
A Scalable Multi-FPGA Platform for Hybrid Intelligent Optimization Algorithms


Abstract
1. Introduction
- A general hardware platform is proposed based on multi-FPGA for hybrid intelligent optimization algorithms.
- A general design flow is proposed based on multi-FPGA for hybrid intelligent optimization algorithms.
- A hardware design case study is presented for the hybrid algorithm of GA, PIO, and SA with comparative and analytical results.
- The potential of the hardware design case for implementation in industry is illustrated by applying the case to the FJSP problem.
2. Related Work
3. A General Hardware Platform and Hardware Design Flow Based on Multi-FPGA for Hybrid Intelligent Optimization Algorithms
3.1. General Hardware Platform Based on Multi-FPGA for Hybrid Intelligent Optimization Algorithm
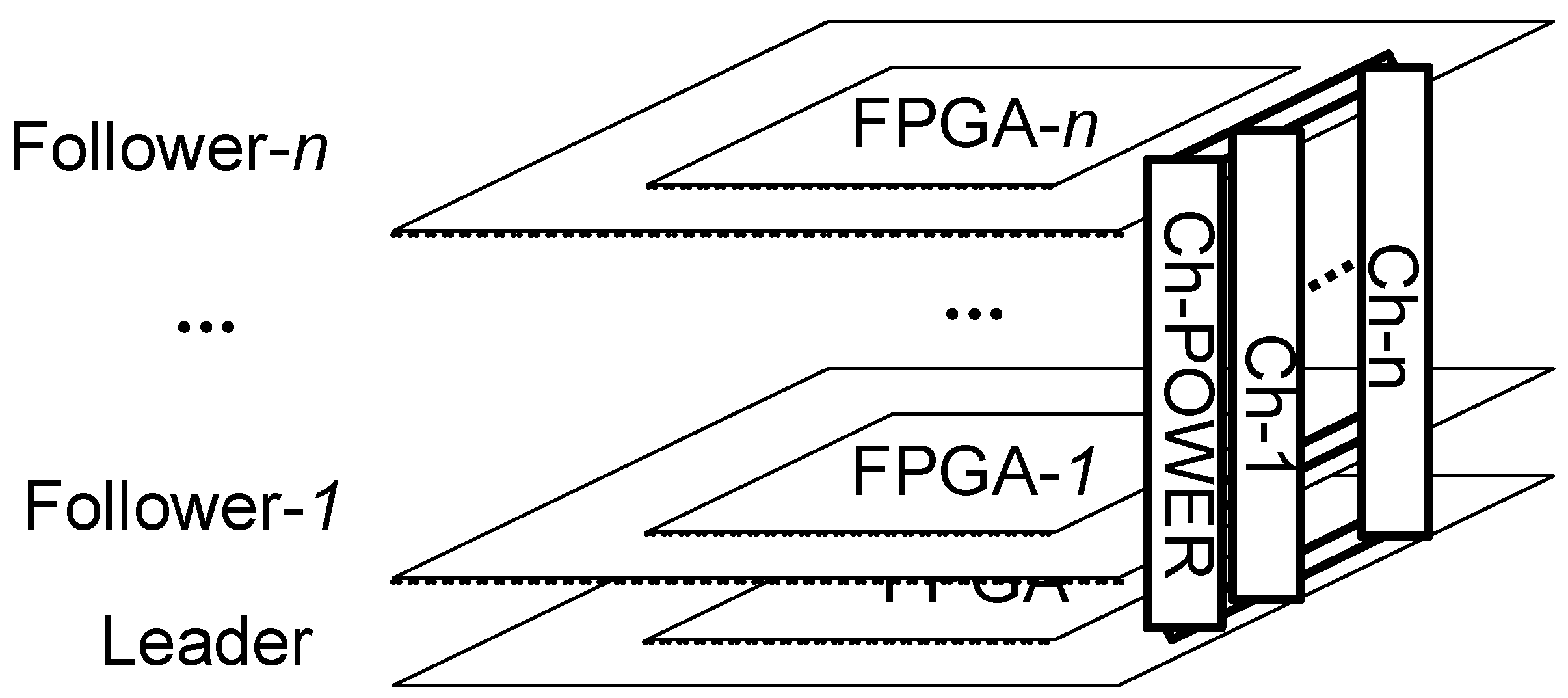
3.1.1. Hardware Architecture
3.1.2. Population Storage
