Abstract
With the development of artificial intelligence (AI), deepfakes, in which the face of one person is changed to another expression of the same person or a different person, have advanced. There is a need for countermeasures against crimes that exploit deepfakes. Methods to interfere with deepfake generation by adding an invisible weak adversarial signal to an image have been proposed. However, there is a problem: the weak signal can be easily removed by processing the image. In this paper, we propose trap signals that appear in response to a process that weakens adversarial signals. We also propose a new type of adversarial signal injection that allow us to reconstruct and change the original image as far as people do not feel strange by Denoising Diffusion Probabilistic Model (DDPM)-based Iterative Latent Variable Refinement. In our experiments with Star Generative Adversarial Network (StarGAN) trained with the CelebFaces Attributes (CelebA) Dataset, we demonstrate that the proposed approach achieves more robust proactive deepfake defense.
1. Introduction
In recent years, image generation techniques have evolved rapidly, and we can now easily obtain realistic synthesized or edited images using various deep learning models, such as generative adversarial network (GAN) models [1,2,3,4,5,6,7] and Denoising Diffusion Probabilistic Models (DDPMs) [8,9,10]. These generated images are also known as deepfakes, and deepfakes pose a number of problems, such as e-fraud and disinformation. Moreover, currently, many people post pictures of themselves and their friends on social media. By using such images, deepfake images that resemble a specific person can be created. This raises concerns about the creation and misuse of images that violate personal privacy. These problems can have serious consequences, and countermeasures against deepfakes have been proposed. There are two main ways to deal with deepfakes [11]: a passive way to detect deepfakes in any possible image, and a proactive way to use noise to disrupt the deepfake generation process.
In the field of image forensics research, the detection of tampered images has been studied for a long time. For example, tamper detection methods using image sensor noise have been proposed [12,13]. These methods use noise caused by variations in the sensitivity characteristics of the pixels of an image sensor, or periodic noise that depends on the design of the image sensor, as a clue to identify the tampered area. On the other hand, images produced by GAN and DDPM also have model-specific artifacts. For this reason, various deep-learning-based methods [14,15,16,17,18] have been proposed to detect deepfakes using such artifacts. A novel approach to deepfake detection utilizes a deep neural network fusion, as proposed by reference [19]. This method leverages the common features learned across different deep learning architectures to create a low-power-consuming and accurate defense system deployable on mobile devices. By identifying breakpoints in different networks, and dividing the obtained knowledge into fixed and adaptive information, this approach combines the decision of multiple deep architectures for improved performance and computational efficiency in deepfake detection.
However, these methods cannot prevent the generation of deepfakes from images uploaded to social media, etc.
On the other hand, proactive deepfake defense methods interfere with the generation of deepfakes by adding weak signals to the image. They are based on the idea of adversarial examples (AEs), which attack vulnerabilities in deep learning models. For example, a projected gradient descent (PGD) [20] repeatedly perturbs the input image based on the gradient of the loss function of the target model so that the loss function increases. However, in order not to degrade image quality, the adversarial signal that interferes with deepfake models should be kept sufficiently weak. Therefore, there is a problem that manipulations such as JPEG compression, Gaussian blur, etc. degrade the adversarial signal and cause the obstruction to fail. Anti-Forgery [11] successfully generates adversarial signals that are harder to remove than PGD by perturbing only the a and b channels in the Lab color space. It maintains a higher attack success rate than PGD in evaluations using the CelebA dataset [21] and StarGAN [5]. However, the attack success rate drops to 5.8% by applying Gaussian blur to images with Anti-Forgery-based adversarial signals. Thus, the development of adversarial signals that are robust to Gaussian blur remains a significant challenge.
In this paper, we propose two methods based on new ideas for more robust proactive deepfake defense. Our main contributions are as follows:
- While adversarial signals have been previously explored in the context of deepfake detection, we introduce PGD-Trap, a novel approach that significantly advances the robustness of generate adversarial signals. Unlike existing methods, PGD-Trap specifically targets the vulnerability of conventional adversarial signals to linear filtering techniques, such as Gaussian blur. PGD-Trap generates trap signals by applying an inverse filter of linear filtering to weak adversarial signals initially produced by PGD. This unique approach ensures that the adversarial signals become more potent when subjected to common removal attempts. When users of deepfake generators attempt to remove these adversarial signals through expected linear filters, our trap signals become stronger. This adaptive behavior significantly interferes with the generation of deepfakes, providing a more robust defense against manipulation attempts.
- Existing methods assume that the original image is as unaltered by adversarial signals as much as possible. However, in practice, images are often modified to improve or change their appearance when they are uploaded to social media. It is expected that social media users will be less resistant to slight changes in their images. Therefore, we propose a new method for embedding adversarial signals based on iterative latent variable refinement (ILVR) [22], which allows the original image to be modified within a reasonable range.
- We evaluate the proposed method for StarGAN with the CelebA dataset, and demonstrate that it is more robust against Gaussian blur than PGD approaches to interfere with deepfake generation.
