
Research on Low-Light Environment Object Detection Algorithm Based on YOLO_GD

Abstract
:1. Introduction
2. Related Works
2.1. Object Detection Methods
2.2. Attention Mechanism
3. The YOLO_GD Network Model
3.1. The Bi-Level Routing Spatial Attention Module
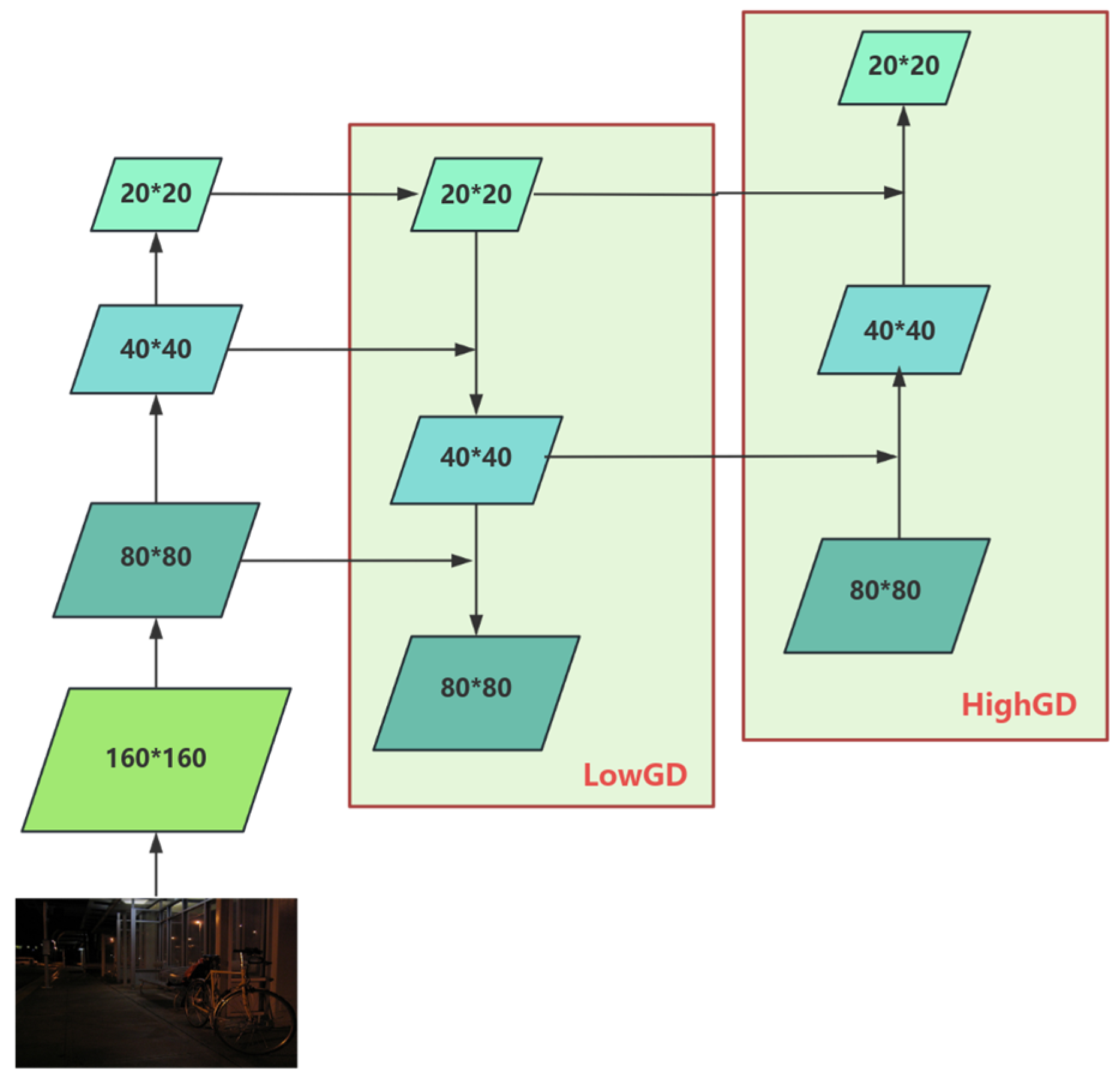
3.2. Cross-Layer Feature Fusion Method Based on Information Aggregation and Distribution Mechanism
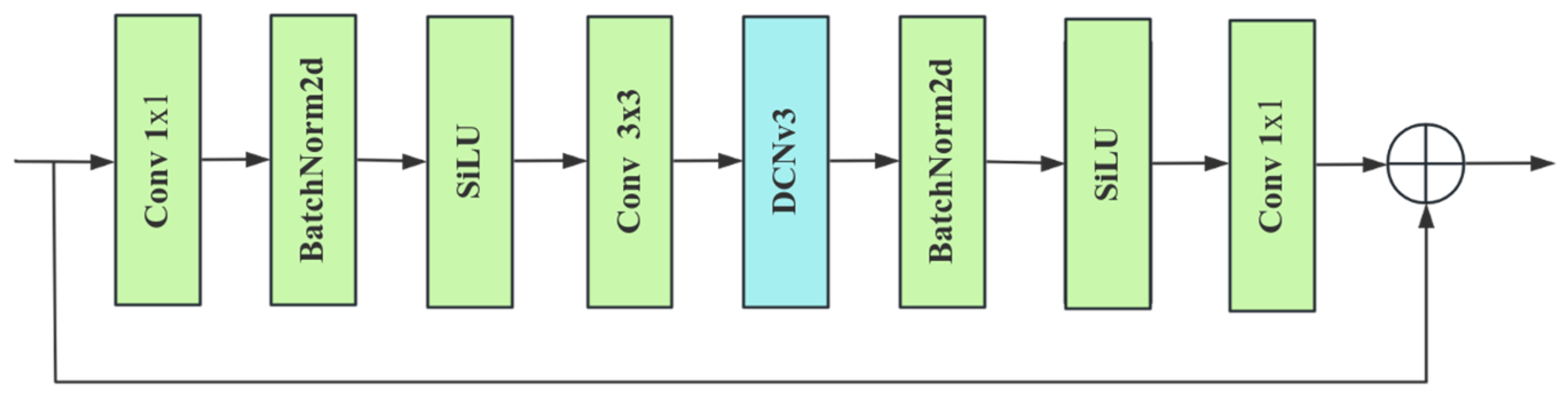
3.3. Cross-Stage Local Feature Fusion Module
3.4. Anchor Box Loss Function with Integrated Minimum Point Distance Mechanism
4. Experimental Results
4.1. Experimental Datasets
4.2. Experimental Environment and Parameter Settings
4.3. Evaluation Metrics
4.4. Model Training Results
4.5. Quantitative Analysis
4.6. Qualitative Analysis
4.7. Ablation Experiments
4.8. Supplementary Experiments on the UAVDT Dataset
5. Conclusions and Future Studies
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Shu, Z.; Zhang, Z.; Song, Z.; Wu, M.; Yuan, X. Low-Light Image Object Detection Based on Improved YOLOv5 Algorithm. Laser Optoelectron. Prog. 2023, 60, 67–74. [Google Scholar] [CrossRef]
- Liu, K.; Sun, Q.; Sun, D.; Peng, L.; Yang, M.; Wang, N. Underwater target detection based on improved YOLOv7. J. Mar. Sci. Eng. 2023, 11, 677. [Google Scholar] [CrossRef]
- Du, X.; Lin, T.Y.; Jin, P.; Ghiasi, G.; Tan, M.; Cui, Y.; Le, Q.V.; Song, X. Spinenet: Learning scale-permuted backbone for recognition and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11592–11601. [Google Scholar]
- Tan, M.X.; Pang, R.M.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; IEEE Computer Society Press: Los Alamitos, CA, USA, 2020; pp. 10778–10787. [Google Scholar]
- Tan, M.; Le, Q. Efficient Net: Rethinking model scaling for con-volutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 6105–6114. [Google Scholar]
- Chen, Q.; Wang, Y.M.; Yang, T.M.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE Computer Society Press: Los Alamitos, CA, USA, 2021; pp. 13034–13043. [Google Scholar]
- Chen, W.; Shah, T. Exploring low-light object detection techniques. arXiv 2021, arXiv:2107.14382. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Wu, Y.; Guo, H.; Chakraborty, C.; Khosravi, M.R.; Berretti, S.; Wan, S. Edge computing driven low-light image dynamic enhancement for object detection. IEEE Trans. Netw. Sci. Eng. 2022, 10, 3086–3098. [Google Scholar] [CrossRef]
- Hashmi, K.A.; Kallempudi, G.; Stricker, D.; Afzal, M.Z. Featenhancer: Enhancing hierarchical features for object detection and beyond under low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6725–6735. [Google Scholar]
