Abstract
Federated learning (FL) can break the problem of data silos and allow multiple data owners to collaboratively train shared machine learning models without disclosing local data in mobile edge computing. However, how to incentivize these clients to actively participate in training and ensure efficient convergence and high test accuracy of the model has become an important issue. Traditional methods often use a reverse auction framework but ignore the consideration of client volatility. This paper proposes a multi-dimensional reverse auction mechanism (MRATR) that considers the uncertainty of client training time and reputation. First, we introduce reputation to objectively reflect the data quality and training stability of the client. Then, we transform the goal of maximizing social welfare into an optimization problem, which is proven to be NP-hard. Then, we propose a multi-dimensional auction mechanism MRATR that can find the optimal client selection and task allocation strategy considering clients’ volatility and data quality differences. The computational complexity of this mechanism is polynomial, which can promote the rapid convergence of FL task models while ensuring near-optimal social welfare maximization and achieving high test accuracy. Finally, the effectiveness of this mechanism is verified through simulation experiments. Compared with a series of other mechanisms, the MRATR mechanism has faster convergence speed and higher testing accuracy on both the CIFAR-10 and IMAGE-100 datasets.
1. Introduction
With the rapid development of Internet of Things technology, more and more intelligent devices are connected to the network, bringing various conveniences to people’s lives. Currently, there are 12 billion Internet of Things (IoT) devices and over 3 billion smartphones worldwide [1]. In recent years, how to use the local data of these intelligent devices to train machine learning models has attracted the attention of researchers. The traditional machine learning model training process enables each edge node to upload local data to the data center through the network, complete model training on the central server, and download the trained model from the data center for each edge node to use. With the increase of data volume, this model training method will lead to large transmission delays and redundant bandwidth consumption, and there is also a risk of leakage of private data uploaded through the network [2]. The emergence of new data regulations (e.g., CCPA 4 and GDPR 5), combined with the growing importance of data, has resulted in a lot of work devoted to addressing data privacy protection needs [3,4,5,6]. However, the issue of data silos [7] still exists.
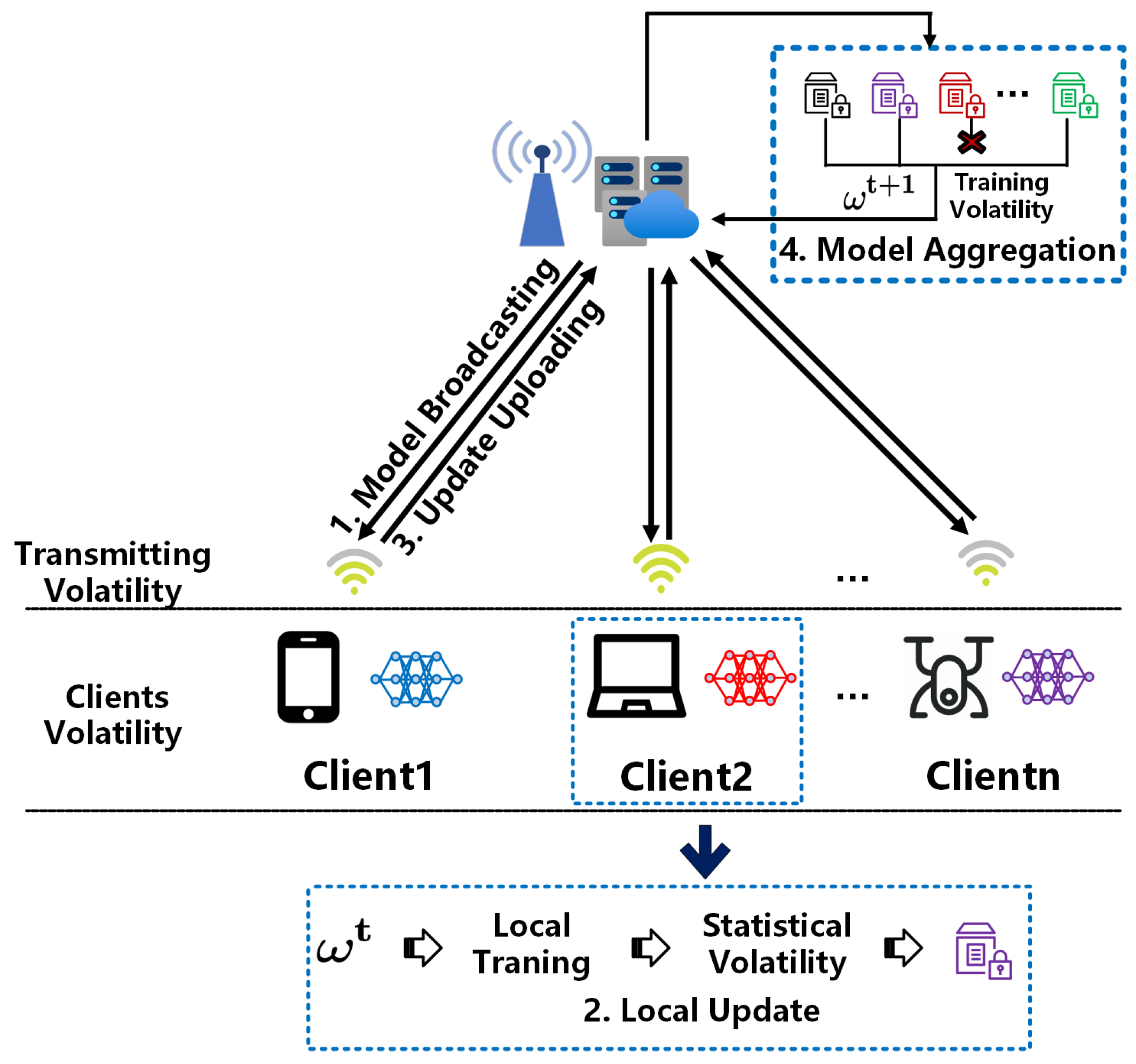
Therefore, while protecting user privacy, there is a need to find better ways to address the issue of data silos. Federated learning (FL) [8] was first proposed in 2016 and has attracted widespread attention in Machine learning (ML) in recent years. Subsequently, relevant researchers proposed a series of practical FL algorithms [9,10,11,12,13,14,15,16,17]. As a distributed ML method, the FL system is organized in an edge computing system consisting of a parameter server, base station, and many clients, as shown in Figure 1. It allows for direct training of machine learning models on local data from various devices. It can fully utilize the high-quality data generated by device interaction. FL follows the principle of “sending computation code to the end where the data is located, rather than sending the dataset to the location where the computation is located”, allowing many devices to participate in the training process of ML models together. Meanwhile, as user data is only stored on local devices and will not be uploaded, this greatly ensures the privacy and security of user data while reducing the cost of centralized data collection and storage.
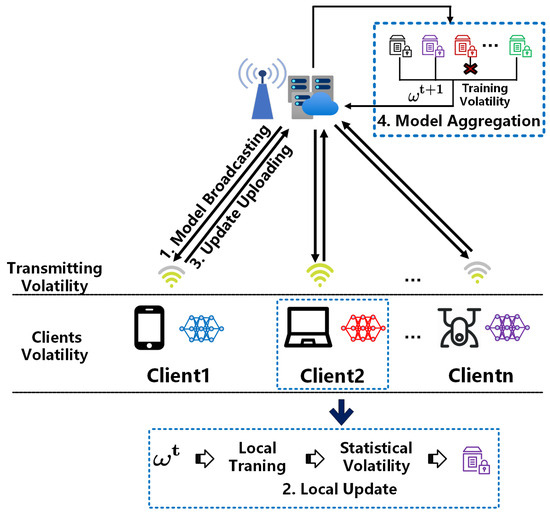
Figure 1.
Federated Edge Learning Architecture.
Although FL can achieve collaborative learning and protect data privacy from leakage, it faces several major challenges. In edge scenarios clients involved in collaborative FL training are distributed in different locations, with different data distributions and limited resources. Limited energy does not allow them to participate in collaborative training for a long duration, and limited computing capacity and communication capabilities may result in their failure to upload models with timely updates and uncertain participation status, which consequently affects the convergence of the global model [18,19]. Therefore, scheduling of clients involved in collaborative training is required to facilitate global model convergence. For example, selecting participating clients reasonably, determining the number of data points they will contribute, and designing appropriate payment plans to motivate customer participation effectively. Many existing studies have adopted designs based on reverse auctions [20,21,22,23,24,25] to address these challenges. However, current research has avoided three unstable factors: set volatility, statistical volatility, and training volatility [26]. The first one is set volatility. For FL, as it typically trains when the client is idle, the clients participating in FL training typically exhibit certain fluctuations at different times [27]. For example, the amount of data on the client at night has increased four times compared to during the day [28]. In addition, smart clients’ growth rate and update speed are astonishing. According to statistics, there were 21.7 billion active connected devices worldwide in 2020, and the number of IoT connections is expected to exceed 30 billion by 2025 [29]. Therefore, new clients may be added during the FL training process. The second one is statistical volatility. The dataset of the same client may vary to select training data flexibly at different times, so it is necessary to select training data over time flexibly. The third one is training volatility. Due to many unexpected reasons, such as unexpected shutdowns, user interruptions, and network instability, local training for some clients may fail. Therefore, not all selected clients can complete local training and return the trained model to the server for aggregation [26]. If there is a lack of consideration for training time, it significantly impacts the collection of model updates on the client side [22]. In this article, we refer to the learning scenario with these three unstable factors as volatile federated learning (volatile FL). The instability of the client set and the dynamic nature of client data, along with the unreliability of clients (e.g., unintentional disconnections and network instability), significantly increase the difficulty of client selection [26]. In addition, if subjected to data poisoning attacks or poor data quality, it may lead to a decrease in the performance of the global model, requiring more rounds to converge or achieve lower accuracy [21]. Therefore, we must develop a solution to accelerate model convergence and improve its accuracy in volatile FL.
We propose a multi-dimensional volatile FL reverse auction mechanism that considers the uncertainty of client training time, the stability of client training status, and the quality of client data. It allows each client to provide data quantity flexibly to achieve fast convergence and effective training of FL task models while achieving near-maximum social welfare. The main contributions of this article are as follows:
- (1)
- We have constructed an optimization problem aimed at maximizing expected social welfare by selecting high-quality clients and determining the amount of training data for each selected client. Furthermore, we have demonstrated that this optimization problem is NP difficult.
- (2)
- To address this NP challenge, We have developed a multi-dimensional volatile FL reverse auction mechanism MRATR based on greedy algorithms, which takes into account the uncertainty of client training time, the stability of client training status, and the quality of client data. This mechanism can meet the expectations of truthfulness and individual rationality and achieve near-optimal social welfare while maintaining lower computational complexity. It also helps the FL task model to converge quickly and achieve higher testing accuracy.
- (3)
- Finally, we compared our mechanism with a series of auction mechanisms on the CIFAR-10 and IMAGE-100 datasets and conducted thorough simulation experiments. The experimental results have demonstrated the superiority of this method.
2. Related Work
In FL research, the design of incentive mechanisms is an important issue. A client’s participation in FL inevitably consumes their device’s resources, including computing, communication, and energy. So, clients may only be willing to participate or share their models with sufficient compensation [30]. To solve this problem, some scholars have begun to explore incentive mechanisms for FL. Currently, many FL incentive mechanisms are designed by combining game theory, contract theory, and auction frameworks.
