Dual-Stream Feature Collaboration Perception Network for Salient Object Detection in Remote Sensing Images


Abstract
1. Introduction
- (1)
- We develop a Dual-Stream Feature Collaboration Perception Network (DCPNet) that coordinates Transformer and CNN to model global relationships and capture local fine-grained representations.
- (2)
- We propose a Multi-path Complementary-aware Interaction Module (MCIM) to fully leverage the local bias of CNN and the long-range dependency characteristics of Transformer, thereby achieving complementation between global information and local details.
- (3)
- We propose a Feature Weighting Balance Module (FWBM) to balance global and local features, preventing the model from overly focusing on global information at the expense of local details, or overly focusing on local information at the expense of overall understanding of images.
2. Materials and Methods
2.1. Network Overview
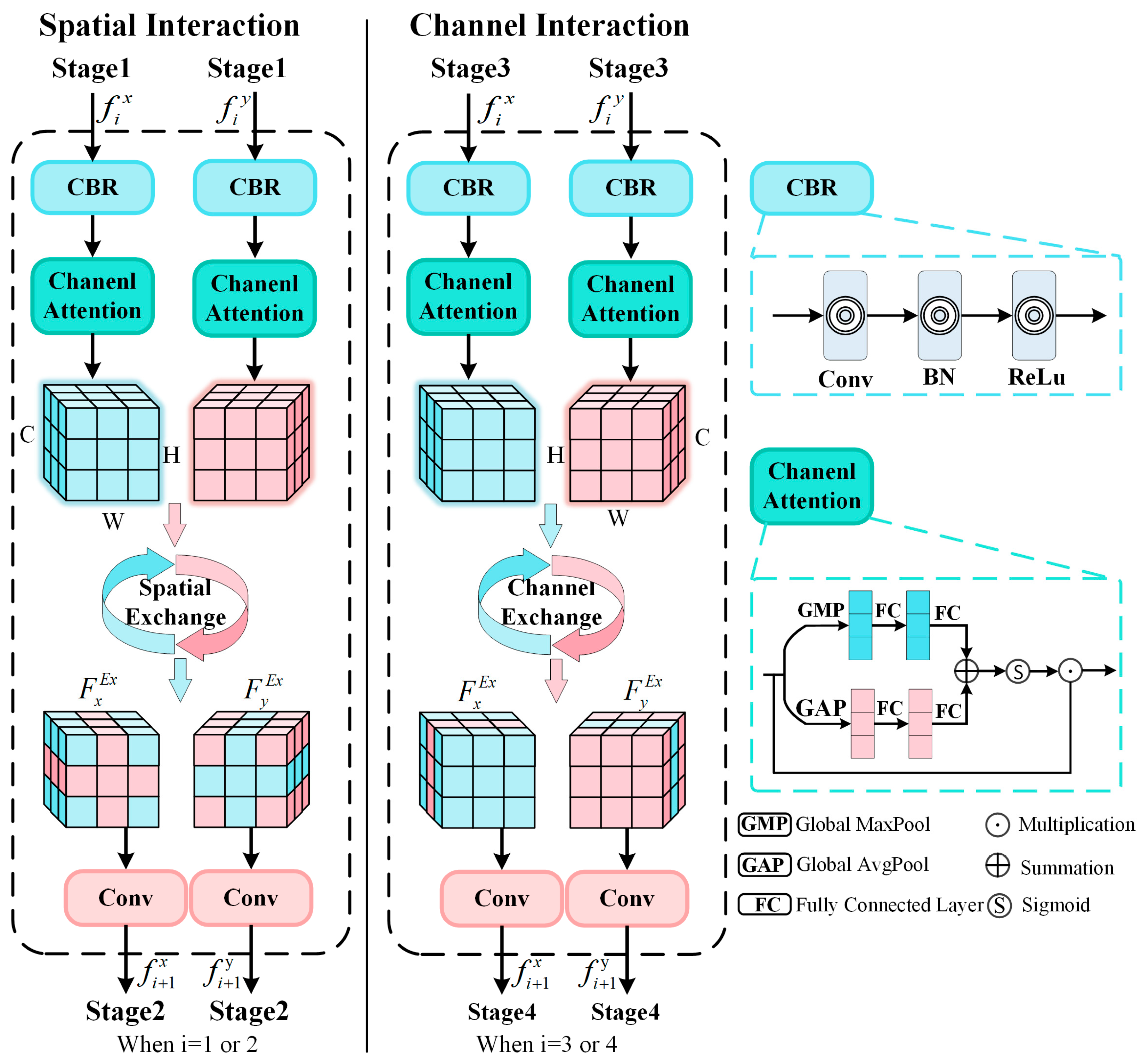
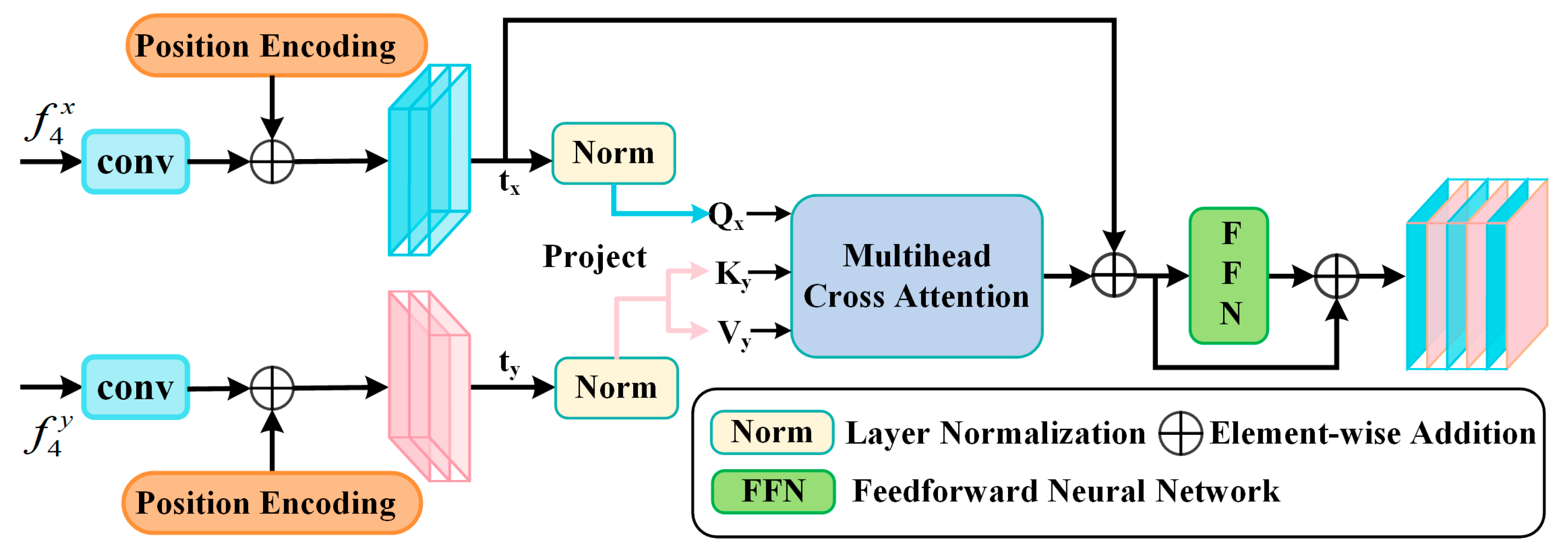
2.2. Multi-Path Complementarity-Aware Interaction Module (MCIM)
2.3. Feature Weighting Balance Module (FWBM)
2.4. Hybrid Loss
3. Results
3.1. Datasets
3.2. Experiment Details
3.2.1. Parameter Settings
3.2.2. Evaluation Metrics
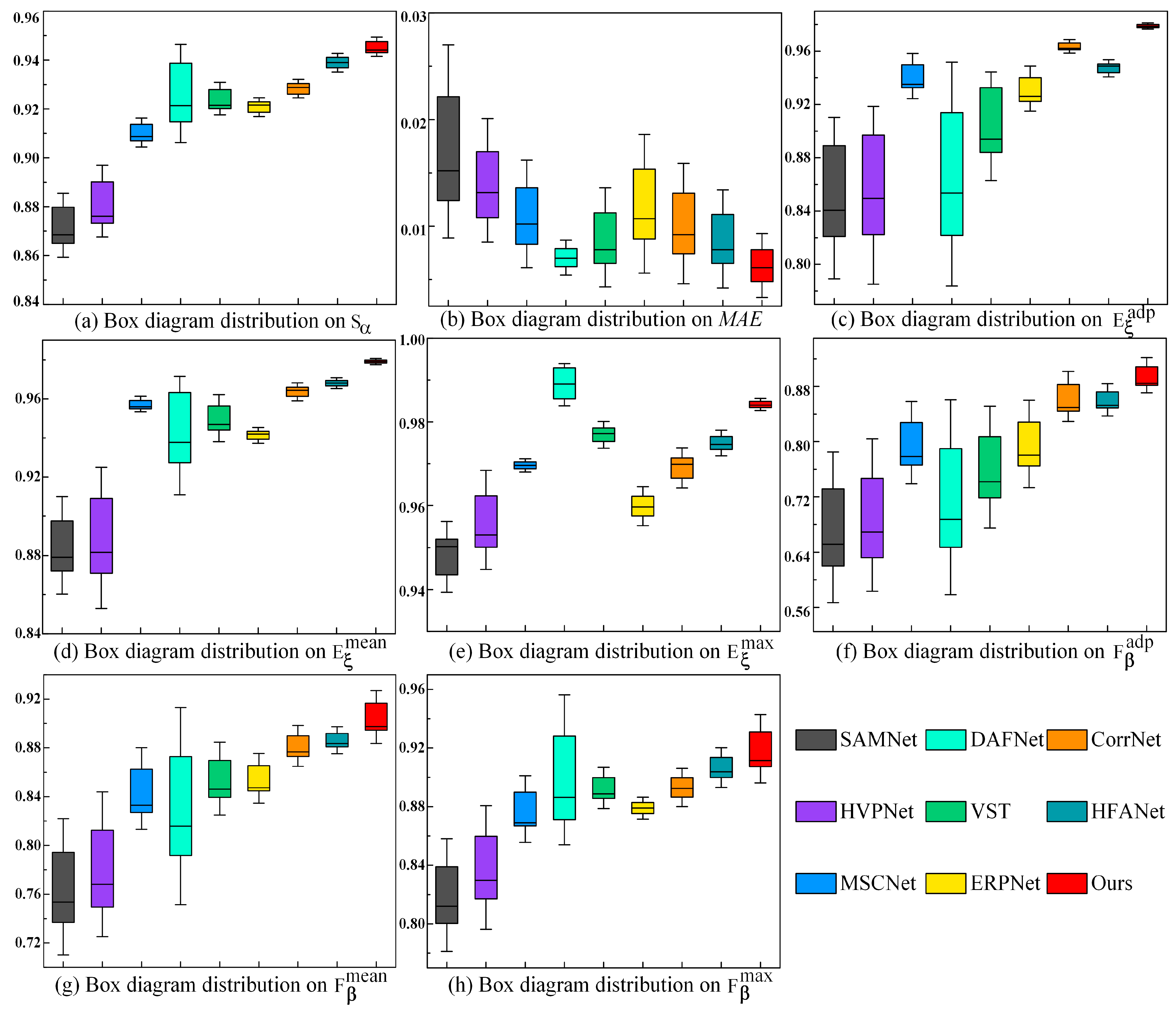
3.3. Comparison with State-of-the-Arts
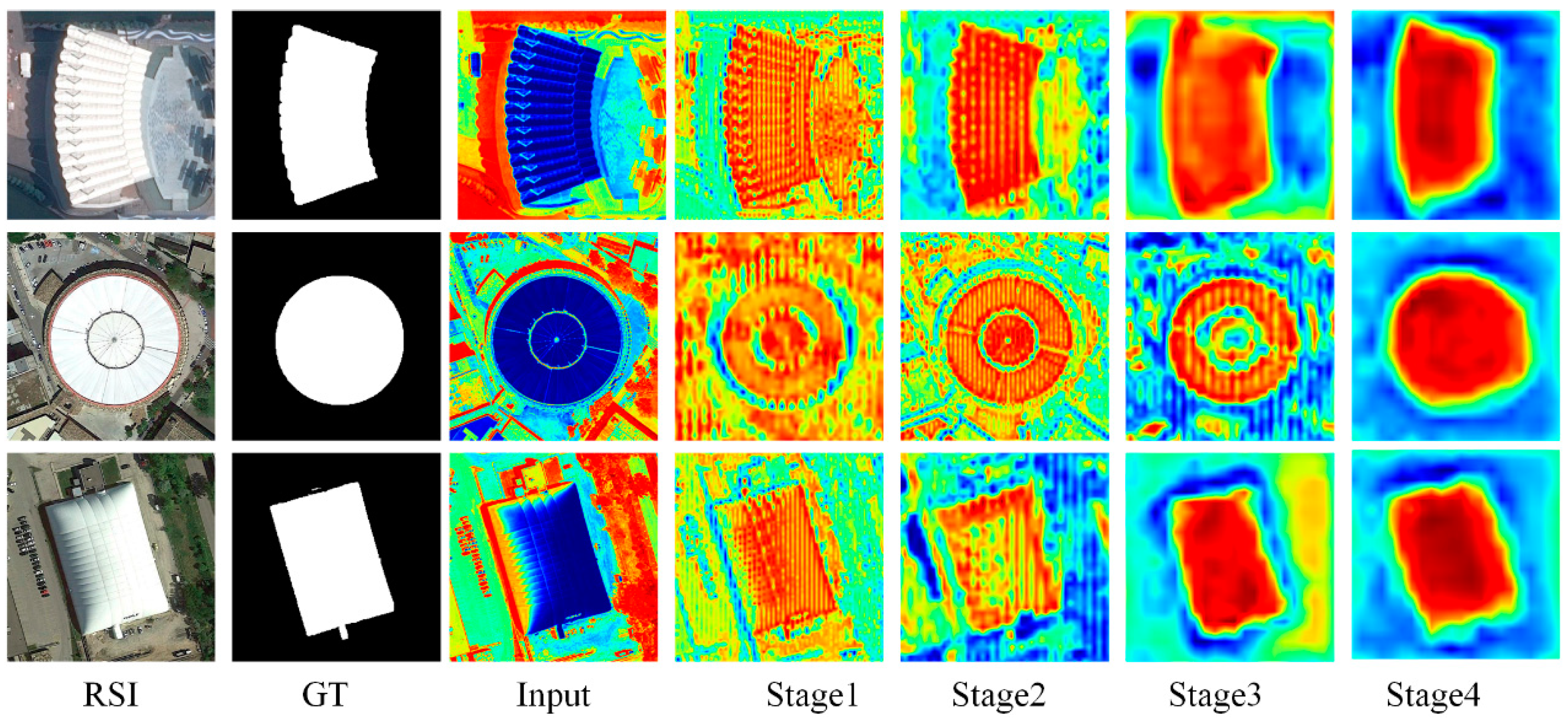
3.3.1. Visual Comparison
3.3.2. Quantitative Comparison
3.4. Ablation Studies
3.4.1. The Ablation Study of DCPNet
3.4.2. Analysis of Feature Interaction Strategies
4. Discussion
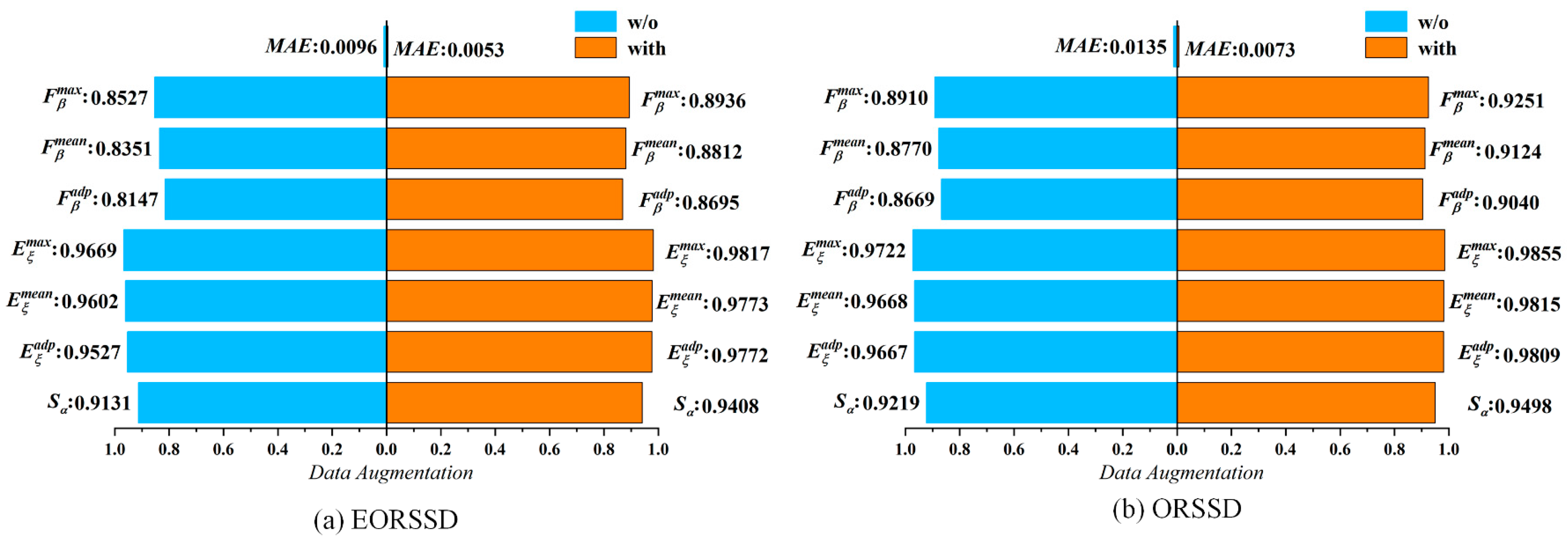
4.1. Effect of Date Augmentation Analysis
4.2. Model Parameter Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Jia, Y.; Ma, L.; Yu, L. Recurrent Adaptive Graph Reasoning Network with Region and Boundary Interaction for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5630720. [Google Scholar] [CrossRef]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H.; Yang, R. Salient object detection in the deep learning era: An in-depth survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3239–3259. [Google Scholar] [CrossRef]
