Abstract
Most of the existing research on video watermarking schemes focus on improving the robustness of watermarking. However, in application scenarios such as judicial forensics and telemedicine, the distortion caused by watermark embedding on the original video is unacceptable. To solve this problem, this paper proposes a robust reversible watermarking (RRW)scheme based on multi-layer embedding in the video compression domain. Firstly, the watermarking data are divided into several sub-secrets by using Shamir’s (t, n)-threshold secret sharing. After that, the chroma sub-block with more complex texture information is filtered out in the I-frame of each group of pictures (GOP), and the sub-secret is embedded in that frame by modifying the discrete cosine transform (DCT) coefficients within the sub-block. Finally, the auxiliary information required to recover the coefficients is embedded into the motion vector of the P-frame of each GOP by a reversible steganography algorithm. In the absence of an attack, the receiver can recover the DCT coefficients by extracting the auxiliary information in the vectors, ultimately recovering the video correctly. The watermarking scheme demonstrates strong robustness even when it suffers from malicious attacks such as recompression attacks and requantization attacks. The experimental results demonstrate that the watermarking scheme proposed in this paper exhibits reversibility and high visual quality. Moreover, the scheme surpasses other comparable methods in the robustness test session.
1. Introduction
The rapid proliferation of video applications has significantly increased the reliance on video as a primary mode of interpersonal information exchange. Video files, which seamlessly integrate the strengths of both images and audio, possess the capability to convey substantial amounts of information within a constrained timeframe, making them an ideal medium for information transmission. However, concerns over copyright infringement and information security in videos have gained prominence in recent times. Video watermarking technology addresses these issues by embedding watermark information into videos [1,2,3,4,5,6,7,8], thereby providing both copyright protection and integrity authentication. Consequently, this technology has emerged as a crucial solution to contemporary video information security challenges.
To mitigate the risk of watermarked information loss during transmission due to malicious or unintentional attacks, researchers have focused on enhancing the robustness of video watermarking techniques [9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24]. These techniques are typically categorized into two groups: frame-content-based schemes [9,10,11,12,13,14,15] and compressed bitstream-based approaches [16,17,18,19,20,21,22,23,24], depending on where the watermark is embedded. Frame-content-based schemes treat video sequences as continuous image sets and adapt existing image watermarking algorithms to video frames by modifying pixel values or modulating transform domain coefficients. Dhall, S et al. [15] proposed a multilayered watermarking mechanism. The watermarking mechanism compresses and quantum encrypts electronic patient records, and then embeds them into medical images after LWT transformation. The various planes of the watermarked medical images are scrambled and compressed, and then embedded into different bands of the reference image after LWT (lifting wavelet transform) transformation. This algorithm has achieved a high level of security. However, these schemes often struggle to balance robustness and complexity. To better suit real-time applications while maintaining robustness, recent advancements have included video watermarking schemes integrated with the video’s coding process, which modify coding process artifacts to embed watermark information, offering improved real-time performance and broader applicability. Chan, K et al. [24] proposed four hypothetical probability estimation methods designed to enhance entropy coding through Contextbased Adaptive Binary Arithmetic Coding (CABAC). These methods have been integrated into the ongoing development of the next-generation video coding standard, known as Versatile Video Coding (VVC). By leveraging improved probability estimation, this approach aims to boost compression efficiency. The adaptability of the various parameters allows the estimator to accommodate environments with differing adaptation rates, thereby enhancing its versatility. Yang L et al. [16] proposed a video watermarking scheme based on discrete cosine transform (DCT) coefficients that embeds watermark information by modifying the highest frequency DCT coefficients. The watermark, encoded as a BCH code carrier to reduce the bit error rate (BER), is embedded into the U-channel of video frames using parity quantization. Synchronization codes are employed to locate the watermark post-cropping. While this scheme achieves superior stealth, its effectiveness against recompression attacks varies due to the limited error correction capability of BCH codes. Di Fan et al. [17] introduced a video watermarking algorithm based on H.264/AVC that selects suitable chroma sub-blocks based on non-zero quantization coefficients and energy factors, employing optimized modulation to embed watermarks into DCT quantization coefficients. It demonstrates good invisibility and compression resistance; however, the irreversible watermark embedding algorithm may cause permanent alterations to the original video.
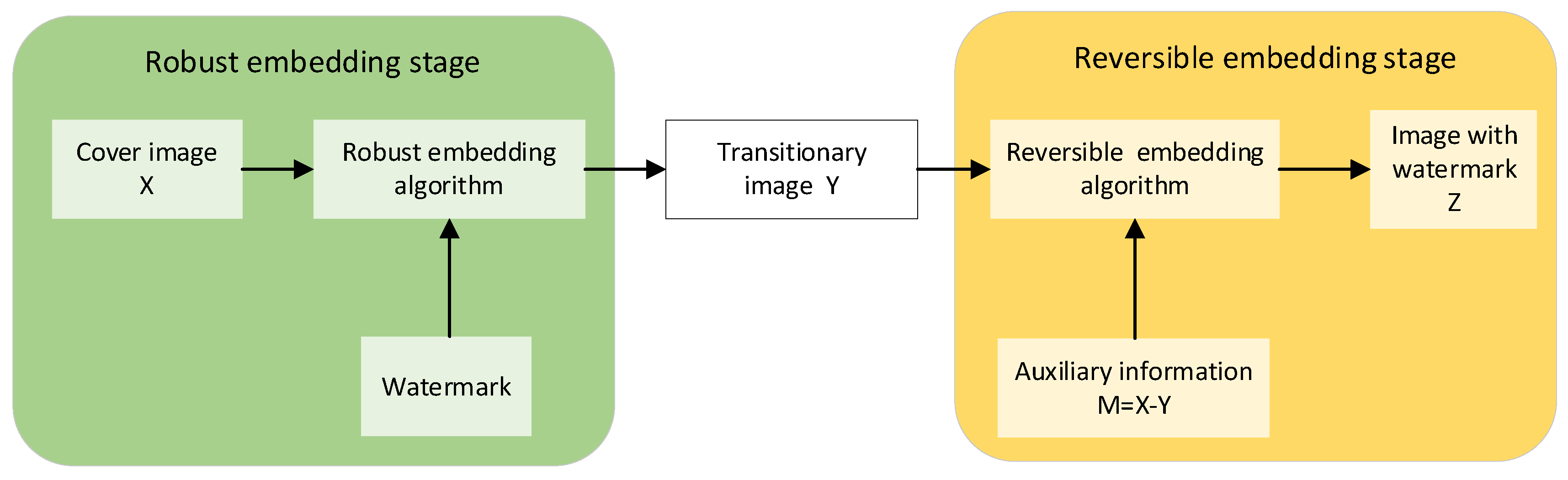
For copyright protection and recovery of the original image, robust reversible watermarking (RRW) has garnered significant attention from researchers. The currently widely used reversible robust watermarking schemes can be categorized into two types: Generalized Histogram Shifting (GHS) and Multilayer Watermarking (MLW). However, the GHS scheme has limited applicability due to its requirement for additional channels to transmit auxiliary information. As shown in Figure 1, Coltuc initially proposed the MLW framework in the literature [6], which employs two distinct phases for watermark embedding: robust embedding and reversible embedding. The distortion introduced during robust embedding forms the basis for the information embedded during reversible embedding, enabling the extraction of the robust watermark and recovery of the original image even if the reversible watermark is compromised post-attack.
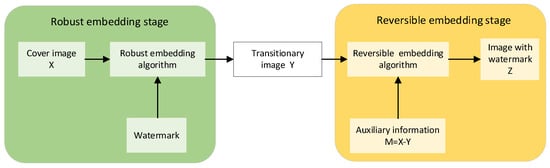
Figure 1.
The framework of Coltuc et al.’s RRW scheme.
However, Coltuc’s approach utilizes the same embedding domain for both robust and reversible embedding phases, resulting in robust watermarking being affected by both embedding noise and attack noise. Furthermore, reversible watermarking necessitates embedding a large amount of information, and embedding it into the same embedding domain as robust watermarking leads to significant distortion of the embedding vector. Wang Xiang et al. [25] proposed a robust reversible watermarking scheme that relies on independent embedding domains. This scheme involves generating two separate embedding domains through an independent embedding domain transformation process. The robust watermark and the reversible watermark are then embedded into these two domains, respectively. Experimental results indicate that this method prevents mutual interference between the two watermarks, enhances the robustness of watermark embedding, and enables the restoration of the original carrier image in the absence of any attacks.
In this paper, we enhance the MLW framework and apply it to video reversible robust watermarking. Initially, the watermarking data are divided into several sub-secrets using Shamir’s (t, n)-threshold secret sharing. These sub-secrets are then embedded by modifying the QDCT coefficients of the I-frame chroma sub-block of each group of pictures (GOP) in the video frame sequence. Subsequently, the auxiliary information necessary for recovering the coefficients is embedded as a reversible watermark in the motion vectors of the subsequent P-frames of the I-frames. By embedding the robust and reversible watermark into different domains of the compressed video, the noise effect on the robust watermark caused by the reversible embedding is mitigated, resulting in improved visual quality of the secret-containing video. Experimental results demonstrate that the scheme surpasses similar schemes in terms of robustness and invisibility.
2. Preliminary Concepts
2.1. H.264/AVC Video Compression Standard
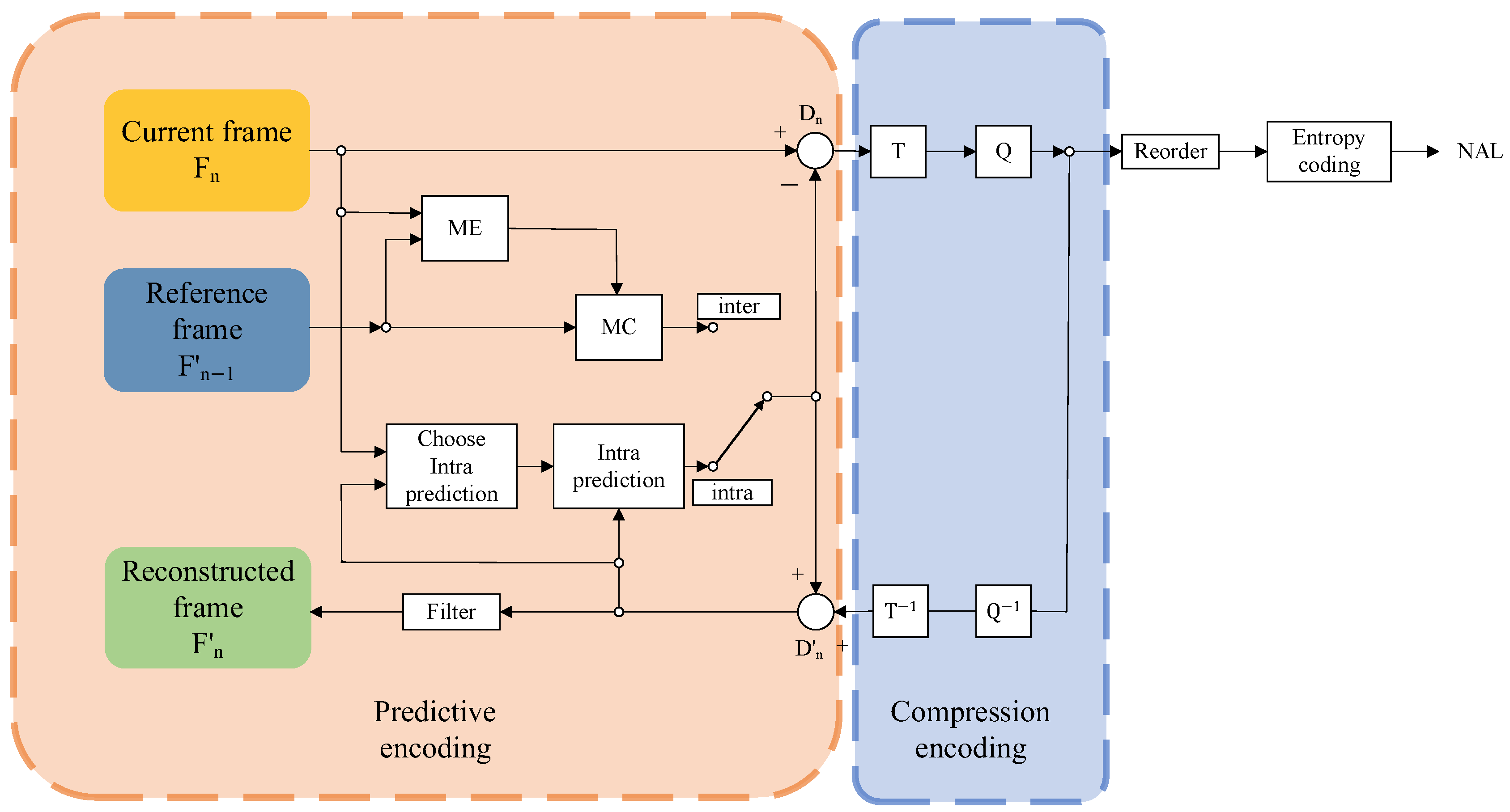
The H.264/AVC video codec standard, proposed jointly by the Joint Video Experts Group of the International Organization for Standardization (ISO) and the International Telecommunication Union (ITU), is currently the most prevalent video codec standard. H.264 employs predictive coding, leveraging either intra-frame or inter-frame prediction for the current coded frame, and organizes the sequence of video frames into GOPs. The initial frame of each GOP is designated as an I-frame, containing the complete picture information and utilizing only intra-frame prediction, enabling decoding to be self-contained. Conversely, P-frames, which constitute the remainder of the GOP, engage in predictive coding, utilizing previously coded video frames as references for inter-frame prediction. The discrepancies between prediction values and motion vectors are subsequently encoded into the video stream. Figure 2 illustrates the coding flow of a video frame using the H.264 standard.
