1. Introduction
As the world’s population grows faster and more urbanized, more pollutants are released into the atmosphere than it can naturally absorb, leading to a growing problem with air pollution [
1,
2,
3]. The primary measure of air pollution, PM
2.5, has a significant effect on air quality [
4]. Particulate matter in the air with a diameter of less than or equal to 2.5 μm is referred to as PM
2.5, which is mainly generated from the combustion of fossil fuels, industrial production, transportation, and other processes of waste gas and smoke. It mainly comes from exhaust gases and soot produced during fossil fuel combustion, industrial production, transportation, and other processes [
5].
PM
2.5 has a significant impact on both the ecological environment and human health. Firstly, PM
2.5 reduces atmospheric visibility, leading to the formation of haze weather, which severely affects urban landscapes and residents’ quality of life [
6]. Secondly, PM
2.5 poses a serious threat to human health. These fine particles can penetrate deep into the lungs and even pass through lung alveolar walls into the bloodstream, causing serious damage to the respiratory and cardiovascular systems [
7]. According to reports from the World Health Organization, millions of people worldwide die prematurely each year due to exposure to PM
2.5 pollution. Specific data indicate that for every increase of 10 µg/m
3 in PM
2.5 concentration, there is an approximately 6% increase in cardiovascular disease mortality and an approximately 8% increase in lung cancer mortality [
8]. Additionally, PM
2.5 is closely associated with increased incidence of respiratory diseases such as childhood asthma and chronic obstructive pulmonary disease [
9]. Therefore, accurate prediction of PM
2.5 concentration is crucial for public health protection and environmental policy-making. Through effective forecasting, governments can issue timely air quality alerts, implement corresponding emission reduction measures, and mitigate the impact of pollution on public health. To facilitate understanding,
Table 1 lists the commonly used abbreviations and their corresponding full forms in this manuscript.
A time series prediction issue relying on past series data to infer future numerical trends is PM
2.5 concentration prediction [
10]. Current PM
2.5 concentration prediction models primarily encompass the following: physical models, statistical models, machine learning models, deep learning models, and hybrid models. Physical models are based on atmospheric physical, chemical, and kinetic equations, taking into account meteorological conditions, atmospheric dispersion, and chemical reactions to predict PM
2.5 concentrations. Commonly used physical models include CMAQ [
11], WRF-Chem [
12,
13], and CAMS [
14]. However, physical models are more complex to construct and require more knowledge of the environment and chemistry. On the other hand, statistical models are straightforward in theory and do not require sophisticated knowledge. Statistical models used for PM
2.5 concentration prediction mainly include auto regressive moving average model (ARIMA) [
15], seasonal auto regressive moving average model (SARIMA) [
16], and grey relational analysis (GRA) [
17]. Due to the limitations of statistical models in capturing complex nonlinear relationships, the introduction of machine learning models can better address these challenges. Mainstream machine learning models mainly include Decision Tree [
18], Random Forest [
19], and support vector regression (SVR) [
20]. As data size and complexity increase, machine learning models have limitations in dealing with more complex nonlinear relationships, thus driving the rise of deep learning models. Deep learning models for time series prediction mainly include convolutional neural networks (CNNs) [
21], long short-term memory (LSTM) [
22], and Transformer models [
23]. Some researchers have started looking into hybrid models [
24,
25] to further lower the error of PM
2.5 prediction by combining the benefits of various models.
Several academics have suggested using signal decomposition techniques to reduce the non-stationary nature of PM
2.5 sequences and improve the models’ forecasting accuracy, as this has an effect on modeling accuracy. Qiao et al. [
26] used the wavelet transform (WT) to decompose PM
2.5 sequences and used stacked auto encoder (SAE) and LSTM to make predictions. However, the wavelet basis function that is selected has a direct impact on the WT’s performance, and choosing a different wavelet basis function could have different consequences for signal feature extraction. Kim et al. [
27] used the empirical wavelet transform (EWT) and CNN combined with a bidirectional long- and short-term memory neural network (BiLSTM) to forecast PM
2.5 levels. Although EWT is a data adaptive wavelet transform method that does not require pre-selection of wavelet basis functions and successfully overcomes the limitations of traditional wavelet transforms, empirical mode decomposition (EMD) performs better in capturing the local features and nonlinear oscillations of the signal. Yuan et al. [
28] designed a self-attention mechanism (SA), and EMD and used LSTM to forecast the classroom’s PM
2.5 concentration. They used EMD to decompose the original PM
2.5 sequence and adopted an improved SA mechanism to reconstruct the subsequence. The reconstructed subsequence was input into LSTM for prediction. It greatly increased the accuracy of the prediction. Consequently, in this research, the original PM
2.5 sequences were decomposed using EMD, and the complexity of each subsequence was assessed using sample entropy (SE).