2. Related Work
2.1. Deepfake Generation
Generative Adversarial Networks (GANs) [1] are a type of deep learning architecture that involves two neural networks competing against each other in a game-theoretic way. The goal is to generate new, synthetic data that resembles the training data distribution. A GAN is composed of a generator and a discriminator.
StarGAN [5] achieves multiple domain transformations with a single generator and discriminator: the StarGAN discriminator takes two input images, a real image and a fake image generated by the generator, and determines whether the image is real or not, and the domain of the input image. The generator receives an input image and the target domain and generates a fake image of the target domain. In addition to training the generator to fool the discriminator, cycle-consistency between the original domain and the target domain is also introduced. Using StarGAN, it is possible to transform subject attributes such as hair color and facial expression. This can be used to generate images that violate the subject’s privacy. For this reason, it is important to take measures to prevent GAN from changing attributes before uploading images to social media, etc.
Another significant development in the field is the introduction of Evolutionary GANs (E-GANs) by [7]. E-GANs address common training problems in existing GANs, such as instability and mode collapse, by evolving a population of generators to play the adversarial game with the discriminator. This framework employs different adversarial training objectives as mutation operations, and implements an evaluation mechanism to measure the quality and diversity of generated samples. By preserving only well-performing generators for further training, E-GANs overcome the limitations of individual adversarial training objectives and contribute to the progress and success of GANs.
Denoising diffusion probabilistic models (DDPMs) [8] are a class of generative models that have gained significant popularity in recent years, particularly for high-quality image generation tasks. These models are based on the principles of non-equilibrium thermodynamics and leverage diffusion processes to learn data distributions. In DDPM-based image generation, a fake image is generated by repeating an inverse diffusion process that corresponds to denoising from the initial noise. Iterative Latent Variable Refinement (ILVR) [22] is an improved version of DDPM that guides the generative process in DDPM to generate high-quality images with a given reference image. In each inverse diffusion process, the low-frequency component of the noisy image in the process of generation is replaced by the low-frequency component of a reference image with a similar level of noise, thereby inducing the generation of an image that is closer to the reference image.
2.2. Proactive Deepfake Defense
Adversarial signals, in the context of deep learning, refer to intentionally crafted inputs designed to cause a trained model to make mistakes or produce undesirable outputs. Those adversarial signals are usually contained in adversarial examples, which are inputs that have been carefully modified or perturbed in a way that can cause a machine-learning model to misclassify them, despite appearing visually indistinguishable from the original inputs to human observers. These examples are created by introducing small, intentional perturbations to the input data, such as images or text, with the goal of causing the model to generate incorrect results. By and large, adversarial signals are used to verify the robustness of a model, but it is also an effective countermeasure against malicious content such as deepfakes.
There are gradient-based methods to generate adversarial examples, such as the Fast Gradient Sign Method (FGSM) [23] and the Projected Gradient Descent (PGD) [20] method. FGSM utilizes the gradient information of the loss function with respect to the input to generate adversarial examples. The method adds carefully crafted perturbations to the original input, resulting in misclassification by the target neural network. The adversarial example is generated as follows:
where:
- is the generated adversarial image;
- is the original input image;
- is the perturbation magnitude, which controls the intensity of the adversarial noise, and can be interpreted as a learning rate;
- represents the model parameters;
- y is the true label;
- is the loss function of the model;
- denotes the gradient with respect to the input .
The PGD method extends FGSM by iteratively applying the perturbation. It generates adversarial examples through multiple steps, each time updating the input sample in the direction of the loss function’s gradient. This iterative process is subject to constraints on the overall magnitude of the perturbation, allowing for a more refined exploration of the adversarial space.
The Carlini and Wagner (C&W) attack [24] generates adversarial examples by solving an optimization problem that finds the smallest perturbation such that the target model fails to inference.
The authors in reference [25] proposed a method that applies different weights to the red, green, and blue channels of images when generating adversarial perturbations. This technique aims to minimize human-detectable distortions while maintaining high attack success rates against deep neural networks. Using the CIFAR-10 dataset, the method achieved 100% attack success with lower distortion compared to traditional approaches like FGSM. This work demonstrates the potential of color-aware strategies in developing more sophisticated image-based adversarial attacks.
There are some common problems and weaknesses associated with the methods for generating adversarial examples. One of the key challenges is the robustness of adversarial examples. The authors in reference [11] point out that a proactive deepfake defense based on these adversarial examples is vulnerable to image processing, such as JPEG compression and Gaussian blur. This is because the adversarial signals are weakened by the image processing, and their effects become weaker, which we will also prove in Section 4 with experimental results. Furthermore, unlike conventional methods that perturb each correlated channel in RGB color space, they propose Anti-Forgery that perturbs only uncorrelated a and b channels in Lab color space, which produces robust and naturally protected images. In the evaluation using the CelebA dataset and StarGAN, a 100% attack success rate is achieved for all methods (PGD, C&W attack, and Anti-Forgery) if the protected images with adversarial signals are inputted as they are. On the other hand, applying JPEG compression, the attack success rates of PGD and C&W attack are reduced to 83.5% and 81.2%, respectively, while Anti-Forgery maintains an attack success rate of 90.7%. Moreover, when Gaussian blur is applied, the attack success rate for PGD and C&W attack drops to 0.0%, and that for Anti-Forgery drops to 5.80%. Thus, it is necessary to develop a more robust proactive deepfake defense method that does not reduce the success rate of attacks even after defending against adversarial signals based on image processing such as Gaussian blur.