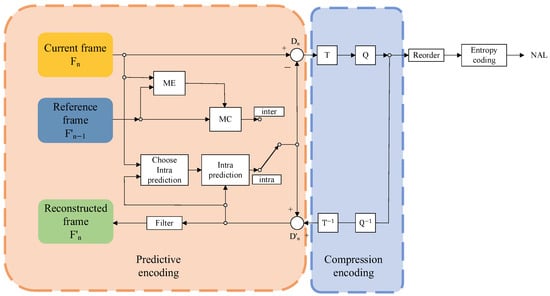
Figure 2.
Coding flow of a video frame using the H.264 standard.
2.2. Reference Frame Conversion Technique
One of the features of the H.264/AVC video codec standard is the multiple reference frame technique. When a video frame is decoded, it is stored in the decoded frame buffer, and some of the decoded frames are saved in the reference frame list. These decoded frames in the reference frame list are utilized as reference frames in the inter-frame prediction part of the subsequent frame encoding process. When motion vectors are used as vectors for reversible steganography, modifications to the motion vectors can cause a cumulative effect of errors in the subsequent frames. Taking the steganography of P-frame vectors as an example, the encoding of a P-frame depends on the completed decoding of the previous frame. If the vectors of the previous frame have been modified, the error caused by such modification will be further amplified in the encoding process of the current frame. To mitigate this issue, a frame is selected as a specific frame in a group of frame sequences at a certain interval distance, leveraging the fact that H.264/AVC can flexibly select a reference frame. As depicted in Figure 3, the specific frame is encoded with reference only to the previously encoded specific frame, and no secret information is embedded to keep the motion vector of the specific frame unchanged. Meanwhile, ordinary frames between adjacent specific frames use the previous specific frame as their own reference frame, which ensures that the accumulation of motion vector distortion caused by the embedding of secret information is limited to a small range between the two specific frames, ultimately reducing the impact of the distortion accumulation.

Figure 3.
Schematic diagram of the reference frame transformation technique.
2.3. QP Value under Recompression Attack
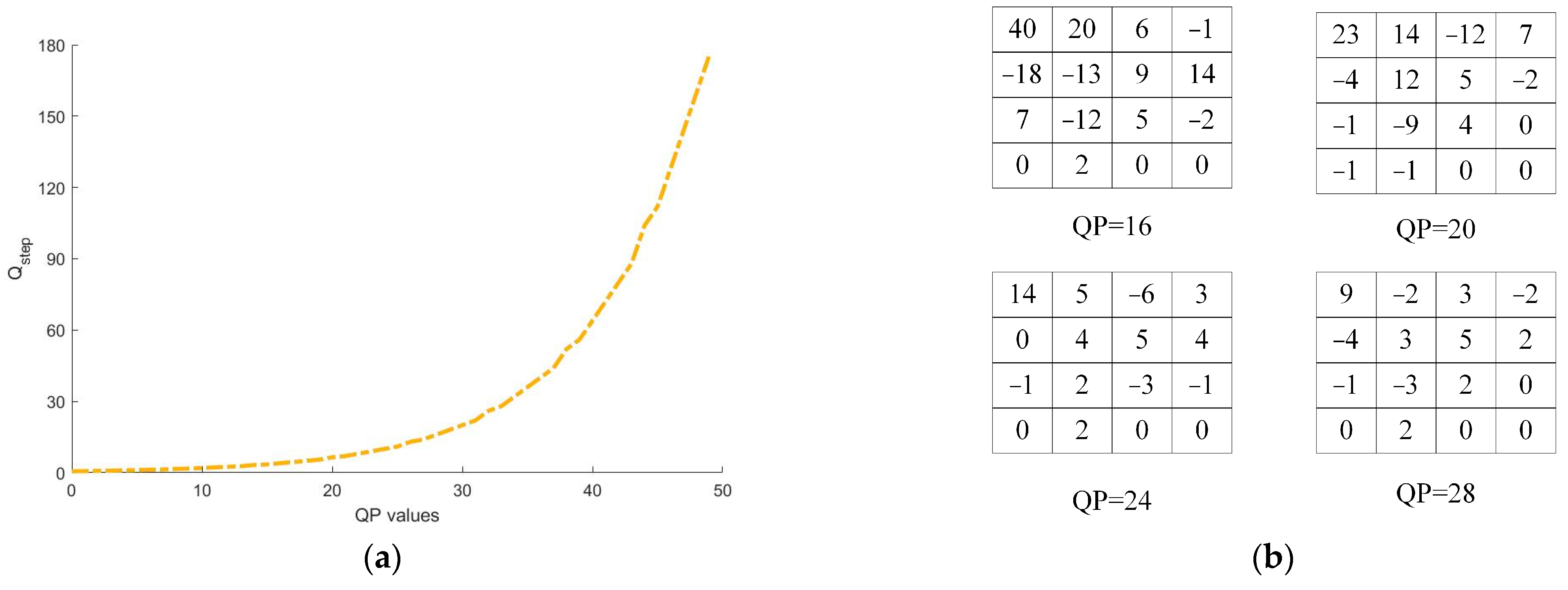
Video watermarks are frequently embedded into video streams and stored and transmitted alongside video files. In practical applications, video files often need to be distributed and shared across various users and network platforms. Due to limited storage resources on local and network servers, as well as bandwidth constraints on the transmission network, video files often require recompression to meet storage and transmission requirements in different scenarios. To achieve a smaller file size, as shown in Figure 4a, users frequently increase the quantization factor QP during video compression to reduce resource consumption of video files. However, altering the QP directly affects parameters such as transform coefficients and prediction modes during video coding, ultimately affecting the video watermark. As depicted in Figure 4b, changes in the QP value result in corresponding changes in the DCT coefficients. Therefore, resistance to recompression and QP value change attacks is a crucial indicator of robust watermarking.
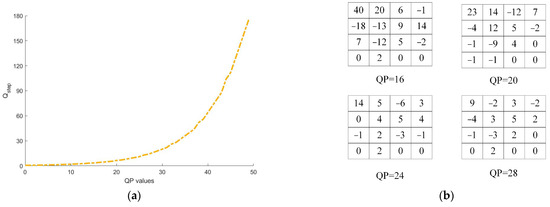
Figure 4.
(a) Relationship between QP and Qstep; (b) impact of increased QP on DCT coefficients.
3. Proposed Scheme
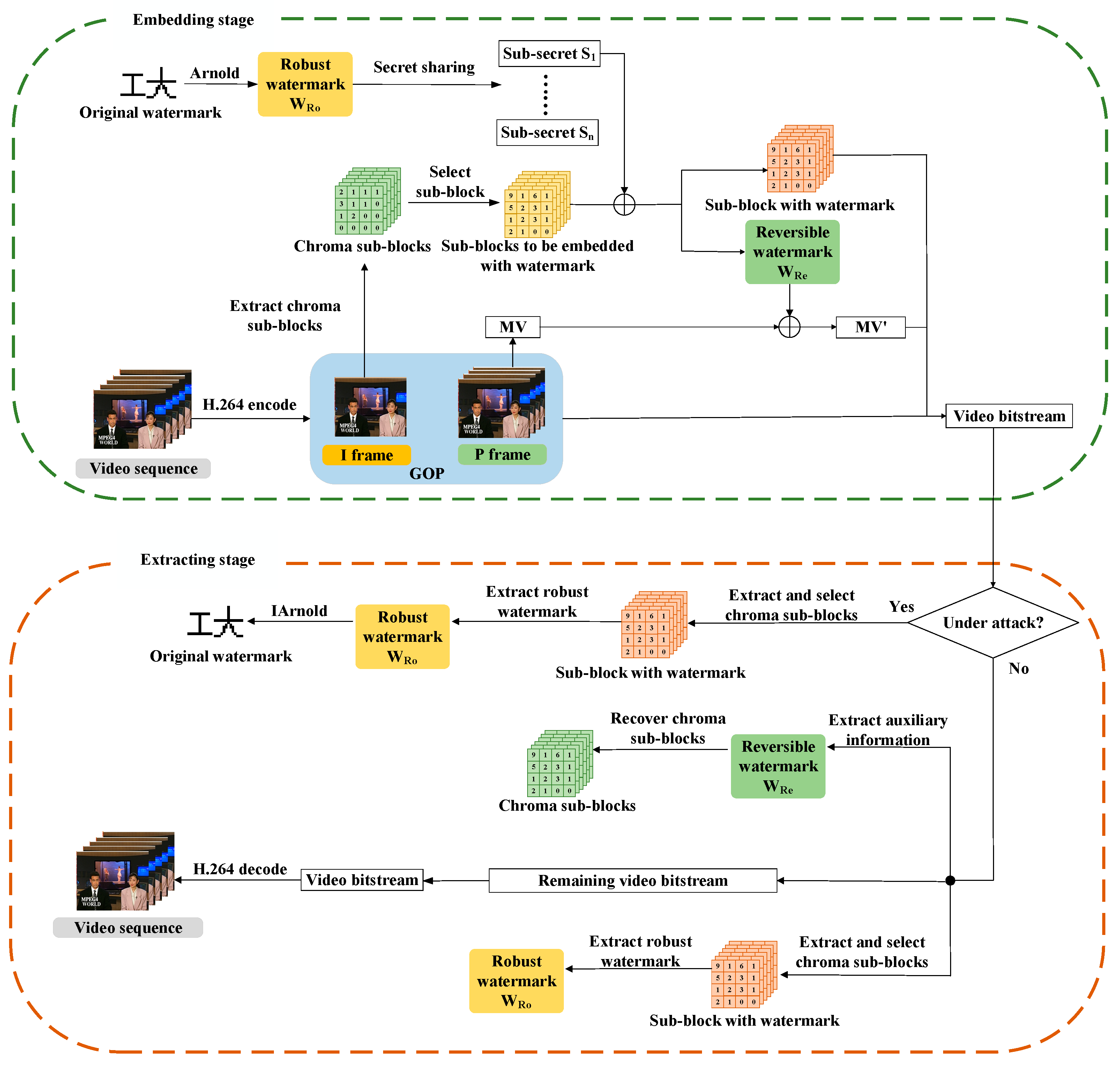
In the traditional RRW framework, both the embedding of the robust watermark and the reversible watermark utilize the same embedding domain. This results in an inevitable impact on the robustness of the scheme when embedding the reversible watermark. Additionally, embedding excessive information in the same domain significantly diminishes the visual quality of the embedding video, thereby reducing the covertness of the watermarking scheme. Furthermore, Liang et al. [18] introduced a robust and reversible video watermarking technique that relies on video multi-domain embedding. This approach considers the high-frequency and low-frequency coefficients produced during U-channel encoding of the embedded frame as distinct embedding domains, allowing for the insertion of robust and reversible watermarks, respectively. As a result, embedding these two types of watermark into separate domains minimizes interference between them during the embedding process. Compared with similar algorithms, this method has stronger robustness. Similarly, Chen et al. [23] created distinct embedding domains by separately embedding two types of watermark into I-frames and P-frames. This embedding method also demonstrates its advantages in improving watermark robustness. These findings indicate that embedding reversible watermarks into different embedding domains than robust watermarks can avoid interference caused by reversible watermark embedding on robust watermarks, thereby improving the robustness of watermarking algorithms. In addition, more effective embedding domain construction methods can be implemented to further enhance the robustness of watermarks. To address this issue, as illustrated in Figure 5, the proposed scheme embeds robust and reversible watermarking into distinct compression domains of the video. Specifically, the robust watermark is embedded in the QDCT coefficients of the chroma macro-block generated during the intra-frame prediction of the I-frame in the H.264 coding process. The auxiliary information required for macro-block recovery is losslessly compressed into a reversible watermark and embedded into the motion vectors of the subsequent P-frames of the I-frame by a reversible steganography algorithm. This method enables the robust and reversible watermark to be embedded into different compression domains of the video, ultimately enhancing the robustness of the watermark and improving the visual quality of the embedded video.