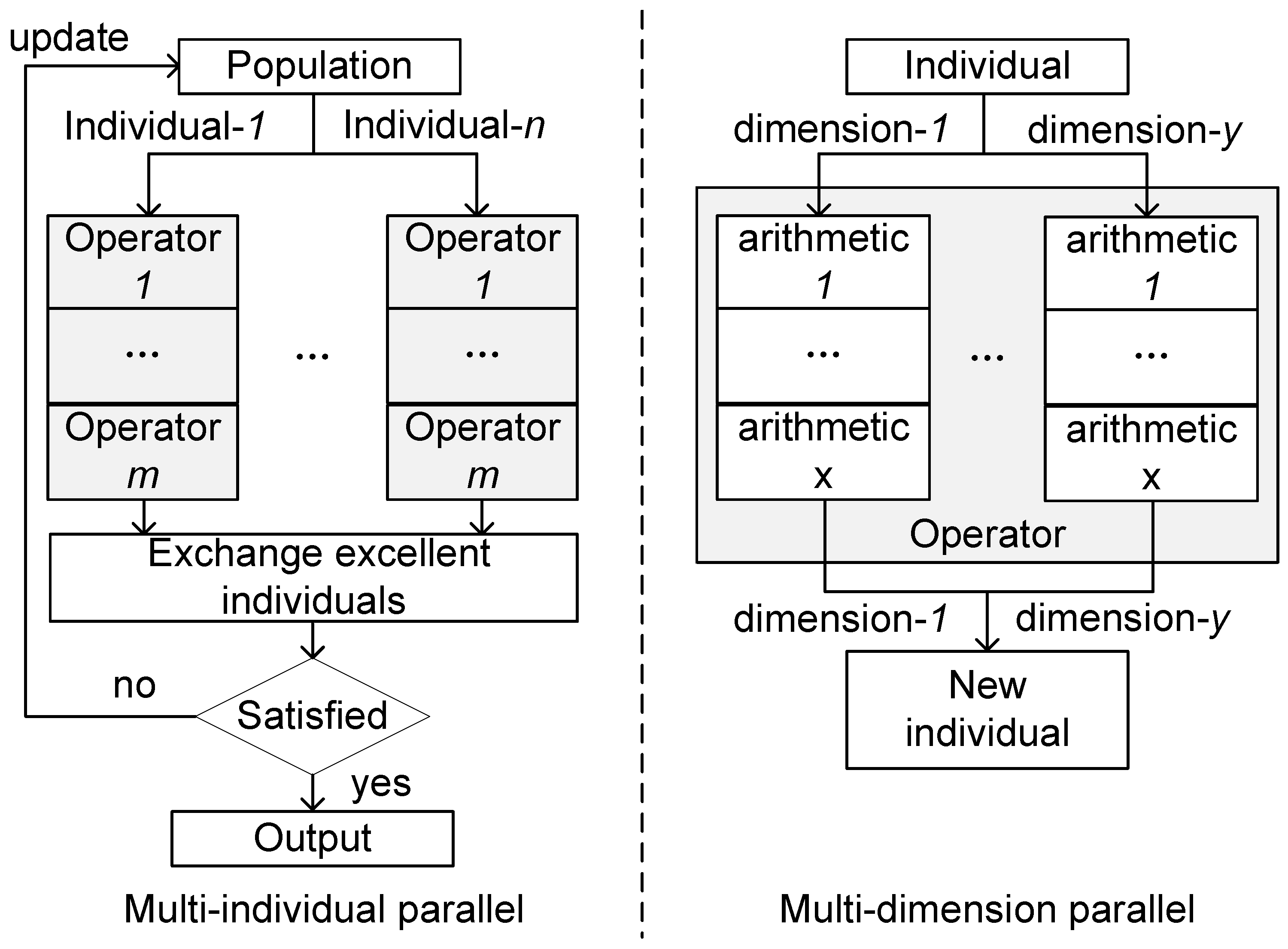
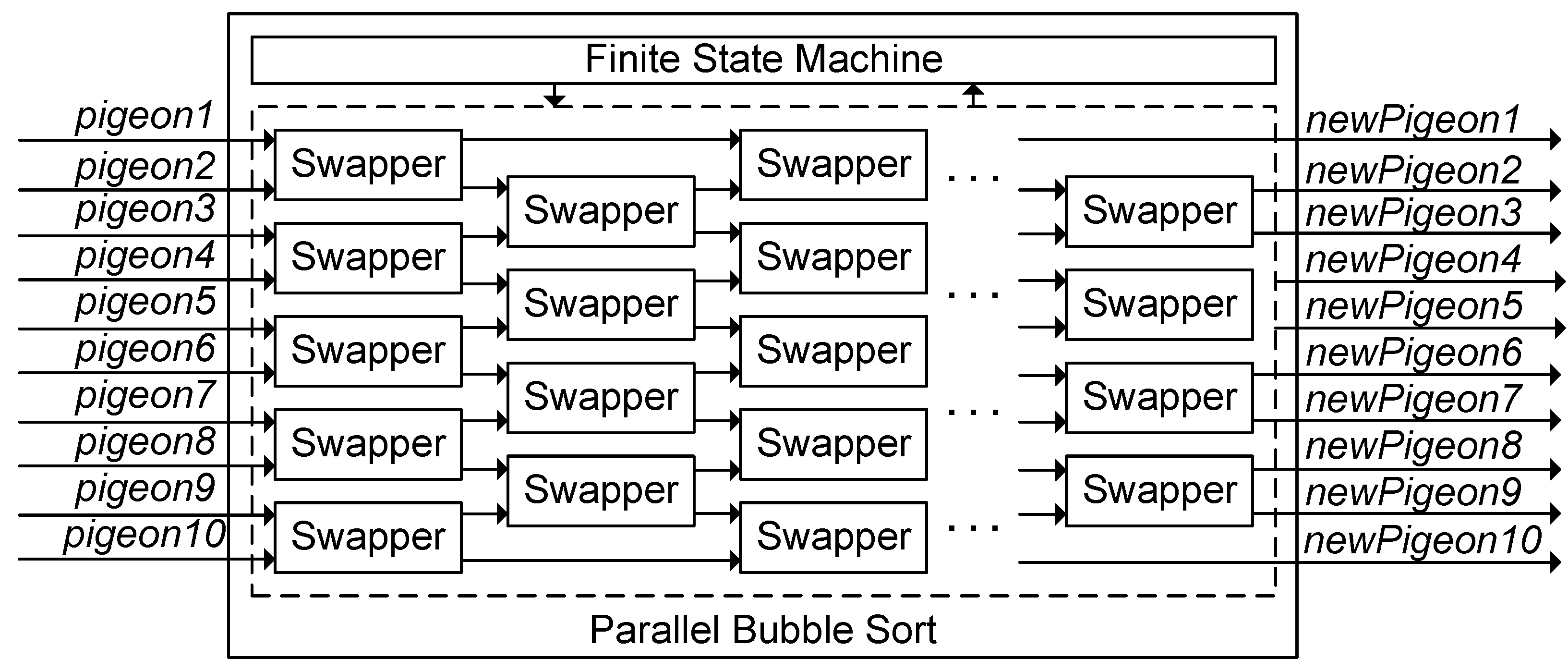
3.1.3. Parallel Processing
3.1.4. Inter-Board Communication
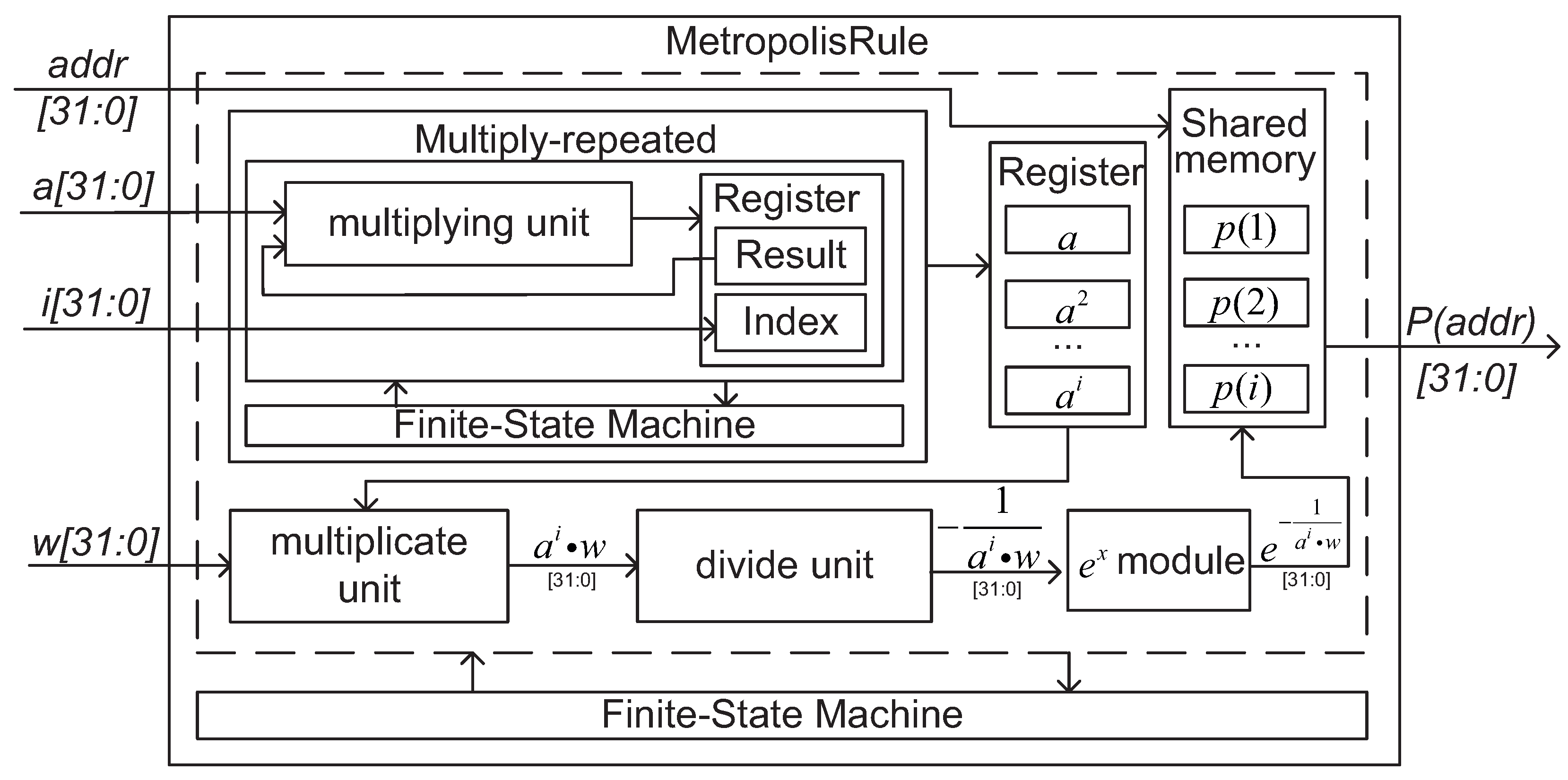
3.1.5. Complex Function Design
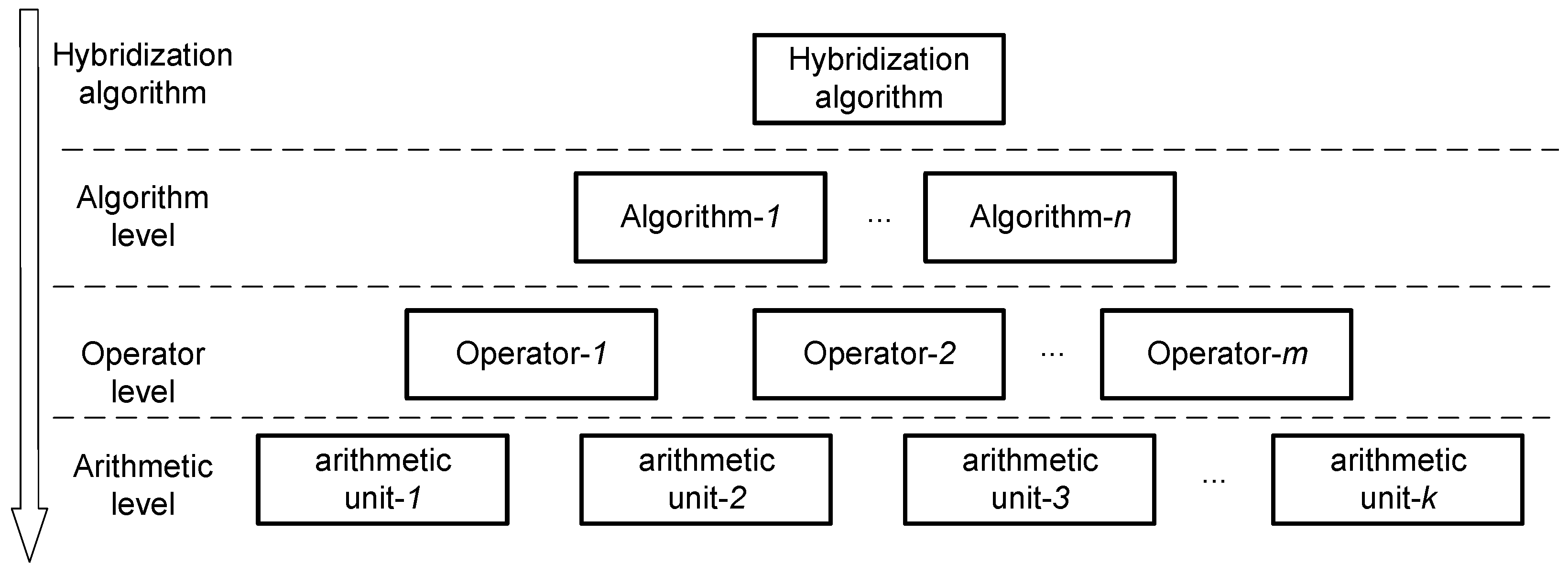
3.2. General Hardware Design Flow for Hybrid Intelligent Optimization Algorithm Based on Multi-FPGA
3.2.1. Designing Hybrid Algorithms
3.2.2. Decomposing Hybrid Algorithm
