
LD-YOLOv10: A Lightweight Target Detection Algorithm for Drone Scenarios Based on YOLOv10

Abstract
:1. Introduction
- To address the issue of excessive parameter count and computational load in the model, we proposed the RGELAN structure, which reduces the number of parameters and computational load of the feature extraction structure by over half.
- To tackle the problem of small target misdetection, we designed the DR-PAN Neck structure. This increases small target detection accuracy by incorporating shallow feature maps using DySample [13] and the RGELAN structure to reduce computational load.
- We optimized the bounding box regression loss to the Wise-EIoU loss function, addressing the issue of anchor box quality while providing more refined and efficient adjustments to anchor box shapes.
- We proposed a lightweight network model for detecting aerial targets, which reduces computational load while maintaining detection accuracy. The model’s real-time detection capability was validated on the Jetson Orin Nano, demonstrating its potential for real-time drone application.
2. Related Work
3. Proposed Models
3.1. Proposal Network Overview
3.1.1. Structure of YOLOv10
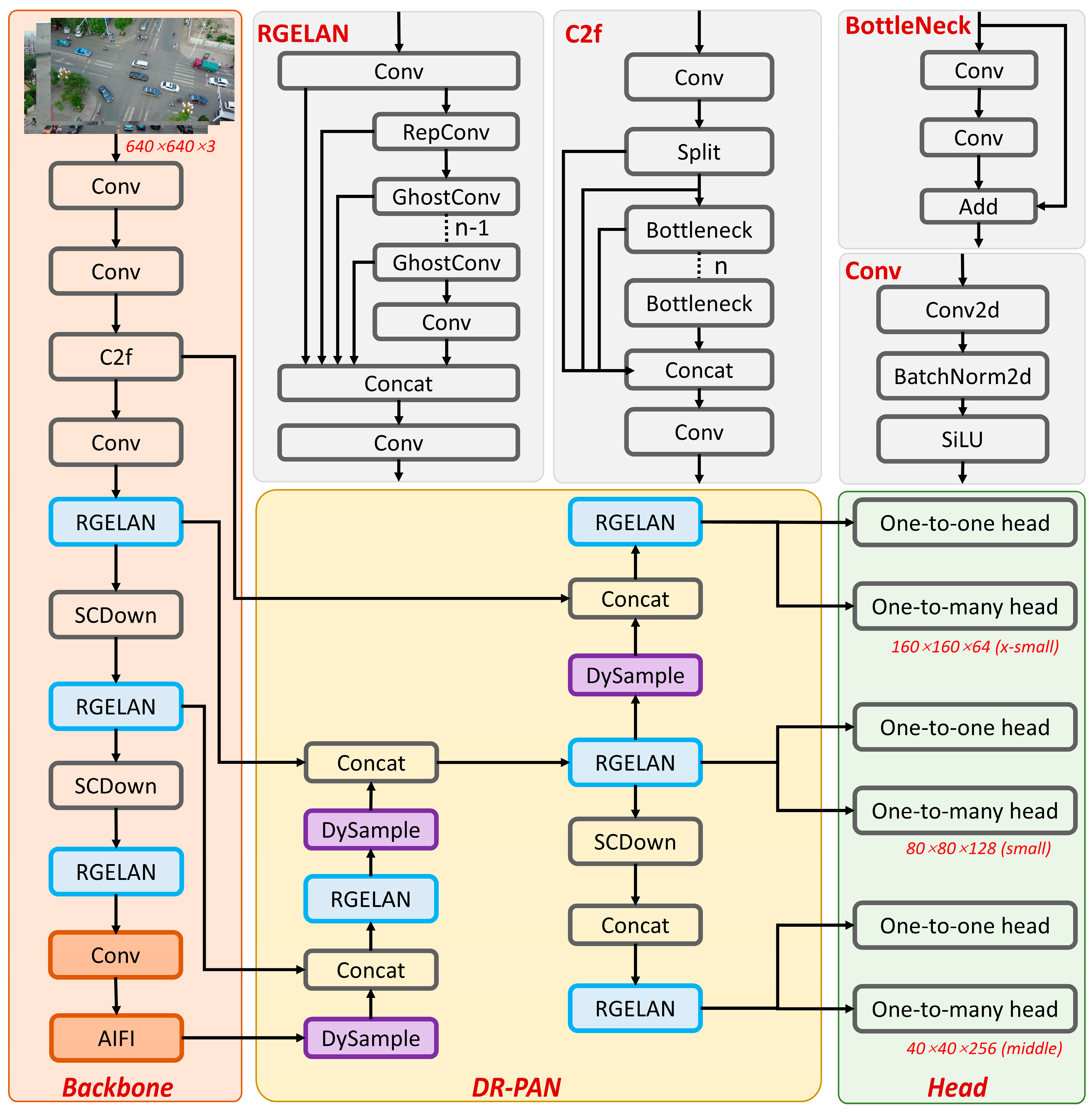
3.1.2. Structure of LD-YOLOv10