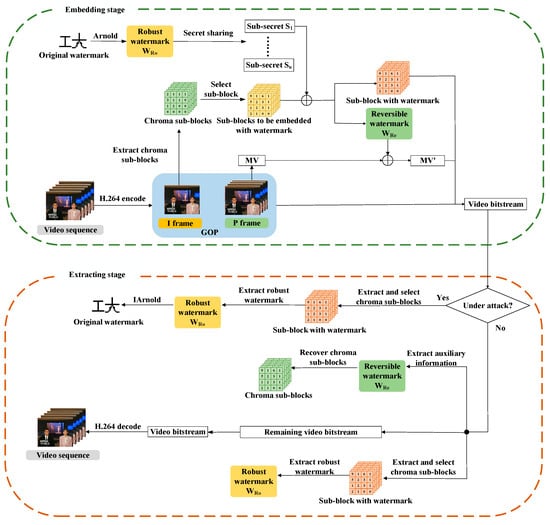
Figure 5.
Proposed watermark embedding scheme framework.
3.1. Watermark Preprocessing
The (t, n)-threshold secret sharing scheme allows a sender to decompose a secret message into n secret shares for distribution. The scheme enables the recovery of the secret message when the receiver holds at least t secret shares. The Shamir secret sharing scheme is based on the Lagrange interpolation and vector methods. For the secret , take random numbers and construct a polynomial:
is a prime number greater than . After that, take any n numbers and substitute them into the polynomial to get n sets of secret shares . In this paper, we utilize the Shamir password sharing scheme to partition the watermark into several secret shares. These shares are then embedded into different video frames to enhance the robustness of the watermarking scheme.
3.2. Embedding Location Selection
The rich bitstream information of H.264 provides researchers with a range of alternative locations for watermark embedding. Among these locations, the frequency domain coefficients generated during the coding process have better robustness than other elements and are widely used for robust watermark embedding. H.264 uses the current block pattern (CBP) parameter to determine whether and how the current residual block needs to be decoded. However, if the video suffers from a recompression attack or the embedded watermark causes a change in the DCT coefficients, the CBP value of the macro-block is likely to change, which can result in the watermarked block not being decoded correctly at the decoding side. The literature [7] suggests recompressing the video and differentiating between chrominance and luminance components. It was found that compared to the luminance component sub-block, the chrominance component sub-block has a lower probability of CBP mutation and a more stable prediction pattern. This means that the DCT coefficients of the chroma sub-block are less affected when the video is subjected to a compression attack, making it a more desirable location for robust watermark embedding. In order to improve the robustness of watermark embedding, watermarks should be embedded in areas with more complex textures in video frames, as these areas are assigned more encoding parameters compared to flat areas. This means that areas with complex textures have more redundant space when embedding watermarks and are less sensitive to compression operations, allowing watermarks to be more stably embedded in these areas [7]. Additionally, embedding information in texture-complex regions helps us find the information extraction location more accurately in the extraction watermarking ground. Because the recompression attack does not alter the visual content of each region in the video frame, this means that the video receiver can still accurately filter out regions with more complex textures in the video frame [22].
Meanwhile, according to the characteristics of the human visual system (HVS), modifying complex texture areas in the image is less noticeable compared to modifying flat background areas [20]. So, embedding watermarks in areas with complex textures can not only enhance the robustness of the watermark and help the recipient find the watermark position more accurately, but also reduce the impact of watermark embedding on video quality.
The number of non-zero coefficients (NNZs) serves as a common measure of the spatial complexity of a macro-block. It counts the total number of non-zero coefficients present within a macro-block. A higher NNZ value indicates a texture complexity region within a video frame. The energy factor () is another metric that reflects the information level of a macro-block. It is defined as follows:
where denote the coordinates of pixels in a 4 × 4 macro-block.
The literature [17] experimentally demonstrates that macro-blocks selected based on both NNZs and Ef exhibit greater robustness against requantization attacks, and introduces the texture coefficient as a metric. In this paper, we extract 4 × 4 chroma macro-blocks from frame I in the video frame sequence, calculate the of each macro-block, and select those with the highest values as the location to embed the watermark information. Compared to previous video codecs, H.264 offers a more fine-grained macro-block division and sub-pixel motion vector estimation and compensation, generating abundant vector information and providing numerous embedding locations for large-capacity reversible information hiding. In this study, we select motion vectors from several subsequent P-frames of I-frames in the video frame sequence as vectors, and compress the distortion caused to these vectors during the robust embedding stage into reversible watermarks using lossless compression techniques. These watermarks are then embedded into the motion vectors through reversible steganography.
3.3. Watermark Embedding
3.3.1. Robust Watermark Embedding
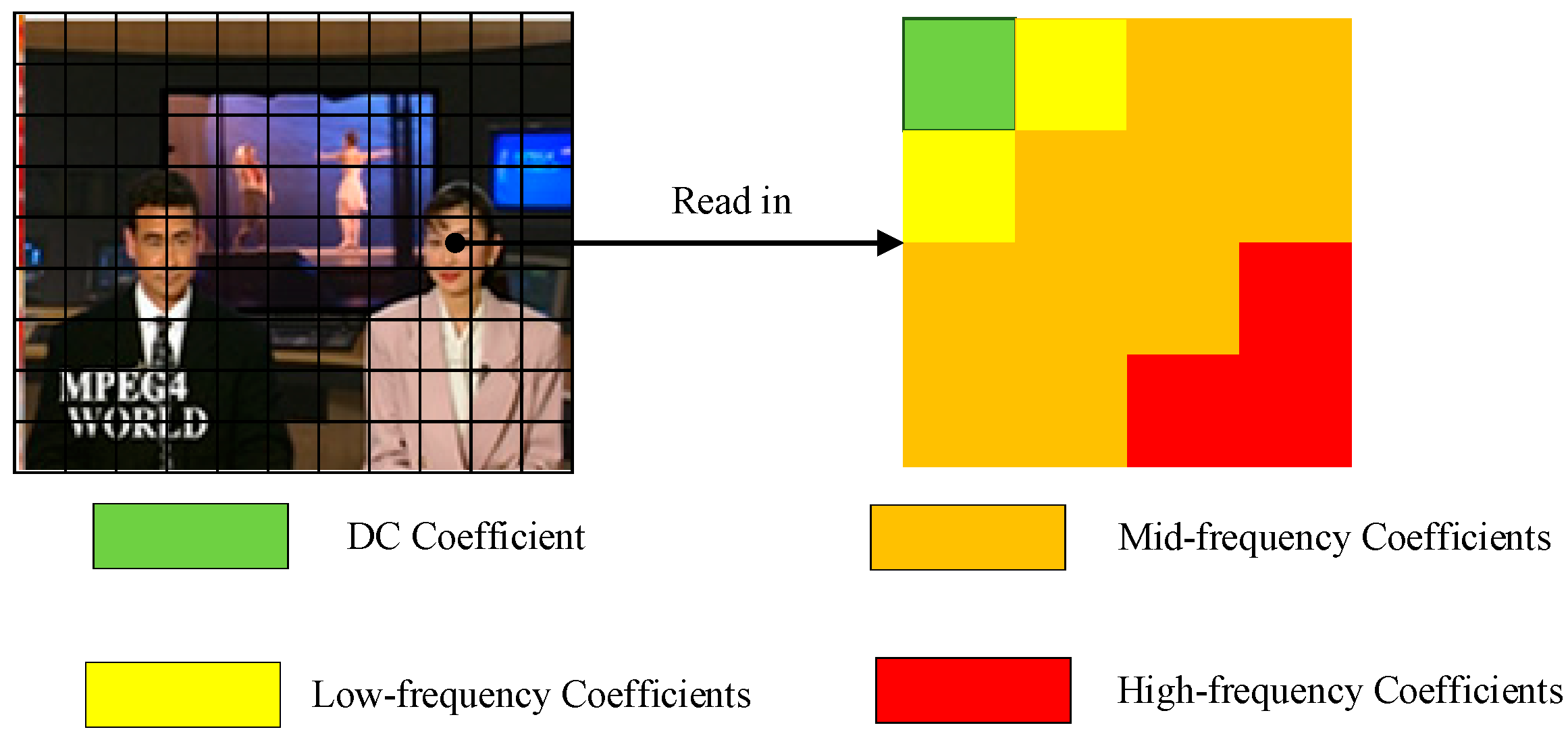
The 4 × 4 chroma macro-block generates a frequency domain coefficient matrix after DCT transformation and quantization, which contains two parts, the DC coefficients at the upper left position and the remaining AC coefficients. Among them, the DC coefficients DC carry a large amount of original image information. The DC coefficients AC, as shown in Figure 6, can be divided into low-frequency coefficients, medium-frequency coefficients, and high-frequency coefficients according to the frequency from low to high. The low-frequency coefficients carry large-scale information, which corresponds to the flat region in the image. Modification of them will have an impact on the visual quality of the video, so this part of the coefficients is not changed. As for the high-frequency coefficients in the lower right corner, they correspond to the texture detail part of the image. In order not to affect the efficiency of the subsequent entropy coding stage, this part of the coefficients is also kept unchanged. Therefore, the scheme embeds the robust watermark by modifying the mid-frequency coefficients of the chroma macro-block in the I-frame.
