
A Novel Short-Term PM2.5 Forecasting Approach Using Secondary Decomposition and a Hybrid Deep Learning Model

Abstract
1. Introduction
- (1)
- An innovative quadratic decomposition method, EMD-SE-GWO-VMD, is proposed. This method can more accurately extract the intrinsic non-stationary characteristics and periodic variation trend when decomposing PM2.5 series and significantly improve the performance of the prediction model.
- (2)
- Taking into account the impact of high-frequency and low-frequency sequences on PM2.5 concentration prediction, the ZCR-CNN-LSTM method is proposed. This method effectively distinguishes and processes the high-frequency and low-frequency components in the data, reducing information confusion. Simultaneously, it comprehensively captures and utilizes the temporal characteristics and periodicity of the data, significantly enhancing the precision of PM2.5 concentration forecast.
- (3)
- An inventive hybrid model, hybrid EMD-SE-GWO-VMD-ZCR-CNN-LSTM, is further designed for the short-term prediction of PM2.5 based on (1) and (2). The model makes full use of the non-stationarity and periodicity of PM2.5 data, effectively solves the influence of high- and low-frequency series on PM2.5 prediction, and significantly improves the reliability of PM2.5 prediction.
- (4)
- In order to evaluate the effectiveness and stability of the model, a series of novel experiments are designed. Data from three air quality monitoring stations 1009A, 1010A, and 1011A in the Beijing area are used. Comparing experimental outcomes with different prediction models, the R2 of this model at the three air quality monitoring stations increases by an average of 2.63%, 0.59%, and 1.88%, respectively. This demonstrates that the model has a major benefit in terms of increasing the precision of PM2.5 concentration forecast.
2. Data and Methods
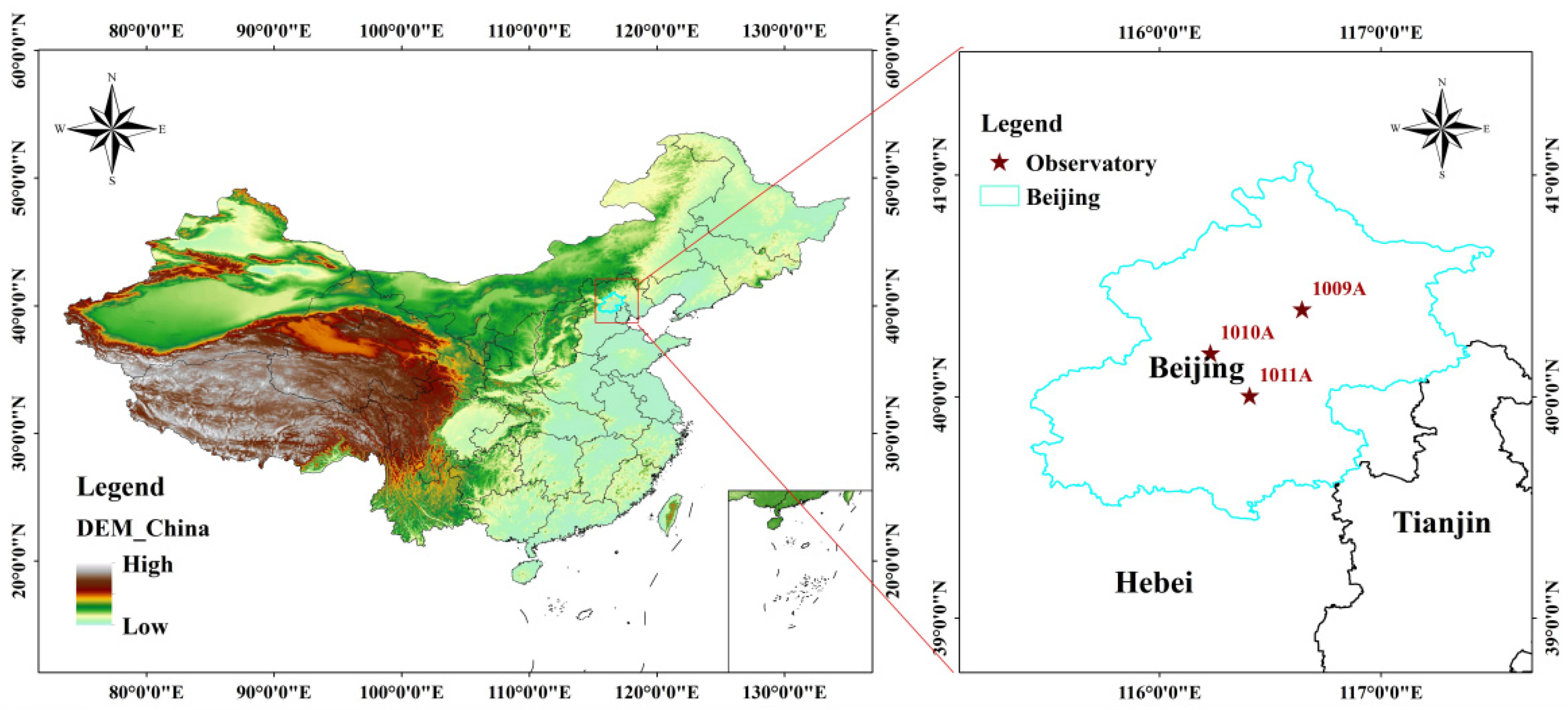
2.1. Description of the Dataset
2.2. Empirical Modal Decomposition
2.3. Sample Entropy
2.4. Variational Modal Decomposition Optimized by the Gray Wolf Optimization Algorithm
2.4.1. Gray Wolf Optimization Algorithm
2.4.2. Variational Modal Decomposition
2.4.3. GWO-VMD
2.5. Zero Crossing Rate
2.6. Convolutional Neural Network
2.7. Long Short-Term Memory Neural Network
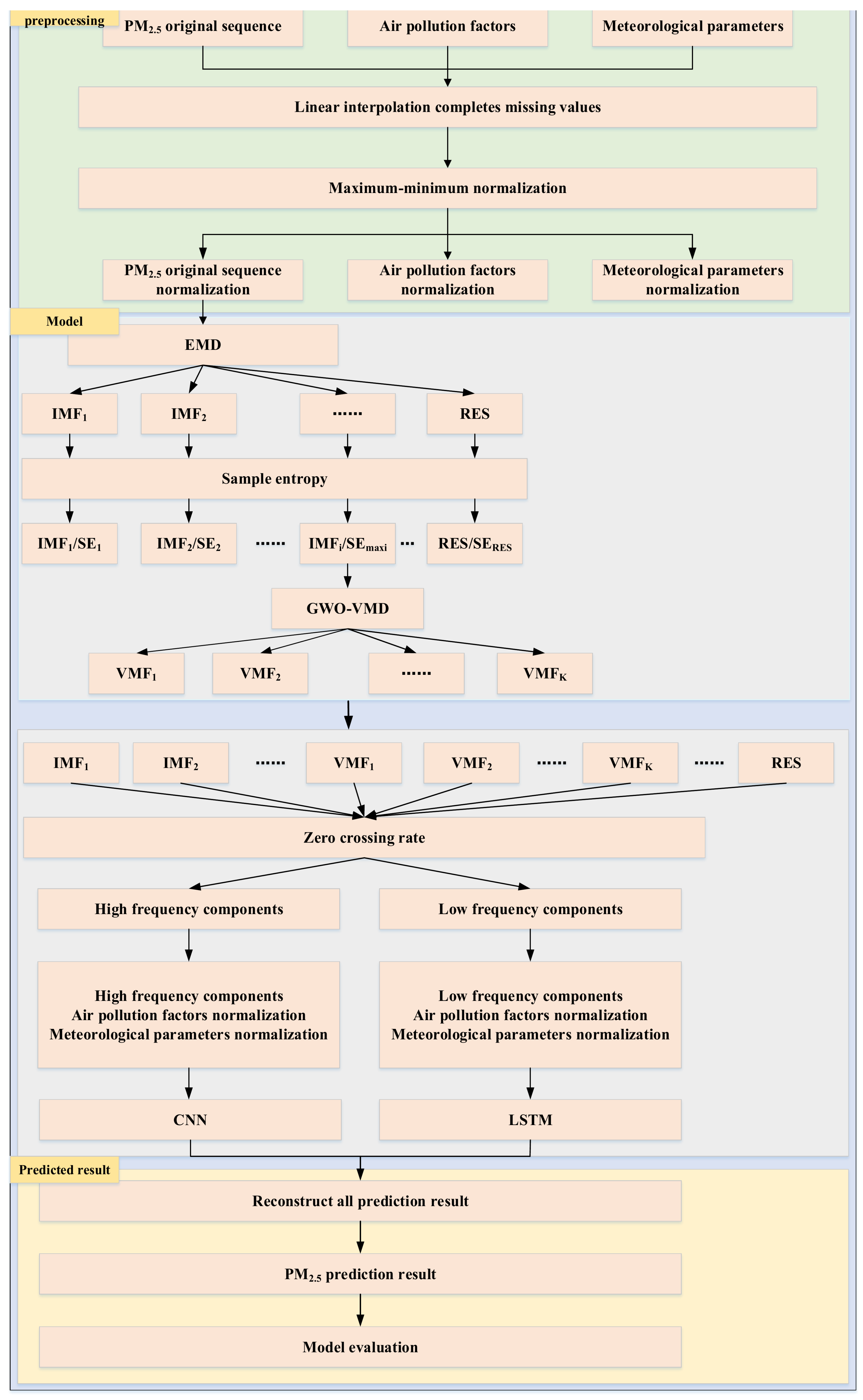
2.8. Prediction Model
2.9. Experimental Analysis and Experimental Setup
2.9.1. EMD Results and SE Calculations
2.9.2. The Greatest Complexity Subsequence of GWO-VMD
2.9.3. High- and Low-Frequency Division of Subsequences
2.9.4. Experimental Setup
2.10. Evaluation Metric
3. Results
3.1. The Predictive Outcomes of the Designed Model
3.2. Comparison between the Designed Model and a Single Deep Learning Model Prediction Result