- Wang, J.; Yang, P.; Liu, Y.; Shang, D.; Hui, X.; Song, J.; Chen, X. Research on improved yolov5 for low-light environment object detection. Electronics 2023, 12, 3089. [Google Scholar] [CrossRef]
- Qiu, Y.; Lu, Y.; Wang, Y.; Jiang, H. IDOD-YOLOV7: Image-dehazing YOLOV7 for object detection in low-light foggy traffic environments. Sensors 2023, 23, 1347. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Yuan, Y.; Liu, X.; Wang, L.; Zhou, X.; Yang, Y. Low-Light Salient Object Detection by Learning to Highlight the Foreground Objects. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7712–7724. [Google Scholar] [CrossRef]
- Cui, X.; Ma, L.; Ma, T.; Liu, J.; Fan, X.; Liu, R. Trash to treasure: Low-light object detection via decomposition-and-aggregation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 1417–1425. [Google Scholar]
- Wen, M.A.I.; Hao, L.I.; Yan, K. Low-Light Object Detection Based on Feature Interaction Structure. J. Comput. Eng. Appl. 2024, 60. [Google Scholar]
- Yao, M.; Lu, Y.; Mou, J.; Yan, C.; Liu, D. End-to-end adaptive object detection with learnable Retinex for low-light city environment. Nondestruct. Test. Eval. 2024, 39, 142–163. [Google Scholar] [CrossRef]
- Peng, D.; Ding, W.; Zhen, T. A novel low light object detection method based on the YOLOv5 fusion feature enhancement. Sci. Rep. 2024, 14, 4486. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE Computer Society Press: Los Alamitos, CA, USA, 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM:convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Wu, A.; Han, Y.; Zhu, L.; Yang, Y. Universal-prototype augmentation for few- shot object detection. arXiv 2021, arXiv:2103.01077. [Google Scholar]
- Ge, C.; Song, Y.; Ma, C.; Qi, Y.; Luo, P. Rethinking attentive object detection via neural attention learning. IEEE Trans. Image Process. 2023, 33, 1726–1739. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Qi, Y.; Zhang, H.; Bai, Z.; Lu, X.; Wang, P. D3d: Dual 3-d convolutional network for real-time action recognition. IEEE Trans. Ind. Inform. 2020, 17, 4584–4593. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. BiFormer: Vision Transformer with Bi-level Routing Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Phan, V.M.H.; Xie, Y.; Zhang, B.; Qi, Y.; Liao, Z.; Perperidis, A.; Phung, S.L.; Verjans, J.W.; To, M.-S. Structural Attention: Rethinking Transformer for Unpaired Medical Image Synthesis. arXiv 2024, arXiv:2406.18967. