


A Multidimensional Framework Incorporating 2D U-Net and 3D Attention U-Net for the Segmentation of Organs from 3D Fluorodeoxyglucose-Positron Emission Tomography Images

 ,
,  , ,
, ,  and
and 
Abstract
1. Introduction
- Address a significant gap in the field by providing a dedicated solution for segmenting PET images;
- Leverage the power of combined machine learning models to enhance automatic segmentation performance;
- Propose a new, ensemble approach, that is particularly suited for achieving high validation performance when training on limited samples.
2. Materials and Methods
2.1. Dataset
2.2. Ensemble Model Architecture
2.2.1. 3D AU-Net
2.2.2. 2D U-Net
2.2.3. Ensemble
2.3. Training Setup
3. Results
- Dice Score (also known as Dice Coefficient or F1 Score), similarly to the Dice Loss, is defined as the ratio of the intersection of the predicted and ground truth regions to the average size of the regions. The Dice score ranges from 0 to 1, where a value of 1 indicates a perfect overlap between the segmentation and ground truth.
- Intersection over Union (IoU): IoU is another popular metric for evaluating segmentation performance. It measures the average overlap between the predicted and ground truth regions for all classes of interest. The IoU for each class is calculated as the ratio of the intersection to the union of the predicted and ground truth regions. The IoU provides a comprehensive evaluation of the model’s performance across all classes and is also known as the Jaccard Index.
- Precision and Recall [31]: Precision and recall are metrics commonly used in binary or multi-class segmentation tasks. Precision (also known as positive predictive value) measures the proportion of true positive predictions (correctly identified pixels) out of all pixels predicted as positive (both true positive and false positive). Recall (also known as sensitivity) measures the proportion of true positive predictions out of all actual positive pixels (both true positive and false negative). Precision and recall are complementary metrics, and a trade-off between them is often encountered when fine-tuning segmentation models.
- The standard deviation (std) of the scores of the metrics measures the variability or consistency of the model’s performance across different samples. A lower standard deviation indicates more stable and reliable segmentation results, while a higher standard deviation suggests greater variability in performance.
4. Discussion