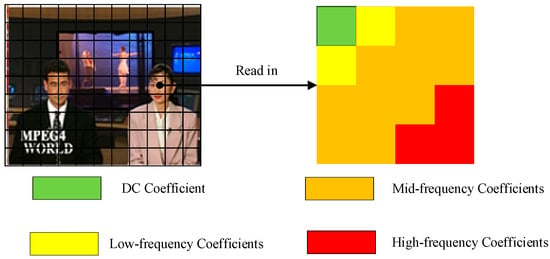
Figure 6.
Frequency distribution of coefficients after DCT transformation.
Compared to the lower coefficient blocks of NNZs, blocks with richer DCT non-zero coefficients exhibit higher robustness. However, excessive modification of zero coefficients can compromise video coding efficiency and increase the code stream volume. For the texture chroma blocks identified in Section 3.1, further differentiation is carried out to apply distinct embedding methods during watermark embedding. The coefficient blocks with NNZ > 5 in the texture chroma blocks are considered the most suitable embedding location. These coefficient blocks are grouped into robust blocks , and a strong embedding approach is taken for such coefficient blocks to embed watermarks by modifying the whole segment of mid-frequency coefficients to embed 3-bit watermark information in each robust block . On the other hand, the robustness of coefficient blocks with NNZ < 5 in the texture chromaticity block is slightly inferior, but they are still situated in the texture-rich region of the video, making watermark embedding less detectable. Thus, these coefficient blocks are grouped into texture blocks and two non-zero coefficients are selected in descending order of frequency to form coefficient pairs. Each texture block embeds 1-bit watermark information by modifying the coefficient pairs.
Furthermore, to ensure the preservation of zero coefficients and thus maintain compression efficiency, the selection process for the texture block focuses on the two non-zero mid-frequency coefficients and . These coefficients are chosen in descending order of frequency, from high to low. Subsequently, the difference between the coefficient pairs, denoted as , is calculated. Following this, 1-bit information is embedded into each coefficient pair according to the specified modulation method.
where is the embedding strength coefficient and is the watermark bit to be embedded.
To enhance the robustness of watermark embedding in the robust block , segmentation of its coefficients and embedding information in distinct segments as carriers can be effective, as suggested by [26]. The mid-frequency coefficients in are divided into three segments, denoted as . Subsequently, by modifying the coefficients within each segment as a whole, the 1-bit watermark information is embedded into that segment. The specific embedding method is presented in Equation (5), where represents the watermark information to be embedded into , and denotes the coefficient after embedding the watermark.
The modification of the coefficient fragment , denoted as , is determined by the formula , where is a pre-set threshold. For coefficient fragments that are smaller than T, both the coefficients and are set to 0.
To eliminate the distortion caused during robust watermark embedding and recover the vector in subsequent stages, the embedding strength of each coefficient pair, original difference of each coefficient pair, and the modification corresponding to each coefficient segment are recorded as auxiliary information . This auxiliary information is then converted into 0–1-bit strings using a lossless compression algorithm and embedded as a reversible watermark in the motion vectors of the subsequent P frames.
The following Algorithm 1 demonstrates the detailed steps of embedding:
| Algorithm 1: Robust embedding algorithm |
| Input: Robust watermark , original reference frame |
| Output: Embedded reference frame , auxiliary information |
Begin:
|
| The modified sub-block is passed back to the encoder to complete the encoding, generating . |
3.3.2. Reversible Watermark Embedding
Two-dimensional histogram shifting algorithms are steganographic algorithms widely used in the field of reversible steganography. They have demonstrated high embedding capacity. This class of algorithms utilizes information from the video stream itself, such as pixel values, prediction errors, motion vectors, and other elements, to construct two-dimensional value pairs. Information is embedded by establishing a mapping relationship between the information to be embedded and the modification of the value pairs at different locations. The literature [27] adapts to the characteristics of different vectors and enhances the embedding capacity by setting the centroid of the algorithm at the location that contains the highest number of vectors. However, given that the number of P-frames significantly exceeds the number of I-frames, the 2D histogram algorithm for motion vectors has been refined to improve the visual quality of the algorithm. This refinement aims to enhance visual quality while appropriately reducing embedding capacity.
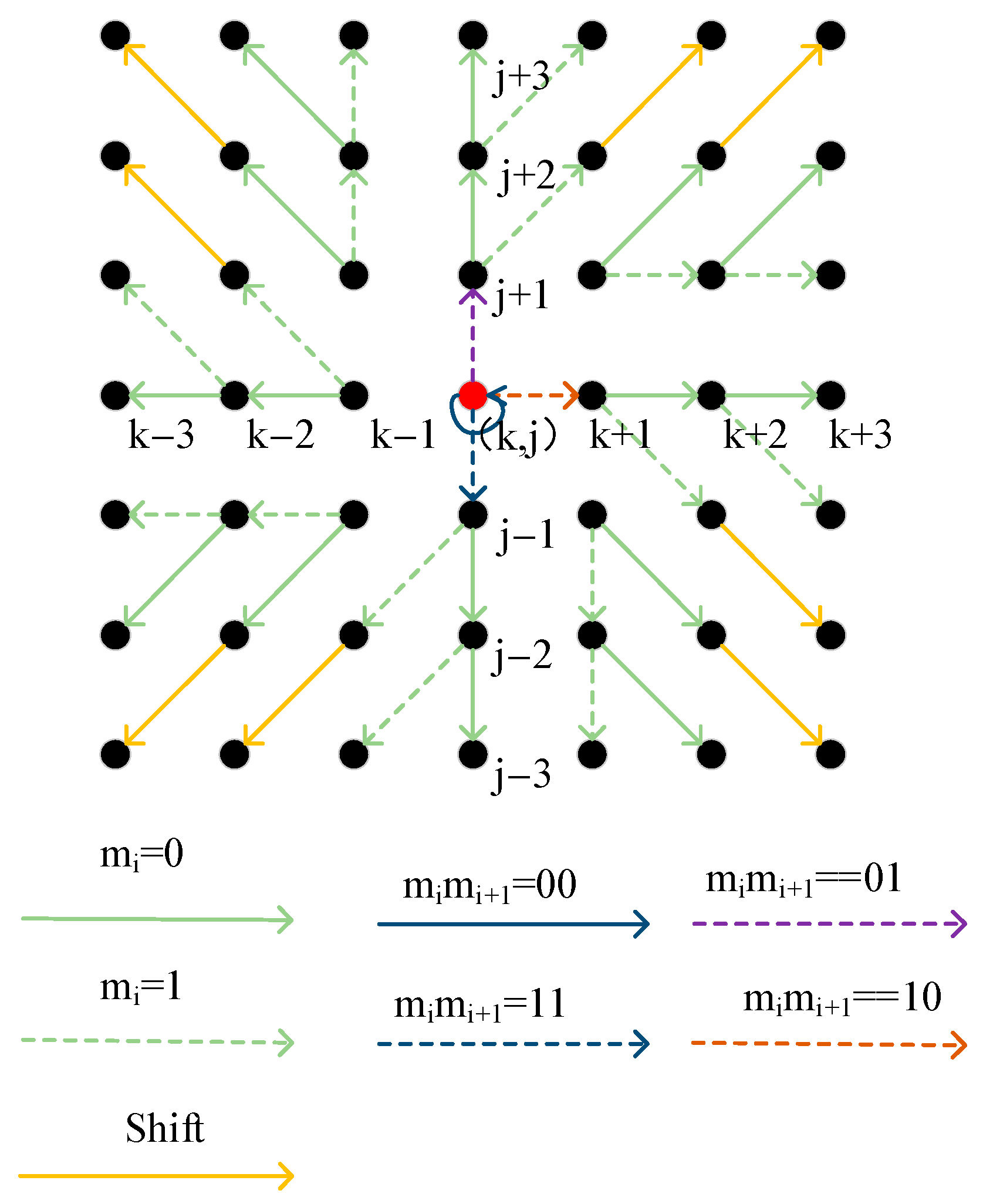
After lossless compression of auxiliary information into reversible watermark , it is embedded into the motion vector through the following reversible steganography algorithm. Firstly, the motion vectors contained in the video frame stream information are extracted. For each vector, its horizontal and vertical components are used as coordinates to construct two-dimensional value pairs, transforming the video frame vector information into a two-dimensional histogram. The vector information of the reference frame is then statistically analyzed to derive the histogram centroid . Due to the coherence between the reference frame and subsequent frames, the vector centroid of the reference frame can be used as the centroid of the subsequent embedded frames during embedding. Meanwhile, the literature [28] demonstrates that embedding watermarks at positions with larger motion amplitudes in video frames can reduce the impact of watermark embedding on the visual quality of the video. To minimize the visual impact of the watermark embedding, the embedding location is fixed in the region with large motion amplitude by retaining only the centroids with , enhancing the covertness of the watermark. Subsequently, the value pairs around the centroid are divided into 13 non-overlapping sets , and the corresponding shift operation is performed on each set to embed the information. The division of value pairs is shown in Equation (6).
When , the mapping relationship between the modification method of the value pair and the embedding information is as follows. Specifically, represents the vector component after embedding, while denotes the bit information to be embedded.
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
When , the coefficient pairs are modified as follows:
The specific modifications are shown in Figure 7.
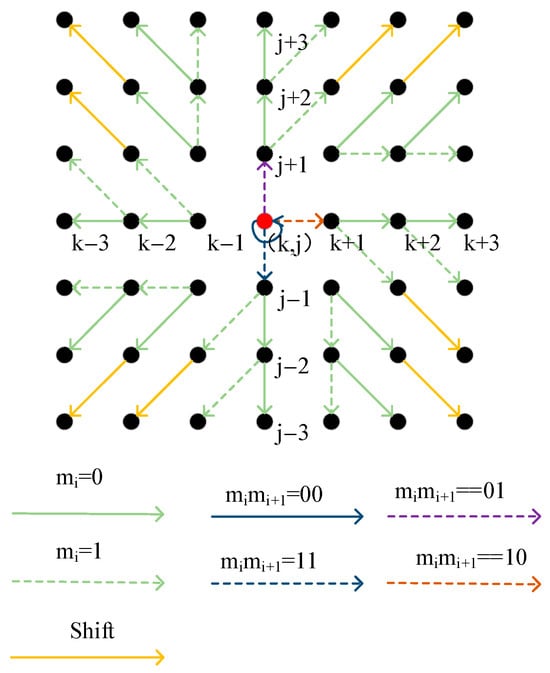
Figure 7.
Shift pattern diagram.
The following Algorithm 2 demonstrates the detailed steps of embedding:
| Algorithm 2: Reversible embedding algorithm |
| Input: Original frame , reversible watermark |
| Output: Embedded frame |
Begin:
|
| The modified motion vector is passed back to the encoder to complete the encoding, generating . |
3.4. Watermark Extraction and Original Video Recovery
After receiving the video from the sender, the receiver extracts the watermark and recovers the original video according to the following steps:
Step 1: Filter the chroma sub-blocks in the I-frame with embedded watermark and differentiate them into and based on the NNZs of the sub-blocks.
Step 2: For , two non-zero mid-frequency coefficients , are selected in the order from high frequency to low frequency, and the coefficient pairwise difference is computed. After that, the watermarked bits are extracted in the manner shown in Equation (16).
For , after segmenting the mid-frequency coefficients within the coefficient block, the watermark is extracted based on the coefficients of each segment and as shown in Equation (17).
Step 3: Furthermore, the motion vector information of the P-frame is transformed into a 2D histogram based on the vector centroids of the reference frame obtained from the statistical analysis. The vector–value pairs are then classified into distinct sets according to the rules outlined in Section 3.3. Utilizing the mapping relationship between these vector–value pairs and the embedding modes, the embedded auxiliary information is extracted to obtain , and .
Step 4: The steganography algorithm used in Section 3.4 is reversible; i.e., for each vector–value pair of points of the 2D histogram, the points have an incidence of 1. Therefore, a shift operation is performed at extraction time as opposed to embedding time to restore the position of each vector–value pair, and thus the motion vectors of the P-frame are recovered.