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO:Efficient Object Detector via Gather-and-Distribute Mechanism. arXiv 2023, arXiv:2309.11331. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Yi, Y.; Ni, F.; Ma, Y.; Zhu, X.; Qi, Y.; Qiu, R.; Zhao, S.; Li, F.; Wang, Y. High Performance Gesture Recognition via Effective and Efficient Temporal Modeling. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, 10–16 August 2019; pp. 1003–1009. [Google Scholar]
- Ma, S.; Xu, Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density map guided object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 190–191. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | P | mAP | Parameters | FLOPs |
|---|---|---|---|---|---|
| Faster R-CNN [32] | ResNet-50 | 70.97% | 63.52% | 43.10 M | 251.40 G |
| EfficientDet [5] | Efficient-B0 | 66.73% | 60.04% | 77.0 M | 515.40 G |
| YOLOv3 [33] | Darknet-53 | 74.58% | 67.80% | 61.53 M | 67.80 G |
| YOLOv5 | DarkNet-53 | 78.17% | 71.05% | 7.02 M | 15.80 G |
| YOLOv7 [10] | ELAN | 77.52% | 71.67% | 6.79 M | 15.70 G |
| YOLOv8 | DarkNet-53 | 77.70% | 71.80% | 3.9 M | 10.10 G |
| SSD [34] | VGG-16 | 69.87% | 61.75% | 41.10 M | 387.00 G |
| Dark-YOLOv8 | DarkNet-53 | 77.90% | 72.10% | 8.53 M | 14.51 G |
| Dark-YOLO | CSPDarkNet-53 | 75.04% | 74.76% | 63.9 M | 60.9 G |
| Night-YOLOX | CSPDarkNet | 74.70% | 74.10% | 121.90 M | 148.26 G |
| YOLO_GD | DarkNet-53 | 78.50% | 77.02% | 6.29 M | 15.61 G |
| Model | Gather- Distribute | BS_Attention | SF_DCNv3 | MPDLoss | P | mAP |
|---|---|---|---|---|---|---|
| YOLOv5s | 78.17% | 71.05% | ||||
| Experiment 1 | √ | 78.10% | 75.60% | |||
| Experiment 2 | √ | √ | 78.30% | 76.40% | ||
| Experiment 3 | √ | √ | 77.70% | 76.50% | ||
| Experiment 4 | √ | √ | √ | 77.75% | 76.57% | |
| Experiment 5 | √ | √ | √ | √ | 78.50% | 77.02% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wang, X.; Chang, Q.; Wang, Y.; Chen, H. Research on Low-Light Environment Object Detection Algorithm Based on YOLO_GD. Electronics 2024, 13, 3527. https://doi.org/10.3390/electronics13173527
Li J, Wang X, Chang Q, Wang Y, Chen H. Research on Low-Light Environment Object Detection Algorithm Based on YOLO_GD. Electronics. 2024; 13(17):3527. https://doi.org/10.3390/electronics13173527
Chicago/Turabian StyleLi, Jian, Xin Wang, Qi Chang, Yongshan Wang, and Haifeng Chen. 2024. "Research on Low-Light Environment Object Detection Algorithm Based on YOLO_GD" Electronics 13, no. 17: 3527. https://doi.org/10.3390/electronics13173527