In terms of game theory, R. Zeng et al. [31] mentioned the incentive mechanisms and game theory methods in FL that encourage honest participation in the FL process by coordinating the economic interests of participants. Y. Zhao et al. [32] proposed a multi-layer Stackelberg game model as the incentive mechanism for FL, and the simulation results showed this mechanism’s effectiveness, revealing stakeholders’ dependence on data resource allocation. In the absence of prior client information on the server, work [33,34,35,36,37] expresses the client selection problem as a MAB problem and uses different exploration and development strategies to train the model.
Regarding contract theory, Kang et al. [38] proposed an effective incentive mechanism that combines reputation and contract theory to incentivize high reputation mobile devices with high-quality data to participate in model learning. Zhang et al. [39] proposed a knowledge trading framework based on prior utility evaluation and contract theory, which utilizes the self-disclosure of contract theory to alleviate dishonest behavior in information asymmetry. The learning process is modeled as an optimization function that includes utility and privacy costs. The monotonicity of the utility function further reduces complexity. The experimental results based on multiple models and datasets show that this scheme outperforms existing schemes in terms of convergence and accuracy. C. Man et al. [40] proposed an incentive scheme based on two-stage dynamic contract theory under information asymmetry conditions. This scheme can balance the weighted preferences of model owners for information age (AoI) and service delay and encourage more data owners to participate in model training to improve the utility of model owners.
Some papers use auction frameworks to model the FL process, unlike the above solutions. Zeng et al. [41] proposed an incentive mechanism FMore for multi-dimensional procurement auctions with K winners, which encourages more low-cost, high-quality edge nodes to participate in learning and ultimately improves the performance of joint learning. Y. Jiao et al. [42] proposed an auction-based market model to incentivize data owners to participate in joint learning. They designed two auction mechanisms for the joint learning platform to maximize the social welfare of the joint learning service market: first, they designed an approximate strategy-proof mechanism. An automated policy-proof mechanism based on deep reinforcement learning and graph neural networks has been developed to improve social welfare. In the proposed model, special consideration was given to the unique characteristics of communication traffic congestion and joint learning. Many experimental results indicate that the proposed auction mechanism can effectively maximize social welfare. J. Zhang et al. [21] proposed a joint learning incentive mechanism based on reputation and reverse auction theory, which selects and rewards participants by combining their reputation and bid within a limited budget. Simulation results demonstrate the effectiveness of the institution. Tang. Y et al. [43] ensured joint learning in the Internet of Things through reputation and reverse auction mechanisms, solving the problem of joint learning in the event of malicious workers launching attacks.
However, in the above work, they did not consider the volatility of the client. Due to the volatility of client training, local training for heterogeneous clients may fail for various reasons and at different frequencies, and excessive training failures will reduce training efficiency [44]. At the same time, the server cannot wait indefinitely for all clients to upload their model parameters. In addition, the quality of customer data is also an important factor affecting the efficiency and utility of FL tasks. Therefore, we designed a volatile FL incentive mechanism that considers the stability of client training, the uncertainty of client training time, and data quality.
3. System Model and Problem Definition
In this section, we described the system model and auction framework, introduced the calculation method of client reputation value, and specifically defined the problem of maximizing expected social welfare. The commonly used symbol definitions are shown in Table 1:

Table 1.
Notations.
3.1. System Model
This article considers an FL model consisting of a central server and a set of clients . The central server coordinates the training process, including assigning training tasks, selecting clients to participate in training, and aggregating model updates uploaded by clients to form a global model . The goal of the server is to train a shared global model and minimize the global loss function. Assuming that client has data points selected for model training, where . Once selected, each client downloads the shared global model and trains on the specified dataset. The loss function for client i can be expressed as:
where k represents the data unit used in training, the client uses their data units for model training and uploads the updated weights to the central server to optimize the global model . The central server sets the duration of one round of training to T and starts timing after sending . When the set time T is reached, the central server stops receiving any new weight updates and begins executing the model aggregation program. The set of clients who successfully uploaded weights is denoted as . In order to accelerate the convergence of the model, the weight aggregation process of the global model considers the ratio of the number of clients who successfully uploaded weights to the total number of participating clients and adopts a multi-round update method. The global loss function is:
Among them, is the data quantity of the i-th client, is the total data quantity of all clients that successfully uploaded weights, and is the loss function on the i-th client.
The ultimate goal is to find the model parameters:
Among them, represents the parameter value that minimizes the function.
3.2. Auction Framework
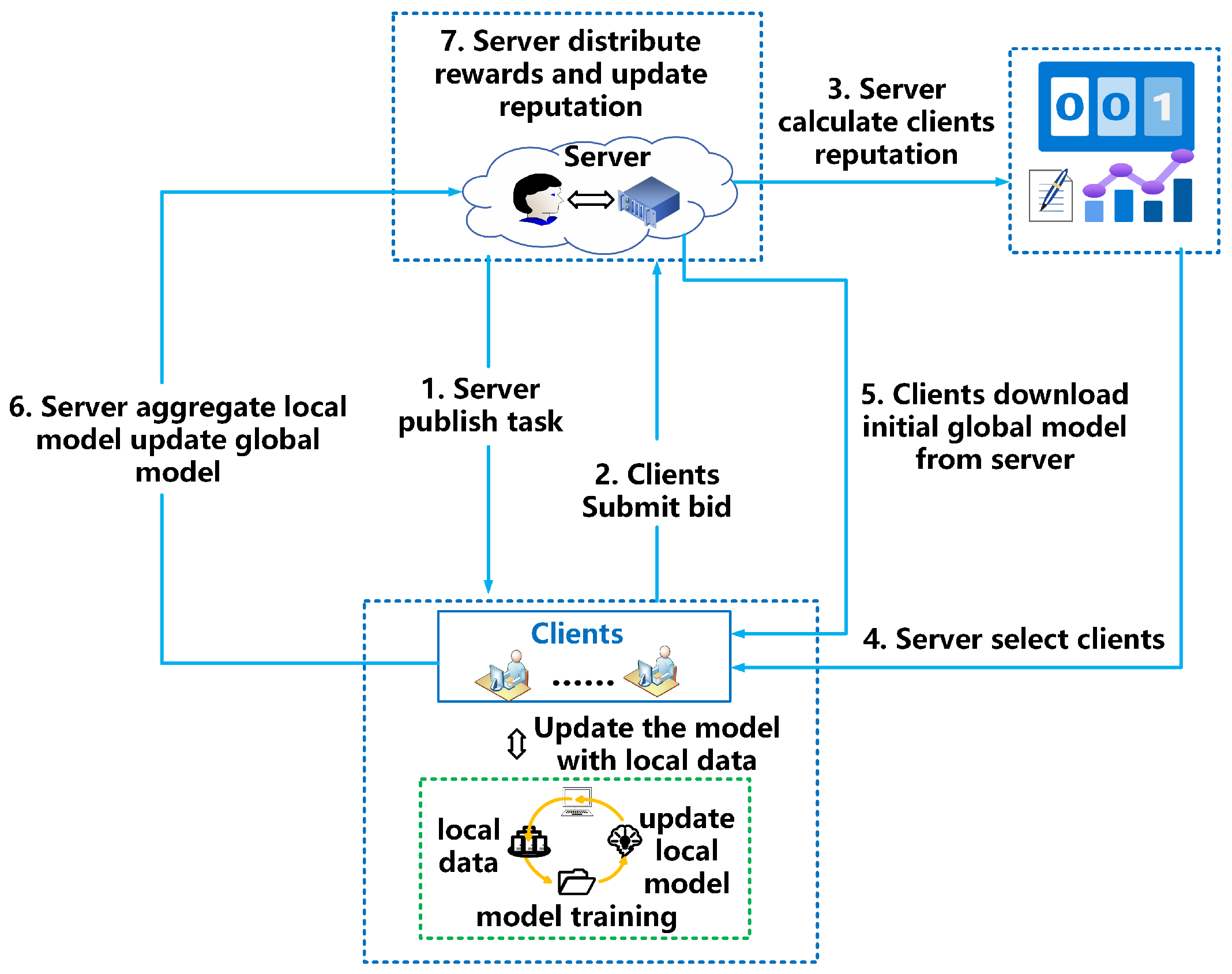
We have designed a reverse auction-based client and its data point quantity selection mechanism, as shown in Figure 1.
Figure 2 shows the detailed process of selecting client data points and volatile FL. (1) Publish task: The central server publishes task information, describes the required data categories, and sets a training time T for one round. (2) Submit bid: Interested clients submit bids based on their comprehensive information. (3) Reputation calculation: The central server calculates the reputation value of each client based on the historical information submitted by the client. (4) Select client: The server selects the number of clients and their data points based on the selection scheme, then sends the parameters and starts timing after sending. (5) Download initial global model: The selected client downloads the initial global model, trains it on the selected local data points, and submits the updated parameters. (6) Model aggregation: The server aggregates models and updates parameters. (7) Distribute rewards and update reputation: After a round of training, distribute rewards, calculate the performance score of the client after stopping training, and use it to update reputation.
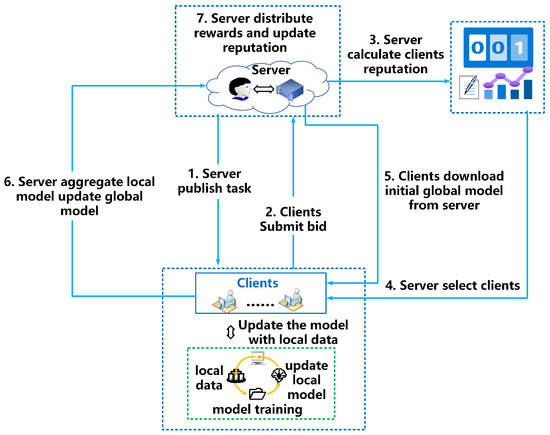
Figure 2.
The architecture of MRATR scheme based on reverse auction.
In the proposed volatile FL scheme, each client interested in the task will submit a bid with , where represents the historical information set of client i, represents the size of the dataset, represents the training time per unit data point, represents the communication speed. contains all information about the client’s past participation in FL tasks, and the client with historical task information , . represents the size of the dataset related to client i of historical task , represents the training time of historical task , represents the performance score of historical task .
Client uses its local data points to perform model training and sends the calculated local gradient information to the central server after the training. The time required for this process is modeled as:
Among them, follows an exponential distribution with a parameter of , is the training time per unit data point, and is communication speed. Assuming . Where is the local model size of client i. Given that a local volatile FL model is composed of a similar number of elements, it is reasonable to assume that all local volatile FL models have the same size [45], i.e., , .
3.3. Reputation Calculation
This article objectively reflects the client’s data quality and training stability through reputation. High-reputation clients often have higher data quality and more stable training status, which means the probability of training failure during the training process is lower due to unexpected shutdowns, user interruptions, network instability, and other reasons. Below, we’d like to introduce a method of calculating reputation using the client’s historical information for you to look at. , where j represents the ID of each subtask. the client i with historical task information , . represents the size of the dataset for client i in subtask j, represents the training time of historical task , represents the performance score of client i in subtask j. The performance score reflects the client’s performance in FL tasks. At the beginning of the training, a performance score will be initialized for each client, and the performance score will be updated after the training. The performance score calculation formula [20] for client i in task j is:
Among them, R represents the number of communication rounds for client i in task j. In Equation (5), the testing accuracy of each local model should be compared with the average testing accuracy of all local models in each round and the testing accuracy of the aggregated global model in each round. is used to evaluate the performance of each local model and compare it to determine whether the model performance of client i is better than the average level of all client models. is used to evaluate the overall performance of all local models in an iteration and to compare it to determine whether the local model performance of client i is closer to that of the global model.