3.3. Comparison of Model Prediction Results Combining Different Signal Decomposition Techniques
3.4. Comparison of Prediction Results Combining Different Models with EMD-SE-GWO-VMD
3.5. Comparison with Existing Model
4. Discussion
5. Conclusions
- (1)
- A VMD improvement based on the GWO algorithm, termed GWO-VMD, was designed, which eliminates the need for the manual selection of decomposition layers and penalty factors.
- (2)
- The complexity of the EMD primary decomposition subsequence was measured by SE, and in order to lower the intricate nature of the PM2.5 concentration sequence, the subsequence with the maximum complexity was decomposed secondarily.
- (3)
- ZCR was designed to divide the sequences after quadratic decomposition into high and low frequency; the high-frequency sequences are predicted by CNN, and the low-frequency sequences are predicted by LSTM, which takes into account the different characteristics of high- and low-frequency sequences.
- (4)
- A hybrid EMD-SE-GWO-VMD-ZCR-CNN-LSTM model was designed, and experiments were conducted at three air quality monitoring stations, 1009A, 1010A, and 1011A, in the Beijing area; the forecast performance of the model in this study was significantly superior than that of all the comparative models when compared with the other single deep learning models, the models with different signal decomposition techniques, and the hybrid model with different models combining EMD-SE-GWO-VMD.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gao, K.; Yuan, Y. Is the sky of smart city bluer? Evidence from satellite monitoring data. J. Environ. Manag. 2022, 317, 115483. [Google Scholar] [CrossRef] [PubMed]
- Yan, D.; Ren, X.; Kong, Y.; Ye, B.; Liao, Z. The heterogeneous effects of socioeconomic determinants on PM2.5 concentrations using a two-step panel quantile regression. Appl. Energy 2020, 272, 115246. [Google Scholar] [CrossRef]
- Yang, Y.; Xu, X.; Wei, J.; You, Q.; Wang, J.; Bo, X. A method of gas-related pollution source layout based on multi-source data: A case study of Shaanxi province, China. J. Environ. Manag. 2023, 347, 119198. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Tang, G.; Zhang, J.; Liu, B.; Liu, C.; Zhang, J.; Cong, L.; Cheng, M.; Yan, G.; Gao, W.; et al. Characteristics of PM2.5 pollution in Beijing after the improvement of air quality. J. Environ. Sci. 2021, 100, 1–10. [Google Scholar] [CrossRef]
- Maciejczyk, P.; Chen, L.C.; Thurston, G. The role of fossil fuel combustion metals in PM2.5 air pollution health associations. Atmosphere 2021, 12, 1086. [Google Scholar] [CrossRef]
- Li, X.; Xue, W.; Wang, K.; Che, Y.; Wei, J. Environmental regulation and synergistic effects of PM2.5 control in China. J. Clean. Prod. 2022, 337, 130438. [Google Scholar] [CrossRef]
