Geometry-Aware Weight Perturbation for Adversarial Training


Abstract
1. Introduction
- We identify that the geometry-aware adversarial training method GAIRAT converges to a sharp local minimum. By incorporating GAIRAT with AWP, we can obtain a flatter optimization result that is shown to be robust against unseen attacks. It provides a better understanding of the robustness generalization issue of GAIRAT.
- We claim that the model weight perturbation of the data that are close to the decision boundary and have a low adversarial risk is essential for achieving higher model robustness and avoiding robust overfitting.
- A novel weight perturbation strategy, GAWP, is developed in this paper. Extensive experiments demonstrate that GAWP outperforms not only GAIRAT, but also existing weight perturbation strategies, achieving superior model robustness.

2. Related Work
2.1. Adversarial Attacks
2.2. Adversarial Training
2.3. Adversarial Purification
3. Methodology
3.1. Preliminaries
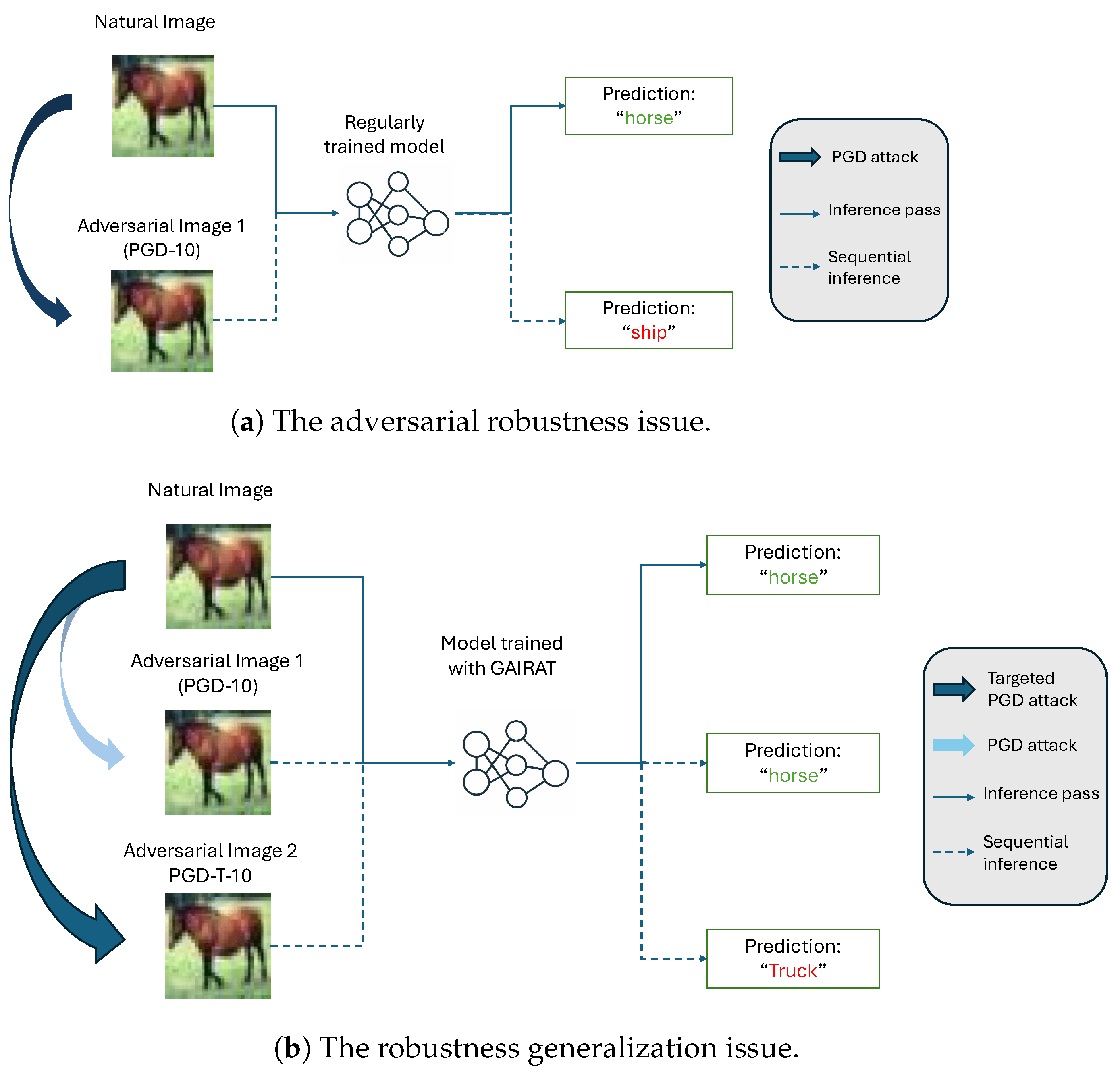
3.2. Understanding the Robustness Generalization Issue of GAIRAT
3.3. Geometry-Aware Weight Perturbation
| Algorithm 1 Geometry-Aware Weight Perturbation (GAWP) |
| Input: DNN , training dataset , batch size m, learning rate , PGD step size , PGD steps , PGD constraint , GAWP stepes , GAWP constraint , parameter . Outout: Adversarially robust model . Repeat Sample a mini-batch with a size m from training set . Generate one batch of adversarial examples based on Equation (2) for steps. for do Compute based on Equation (12). end for Initialize for do end for Until training converges |
4. Experimental Results
4.1. Experimental Setup
4.2. Robustness Evaluation
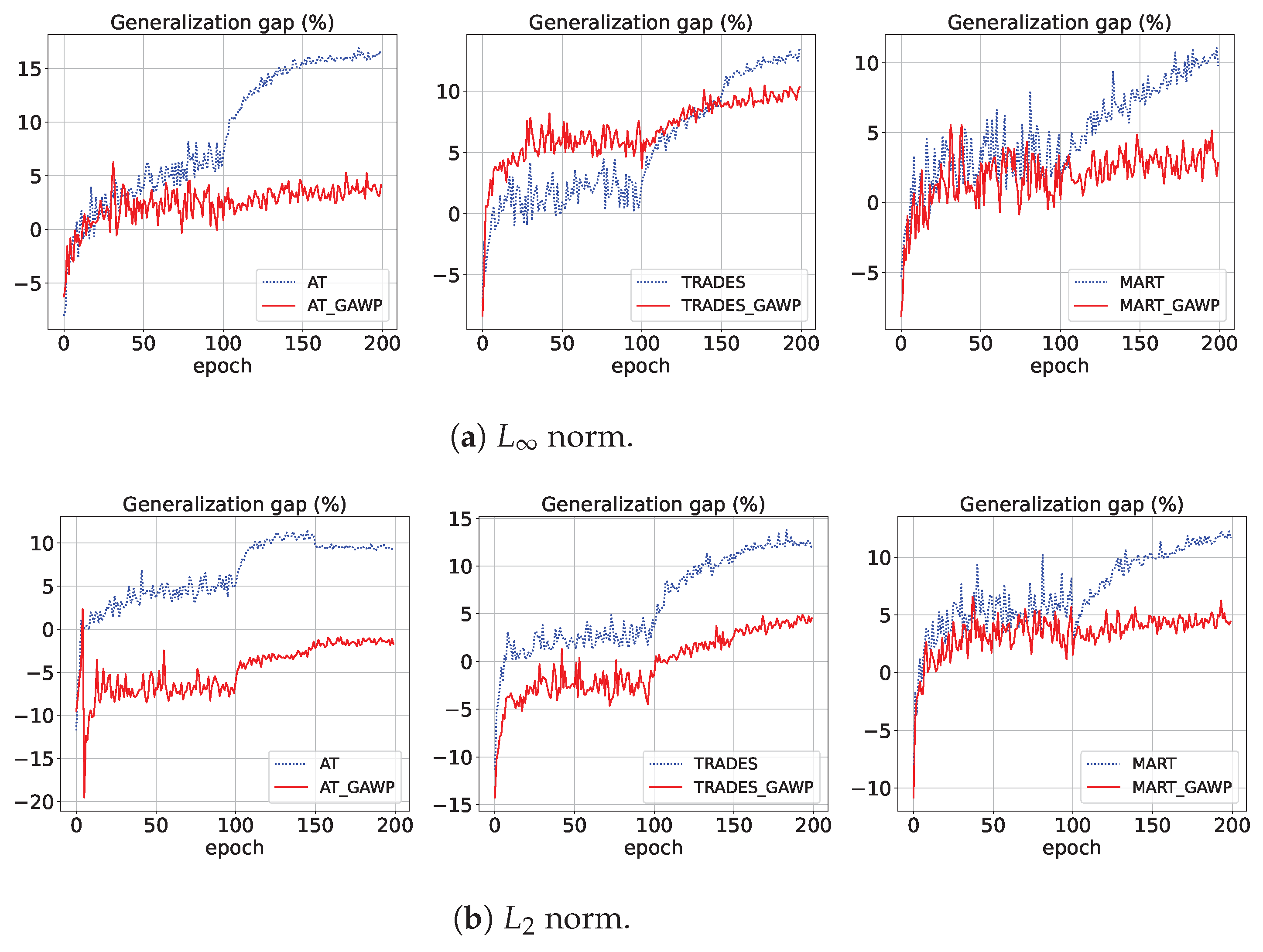
4.2.1. Mitigating Robustness Generalization and Overfitting Issues
4.2.2. Imposing Geometric Distance Benefits Weight Perturbation
4.3. Ablation Studies
4.3.1. Effect of Different Ways to Determine Importance Scores
4.3.2. Hyper-Parameter Sensitivity