- Di, L.; Zhang, B.; Wang, Y. Multiscale and Multidimensional Weighted Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5625114. [Google Scholar] [CrossRef]
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Scheuer, S.; Kremer, P.; Mascarenhas, A.; Kraemer, R. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Mei, L.; Ye, Z.; Xu, C.; Wang, H.; Wang, Y.; Lei, C.; Yang, W.; Li, Y. SCD-SAM: Adapting Segment Anything Model for Semantic Change Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5626713. [Google Scholar] [CrossRef]
- Sun, L.; Wang, Q.; Chen, Y.; Zheng, Y.; Wu, Z.; Fu, L.; Jeon, B. CRNet: Channel-Enhanced Remodeling-Based Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5618314. [Google Scholar] [CrossRef]
- Cong, R.; Zhang, Y.; Fang, L.; Li, J.; Zhao, Y.; Kwong, S. RRNet: Relational reasoning network with parallel multiscale attention for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5613311. [Google Scholar] [CrossRef]
- Huang, M.; Gong, D.; Zhang, L.; Lin, H.; Chen, Y.; Zhu, D.; Xiao, C.; Altan, O. Spatiotemporal dynamics and forecasting of ecological security pattern under the consideration of protecting habitat: A case study of the Poyang Lake ecoregion. Int. J. Digit. Earth 2024, 17, 2376277. [Google Scholar] [CrossRef]
- Fu, Y.; Huang, M.; Gong, D.; Lin, H.; Fan, Y.; Du, W. Dynamic simulation and prediction of carbon storage based on land use/land cover change from 2000 to 2040: A case study of the Nanchang urban agglomeration. Remote Sens. 2023, 15, 4645. [Google Scholar] [CrossRef]
- Prokop, K.; Polap, D. Image segmentation enhanced by heuristic assistance for retinal vessels case. In Proceedings of the 2024 IEEE Congress on Evolutionary Computation (CEC), Yokohama, Japan, 30 June–5 July 2024; pp. 1–6. [Google Scholar]
- Wang, X.; Liu, Z.; Liesaputra, V.; Huang, Z. Feature specific progressive improvement for salient object detection. Pattern Recognit. 2024, 147, 110085. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, N.; Zhou, W.; Shi, Y.; Xie, G.; Wang, J. GPONet: A two-stream gated progressive optimization network for salient object detection. Pattern Recognit. 2024, 150, 110330. [Google Scholar] [CrossRef]