3.2. The RGELAN Structure
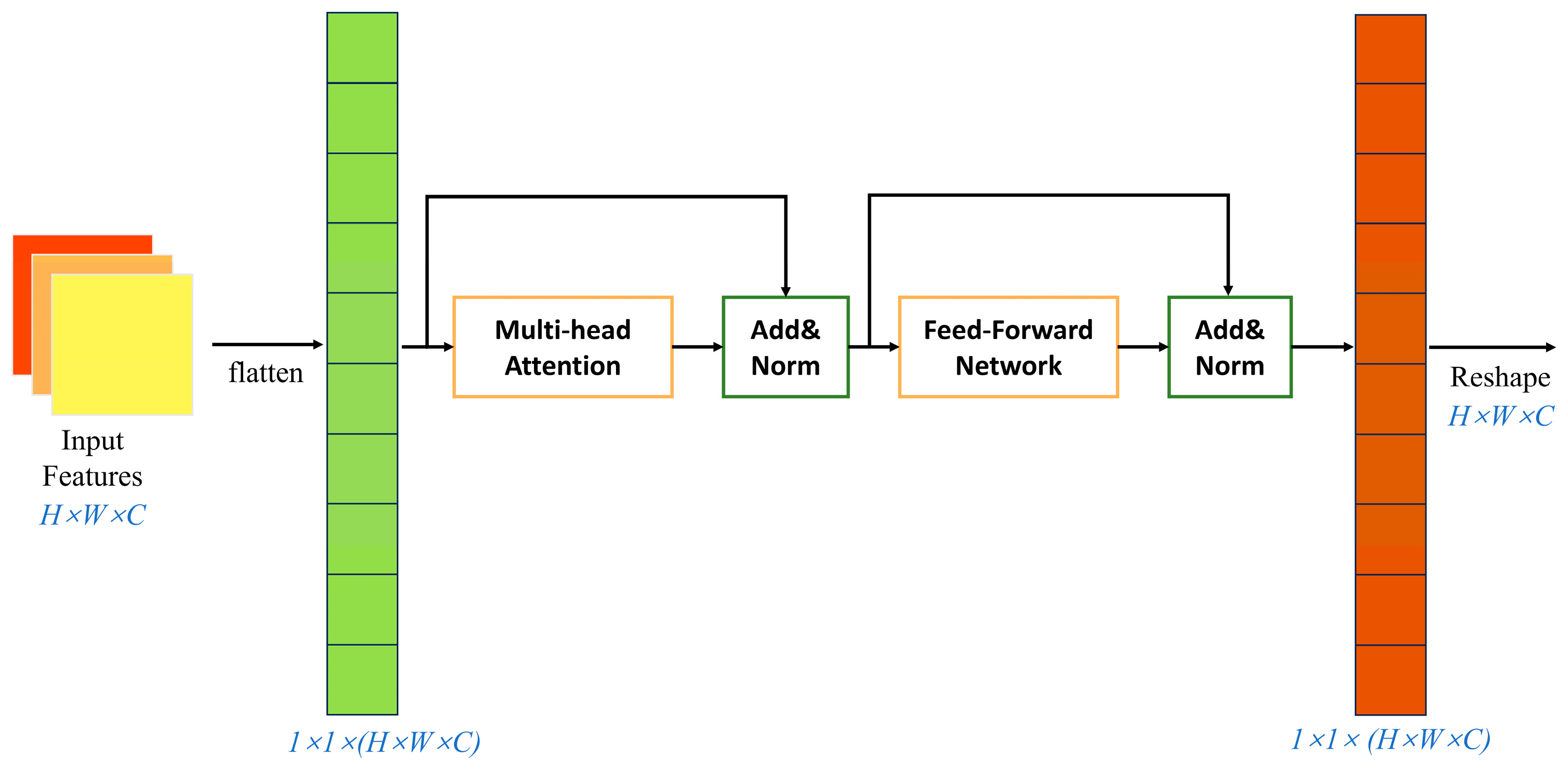
3.3. The AIFI Structure
3.4. The DR-PAN Neck Structure
3.5. Wise-EIoU Loss
4. Discussion
4.1. Dataset Description
4.2. Implementation Details and Evaluation Indicators
4.3. Ablation Experiments
4.3.1. Effect of RGELAN Module
4.3.2. Effect of Wise-EIoU Loss
4.3.3. Ablation Experiments of LD-YOLOv10
4.3.4. The Impact of Different IoUs
4.4. Comparisons with Lightweight Object Detection Networks
4.5. Extended Experiments
4.6. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cui, B.; Liang, L.; Ji, B.; Zhang, L.; Zhao, L.; Zhang, K.; Shi, F.; Creput, J.C. Exploring the YOLO-FT Deep Learning Algorithm for UAV-Based Smart Agriculture Detection in Communication Networks. IEEE Trans. Netw. Serv. Manag. 2024. Early Access. [Google Scholar] [CrossRef]
- Mao, G.; Liang, H.; Yao, Y.; Wang, L.; Zhang, H. Split-and-Shuffle Detector for Real-Time Traffic Object Detection in Aerial Image. IEEE Internet Things J. 2024, 11, 13312–13326. [Google Scholar] [CrossRef]
- Xu, J.; Fan, X.; Jian, H.; Xu, C.; Bei, W.; Ge, Q.; Zhao, T. YoloOW: A Spatial Scale Adaptive Real-Time Object Detection Neural Network for Open Water Search and Rescue From UAV Aerial Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5623115. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Min, X.; Zhou, W.; Hu, R.; Wu, Y.; Pang, Y.; Yi, J. LWUAVDet: A Lightweight UAV Object Detection Network on Edge Devices. IEEE Internet Things J. 2024, 11, 24013–24023. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Wang, Y.; Zou, H.; Yin, M.; Zhang, X. SMFF-YOLO: A Scale-Adaptive YOLO Algorithm with Multi-Level Feature Fusion for Object Detection in UAV Scenes. Remote Sens. 2023, 15, 4580. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, C.; Zhang, T.; Zheng, Y. Full-Scale Feature Aggregation and Grouping Feature Reconstruction-Based UAV Image Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5621411. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. ISBN 978-3-319-10601-4. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6027–6037. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Chaurasia, A.; Changyu, L.; Hogan, A.; Hajek, J.; Diaconu, L.; Kwon, Y.; Defretin, Y. Ultralytics/Yolov5: V5. 0-YOLOv5-P6 1280 Models, AWS, Supervise. Ly and YouTube Integrations. Zenodo 2021. [Google Scholar] [CrossRef]
- Jocher, G. Ultralytics YOLOv8: V6. Available online: https://Github.Com/Ultralytics/Ultralytics (accessed on 23 October 2023).