Limitations and Future Recommendations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Phelps, M.E. Positron emission tomography provides molecular imaging of biological processes. Proc. Natl. Acad. Sci. USA 2000, 97, 9226–9233. [Google Scholar] [CrossRef] [PubMed]
- Wahl, R.L.; Jacene, H.; Kasamon, Y.; Lodge, M.A. From RECIST to PERCIST: Evolving Considerations for PET Response Criteria in Solid Tumors. J. Nucl. Med. 2009, 50, 122S–150S. [Google Scholar] [CrossRef] [PubMed]
- Javaid, M.; Haleem, A.; Pratap Singh, R.; Suman, R.; Rab, S. Significance of machine learning in healthcare: Features, pillars and applications. Int. J. Intell. Networks 2022, 3, 58–73. [Google Scholar] [CrossRef]
- Montagne, S.; Hamzaoui, D.; Allera, A.; Ezziane, M.; Luzurier, A.; Quint, R.; Kalai, M.; Ayache, N.; Delingette, H.; Renard-Penna, R. Challenge of prostate MRI segmentation on T2-weighted images: Inter-observer variability and impact of prostate morphology. Insights Imaging 2021, 12, 71. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Iliadou, V.; Kakkos, I.; Karaiskos, P.; Kouloulias, V.; Platoni, K.; Zygogianni, A.; Matsopoulos, G.K. Early Prediction of Planning Adaptation Requirement Indication Due to Volumetric Alterations in Head and Neck Cancer Radiotherapy: A Machine Learning Approach. Cancers 2022, 14, 3573. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Kakkos, I.; Vagenas, T.P.; Zygogianni, A.; Matsopoulos, G.K. Towards Automation in Radiotherapy Planning: A Deep Learning Approach for the Delineation of Parotid Glands in Head and Neck Cancer. Bioengineering 2024, 11, 214. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017, arXiv:1606.00915. [Google Scholar] [CrossRef]
- Myronenko, A. 3D MRI brain tumor segmentation using autoencoder regularization. arXiv 2018, arXiv:1810.11654. [Google Scholar]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.; et al. nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.; Xu, D. UNETR: Transformers for 3D Medical Image Segmentation. arXiv 2021, arXiv:2103.10504. [Google Scholar]
- Eiber, M.; Weirich, G.; Holzapfel, K.; Souvatzoglou, M.; Haller, B.; Rauscher, I.; Beer, A.J.; Wester, H.J.; Gschwend, J.; Schwaiger, M.; et al. Simultaneous 68Ga-PSMA HBED-CC PET/MRI Improves the Localization of Primary Prostate Cancer. Eur. Urol. 2016, 70, 829–836. [Google Scholar] [CrossRef]