- Abdelrahman, E.A.; Algethami, F.K.; AlSalem, H.S.; Al-Goul, S.T.; Saad, F.A.; El-Sayyad, G.S.; Alghanmi, R.M.; Rehman, K.u. Remarkable removal of pb (ii) ions from aqueous media using facilely synthesized sodium manganese silicate hydroxide hydrate/manganese silicate as a novel nanocomposite. J. Inorg. Organomet. Polym. Mater. 2024, 34, 1208–1220. [Google Scholar] [CrossRef]
- Hayes, R.B.; Lim, C.; Zhang, Y.; Cromar, K.; Shao, Y.; Reynolds, H.R.; Silverman, D.T.; Jones, R.R.; Park, Y.; Jerrett, M.; et al. PM2.5 air pollution and cause-specific cardiovascular disease mortality. Int. J. Epidemiol. 2020, 49, 25–35. [Google Scholar] [CrossRef]
- Shin, S.; Bai, L.; Burnett, R.T.; Kwong, J.C.; Hystad, P.; van Donkelaar, A.; Lavigne, E.; Weichenthal, S.; Copes, R.; Martin, R.V.; et al. Air pollution as a risk factor for incident chronic obstructive pulmonary disease and asthma. A 15-year population-based cohort study. Am. J. Resp. Crit. Care 2021, 203, 1138–1148. [Google Scholar] [CrossRef]
- Jiang, F.; Zhang, C.; Sun, S.; Sun, J. Forecasting hourly PM2.5 based on deep temporal convolutional neural network and decomposition method. Appl. Soft Comput. 2021, 113, 107988. [Google Scholar] [CrossRef]
- Thongthammachart, T.; Araki, S.; Shimadera, H.; Eto, S.; Matsuo, T.; Kondo, A. An integrated model combining random forests and WRF/CMAQ model for high accuracy spatiotemporal PM2.5 predictions in the Kansai region of Japan. Atmos. Environ. 2021, 262, 118620. [Google Scholar] [CrossRef]
- Hong, J.; Mao, F.; Min, Q.; Pan, Z.; Wang, W.; Zhang, T.; Gong, W. Improved PM2.5 predictions of WRF-chem via the integration of himawari-8 satellite data and ground observations. Environ. Pollut. 2020, 263, 114451. [Google Scholar] [CrossRef]
- Jat, R.; Jena, C.; Yadav, P.P.; Govardhan, G.; Kalita, G.; Debnath, S.; Gunwani, P.; Acharja, P.; Pawar, P.; Sharma, P.; et al. Evaluating the sensitivity of fine particulate matter (PM2.5) simulations to chemical mechanism in WRF-chem over Delhi. Atmos. Environ. 2024, 323, 120410. [Google Scholar] [CrossRef]
- Wu, C.; Li, K.; Bai, K. Validation and calibration of cams PM2.5 forecasts using in situ PM2.5 measurements in China and united states. Remote Sens. 2020, 12, 3813. [Google Scholar] [CrossRef]
- Zhao, L.; Li, Z.; Qu, L. Forecasting of Beijing PM2.5 with a hybrid ARIMA model based on integrated AIC and improved GS fixed-order methods and seasonal decomposition. Heliyon 2022, 8, e12239. [Google Scholar] [CrossRef] [PubMed]
- Bhatti, U.A.; Yan, Y.; Zhou, M.; Ali, S.; Hussain, A.; Huo, Q.; Yu, Z.; Yuan, L. Time series analysis and forecasting of air pollution particulate matter (PM 2.5): An SARIMA and factor analysis approach. IEEE Access 2021, 9, 41019–41031. [Google Scholar] [CrossRef]