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bai, T.; Luo, J.; Zhao, J.; Wen, B.; Wang, Q. Recent Advances in Adversarial Training for Adversarial Robustness. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–26 August 2021; pp. 4312–4321. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, J.; Zhu, J.; Niu, G.; Han, B.; Sugiyama, M.; Kankanhalli, M.S. Geometry-aware Instance-reweighted Adversarial Training. arXiv 2020, arXiv:2010.01736. [Google Scholar] [CrossRef]
- Hitaj, D.; Pagnotta, G.; Masi, I.; Mancini, L.V. Evaluating the Robustness of Geometry-Aware Instance-Reweighted Adversarial Training. arXiv 2021, arXiv:2103.01914. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, Y.; Jiao, J.; Xing, E.; El Ghaoui, L.; Jordan, M. Theoretically Principled Trade-off between Robustness and Accuracy. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7472–7482. [Google Scholar]
- Wang, Y.; Zou, D.; Yi, J.; Bailey, J.; Ma, X.; Gu, Q. Improving Adversarial Robustness Requires Revisiting Misclassified Examples. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wu, D.; Xia, S.T.; Wang, Y. Adversarial Weight Perturbation Helps Robust Generalization. Adv. Neural Inf. Process. Syst. 2020, 33, 2958–2969. [Google Scholar]
- Li, H.; Xu, Z.; Taylor, G.; Studer, C.; Goldstein, T. Visualizing the Loss Landscape of Neural Nets. Adv. Neural Inf. Process. Syst. 2018, 6389–6399. [Google Scholar]
- Neyshabur, B.; Bhojanapalli, S.; McAllester, D.; Srebro, N. Exploring Generalization in Deep Learning. Adv. Neural Inf. Process. Syst. 2017, 30, 5947–5956. [Google Scholar]
- Rice, L.; Wong, E.; Kolter, J.Z. Overfitting in adversarially robust deep learning. In Proceedings of the International Conference on Machine Learning, Virtual, 12–18 July 2020; pp. 8093–8104. [Google Scholar]
- Yu, C.; Han, B.; Gong, M.; Shen, L.; Ge, S.; Bo, D.; Liu, T. Robust Weight Perturbation for Adversarial Training. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 3659–3665. [Google Scholar]