Next, we will comprehensively consider the reputation value based on the client’s historical performance score. Because the client’s credibility may change over time, it is not always trustworthy. Therefore, the historical performance closer to the current time point reflects the client’s current performance; that is, the weight of the most recent task performance with higher freshness exceeds the weight of the previous task performance [20]. We introduce an event freshness decay function to represent the historical task freshness of the client: . Where is the fade parameter of event freshness, generally considered as 0.5 [38], is the time slot for determining the freshness of an event. Therefore, the calculation formula for reputation [20] is as follows:
3.4. Problem Definition
Define as a binary random variable, if client i successfully submits the result to the server within time T, then ; Otherwise, if client i fails to submit the result within time T, then . Client uses data points to participate in FL, where , and when , represents:
Among them, follows an exponential distribution with a parameter of , is the training time per unit data point and is communication speed. Assuming . Where is the local model size of client i.
The reward function of the server is an increasing concave function of the actual data points participating in training [46], expressed as
where is an increasing function of the number of data points, is the number of data points selected for the i-th client, and is the reputation value of the i-th client. Therefore, social welfare is:
where is the unit training cost for the i-th client. According to the expected linearity, the total expected contribution of clients completing tasks and successfully submitting results can be obtained by calculating the expected composite of individual contributions from each client, expressed as:
In general, the expected reward is not equal to . However, under some mild assumptions, the actual value of can be tightly concentrated near its expected value through the Chernoff boundary. Therefore, this article uses the following approximate values:
The problem of maximizing expected social welfare is expressed in the following form:
One of the practical challenges in designing an FL incentive mechanism is that clients may falsely report prices to obtain greater profits, leading to the failure of the auction mechanism. In addition, it is necessary to ensure that the client’s utility is non-negative to maintain long-term participation. To ensure the effectiveness and fairness of transactions, incentive mechanisms need to adhere to the following attributes:
- (1)
- Truthfulness in expectation: For client , reporting true bids is the optimal strategy to achieve the highest expected return after FL is completed, and client i cannot further increase its expected return by falsely reporting bid . Given the bidding determination of other clients, it is necessary to meet the following requirements:Therefore, the auction mechanism is truthful in expectation.
- (2)
- Incentive rationality (IR) in expectation: Under the FL framework, all participating clients can ensure their utility is non-negative. The utility of the client i is represented by the payment of all unit data points received to complete the task within the specified time minus the cost. Where is the payment for unit data points, and is the cost per unit data point. For a client , it usually satisfies:This ensures that the incentive mechanism has the expected rationality.
4. MRATR Auction Mechanism
The VCG mechanism has been adopted in many situations in the context of game theory [47,48,49,50]. Its effectiveness is reflected in the truthfulness and individual rationality attributes it establishes, which meet the requirements of incentive mechanisms [51]. Despite the VCG mechanism providing the optimal solution for maximizing social welfare, its computational complexity is proportional to the budget, which could be exhibitive [22]. In order to strike a balance between accuracy and time efficiency, we propose a multidimensional auction mechanism MRATR, which can solve the problem of maximizing expected social welfare (Q1) in polynomial time.
4.1. Problem Transformation
To address the issue of maximizing social welfare, we introduce a total training cost budget B, i.e., , and consider the following issues:
Since the reward function is an increasing function, it is equivalent to the following problem:
We can observe that if we have an effective algorithm for problem (Q3), then by applying this algorithm to multiple different inputs B, we can solve problem (Q1) and find a solution that maximizes the objective function. For (Q3), we obtained the following hardness results.
Theorem 1.
(Q3) is NP-hard.
Proof.
Consider (Q3) a simplified version under a specific condition to prove this point. When , , and for each i, in this case, , the objective function becomes , and the problem becomes a standard 0–1 knapsack problem, which determines how to choose clients to maximize social welfare under a given total cost budget B. The capacity of the knapsack is the total training cost budget B, and each client is equivalent to an item in the knapsack problem with a weight of and a value of . It is known that the 0–1 knapsack problem is NP-hard, so (Q3) is also NP-hard. □
4.2. Selecting Client Training Data Based on MRATR
The algorithm of the choice of clients’ training data is shown in Algorithm 1. Where is used to store the client for exiting the iteration; is used to store the maximum social welfare plan before each update.
| Algorithm 1: The choice of clients’training data |
|
- (1)
- When we choose client i to participate in a training program that includes k data points, we use to define the value of the k-th data point for each training cost. As the value of each client i decreases with increasing quantity, in order to reduce computational complexity, we only need to calculate the value of the positive data points for each client and compare each time.
- (2)
- The formula for calculating the value of each data point using this mechanism is as follows:We can see that when the client’s reputation is good, the value of data points decreases correspondingly with the increase in quantity.
- (3)
- During the iterative process, the server continuously searches for the current maximum value and adds the data point corresponding to this maximum value and its client j to the current client solution. This solution is used to calculate social welfare. Suppose the calculated current social welfare value in an iteration is greater than the result of the previous iteration. In that case, the server will continue to the next iteration to find whether more data points can further improve social welfare. However, suppose the current social welfare value does not exceed the previous iteration’s result. In that case, it means that the selected data points in this iteration cannot bring additional gains to social welfare. Therefore, the corresponding jth client will no longer participate in the subsequent iteration process. In short, the server selects and tests data points through iteration to optimize social welfare. When it is found that new data points cannot further improve social welfare, further iterations of the client will be stopped. Finally, the maximum social welfare value along the path and the corresponding customer solution can be obtained.
In Algorithm 1, the time complexity of generating values is , where n is the number of clients and represents the maximum number of data points among all clients. This step requires traversing each client and calculating each client’s data point. Therefore, in the worst case, the time complexity is the product of the number of clients and the maximum number of data points. In the process of selecting training data for clients, its time complexity is also because, during the selection process, it may be necessary to traverse each data point of each client to make decisions. For the payment calculation in the process, the time complexity is . Considering that the server may still face an increase in computational requirements when dealing with a large number of participating clients, in order to solve this problem, this article adopts a batch processing approach to improve the greedy algorithm auction mechanism further and reduce time complexity.
Before the auction starts, the server sets a parameter: batch b. In order to optimize the processing process, the server divides the data points of each client into an average of b batches. For client i with data points, each batch contains data points. This batch method helps the server process data in parallel, reducing the amount of data required for a single operation and thus reducing the computational pressure on the server. The cost-benefit ratio of each batch is added to the queue, and its calculation formula is:
where k is the index of data points in the batch, l is the batch index. Afterward, the server no longer processes each data point individually but rather processes it in batches. Each batch is independently calculated for its value and cost and then incorporated into the overall optimization and decision-making process. This method sacrifices some accuracy to reduce computational and time complexity to . The server can adjust resource allocation flexibly through this batch processing method while maintaining the system’s response speed and processing efficiency. This is particularly important for FL systems that require large data processing.
4.3. Payment
Due to the selection of training data one by one in Algorithm 1, the payment for each client is the total payment for each selected data point. According to this algorithm, the server pays the client in the order of selected data points. Assuming that client i has selected data points and a value list , the payment for each data point is:
is the maximum value after the last selected data point for client i in the program, which can be expressed as .
Finally, the payment for client i is:
Because the values of each client data point have already been sorted during the auction process, there is no need for additional steps in payment.
4.4. Properties
Theorem 2.
Incentive compatibility in expectations.
To prove this theorem, it is necessary to satisfy the next property.
Lemma 1.
Monotonicity: If a client’s bid , the selected data points will not be less than the original data points.
Proof.
If the client’s bid meets the condition of , the value of the data points provided by the client will correspondingly increase, and it will receive higher priority in the selection process of the central server, allowing more data points to be selected for training. □
Lemma 2.
Critical payment: For the above auction mechanism, the main strategy for each client is to bid on their true unit cost .
Proof.
Client i’s bid should be its optimal strategy, considering only the value v of one data point on client i, and the lemma can be extended to all data points. Because , when the reputation value of the client is determined, v will increase as decreases, c is the bid from the client, and when , consider the following situations:
- (1)
- The client’s quotation is lower than its actual cost . Because a lower quote will make the value of its data points appear higher, the probability of data points being selected will increase. However, if selected due to a lower quote, customers may face losses because their payments may not be sufficient to cover their actual costs. Its unit profit is in exceptional cases. Therefore, for case 1, the optimal bid for client i is .
- (2)
- The client’s quotation is higher than its true cost . A higher quotation will result in higher payments for each selected data point. Still, a high quotation reduces the data point’s value, which will reduce the probability of the data point being selected. An excessively high quotation may even result in no data point being selected. Therefore, for case 2, the optimal bid for client i is .
The proof is completed, and the mechanism meets the expected incentive compatibility. □
Theorem 3.
Individual rationality in expectations.
Proof.
The expected unit profit for client i is:
The proof is completed, and the mechanism satisfies the expected individual rationality. □
5. Simulation Results
5.1. Experiment Settings
This article uses the CIFAR-10 dataset and the IMAGE-100 dataset for simulation experiments to evaluate the performance of the proposed auction mechanism, using Python 3.9 as the software environment. CIFAR-10 is an image dataset consisting of 60,000 32 × 32 color images from 10 categories (50,000 for training and 10,000 for testing). IMAGE-100 is a subset of ImageNet. ImageNet is a visual recognition dataset that contains 1,281,167 training images, 50,000 validation images, and 100,000 test images from 1000 categories. To cope with the limited resources of edge devices, we conducted experiments using IMAGE-100, which included samples from 100 categories, each with a size of 64 × 64 × 3. In terms of dataset splitting, we divided the CIFAR-10 training samples into equal and disjoint groups of 300 samples. According to the non IID principle, each customer is randomly assigned 2–20 sample groups. The IMAGE-100 dataset was also split using a similar method. Each client’s parameters are generated within the following parameter range. The focus of parameter settings is to reflect the differences between clients. The specific parameter settings under the standard are shown in Table 2. In addition, in the simulation experiment, we set the number of clients participating in each round of training to 10, the number of communication rounds to 500, the learning rate to 0.001, and the batch size to 32. The mechanism considering the uncertainty of client training time depends on the server’s given single round duration T for local training times, while other mechanisms are set to 40. For the CIFAR-10 dataset, we used ResNet-14 as the training model, and for the IMAGE-100 dataset, we used VGG16 as the training model.
Table 2.
Experimental parameter settings.
Baselines. We measure the effectiveness of MRATR through a comparison with four baselines. Among them, due to the possible differences in the quantification methods of social welfare among different solutions, we only choose to compare solutions that use the same quantification method with our mechanism in terms of social welfare.
(1) VCG Solution [22] is based on dynamic programming to solve for maximum social welfare, which only considers the uncertainty of client training time.
(2) Greedy Agl [22] is based on greedy algorithm to solve for approximate maximum social welfare, which only considers the uncertainty of client training time.
(3) FAIR [52] is a federated learning scheme that considers the learning quality of clients. This scheme utilizes historical learning records to estimate user learning quality and constructs a reverse auction problem within the recruitment budget to encourage the participation of high-quality learning users.