- Lu, N.; Liu, S.; Du, J.; Fang, Z.; Dong, W.; Tao, L.; Yang, Y. Grey relational analysis model with cross-sequences and its application in evaluating air quality index. Expert Syst. Appl. 2023, 233, 120910. [Google Scholar] [CrossRef]
- Kim, B.Y.; Lim, Y.K.; Cha, J.W. Short-term prediction of particulate matter (PM10 and PM2.5) in Seoul, South Korea using tree-based machine learning algorithms. Atmos. Pollut. Res. 2022, 13, 101547. [Google Scholar] [CrossRef]
- Lee, D.; Lee, S. Hourly prediction of particulate matter (PM2.5) concentration using time series data and random forest. KIPS Trans. Softw. Data Eng. 2020, 9, 129–136. [Google Scholar]
- Liu, W.; Chen, F.; Chen, Y. PM2.5 concentration prediction based on pollutant pattern recognition using PCA-clustering method and CS algorithm optimized SVR. Nat. Environ. Pollut. Technol. 2022, 21, 393–403. [Google Scholar] [CrossRef]
- Chae, S.; Shin, J.; Kwon, S.; Lee, S.; Kang, S.; Lee, D. PM10 and PM2.5 real-time prediction models using an interpolated convolutional neural network. Sci. Rep. 2021, 11, 11952. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Li, W. A graph-based LSTM model for PM2.5 forecasting. Atmos. Pollut. Res. 2021, 12, 101150. [Google Scholar] [CrossRef]
- Yu, M.; Masrur, A.; Blaszczak-Boxe, C. Predicting hourly PM2.5 concentrations in wildfire-prone areas using a spatiotemporal transformer model. Sci. Total Environ. 2023, 860, 160446. [Google Scholar] [CrossRef] [PubMed]
- Verma, S.; Vaibhav, V.; Kumar, A. PM2.5 Concentration Forecast Using Hybrid Models over Urban Cities in India. In Proceedings of the Copernicus Meetings, New Delhi, India, 20–22 March 2024; Singh, R., Patel, M., Eds.; Copernicus Publications: Göttingen, Germany, 2024. Abstract No. 134. pp. 56–65. [Google Scholar]
- Nikpour, P.; Shafiei, M.; Khatibi, V. Gelato: A new hybrid deep learning-based informer model for multivariate air pollution prediction. Environ. Sci. Pollut. Res. 2024, 31, 29870–29885. [Google Scholar] [CrossRef] [PubMed]
- Qiao, W.; Tian, W.; Tian, Y.; Yang, Q.; Wang, Y.; Zhang, J. The forecasting of PM2.5 using a hybrid model based on wavelet transform and an improved deep learning algorithm. IEEE Access 2019, 7, 142814–142825. [Google Scholar] [CrossRef]
- Kim, J.; Wang, X.; Kang, C.; Yu, J.; Li, P. Forecasting air pollutant concentration using a novel spatiotemporal deep learning model based on clustering, feature selection and empirical wavelet transform. Sci. Total Environ. 2021, 801, 149654. [Google Scholar] [CrossRef]
- Yuan, E.; Yang, G. SA–EMD–LSTM: A novel hybrid method for long-term prediction of classroom PM2.5 concentration. Expert Syst. Appl. 2023, 230, 120670. [Google Scholar] [CrossRef]