- Zhou, S.; Feng, Y.; Li, S.; Zheng, D.; Fang, F.; Liu, Y.; Wan, B. DSM-assisted unsupervised domain adaptive network for semantic segmentation of remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5608216. [Google Scholar] [CrossRef]
- Bai, Z.; Liu, Z.; Li, G.; Wang, Y. Adaptive group-wise consistency network for co-saliency detection. IEEE Trans. Multimed. 2021, 25, 764–776. [Google Scholar] [CrossRef]
- Cong, R.; Qin, Q.; Zhang, C.; Jiang, Q.; Wang, S.; Zhao, Y.; Kwong, S. A weakly supervised learning framework for salient object detection via hybrid labels. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 534–548. [Google Scholar] [CrossRef]
- Wang, K.; Tu, Z.; Li, C.; Zhang, C.; Luo, B. Learning Adaptive Fusion Bank for Multi-modal Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7344–7358. [Google Scholar] [CrossRef]
- Ma, L.; Luo, X.; Hong, H.; Zhang, Y.; Wang, L.; Wu, J. Scribble-attention hierarchical network for weakly supervised salient object detection in optical remote sensing images. Appl. Intell. 2023, 53, 12999–13017. [Google Scholar] [CrossRef]
- Luo, H.; Liang, B. Semantic-Edge Interactive Network for Salient Object Detection in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6980–6994. [Google Scholar] [CrossRef]
- Quan, Y.; Xu, H.; Wang, R.; Guan, Q.; Zheng, J. ORSI Salient Object Detection via Progressive Semantic Flow and Uncertainty-aware Refinement. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608013. [Google Scholar] [CrossRef]
- Huang, K.; Li, N.; Huang, J.; Tian, C. Exploiting Memory-based Cross-Image Contexts for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5614615. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zhang, X.; Lin, W. Lightweight salient object detection in optical remote-sensing images via semantic matching and edge alignment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5601111. [Google Scholar] [CrossRef]
- Gong, A.; Nie, J.; Niu, C.; Yu, Y.; Li, J.; Guo, L. Edge and Skeleton Guidance Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7109–7120. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, N.; Zhang, N.; Wan, K.; Shao, L.; Han, J. Visual saliency transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4722–4732. [Google Scholar]