3.2.3. Selecting Implementation Methods
3.2.4. Designing Low-Layer Modules
3.2.5. Integrate Low-Layer Modules
3.2.6. Testing and Optimization
4. A Case Study of Hardware Design for a Hybrid Intelligent Optimization Algorithm Based on the Multi-FPGA Platform
4.1. Basic PIO
4.1.1. Map and Compass Operator
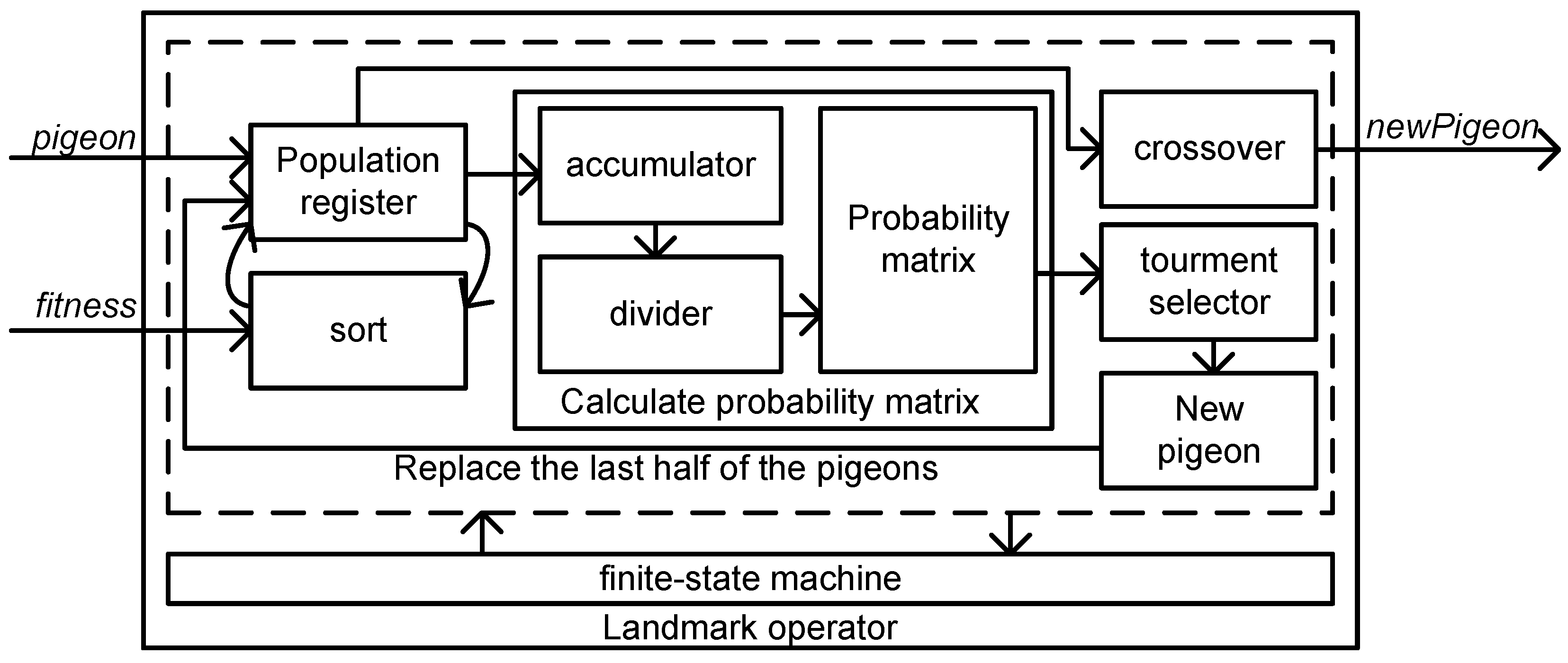
4.1.2. Landmark Operator
4.1.3. Mathematical Model
4.2. Hybrid Intelligent Optimization Algorithm for SA-PIO
