

Lightweight Water Surface Object Detection Network for Unmanned Surface Vehicles
Abstract
:1. Introduction
- The C2F-E module is designed and employed to reconstruct the backbone network using the gradient path design strategy and the ELAN structure. The introduction of more enriched feature extraction levels not only reduces the parameters and computational load of the backbone network but also enhances the overall detection performance of the model.
- The feature fusion network structure has been redesigned, incorporating the bidirectional feature pyramid design and introducing lower-level features for multi-level fusion. The improved structure significantly enhances the fusion capability of features at different scales, thereby greatly improving the model detection accuracy.
- A comparative study is conducted on the impact of different channel numbers at high and low levels on the feature fusion of the Concat module, reaching preliminary conclusions.
- The weighted intersection over union (WIOU) accelerates model convergence, enhancing model accuracy without increasing computational load or inference speed.
2. Related Work
2.1. Surface Target Detection Based on Deep Learning
2.2. Guidelines for Target Detection Model Design
3. Methods
3.1. C2F-E Module and the Redesigned Backbone Network
3.2. Multi-Scale Feature Fusion Network
3.3. WIOU Loss Function
4. Dataset and Training Strategy
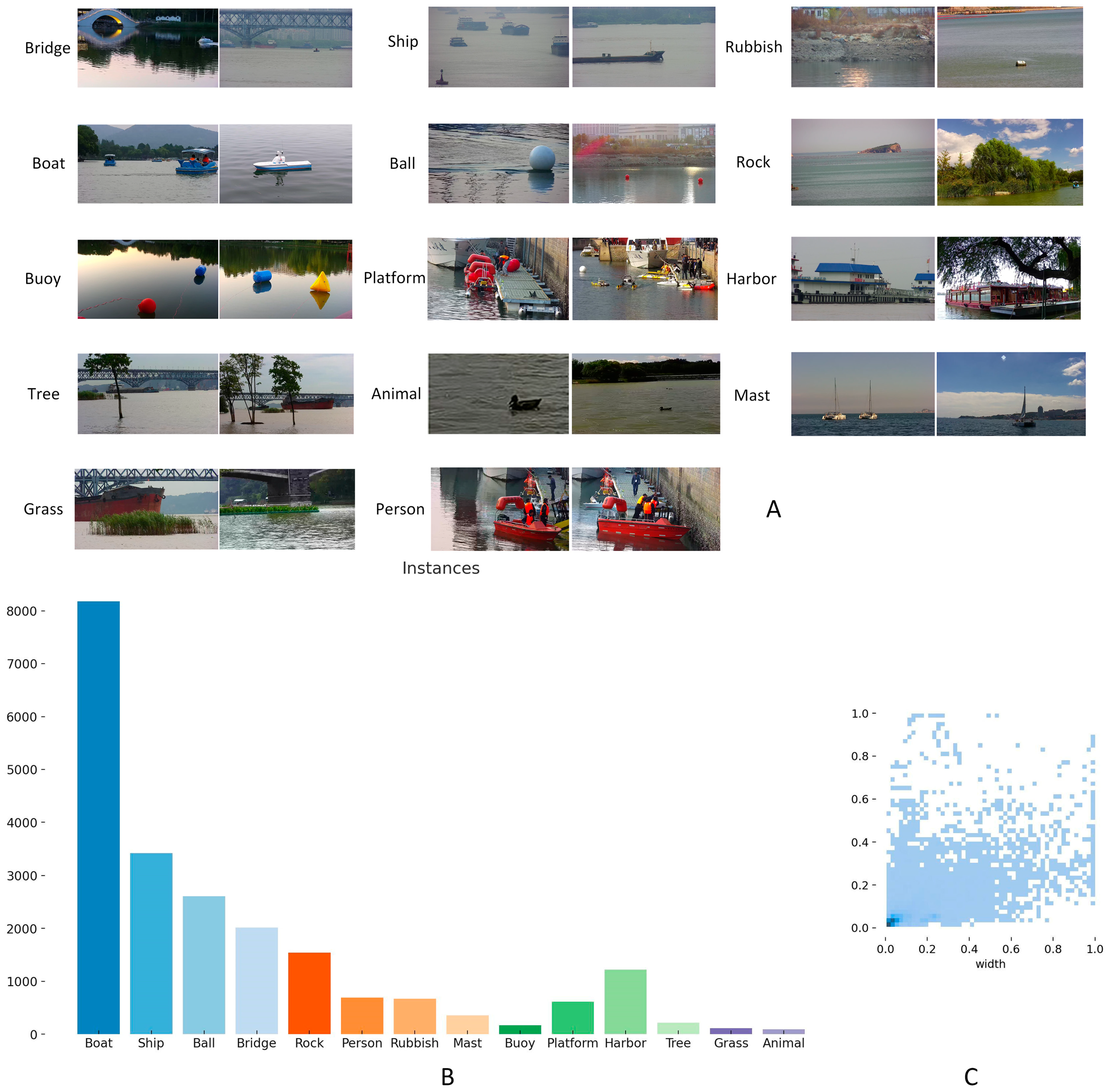
4.1. Dataset
4.2. Experiment Environment and Parameters
4.3. Model Evaluation Metrics
5. Experiment
5.1. Comparison of Lightweight Object Detection Algorithms
5.2. Comparative Experiment of the Neck Section
5.3. Cross-Dataset Validation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qi, Q.; Li, K.; Zheng, H.; Gao, X.; Hou, G.; Sun, K. SGUIE-Net: Semantic attention guided underwater image enhancement with multi-scale perception. IEEE Trans. Image Process. 2022, 31, 6816–6830. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control. 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Specht, C.; Świtalski, E.; Specht, M. Application of an autonomous/unmanned survey vessel (ASV/USV) in bathymetric measurements. Polish Marit. Res. 2017, 24, 36–44. [Google Scholar] [CrossRef]
- Tanakitkorn, K. A review of unmanned surface vehicle development. Marit. Technol. Res. 2019, 1, 2–8. [Google Scholar] [CrossRef]
- Campbell, S.; Naeem, W.; Irwin, G.W. A review on improving the autonomy of unmanned surface vehicles through intelligent collision avoidance manoeuvres. Annu. Rev. Control. 2012, 36, 267–283. [Google Scholar] [CrossRef]
