
A UAV Aerial Image Target Detection Algorithm Based on YOLOv7 Improved Model

Abstract
1. Introduction
- (1)
- The small target detection layer (P2) was added, and the deep detection layer (P5) was eliminated. At the same time, the K-means++ method [11] was used to compute the anchor frame after operation. This enhanced the performance of the model in detecting small targets and reduced the possibility of false detection or missed detection.
- (2)
- (3)
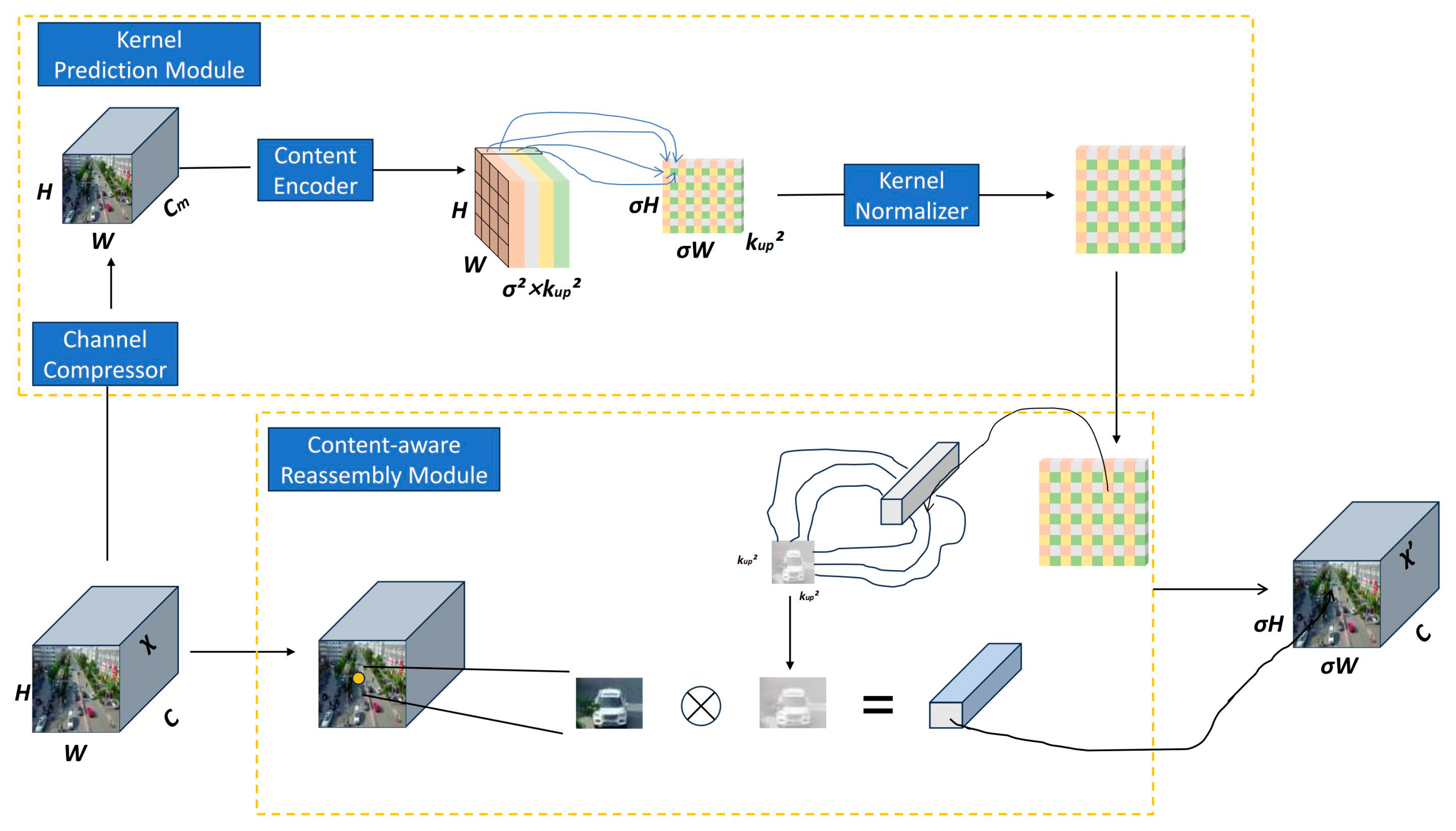
- Introducing the CARAFE module [14] as a replacement for traditional upsampling methods allowed for a larger field of view, effectively aggregating contextual information to enhance the acquisition of target feature information.
- (4)
- A new convolution module, SPD-Conv [15], was introduced to improve computational efficiency, enhance the model’s performance and generalization ability, reduce information loss, and strengthen the feature extraction capability for small target objects.