- Vagenas, T.P.; Economopoulos, T.L.; Sachpekidis, C.; Dimitrakopoulou-Strauss, A.; Pan, L.; Provata, A.; Matsopoulos, G.K. A Decision Support System for the Identification of Metastases of Metastatic Melanoma Using Whole-Body FDG PET/CT Images. IEEE J. Biomed. Health Inform. 2023, 27, 1397–1408. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Gatidis, S.; Hepp, T.; Früh, M.; Fougère, C.L.; Nikolaou, K.; Pfannenberg, C.; Schölkopf, B.; Küstner, T.; Cyran, C.; Rubin, D. A whole-body FDG-PET/CT Dataset with manually annotated Tumor Lesions. Sci. Data 2022, 9, 601. [Google Scholar] [CrossRef]
- Lee, C.Y.; Xie, S.; Gallagher, P.W.; Zhang, Z.; Tu, Z. Deeply-Supervised Nets. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015. [Google Scholar]
- Wahid, K.A.; He, R.; McDonald, B.A.; Anderson, B.M.; Salzillo, T.; Mulder, S.; Wang, J.; Sharafi, C.S.; McCoy, L.A.; Naser, M.A.; et al. Intensity standardization methods in magnetic resonance imaging of head and neck cancer. Phys. Imaging Radiat. Oncol. 2021, 20, 88–93. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, C.C.; Peng, C.H.; Wu, F.Z.; Cheng, D.C. Impact of Voxel Normalization on a Machine Learning-Based Method: A Study on Pulmonary Nodule Malignancy Diagnosis Using Low-Dose Computed Tomography (LDCT). Diagnostics 2023, 13, 3690. [Google Scholar] [CrossRef] [PubMed]
- Ghazvanchahi, A.; Maralani, P.J.; Moody, A.R.; Khademi, A. Effect of Intensity Standardization on Deep Learning for WML Segmentation in Multi-Centre FLAIR MRI. Proc. Mach. Learn. Res. 2023, 227, 1923–1940. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar] [CrossRef]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Cardoso, M.J., Arbel, T., Carneiro, G., Syeda-Mahmood, T., Tavares, J.M.R., Moradi, M., Bradley, A., Greenspan, H., Papa, J.P., Madabhushi, A., et al., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. arXiv 2017, arXiv:1506.01186. [Google Scholar]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar] [CrossRef]
- Ruxton, G.D. The unequal variance t-test is an underused alternative to Student’s t-test and the Mann–Whitney U test. Behav. Ecol. 2006, 17, 688–690. [Google Scholar] [CrossRef]
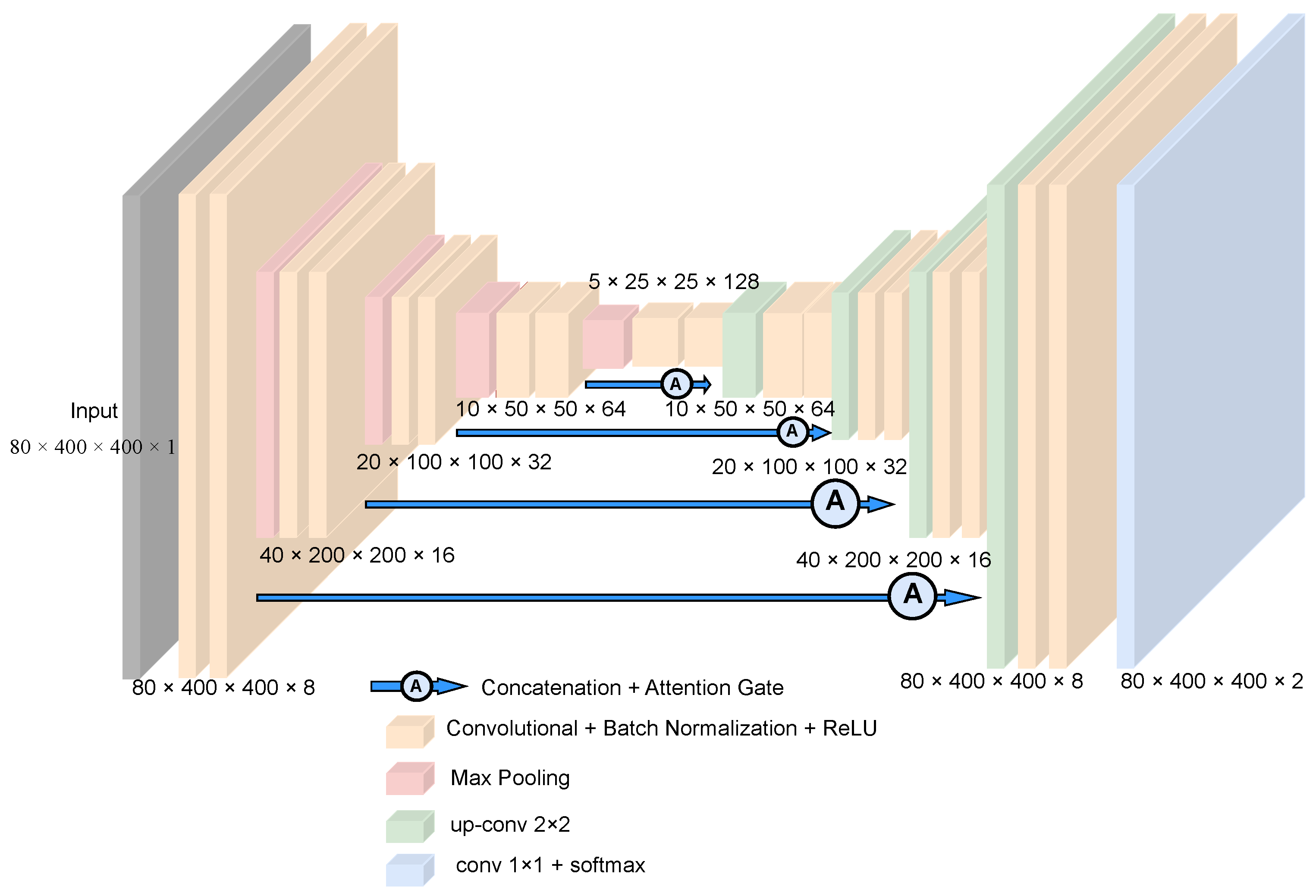
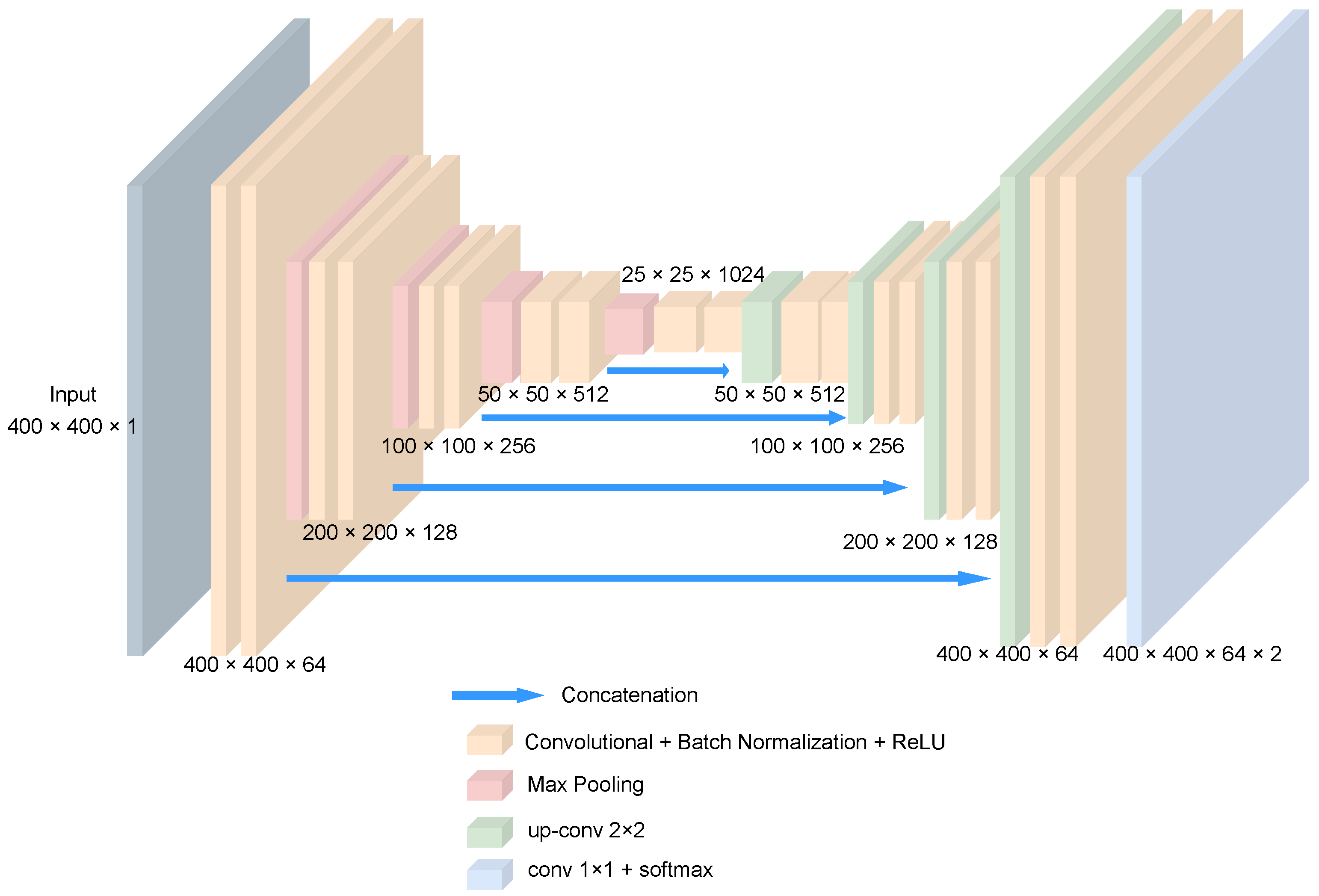
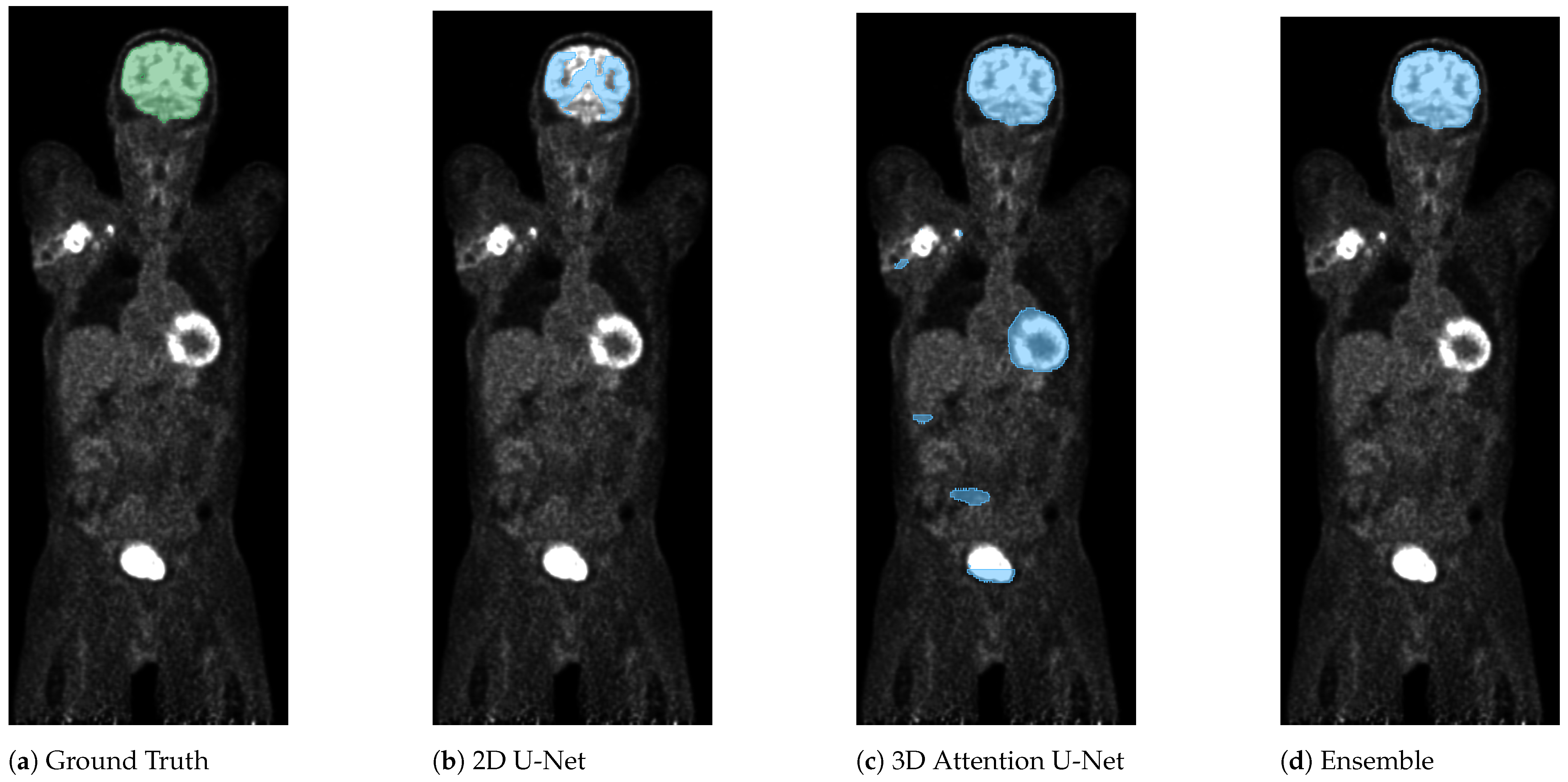
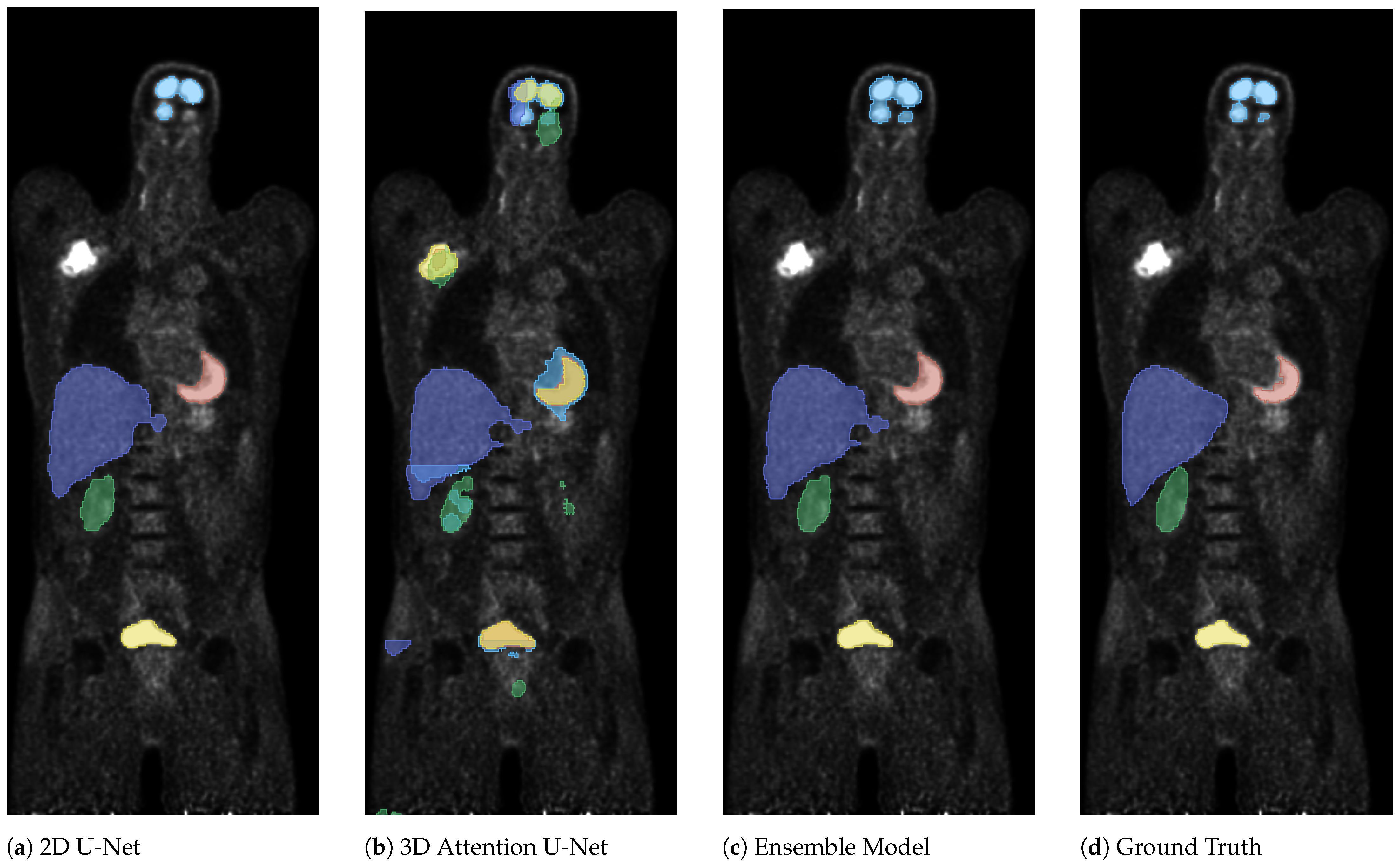


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Organ | Models | Metrics | Trained on 15 Data | 20 Data | 30 Data | 40 Data | 50 Data |
|---|---|---|---|---|---|---|---|
| Bladder | Ensemble | Dice Score | 92.49 ± 3.12 | 96 ± 4.90 | 95.15 ± 2.45 | 86.29 ± 2.23 | 96.89 ± 2.21 |
| Precision | 88.07 ± 5.11 | 0.9684 ± 6.50 | 0.9422 ± 4.92 | 0.7808 ± 4.25 | 0.9509 ± 4.01 | ||