In pursuit of heightened prediction accuracy, certain scholars utilize secondary decomposition techniques to delve deeper into extracting data characteristics. Yang et al. [
29] delved into secondary decomposition through the integration of complete ensemble empirical modal decomposition (CEEMDAN) and variational modal decomposition (VMD) with the least-squares support vector machine (LSSVM) to forecast PM
2.5 concentration. The findings illustrated the superior predictive accuracy of this model compared to both single and hybrid models. Liu et al. [
30] used EWT-SE-VMD to decompose the original air quality index (AQI) sequence into multiple subsequences, used the imperial competition algorithm (ICA) to select the subsequences and input them into the echo state network (ESN) for prediction, and output the future AQI. While VMD offers superior advantages in mathematical stability and addressing local extreme point problems, the manual configuration of the number of decomposition layers and penalty factor can influence its effectiveness. To address this issue, the Gray Wolf Optimizer (GWO) algorithm, requiring fewer parameters and devoid of the necessity for gradient information, is employed in this study to fine-tune the parameters of VMD.
Researchers have used different models for PM
2.5 concentration prediction. Ragab et al. [
31] used a one-dimensional deep convolutional neural network (1D-CNN) combined with exponential adaptive gradient (EAG) optimization to predict the air pollution index in Malaysia, but the 1D-CNN struggles with capturing long-term dependencies. Kristiani et al. [
32] utilized the LSTM deep learning technique for short-term PM
2.5 concentration forecasting, resulting in significantly enhanced predictive performance. The efficacy of an individual model is constrained, and superior outcomes can be attained through the fusion of diverse network architectures. Ding et al. [