3. Methodology
As discussed in the previous section, existing proactive deepfake defense methods have the problem that preprocessing, such as Gaussian blur, significantly reduces the success rate of attacks. In this section, we explain two proposed methods for realizing a more robust proactive deepfake defense.
3.1. PGD-Trap
Figure 1a represents the processing flow of the PGD-Trap method. The PGD-Trap method receives the input image and the target model of the deepfake generator, and generates a trap image through three-stage process: intensity-based PGD generating the adversarial signal , frequency filtering with an inverse filter that generates trap signal , and addition of the original image and the trap signal.
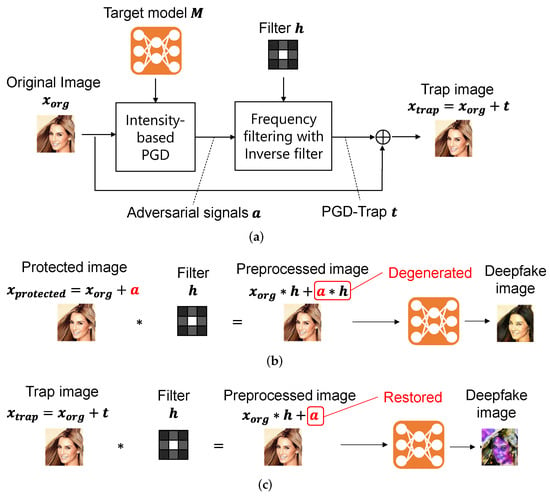
Figure 1.
Processing flow and effects of PGD-Trap. The example image is from CelebA dataset [21]. (a) Processing flow; (b) interference to a PGD-based adversarial example; (c) effect of PGD-Trap signal.
The intensity-based PGD, called PGD-Dark, is an extension of PGD. The PGD method generates an adversarial example by iteratively updating the input sample in the direction of the gradient of the loss function with Equation (2).
where corresponds to the original image, is the input sample of the t-th iteration, is a constant learning rate, is the trained parameter of the target model, is the teacher signal, and is the loss function. The value of each element in is in the range of −1 and 1. is an element-wise clipping function that clips each element to the range .
The PGD method adds adversarial signals based on a constant learning rate , regardless of the intensity of pixels. Due to the human eye’s insensitivity to image darkness, the actual change in a physical stimulus and the perceived change are different. In particular, in a bright and dark image, the human eye is typically more sensitive to the bright portions of the image as compared to the relatively dark portions of the image. Therefore, we propose an extended version of PGD, which is called PGD-Dark. For PGD-Dark, we add more adversarial signals to the relatively dark portions of the image and, conversely, reduce the addition of signals in the bright portions of the image in order to increase the efficiency of the adversarial signaling and improve the quality of the image. For this reason, we extend Equation (2) to Equation (3).
Here, is the tensor data of the same shape as and each element of represents the learning rate of the corresponding pixel. Specifically, a smaller learning rate is used for bright portions, while a larger learning rate is used for relatively dark portions of the image to enhance the intensity of the noise. The input image will be turned into a grayscale in the range of . In this paper, we determine with the following simple function:
In the experiments, we set and to and , respectively. The adversarial signal is calculated by , where T is the number of iterations of the PGD process. We employ the mean square error function of and as a loss function, where G is the target deepfake generator and represents the deepfake image for the original image.
In the process of frequency filtering with an inverse filter, we apply an inverse filter in the frequency domain as a countermeasure against the preprocessing to adversarial examples. Let h be the target filter. Figure 1b shows the problem of interference by preprocessing with linear filtering. In the existing methods, adversarial signal is directly added to the original image, and generates a protected image. Therefore, by applying the linear filtering with filter , the adversarial signal is generated to . Because must be a weak signal to keep the quality of the protected image sufficiently high, it becomes harder to interfere with the target deepfake generator. On the other hand, PGD-Trap adds the trap signal, which is the output of inverse filtering of adversarial signals to the original image.
The trap signal is generated as follows. First, we transform adversarial signal and a target linear filter with Fast Fourier Transform (FFT).
The inverse filter of is calculated by . This is a linear filter used to reverse the effects of a previous filtering process. For example, it aims to counteract the effects of the Gaussian blurring. We calculate a trap signal in the frequency domain by
where represents a small constant value. Optionally, instead of the inverse filter of Equation (7), we can also use the Wiener filter as follows:
In experiments, we employ the Wiener filter and set to . Then, we obtain a trap signal in the spatial domain by taking an inverse FFT (IFFT).