(4) RRAFL [21] is a joint learning incentive mechanism based on reputation and reverse auction theory, which selects and rewards participants by combining their reputation and bids within a limited budget.
5.2. Experiment Analysis
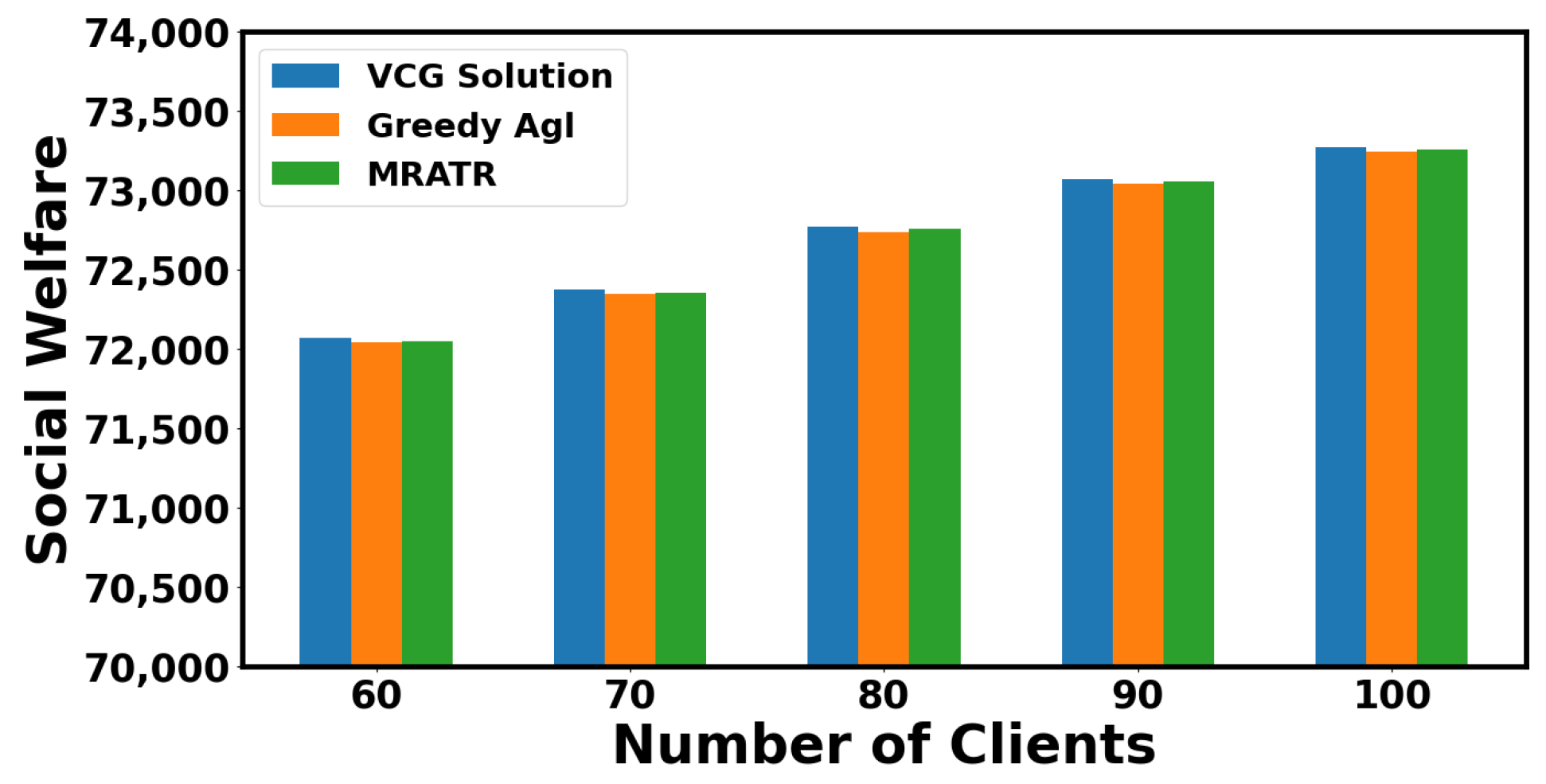
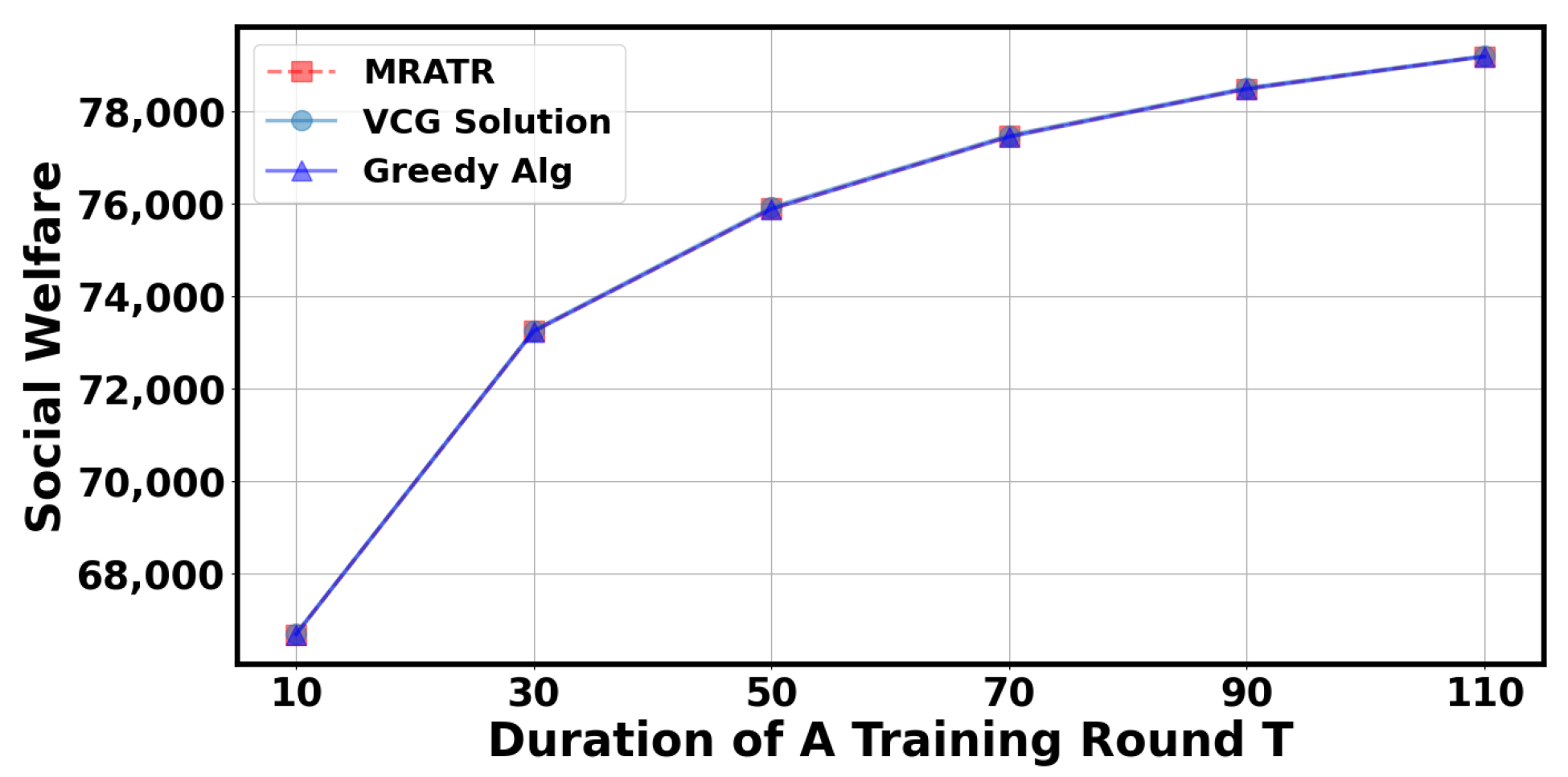
In Figure 3, we compare the social welfare size of the MRATR mechanism proposed in this article with VCG Solution and Greedy Agl. The reason why the FAIR mechanism and RRAFL mechanism have not been compared with the MRATR mechanism in terms of social welfare is that they have different ways of quantifying social welfare. From the comparison results, it can be seen that the social welfare differences between the three mechanisms are relatively small under different numbers of clients, and our proposed mechanism results are closer to the VCG Solution. Because the VCG Solution is based on dynamic programming to solve for maximum social welfare, it can be found that our mechanism can achieve the goal of approaching the maximum social welfare. In most cases, it can be used as a substitute for the VCG mechanism to reduce computational complexity.
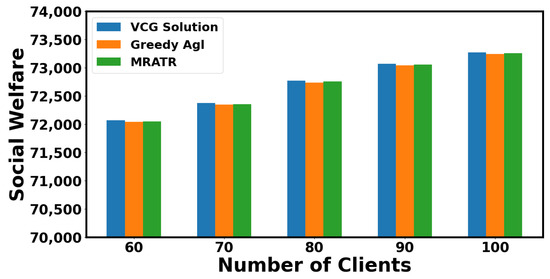
Figure 3.
Social welfare under different mechanisms.