| Recall | 0.9812 ± 2.15 | 0.9535 ± 4.36 | 0.9659 ± 5.55 | 0.9958 ± 5.45 | 0.9887 ± 1.22 | ||
| IoU | 0.8646 ± 5.18 | 0.9241 ± 3.36 | 0.9100 ± 3.67 | 0.7769 ± 6.34 | 0.9399 ± 3.01 | ||
| 2D | Dice Score | 50.26 ± 12.02 | 46.43 ± 10.10 | 48.28 ± 6.35 | 31.35 ± 5.02 | 30.76 ± 5.09 | |
| Precision | 35.63 ± 15.01 | 32.19 ± 16.78 | 33.77 ± 10.50 | 19.31 ± 20.11 | 18.61 ± 18.47 | ||
| Recall | 94.48 ± 2.19 | 94.18 ± 4.34 | 89.81 ± 2.25 | 99.04 ± 2.25 | 96.99 ± 4.12 | ||
| IoU | 34.97 ± 10.54 | 31.60 ± 12.10 | 32.41 ± 10.64 | 19.26 ± 14.92 | 18.49 ± 14.48 | ||
| 3D | Dice Score | 26.16 ± 5.10 | 49.80 ± 17.54 | 58.80 ± 18.02 | 28.19 ± 13.05 | 32.90 ± 17.06 | |
| Precision | 15.57 ± 5.51 | 35.84 ± 15.90 | 45.38 ± 10.31 | 16.83 ± 5.34 | 20.05 ± 8.90 | ||
| Recall | 96.58 ± 4.80 | 88.60 ± 7.82 | 91.86 ± 5.66 | 97.79 ± 4.36 | 97.41 ± 5.97 | ||
| IoU | 15.50 ± 7.82 | 34.31 ± 10.10 | 44.03 ± 15.39 | 16.78 ± 9.25 | 19.95 ± 9.50 | ||
| Deeplab | Dice Score | 32.78 ± 10.25 | 17.13 ± 6.01 | 46.45 ± 17.56 | 54.77 ± 13.78 | 49.30 ± 16.34 | |
| Precision | 20.61 ± 5.40 | 9.61 ± 4.16 | 34.87 ± 6.85 | 38.88 ± 6.32 | 35.98 ± 8.40 | ||
| Recall | 91.41 ± 7.81 | 89.08 ± 3.20 | 81.55 ± 12.58 | 41.14 ± 6.98 | 97.41 ± 10.95 | ||
| IoU | 20.09 ± 8.91 | 9.49 ± 4.21 | 32.05 ± 7.92 | 87.07 ± 7.50 | 89.21 ± 11.35 | ||
| SegResNet | Dice Score | 69.28 ± 14.90 | 73.39 ± 15.30 | 63.11 ± 18.05 | 81.30 ± 10.22 | 80.50 ± 13.13 | |
| Precision | 60.09 ± 10.55 | 65.77 ± 11.12 | 50.40 ± 15.25 | 76.71 ± 10.20 | 86.68 ± 12.40 | ||
| Recall | 86.59 ± 8.40 | 87.30 ± 10.92 | 94.02 ± 12.08 | 87.97 ± 7.71 | 77.61 ± 4.55 | ||
| IoU | 54.90 ± 12.66 | 60.27 ± 12.60 | 48.89 ± 15.05 | 69.68 ± 11.95 | 69.32 ± 9.38 |
| Organ | Models | Metrics | Trained on 15 Data | 20 Data | 30 Data | 40 Data | 50 Data |
|---|---|---|---|---|---|---|---|
| Brain | Ensemble | Dice Score | 93.70 ± 2.12 | 94.70 ± 3.15 | 96.53 ± 3.34 | 97.09 ± 2.90 | 97.01 ± 3.03 |
| Precision | 89.09 ± 3.32 | 93.65 ± 4.38 | 95.36 ± 4.85 | 95.83 ± 3.11 | 96.55 ± 3.85 | ||
| Recall | 99.08 ± 3.05 | 96.50 ± 2.95 | 97.88 ± 3.09 | 98.52 ± 2.47 | 97.67 ± 2.67 | ||
| IoU | 88.31 ± 4.01 | 90.22 ± 3.54 | 93.33 ± 4.16 | 94.40 ± 3.16 | 94.27 ± 3.21 | ||
| 2D | Dice Score | 78.79 ± 5.10 | 59.02 ± 2.85 | 70.13 ± 7.23 | 53.41 ± 3.67 | 86.14 ± 7.31 | |
| Precision | 70.27 ± 7.95 | 43.29 ± 1.88 | 56.09 ± 3.68 | 37.20 ± 1.15 | 78.95 ± 4.44 | ||
| Recall | 91.72 ± 5.16 | 94.73 ± 7.39 | 96.42 ± 5.22 | 96.72 ± 6.10 | 95.78 ± 3.08 | ||