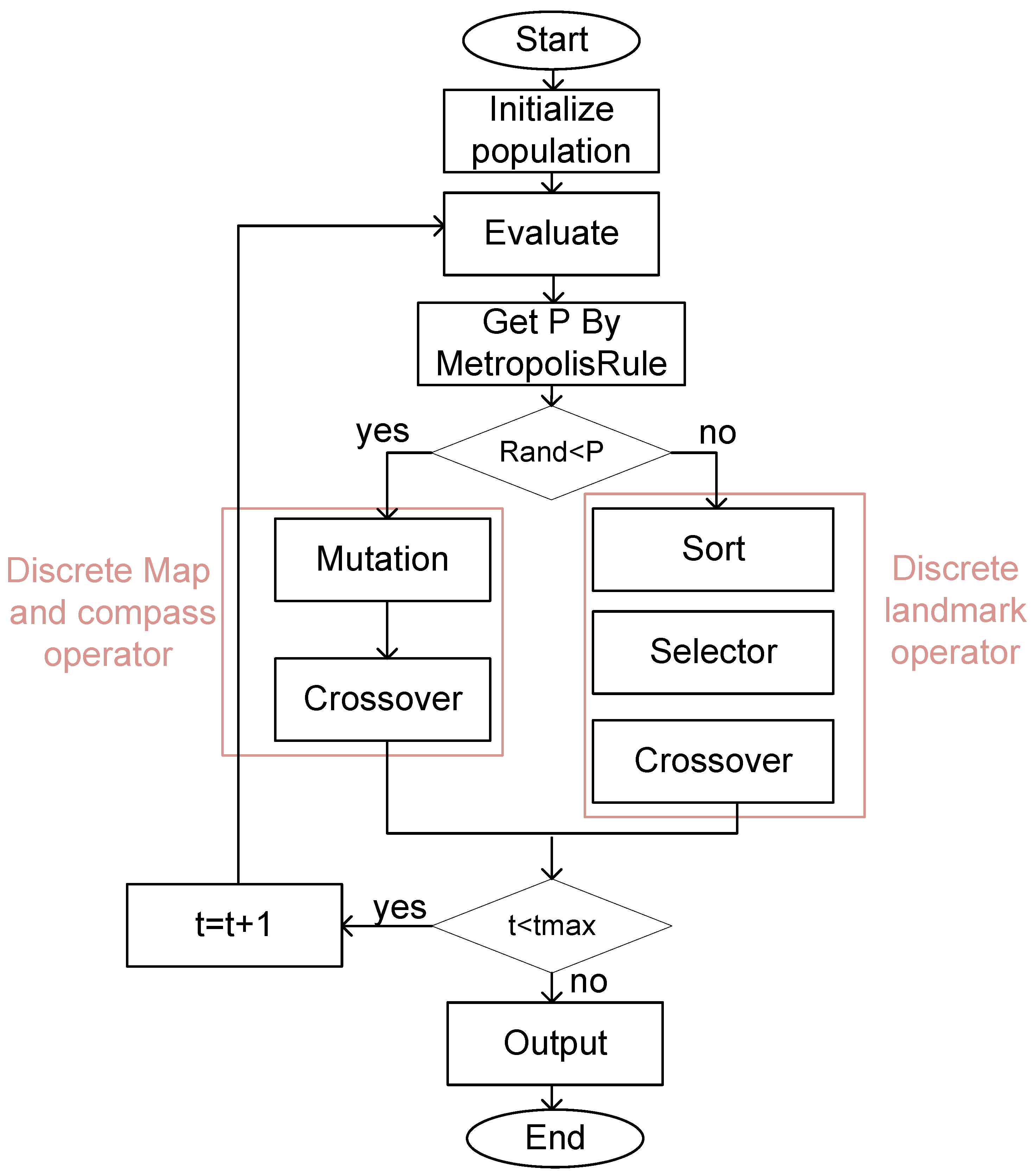
4.3. Hybrid Intelligent Optimization Algorithm for SA-GA-PIO
4.3.1. The Discrete Map and Compass Operator
4.3.2. The Discrete Landmark Operator
4.4. Case for Hardware Design of SA-GA-PIO Based on Multi-FPGA
4.5. Apply the Hardware Design to FJSP
4.5.1. Problem Formulation
4.5.2. Assumption
- The jobs are independent, and job preemption is not allowed. Additionally, each machine can process only one job at a time.