We added the trap signal to the original image and obtained a trap image.
As shown in Figure 1c, by applying the linear filtering with , the adversarial signal is restored from the trap signal . That effectively interferes with the target deepfake generator.
3.2. Adversarial Signal Injection with Iterative Latent Variable Refinement
Existing methods assume that the original image has been modified as little as possible by adversarial signals. However, in practice, images are often modified to enhance or change their appearance when uploaded to social media. Many social media users are expected to be less resistant to minor image alterations. Therefore, we propose a method that opens up new possibilities for proactive deepfake defense, which allows the original image to be modified within a reasonable range.
Our approach is an extension of Iterative Latent Variable Refinement (ILVR) [22] based on a Denoising Diffusion Probabilistic Model (DDPM) [8]. The DDPM consists of two key processes: a forward process and a reverse process, which together form the foundation of the model’s image generation capabilities.
Forward process: The forward process of DDPM is designed to gradually add Gaussian noise to an initial sample, transforming a clear image into pure noise over a series of steps. This process can be described as follows.
The DDPM generates samples through a Markov chain that progressively adds Gaussian noise to the initial sample , which is a training image. At each time step t, represents a small positive constant that controls the variance of the noise added to the latent variable. The generation of the noisy image can be expressed as:
where is a normal distribution and represents an identity matrix. Equation (11) describes the overall forward process as a product of conditional probabilities, while Equation (12) defines how each step adds noise to the previous state.
Reverse process: The reverse process of DDPM aims to reconstruct the original image by gradually denoising a pure noise sample. This process is crucial for image generation, and is described as follows.
Starting from , which represents pure Gaussian noise, the reverse process is defined by:
Equation (13) describes the overall reverse process as a product of conditional probabilities, similar to the forward process. Equation (14) defines how each step reconstructs the previous state from the current noisy state.
To implement this reverse process, a neural network based on U-net [26] is trained to predict the noise added to at each time step t. This prediction is then used to calculate :
where and . The next state is then sampled by:
where . By iterating this process, we obtain a synthesized image . The ILVR method [22] enables a synthesized image guided by a given reference image . In ILVR, we also generate samples by a Markov chain that gradually adds Gaussian noise to the reference image . At each time step t of the reverse process of DDPM, we combine the low-frequency component of and the high-frequency component of by
where extracts low-frequency component by combining down-sampling and up-sampling. is passed to the next iteration of reverse process instead of .
We propose ILVR-based adversarial signal injection (ILVR-A) as shown in Figure 2. It generates a synthesized image that is similar to an input image and degenerates the quality of a target GAN.
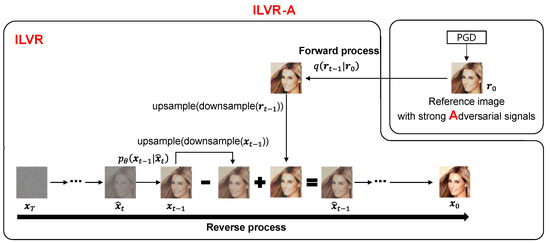
Figure 2.
Iterative latent variable refinement with reference image in which strong adversarial signals are injected. The example image is from CelebA dataset [21].
We use the same neural network architecture as [8], which is a U-Net based on Wide ResNet and the same as [22].
First, we generate the reference image by adding strong adversarial signals to an input image with the original PGD method of Equation (2). In the experiments, we set to 0.6 and the number of iterations to 10 to make the reference image; is 60 times larger than the normal PGD-based adversarial example generation. Then, we generate a synthesized image by ILVR-A with the reference image.
In ILVR-A, the operation of the reverse process is performed T times. The replacement operation of the low-frequency component is performed from step T to step 5, while only denoising will be performed in the last five steps to ensure the quality of the generated image .
We set T to 100 and the downscaling (upscaling) factor of Equation (17) to 8 in our experiments.
4. Experiments
In this section, we compare the specific performance of the proposed PGD-Trap method, including the quality of the generated examples, as well as the interference effect of the adversarial examples on the target model. PGD-Trap is a method that is designed to respond to image preprocessing methods. We chose the Gaussian blur filter as the target preprocessing, because making adversarial signals to the Gaussian blur is an important challenge, as shown in the experiments of reference [11]. We also evaluated our proposed ILVR-A method.
4.1. Dataset and Target Deepfake Generator
For this study, we used the CelebFaces Attributes (CelebA) dataset [21], which consists of over 200,000 celebrity images with 40 attribute labels. As for the experiments, we used 200 images from the CelebA dataset to test our proposed method. The images were resized to 256 × 256 pixels to fit the input requirements of the model. The dataset includes a diverse range of facial attributes and variations in pose, background, and lighting conditions. Each image was normalized to have pixel values in the range [0, 1].