| IoU | 65.57 ± 9.12 | 42.32 ± 8.22 | 54.66 ± 8.23 | 36.72 ± 4.54 | 76.24 ± 4.45 | ||
| 3D | Dice Score | 34.29 ± 4.11 | 37.59 ± 2.87 | 38.16 ± 9.01 | 48.68 ± 8.03 | 48.99 ± 7.44 | |
| Precision | 21.57 ± 3.12 | 24.39 ± 1.46 | 24.76 ± 7.80 | 34.01 ± 5.6 | 34.31 ± 7.05 | ||
| Recall | 98.16 ± 9.79 | 92.76 ± 9.59 | 97.25 ± 10.05 | 98.27 ± 11.61 | 96.93 ± 9.90 | ||
| IoU | 21.51 ± 3.65 | 24.21 ± 2.76 | 24.62 ± 7.41 | 33.86 ± 7.99 | 34.02 ± 8.31 | ||
| Deeplab | Dice Score | 26.16 ± 5.40 | 49.80 ± 10.12 | 58.80 ± 7.09 | 77.39 ± 25.88 | 81.19 ± 8.67 | |
| Precision | 15.57 ± 4.30 | 35.84 ± 8.92 | 45.38 ± 6.44 | 89.88 ± 23.01 | 85.32 ± 12.08 | ||
| Recall | 96.58 ± 8.33 | 88.60 ± 12.31 | 91.86 ± 10.05 | 72.87 ± 19.30 | 79.30 ± 5.02 | ||
| IoU | 15.50 ± 4.05 | 34.31 ± 7.35 | 44.03 ± 5.53 | 65.74 ± 15.71 | 69.21 ± 7.10 | ||
| SegResNet | Dice Score | 91.12 ± 10.22 | 93.62 ± 4.14 | 90.90 ± 4.06 | 93.83 ± 3.17 | 93.38 ± 4.81 | |
| Precision | 96.78 ± 15.35 | 94.02 ± 7.81 | 89.94 ± 7.66 | 92.16 ± 8.31 | 96.23 ± 8.10 | ||
| Recall | 87.96 ± 8.51 | 94.05 ± 3.25 | 93.08 ± 2.12 | 96.15 ± 3.28 | 97.41 ± 3.54 | ||
| IoU | 85.07 ± 10.50 | 88.28 ± 6.02 | 83.57 ± 7.05 | 88.55 ± 5.91 | 91.50 ± 5.19 |
| Organ | Models | Metrics | Trained on 15 Data | 20 Data | 30 Data | 40 Data | 50 Data |
|---|---|---|---|---|---|---|---|
| Kidneys | Ensemble | Dice Score | 53.02 ± 2.28 | 50.93 ± 1.47 | 67.27 ± 2.94 | 55.13 ± 3.52 | 36.51 ± 3.92 |
| Precision | 48.08 ± 3.76 | 43.90 ± 1.89 | 63.68 ± 3.45 | 45.10 ± 3.11 | 28.05 ± 4.02 | ||
| Recall | 62.09 ± 4.98 | 65.67 ± 3.14 | 74.93 ± 4.10 | 73.28 ± 4.89 | 57.66 ± 3.09 | ||
| IoU | 37.70 ± 2.78 | 35.87 ± 2.87 | 53.73 ± 5.21 | 39.74 ± 3.25 | 23.82 ± 3.07 | ||
| 2D | Dice Score | 35.24 ± 2.56 | 39.64 ± 4.75 | 35.23 ± 5.19 | 36.16 ± 5.95 | 16.81 ± 3.47 | |
| Precision | 24.49 ± 5.01 | 29.96 ± 5.10 | 23.98 ± 6.24 | 23.12 ± 7.02 | 09.38 ± 2.11 | ||
| Recall | 67.77 ± 2.40 | 63.67 ± 4.51 | 73.69 ± 4.72 | 87.54 ± 4.03 | 85.89 ± 3.69 | ||
| IoU | 21.74 ± 3.58 | 25.18 ± 4.93 | 21.70 ± 4.71 | 22.17 ± 6.12 | 09.22 ± 1.19 | ||
| 3D | Dice Score | 37.61 ± 9.71 | 45.33 ± 13.28 | 33.25 ± 5.36 | 73.36 ± 7.80 | 73.64 ± 5.41 | |
| Precision | 26.91 ± 8.61 | 32.90 ± 7.62 | 22.91 ± 3.21 | 72.85 ± 8.53 | 67.50 ± 7.02 | ||
| Recall | 69.14 ± 2.22 | 76.64 ± 13.49 | 67.27 ± 7.85 | 76.71 ± 7.75 | 81.76 ± 4.91 | ||
| IoU | 24.78 ± 4.48 | 30.87 ± 7.40 | 20.84 ± 3.82 | 59.30 ± 12.01 | 59.71 ± 5.06 | ||
| Deeplab | Dice Score | 39.75 ± 15.99 | 31.70 ± 17.35 | 47.41 ± 20.14 | 40.89 ± 15.77 | 46.89 ± 20.00 | |