- Each job has a predefined operation precedence.
- All jobs and machines are available from the beginning.
- After a job is processed on a machine, the job is immediately delivered to the next machine. The delivery time is negligible.
- The setup time for an operation is independent of the operation sequence and is included in the processing time.
4.5.3. Mathematical Model
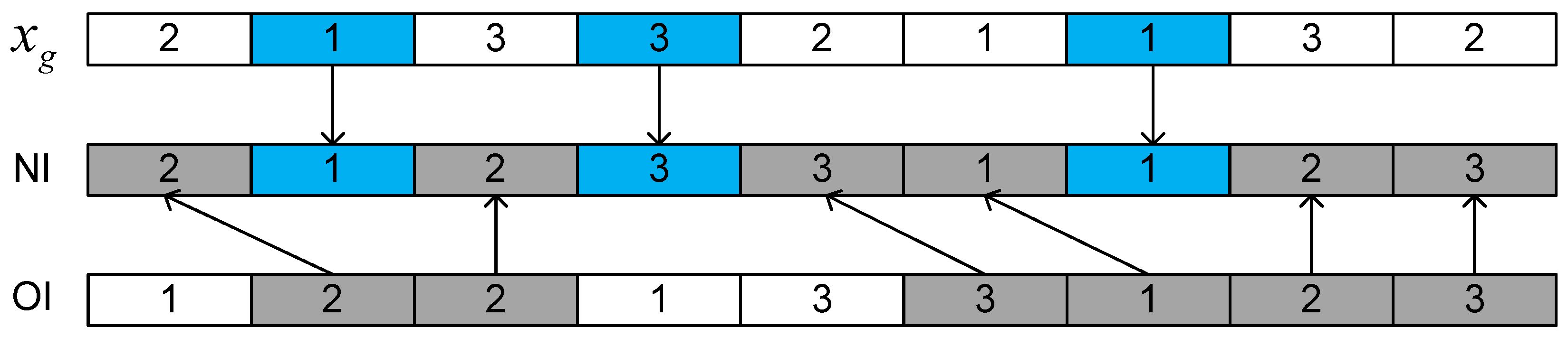
4.5.4. Encode
4.5.5. Decoding
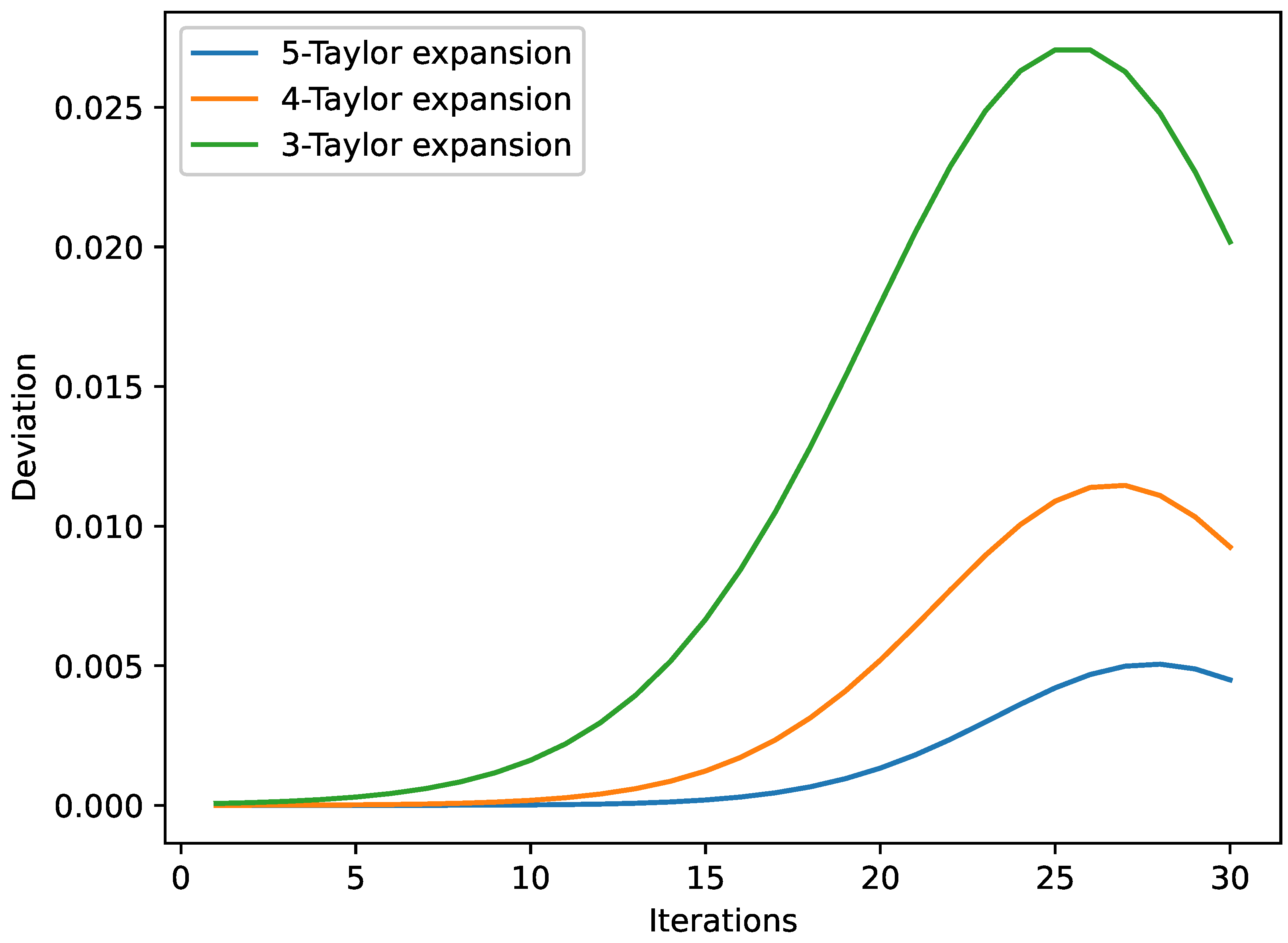
5. Results and Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Altay, E.V.; Alatas, B. Intelligent optimization algorithms for the problem of mining numerical association rules. Phys. A Stat. Mech. Its Appl. 2020, 540, 123142. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Prayogo, D. Symbiotic organisms search: A new metaheuristic optimization algorithm. Comput. Struct. 2014, 139, 98–112. [Google Scholar] [CrossRef]
- Bayraktar, Z.; Komurcu, M.; Werner, D. Wind Driven Optimization (WDO): A novel nature-inspired optimization algorithm and its application to electromagnetics. In Proceedings of the 2010 IEEE Antennas Propagation Society International Symposium, Toronto, ON, Canada, 11–17 July 2010; pp. 1–4. [Google Scholar]
- Zhang, X.; Wang, Y.; Cui, G.; Niu, Y.; Xu, J. Application of a novel IWO to the design of encoding sequences for DNA computing. Comput. Math. Appl. 2009, 57, 2001–2008. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef] [PubMed]
- Marini, F.; Walczak, B. Particle swarm optimization (PSO). A tutorial. Chemom. Intell. Lab. Syst. 2015, 149, 153–165. [Google Scholar] [CrossRef]
- Stützle, T.; Dorigo, M. ACO algorithms for the traveling salesman problem. Evol. Algorithms Eng. Comput. Sci. 1999, 4, 163–183. [Google Scholar]
- Rutenbar, R.A. Simulated annealing algorithms: An overview. IEEE Circuits Devices Mag. 1989, 5, 19–26. [Google Scholar] [CrossRef]
- Hao, R.; Luo, D.; Duan, H. Multiple UAVs mission assignment based on modified pigeon-inspired optimization algorithm. In Proceedings of the 2014 IEEE Chinese Guidance, Navigation and Control Conference, Yantai, China, 8–10 August 2014; pp. 2692–2697. [Google Scholar]
- Chen, S.; Duan, H. Fast image matching via multi-scale Gaussian mutation pigeon-inspired optimization for low cost quadrotor. Aircr. Eng. Aerosp. Technol. 2017, 89, 777–790. [Google Scholar] [CrossRef]
- Duan, H.; Qiu, H.; Fan, Y. Unmanned aerial vehicle close formation cooperative control based on predatory escaping pigeon-inspired optimization. Sci. Sin. Tech. 2015, 45, 559–572. [Google Scholar]
- Juang, C.F. A hybrid of genetic algorithm and particle swarm optimization for recurrent network design. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 997–1006. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, Y.; Liu, Z. A survey on convolutional neural network accelerators: GPU, FPGA and ASIC. In Proceedings of the 2022 14th International Conference on Computer Research and Development (ICCRD), Shenzhen, China, 7–9 January 2022; pp. 100–107. [Google Scholar]