The target deepfake generator used for our experiments was the Star Generative Adversarial Network (StarGAN) [5]. StarGAN is a versatile GAN architecture designed for multi-domain image-to-image translation, capable of performing multiple attribute transformations using a single model.
Generator architecture: The StarGAN generator network consists of the following layers:
- Input layer: accepts an input image of size 256 × 256 × 3 and a target domain vector.
- Downsampling: two-strided convolutional layers with 64 and 128 filters, respectively, each followed by instance normalization and ReLU activation.
- Bottleneck: six residual blocks, each containing two 3 × 3 convolutional layers with 256 filters, instance normalization, and ReLU activation.
- Upsampling: two transposed convolutional layers with 64 and 32 filters, respectively, each followed by instance normalization and ReLU activation.
- Output layer: a final convolutional layer with 3 filters and tanh activation to produce the transformed image.
Discriminator architecture: The StarGAN discriminator is based on the PatchGAN architecture, which classifies overlapping image patches as real or fake. Its structure is as follows:
- Input layer: accepts an image of size 256 × 256 × 3.
- Convolutional layers: Five convolutional layers with 64, 128, 256, 512, and 1 filters, respectively. Each layer (except the last) is followed by instance normalization and LeakyReLU activation with a slope of 0.01.
- Output: the final layer produces a 16 × 16 × 1 feature map, where each value represents the probability of the corresponding 70 × 70 input patch being real.
Training parameters:
- Optimizer: Adam optimizer with and .
- Learning rate: for both generator and discriminator, with a linear decay starting from the 100,000th iteration.
- Batch size: 16
- Total iterations: 200,000
Loss functions: StarGAN employs multiple loss functions to achieve its multi-domain translation capabilities:
- Adversarial loss: Wasserstein GAN loss with gradient penalty.
- Domain classification loss: auxiliary classifier for domain prediction.
- Reconstruction loss: L1 loss between the input and the reconstructed image.
This detailed architecture allows StarGAN to effectively learn the mapping between multiple domains, enabling it to perform various image transformations such as changing hair color, age, or facial expressions using a single model.
4.2. Evaluation Indices
error is a common metric for measuring the difference between two images and . It calculates the average of the squares of the differences between corresponding pixel values. Let and be vectors generated by flattening images.
where N represents the number of elements of and , and and represent the i-th element of and , respectively. We evaluated the effectiveness of interference by the error between the deepfake generator output for proactively defensed image and that for the original image. According to the conclusions drawn in the previous study on Anti-Forgery [11], adversarial signals are considered effective when the error exceeds . Therefore, we used Attack Success Rate () that counts results with an error above to evaluate the success rate of interference.
Peak signal-to-noise ratio () measures the quality of an image compared to a reference image, where is the maximum possible pixel value (e.g., 1.0 for our images).
where MSE represents the mean square error of an original image and an adversarial example. Even image degeneration that is imperceptible to the human eye can yield large differences in . As a complement, we used the structural similarity index () as a complementary illustration of the peak signal-to-noise ratio (). takes into account the local patterns of pixel intensities that have been normalized for brightness and contrast.
where and are the mean values, and are the variances, and represents the covariance of the images x and y. Constants and are used to stabilize the division. The higher values of indicate more similarity with a range from to 1.
4.3. Evaluation of PGD-Trap
In Table 1 and Table 2, we present and of Deepfool [27], PGD and PGD-Strong with two levels of adversarial signals, Anti-Forgery, and our proposed methods for different levels of the Gaussian blur. We also show their and with the original image without adversarial signals in Table 3 and Table 4. For the Winner filter of PGD-Trap, we employed Gaussian blur with a kernel size of and . We set to 0.004.

Table 1.
The performance of our method is tested by Gaussian blurring with the parameter in different cases. In this experiment, was set to 0.02 and 0.06 for PGD and PGD-Strong, respectively. PGD-Strong is a PGD method with a high epsilon of 0.06, and PGD-Dark is a PGD method that mainly adds attack signals into its relatively dark area of the image.
Table 2.
Comparison of PGD-Trap and Anti-Forgery.
Table 3.
Generated samples’ quality tested by and to the original image. The values in parentheses represent and to the synthesized image by ILVR-A. Peak signal-to-noise ratio () and the structural similarity index () represents the similarity between two images, the latter is closer to human visual.
Table 4.
Generated samples’ quality tested by and to the original image. We compare our method with Anti-Forgery. Anti-Forgery can achieve SOTA performance in adversarial attack. However, it fails to generate successful samples frequently.
Deepfool does not achieve 100% , even when . In our experiments, Anti-Forgery with the default settings provided on the official website tended to generate low-quality images with high probabilities. Especially, the probability for Anti-Forgery to generate a successful sample is only around . Table 2 and Table 4 (ideally) show the evaluation when we only focus on successful images. If we focus on the successful samples, it can achieve high quality with a value of . However, its average value, including low-quality images, is only .
