Abstract
The research of multimodal emotion recognition based on facial expressions, speech, and body gestures is crucial for oncoming intelligent human–computer interfaces. However, it is a very difficult task and has seldom been researched in this combination in the past years. Based on the GEMEP and Polish databases, this contribution focuses on trimodal emotion recognition from facial expressions, speech, and body gestures, including feature extraction, feature fusion, and multimodal classification of the three modalities. In particular, for feature fusion, two novel algorithms including supervised least squares multiset kernel canonical correlation analysis (SLSMKCCA) and sparse supervised least squares multiset kernel canonical correlation analysis (SSLSMKCCA) are presented, respectively, to carry out efficient facial expression, speech, and body gesture feature fusion. Different from the traditional multiset kernel canonical correlation analysis (MKCCA) algorithms, our SLSKMCCA algorithm is a supervised version and is based on the least squares form. The SSLSKMCCA algorithm is implemented by the combination of SLSMKCCA and a sparse item (L1 Norm). Moreover, two effective solving algorithms for SLSMKCCA and SSLSMKCCA are presented in addition, which use the alternated least squares and augmented Lagrangian multiplier methods, respectively. The extensive experimental results on the popular public GEMEP and Polish databases show that the recognition rate of multimodal emotion recognition is superior to bimodal and monomodal emotion recognition on average, and our presented SLSMKCCA and SSLSMKCCA fusion methods both obtain very high recognition rates, especially for the SSLSMKCCA fusion method.
1. Introduction
Intelligent human–computer interfaces have been developed for several decades, approximately. Nowadays, the application of artificial intelligence in such interfaces has become more and more extensive, and intelligent human–computer interfaces are also increasingly demanded to act the same as or approximate human-to-human interfaces when it comes to emotional intelligence in interactions. This includes all kinds of emotions such as happiness, sadness, disgust, and many more [1,2,3]. Consequently, this comes at a higher requirement for the research of intelligent human–computer interfaces; after all, the computer still has a wide gap in emotional intelligence when compared to human beings. If tomorrow’s intelligent human–computer interfaces aim to achieve parity with human-to-human emotional interaction, accurate emotion recognition ability is the key necessary prerequisite [4].
Human-to-human emotional interaction is very common in daily life for human beings. The form of such human-to-human emotional interaction is, however, very sophisticated, variable, and dynamic. For human beings with different cultural backgrounds, races, genders, ages, personalities, and, furthermore, differences in traits, the form of human-to-human emotional interaction is often significantly different [5,6]. Even for the same person, it may highly vary in various environments. Among those complexities and variabilities, however, one can also find a certain generality of human-to-human emotional interaction. This generality is given by the fact that most human beings interact emotionally with other people using a multimodal combination form most of the time [7,8,9,10]. This multimodal combination form most often includes the modalities of facial expressions, speech, and body gestures [11,12,13,14,15,16]. Therefore, if the ability of intelligent human–computer interfaces achieves or approximates the level of human-to-human emotional interface, it is essential to research such a multimodal emotion recognition for computers. Specifically, the research of multimodal emotion recognition based on facial expressions, speech, and body gestures is, accordingly, of crucial relevance for the next generation of intelligent human–computer interfaces [3,17,18]. However, it is a considerably challenging task and has seldom been researched in the past years.
In general, emotion recognition can be divided into two types according to the literature: monomodal emotion recognition and multimodal emotion recognition [9,12,19,20,21,22]. Monomodal emotion recognition is based on only one modality, while multimodal emotion recognition is based on two or more than two modalities [3,10,23,24,25]. The typical monomodal emotion recognition covers facial expression recognition, speech emotion recognition, body gesture emotion recognition, physiological signal emotion recognition, and likes [13,14,25,26,27]. Among those monomodal emotion recognition types, most of the emotion recognition researchers focus on facial expression recognition and speech emotion recognition. Body gesture emotion recognition, physiological signal emotion recognition, and other monomodal emotion recognition types have been less researched in the past years [25,26,27].