Step 5: The chroma sub-block coefficients in the I-frame are restored based on the obtained watermark information and auxiliary information.
For , as shown in Equation (18), the coefficients are calculated from and :
For , as shown in Equations (19) and (20), is computed from , and :
After these steps, the receiver can recover the original video with the watermark extracted.
The following Algorithm 3 demonstrates the detailed steps for extracting and recovering original video :
| Algorithm 3: Watermark extraction and original video recovery algorithm |
| Input: Embedded reference frame , embedded frame |
| Output: Robust watermark , original video |
Begin:
|
| With the above steps, we can get . The recovered sub-blocks and are passed back to the decoder to get the original video . |
4. Experimental Results and Analysis
Furthermore, to verify the actual performance of the algorithm, this paper relies on the Visual Studio 2022 and MATLAB 2021a platforms. The H.264/AVC test model JM8.6 was utilized to implement the video codec. The experimental subjects consist of five common standard QCIF format test videos (Carphone, Foreman, Hall, Mobile, News) and one CIF format test video (Stefan). The QCIF format videos contain 150 frames, while the CIF format video comprises 90 frames. The specific encoding parameters are detailed in Table 1.

Table 1.
Encoder parameter configuration.
4.1. Invisibility Experiment
4.1.1. Subjective Invisibility Experiment
Based on the characteristics of the human visual system, the spatial resolution of the human eye for chromaticity signals is inferior to that of luminance signals. Additionally, compared to flat background areas, changes in detailed textures are less likely to be noticed by the human eye. The scheme in this paper embeds watermark information into the chromaticity component of the video carrier, while simultaneously selecting macro-blocks with high spatial complexity as the embedding location. This method enhances the imperceptibility of the watermarking algorithm. The effect before and after embedding is illustrated in Figure 8. Subjective observations reveal no obvious artifacts or distortions in the corresponding frames of the watermarked video, indicating that the embedding of the watermark does not significantly reduce the visual quality of the video.

Figure 8.
Subjective visual representation of watermarked video (Carphone, Foreman, Hall, Mobile, News, Stefan). (a) Original video frame; (b) corresponding video frame after embedding watermark.
4.1.2. Objective Invisibility Experiment
To assess the impact of watermark embedding on the visual quality of video, this paper adopts two widely recognized indicators: peak signal to noise ratio (PSNR) and structural similarity (SSIM). These criteria are employed to evaluate and compare the visual quality of the watermarked videos with those reported in the literature [16,17]. PSNR, measured in dB, quantifies the pixel difference between the original image and the embedded watermarked image. A higher PSNR value indicates a smaller loss of image quality. SSIM, ranging from −1 to +1, evaluates the quality of the image based on brightness, contrast, and structure. An SSIM value closer to 1 signifies that the two images are more similar. The calculation of SSIM is presented in Equation (21).
where and are the mean of the two images, and represent the standard deviation of the two images, is the covariance of the two images, and , are constants.
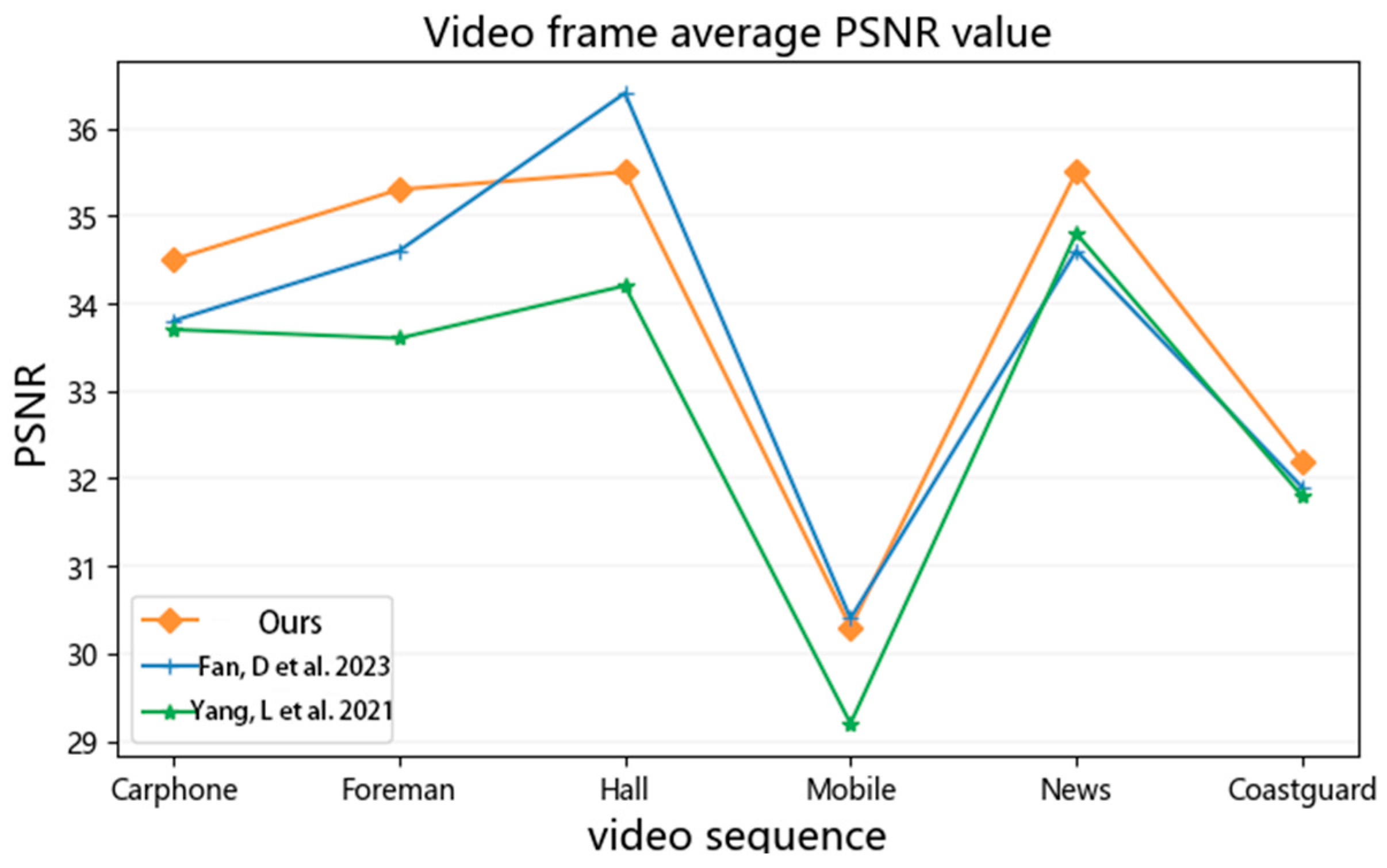
Figure 9 displays the comparison of the average PSNR values of the video frame sequences after embedding the watermarking information on the six test videos. As can be observed from Figure 9, the average PSNR values achieved by the algorithm proposed in this paper on the six test videos are all above 29, indicating that the videos after embedding the watermark have achieved a relatively good visual quality.
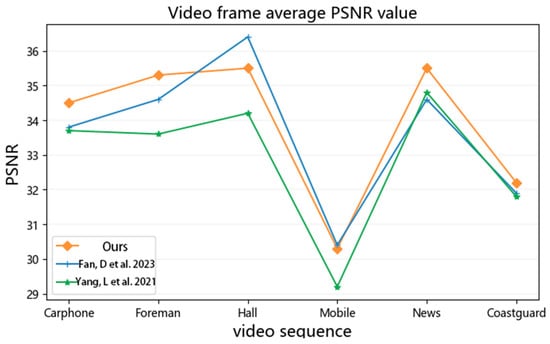
Figure 9.
Objective visual quality of watermarked video [16,17].
Table 2 compares the algorithm proposed in this paper with similar algorithms in the literature [16,17], using the change value of SSIM before and after video embedding as a measure. From the table, it can be seen that the invisibility of the algorithm proposed in this paper is basically kept on par with similar algorithms. However, considering that the other two algorithms only embedded robust watermarks and did not embed auxiliary information, the total information embedded is lower than the present algorithm. Therefore, the algorithm proposed in this paper still has a certain advantage in visual quality.
Table 2.
Decrease in SSIM values after embedding watermarks.
4.2. Anti-Recompression Test
Recompression attacks are one of the primary attacks encountered during video file transmission. In the experimental session, the test video was compressed multiple times using the same initial quantization parameters. To evaluate the robustness of the algorithm, bit error rate (BER) and normalized correlation coefficient (NC) were introduced as evaluation metrics. NC and BER are calculated as follows:
where represents the original watermark, represents the extracted watermark, and represents the size of the watermark. The value of the NC ranges from −1 to 1. A higher value of NC indicates a stronger correlation between the extracted watermark and the original watermark, which suggests that the algorithm’s robustness is stronger. The BER reflects the watermark extraction accuracy. In the formula, represents the heteroscedastic computation, when the BER is closer to 0; that is, when the extracted watermark has a high accuracy, indicating that the algorithm has a strong robustness.