- Gao, L.; Liu, B.; Fu, P.; Xu, M. Adaptive spatial tokenization transformer for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602915. [Google Scholar] [CrossRef]
- Li, G.; Bai, Z.; Liu, Z.; Zhang, X.; Ling, H. Salient Object Detection in Optical Remote Sensing Images Driven by Transformer. IEEE Trans. Image Process. 2023, 32, 5257–5269. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, B.; Lu, J.; Yan, H. Towards Integrity and Detail with Ensemble Learning for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5624615. [Google Scholar] [CrossRef]
- Dong, P.; Wang, B.; Cong, R.; Sun, H.-H.; Li, C. Transformer with large convolution kernel decoder network for salient object detection in optical remote sensing images. Comput. Vis. Image Underst. 2024, 240, 103917. [Google Scholar] [CrossRef]
- Yan, R.; Yan, L.; Geng, G.; Cao, Y.; Zhou, P.; Meng, Y. ASNet: Adaptive Semantic Network Based on Transformer-CNN for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608716. [Google Scholar] [CrossRef]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. Efficientformer: Vision transformers at mobilenet speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar]
- Li, J.; Xia, X.; Li, W.; Li, H.; Wang, X.; Xiao, X.; Wang, R.; Zheng, M.; Pan, X. Next-vit: Next generation vision transformer for efficient deployment in realistic industrial scenarios. arXiv 2022, arXiv:2207.05501. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Liu, J.; Sun, H.; Katto, J. Learned image compression with mixed transformer-cnn architectures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14388–14397. [Google Scholar]
- Chen, B.; Zou, X.; Zhang, Y.; Li, J.; Li, K.; Xing, J.; Tao, P. LEFormer: A hybrid CNN-transformer architecture for accurate lake extraction from remote sensing imagery. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 5710–5714. [Google Scholar]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5906–5916. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested network with two-stream pyramid for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.-M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense attention fluid network for salient object detection in optical remote sensing images. IEEE Trans. Image Process. 2020, 30, 1305–1317. [Google Scholar] [CrossRef]
