
Research on Default Classification of Unbalanced Credit Data Based on PixelCNN-WGAN


Abstract
:1. Introduction
2. Relevant Theories
2.1. Generative Adversarial Networks (GAN)
2.2. Pixel Convolutional Neural Networks (PixelCNNs)
2.3. Convolutional Neural Network (CNN)
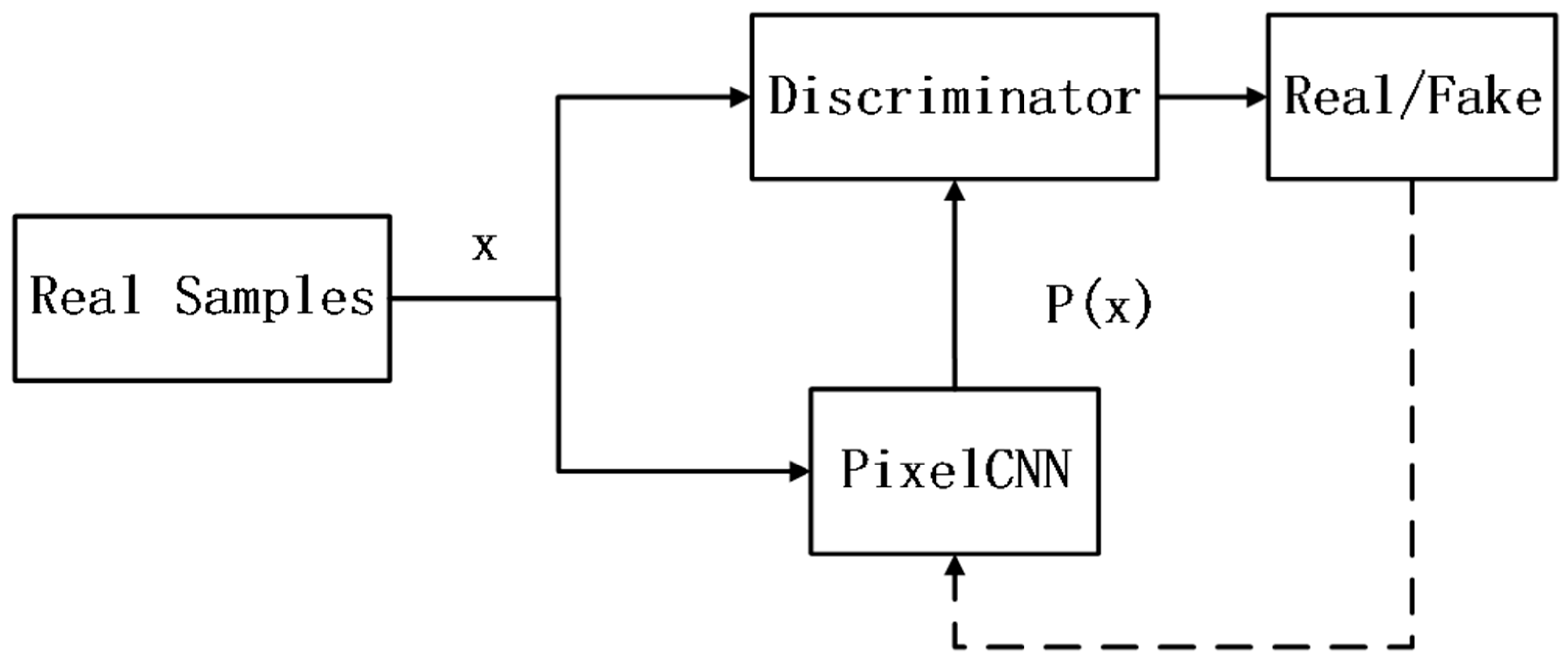
3. Credit Default Classification Process Based on PixelCNN-WGAN Algorithm
3.1. PixelCNN-WGAN Generative Model Construction
3.2. Generator and Discriminator Network Structure
3.3. Default Prediction Model Based on PixelCNN-WGAN Models
4. Experimental Results and Analysis
4.1. Experimental Environment and Hyperparameter Settings
4.2. Datasets and Data Preprocessing
4.3. Evaluation of the Quality of the Generated Images
4.4. Evaluation Indicators
4.5. Comparison of Data Enhancement Effectiveness
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dal Pozzolo, A.; Boracchi, G.; Caelen, O.; Alippi, C.; Bontempi, G. Credit card fraud detection: A realistic modeling and a novel learning strategy. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3784–3797. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Cao, W.; Gao, Z.; Bian, J.; Chen, H.; Chang, Y.; Liu, T.-Y. Self-paced ensemble for highly imbalanced massive data classification. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 841–852. [Google Scholar]
- Zhang, Q.; Zhu, Y.; Yang, M.; Jin, G.; Zhu, Y.; Chen, Q. Cross-to-merge training with class balance strategy for learning with noisy labels. Expert Syst. Appl. 2024, 249, 123846. [Google Scholar] [CrossRef]
- Zhang, Q.; Lee, F.; Wang, Y.-g.; Ding, D.; Yao, W.; Chen, L.; Chen, Q. An joint end-to-end framework for learning with noisy labels. Appl. Soft Comput. 2021, 108, 107426. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Inoue, H. Data augmentation by pairing samples for images classification. arXiv 2018, arXiv:1801.02929. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Ratliff, L.J.; Burden, S.A.; Sastry, S.S. Characterization and computation of local Nash equilibria in continuous games. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA,, 2–4 October 2013; pp. 917–924. [Google Scholar]
- Hu, W.; Tan, Y. Generating adversarial malware examples for black-box attacks based on GAN. In Proceedings of the International Conference on Data Mining and Big Data, Beijing, China, 21–24 November 2022; pp. 409–423. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Yang, Q.; Yan, P.; Zhang, Y.; Yu, H.; Shi, Y.; Mou, X.; Kalra, M.K.; Zhang, Y.; Sun, L.; Wang, G. Low-dose CT image denoising using a generative adversarial network with Wasserstein distance and perceptual loss. IEEE Trans. Med. Imaging 2018, 37, 1348–1357. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yang, Z.; Zhang, J.; Zhang, Q.; Chien, W.-T.K. AdaBalGAN: An improved generative adversarial network with imbalanced learning for wafer defective pattern recognition. IEEE Trans. Semicond. Manuf. 2019, 32, 310–319. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Zhang, X.; Yu, L.; Yin, H.; Lai, K.K. Integrating data augmentation and hybrid feature selection for small sample credit risk assessment with high dimensionality. Comput. Oper. Res. 2022, 146, 105937. [Google Scholar] [CrossRef]