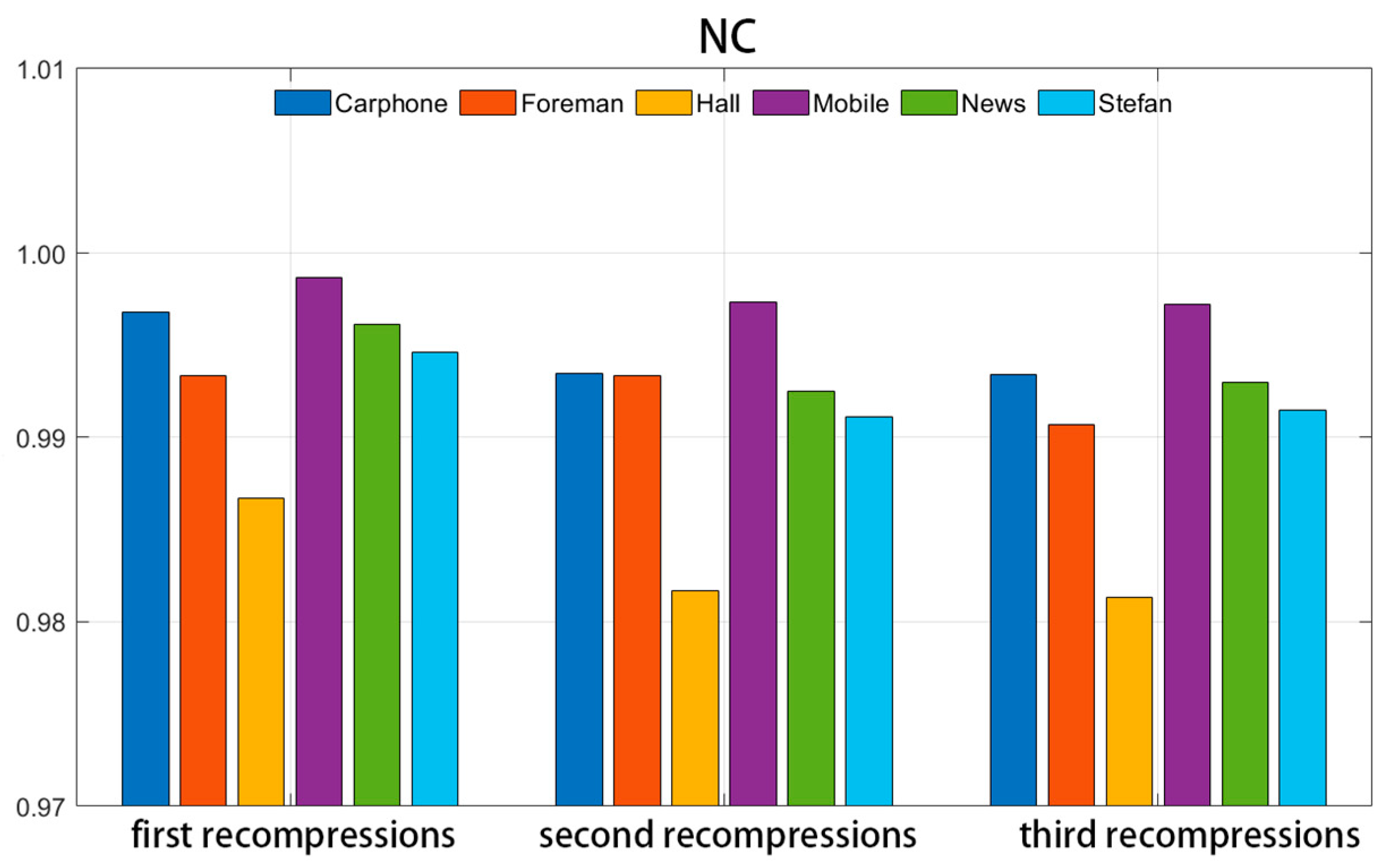
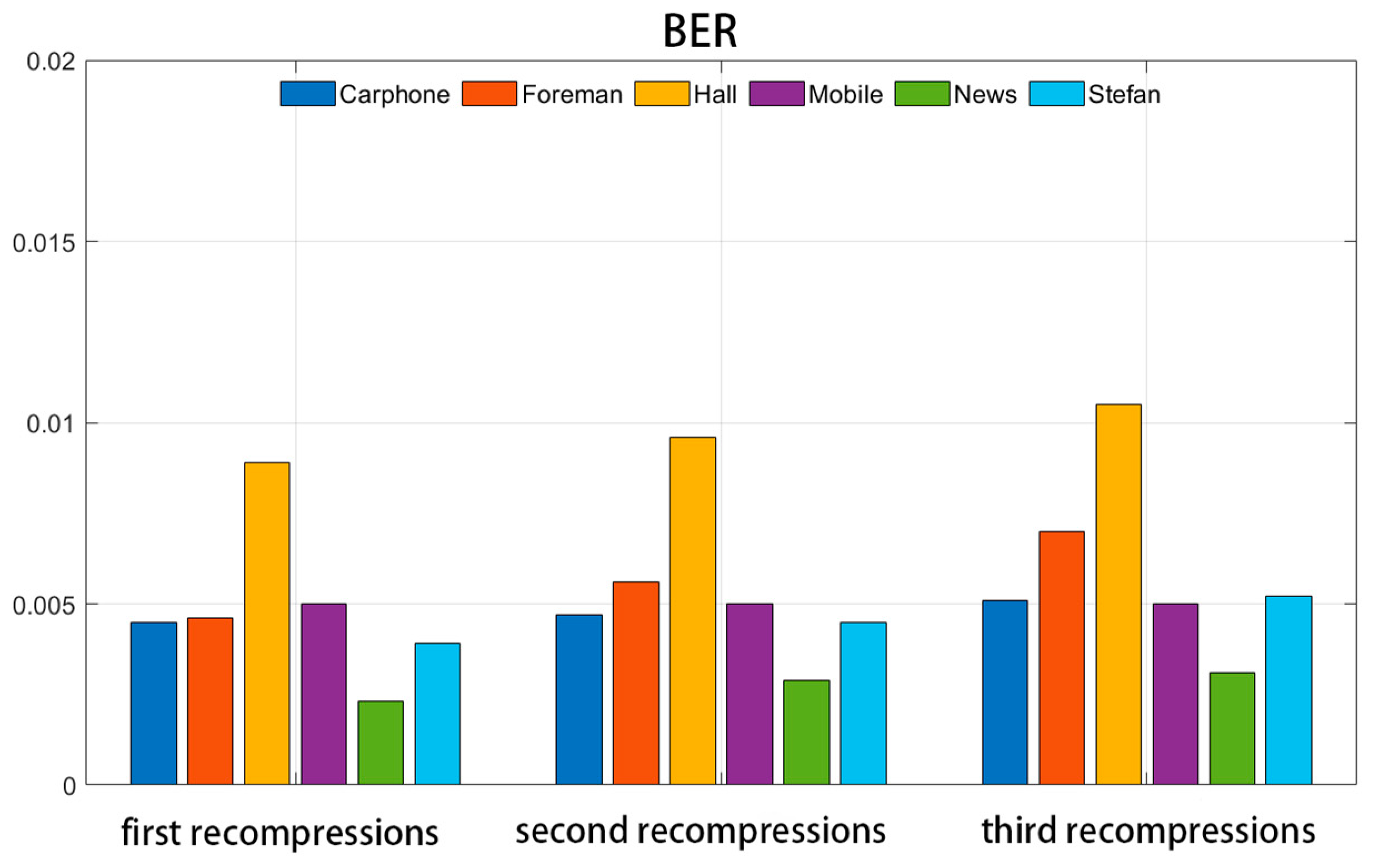
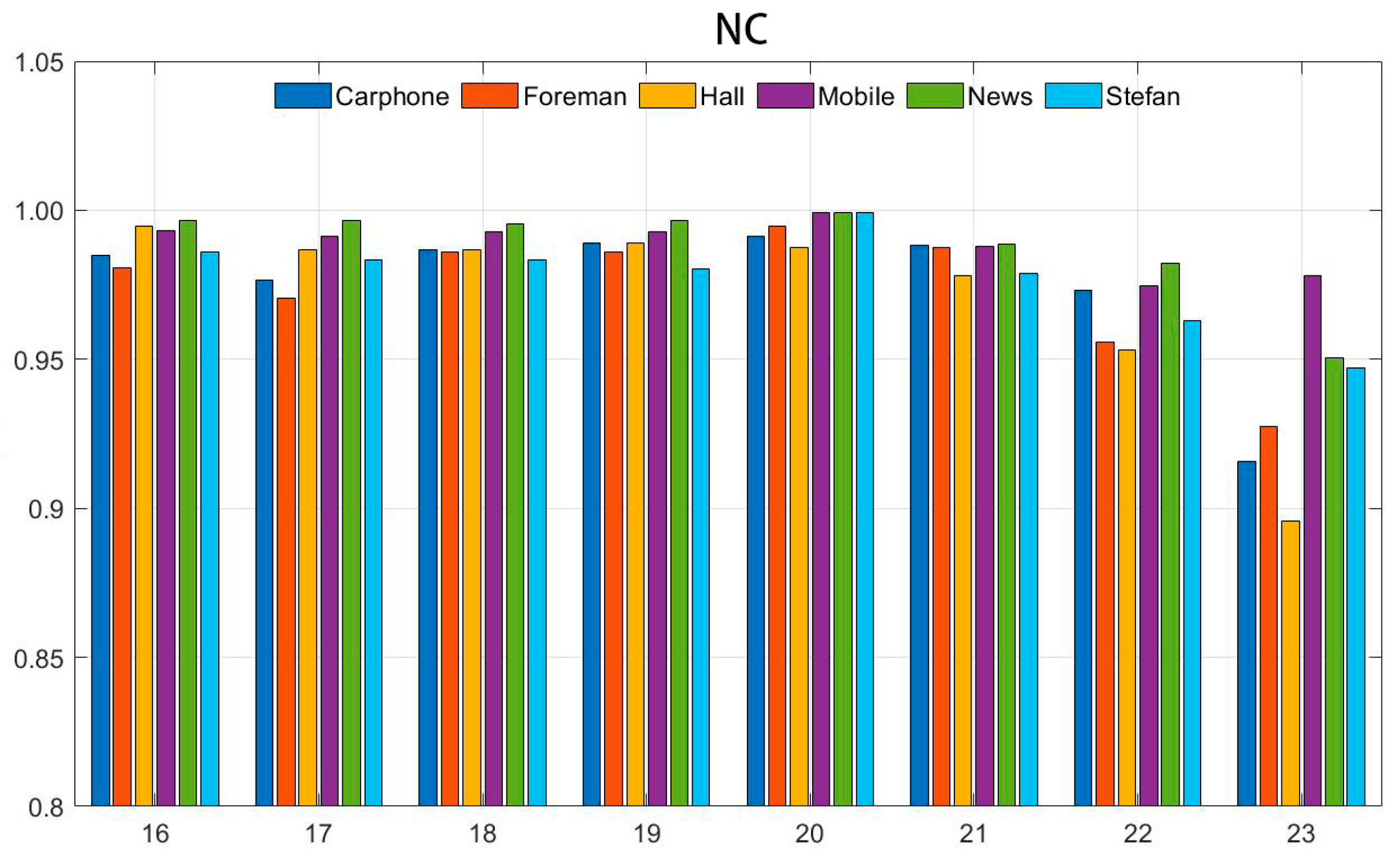
Figure 10 and Figure 11 illustrate the NC and BER values of the watermark information following each compression cycle, where the video was compressed three times consecutively using the same initial quantization parameter (QP = 20).
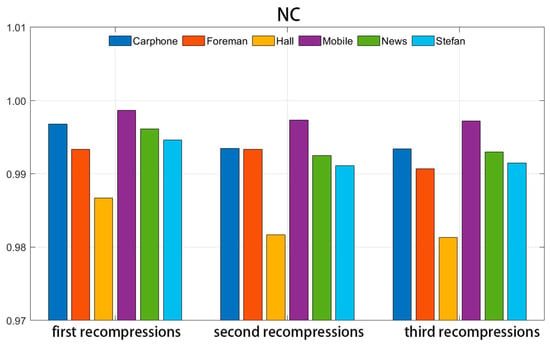
Figure 10.
NC values under recompression attack.
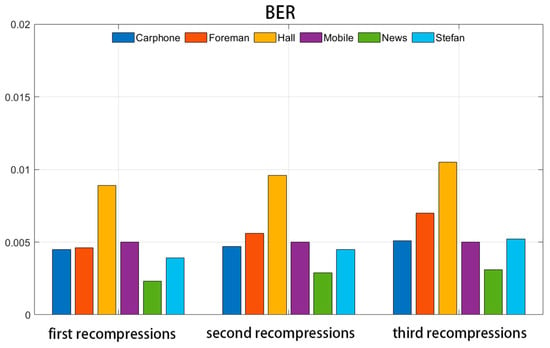
Figure 11.
BER values under recompression attack.
Upon examination of the figures, it becomes evident that after three compressions, the NC value of the extracted watermark experiences a slight decrease, while the BER value shows a minor increase. This indicates that the repeated compression of the video carrier has a discernible impact on the watermark information. However, despite the three compression cycles, the majority of the mean NC values of the extracted watermark remain above 0.99, and the mean BER values are generally maintained below 0.01. This suggests that the algorithm can still accurately extract the watermark information after numerous repetitive compressions, demonstrating the strong robustness of the watermarking algorithm.
Table 3 and Table 4 present the results of the proposed scheme in this paper, comparing it to the algorithms in the literature [17,22], respectively, in terms of resistance to recompression attacks. After three compression cycles, the average NC value of the watermark extracted by the algorithm presented in this paper across six videos is 0.99, which surpasses the 0.98 achieved by the algorithm in the literature [17] and the 0.92 achieved by the algorithm in the literature [22]. The algorithm in the literature [17] embeds watermark information by utilizing the third quantization coefficients of the chroma sub-block in the modulation of I-frames. Conversely, the algorithm proposed in this paper embeds 1-bit watermarks by segmenting the mid-frequency coefficients of the chroma sub-block and utilizing a segment of these coefficients as the carrier. This approach, compared to using a single coefficient as the carrier in the literature [17], results in the entire segment of coefficients being less susceptible to distortion during video recompression operations. The literature [22] embeds watermark information into the last P-frame of a set of GOPs by altering the positive and negative signs of the first AC coefficients of the QDCT of the candidate block. While embedding the watermark into the last frame of the GOP helps to minimize the visual impact of watermark embedding, the coding of P-frames relies on preceding I-frames and P-frames within the GOP. Therefore, when the video carrier is recompressed, variations in the coefficients of the preceding frames can affect the coding of the last frame, ultimately impacting the watermark information. From Table 3 and Table 4, it can be seen that the algorithm proposed in this paper is more robust against recompression compared to the other two algorithms.