- Fefilatyev, S.; Goldgof, D.; Shreve, M.; Lembke, C. Detection and tracking of ships in open sea with rapidly moving buoy-mounted camera system. Ocean Eng. 2012, 54, 1–12. [Google Scholar] [CrossRef]
- Liu, P.; Wang, G.; Qi, H.; Zhang, C.; Zheng, H.; Yu, Z. Underwater image enhancement with a deep residual framework. IEEE Access 2019, 7, 94614–94629. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Jiang, Z.; Wang, R. Underwater Object Detection Based on Improved Single Shot Multibox Detector. In Proceedings of the 2020 3rd International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 24–26 December 2021; pp. 1–7. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Moosbauer, S.; König, D.; Jäkel, J.; Teutsch, M. A Benchmark for Deep Learning Based Object Detection in Maritime Environments. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 916–925. [Google Scholar]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. Seaships: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Zhou, Z.; Sun, J.; Yu, J.; Liu, K.; Duan, J.; Chen, L.; Chen, C.L.P. An image-based benchmark dataset and a novel object detector for water surface object detection. Front. Neurorobot. 2021, 15, 723336. [Google Scholar] [CrossRef] [PubMed]
- Zou, Y.; Zhao, L.; Qin, S.; Pan, M.; Li, Z. Ship Target Detection and Identification based on SSD_MobilenetV2. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1676–1680. [Google Scholar]
- Liu, C.; Li, J. Self-correction ship tracking and counting with variable time window based on YOLOv3. Complexity 2021, 2021, 2889115. [Google Scholar] [CrossRef]
- Han, X.; Zhao, L.; Ning, Y.; Hu, J. ShipYOLO: An enhanced model for ship detection. J. Adv. Transp. 2021, 2021, 1060182. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, J.; Ma, Y.; Ren, P. Lightweight object detection algorithm based on YOLOv5 for unmanned surface vehicles. Front. Mar. Sci. 2023, 9, 1058401. [Google Scholar] [CrossRef]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing Network Design Spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. J. Inf. Sci. Eng. 2023, 39, 975–995. [Google Scholar] [CrossRef]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. PANet: Few-shot Image Semantic Segmentation with Prototype Alignment. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9196–9205. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP0.5 (%) ↑ | [email protected]:0.95 (%) ↑ | P (%) ↑ | R (%) ↑ | Parameters (M) ↓ | Speed (ms) ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|