Aside from monomodal emotion recognition, multimodal emotion recognition also covers bimodal emotion recognition based on facial expressions and speech, bimodal emotion recognition based on facial expressions and physiological signals, bimodal emotion recognition based on facial expressions and body gestures, bimodal emotion recognition based on speech and physiological signals, multimodal emotion recognition based on facial expressions, speech, and body gestures, multimodal emotion recognition based on facial expressions, physiological signal, body gestures, and more [3,9,10,11,17,22,24,25,28,29,30,31,32,33,34]. Among the multimodal emotion recognition types, bimodal emotion recognition based on two modalities is relatively present in the body of literature, but multimodal emotion recognition based on three or more than three modalities is very rare in research, as adding further modalities obviously increases the difficulty and complexity for building the multimodal emotion database and multimodal emotion recognition engine [22,25]. However, as described in the first two paragraphs in this article, if the ability of an emotionally intelligent human–computer interface can reach or get close to the level of human-to-human emotional interaction, it is essential to study multimodal emotion recognition based on facial expressions, speech, and body gestures [29,30,34].
Although the research of multimodal emotion recognition based on facial expressions, speech, and body gestures is a very difficult task, there are a few researchers that have preliminarily carried out this task [12,21]. Caridakis and Castellano et al. [17,18] used two fusion levels (feature level and decision level) and a Bayesian classifier to reach multimodal emotion recognition based on facial expressions, speech, and body gestures, and their experimental results show that multimodal emotion recognition based on three modalities significantly improves the recognition performance over using less modalities. Metallinou et al. [35] present a multimodal emotion recognition from a facial expression, speech, and head movement approach, which is implemented by decision-level fusion and a Bayesian model. Similar to the work of [17,18], Kessous et al. [36] also use two fusion levels (feature level and decision level) and a Bayesian model to implement multimodal emotion recognition based on facial expressions, speech, and body gestures, and also obtain similar multimodal emotion recognition experimental results in their established speech-centered interaction multimodal emotion corpus. Different from the above recognition-based works, Nicolaou et al. [37] researched multimodal dimensional emotion prediction based on facial expressions, speech, and body gestures by using two regression methods including bidirectional long short-term memory neural networks and support vector machines for regression. Ozkul et al. [38] used a hidden Markov model and a mutual information measure to realize multimodal emotion recognition based on facial expressions, speech, and upper-body gestures on their spontaneous multimodal corpora. Ghayoumi et al. [39] recently set up a real-time multimodal emotion recognition engine based on facial expressions, speech, and body gestures, which was implemented as a formal model based on decision-level fusion. Moreover, other related works on this task are described in references [40,41].
From the above discussion, we can see that multimodal emotion recognition based on facial expressions, speech, and body gestures has not been well studied in the past years, and there are still many steps to be taken. In this article, we focus on the study of multimodal emotion recognition from facial expressions, speech, and body gestures using the GEMEP [42,43] and Polish databases [41]. Our work includes the feature extraction, feature fusion, and multimodal classification of three modalities.
Specifically for feature fusion, two novel algorithms including supervised least squares multiset kernel canonical correlation analysis (SLSMKCCA) and sparse supervised least squares multiset kernel canonical correlation analysis (SSLSMKCCA) are presented in this article to carry out facial expression, speech, and body gesture feature fusion. Different from the traditional multiset kernel canonical correlation analysis (MKCCA) algorithms [44,45], our SLSKMCCA algorithm is a supervised version and is based on the least squares form. The SLSMKCCA algorithm is implemented by the combination of SLSMKCCA and a sparse item (L1 Norm) [3,46,47,48,49], and it can be used to select the useful features of three modalities by joining the sparse item (L1 Norm). Moreover, two effective solution algorithms for SLSMKCCA and SSLSMKCCA are also presented, which use the alternated least squares [15,49,50,51] and augmented Lagrangian multiplier method [22,52,53,54,55,56], respectively.
The main novelty of this article stems from the following three contributions. The first contribution is that two novel algorithms including SLSMKCCA and SSLSMKCCA are presented to carry out facial expression, speech, and body gesture feature fusion. The second contribution is that two effective solution algorithms for SLSMKCCA and SSLSMKCCA are presented. The last contribution is that we implemented the multimodal emotion recognition based on facial expressions, speech, and body gestures using the SLSMKCCA and SSLSMKCCA algorithm.