- Fan, D.-P.; Cheng, M.-M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.-P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.-M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Liu, Y.; Zhang, X.-Y.; Bian, J.-W.; Zhang, L.; Cheng, M.-M. SAMNet: Stereoscopically attentive multi-scale network for lightweight salient object detection. IEEE Trans. Image Process. 2021, 30, 3804–3814. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, Y.-C.; Zhang, X.-Y.; Wang, W.; Cheng, M.-M. Lightweight salient object detection via hierarchical visual perception learning. IEEE Trans. Cybern. 2020, 51, 4439–4449. [Google Scholar] [CrossRef]
- Lin, Y.; Sun, H.; Liu, N.; Bian, Y.; Cen, J.; Zhou, H. A lightweight multi-scale context network for salient object detection in optical remote sensing images. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 238–244. [Google Scholar]
- Tu, Z.; Wang, C.; Li, C.; Fan, M.; Zhao, H.; Luo, B. ORSI salient object detection via multiscale joint region and boundary model. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607913. [Google Scholar] [CrossRef]
- Li, X.; Xu, Y.; Ma, L.; Huang, Z.; Yuan, H. Progressive attention-based feature recovery with scribble supervision for saliency detection in optical remote sensing image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5631212. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Bai, Z.; Lin, W.; Ling, H. Lightweight Salient Object Detection in Optical Remote Sensing Images via Feature Correlation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617712. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Liu, Z.; Gong, C.; Zhang, J.; Yan, C. Edge-Aware Multiscale Feature Integration Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5634819. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Lin, W.; Ling, H. Multi-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614513. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent Context Coordination Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Cybern. 