- Yu, C.; Han, B.; Shen, L.; Yu, J.; Gong, C.; Gong, M.; Liu, T. Understanding Robust Overfitting of Adversarial Training and Beyond. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report 0; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, Virtual, 12–18 July 2020; pp. 2206–2216. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Meng, D.; Chen, H. MagNet: A Two-Pronged Defense against Adversarial Examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 135–147. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-GAN: Protecting Classifiers against Adversarial Attacks Using Generative Models. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Nie, W.; Guo, B.; Huang, Y.; Xiao, C.; Vahdat, A.; Anandkumar, A. Diffusion Models for Adversarial Purification. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 16805–16827. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. Adv. Neural Inf. Process. Syst. 2017, 30, 5767–5777. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the Advances in Neural Information Processing Systems, virtual, 6–12 December 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Carmon, Y.; Raghunathan, A.; Schmidt, L.; Duchi, J.C.; Liang, P.S. Unlabeled Data Improves Adversarial Robustness. Adv. Neural Inf. Process. Syst. 2019, 32, 11190–11201. [Google Scholar]
- Dong, Y.; Xu, K.; Yang, X.; Pang, T.; Deng, Z.; Su, H.; Zhu, J. Exploring Memorization in Adversarial Training. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Chen, T.; Zhang, Z.; Wang, P.; Balachandra, S.; Ma, H.; Wang, Z.; Wang, Z. Sparsity Winning Twice: Better Robust Generalization from More Efficient Training. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Chen, T.; Zhang, Z.; Liu, S.; Chang, S.; Wang, Z. Robust Overfitting may be mitigated by properly learned smoothening. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Lin, L.; Spratling, M. Understanding and combating robust overfitting via input loss landscape analysis and regularization. Pattern Recognit. 2023, 136, 109229. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Zhao, Z.; Dua, D.; Singh, S. Generating Natural Adversarial Examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-Aware Neural Language Models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2741–2749. [Google Scholar]
- Wang, Y.; Gao, J.; Cheng, G.; Jiang, T.; Li, J. Textual Adversarial Training of Machine Learning Model for Resistance to Adversarial Examples. Secur. Commun. Netw. 2022, 2022, 4511510. [Google Scholar]