The rest of the paper is organized as follows. Section 2 and Section 3 introduce the traditional multiset canonical correlation analysis (MCCA) and multiset kernel canonical correlation analysis (MKCCA) algorithms, respectively. Section 4 and Section 5 introduce our proposed supervised least squares multiset kernel canonical correlation analysis (SLSMKCCA) and sparse least squares multiset canonical correlation analysis (SSLSMKCCA) algorithms, respectively. Section 6 and Section 7 introduce the experimental result on the GEMEP and Polish multimodal emotion databases and conclusion, respectively.
2. Multiset Canonical Correlation Analysis
Different from the canonical correlation analysis (CCA) method, the multiset canonical correlation analysis (MCCA) method [15,57,58,59,60,61,62,63] was proposed to implement a linear correlation analysis between three or more sets of data. So far, it has been applied to implement feature fusion in many applications such as handwritten digit recognition, remote sensing image classification, face recognition, blind source separation, and more [64,65].
As this paper focuses on multimodal emotion recognition from three modalities (facial expressions, speech, and body gestures), in the following, we will introduce the MCCA in the form of three sets of data to be handled, which correspond to the above three modalities, respectively. We suppose that , , and are the feature matrices of facial expression, speech, and body gesture modalities, respectively, p, q, and r are the corresponding dimension of the three modalities, and N is the number of the three modalities’ samples. , , and are three projection matrices of the MCCA method, which correspond to facial expression, speech, and body gesture modalities, respectively. Then, the MCCA method can be shown as [57,58,59,60]
The formulation (1) of the MCCA method can be transformed to optimize the following equation:
Lastly, the optimization formulation of (2) can be solved by the traditional Lagrangian multiplier method.
3. Multiset Kernel Canonical Correlation Analysis
Based on the linear MCCA method, the MKCCA method [44,45,66] was proposed next to implement a non-linear correlation analysis between three or more sets of data by non-linear mapping. So far, the MKCCA method has also been applied to implement feature fusion in many applications such as remote sensing image classification, genomic data analysis, blind source separation, and many more [44,45,67,68].
We suppose that , , and are the feature matrices of the facial expression, speech, and body gesture modalities, respectively, which are mapped into a higher space by three corresponding mapping functions , , and . , , and are the corresponding dimensions of the three modalities in higher space. Then, the MKCCA method can be shown as [44,45,67,68]
It is noted that the three projection matrices of the MKCCA method , , and can be represented as
where , , and are three other matrices which, respectively, correspond to the three projection matrices of the MKCCA method , , and .
Then, the formulation (3) of the MKCCA method can be represented as
Now, let us define three kernel matrices of the MKCCA method , , and for facial expression, speech, and body gesture modalities respectively. Then, the formulation (7) of the MKCCA method can be represented as
Similar to the above MCCA method, the formulation (8) of the MKCCA method can also be transformed to optimize the following equation:
Lastly, the optimization formulation of (9) can also be solved by the traditional Lagrangian multiplier method.
4. Supervised Least Squares Multiset Kernel Canonical Correlation Analysis
In this section, we introduce the optimization formulation of the MCCA method. For the CCA method, the formulation (1) can be changed as (we suppose that we only consider the modality of facial expressions and speech in this formulation) [57,58]
Unlike the traditional form (10) of the CCA method, it also can be shown as another least squares form [3,15,50,51]:
The formulations (10) and (11) of the CCA method are equivalent, which has been proven in the literature [50]. Based on the least squares form (11) of the CCA method, we present the supervised least squares multiset kernel canonical correlation analysis (SLSMKCCA) algorithm as follows:
where is the label matrix [15,46,51,56] for , , and , is the projection matrix of the label matrix , and m is the dimension of the label matrix .