2023, 53, 526–538. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Xu, M.; Hu, Y.; Tang, H.; Hu, Y.; Nie, L. Adaptive Edge-Aware Semantic Interaction Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5617416. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-Guided Recurrent Positioning Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Cybern. 2023, 53, 539–552. [Google Scholar] [CrossRef]
- Zhao, J.; Jia, Y.; Ma, L.; Yu, L. Adaptive Dual-Stream Sparse Transformer Network for Salient Object Detection in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 5173–5192. [Google Scholar] [CrossRef]
- Zhuge, M.; Fan, D.-P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient object detection via integrity learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3738–3752. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, Y.; Xiong, Z.; Yuan, Y. Hybrid feature aligned network for salient object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5624915. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | EORSSD [42] | |||||||
|---|---|---|---|---|---|---|---|---|
| CNN-based SOD methods | ||||||||
| SAMNet | 0.8622 | 0.0132 | 0.8284 | 0.8700 | 0.9421 | 0.6114 | 0.7214 | 0.7813 |
| HVPNet | 0.8734 | 0.0110 | 0.8270 | 0.8721 | 0.9482 | 0.6202 | 0.7377 | 0.8036 |
| DAFNet | 0.9166 | 0.0060 | 0.8443 | 0.9290 | 0.9859 | 0.6423 | 0.7842 | 0.8612 |
| MSCNet | 0.9071 | 0.0090 | 0.9329 | 0.9551 | 0.9689 | 0.7553 | 0.8151 | 0.8539 |
| MJRBM | 0.9197 | 0.0099 | 0.8897 | 0.9350 | 0.9646 | 0.7066 | 0.8239 | 0.8656 |
| PAFR | 0.8927 | 0.0119 | 0.8959 | 0.9210 | 0.9490 | 0.7123 | 0.7961 | 0.8260 |
| CorrNet | 0.9289 | 0.0083 | 0.9593 | 0.9646 | 0.9696 | 0.8311 | 0.8620 | 0.8778 |
| EMFINet | 0.9319 | 0.0075 | 0.9500 | 0.9598 | 0.9712 | 0.8036 | 0.8505 | 0.8742 |
| MCCNet | 0.9327 | 0.0066 | 0.9538 | 0.9685 | 0.9755 | 0.8137 | 0.8604 | 0.8904 |
| ACCoNet | 0.929 | 0.0074 | 0.9450 | 0.9653 | 0.9727 | 0.7969 | 0.8552 | 0.8837 |
| AESINet | 0.9358 | 0.0079 | 0.9462 | 0.9636 | 0.9751 | 0.7923 | 0.8524 | 0.8838 |
| ERPNet | 0.9210 | 0.0089 | 0.9228 | 0.9401 | 0.9603 | 0.7554 | 0.8304 | 0.8632 |