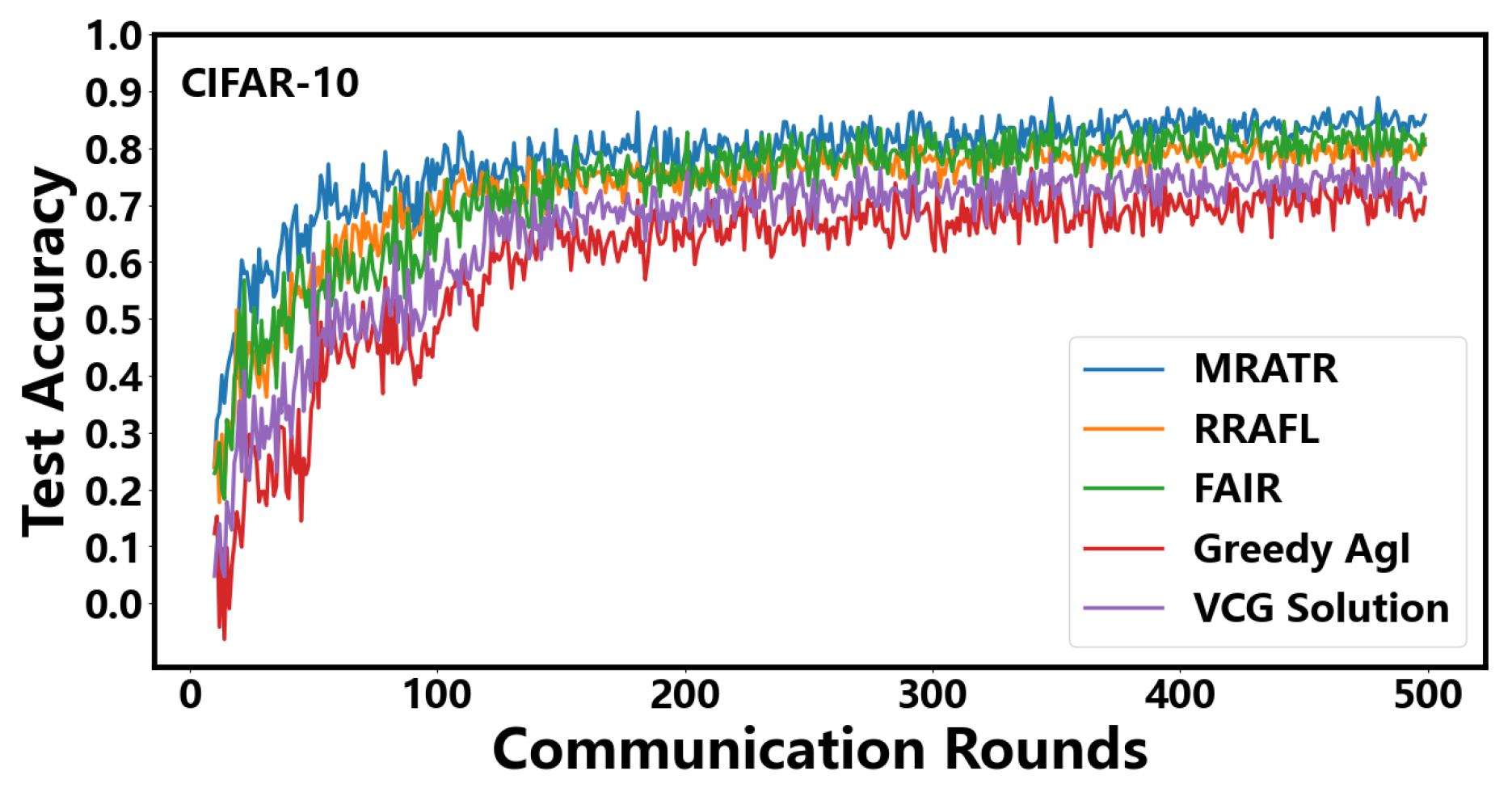
In Figure 4, we compared the testing accuracy performance of five auction mechanisms in the CIFAR-10 dataset. From the results, it can be seen that the MRATR mechanism has achieved significant improvements on the CIFAR-10 dataset compared to VCG Solution, greedy Agl, FAIR, and RRAFL. Specifically, the test accuracy of MRATR has increased by 14.7%, 21.6%, 4.2%, and 5.4%, respectively, compared to VCG Solution, greedy Agl, FAIR, and RRAFL. Additionally, the number of communication rounds required for model convergence has been reduced by 45.2%, 46.3%, 24.3%, and 28.6%, respectively. This is because our MRATR mechanism takes into account the uncertainty of client training time and client reputation. Considering the uncertainty of the client’s training time, we can ensure that the client completes the training and uploads the model within the specified time as much as possible. The timeliness of updating and collecting the client model helps accelerate the convergence of the FL model and improve its accuracy. Considering the client’s reputation enables us to select clients with higher data quality and more stable training status for training during the task process. Highly reputable clients often objectively reflect their higher data quality and more stable training status, which will minimize the occurrence of unexpected shutdowns, user interruptions, network instability, and other fluctuations in the client. VCG Solution and Greedy Agl only consider the uncertainty of client training time. Although they can ensure that the client completes training and uploads the model within the specified time as much as possible, they cannot guarantee the data quality of the client and the stability of the client training state. Due to the volatility of the client itself, upload failures cannot be avoided as much as possible, which results in their convergence speed and testing accuracy performance being inferior to other solutions. FAIR mainly utilizes historical learning records to estimate user learning quality and constructs a reverse auction problem within the recruitment budget to encourage the participation of high-quality learning clients. However, due to the lack of consideration for the uncertainty of client training time, there may be situations where training is successful but cannot be uploaded in a timely manner or upload fails due to the instability of the client itself. RRAFL selects and rewards participants based on their reputation and bids. This mechanism can select clients with higher data quality and reliability for training, but lacks consideration for the uncertainty of client training time, which may result in some clients being unable to upload models in a timely manner. FAIR and RRAFL are not as fast as our MRATR mechanism in terms of convergence speed, but our mechanism can achieve higher testing accuracy when trained for the same number of rounds. However, as the number of training rounds for FAIR and RRAFL increases, the gap between the final achievable testing accuracy and our mechanism will narrow. This is because the efficiency reduction caused by the client’s inability to upload in a timely manner and unexpected shutdown during FAIR and RRAFL training needs to be compensated for by more training rounds.
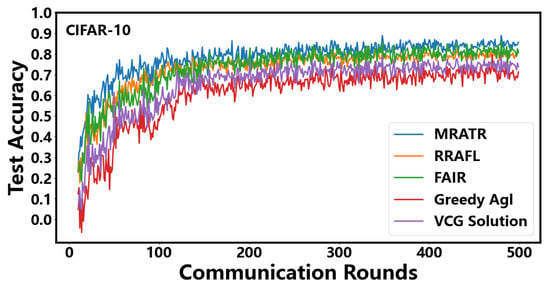
Figure 4.
Testing accuracy under different mechanisms on CIFAR-10 data.
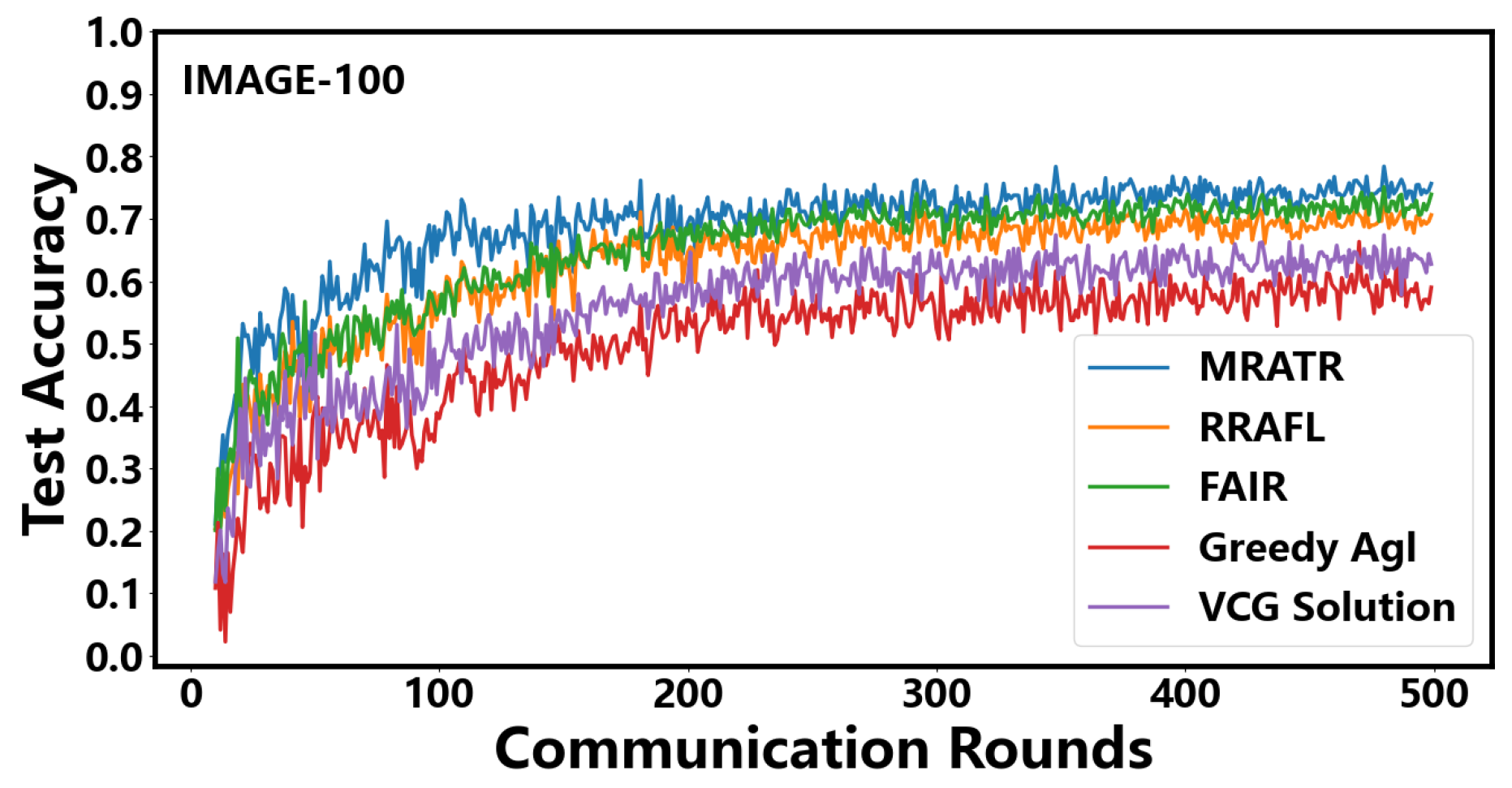
In Figure 5, we compared the testing accuracy performance of five auction mechanisms in the IMAGE-100 dataset. From the results, it can be seen that the MRATR mechanism has achieved significant improvements on the IMAGE-100 dataset compared to VCG Solution, greedy Agl, FAIR, and RRAFL. Specifically, the test accuracy of MRATR has increased by 15.6%, 22.9%, 6.1%, and 7.2%, respectively, compared to VCG Solution, greedy Agl, FAIR, and RRAFL. Additionally, the number of communication rounds required for model convergence has been reduced by 65.5%, 68.3%, 33.5%, and 36.9% respectively. From the experimental results, it can be seen that our MRATR mechanism still has advantages in larger and more complex datasets, especially in terms of model convergence speed. This is because in larger and more complex datasets, models often require more training epochs to converge. And fully considering the volatility of the client and the uncertainty of training time, efforts should be made to avoid situations where the client needs more training epochs due to training failures caused by its own instability. At the same time, considering the quality of client data can further accelerate model convergence and improve testing accuracy. Compared to the CIFAR-10 dataset, the poor convergence speed of VCG Solution and Greedy Agl in the IMAGE-100 dataset is due to the lack of consideration for the quality of client data and the stability of client training status, resulting in a more significant decline in convergence speed in larger and more complex datasets.
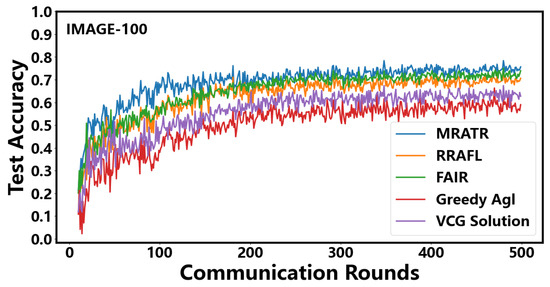
Figure 5.
Testing accuracy under different mechanisms on IMAGE-100 data.