- Yang, H.; Liu, Z.; Li, G. A new hybrid optimization prediction model for PM2.5 concentration considering other air pollutants and meteorological conditions. Chemosphere 2022, 307, 135798. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X. AQI time series prediction based on a hybrid data decomposition and echo state networks. Environ. Sci. Pollut. Res. 2021, 28, 51160–51182. [Google Scholar] [CrossRef]
- Ragab, M.G.; Abdulkadir, S.J.; Aziz, N.; Al-Tashi, Q.; Alyousifi, Y.; Alhussian, H.; Alqushaibi, A. A novel one-dimensional CNN with exponential adaptive gradients for air pollution index prediction. Sustainability 2020, 12, 10090. [Google Scholar] [CrossRef]
- Kristiani, E.; Lin, H.; Lin, J.R.; Chuang, Y.H.; Huang, C.Y.; Yang, C.T. Short-term prediction of PM2.5 using LSTM deep learning methods. Sustainability 2022, 14, 2068. [Google Scholar] [CrossRef]
- Ding, C.; Wang, G.; Zhang, X.; Liu, Q.; Liu, X. A hybrid CNN-LSTM model for predicting PM2.5 in Beijing based on spatiotemporal correlation. Environ. Ecol. Stat. 2021, 28, 503–522. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol.-Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Teng, M.; Li, S.; Yang, J.; Wang, S.; Fan, C.; Ding, Y.; Dong, J.; Lin, H.; Wang, S. Long-term PM2.5 concentration prediction based on improved empirical mode decomposition and deep neural network combined with noise reduction auto-encoder-a case study in Beijing. J. Clean. Prod. 2023, 428, 139449. [Google Scholar] [CrossRef]
- Tran, H.D.; Huang, H.Y.; Yu, J.Y.; Wang, S.H. Forecasting hourly PM2.5 concentration with an optimized LSTM model. Atmos. Environ. 2023, 315, 120161. [Google Scholar] [CrossRef]
- Huang, H.; Qian, C. Modeling PM2.5 forecast using a self-weighted ensemble GRU network: Method optimization and evaluation. Ecol. Indic. 2023, 156, 111138. [Google Scholar]
- Zhang, Z.; Zeng, Y.; Yan, K. A hybrid deep learning technology for PM2.5 air quality forecasting. Environ. Sci. Pollut. Res. 2021, 28, 39409–39422. [Google Scholar]
- Zeng, Y.; Chen, J.; Jin, N.; Jin, X.; Du, Y. Air quality forecasting with hybrid LSTM and extended stationary wavelet transform. Build. Environ. 2022, 213, 108822. [Google Scholar] [CrossRef]
- Chen, Y.; Hu, C. Hourly PM2.5 concentration prediction based on empirical mode decomposition and geographically weighted neural network. ISPRS Int. J. Geo-Inf. 2024, 13, 79. [Google Scholar] [CrossRef]
- Sun, W.; Huang, C. A hybrid air pollutant concentration prediction model combining secondary decomposition and sequence reconstruction. Environ. Pollut. 2020, 266, 115216. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.; Hua, P.; Gui, D.; Zhang, J. Extraction of multi-scale features enhances the deep learning-based daily PM2.5 forecasting in cities. Chemosphere 2022, 308, 136252. [Google Scholar] [CrossRef]