- Nurvitadhi, E.; Sim, J.; Sheffield, D.; Mishra, A.; Krishnan, S.; Marr, D. Accelerating recurrent neural networks in analytics servers: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–4. [Google Scholar]
- Huang, H.C. FPGA-based parallel metaheuristic PSO algorithm and its application to global path planning for autonomous robot navigation. J. Intell. Robot. Syst. 2014, 76, 475–488. [Google Scholar] [CrossRef]
- Da Costa, A.L.; Silva, C.A.; Torquato, M.F.; Fernandes, M.A. Parallel implementation of particle swarm optimization on FPGA. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 1875–1879. [Google Scholar] [CrossRef]
- Scheuermann, B.; So, K.; Guntsch, M.; Middendorf, M.; Diessel, O.; ElGindy, H.; Schmeck, H. FPGA implementation of population-based ant colony optimization. Appl. Soft Comput. 2004, 4, 303–322. [Google Scholar] [CrossRef]
- Messai, A.; Mellit, A.; Guessoum, A.; Kalogirou, S.A. Maximum power point tracking using a GA optimized fuzzy logic controller and its FPGA implementation. Sol. Energy 2011, 85, 265–277. [Google Scholar] [CrossRef]
- Allaire, F.C.; Tarbouchi, M.; Labonté, G.; Fusina, G. FPGA implementation of genetic algorithm for UAV real-time path planning. In Proceedings of the Unmanned Aircraft Systems: International Symposium on Unmanned Aerial Vehicles, UAV’08, Reno, NV, USA, 8–10 June 2009; pp. 495–510. [Google Scholar]
- Huang, H.C. FPGA-based hybrid GA-PSO algorithm and its application to global path planning for mobile robots. Prz. Elektrotechniczny 2012, 88, 281–284. [Google Scholar]
- Huang, H.C. A Taguchi-based heterogeneous parallel metaheuristic ACO-PSO and its FPGA realization to optimal polar-space locomotion control of four-wheeled redundant mobile robots. IEEE Trans. Ind. Inform. 2015, 11, 915–922. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Shi, Y. Brain storm optimization algorithm. In Proceedings of the Advances in Swarm Intelligence: Second International Conference, ICSI 2011, Chongqing, China, 12–15 June 2011; pp. 303–309. [Google Scholar]
- Yang, X.S.; He, X. Firefly algorithm: Recent advances and applications. Int. J. Swarm Intell. 2013, 1, 36–50. [Google Scholar] [CrossRef]
- Jiang, Q.; Guo, Y.; Yang, Z.; Zhou, X. A parallel whale optimization algorithm and its implementation on FPGA. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Hassanein, A.; El-Abd, M.; Damaj, I.; Rehman, H.U. Parallel hardware implementation of the brain storm optimization algorithm using FPGAs. Microprocess. Microsyst. 2020, 74, 103005. [Google Scholar] [CrossRef]
- Sadeeq, H.; Abdulazeez, A.M. Hardware implementation of firefly optimization algorithm using FPGAs. In Proceedings of the 2018 International Conference on Advanced Science and Engineering (ICOASE), Duhok, Iraq, 9–11 October 2018; pp. 30–35. [Google Scholar]
- Biookaghazadeh, S.; Ravi, P.K.; Zhao, M. Toward multi-fpga acceleration of the neural networks. ACM J. Emerg. Technol. Comput. Syst. JETC 2021, 17, 1–23. [Google Scholar] [CrossRef]