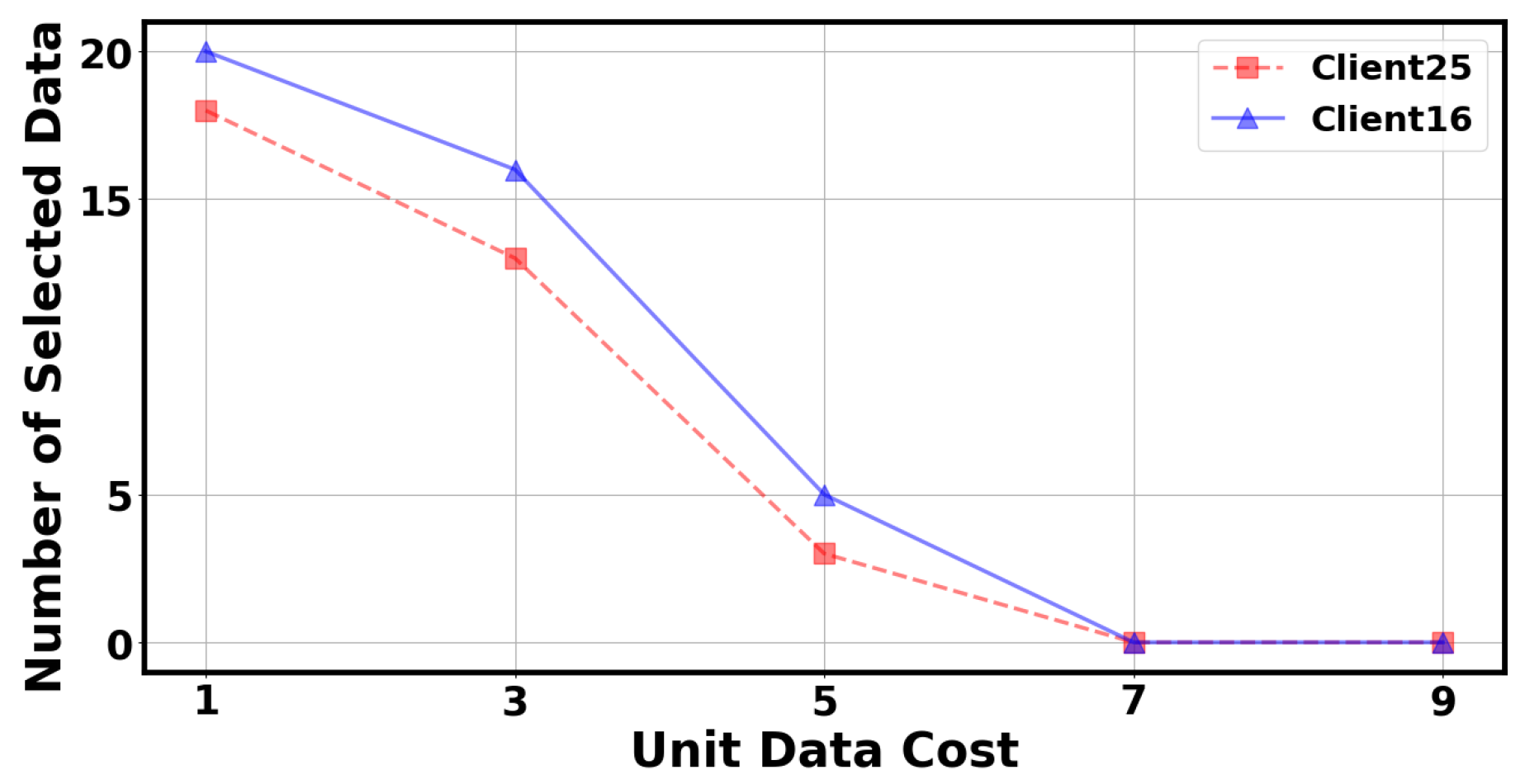
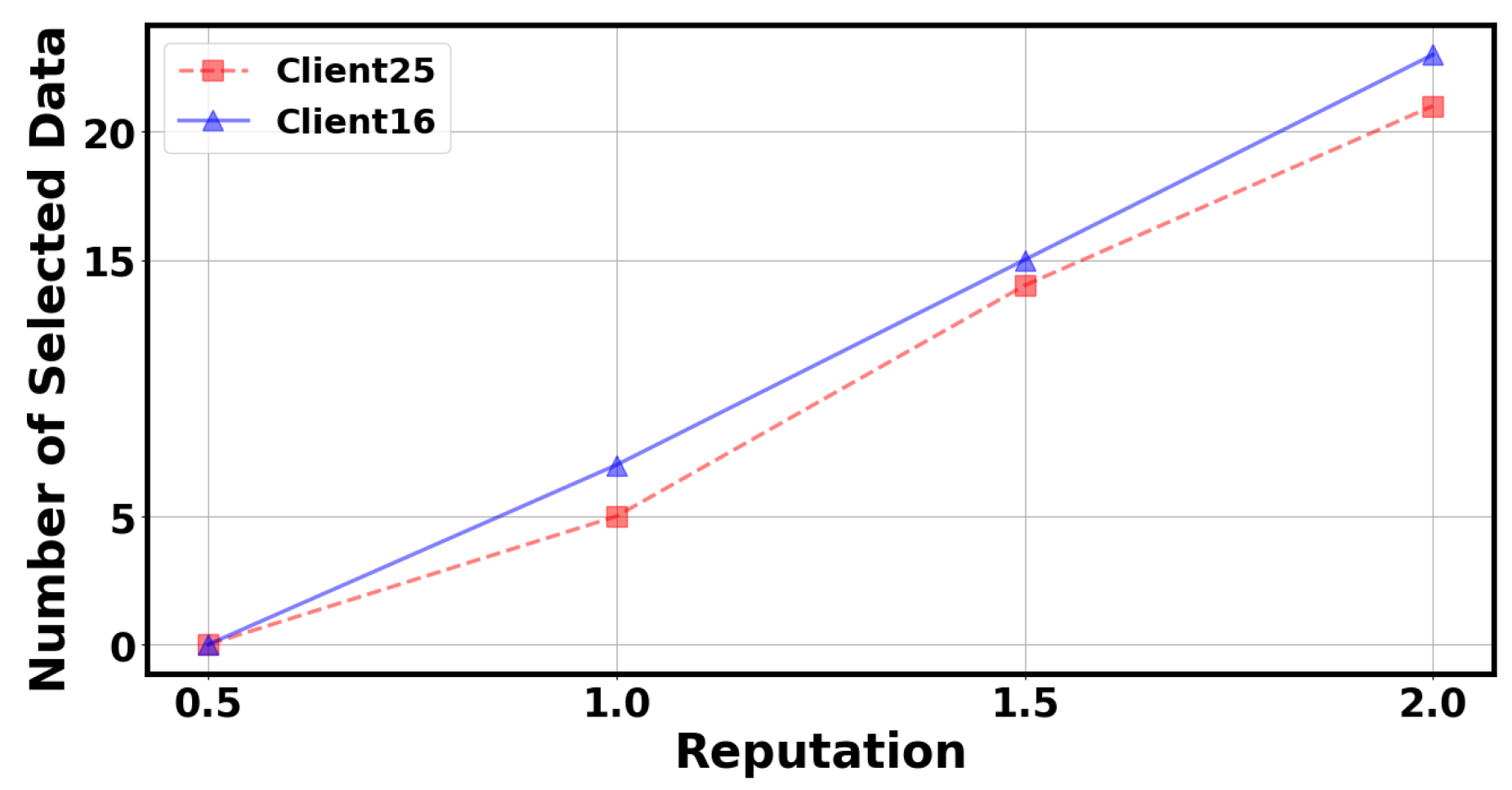
In Figure 6 and Figure 7, we investigated the effects of unit training cost and client reputation value in our mechanism. Specifically, we selected client 25 and client 16 to observe the changes in the number of selected data points as the unit training cost increases while keeping other parameters constant. We can observe that as the unit training cost increases, the number of data points selected by the client gradually decreases. When the unit training cost reaches a certain value, the client will not have any data points selected. Similarly, we selected client 25 and client 16 to observe the change in the number of selected data points as the client reputation value increases while keeping other parameters constant. We can observe that as the client reputation value increases, the number of data points selected by the client gradually increases. When the client’s reputation value is too low, no data points will be selected by the client. This result aligns with auction logic, as servers choose clients with lower training costs and higher reputations to join volatile FL.
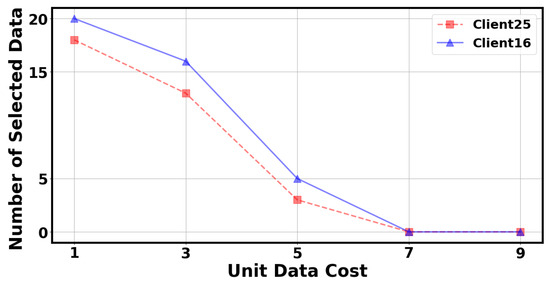
Figure 6.
The number of selected data by the client under different unit data cost.
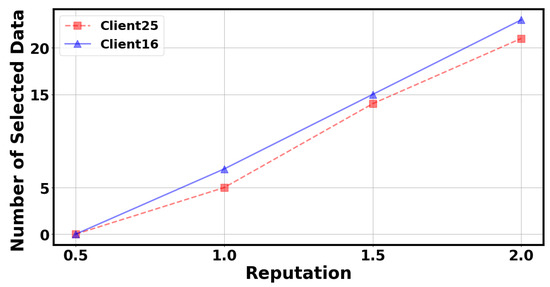
Figure 7.
The number of selected data by the client under different reputations.
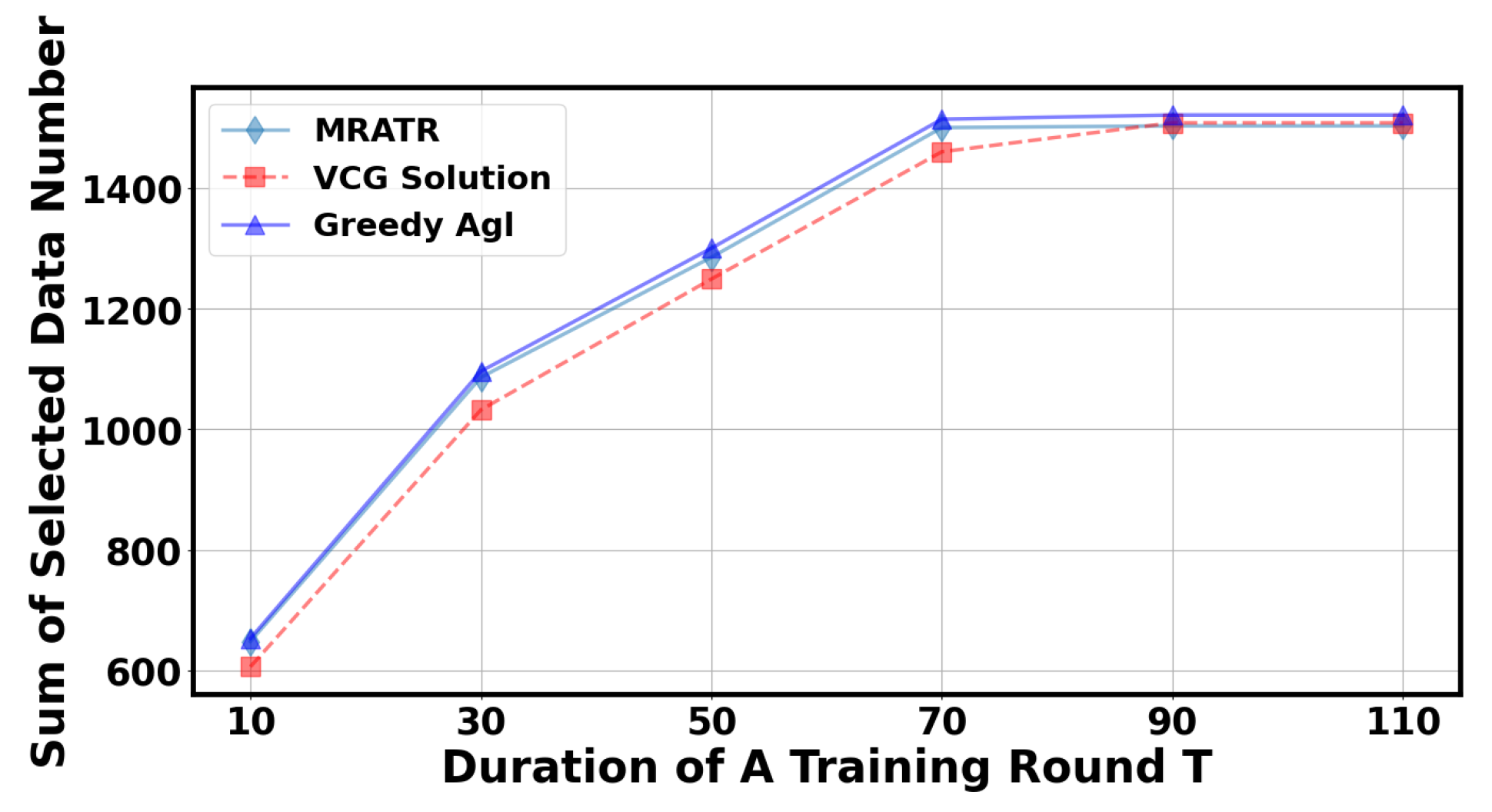
In Figure 8 and Figure 9, we analyzed the impact of the duration of a training round T. It can be observed that as the duration of a training round T increases, the total number of data selected by the server and social welfare will correspondingly increase. This is because extending T can give the client more time to train and upload data. However, when the duration of a training round T reaches a certain value, the results will tend to stabilize because the probability of the client uploading training parameters at the specified time approaches 1, and the algorithm’s results are close to the optimal solution for maximizing social welfare.