| ADSTNet | 0.9311 | 0.0065 | 0.9681 | 0.9709 | 0.9769 | 0.8532 | 0.8716 | 0.8804 |
| SFANet | 0.9349 | 0.0058 | 0.9669 | 0.9726 | 0.9769 | 0.8492 | 0.8680 | 0.8833 |
| Transformer-based SOD methods | ||||||||
| VST | 0.9208 | 0.0067 | 0.8941 | 0.9442 | 0.9743 | 0.7089 | 0.8263 | 0.8716 |
| ICON | 0.9185 | 0.0073 | 0.9497 | 0.9619 | 0.9687 | 0.8065 | 0.8371 | 0.8622 |
| HFANet | 0.9380 | 0.0070 | 0.9644 | 0.9679 | 0.9740 | 0.8365 | 0.8681 | 0.8876 |
| TLCKDNet | 0.9350 | 0.0056 | 0.9514 | 0.9661 | 0.9788 | 0.7969 | 0.8535 | 0.8843 |
| CNN–Transformer-based SOD methods | ||||||||
| ASNet | 0.9345 | 0.0055 | 0.9748 | 0.9745 | 0.9783 | 0.8672 | 0.8770 | 0.8959 |
| Ours | 0.9408 | 0.0053 | 0.9772 | 0.9773 | 0.9817 | 0.8695 | 0.8812 | 0.8936 |
| Methods | ORSSD [41] | |||||||
|---|---|---|---|---|---|---|---|---|
| CNN-based SOD methods | ||||||||
| SAMNet | 0.8761 | 0.0217 | 0.8656 | 0.8818 | 0.9478 | 0.6843 | 0.7531 | 0.8137 |
| HVPNet | 0.8610 | 0.0225 | 0.8471 | 0.8717 | 0.9320 | 0.6726 | 0.7396 | 0.7938 |
| DAFNet | 0.9191 | 0.0113 | 0.9360 | 0.9539 | 0.9771 | 0.7876 | 0.8511 | 0.8928 |
| MSCNet | 0.9227 | 0.0129 | 0.9584 | 0.9653 | 0.9754 | 0.8350 | 0.8676 | 0.8927 |
| MJRBM | 0.9204 | 0.0163 | 0.9328 | 0.9415 | 0.9623 | 0.8022 | 0.8566 | 0.8842 |
| PAFR | 0.8938 | 0.0211 | 0.9315 | 0.9268 | 0.9467 | 0.8025 | 0.8275 | 0.8438 |
| CorrNet | 0.938 | 0.0098 | 0.9721 | 0.9746 | 0.979 | 0.8875 | 0.9002 | 0.9129 |
| EMFINet | 0.9432 | 0.0095 | 0.9715 | 0.9726 | 0.9813 | 0.8797 | 0.9000 | 0.9155 |
| MCCNet | 0.9437 | 0.0087 | 0.9735 | 0.9758 | 0.9800 | 0.8957 | 0.9054 | 0.9155 |
| ACCoNet | 0.9437 | 0.0088 | 0.9721 | 0.9754 | 0.9796 | 0.8806 | 0.8971 | 0.9149 |
| AESINet | 0.9460 | 0.0086 | 0.9707 | 0.9747 | 0.9828 | 0.8666 | 0.8986 | 0.9183 |
| ERPNet | 0.9254 | 0.0135 | 0.9520 | 0.8566 | 0.9710 | 0.8356 | 0.8745 | 0.8974 |
| ADSTNet | 0.9379 | 0.0086 | 0.9785 | 0.9740 | 0.9807 | 0.8979 | 0.9042 | 0.9124 |
| SFANet | 0.9453 | 0.0070 | 0.9765 | 0.9789 | 0.9830 | 0.8984 | 0.9063 | 0.9192 |
| Transformer-based SOD methods | ||||||||
| VST | 0.9365 | 0.0094 | 0.9466 | 0.9621 | 0.9810 | 0.8262 | 0.8817 | 0.9095 |