- Cui, J.; Zhang, Y.; Men, J.; Wu, L. Utilizing Wasserstein Generative Adversarial Networks for Enhanced Hyperspectral Imaging: A Novel Approach to Predict Soluble Sugar Content in Cherry Tomatoes. LWT 2024, 206, 116585. [Google Scholar] [CrossRef]
- Zekrifa, D.M.S.; Lamani, D.; Chaitanya, G.K.; Kanimozhi, K.; Saraswat, A.; Sugumar, D.; Vetrithangam, D.; Koshariya, A.K.; Manjunath, M.S.; Rajaram, A. Advanced deep learning approach for enhancing crop disease detection in agriculture using hyperspectral imaging. J. Intell. Fuzzy Syst. 2024, 46, 3281–3294. [Google Scholar] [CrossRef]
- Fan, H.; Ma, J.; Zhang, X.; Xue, C.; Yan, Y.; Ma, N. Intelligent data expansion approach of vibration gray texture images of rolling bearing based on improved WGAN-GP. Adv. Mech. Eng. 2022, 14, 16878132221086132. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, L.; Zhong, M. An Improved WGAN-Based Fault Diagnosis of Rolling Bearings. In Proceedings of the 2022 IEEE International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Chongqing, China, 5–7 August 2022; pp. 322–327. [Google Scholar]
- Van Den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1747–1756. [Google Scholar]
- Liao, W.; Ge, L.; Bak-Jensen, B.; Pillai, J.R.; Yang, Z. Scenario prediction for power loads using a pixel convolutional neural network and an optimization strategy. Energy Rep. 2022, 8, 6659–6671. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. In Proceedings of the IEEE; IEEE: Seattle, WA, USA, 15 May 1998; pp. 2278–2324. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- LendingClub Home Page. Available online: https://www.lendingclub.com/info/download-data.action (accessed on 17 July 2023).
- Hosaka, T. Bankruptcy prediction using imaged financial ratios and convolutional neural networks. Expert Syst. Appl. 2019, 117, 287–299. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameterization |
|---|---|
| CNN | kernel_size:3,batch_size:128,pool_size:(2, 2) |
| AlexCNN | kernel_size:3,batch_size:64,dropout rate:0.5 |
| SqueezeNet | kernel_size:3,fire module:kernel_size:1,dropout rate:0.5 |
| MobileNetV2 | inverted_residual_blockmodule:kernel_size:3 |
| Model | FID Values | Time per Epoch/min |
|---|---|---|
| WGAN | 152.70 | 0.73 |
| PixelCNN-WGAN | 92.02 | 2.15 |
| Algorithm | Original Dataset | Pixel-WGAN Balanced Dataset | ||
|---|---|---|---|---|
| Accuracy | AUC | Accuracy | AUC | |
| CNN | 0.9392 | 0.6788 | 0.9749 | 0.9749 |
| AlexCNN | 0.9591 | 0.7873 | 0.9746 | 0.9746 |
| SqueezeNet | 0.9587 | 0.7874 | 0.9771 | 0.9771 |
| MobileNetV2 | 0.9559 | 0.7947 | 0.9734 | 0.9734 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Ji, Y.; Tao, X. Research on Default Classification of Unbalanced Credit Data Based on PixelCNN-WGAN. Electronics 2024, 13, 3419. https://doi.org/10.3390/electronics13173419
Sun Y, Ji Y, Tao X. Research on Default Classification of Unbalanced Credit Data Based on PixelCNN-WGAN. Electronics. 2024; 13(17):3419. https://doi.org/10.3390/electronics13173419
Chicago/Turabian StyleSun, Yutong, Yanting Ji, and Xiangxing Tao. 2024. "Research on Default Classification of Unbalanced Credit Data Based on PixelCNN-WGAN" Electronics 13, no. 17: 3419. https://doi.org/10.3390/electronics13173419