2. Related Work
2.1. Common Target Detection Algorithms
2.2. YOLO Architectures Suitable for Aerial Imagery
2.3. YOLOv7 Network Structure
3. Method
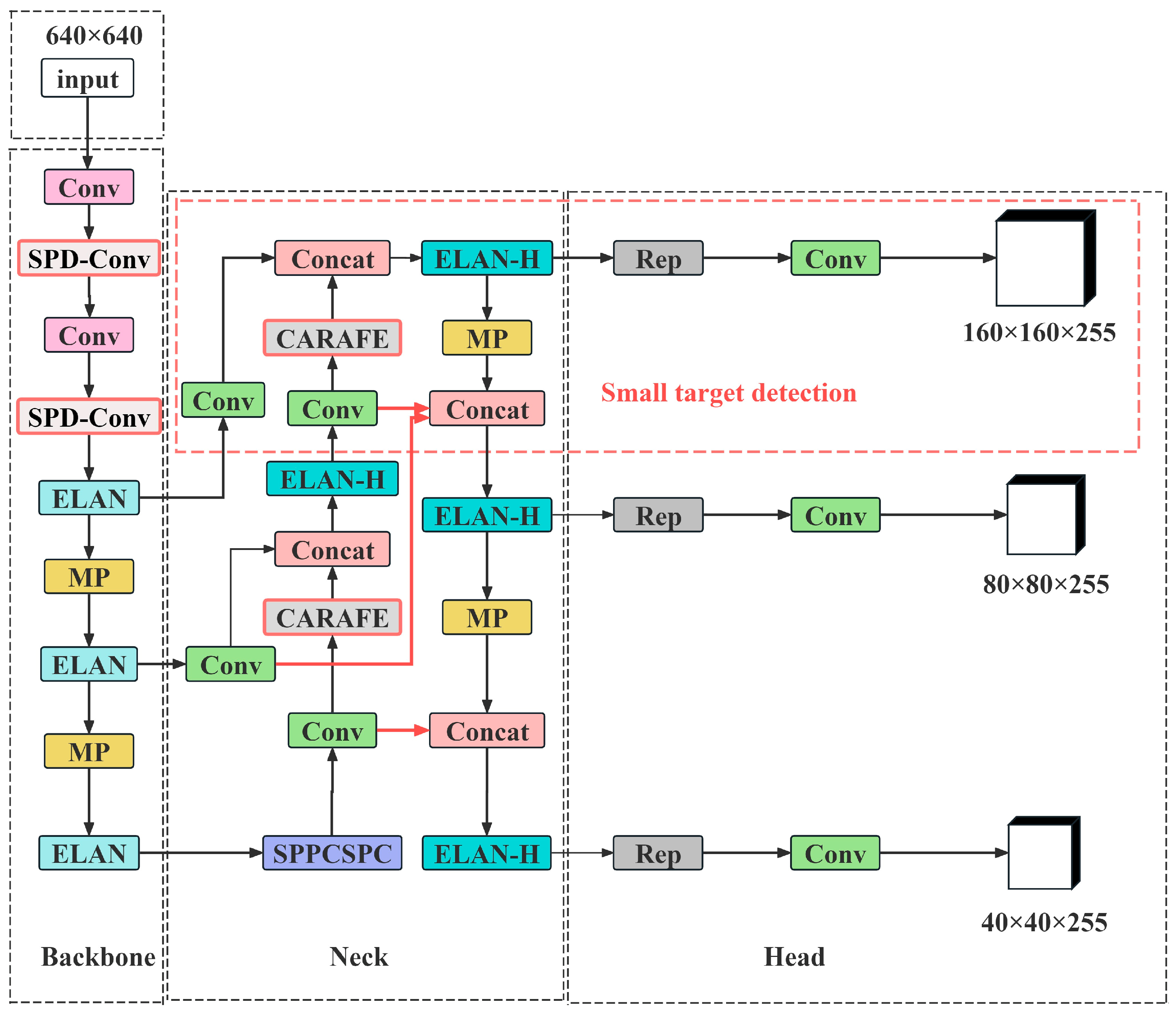
3.1. CMS-YOLOv7
3.2. Small Target Detection Layer
3.3. Inner-MPDIoU
3.4. CARAFE
3.5. SPD-Conv
4. Experiments
4.1. Dataset
4.2. Parameter Settings
4.3. Evaluation Metrics
4.4. Ablation Experiments
4.4.1. Comparison with Baseline Model
4.4.2. Determining Parameters in Inner-MPDIoU
4.5. Detection Results Visualization
4.6. Comparison with Other Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fan, B.; Li, Y.; Zhang, R.; Fu, Q. Review on the technological development and application of UAV systems. Chin. J. Electron. 2020, 29, 199–207. [Google Scholar] [CrossRef]
- Do-Duy, T.; Nguyen, L.D.; Duong, T.Q.; Khosravirad, S.R.; Claussen, H. Joint optimisation of real-time deployment and resource allocation for UAV-aided disaster emergency communications. IEEE J. Sel. Areas Commun. 2021, 39, 3411–3424. [Google Scholar] [CrossRef]
- Villarreal, C.A.; Garzón, C.G.; Mora, J.P.; Rojas, J.D.; Ríos, C.A. Workflow for capturing information and characterizing difficult-to-access geological outcrops using unmanned aerial vehicle-based digital photogrammetric data. J. Ind. Inf. Integr. 2022, 26, 100292. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-Means++: The Advantages of Careful Seeding; Stanford: Stanford, CA, USA, 2006. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 3007–3016. [Google Scholar]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Grenoble, France, 19–23 September 2022; pp. 443–459. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics: Yolov5. [EB/OL]. Available online: https://github.com/ultralytics/yolov5 (accessed on 23 July 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. YOLOv9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37, Proceedings, Part I 14. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Qin, Z.; Chen, D.; Wang, H. MCA-YOLOv7: An Improved UAV Target Detection Algorithm Based on YOLOv7. IEEE Access 2024, 12, 42642–42650. [Google Scholar] [CrossRef]
- Wu, H.; Hua, Y.; Zou, H.; Ke, G. A lightweight network for vehicle detection based on embedded system. J. Supercomput. 2022, 78, 18209–18224. [Google Scholar] [CrossRef]
- Liu, S.; Zha, J.; Sun, J.; Li, Z.; Wang, G. EdgeYOLO: An edge-real-time object detector. In Proceedings of the 2023 42nd Chinese Control Conference (CCC), Tianjin, China, 24–26 July 2023; pp. 7507–7512. [Google Scholar]
