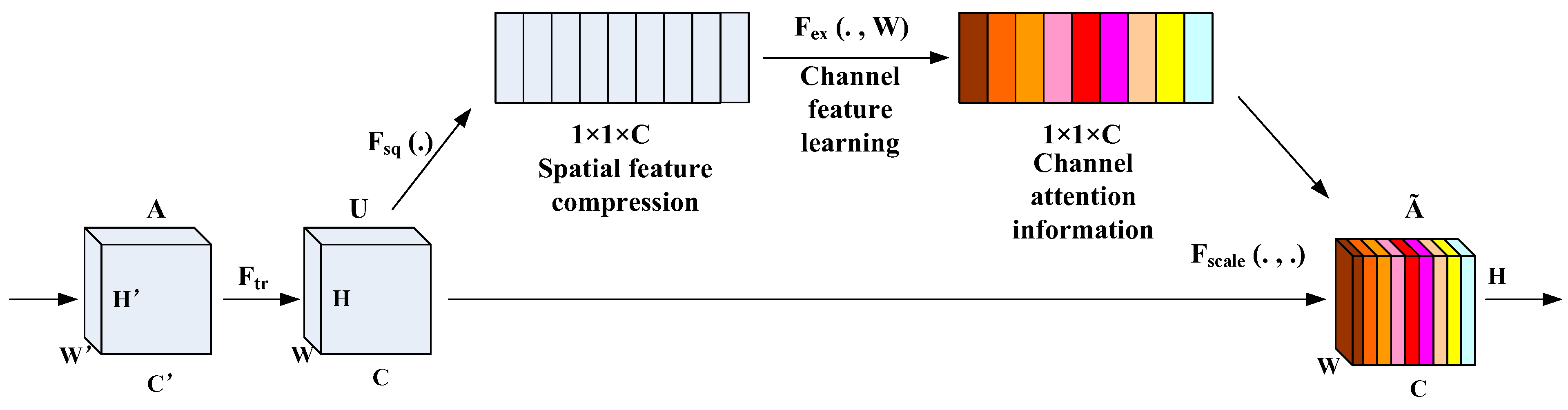
3.2. Squeeze-and-Excitation (SE) Attention Mechanism
3.3. EIoU_Loss Function
4. Experimental Results and Analysis
4.1. Collection of Datasets
4.2. Experimental Environment and Evaluation Index
4.2.1. Experimental Environment and Parameter Configuration
4.2.2. Evaluation Index
4.3. Analysis of Experimental Results
4.3.1. Ablation Experiment
4.3.2. Contrast Experiment
4.3.3. Comparison of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.H.; Wang, Y.S. Modular Learning: Agile Development of Robust Traffic Sign Recognition. IEEE Trans. Intell. Veh. 2024, 9, 764–774. [Google Scholar] [CrossRef]
- Wang, Q.; Li, X.; Lu, M. An Improved Traffic Sign Detection and Recognition Deep Model Based on YOLOv5. IEEE Access 2023, 11, 54679–54691. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Ji, X.; Dong, Z.; Gao, M.; Lai, C.S. Vehicle-Mounted Adaptive Traffic Sign Detector for Small-Sized Signs in Multiple Working Conditions. IEEE Trans. Intell. Transp. Syst. 2024, 25, 710–724. [Google Scholar] [CrossRef]
- Dharnesh, K.; Prramoth, M.M.; Sivabalan, M.A.; Sivraj, P. Performance Comparison of Road Traffic Sign Recognition System Based on CNN and Yolov5. In Proceedings of the 2023 Innovations in Power and Advanced Computing Technologies (i-PACT), Kuala Lumpur, Malaysia, 8–10 December 2023; pp. 1–6. [Google Scholar]
- Chen, Y.; Chungui, L.; Bo, H. An improved feature point extraction algorithm for field navigation. J. Guangxi Univ. Technol. 2018, 29, 71–76. [Google Scholar]
- Omachi, M.; Omachi, S. Traffic Light Detection with Color and Edge Information. In Proceedings of the IEEE International Conference on Computer Science and Information Technology, Beijing, China, 8–11 August 2009; pp. 284–287. [Google Scholar]
- Wang, X.; Cheng, X.; Wu, X.; Zhou, H.; Chen, X.; Wang, L. Design of traffic light identification scheme based on TensorFlow and HSV color space. J. Phys. Conf. Ser. 2018, 1074, 012081. [Google Scholar] [CrossRef]
- Zhu, Z.; Li, C.; Li, W.; Huang, W. The defect detection algorithm of vehicle injector seat based on Faster R-CNN model is improved. J. Guangxi Univ. Technol. 2020, 31, 1–10. [Google Scholar]
- Tian, Y.; Gelernter, J.; Wang, X.; Chen, W.; Gao, J.; Zhang, Y.; Li, X. Lane marking detection via deep convolutional neural network. Neurocomputing 2018, 280, 46–55. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Pan, W.; Chen, Y.; Liu, B.; Shi, H. Traffic light detection and recognition based on Faster-RCNN. Sens. Micro-Syst. 2019, 38, 147–149+160. [Google Scholar]
- Li, H. Research on Traffic Signal Detection Algorithm Based on Deep Learning in Complex Environment. Master’s thesis, Zhengzhou University, Zhengzhou, China, 2018.