33] devised a hybrid deep learning model that integrates both CNN and LSTM architectures to forecast PM
2.5 concentration, resulting in high accuracy. Nonetheless, in the majority of their research, the impact of both high and low data frequency on the prediction outcomes was overlooked. Therefore, in this study, ZCR is employed to separate the data’s high and low frequencies. The long-term features of the low-frequency sequences are extracted using LSTM, and the local features of the high-frequency sequences are extracted using CNN, to accomplish the prediction of the concentration of PM
2.5 by more thoroughly capturing the various aspects of the sequential data. This study’s main innovations and contributions are as follows:
- (1)
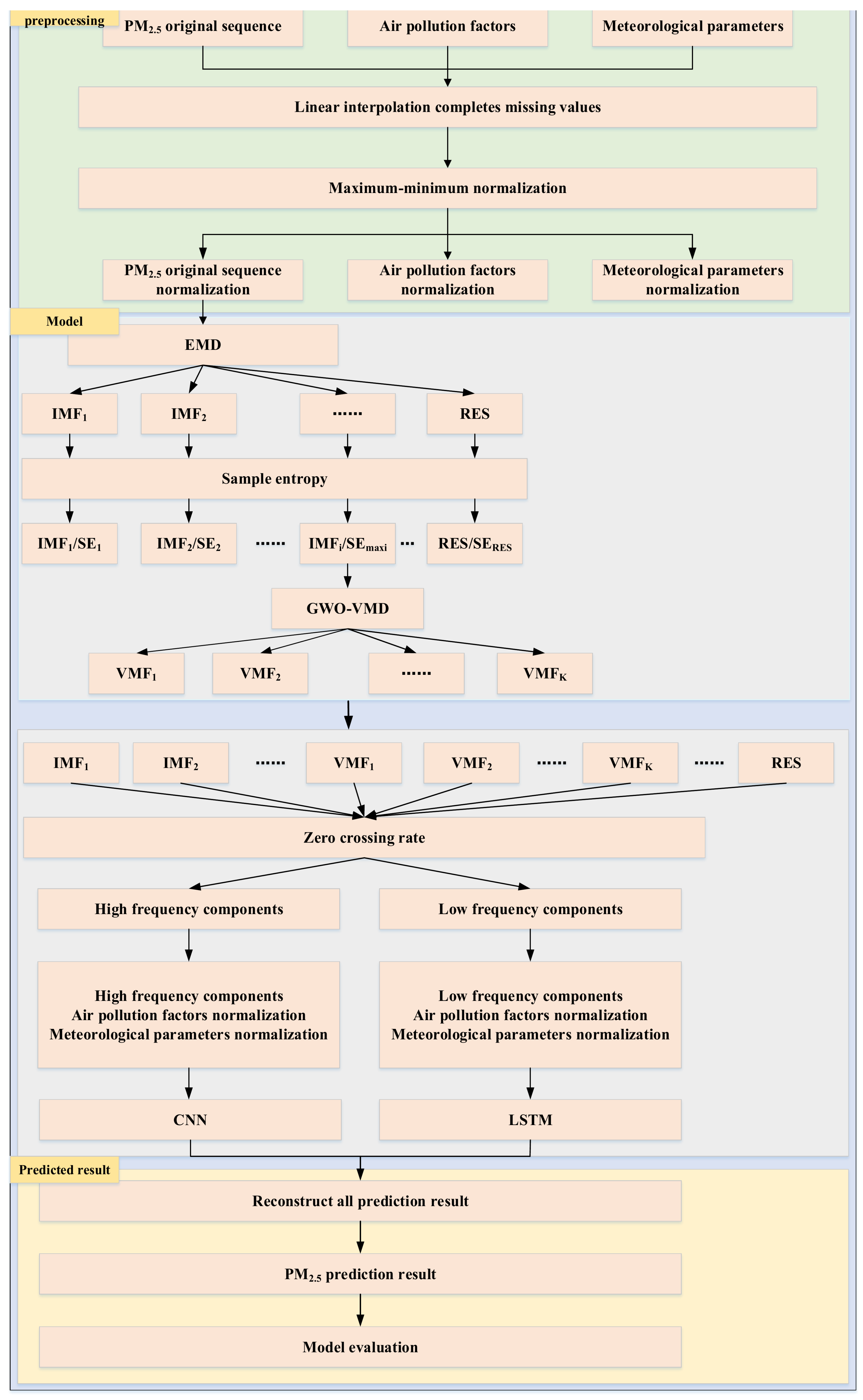
An innovative quadratic decomposition method, EMD-SE-GWO-VMD, is proposed. This method can more accurately extract the intrinsic non-stationary characteristics and periodic variation trend when decomposing PM2.5 series and significantly improve the performance of the prediction model.
- (2)
Taking into account the impact of high-frequency and low-frequency sequences on PM2.5 concentration prediction, the ZCR-CNN-LSTM method is proposed. This method effectively distinguishes and processes the high-frequency and low-frequency components in the data, reducing information confusion. Simultaneously, it comprehensively captures and utilizes the temporal characteristics and periodicity of the data, significantly enhancing the precision of PM2.5 concentration forecast.
- (3)
An inventive hybrid model, hybrid EMD-SE-GWO-VMD-ZCR-CNN-LSTM, is further designed for the short-term prediction of PM2.5 based on (1) and (2). The model makes full use of the non-stationarity and periodicity of PM2.5 data, effectively solves the influence of high- and low-frequency series on PM2.5 prediction, and significantly improves the reliability of PM2.5 prediction.