- Zhao, L.; Zhu, M. MS-YOLOv7: YOLOv7 based on multi-scale for object detection on UAV aerial photography. Drones 2023, 7, 188. [Google Scholar] [CrossRef]
- Siliang, M.; Yong, X. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Layer | Feature Map Size | Anchor Frame Setting |
|---|---|---|
| P2 | 160 × 160 | [3, 4, 4, 8, 7, 6] |
| P3 | 80 × 80 | [7, 12, 14, 8, 11, 17] |
| P4 | 40 × 40 | [27, 15, 21, 28, 48, 38] |
| Add P2 | Remove P5 with Optimized Neck | Inner-MPDIoU | CARAFE | SPD-Conv | mAP@0.5 | mAP@0.5:0.95 | Params (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|
| 48.8% | 27.7% | 36.53 | 103.3 | 119 | |||||
| √ | 50.0% | 29.5% | 37.08 | 117.1 | 96 | ||||
| √ | √ | 50.3% | 29.7% | 17.71 | 116.9 | 102 | |||
| √ | √ | √ | 50.7% | 29.9% | 17.71 | 116.9 | 104 | ||
| √ | √ | √ | √ | 51.1% | 30.2% | 17.84 | 117.9 | 88 | |
| √ | √ | √ | √ | √ | 52.3% | 30.7% | 17.99 | 166.0 | 73 |
| Ratio | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|
| 1.30 | 50.6% | 29.8% |
| 1.33 | 50.7% | 29.9% |
| 1.35 | 50.7% | 29.8% |
| 1.37 | 50.6% | 29.7% |
| 1.40 | 50.5% | 29.7% |
| 1.41 | 50.5% | 29.6% |
| 1.45 | 50.3% | 29.5% |
| Model | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|
| YOLOv4 | 47.5% | 26.1% |
| YOLOv5l | 39.8% | 22.9% |
| TPH-YOLOv5 | 46.4% | 27.6% |
| YOLOv6m | 31.9% | 21.8% |
| YOLOv7 | 48.8% | 27.7% |
| YOLOv8 | 45.5% | 27.8% |
| CMS-YOLOv7 | 52.3% | 30.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, J.; Yu, W.; Feng, X.; Meng, Z.; Tan, C. A UAV Aerial Image Target Detection Algorithm Based on YOLOv7 Improved Model. Electronics 2024, 13, 3277. https://doi.org/10.3390/electronics13163277
Qin J, Yu W, Feng X, Meng Z, Tan C. A UAV Aerial Image Target Detection Algorithm Based on YOLOv7 Improved Model. Electronics. 2024; 13(16):3277. https://doi.org/10.3390/electronics13163277
Chicago/Turabian StyleQin, Jie, Weihua Yu, Xiaoxi Feng, Zuqiang Meng, and Chaohong Tan. 2024. "A UAV Aerial Image Target Detection Algorithm Based on YOLOv7 Improved Model" Electronics 13, no. 16: 3277. https://doi.org/10.3390/electronics13163277
APA StyleQin, J., Yu, W., Feng, X., Meng, Z., & Tan, C. (2024). A UAV Aerial Image Target Detection Algorithm Based on YOLOv7 Improved Model. Electronics, 13(16), 3277. https://doi.org/10.3390/electronics13163277