- Shen, L.; Su, J.; He, R.; Song, L.; Huang, R.; Fang, Y.; Song, Y.; Su, B. Real-Time Tracking and Counting of Grape Clusters in the Field Based on Channel Pruning with YOLOv5s. Comput. Electron. Agric. 2023, 206, 107662. [Google Scholar] [CrossRef]
- Liu, X.; Wang, T.; Yang, J.; Tang, C.; Lv, J. MPQ-YOLO: Ultra Low Mixed-Precision Quantization of YOLO for Edge Devices Deployment. Neurocomputing 2024, 574, 127210. [Google Scholar] [CrossRef]
- Ma, T.; Tian, W.; Xie, Y. Multi-Level Knowledge Distillation for Low-Resolution Object Detection and Facial Expression Recognition. Knowl.-Based Syst. 2022, 240, 108136. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for Small Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Cao, J.; Bao, W.; Shang, H.; Yuan, M.; Cheng, Q. GCL-YOLO: A GhostConv-Based Lightweight Yolo Network for UAV Small Object Detection. Remote Sens. 2023, 15, 4932. [Google Scholar] [CrossRef]
- Cao, L.; Song, P.; Wang, Y.; Yang, Y.; Peng, B. An Improved Lightweight Real-Time Detection Algorithm Based on the Edge Computing Platform for UAV Images. Electronics 2023, 12, 2274. [Google Scholar] [CrossRef]
- Mobilenetv3: A Deep Learning Technique for Human Face Expressions Identification|International Journal of Information Technology. Available online: https://link.springer.com/article/10.1007/s41870-023-01380-x (accessed on 21 July 2024).
- Yu, G.; Chang, Q.; Lv, W.; Xu, C.; Cui, C.; Ji, W.; Dang, Q.; Deng, K.; Wang, G.; Du, Y.; et al. PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices. arXiv 2021, arXiv:2111.00902. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An Evolved Version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Peng, G.; Yang, Z.; Wang, S.; Zhou, Y. AMFLW-YOLO: A Lightweight Network for Remote Sensing Image Detection Based on Attention Mechanism and Multiscale Feature Fusion. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4600916. [Google Scholar] [CrossRef]
- Xie, T.; Han, W.; Xu, S. YOLO-RS: A More Accurate and Faster Object Detection Method for Remote Sensing Images. Remote Sens. 2023, 15, 3863. [Google Scholar] [CrossRef]
- Gunasekara, S.; Gunarathna, D.; Dissanayake, M.B.; Aramith, S.; Muhammad, W. Deep Learning Based Autonomous Real-Time Traffic Sign Recognition System for Advanced Driver Assistance. Int. J. Image Graph. Signal Process. 2022, 14, 70–83. [Google Scholar] [CrossRef]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution Based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 6070–6079. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Soudy, M.; Afify, Y.; Badr, N. RepConv: A Novel Architecture for Image Scene Classification on Intel Scenes Dataset. Int. J. Intell. Comput. Inf. Sci. 2022, 22, 63–73. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Yang, Z.; Wang, X.; Li, J. EIoU: An Improved Vehicle Detection Algorithm Based on Vehiclenet Neural Network. J. Phys. Conf. Ser. 2021, 1924, 012001. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Gool, L.V.; Han, J. VisDrone-DET2021: The Vision Meets Drone Object Detection Challenge Results. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2847–2854. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Zhang, H.; Zhang, S. Shape-IoU: More Accurate Metric Considering Bounding Box Shape and Scale. arXiv 2024, arXiv:2312.17663. [Google Scholar]
- Powerful-IoU: More Straightforward and Faster Bounding Box Regression Loss with a Nonmonotonic Focusing Mechanism—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0893608023006640 (accessed on 21 July 2024).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Sun, J.; Gao, H.; Yan, Z.; Qi, X.; Yu, J.; Ju, Z. Lightweight UAV Object-Detection Method Based on Efficient Multidimensional Global Feature Adaptive Fusion and Knowledge Distillation. Electronics 2024, 13, 1558. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module Name | Meantime (%) | FPS | FLOPS | Params (K) |
|---|---|---|---|---|
| C3Ghost | 0.13 | 785 | 2.33 | 142.56 |
| C3 | 0.14 | 716 | 4.83 | 295.68 |
| ELAN | 0.20 | 501 | 8.05 | 492.28 |
| C2f | 0.18 | 543 | 7.51 | 459.52 |
| RepNCSPELAN4 | 0.14 | 707 | 3.69 | 226.17 |
| C2fCIB | 0.18 | 531 | 3.83 | 235.39 |
| RGELAN | 0.11 | 911 | 3.42 | 209.53 |
| Structure | FPN-PAN | FPN-PAN + P2 | FPN-PAN + P2 − P5 | DR-ELAN |
|---|---|---|---|---|
| Params (M) | 8.07 | 8.25 | 6.33 | 5.40 |
| FLOPS (G) | 24.8 | 37.1 | 35.4 | 29.5 |
| Hyperparameters | Value |
|---|---|
| Imgsz | 640 × 640 |
| Batch Size | 4 |
| Epoch | 300 |
| Weight Decay | 0.0005 |
| Momentum | 0.937 |
| Initial Learning Rate | 0.01 |
| Optimizer | SGD |
| Module | mAP0.5 | mAP0.5:0.95 | GFLOPS | Params (M) |
|---|---|---|---|---|
| C3Ghost | 36.7 | 21.8 | 20.6 | 7.28 |
| RepNCSPELAN4 | 37.2 | 22.2 | 22.7 | 7.84 |
| RGELAN | 37.2 | 22.3 | 20.9 | 7.24 |
| Method | P | R | mAP0.5 | mAP0.5:0.95 |
|---|---|---|---|---|
| CIoU | 46.6 | 37.8 | 38.1 | 22.8 |
| Wise-IoU | 47.5 | 38.2 | 38.3 | 22.7 |
| Wise-CIoU | 48.6 | 38.0 | 38.8 | 22.9 |
| Wise-DIoU | 48.0 | 37.6 | 38.2 | 22.8 |
| Wise-shapeIoU | 48.7 | 37.7 | 38.6 | 23.2 |
| Wise-PIoU2 | 47.6 | 38.6 | 38.8 | 23.0 |
| Wise-EIoU | 48.8 | 37.9 | 38.9 | 23.1 |
| Module | P (%) | R (%) | mAP0.5 (%) | mAP0.5:0.95 (%) | Params (M) | GFLOPS | Latency (ms) |
|---|---|---|---|---|---|---|---|
| YOLOv10-S | 50.1 | 38.3 | 38.8 | 23.3 | 8.04 | 24.5 | 6.9 |
| +RGELAN | 48.1 | 37.0 | 37.4 | 22.4 | 7.24 | 20.9 | 6.1 |
| +AIFI | 48.5 | 37.4 | 37.9 | 28.8 | 6.46 | 22.9 | 5.5 |
| +DR-PAN | 48.3 | 37.9 | 38.9 | 23.1 | 3.04 | 23.7 | 6.5 |
| +Wise-EIoU | 48.4 | 38.9 | 39.4 | 23.5 | 3.04 | 23.7 | 6.5 |
| IoU | mAP (%) | AP (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pedestrian | People | Bicycle | Car | Van | Truck | Tricycle | Awning-Tricycle | Bus | Motor | ||