- (4)
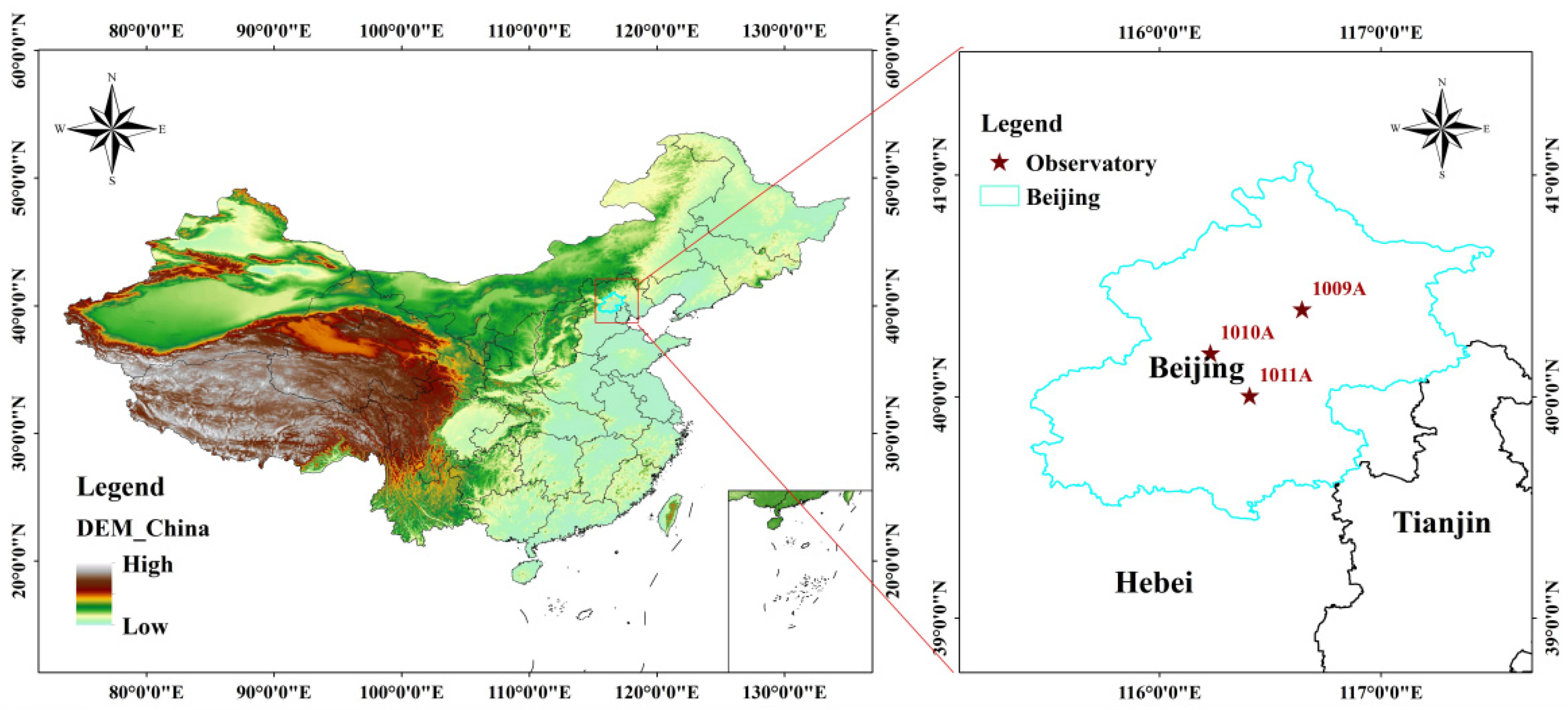
In order to evaluate the effectiveness and stability of the model, a series of novel experiments are designed. Data from three air quality monitoring stations 1009A, 1010A, and 1011A in the Beijing area are used. Comparing experimental outcomes with different prediction models, the R2 of this model at the three air quality monitoring stations increases by an average of 2.63%, 0.59%, and 1.88%, respectively. This demonstrates that the model has a major benefit in terms of increasing the precision of PM2.5 concentration forecast.
4. Discussion
VMD is an adaptive approach devoid of recursive operations for signal processing yielding excellent decomposition results. However, its decomposition outcomes are affected by the manual setting of the penalty factor and the number of decomposed layers. GWO-VMD automatically determines the optimal parameters of VMD based on the adaptive timing signal that needs to be broken down, which realizes the efficient decomposition of the signal and improves the decomposition effect.