Table 3.
Comparison of the NC and BER values between the scheme in this paper and the algorithm in [17].
Table 4.
Comparison of the NC and BER values between the scheme in this paper and the algorithm in [22].
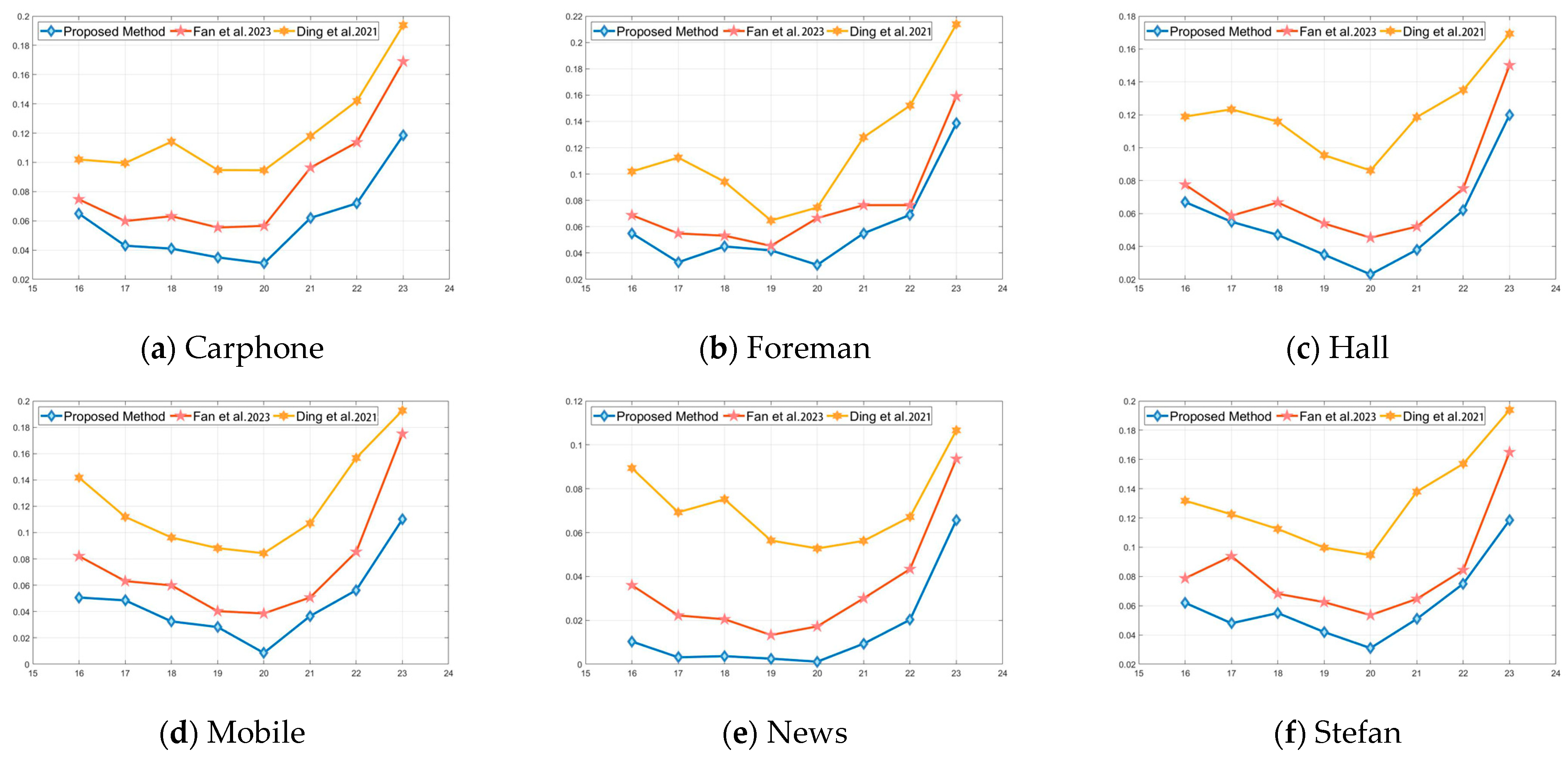
4.3. Anti-Requantization Test
When watermark-containing videos are transmitted on network platforms, attackers may manipulate the step size of video compression by adjusting the quantization parameter to remove the file watermark. Thus, it is imperative to investigate the robustness of watermarked videos against recompression attacks with varying quantization parameters. The original quantization parameter of the video was set to 20. To evaluate the robustness of the algorithm under different quantization parameter attacks, the quantization parameter was incrementally adjusted from 16 to 23, and the accuracy of watermark extraction was tested. Figure 12 illustrates the variation of the NC value of the watermark extracted from the watermark-containing video under various quantization parameter attacks.
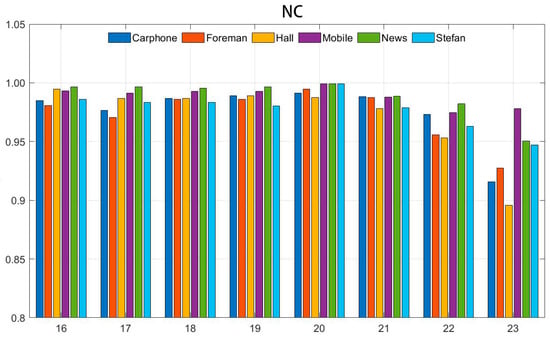
Figure 12.
NC values under attacks with different quantization parameters.
Figure 13 illustrates that adjusting the quantization parameter, whether by increasing or decreasing it, impacts the accurate extraction of the watermark in comparison to the original quantization parameter. Notably, an increase in the quantization parameter has a more significant effect on the watermark. This is likely due to the fact that as the quantization parameter increases, more QDCT coefficients become zero, resulting in the loss of watermark information and preventing accurate extraction. Despite this, the figure indicates that even when the quantization parameter reaches 23, the NC value of the extracted watermark in the six test videos remains above 0.88. This demonstrates that the algorithm exhibits robustness against quantization parameter attacks. This robustness may be attributed to the algorithm’s filtering of chroma sub-blocks through parameter settings, as the selected sub-blocks are less sensitive to changes in quantization parameters compared to other sub-blocks. Furthermore, when the global QDCT coefficients change, the distribution of the QDCT coefficients remains relatively stable, indicating that the texture information of the video itself does not change with the alteration of QDCT coefficients. Thus, the method demonstrates better robustness against attacks with different quantization parameters.
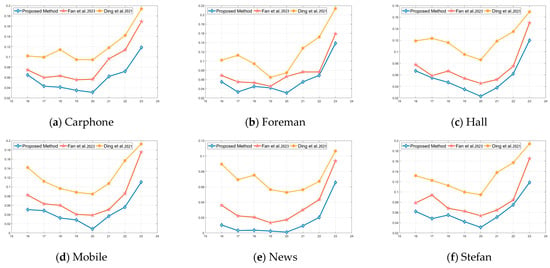
Figure 13.
Comparison of the BER values between the proposed scheme and the algorithms in the literature [17,22] under requantization attacks with different QP values.
The BER values of the proposed scheme, as well as two other video watermarking algorithms, under requantization attack with varying QP values are presented in Figure 13a–f. This figure demonstrates that the proposed scheme exhibits significant advantages in resisting requantization attacks. Specifically, the growth of BER values is effectively suppressed across the videos.
4.4. Bit Increase Rate Test
Embedding a watermark into a video results in an increase in the size of the video file. To prevent attackers from noticing the excessive volume of the watermarked video and to minimize the consumption of storage and network resources, the watermarking algorithm should minimize the impact of watermark embedding on the size of the carrier file. Table 5 illustrates the bit rate growth of the six test videos after embedding the watermark using the watermarking method proposed in this paper.
Table 5.
Experimental results of bit increase rate after watermark embedding.
The table indicates that the volume of each video file has increased to varying degrees due to the embedded watermark information. Additionally, apart from the impact of watermark embedding, the algorithm presented in this paper employs the reference frame transformation technique to modify the reference structure of the original video frame sequence. This modification mitigates error propagation and increases the interval between the reference frame and the coded frame, ultimately leading to a certain increase in the video bit rate.
4.5. Complexity Experiment
The coding and decoding time of videos containing watermarks can visually indicate the complexity of the algorithm. In certain application scenarios, such as webcasting and video conferencing, it is essential to keep the algorithm’s complexity low to ensure that real-time communication is not affected. Table 6 presents the time required for coding and decoding six videos using the method proposed in this paper.
Table 6.
Impact of watermark embedding on video coding and decoding time consumption.
Table 6 indicates that the growth rate of the elapsed encoding time for the algorithm proposed in this paper is generally lower than 3.12%, while the growth rate of the elapsed decoding time is generally lower than 2.9%. Furthermore, the growth of the coding and decoding time is relatively small, indicating that the algorithm’s complexity is not high and can be adapted to the requirements of most real-time application scenarios.
4.6. Reversibility Experiment
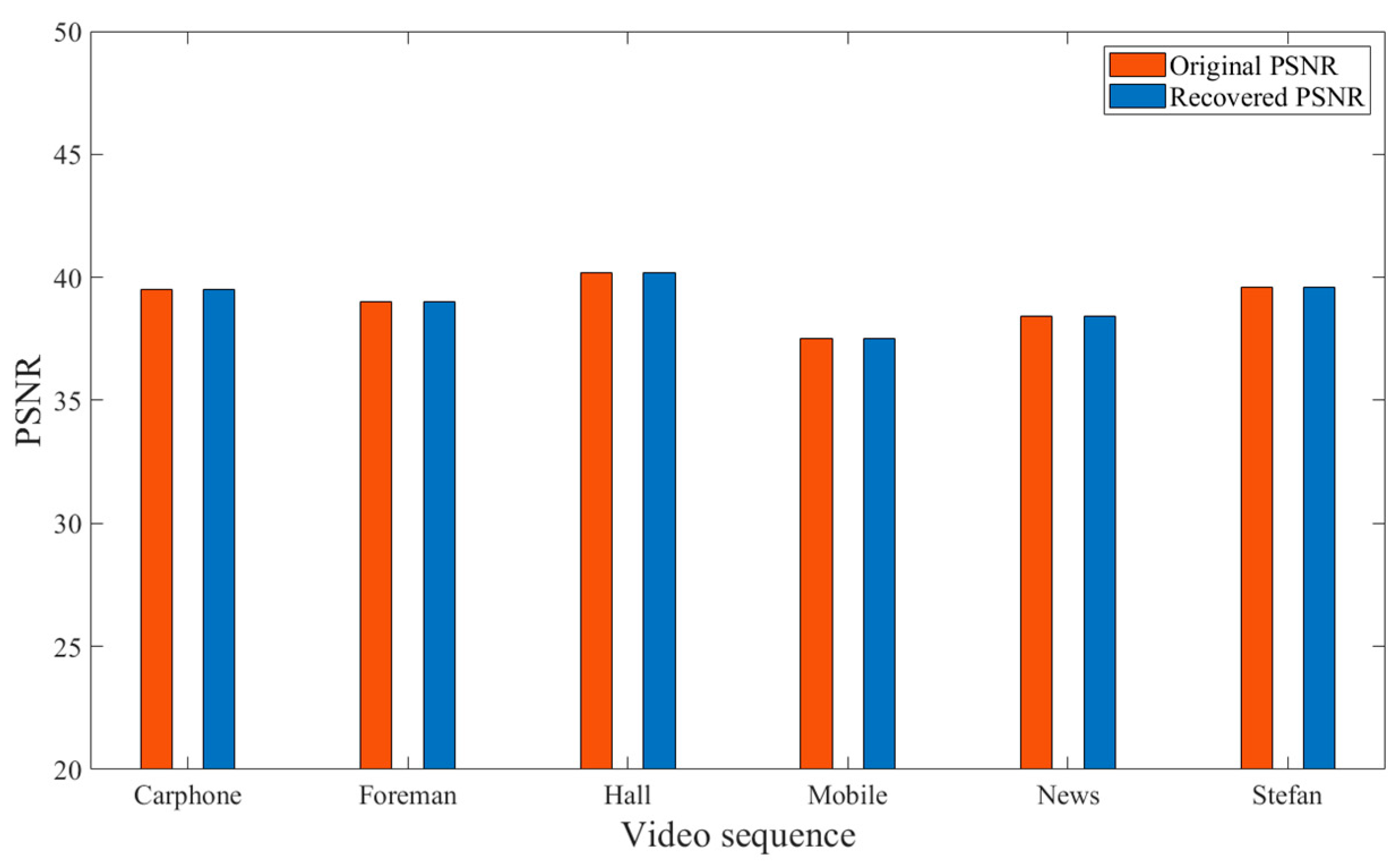
The robust reversible watermarking algorithm proposed in this paper embeds auxiliary information within the motion vectors of P-frames. This auxiliary information enables the recovery of DCT coefficients that were previously altered due to the embedded watermark. Additionally, the reversible steganography algorithm employed for embedding the auxiliary information within the motion vectors can restore the motion vectors upon information extraction, ultimately facilitating the complete recovery of the original video.