| 0.5 | 39.4 | 46.2 | 35.3 | 12.4 | 82.1 | 46.1 | 31.7 | 25.2 | 16.1 | 51.5 | 47.4 |
| 0.75 | 24.2 | 21.7 | 14.7 | 5.5 | 58.2 | 32.0 | 20.1 | 14.1 | 10.3 | 36.0 | 22.3 |
| 0.9 | 5.0 | 17.2 | 8.9 | 4.0 | 66.0 | 36.7 | 21.7 | 14.4 | 11.8 | 43.1 | 17.6 |
| Model | Params (M) | GFLOPS | mAP50 (%) | mAP50:95 (%) | FPS |
|---|---|---|---|---|---|
| YOLOv3-Tiny (2018) | 8.68 | 12.9 | 15.9 | 6.9 | 195 |
| YOLOv4-Tiny (2020) | 5.90 | 16.2 | 13.5 | 24.4 | 172 |
| YOLOv5-S (2020) | 7.04 | 15.8 | 32.7 | 16.2 | 139 |
| PP-PicoDet-L (2021) | 3.30 | 8.90 | 34.2 | - | 150 |
| YOLOX-S (2021) | 9.00 | 26.8 | 34.0 | 19.8 | 106 |
| YOLOv6-N (2022) | 4.30 | 11.1 | 31.6 | 16.9 | - |
| YOLOv7-Tiny (2022) | 6.03 | 13.1 | 36.8 | 18.9 | 112 |
| YOLOv8-S (2023) | 11.1 | 28.5 | 39.2 | 23.4 | 128 |
| MELF-YOLOv5-S (2023) | 3.40 | 9.8 | 34.8 | 18.7 | - |
| MGFAFNET-S (2024) | 4.20 | 24.2 | 36.0 | 21.0 | - |
| YOLOv9-S (2024) | 9.60 | 38.8 | 38.6 | 23.2 | - |
| YOLOv10-S (2024) | 8.04 | 24.5 | 38.8 | 23.0 | 143 |
| LD-YOLOv10 (ours) | 3.04 | 23.7 | 39.4 | 23.5 | 147 |
| Network | Params (M) | GFLOPS | FPS | mAP50 (%) | |||
|---|---|---|---|---|---|---|---|
| ALL | Car | Truck | Bus | ||||
| YOLOv3-Tiny | 8.68 | 12.9 | 193 | 26.9 | 61.4 | 12.9 | 6.1 |
| YOLOv4-Tiny | 5.89 | 7.0 | 172 | 27.7 | 63.5 | 13.4 | 6.4 |
| YOLOv5-S | 7.04 | 15.8 | 138 | 29.8 | 70.1 | 14.4 | 5.0 |
| YOLOX-Tiny | 5.04 | 15.3 | 155 | 29.1 | 68.4 | 13.8 | 5.3 |
| PP-PicoDet-L | 3.30 | 8.9 | 151 | 31.1 | 71.2 | 16.5 | 5.8 |
| YOLOv7-Tiny | 6.03 | 13.1 | 114 | 31.2 | 70.4 | 16.8 | 6.8 |
| YOLOv8-S | 11.10 | 28.8 | 126 | 31.9 | 71.3 | 17.4 | 7.1 |
| LWUAVDet-S | 5.20 | 19.2 | - | 34.1 | - | - | - |
| YOLOv10 | 8.04 | 24.5 | 147 | 36.0 | 77.0 | 11.9 | 19.0 |
| LD-YOLOv10 | 3.04 | 23.7 | 146 | 36.3 | 74.9 | 20.4 | 13.7 |
| Model | mAP0.5 (%) | Params (M) | Model Scale (M) | FPS | Average Inference Time per Image |
|---|---|---|---|---|---|
| YOLOv10-S | 38.6 | 8.04 | 16.1 | 23 | 41.7 |
| LD-YOLOv10 | 39.3 | 3.04 | 6.3 | 25 | 38.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, X.; Chen, Y.; Cai, W.; Niu, M.; Li, J. LD-YOLOv10: A Lightweight Target Detection Algorithm for Drone Scenarios Based on YOLOv10. Electronics 2024, 13, 3269. https://doi.org/10.3390/electronics13163269
Qiu X, Chen Y, Cai W, Niu M, Li J. LD-YOLOv10: A Lightweight Target Detection Algorithm for Drone Scenarios Based on YOLOv10. Electronics. 2024; 13(16):3269. https://doi.org/10.3390/electronics13163269
Chicago/Turabian StyleQiu, Xiaoyang, Yajun Chen, Wenhao Cai, Meiqi Niu, and Jianying Li. 2024. "LD-YOLOv10: A Lightweight Target Detection Algorithm for Drone Scenarios Based on YOLOv10" Electronics 13, no. 16: 3269. https://doi.org/10.3390/electronics13163269
APA StyleQiu, X., Chen, Y., Cai, W., Niu, M., & Li, J. (2024). LD-YOLOv10: A Lightweight Target Detection Algorithm for Drone Scenarios Based on YOLOv10. Electronics, 13(16), 3269. https://doi.org/10.3390/electronics13163269