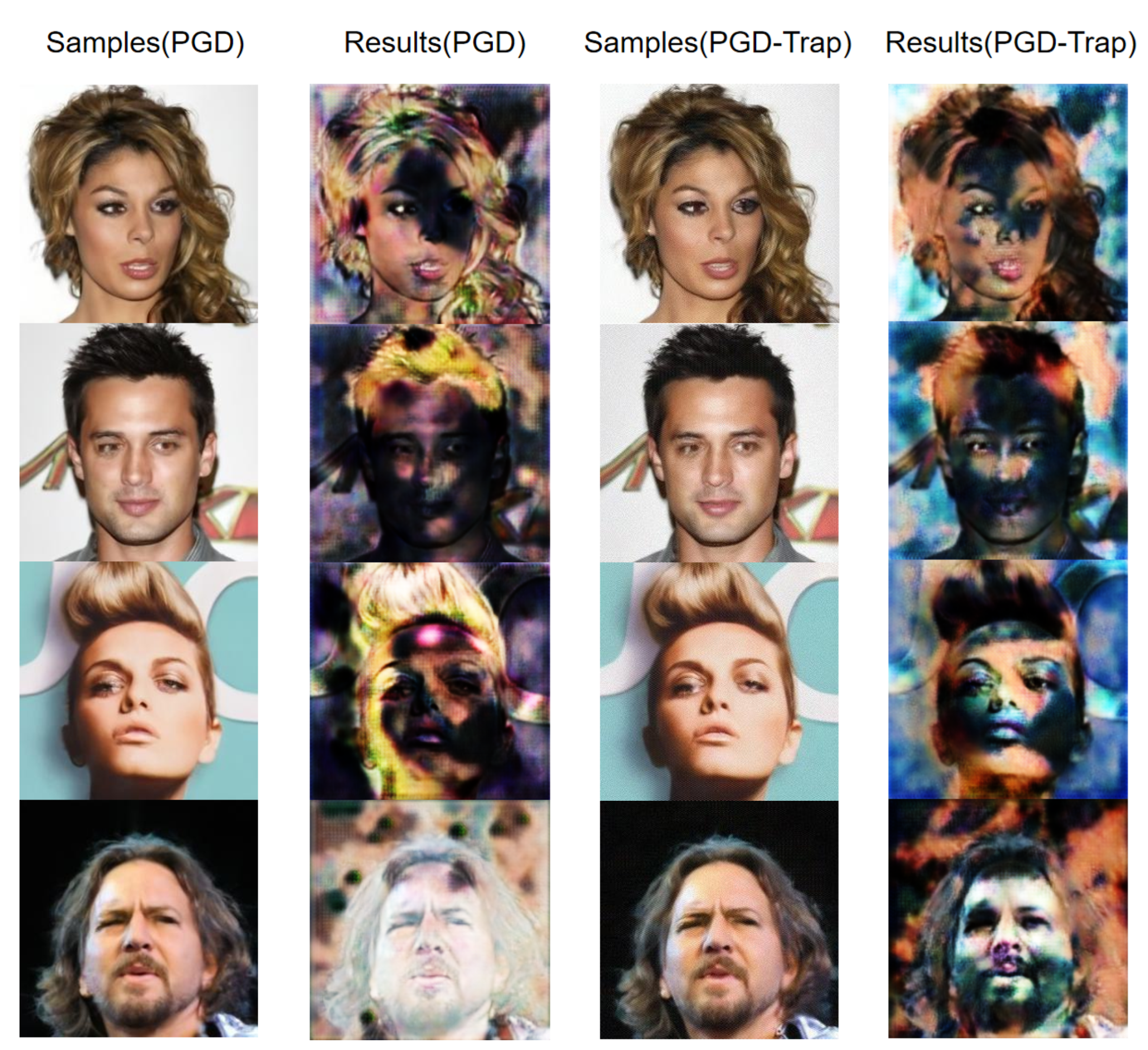
Although PGD-Strong shows better and than PGD, as increases, the effectiveness of adversarial examples generated by the PGD and PGD-Strong methods decreases sharply. Notably, at , the PGD method failed to produce valid adversarial examples. PGD-Dark represents our modified PGD method, in which noise of varying intensity is added to the image based on the brightness of its grayscale map. PGD-Dark realized more natural adversarial samples with higher and than PGD and PGD-Strong while achieving comparable or even better . Moreover, compared to the PGD and PGD-Strong, the adversarial signals generated by PGD-Trap showed significantly different characteristics. Our results indicated that PGD-Trap maintained good stability across different Gaussian blur parameters which was the standard deviation, with average values consistently above until a strong Gaussian blur filtering while achieving comparable with PGD-Strong. We show examples of StarGAN’s outputs for adversarial samples generated by PGD and PGD-Trap and preprocessed with Gaussian blur of different levels when we convert hair color to black in Figure 3. We can see that the adversarial samples generated by the PGD-Trap method exhibit effective interference. In addition, the effect of adversarial signals of the samples generated by the PGD method is sharply weakening with the enhancement of blurring. We also show the comparison of interference by PGD and PGD-Trap for four images in Figure 4 and Figure 5. We apply Gaussian blur with and as preprocessing in Figure 4 and Figure 5, respectively.