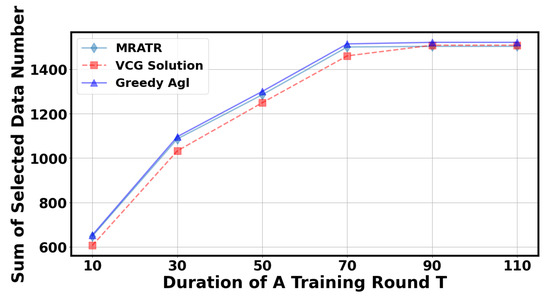
Figure 8.
The impact of a training round on the total number of selected data points.
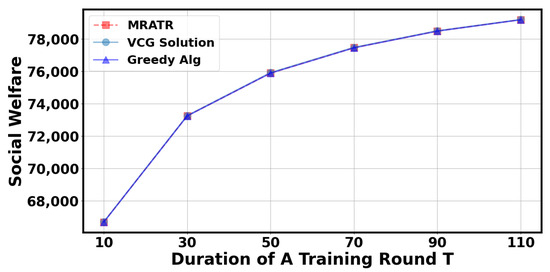
Figure 9.
The impact of a training round on social welfare.
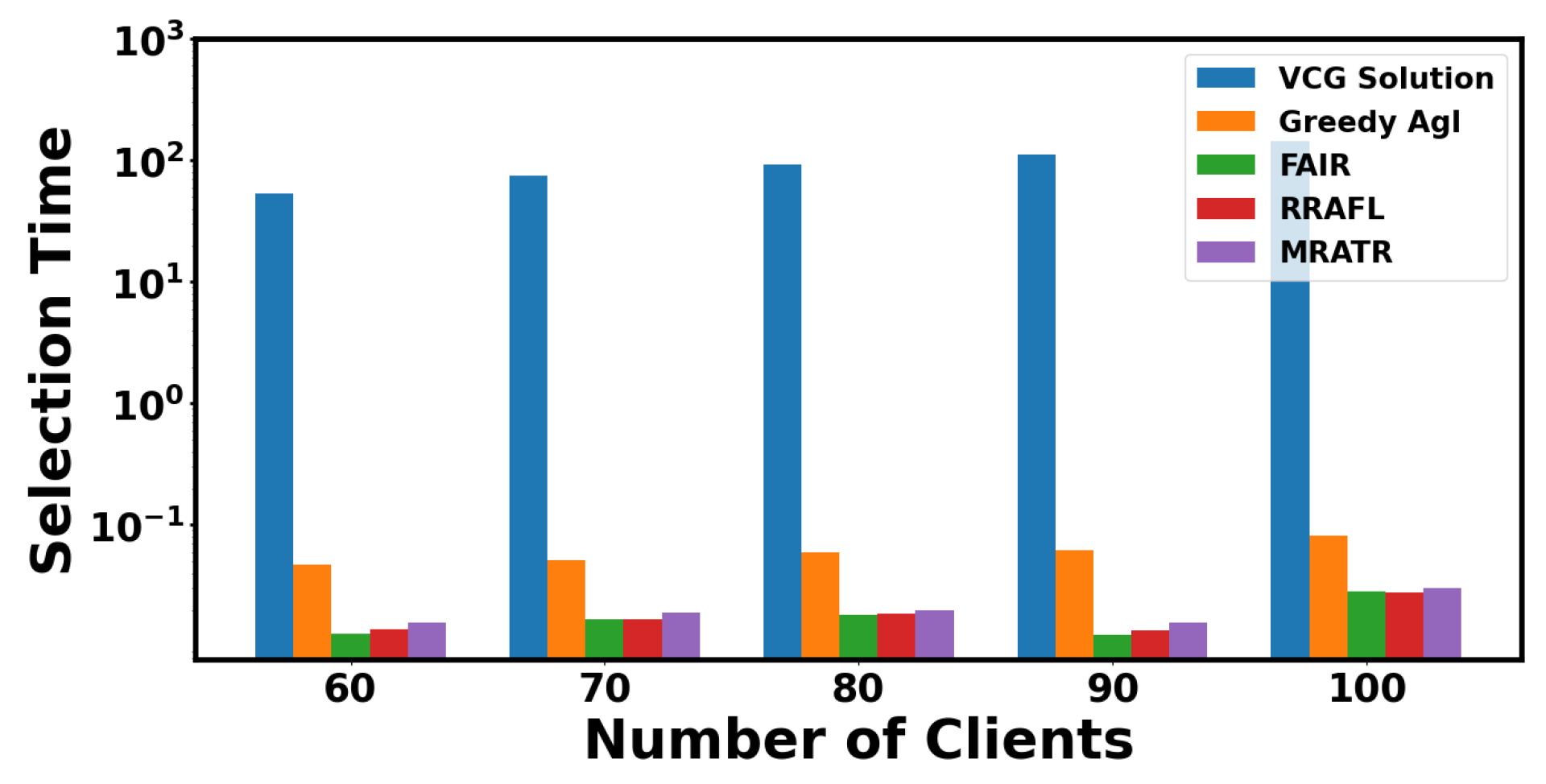
In Figure 10, we compared the selection time of client data point selection for five mechanisms as the number of clients increased. The VCG Solution mechanism has the highest selection time and increases significantly with the increase in data quantity. The selection time of the Greedy Agl mechanism is reduced compared to the VCG Solution mechanism, and it still shows good computational performance when the number of clients increases. Due to the introduction of batch processing mechanism, as the amount of data increases, MRATR mechanism has less selection time and more stable computational performance compared to VCG Solution and Greedy Agl. Compared with VCG Solution and Greedy Agl mechanism, the time required for single round client data point selection has been reduced by 99.94% and 62.83%, respectively. FAIR and RRAFL are not significantly different from our MRATR mechanism in terms of selection time, but MRATR performs better than FAIR and RRAFL on the CIFAR-10 and IMAGE-100 datasets. Therefore, in cases where the client data scale is large, the use of MRATR mechanism for volatile FL model training can be considered to reduce computational pressure on the device and improve model performance.
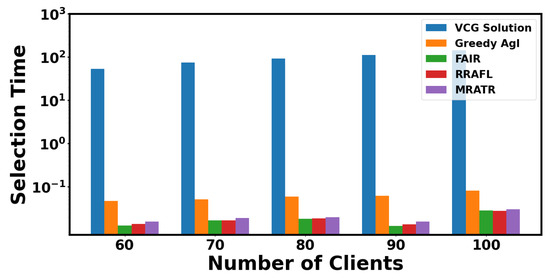
Figure 10.
Selection time required for client selection through different mechanisms.
6. Conclusions
This article delves into the design of incentive mechanisms for data owners in FL. It proposes a new multidimensional reverse auction mechanism to address the challenges posed by client volatility and data quality differences in FL. The design of this mechanism considers two key factors: the uncertainty of client training time and the client’s reputation. Firstly, we introduced customer reputation to objectively reflect the data quality of the client and the stability of the client’s training status. Then, we transformed the goal of maximizing social welfare into an optimization problem, proving that the problem is NP-hard. To address this issue, we propose the MRATR mechanism, which can achieve near maximization of social welfare while maintaining low time complexity. In addition, it can also accelerate the convergence speed and improve the testing accuracy of volatile FL models. Finally, the effectiveness of the mechanism was verified through simulation experiments. The current mechanism mainly focuses on maximizing social welfare, ensuring computational efficiency and model performance, but in practical applications, other goals such as data privacy protection and system security may also need to be considered. In future research, we will explore how to integrate more advanced privacy protection technologies and security protocols into incentive mechanisms to ensure the security and privacy of data during transmission, processing, and storage, as well as how to find a balance between multiple objectives, and design incentive mechanisms that can dynamically adjust and optimize objectives.
Author Contributions
Conceptualization, Y.H. and Z.Z.; methodology, Y.H. and Z.Z.; software, Y.H. and Z.Z.; validation, Y.H., Z.Z. and Z.W.; formal analysis, Y.H. and Z.Z.; investigation, Y.H. and Z.Z.; data curation, Y.H. and Z.Z.; writing—original draft preparation, Y.H. and Z.Z.; writing—review and editing, Z.Z. and Y.H.; visualization, Y.H.; supervision, Z.Z.; project administration, Z.Z.; funding acquisition, Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by Hainan Provincial Natural Science Foundation of China (Grant No. 622RC616) and Hainan Province Science and Technology Special Fund (Grant No. ZDYF2024GXJS008).