- Wang, W.; Ma, T.; Wang, L. Air pollutant concentration prediction based on a new hybrid model, feature selection, and secondary decomposition. Air Qual. Atmos. Health 2023, 16, 2019–2033. [Google Scholar] [CrossRef]
- Ma, J.; Qu, Y.; Yu, Z.; Wan, S. Climate modulation of external forcing factors on air quality change in eastern China: Implications for PM2. 5 seasonal prediction. Sci. Total Environ. 2023, 905, 166989. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Form |
|---|---|
| ARIMA | Auto Regressive Moving Average |
| SARIMA | Seasonal Auto Regressive Moving Average |
| GRA | Grey Relational Analysis |
| SVR | Support Vector Regression |
| CNN | Convolutional Neural Network |
| 1D-CNN | One-Dimensional Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short-Term Memory Network |
| NLSTM | Nested Long Short-Term Memory Network |
| BiLSTM | Bidirectional Long Short-Term Memory Network |
| LSSVM | Least-Squares Support Vector Machine |
| WT | Wavelet Transform |
| SAE | Stacked Autoencoder |
| EWT | Empirical Wavelet Transform |
| ESWT | Extended Stationary Wavelet Transform |
| EMD | Empirical Mode Decomposition |
| CEEMDAN | Complete Ensemble Empirical Mode Decomposition with Adaptive Noise |
| VMD | Variational Mode Decomposition |
| SA | Self-Attention |
| SE | Sample Entropy |
| AQI | Air Quality Index |
| ICA | Imperial Competition Algorithm |
| ESN | Echo State Network |
| GWO | Gray Wolf Optimizer |
| EAG | Exponential Adaptive Gradient |
| IMF | Intrinsic Mode Function |
| mRMR | Minimum Redundancy Maximum Relevance |
| GWNN | Geographically Weighted Neural Network |
| WOA | Whale Optimization Algorithm |
| ELM | Extreme Learning Machine |
| Air Quality Monitoring Station | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|
| 1009A | 5.5125 | 3.1847 | 0.2124 | 0.9936 |
| 1010A | 5.8898 | 3.5393 | 0.1484 | 0.9934 |
| 1011A | 6.3177 | 4.1527 | 0.1414 | 0.9943 |
| Air Quality Monitoring Station | Model | Model Number | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|---|
| 1009A | MLP | M2 | 17.1489 | 8.8310 | 0.3032 | 0.9379 |
| CNN | M3 | 17.0085 | 8.9903 | 0.3726 | 0.9389 | |
| RNN | M4 | 17.3233 | 8.6291 | 0.3228 | 0.9366 | |
| LSTM | M5 | 16.9490 | 8.3722 | 0.2806 | 0.9393 | |
| GRU | M6 | 17.0007 | 8.4437 | 0.2892 | 0.9390 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 5.5125 | 3.1847 | 0.2124 | 0.9936 | |
| 1010A | MLP | M2 | 18.7094 | 10.6266 | 0.3254 | 0.9337 |
| CNN | M3 | 17.7077 | 10.2174 | 0.3107 | 0.9406 | |
| RNN | M4 | 18.2045 | 10.5593 | 0.3025 | 0.9372 | |