Figure 3.
Results of PGD-Trap and PGD under the influence of Gaussian blur. The input image is from CelebA dataset [21].

Figure 4.
Comparison of PGD and PGD-Trap when using Gaussian blur attacks with . The input images are from CelebA dataset [21].

Figure 5.
Comparison of PGD and PGD-Trap when using Gaussian blur attacks with . The input images are from CelebA dataset [21].
We then compared the results of PGD, PGD-Strong, and PGD-Dark with those obtained by adding adversarial signals using PGD-Dark to the images synthesized by ILVR-A. We confirmed that the combination of PGD-Dark and ILVR-A improved and compared to PGD-Dark. This may be due to the fact that the images synthesized by ILVR-A contained a small amount of signals that interfered with StarGAN’s process, or the synthesized image is more suitable for adversarial signal injection with PGD-Dark. Compared to PGD-Strong, and were slightly improved at . Although the image synthesized by ILVR-A looks similar to the original image in terms of subject, the value of each pixel is different. Therefore, and were reduced when the original image was considered as the correct image. On the other hand, the values in parentheses for PGD-Dark and ILVR-A in Table 3 represent the and for the image synthesized by ILVR-A. In particular, high values are maintained for , indicating that the quality of the images generated by ILVR-A is maintained after the application of PGD-Dark. These results show that although the improvement by ILVR-A is marginal, the reconstruction of the images could potentially provide higher quality images than PGD, PGD-Strong, and PGD-Dark with more robust preprocessing for embedding adversarial signals.
5. Discussion and Future Work
The introduction of the ILVR-A method in the experiments enhances the adversarial signals. However, at the same time it reduces the quality of the generated samples. There is still space for exploration of ILVR-A as a novel method to be used in conjunction with adversarial signals. In the future, for this DDPM-based method, increasing the strength of the adversarial signal while maintaining the quality of the samples is a direction worth exploring. In the following, we summarize the comparison and discussion of adversarial signals in detail.
5.1. Performance Comparison
Our experimental results demonstrate the effectiveness of PGD-Trap compared to existing methods. We compared our approach with the state-of-the-art Anti-Forgery method, which has shown impressive performance in adversarial attacks. However, our findings reveal some limitations of Anti-Forgery:
- Attack success rate: while Anti-Forgery can achieve high-quality results, its Attack Success Rate is only around 33%, indicating inconsistent performance.
- Image quality: despite its potential for high-quality outputs, Anti-Forgery’s average value is only 19.20, which is lower than expected for a state-of-the-art method.
In contrast, our PGD-Trap method demonstrates more consistent performance, with higher Attack Success Rates and competitive and values. This balance between attack effectiveness and image quality positions our method as a more reliable solution for deepfake defense.
5.2. Scalability and Limitations
While our method shows promise, there are several areas for improvement and further research:
- Balance of sample quality and adversarial strength: Currently, it remains challenging to optimally balance the quality of the generated samples with the strength of the adversarial signals. Further research is needed to fine-tune this trade-off.
- Image preprocessing resilience: Our current focus has been primarily on generating adversarial signals. However, more research is needed to address the impact of various image preprocessing techniques, such as image reconstruction and compression, which can significantly affect adversarial samples.
- Scalability: As we move towards more complex and larger-scale image generation tasks, the computational requirements of our method may increase. Future work should investigate optimizations to improve scalability while maintaining performance.
5.3. Discussion about Computational Efficiency
We analyze the computational efficiency of our proposed method, PGD-Trap, in comparison to the PGD method. In the PGD method, we need to calculate gradient for the target model. The forward propagation from the inputs to the outputs and the back propagation from the outputs to the inputs are required to calculate the gradients. Although the computational cost of forward and back propagation depends on the structure of the target model, it has many computationally heavy layers, such as convolutional layers. The computational complexity of a single convolution layer can be represented as , where and are the number of input and output channels, K is the filter size, is the image size. This cost is common to both PGD and PGD-Trap, as it represents the fundamental operation in convolutional neural networks. The primary distinction in our proposed method lies in the utilization of the FFT and its inverse transform. The computational complexity of FFT and IFFT for each channel is , where is the image size. We perform FFT and IFFT three times for a color image. Therefore, typically, the computational cost of FFT is much less than the computational cost for GAN models. It is important to note that while our method incurs this additional Fourier Transform cost, the overall impact on computational efficiency is relatively minor.
5.4. Future Directions
Several promising avenues for future research emerge from our findings:
- Advanced preprocessing defenses: developing more sophisticated adversarial methods that are robust against a wider range of image preprocessing techniques could significantly enhance the practicality of deepfake defenses.
- Exploration of new models: The potential of diffusion models in this domain is substantial. Future work could investigate more advanced adversarial attack strategies and defenses within these frameworks, potentially leading to more robust and efficient solutions.