Data Availability Statement
The CIFAR-10 dataset presented in the study are openly available in [https://www.cs.toronto.edu/~kriz/cifar.html]. The IMAGE-100 dataset presented in the study are openly available in [https://pan.baidu.com/s/1PwQFY7ZSnZd5REg38IFaJQ(yxzb)].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Dai, H.; Hong, Y. Research on Model Optimization Technology of Federated Learning. In Proceedings of the 2023 IEEE 8th International Conference on Big Data Analytics (ICBDA), Harbin, China, 3–5 March 2023; pp. 107–112. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, C.; Lei, D.; Wu, T.; Liu, X.; Zhu, L. Achieving Privacy-Preserving and Verifiable Support Vector Machine Training in the Cloud. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3476–4291. [Google Scholar] [CrossRef]
- Zhang, C.; Luo, X.; Liang, J.; Liu, X.; Zhu, L.; Guo, S. POTA: Privacy-preserving online multi-task assignment with path planning. IEEE Trans. Mob. Comput. 2023, 23, 5999–6011. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Liang, J.; Fan, Q.; Zhu, L.; Guo, S. NANO: Cryptographic Enforcement of Readability and Editability Governance in Blockchain Database. IEEE Trans. Dependable Secur. Comput. 2023; early access. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, C.; Wu, T.; Zhu, L.; Liu, X. Achieving Efficient and Privacy-Preserving Neural Network Training and Prediction in Cloud Environments. IEEE Trans. Dependable Secur. Comput. 2023, 20, 4245–4257. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhou, Y.; Sun, Y.; Wang, Z.; Liu, B.; Li, K. Federated Learning in Smart Cities: A Comprehensive Survey. arXiv 2021, arXiv:2102.01375. [Google Scholar]
- Mcmahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2016. [Google Scholar]
- Chen, S.; Miao, Y.; Li, X.; Zhao, C. Compressed Sensing-Based Practical and Efficient Privacy-Preserving Federated Learning. IEEE Internet Things J. 2023, 11, 14017–14030. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, Y.; Qiu, C.; Liu, Z.; Nie, J.; Leung, V.C.M. InFEDge: A Blockchain-Based Incentive Mechanism in Hierarchical Federated Learning for End-Edge-Cloud Communications. IEEE J. Sel. Areas Commun. 2022, 40, 3325–3342. [Google Scholar] [CrossRef]
- Zheng, Z.; Qin, Z.; Li, K.; Qiu, T. A team-based multitask data acquisition scheme under time constraints in mobile crowd sensing. Connect. Sci. 2022, 34, 1119–1145. [Google Scholar] [CrossRef]
- Yu, H.; Liu, Z.; Liu, Y.; Chen, T.; Cong, M.; Weng, X.; Niyato, D.; Yang, Q. A Sustainable Incentive Scheme for Federated Learning. IEEE Intell. Syst. 2020, 35, 58–69. [Google Scholar] [CrossRef]
- Zhou, Y.; Shi, M.; Tian, Y.; Li, Y.; Ye, Q.; Lv, J. Federated CINN Clustering for Accurate Clustered Federated Learning. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 5590–5594. [Google Scholar] [CrossRef]
- Tang, R.; Jiang, M. Enhancing Federated Learning: Transfer Learning Insights. In Proceedings of the 2024 IEEE 3rd International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 27–29 February 2024; pp. 1358–1362. [Google Scholar] [CrossRef]
- Wang, D.; Ren, J.; Wang, Z.; Wang, Y.; Zhang, Y. PrivAim: A Dual-Privacy Preserving and Quality-Aware Incentive Mechanism for Federated Learning. IEEE Trans. Comput. 2023, 72, 1913–1927. [Google Scholar] [CrossRef]
- Behera, M.R.; Chakraborty, S. pFedGame - Decentralized Federated Learning Using Game Theory in Dynamic Topology. In Proceedings of the 2024 16th International Conference on COMmunication Systems & NETworkS (COMSNETS), Bengaluru, India, 3–7 January 2024; pp. 651–655. [Google Scholar] [CrossRef]
- Tuo, J.; Shang, K.; Ma, X.; Cui, M.; Liu, Y.; Wang, Y. Federated Learning for ASR Based on FedEA. In Proceedings of the 2024 IEEE 7th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 15–17 March 2024; Volume 7, pp. 337–341. [Google Scholar] [CrossRef]
- Imteaj, A.; Thakker, U.; Wang, S.; Li, J.; Amini, M.H. A survey on federated learning for resource-constrained IoT devices. IEEE Internet Things J. 2021, 9, 1–24. [Google Scholar] [CrossRef]
- Beitollahi, M.; Lu, N. Federated learning over wireless networks: Challenges and solutions. IEEE Internet Things J. 2023, 10, 14749–14763. [Google Scholar] [CrossRef]
- Zheng, Z.; Qin, Z.; Li, D.; Li, K.; Xu, G. A Holistic Client Selection Scheme in Federated Mobile CrowdSensing Based on Reverse Auction. In Proceedings of the 2022 IEEE 25th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Hangzhou, China, 4–6 May 2022; pp. 1305–1310. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Y.; Pan, R. Incentive Mechanism for Horizontal Federated Learning Based on Reputation and Reverse Auction. In Proceedings of the WWW ’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021. [Google Scholar]
- Xu, J.; Tang, B.; Cui, H.; Ye, B. An Uncertainty-Aware Auction Mechanism for Federated Learning. In Algorithms and Architectures for Parallel Processing; Tari, Z., Li, K., Wu, H., Eds.; Springer: Singapore, 2024; pp. 1–18. [Google Scholar]
- Wu, C.; Zhu, Y.; Zhang, R.; Chen, Y.; Wang, F.; Cui, S. FedAB: Truthful Federated Learning With Auction-Based Combinatorial Multi-Armed Bandit. IEEE Internet Things J. 2023, 10, 15159–15170. [Google Scholar] [CrossRef]
- Su, P.Y.; Tsai, P.H.; Lin, Y.K.; Wei, H.Y. Valuation-Aware Federated Learning: An Auction-Based Approach for User Selection. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Y.; Pan, R. Auction-Based Ex-Post-Payment Incentive Mechanism Design for Horizontal Federated Learning with Reputation and Contribution Measurement. arXiv 2022, arXiv:2201.02410. [Google Scholar]
- Shi, F.; Hu, C.; Lin, W.; Fan, L.; Huang, T.; Wu, W. VFedCS: Optimizing Client Selection for Volatile Federated Learning. IEEE Internet Things J. 2022, 9, 24995–25010. [Google Scholar] [CrossRef]
- Shi, F.; Lin, W.; Fan, L.; Lai, X.; Wang, X. Efficient Client Selection Based on Contextual Combinatorial Multi-Arm Bandits. IEEE Trans. Wirel. Commun. 2023, 22, 5265–5277. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konen, J.; Mazzocchi, S.; Mcmahan, H.B. Towards Federated Learning at Scale: System Design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Lueth, K.L. State of the IoT 2020. Available online: https://iot-analytics.com/state-of-the-iot-2020-12-billion-iot-connections-surpassing-non-iot-for-the-first-time (accessed on 19 November 2020).
- Zhan, Y.; Zhang, J.; Hong, Z.; Wu, L.; Guo, S. A Survey of Incentive Mechanism Design for Federated Learning. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1035–1044. [Google Scholar] [CrossRef]
- Zeng, R.; Zeng, C.; Wang, X.; Li, B.; Chu, X. Incentive Mechanisms in Federated Learning and A Game-Theoretical Approach. IEEE Netw. 2022, 36, 229–235. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, Z.; Qiu, C.; Wang, X.; Yu, F.R.; Leung, V.C. An Incentive Mechanism for Big Data Trading in End-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Xia, W.; Wen, W.; Wong, K.K.; Quek, T.Q.; Zhang, J.; Zhu, H. Federated-Learning-Based Client Scheduling for Low-Latency Wireless Communications. IEEE Wirel. Commun. 2021, 28, 32–38. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ma, C.; Ding, M.; Chen, C.; Jin, S.; Han, Z.; Poor, H.V. Low-Latency Federated Learning over Wireless Channels with Differential Privacy. IEEE J. Sel. Areas Commun. 2021, 40, 290–307. [Google Scholar] [CrossRef]
- Xia, W.; Quek, T.Q.S.; Guo, K.; Wen, W.; Zhu, H. Multi-Armed Bandit Based Client Scheduling for Federated Learning. IEEE Trans. Wirel. Commun. 2020, 19, 7108–7123. [Google Scholar] [CrossRef]
- Lai, F.; Zhu, X.; Madhyastha, H.V.; Chowdhury, M. Oort: Efficient Federated Learning via Guided Participant Selection. 2020. Available online: https://www.usenix.org/conference/osdi21/presentation/lai (accessed on 15 May 2024).
- Yoshida, N.; Nishio, T.; Morikura, M.; Yamamoto, K. MAB-based Client Selection for Federated Learning with Uncertain Resources in Mobile Networks. In Proceedings of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.; Xie, S.; Zhang, J. Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Combining Reputation and Contract Theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, C.; Li, S. Differential private knowledge trading in vehicular federated learning using contract theory. Knowl.-Based Syst. 2024, 285, 111356. [Google Scholar] [CrossRef]
- Cao, M.; Wang, Q.; Wang, Q. Federated learning in smart home: A dynamic contract-based incentive approach with task preferencc.manes. Comput. Netw. 2024, 249, 110510. [Google Scholar] [CrossRef]
- Zeng, R.; Zhang, S.; Wang, J.; Chu, X. FMore: An Incentive Scheme of Multi-dimensional Auction for Federated Learning in MEC. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 23 February 2021. [Google Scholar]
- Jiao, Y.; Wang, P.; Niyato, D.; Lin, B.; Kim, D.I. Toward an Automated Auction Framework for Wireless Federated Learning Services Market. IEEE Trans. Mob. Comput. 2019, 20, 3034–3048. [Google Scholar] [CrossRef]
- Tang, Y.; Liang, Y.; Liu, Y.; Zhang, J.; Ni, L.; Qi, L. Reliable federated learning based on dual-reputation reverse auction mechanism in Internet of Things. Future Gener. Comput. Syst. 2024, 156, 269–284. [Google Scholar] [CrossRef]
- Huang, T.; Lin, W.; Shen, L.; Li, K.; Zomaya, A.Y. Stochastic Client Selection for Federated Learning With Volatile Clients. IEEE Internet Things J. 2022, 9, 20055–20070. [Google Scholar] [CrossRef]
- Wu, B.; Fang, F.; Wang, X. Joint Age-Based Client Selection and Resource Allocation for Communication-Efficient Federated Learning Over NOMA Networks. IEEE Trans. Commun. 2024, 72, 179–192. [Google Scholar] [CrossRef]
- Zhan, Y.; Li, P.; Qu, Z.; Zeng, D.; Guo, S. A Learning-Based Incentive Mechanism for Federated Learning. IEEE Internet Things J. 2020, 7, 6360–6368. [Google Scholar] [CrossRef]
- Ahmed, K.; Tasnim, S.; Yoshii, K. Simulation of Auction Mechanism Model for Energy-Efficient High Performance Computing. In Proceedings of the ACM SIGSIM Conference on Principles of Advanced Discrete Simulation, Miami, FL, USA, 15–17 June 2020. [Google Scholar]
- Dütting, P.; Henzinger, M.; Starnberger, M. Valuation compressions in VCG-based combinatorial auctions. LSE Res. Online Doc. Econ. 2018, 6, 2167–8375. [Google Scholar] [CrossRef]
- Gu, Y.; Hou, D.; Wu, X.; Tao, J.; Zhang, Y. Decentralized Transaction Mechanism Based on Smart Contract in Distributed Data Storage. Information 2018, 9, 286. [Google Scholar] [CrossRef]
- Huang, D.; Huang, C.; Xu, J.; Liu, Y.; Li, T.; Ma, S. Carbon Neutrality-Oriented Energy Sharing for Prosumers Based on VCG Auction Mechanism. In Proceedings of the 2022 4th International Conference on Power and Energy Technology (ICPET), Qinghai, China, 28–31 July 2022; pp. 922–926. [Google Scholar] [CrossRef]
- Gautier, A.; Wooldridge, M. Understanding Mechanism Design—Part 3 of 3: Mechanism Design in the Real World: The VCG Mechanism. IEEE Intell. Syst. 2022, 37, 108–109. [Google Scholar] [CrossRef]
- Deng, Y.; Lyu, F.; Ren, J.; Chen, Y.C.; Yang, P.; Zhou, Y.; Zhang, Y. FAIR: Quality-Aware Federated Learning with Precise User Incentive and Model Aggregation. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).