- Sun, Y.; Amano, H. Fic-rnn: A multi-fpga acceleration framework for deep recurrent neural networks. IEICE Trans. Inf. Syst. 2020, 103, 2457–2462. [Google Scholar] [CrossRef]
- Goel, S. Pigeon optimization algorithm: A novel approach for solving optimization problems. In Proceedings of the 2014 International Conference on Data Mining and Intelligent Computing (ICDMIC), New Delhi, India, 5–6 September 2014; pp. 1–5. [Google Scholar]
- Brandimarte, P. Routing and scheduling in a flexible job shop by tabu search. Ann. Oper. Res. 1993, 41, 157–183. [Google Scholar] [CrossRef]
- Wu, X.; Wu, S. An elitist quantum-inspired evolutionary algorithm for the flexible job-shop scheduling problem. J. Intell. Manuf. 2017, 28, 1441–1457. [Google Scholar] [CrossRef]
- Fattahi, P.; Saidi Mehrabad, M.; Jolai, F. Mathematical modeling and heuristic approaches to flexible job shop scheduling problems. J. Intell. Manuf. 2007, 18, 331–342. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Storage Mode | Memory Capacity | Access Speed | Flexibility |
|---|---|---|---|
| External memory | Enormous | Rapid | Enormous |
| BRAM | Large | Fast | Large |
| DRAM | Moderate | Slow | Moderate |
| Register | Small | Gradual | Small |
| Variables | Descriptions |
|---|---|
| n | Number of jobs |
| m | Number of machines |
| Number of the operations for job j | |
| Index for jobs, | |
| Index for operations, | |
| k | Index for machines, |
| i-th operation of job j | |
| Operation is processed on machine k | |
| Processing time of operation on machine k | |
| Makespan, the completing time for a scheduling solution | |
| Ending time of operation | |
| if the operation is processed on machine k; otherwise | |
| if operation is the precedence of operation | |
| if operation is the precedence of operation ; | |
| otherwise | |
| Set of available machines for operation |
| Module | Used Logic (LUT-6) | Registers | Clock Cycles to Output | Time to Output (in ns) | Time to Output in Software (in ns) |
|---|---|---|---|---|---|
| MR | 4105 | 5463 | 293 | 2930 | 3399 |
| 1450 | 1706 | 242 | 2420 | 599 | |
| Evaluation | 168 | 118 | 32 | 320 | 7700 |
| Compass | 2668 | 3225 | 248 | 2480 | 10,299 |
| Sort | 1525 | 1706 | 52 | 520 | 4710 |
| Landmark | 2889 | 3345 | 199 | 1990 | 45,500 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhao, C.; Zhao, L. A Scalable Multi-FPGA Platform for Hybrid Intelligent Optimization Algorithms. Electronics 2024, 13, 3504. https://doi.org/10.3390/electronics13173504
Zhao Y, Zhao C, Zhao L. A Scalable Multi-FPGA Platform for Hybrid Intelligent Optimization Algorithms. Electronics. 2024; 13(17):3504. https://doi.org/10.3390/electronics13173504
Chicago/Turabian StyleZhao, Yu, Chun Zhao, and Liangtian Zhao. 2024. "A Scalable Multi-FPGA Platform for Hybrid Intelligent Optimization Algorithms" Electronics 13, no. 17: 3504. https://doi.org/10.3390/electronics13173504
APA StyleZhao, Y., Zhao, C., & Zhao, L. (2024). A Scalable Multi-FPGA Platform for Hybrid Intelligent Optimization Algorithms. Electronics, 13(17), 3504. https://doi.org/10.3390/electronics13173504