- Adaptive attack strategies: developing methods that can dynamically adjust their attack strategy based on the target model and preprocessing techniques could lead to more versatile and effective adversarial examples.
- Ethical considerations: As these technologies advance, it is crucial to consider the ethical implications and potential misuse. Future research should also focus on developing responsible AI practices in the context of deepfake generation and defense.
The development and refinement of these models and methods will contribute to advancing the robustness and security of image generation and processing systems, thereby addressing critical challenges in the field of adversarial machine learning. By building upon the foundations laid by our PGD-Trap method and addressing its current limitations, we anticipate significant progress in creating more resilient and effective deepfake defense mechanisms.
6. Conclusions
In this study, we presented the PGD-Trap method, which effectively addresses image preprocessing challenges, particularly for Gaussian blurring operations. Our approach significantly enhances the robustness of adversarial signals against such preprocessing. Additionally, we integrated a modified ILVR method with an adversarial attack. This combined technique progressively interchanges the reference image with that of the generated image during the denoising process of the diffusion model, allowing the generated image to gradually approach the reference image. This represents a novel approach to generating adversarial examples by directly creating adversarial signals from the generative model.
Author Contributions
Conceptualization, Z.Z. and Y.T.; methodology, Z.Z., Y.T. and J.S.; software, Z.Z.; validation, Z.Z. and Y.T.; formal analysis, Z.Z., Y.T., J.S. and Y.O.; investigation, Z.Z. and Y.T.; resources, Y.T.; data curation, Y.T.; writing—original draft preparation, Z.Z. and Y.T.; writing—review and editing, Z.Z., Y.T., J.S. and Y.O.; visualization, Z.Z. and Y.T.; supervision, Y.T.; project administration, Y.T.; funding acquisition, Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Sumitomo Electric Industries Group CSR Foundation.
Data Availability Statement
CelebA dataset is accessible at https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (accessed on 27 June 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Liu, M.; Ding, Y.; Xia, M.; Liu, X.; Ding, E.; Zuo, W.; Wen, S. Stgan: A unified selective transfer network for arbitrary image attribute editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3673–3682. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8188–8197. [Google Scholar]
- Wang, P.; Liu, Z.; Wang, Z.; Zhao, Z.; Yang, D.; Yan, W. Graph generative adversarial networks with evolutionary algorithm. Appl. Soft Comput. 2024, 164, 111981. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Cao, H.; Tan, C.; Gao, Z.; Xu, Y.; Chen, G.; Heng, P.A.; Li, S.Z. A Survey on Generative Diffusion Models. IEEE Trans. Knowl. Data Eng. 2024, 36, 2814–2830. [Google Scholar] [CrossRef]
- Wang, R.; Huang, Z.; Chen, Z.; Liu, L.; Chen, J.; Wang, L. Anti-Forgery: Towards a Stealthy and Robust DeepFake Disruption Attack via Adversarial Perceptual-aware Perturbations. arXiv 2022, arXiv:2206.00477. [Google Scholar]
- Chen, M.; Fridrich, J.; Goljan, M.; Lukas, J. Determining Image Origin and Integrity Using Sensor Noise. IEEE Trans. Inf. Forensics Secur. 2008, 3, 74–90. [Google Scholar] [CrossRef]
- Koopman, M.; Rodriguez, A.M.; Geradts, Z. Detection of deepfake video manipulation. In Proceedings of the The 20th Irish Machine Vision and Image Processing Conference (IMVIP), Belfast, Ireland, 29–31 August 2018; pp. 133–136. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Hsu, C.C.; Zhuang, Y.X.; Lee, C.Y. Deep fake image detection based on pairwise learning. Appl. Sci. 2020, 10, 370. [Google Scholar] [CrossRef]
- Nirkin, Y.; Wolf, L.; Keller, Y.; Hassner, T. DeepFake detection based on discrepancies between faces and their context. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6111–6121. [Google Scholar] [CrossRef] [PubMed]
- Hu, S.; Li, Y.; Lyu, S. Exposing GAN-generated faces using inconsistent corneal specular highlights. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2500–2504. [Google Scholar]
- Lanzino, R.; Fontana, F.; Diko, A.; Marini, M.R.; Cinque, L. Faster Than Lies: Real-time Deepfake Detection using Binary Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle WA, USA, 17–21 June 2024; pp. 3771–3780. [Google Scholar]
- Agarwal, A.; Ratha, N. Deepfake Catcher: Can a Simple Fusion be Effective and Outperform Complex DNNs? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle WA, USA, 17–21 June 2024; pp. 3791–3801. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Choi, J.; Kim, S.; Jeong, Y.; Gwon, Y.; Yoon, S. Ilvr: Conditioning method for denoising diffusion probabilistic models. arXiv 2021, arXiv:2108.02938. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Kwon, H. Adversarial image perturbations with distortions weighted by color on deep neural networks. Multimed. Tools Appl. 2023, 82, 13779–13795. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).