| Precision | 39.04 ± 14.61 | 22.81 ± 11.12 | 54.96 ± 19.68 | 35.38 ± 10.34 | 43.31 ± 18.60 | ||
| Recall | 26.86 ± 10.10 | 54.60 ± 18.32 | 46.06 ± 20.12 | 52.93 ± 17.91 | 53.40 ± 21.42 | ||
| IoU | 15.50 ± 9.92 | 20.10 ± 10.04 | 34.06 ± 18.35 | 27.10 ± 9.05 | 33.12 ± 17.12 | ||
| SegResNet | Dice Score | 37.27 ± 12.60 | 22.30 ± 17.16 | 61.54 ± 10.00 | 33.51 ± 7.51 | 53.08 ± 5.10 | |
| Precision | 30.91 ± 11.91 | 14.97 ± 15.01 | 64.38 ± 12.92 | 21.51 ± 5.98 | 38.57 ± 5.11 | ||
| Recall | 48.90 ± 13.75 | 63.38 ± 19.33 | 60.40 ± 10.56 | 78.20 ± 10.77 | 86.03 ± 7.80 | ||
| IoU | 23.56 ± 10.04 | 13.61 ± 9.65 | 45.16 ± 9.72 | 20.36 ± 6.12 | 36.29 ± 4.11 |
| Organ | Models | Metrics | Trained on 15 Data | 20 Data | 30 Data | 40 Data | 50 Data |
|---|---|---|---|---|---|---|---|
| Left Ventricle of the Heart | Ensemble | Dice Score | 76.77 ± 13.53 | 71.63 ± 18.65 | 82.33 ± 20.07 | 67.43 ± 14.54 | 72.05 ± 13.19 |
| Precision | 79.12 ± 14.12 | 69.78 ± 15.31 | 84.18 ± 22.30 | 54.86 ± 15.51 | 66.57 ± 13.01 | ||
| Recall | 81.65 ± 10.10 | 81.75 ± 19.45 | 84.33 ± 18.40 | 59.55 ± 13.66 | 86.31 ± 15.21 | ||
| IoU | 63.09 ± 14.54 | 57.04 ± 14.09 | 70.99 ± 19.36 | 90.17 ± 16.71 | 59.82 ± 12.53 | ||
| 2D | Dice Score | 22.53 ± 10.43 | 25.03 ± 10.12 | 36.96 ± 2.81 | 28.98 ± 14.81 | 34.88 ± 9.64 | |
| Precision | 15.24 ± 4.11 | 16.58 ± 5.50 | 27.12 ± 4.01 | 19.05 ± 10.12 | 24.64 ± 7.31 | ||
| Recall | 45.61 ± 14.33 | 70.01 ± 15.99 | 71.64 ± 2.02 | 83.90 ± 15.11 | 81.88 ± 12.30 | ||
| IoU | 12.76 ± 4.72 | 14.50 ± 5.02 | 22.96 ± 3.30 | 17.83 ± 5.30 | 22.30 ± 5.11 | ||
| 3D | Dice Score | 35.26 ± 13.26 | 22.36 ± 10.65 | 29.02 ± 4.18 | 24.85 ± 11.23 | 29.47 ± 13.42 | |
| Precision | 23.17 ± 12.62 | 14.11 ± 8.34 | 18.19 ± 3.85 | 15.57 ± 9.68 | 20.71 ± 11.64 | ||
| Recall | 78.84 ± 14.85 | 62.32 ± 12.45 | 78.26 ± 7.84 | 76.06 ± 13.24 | 66.80 ± 14.67 | ||
| IoU | 21.53 ± 11.46 | 13.02 ± 7.43 | 17.08 ± 4.48 | 15.03 ± 8.54 | 18.31 ± 10.62 | ||
| Deeplab | Dice Score | 21.89 ± 12.32 | 29.03 ± 11.32 | 34.66 ± 9.89 | 18.33 ± 10.84 | 44.68 ± 15.25 | |
| Precision | 19.15 ± 9.47 | 23.06 ± 10.43 | 35.66 ± 8.57 | 12.40 ± 8.46 | 59.95 ± 17.21 | ||
| Recall | 38.92 ± 13.06 | 44.74 ± 14.05 | 38.57 ± 10.30 | 16.16 ± 11.01 | 37.72 ± 12.12 | ||
| IoU | 14.09 ± 9.48 | 19.22 ± 10.30 | 24.20 ± 9.54 | 37.27 ± 9.30 | 32.72 ± 11.81 | ||
| SegResNet | Dice Score | 61.50 ± 25.60 | 30.94 ± 13.35 | 77.11 ± 2.46 | 56.96 ± 19.40 | 68.40 ± 15.84 | |
| Precision | 61.72 ± 22.61 | 19.58 ± 10.36 | 78.82 ± 5.10 | 44.37 ± 15.57 | 55.62 ± 10.11 | ||