| LSTM | M5 | 17.6573 | 10.1501 | 0.3027 | 0.9409 | |
| GRU | M6 | 17.7861 | 10.3277 | 0.2938 | 0.9400 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 5.8898 | 3.5393 | 0.1484 | 0.9934 | |
| 1011A | MLP | M2 | 19.2915 | 11.5904 | 0.3034 | 0.9468 |
| CNN | M3 | 17.7227 | 10.4208 | 0.3046 | 0.9551 | |
| RNN | M4 | 18.8139 | 10.6044 | 0.3032 | 0.9494 | |
| LSTM | M5 | 18.8494 | 10.7690 | 0.3082 | 0.9495 | |
| GRU | M6 | 18.8307 | 10.7373 | 0.3161 | 0.9493 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 6.3177 | 4.1527 | 0.1414 | 0.9943 |
| Air Quality Monitoring Station | Model | Model Number | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|---|
| 1009A | EWT-ZCR-CNN-LSTM | M7 | 16.5682 | 8.5400 | 0.2755 | 0.9468 |
| EMD-ZCR-CNN-LSTM | M8 | 10.2029 | 6.2355 | 0.2580 | 0.9802 | |
| GWO-VMD-ZCR-CNN-LSTM | M9 | 8.5861 | 5.2579 | 0.1997 | 0.9844 | |
| EWT-SE-GWO-VMD-ZCR-CNN-LSTM | M10 | 5.7798 | 8.1372 | 0.1812 | 0.9865 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 5.5125 | 3.1847 | 0.2124 | 0.9936 | |
| 1010A | EWT-ZCR-CNN-LSTM | M7 | 17.4899 | 10.7099 | 0.2987 | 0.9481 |
| EMD-ZCR-CNN-LSTM | M8 | 9.7201 | 6.2326 | 0.2115 | 0.9821 | |
| GWO-VMD-ZCR-CNN-LSTM | M9 | 9.0048 | 5.6965 | 0.2006 | 0.9846 | |
| EWT-SE-GWO-VMD-ZCR-CNN-LSTM | M10 | 7.8405 | 5.4195 | 0.1955 | 0.9889 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 5.8898 | 3.5393 | 0.1484 | 0.9934 | |
| 1011A | EWT-ZCR-CNN-LSTM | M7 | 17.1795 | 9.7908 | 0.2241 | 0.9643 |
| EMD-ZCR-CNN-LSTM | M8 | 10.7740 | 7.5436 | 0.2075 | 0.9834 | |
| GWO-VMD-ZCR-CNN-LSTM | M9 | 10.4423 | 6.3800 | 0.2013 | 0.9844 | |
| EWT-SE-GWO-VMD-ZCR-CNN-LSTM | M10 | 7.8944 | 6.1604 | 0.1606 | 0.9926 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 6.3177 | 4.1527 | 0.1414 | 0.9943 |
| Air Quality Monitoring Station | Model | Model Number | RMSE | MAE | MAPE | R2 |
|---|---|---|---|---|---|---|
| 1009A | EMD-SE-GWO-VMD-Decision Tree | M11 | 28.1985 | 17.9341 | 0.5809 | 0.8321 |
| EMD-SE-GWO-VMD-Random Forest | M12 | 17.7902 | 11.7570 | 0.4238 | 0.9332 | |
| EMD-SE-GWO-VMD-SVR | M13 | 15.7476 | 14.9050 | 0.5172 | 0.9476 | |
| EMD-SE-GWO-VMD-MLP | M14 | 14.2142 | 8.7555 | 0.3981 | 0.9573 | |
| EMD-SE-GWO-VMD-CNN | M15 | 10.4135 | 7.2636 | 0.3598 | 0.9771 | |
| EMD-SE-GWO-VMD-RNN | M16 | 10.0810 | 7.8021 | 0.4379 | 0.9785 | |
| EMD-SE-GWO-VMD-LSTM | M17 | 9.0059 | 6.7441 | 0.3591 | 0.9829 | |
| EMD-SE-GWO-VMD-GRU | M18 | 9.3199 | 7.2351 | 0.3897 | 0.9817 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 5.5125 | 3.1847 | 0.2124 | 0.9936 | |
| 1010A | EMD-SE-GWO-VMD-Decision Tree | M11 | 25.6944 | 15.7063 | 0.5127 | 0.8749 |
| EMD-SE-GWO-VMD-Random Forest | M12 | 19.4256 | 12.6792 | 0.3994 | 0.9285 | |