Figure 14 illustrates the PSNR values of the original video and the recovered video. As evident from Figure 14, the PSNR value of the final recovered video, after information embedding and extraction, remains largely consistent with the original video. This indicates that the scheme proposed in this paper can effectively restore the video to its original state, confirming the reversibility of the proposed scheme.
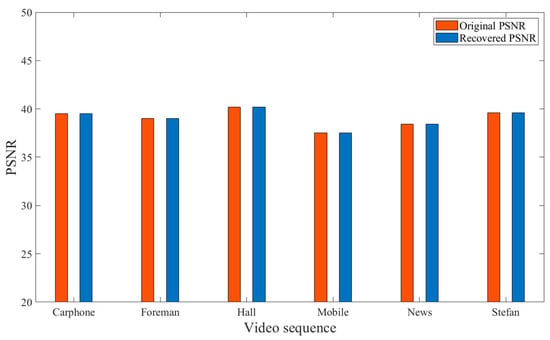
Figure 14.
PSNR comparison between recovered video and original video.
5. Conclusions
In this paper, we propose a robust reversible watermarking scheme based on multilayer embedding in the video compression domain. This scheme enhances the robustness and invisibility of the scheme by embedding robust and reversible watermarks in different compression domains of the video. Specifically, the watermarking information is split into several sub-secrets using a secret sharing technique and then embedded into the DCT coefficients of the I-frames of each GOP. Subsequently, the auxiliary information required to recover these coefficients is embedded into the motion vectors of the P-frames within the GOPs through reversible steganography. The experimental results demonstrate that our proposed scheme exhibits superior robustness against recompression and requantization attacks compared to similar algorithms, while also ensuring high visual quality. The reversibility test section reveals that this scheme can restore the video to its original state using the extracted auxiliary information even when under attack. In comparison to existing video watermarking schemes, our approach achieves both robustness and reversibility, making it suitable for a wider range of application scenarios.
Furthermore, it is important to acknowledge that the watermarking scheme proposed in this article results in bit increase in the video. This bit increase may be attributed to the utilization of the Reference Frame Conversion Technique. Not only does this technology intercept error propagation, but it also leads to an increase in video bit rate. Additionally, during the robust watermarking embedding stage, employing a strong embedding approach for certain coefficient blocks can result in excessive embedding strength, further contributing to video bit increase. Such abnormal changes in video may draw the attention of potential attackers.
In light of these findings, future work will focus on exploring the setting of appropriate reference frame intervals and adaptively adjusting the embedding strength of watermarking based on the unique characteristics of different video frames. These efforts aim to reduce the bit increase caused by watermark embedding and enhance the security of the watermarking scheme.
Author Contributions
Conceptualization: Y.M., K.N.; experimental operation and data proofreading: Y.M., Y.Z.; analysis and interpretation of results: Y.M., K.N., Y.Z.; draft manuscript preparation: Y.M., Y.L.; figure design and drawing: Y.L., K.N., F.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under grants 62202496 and 62272478, and the Basic Frontier Innovation Project of Engineering university of People Armed Police under grants WJY202314 and WJY202221.
Data Availability Statement
The data supporting the findings of this study are available upon request from the corresponding author, Ke Niu. The data are not publicly available due to confidential agreements.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mareen, H.; Courteaux, M.; Praeter, J.D.; Asikuzzaman, M.; Wallendael, G.V.; Pickering, M.R.; Lambert, P. Camcording-resistant forensic watermarking fallback system using secondary watermark signal. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3403–3416. [Google Scholar] [CrossRef]
- Wang, Y.F.; Zhou, Y.M.; Qian, Z.X.; Li, S.; Zhang, X.P. Review of robust video watermarking. J. Image Graph. 2022, 27, 27–42. [Google Scholar]
- Di, F.; Sun, W.; Zhao, H.; Kang, W. Audio and video matching zero-watermarking algorithm based on NSCT. Complexity 2022, 3445583. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, J.; Huang, H.; Chen, Q. Research on scalable video watermarking algorithm based on H.264 compressed domain. Optik 2021, 227, 165911. [Google Scholar] [CrossRef]
- Sun, J.; Jiang, X.; Liu, J.; Zhang, F.; Li, C. An anti-Recompression video watermarking algorithm in bitstream domain. Tsinghua Sci. Technol. 2021, 26, 22–30. [Google Scholar] [CrossRef]
- Coltuc, D.; Chassery, J. Distortion-free robust watermarking: A case study. In Security, Steganography, and Watermarking of Multimedia Contents IX, 65051N, Proceedings of the Electronic Imaging 2007, San Jose, CA, USA, 28 January–1 February 2007; SPIE: Bellingham, DC, USA, 2007; Volume 6505, p. 6505. [Google Scholar]
- Tian, L.; Dai, H.; Li, C. A semi-fragile video watermarking algorithm based on chromatic Residual DCT. Multimed. Tools Appl. 2020, 79, 1759–1779. [Google Scholar] [CrossRef]
- Nguyen, T.S. Reversible Data Hiding Scheme Based on Coefficient Pair Mapping for Videos H. 264/AVC without Distortion Drift. Symmetry 2022, 14, 1768. [Google Scholar] [CrossRef]
- Shoitan, R.; Moussa, M.M.; Elshoura, S.M. A Robust Video Watermarking Scheme Based on Laplacian Pyramid, SVD, and DWT with Improved Robustness towards Geometric Attacks via SURF. Multimed. Tools Appl. 2020, 79, 26837–26860. [Google Scholar] [CrossRef]
- Huan, W.; Li, S.; Qian, Z.; Zhang, X. Exploring Stable Coefficients on Joint Sub-Bands for Robust Video Watermarking in DT CWT Domain. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1955–1965. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, S.; Liu, J.; Xiong, P.; Zhou, M. A discrete wavelet transform and singular value decomposition-based digital video watermark method. Appl. Math. Model. 2020, 85, 273–293. [Google Scholar] [CrossRef]
- Manjunath, K.K.; Kunte, R.S. A Robust Reversible Data Hiding Framework for Video Steganography Applications. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 430–441. [Google Scholar]
- Suresh, M.; Sam, I.S. Optimized interesting region identification for video steganography using Fractional Grey Wolf Optimization along with multi-objective cost function. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 3489–3496. [Google Scholar] [CrossRef]
- Suresh, M.; Sam, I.S. Optimized interesting region identification for video steganography using multi-objective cost function. Multimed. Tools Appl. 2023, 82, 31373–31396. [Google Scholar] [CrossRef]
- Dhall, S.; Gupta, S. Multilayered Highly Secure Authentic Watermarking Mechanism for Medical Applications. Multimed. Tools Appl. 2021, 80, 18069–18105. [Google Scholar] [CrossRef]
- Yang, L.; Wang, H.; Zhang, Y.; Li, J.; He, P.; Meng, S. A Robust DCT-Based Video Watermarking Scheme Against Recompression and Synchronization Attacks. In Digital Forensics and Watermarking, Proceedings of the IWDW 2021, Beijing, China, 20–22 November 2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Fan, D.; Zhao, H.; Zhang, C.; Liu, H.; Wang, X. Anti-Recompression video watermarking algorithm based on H.264/AVC. Mathematics 2023, 11, 2913. [Google Scholar] [CrossRef]
- Liang, Y.; Niu, K.; Zhang, Y.; Meng, Y. A dual domain robust reversible watermarking algorithm for frame grouping videos using scene smoothness. CMC-Comput Mater. Contin. 2024, 79, 5143–5174. [Google Scholar] [CrossRef]
- Tao, X.; Xiong, L.; Zhang, X. Robust video watermarking scheme based on QDCT global equalization strategy. Comput. Sci. 2023, 50, 168–176. [Google Scholar]
- Wang, Y.; Huang, J.; Chen, Y.; Zhang, J.; Chen, X. Algorithm for H.264/AVC adaptive watermarking. J. Xidian Univ. 2023, 50, 95–104. [Google Scholar]
- Zhu, B.; Fan, X.; Zhang, T.; Zhou, X. Robust Blind Image Watermarking Using Coefficient Differences of Medium Frequency between Inter-Blocks. Electronics 2023, 12, 4117. [Google Scholar] [CrossRef]
- Ding, H.; Tao, R.; Sun, J.; Liu, J.; Zhang, F.; Jiang, X.; Li, J. A compressed-domain robust video watermarking against recompression attack. IEEE Access 2021, 9, 35324–35337. [Google Scholar] [CrossRef]
- Chen, P.; Zhang, Z.; Lei, Y.; Niu, K.; Yang, X. A Multi-Domain Embedding Framework for Robust Reversible Data Hiding Scheme in Encrypted Videos. Electronics 2022, 11, 2552. [Google Scholar] [CrossRef]
- Chan, K.; Im, S.K. Using Four Hypothesis Probability Estimators for CABAC in Versatile Video Coding. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 19, 1–17. [Google Scholar] [CrossRef]
- Wang, X.; Li, X.; Pei, Q. Independent Embedding Domain Based Two-Stage Robust Reversible Watermarking. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2406–2417. [Google Scholar] [CrossRef]
- Li, Q.; Wang, X.; Pei, Q. Compression Domain Reversible Robust Watermarking Based on Multilayer Embedding. Secur. Commun. Netw. 2022, 1, 4542705. [Google Scholar] [CrossRef]
- Qiu, F.; Niu, K.; Zhao, H.; Ning, Z. Reversible Steganography Algorithm for High Capacity Video Based on Motion Vector Multi Histogram Correction. In Proceedings of the CAIBDA 2022, 2nd International Conference on Artificial Intelligence, Big Data and Algorithms, Nanjing, China, 17–19 June 2022. [Google Scholar]
- Meng, Y.; Niu, K.; Liang, Y.; Shi, L.; Zhang, Y. Reversible Video Information Hiding Based on Multi-pass Motion Vector Ordering. J. Inf. Secur. Res. 2024, 10, 698–705. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).