| Recall | 64.89 ± 26.06 | 81.41 ± 15.03 | 77.06 ± 1.92 | 95.16 ± 20.84 | 95.10 ± 18.12 | ||
| IoU | 49.23 ± 20.24 | 19.07 ± 9.84 | 64.35 ± 2.11 | 42.43 ± 19.85 | 53.81 ± 11.02 |
| Organ | Models | Metrics | Trained on 15 Data | 20 Data | 30 Data | 40 Data | 50 Data |
|---|---|---|---|---|---|---|---|
| Liver | Ensemble | Dice Score | 83.10 ± 2.54 | 85.27 ± 3.08 | 88.11 ± 3.68 | 88.42 ± 3.86 | 88.46 ± 3.46 |
| Precision | 76.83 ± 4.54 | 83.41 ± 4.04 | 85.83 ± 3.56 | 86.15 ± 2.87 | 88.76 ± 3.78 | ||
| Recall | 92.29 ± 2.60 | 88.91 ± 3.00 | 91.23 ± 3.54 | 91.34 ± 4.05 | 88.98 ± 3.41 | ||
| IoU | 71.64 ± 3.50 | 75 ± 3.04 | 78.93 ± 3.54 | 79.41 ± 2.08 | 79.55 ± 2.01 | ||
| 2D | Dice Score | 67.58 ± 5.40 | 53.49 ± 5.54 | 81.18 ± 3.45 | 70.81 ± 3.54 | 68.88 ± 4.85 | |
| Precision | 55.61 ± 4.51 | 41.56 ± 4.61 | 76.52 ± 2.88 | 60.37 ± 2.81 | 62.80 ± 4.16 | ||
| Recall | 89.73 ± 6.73 | 80.57 ± 7.11 | 87.35 ± 4.71 | 89.59 ± 6.06 | 82.23 ± 6.54 | ||
| IoU | 51.17 ± 4.02 | 37.55 ± 4.58 | 68.61 ± 3.92 | 55.88 ± 4.20 | 54.31 ± 3.93 | ||
| 3D | Dice Score | 57.54 ± 7.42 | 57.15 ± 5.10 | 71.99 ± 5.03 | 80.89 ± 3.91 | 74.02 ± 30.01 | |
| Precision | 46.59 ± 5.12 | 44.47 ± 5.03 | 64.06 ± 4.85 | 82.44 ± 3.05 | 67.27 ± 25.01 | ||
| Recall | 79.92 ± 9.01 | 84.37 ± 7.06 | 84.47 ± 7.12 | 80.07 ± 4.26 | 85.87 ± 30.62 | ||
| IoU | 41.09 ± 5.82 | 40.65 ± 4.40 | 56.72 ± 5.01 | 68.31 ± 3.19 | 59.50 ± 28.30 | ||
| Deeplab | Dice Score | 41.57 ± 20.01 | 48.86 ± 15.57 | 50.52 ± 14.19 | 52.85 ± 20.58 | 55.94 ± 15.95 | |
| Precision | 31.23 ± 15.00 | 47.78 ± 14.04 | 51.18 ± 14.22 | 49.23 ± 19.58 | 55.73 ± 15.21 | ||
| Recall | 74.20 ± 22.18 | 55.10 ± 16.93 | 53.10 ± 15.03 | 61.04 ± 22.41 | 58.03 ± 15.99 | ||
| IoU | 28.71 ± 15.37 | 36.08 ± 14.02 | 37.53 ± 13.87 | 40.57 ± 18.62 | 44.08 ± 13.83 | ||
| SegResNet | Dice Score | 75.36 ± 15.78 | 81.91 ± 4.91 | 87.23 ± 2.89 | 86.43 ± 2.17 | 66.04 ± 10.02 | |
| Precision | 75.43 ± 14.39 | 90.66 ± 7.90 | 88.03 ± 1.90 | 81.98 ± 3.47 | 52.29 ± 8.30 | ||
| Recall | 78.20 ± 16.09 | 75.13 ± 10.15 | 86.55 ± 2.05 | 91.63 ± 4.32 | 93.06 ± 12.02 | ||
| IoU | 63.19 ± 13.45 | 69.56 ± 5.31 | 77.47 ± 5.12 | 76.21 ± 5.95 | 50.15 ± 9.76 |
| Organ | Model | Trained On 15 Data | 20 Data | 30 Data | 40 Data | 50 Data |
|---|---|---|---|---|---|---|
| Liver | 2D | 1.3 × 10−5 | 1.0 × 10−6 | 8 × 10−4 | 3.5 × 10−5 | 4.5 × 10−5 |
| 3D | 1.4 × 10−5 | 2.1 × 10−7 | 2.3 × 10−6 | 0.01 | 4.9 × 10−7 | |
| Deeplab | 1.5 × 10−4 | 0.001 | 0.0008 | 0.002 | 1.02 × 10−5 | |