- Li, L.; Qiu, X. TextAT: Adversarial Training for Natural Language Understanding with Token-Level Perturbation. arXiv 2020, arXiv:2004.14543. [Google Scholar]
- Raina, V.; Gales, M.J.F.; Knill, K. Universal Adversarial Attacks on Spoken Language Assessment Systems. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 3855–3859. [Google Scholar]
- Wu, H.; Liu, S.; Meng, H.M.; Lee, H.y. Defense Against Adversarial Attacks on Spoofing Countermeasures of ASV. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–9 May 2020; pp. 6564–6568. [Google Scholar]
- Li, R.; Jiang, J.Y.; Wu, X.; Hsieh, C.C.; Stolcke, A. Speaker Identification for Household Scenarios with Self-attention and Adversarial Training. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Li, X.; Li, N.; Zhong, J.; Wu, X.; Liu, X.; Su, D.; Yu, D.; Meng, H. Investigating Robustness of Adversarial Samples Detection for Automatic Speaker Verification. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 981–985. [Google Scholar]
- Lv, X.L.; Chiang, H.D. Visual clustering network-based intelligent power lines inspection system. Eng. Appl. Artif. Intell. 2024, 129, 107572. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Zhu, L. A survey of intelligent transmission line inspection based on unmanned aerial vehicle. Sci. Rep. 2022, 12, 6617. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | |
|---|---|
| AT | |
| TRADES | |
| MART |
| Method | Natural | AA | PGD-10 | ||
|---|---|---|---|---|---|
| Best | Last | Diff | |||
| GAIRAT | 79.24 | 29.99 | 63.28 | 59.47 | 3.81 |
| AT-AWP | 83.54 | 50.16 | 55.65 | 54.91 | 0.74 |
| AT-GAWP_baseline | 82.80 | 50.17 | 55.27 | 53.97 | 1.30 |
| Threat Model | Method | Natural | AA | PGD-10 | ||
|---|---|---|---|---|---|---|
| Best | Last | Diff | ||||
| AT | 83.73 | 47.00 | 51.26 | 43.57 | 7.69 | |
| GAIRAT | 79.24 | 29.99 | 63.28 | 59.47 | 3.81 | |
| AT-GAWP | 81.07 | 50.01 | 55.77 | 54.93 | 0.84 | |
| TRADES | 82.86 | 49.37 | 53.82 | 51.32 | 2.50 | |
| TRADES-GAWP | 81.31 | 50.61 | 55.20 | 54.56 | 0.64 | |
| MART | 77.06 | 47.47 | 54.08 | 50.41 | 3.67 | |