| EMD-SE-GWO-VMD-SVR | M13 | 13.8582 | 12.3357 | 0.6239 | 0.9636 | |
| EMD-SE-GWO-VMD-MLP | M14 | 14.2273 | 8.1253 | 0.2304 | 0.9616 | |
| EMD-SE-GWO-VMD-CNN | M15 | 9.7439 | 6.2053 | 0.2165 | 0.9820 | |
| EMD-SE-GWO-VMD-RNN | M16 | 6.9800 | 4.5268 | 0.1534 | 0.9908 | |
| EMD-SE-GWO-VMD-LSTM | M17 | 7.5932 | 4.7892 | 0.1552 | 0.9891 | |
| EMD-SE-GWO-VMD-GRU | M18 | 6.6581 | 4.3458 | 0.1492 | 0.9916 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 5.8898 | 3.5393 | 0.1484 | 0.9934 | |
| 1011A | EMD-SE-GWO-VMD-Decision Tree | M11 | 27.6091 | 17.5169 | 0.4381 | 0.8910 |
| EMD-SE-GWO-VMD-Random Forest | M12 | 21.4988 | 15.2694 | 0.3198 | 0.9339 | |
| EMD-SE-GWO-VMD-SVR | M13 | 17.6020 | 14.9459 | 0.6501 | 0.9557 | |
| EMD-SE-GWO-VMD-MLP | M14 | 15.7315 | 9.7975 | 0.2409 | 0.9646 | |
| EMD-SE-GWO-VMD-CNN | M15 | 11.3352 | 7.4703 | 0.2415 | 0.9816 | |
| EMD-SE-GWO-VMD-RNN | M16 | 7.2692 | 5.1784 | 0.1706 | 0.9924 | |
| EMD-SE-GWO-VMD-LSTM | M17 | 9.5960 | 7.1031 | 0.2076 | 0.9868 | |
| EMD-SE-GWO-VMD-GRU | M18 | 7.7402 | 5.8082 | 0.1923 | 0.9914 | |
| EMD-SE-GWO-VMD-ZCR-CNN-LSTM | M1 | 6.3177 | 4.1527 | 0.1414 | 0.9943 |
| Model | Time | Air Quality Monitoring Station | RMSE | MAE | MAPE (%) | R2 |
|---|---|---|---|---|---|---|
| The proposed model | 1 h | 1009A | 5.5125 | 3.1847 | 21.2403 | 0.9936 |
| 1010A | 5.8898 | 3.5393 | 14.8488 | 0.9934 | ||
| 1011A | 6.3177 | 4.1527 | 14.1465 | 0.9943 | ||
| VMD-BiLSTM [41] | 1 h | 1010A | 9.398 | 5.359 | 16.408 | 0.992 |
| ESWT-NLSTM [42] | 1 h | Beijing | 5.579 | 3.456 | 11.61 | 0.990 |
| EMD-mRMR-GWNN [43] | 1 h | 1005A | 8.9714 | 5.4614 | - | 0.9435 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Xu, L.; Zeng, T.; Luo, T.; Wang, M.; Zhou, Y.; Chen, C.; Zhao, S. A Novel Short-Term PM2.5 Forecasting Approach Using Secondary Decomposition and a Hybrid Deep Learning Model. Electronics 2024, 13, 3658. https://doi.org/10.3390/electronics13183658
Liu R, Xu L, Zeng T, Luo T, Wang M, Zhou Y, Chen C, Zhao S. A Novel Short-Term PM2.5 Forecasting Approach Using Secondary Decomposition and a Hybrid Deep Learning Model. Electronics. 2024; 13(18):3658. https://doi.org/10.3390/electronics13183658
Chicago/Turabian StyleLiu, Ruru, Liping Xu, Tao Zeng, Tao Luo, Mengfei Wang, Yuming Zhou, Chunpeng Chen, and Shuo Zhao. 2024. "A Novel Short-Term PM2.5 Forecasting Approach Using Secondary Decomposition and a Hybrid Deep Learning Model" Electronics 13, no. 18: 3658. https://doi.org/10.3390/electronics13183658
APA StyleLiu, R., Xu, L., Zeng, T., Luo, T., Wang, M., Zhou, Y., Chen, C., & Zhao, S. (2024). A Novel Short-Term PM2.5 Forecasting Approach Using Secondary Decomposition and a Hybrid Deep Learning Model. Electronics, 13(18), 3658. https://doi.org/10.3390/electronics13183658