| ICON | 0.9256 | 0.0116 | 0.9554 | 0.9637 | 0.9704 | 0.8444 | 0.8671 | 0.8939 |
| HFANet | 0.9399 | 0.0092 | 0.9722 | 0.9712 | 0.9770 | 0.8819 | 0.8981 | 0.9112 |
| TLCKDNet | 0.9421 | 0.0082 | 0.9696 | 0.9710 | 0.9794 | 0.8719 | 0.8947 | 0.9114 |
| CNN–Transformer-based SOD methods | ||||||||
| ASNet | 0.9441 | 0.0081 | 0.9795 | 0.9764 | 0.9803 | 0.8986 | 0.9072 | 0.9172 |
| Ours | 0.9498 | 0.0073 | 0.9809 | 0.9815 | 0.9855 | 0.9040 | 0.9124 | 0.9251 |
| No. | Method | EORSSD [42] | |||
|---|---|---|---|---|---|
| 1 | Baseline | 0.9346 | 0.8545 | 0.8675 | 0.8826 |
| 2 | Baseline + MCIM | 0.9387 | 0.8584 | 0.8749 | 0.8912 |
| 3 | Baseline + FWBM | 0.9401 | 0.8648 | 0.8783 | 0.8932 |
| 4 | DCPNet | 0.9408 | 0.8695 | 0.8812 | 0.8936 |
| No. | Interaction Method | |||
|---|---|---|---|---|
| 1 | DCPNet (MCIM) | 0.9387 | 0.9816 | 0.8912 |
| 2 | MCIM w/, Spatial Interaction | 0.9364 | 0.9780 | 0.8857 |
| 3 | MCIM w/, Channel Interaction | 0.9373 | 0.9787 | 0.8868 |
| Methods | Params (M) | FLOPs (G) |
|---|---|---|
| CorrNet | 4.086 | 21.379 |
| EMFINet | 95.086 | 176 |
| MCCNet | 67.652 | 114 |
| ACCoNet | 127 | 50.422 |
| ERPNet | 77.195 | 171 |
| GeleNet | 25.453 | 6.43 |
| Ours | 99.311 | 20.524 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Chen, X.; Mei, L.; Yang, W. Dual-Stream Feature Collaboration Perception Network for Salient Object Detection in Remote Sensing Images. Electronics 2024, 13, 3755. https://doi.org/10.3390/electronics13183755
Li H, Chen X, Mei L, Yang W. Dual-Stream Feature Collaboration Perception Network for Salient Object Detection in Remote Sensing Images. Electronics. 2024; 13(18):3755. https://doi.org/10.3390/electronics13183755
Chicago/Turabian StyleLi, Hongli, Xuhui Chen, Liye Mei, and Wei Yang. 2024. "Dual-Stream Feature Collaboration Perception Network for Salient Object Detection in Remote Sensing Images" Electronics 13, no. 18: 3755. https://doi.org/10.3390/electronics13183755
APA StyleLi, H., Chen, X., Mei, L., & Yang, W. (2024). Dual-Stream Feature Collaboration Perception Network for Salient Object Detection in Remote Sensing Images. Electronics, 13(18), 3755. https://doi.org/10.3390/electronics13183755