- Qian, H.; Wang, L.; Mou, H. Fast detection and identification of traffic lights based on deep learning. Comput. Sci. 2019, 46, 272–278. [Google Scholar]
- Ju, M.R.; Luo, H.B.; Wang, Z.B.; He, M.; Chang, Z.; Hui, B. Improved YOLOv3 algorithm and its application in small target detection. Acta Opt. 2019, 39, 253–260. [Google Scholar]
- Yan, S.; Liu, X.; Qian, W.; Chen, Q. An end-to-end traffic light detection algorithm based on deep learning. In Proceedings of the 2021 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Chengdu, China, 18–20 June 2021; pp. 370–373. [Google Scholar]
- Garg, H.; Bhartee, A.K.; Rai, A.; Kumar, M.; Dhakrey, A. A Review of Object Detection Algorithms for Autonomous Vehicles: Trends and Developments. In Proceedings of the 5th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 15–16 December 2023; pp. 1173–1181. [Google Scholar]
- Zhang, C.; Hu, X.; Niu, H. Research on vehicle target detection based on improved YOLOv5. J. Sichuan Univ. (Nat. Sci. Ed.) 2022, 59, 79–87. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, P.; Huang, H.; Wang, M. Complex road target detection algorithm based on improved YOLOv5. Comput. Eng. Appl. 2022, 58, 81–92. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–23 June 2018; pp. 7132–7141. [Google Scholar]
- Cira, C.-I.; Díaz-Álvarez, A.; Serradilla, F.; Manso-Callejo, M. Convolutional Neural Networks Adapted for Regression Tasks: Predicting the Orientation of Straight Arrows on Marked Road Pavement Using Deep Learning and Rectified Orthophotography. Electronics 2023, 12, 3980. [Google Scholar] [CrossRef]
- Guo, S.; Li, L.; Guo, T.; Cao, Y.; Li, Y. Research on Mask-Wearing Detection Algorithm Based on Improved YOLOv5. Sensors 2022, 22, 4933. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label Category | Red | Green | Yellow |
|---|---|---|---|
| number | 758 | 740 | 689 |
| Configuration Name | Version Parameter |
|---|---|
| Operating system | Window 10 |
| Deep learning framework | Pytorch 1.12.1 |
| GPU | NVIDIA GeForce GTX 1650 |
| CUDA | 11.4.0 |
| Programming language | Python 3.9.2 |
| Epochs | Batch_Size | Initial Learning Rate |
|---|---|---|
| 400 | 8 | 0.01 |
| Experiment | Model | Precision (P)/% | Recall (R)/% | mAP/% | FPS/frame ∗ s−1 |
|---|---|---|---|---|---|
| Experiment 1 | YOLOv5 | 93.6 | 92.2 | 93.1 | 53 |
| Experiment 2 | YOLOv5+Mosaic-9 | 96.6 | 97.3 | 97.2 | 65 |
| Experiment 3 | YOLOv5+Mosaic-9+SE | 97.6 | 98.2 | 98.1 | 67 |
| Experiment 4 | YOLOv5+Mosaic-9+SE+EIoU | 99.5 | 98.9 | 99.4 | 74 |
| Models | mAP/% | FPS/Frame ∗ s−1 | Params/MB |
|---|---|---|---|
| Faster R-CNN | 91.5 | 53 | 74.4 |
| YOLOv3 | 92.6 | 58 | 68.4 |
| YOLOv4 | 92.1 | 67 | 50 |
| SSD | 93.5 | 75 | 43.5 |
| YOLOv6 | 98.2 | 73 | 41.3 |
| YOLOv7 | 99.3 | 73 | 41.5 |
| Our improved algorithm | 99.4 | 74 | 42.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Hu, T.; Gong, Z.; Zhang, Y.; Cui, M. TLDM: An Enhanced Traffic Light Detection Model Based on YOLOv5. Electronics 2024, 13, 3080. https://doi.org/10.3390/electronics13153080
Song J, Hu T, Gong Z, Zhang Y, Cui M. TLDM: An Enhanced Traffic Light Detection Model Based on YOLOv5. Electronics. 2024; 13(15):3080. https://doi.org/10.3390/electronics13153080
Chicago/Turabian StyleSong, Jun, Tong Hu, Zhengwei Gong, Youcheng Zhang, and Mengchao Cui. 2024. "TLDM: An Enhanced Traffic Light Detection Model Based on YOLOv5" Electronics 13, no. 15: 3080. https://doi.org/10.3390/electronics13153080