The complexity of the subsequence formed by the EMD of the original sequence is still high due to the non-stationarity and nonlinearity of the PM2.5 sequence. Therefore, SE is used to evaluate the complexity of each subsequence, and GWO-VMD uses the secondary decomposing of the subsequence with the biggest complexity to reduce the additional complexity while increasing the model prediction correctness. EMD-SE-GWO-VMD is able to deconstruct the potential characteristics of the PM2.5 concentration series more effectively than EWT, EMD, and GWO-VMD.
Most researchers disregarded how high and low data frequencies affected the outcomes of their predictions. Thus, following secondary decomposition, ZCR was utilized to separate the sequences’ high and low frequencies, and it was shown that using ZCR to separate the high and low frequencies had the optimal prediction effect in the M11-M18 models.
Three Beijing air quality monitoring stations are used to test eighteen comparison models in order to confirm the designed model accuracy. The designed model outperforms other prediction models by a wide margin, according to the results.
5. Conclusions
In the existing literature, many studies have used signal decomposition techniques to improve the prediction accuracy of PM
2.5 and other air pollutants. For example, Ref. [
44] proposed a decomposition method combining CEEMDAN, SE, and VMD, used in conjunction with whale optimization algorithm (WOA)-optimized extreme learning machine (ELM). This approach significantly improved the prediction accuracy of NO
2 and SO
2 through secondary decomposition and complexity quantification. The authors of [
45] employed a two-stage decomposition technique combining CEEMDAN and VMD, along with LSTM, to enhance PM
2.5 prediction capabilities. The authors in [
46] utilized CEEMDAN and VMD techniques and applied MLP and GRU to predict secondary decomposition sequences and residual sequences, thereby improving prediction performance. These studies indicate that secondary decomposition strategies play a crucial role in enhancing prediction accuracy.
In contrast, this research introduces an innovative hybrid model for short-term PM2.5 forecasting, named EMD-SE-GWO-VMD-ZCR-CNN-LSTM. This model integrates EMD, SE, GWO-VMD, and ZCR-CNN-LSTM techniques to further enhance prediction accuracy. The following are the primary conclusions:
- (1)
A VMD improvement based on the GWO algorithm, termed GWO-VMD, was designed, which eliminates the need for the manual selection of decomposition layers and penalty factors.
- (2)
The complexity of the EMD primary decomposition subsequence was measured by SE, and in order to lower the intricate nature of the PM2.5 concentration sequence, the subsequence with the maximum complexity was decomposed secondarily.
- (3)
ZCR was designed to divide the sequences after quadratic decomposition into high and low frequency; the high-frequency sequences are predicted by CNN, and the low-frequency sequences are predicted by LSTM, which takes into account the different characteristics of high- and low-frequency sequences.
- (4)
A hybrid EMD-SE-GWO-VMD-ZCR-CNN-LSTM model was designed, and experiments were conducted at three air quality monitoring stations, 1009A, 1010A, and 1011A, in the Beijing area; the forecast performance of the model in this study was significantly superior than that of all the comparative models when compared with the other single deep learning models, the models with different signal decomposition techniques, and the hybrid model with different models combining EMD-SE-GWO-VMD.
Although this study effectively employs the innovative EMD-SE-GWO-VMD-ZCR-CNN-LSTM hybrid model for short-term PM
2.5 concentration forecasting, it has not fully considered the impact of seasonal factors on PM
2.5 concentrations. Research indicates that seasonal meteorological conditions significantly affect PM
2.5 levels. For example, spring features high wind speeds and temperature fluctuations, summer is characterized by high temperatures and aerosol generation, autumn has low humidity, and winter involves increased heating emissions [
47]. These seasonal variations can lead to significant fluctuations in PM
2.5 concentrations, thereby affecting the accuracy of prediction models.
Future research will incorporate seasonal factors to enhance the accuracy of the model. By integrating multi-site data and satellite remote sensing technology, it will be possible to more comprehensively account for the impact of seasons on PM2.5 concentrations, leading to more precise and effective air quality management strategies. These improvements are expected to further enhance the model’s predictive capability and provide stronger support for air quality management.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}