| Efficientdet-D0 | 48.5 | 25.5 | 74.0 | 32.5 | 3.9 | - | 35.6 |
| YOLOv5n | 67.2 | 36.1 | 74.0 | 61.5 | 2.5 | 1.7 | 78.1 |
| YOLOv5s | 74.7 | 42.1 | 75.6 | 70.8 | 9.1 | 2.5 | 76.9 |
| YOLOv7-tiny | 65.9 | 33.3 | 67.9 | 63.2 | 6.2 | - | 93.4 |
| YOLOv8s | 75.0 | 42.7 | 83.3 | 68.2 | 11.1 | 2.7 | 74.6 |
| YOLOv8n (baseline) | 70.7 | 39.2 | 76.2 | 65.5 | 3.15 | 1.9 | 83.3 |
| YOLO-WSD | 75.3 | 41.3 | 76.3 | 70.9 | 3.3 | 2.1 | 76.9 |
| Methods | mAP0.5 (%) | [email protected]:0.95 (%) | P (%) | R (%) | Parameters (M) | Speed (ms) |
|---|---|---|---|---|---|---|
| PAN-FPN | 70.7 | 39.0 | 76.2 | 65.5 | 3.2 | 1.9 |
| PAN-FPN + WIOU | 71.1 | 39.5 | 74.0 | 66.9 | 3.2 | 1.9 |
| BiFPN-YOLO | 70.7 | 38.9 | 75.8 | 64.9 | 3.7 | 2.0 |
| BiFPN-YOLO + WIOU | 73.2 | 41.4 | 76.7 | 68.1 | 3.7 | 2.1 |
| Methods | mAP0.5 (%) | [email protected]:0.95 (%) | P (%) | R (%) | Parameters (M) | Speed (ms) |
|---|---|---|---|---|---|---|
| PAN-FPN | 70.8 ↑ | 39.0 ↑ | 74.2 | 66.0 | 3.2 | 2.0 |
| PAN-FPN + WIOU | 73.0 ↑ | 40.4 ↑ | 77.6 | 67.6 | 3.2 | 2.0 |
| BiFPN-YOLO | 74.3 ↑ | 40.8 ↑ | 73.5 | 69.9 | 3.4 | 2.1 |
| BiFPN-YOLO + WIOU | 74.6 ↑ | 41.3 ↓ | 80.0 | 68.6 | 3.4 | 2.1 |
| Methods | C2F-E | BiFPN YOLO | WIOU | mAP0.5 (%) | [email protected]:0.95 (%) | Parameters (M) | Speed (ms) |
|---|---|---|---|---|---|---|---|
| M1 | 70.7 | 39.0 | 3.2 | 1.9 | |||
| M2 | √ | 71.1 | 39.5 | 3.2 | 1.9 | ||
| M3 | √ | 74.3 | 40.8 | 3.4 | 2.1 | ||
| M4 | √ | 71.4 | 39.4 | 3.0 | 1.8 | ||
| M5 | √ | √ | 74.6 | 41.3 | 3.4 | 2.0 | |
| M6 | √ | √ | √ | 75.3 | 41.3 | 3.3 | 2.1 |
| Methods | mAP0.5 (%) | [email protected]:0.95 (%) | P (%) | R (%) | Parameters (M) | Speed (ms) |
|---|---|---|---|---|---|---|
| YOLOv8n (baseline) | 74.2 | 44.1 | 77.3 | 67.3 | 3.15 | 1.9 |
| YOLOv8s | 78.3 | 51.9 | 79.3 | 68.7 | 11.1 | 2.8 |
| YOLO-WSD (CIOU) | 77.6 | 50.4 | 75.5 | 75.8 | 3.3 | 2.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wang, L.; Liu, Y.; Zhang, S. Lightweight Water Surface Object Detection Network for Unmanned Surface Vehicles. Electronics 2024, 13, 3089. https://doi.org/10.3390/electronics13153089
Li C, Wang L, Liu Y, Zhang S. Lightweight Water Surface Object Detection Network for Unmanned Surface Vehicles. Electronics. 2024; 13(15):3089. https://doi.org/10.3390/electronics13153089
Chicago/Turabian StyleLi, Chenlong, Lan Wang, Yitong Liu, and Shuaike Zhang. 2024. "Lightweight Water Surface Object Detection Network for Unmanned Surface Vehicles" Electronics 13, no. 15: 3089. https://doi.org/10.3390/electronics13153089