| SegResNet | 0.05 | 0.0007 | 0.02 | 0.0005 | 5.4 × 10−5 | |
| Bladder | 2D | 1.7 × 10−5 | 8.4 × 10−7 | 3.8 × 10−8 | 1.1 × 10−10 | 1.2 × 10−9 |
| 3D | 1.4 × 10−9 | 0.0005 | 3.6 × 10−5 | 6 × 10−6 | 0.0001 | |
| Deeplab | 4.1 × 10−8 | 6.5 × 10−9 | 2.7 × 10−5 | 2.8 × 10−5 | 2.8 × 10−5 | |
| SegResNet | 0.001 | 0.004 | 0.0009 | 0.006 | 0.01 | |
| Left Ventricle of the Heart | 2D | 2.3 × 10−8 | 1.4 × 10−5 | 6.7 × 10−8 | 5 × 10−7 | 4.5 × 10−7 |
| 3D | 3.5 × 10−7 | 0.005 | 8.8 × 10−9 | 3.1 × 10−8 | 1.5 × 10−8 | |
| Deeplab | 4.3 × 10−5 | 0.005 | 0.002 | 1 × 10−5 | 0.008 | |
| SegResNet | 0.07 | 0.0007 | 0.40 | 0.0009 | 0.27 | |
| Brain | 2D | 5.4 × 10−9 | 3.8 × 10−10 | 3.3 × 10−8 | 1.4 × 10−9 | 3.6 × 10−6 |
| 3D | 4 × 10−9 | 7.9 × 10−12 | 1.8 × 10−8 | 6.8 × 10−9 | 1.4 × 10−9 | |
| Deeplab | 5.3 × 10−1 | 1 × 10−8 | 1.6 × 10−10 | 0.01 | 0.0002 | |
| SegResNet | 0.1 | 0.4 | 0.003 | 0.001 | 0.08 | |
| Kidneys | 2D | 1.2 × 10−6 | 4.3 × 10−5 | 4.6 × 10−5 | 4.2 × 10−9 | 1.2 × 10−7 |
| 3D | 0.001 | 0.08 | 0.2 | 1.2 × 10−7 | 6.4 × 10−8 | |
| Deeplab | 0.01 | 0.001 | 0.19 | 0.03 | 0.8 | |
| SegResNet | 0.001 | 0.0001 | 0.2 | 7.6 × 10−5 | 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vezakis, A.; Vezakis, I.; Vagenas, T.P.; Kakkos, I.; Matsopoulos, G.K. A Multidimensional Framework Incorporating 2D U-Net and 3D Attention U-Net for the Segmentation of Organs from 3D Fluorodeoxyglucose-Positron Emission Tomography Images. Electronics 2024, 13, 3526. https://doi.org/10.3390/electronics13173526
Vezakis A, Vezakis I, Vagenas TP, Kakkos I, Matsopoulos GK. A Multidimensional Framework Incorporating 2D U-Net and 3D Attention U-Net for the Segmentation of Organs from 3D Fluorodeoxyglucose-Positron Emission Tomography Images. Electronics. 2024; 13(17):3526. https://doi.org/10.3390/electronics13173526
Chicago/Turabian StyleVezakis, Andreas, Ioannis Vezakis, Theodoros P. Vagenas, Ioannis Kakkos, and George K. Matsopoulos. 2024. "A Multidimensional Framework Incorporating 2D U-Net and 3D Attention U-Net for the Segmentation of Organs from 3D Fluorodeoxyglucose-Positron Emission Tomography Images" Electronics 13, no. 17: 3526. https://doi.org/10.3390/electronics13173526
APA StyleVezakis, A., Vezakis, I., Vagenas, T. P., Kakkos, I., & Matsopoulos, G. K. (2024). A Multidimensional Framework Incorporating 2D U-Net and 3D Attention U-Net for the Segmentation of Organs from 3D Fluorodeoxyglucose-Positron Emission Tomography Images. Electronics, 13(17), 3526. https://doi.org/10.3390/electronics13173526