| MART-GAWP | 78.04 | 49.15 | 56.21 | 55.81 | 0.40 | |
| AT | 88.57 | 67.20 | 71.01 | 68.78 | 2.23 | |
| GAIRAT | 84.34 | 53.36 | 72.56 | 69.55 | 3.01 | |
| AT-GAWP | 89.26 | 70.06 | 74.61 | 74.17 | 0.44 | |
| TRADES | 86.47 | 68.06 | 71.64 | 69.70 | 1.94 | |
| TRADES-GAWP | 87.93 | 71.14 | 74.61 | 74.19 | 0.42 | |
| MART | 87.90 | 66.63 | 70.95 | 68.27 | 2.68 | |
| MART-GAWP | 88.07 | 68.89 | 74.09 | 73.57 | 0.52 | |
| Threat Model | Method | CIFAR-10 | CIFAR-100 | SVHN | |||
|---|---|---|---|---|---|---|---|
| Natural | AA | Natural | AA | Natural | AA | ||
| AT | 86.50 | 51.67 | 60.88 | 27.71 | 92.89 | 50.23 | |
| AT-AWP | 86.80 | 54.64 | 60.73 | 29.99 | 93.78 | 55.83 | |
| AT-RWP | 86.18 | 55.53 | 62.95 | 30.30 | 92.74 | 54.28 | |
| AT-MLCATWP | 82.89 | 53.45 | 59.50 | 29.49 | 92.76 | 53.47 | |
| AT-GAWP | 87.29 | 56.28 | 63.97 | 30.91 | 93.82 | 56.01 | |
| AT | 90.50 | 70.11 | 68.01 | 42.00 | 93.65 | 65.73 | |
| AT-AWP | 92.61 | 74.21 | 70.10 | 45.89 | 94.01 | 68.80 | |
| AT-RWP | 92.11 | 74.41 | 70.31 | 46.07 | 94.48 | 68.95 | |
| AT-MLCATWP | 90.38 | 72.45 | 70.30 | 45.97 | 94.40 | 68.99 | |
| AT-GAWP | 92.88 | 74.56 | 70.88 | 46.71 | 95.21 | 69.71 | |
| Natural (%) | AA (%) | ||
|---|---|---|---|
| ✓ | 85.21 | 54.56 | |
| ✓ | 86.95 | 55.94 | |
| ✓ | ✓ | 87.29 | 56.28 |
| Strategy | Natural (%) | AA (%) |
|---|---|---|
| 86.95 | 55.94 | |
| 86.83 | 55.88 | |
| 87.29 | 56.28 | |
| 86.55 | 55.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Chiang, H.-D. Geometry-Aware Weight Perturbation for Adversarial Training. Electronics 2024, 13, 3508. https://doi.org/10.3390/electronics13173508
Jiang Y, Chiang H-D. Geometry-Aware Weight Perturbation for Adversarial Training. Electronics. 2024; 13(17):3508. https://doi.org/10.3390/electronics13173508
Chicago/Turabian StyleJiang, Yixuan, and Hsiao-Dong Chiang. 2024. "Geometry-Aware Weight Perturbation for Adversarial Training" Electronics 13, no. 17: 3508. https://doi.org/10.3390/electronics13173508
APA StyleJiang, Y., & Chiang, H.-D. (2024). Geometry-Aware Weight Perturbation for Adversarial Training. Electronics, 13(17), 3508. https://doi.org/10.3390/electronics13173508