Substituting , , and in Section 3 into the formulation (13), the SLSMKCCA algorithm can be shown as
then, it can be reformulated as
then, it can be shown as
then,
then, , , , and can be written as
According to the above derivation, the iterative solution algorithm of the SLSMKCCA method using the alternated least squares [3,15,22,49,50,51,54] is given in Algorithm 1.
| Algorithm 1: SLSMKCCA |
Repeating four steps until convergence:
Output: , , . |
Lastly, the SLSMKCCA method carries out facial expression, speech, and body gesture feature fusion by [3,8,11,15,19,22,31]
5. Sparse Supervised Least Squares Multiset Kernel Canonical Correlation Analysis
In recent years, based on the MCCA method, the sparse multiset canonical correlation analysis (SMCCA) [69,70,71] method has also been proposed and applied to implement feature fusion in applications such as genomic data analysis, neoadjuvant breast cancer prediction, imaging, and (epi)genomics [69,70,72].
Different from the above SMCCA algorithm, we present the sparse supervised least squares multiset kernel canonical correlation analysis (SSLSMKCCA) algorithm as follows based on our SLSMKCCA algorithm in Section 4:
where , , and denote the L1 Norm parameter for , , and , respectively.
Then, the formulation (26) of the SSLSMKCCA algorithm can also be written as
Based on the augmented Lagrangian multiplier approach [3,15,22,49,51,52,53,54,55,56], we can add three equality constraints , , and for formulation (27); then, the formulation (27) can be noted as
where the set of parameters , , and denote three constants, and the set of parameters , , and denote three Lagrangian multiplication matrices.
Then,
then, , , , and can be shown as
When , , , and are fixed, we only need to solve , , and , and formulation (28) of the SSLSMKCCA algorithm can be reformulated as
which can be resolved into
then, based on the Lemma in [3,22,49,52,53,54,56], , , and can be shown as
According to the above derivation, the iterative solution algorithm of the SSLSMKCCA method using the alternated least squares [3,15,22,49,50,51,54] is shown in Algorithm 2. In our experiment, the initial matrices of , , and are all set to 0 matrix, and , , and are all set to . , , and are all set to , and , , and are all set to .
| Algorithm 2: SSLSMKCCA |
Repeating nine steps until convergence:
Output: , , . |
Lastly, the SSLSMKCCA method also carries out facial expression, speech, and body gesture feature fusion by [3,8,11,15,19,22,31]
6. Experiments
In this section, we conducted single-modal and multimodal emotion recognition experiments using the GEMEP and Polish databases to validate the effectiveness of our proposed SLSMKCCA and SSLSMKCCA algorithms, and compared them with other methods.
6.1. The GEMEP Multimodal Emotion Database
Among all of the existing emotion databases, monomodal emotion database and bimodal emotion database are relatively common [9,10,12,21,25]. However, multimodal emotion databases (three modalities or more than three modalities) are relatively rare, especially for the case of a multimodal emotion database consisting of facial expressions, speech, and body gestures. The Geneva Multimodal Emotion Portrayals (GEMEP) [42,43] is a public multimodal emotion database that contains this combination of modalities, built by Banziger, Mortillaro, and Scherer at the University of Geneva in recent years.
The original GEMEP database, in total, collected 1260 samples from 10 professional actors. That is to say, each modality contains 1260 samples. Banziger et al. evaluated the validity of the 1260 samples by rating, and, lastly, only kept 145 reliable samples for public usage and abandoned most of the samples [42,43]. The reserved parts of the GEMEP database cover 17 emotion categories including tenderness, cold anger (irritation), amusement, anxiety, contempt, despair, pride, hot anger (rage), interest, fear (panic), joy (elation), surprise, pleasure (sensory), relief, sadness, admiration, and disgust [42,43].
Although the GEMEP database has 17 emotion categories, some categories are similar to each other. For example, the emotion categories hot anger (rage) and cold anger (irritation) are actually similar in terms of arousal and, particularly, valence (it refers to the degree of pleasure or displeasure associated with an emotional experience), essentially measuring the positive or negative characteristics of an emotion. Moreover, the sample number of each emotion category is very small. Therefore, we clustered the similar emotion categories into the same emotion category in the following. In our experiment, we specifically merged the emotion categories cold anger (irritation) and hot anger (rage) as the ‘anger’ emotion category, the emotion categories contempt and disgust as the ‘disgust’ emotion category, the emotion categories anxiety and fear (panic) as the ‘fear’ emotion category, the emotion categories amusement, joy (elation), pleasure (sensory), and pride as the ‘happy’ emotion category, the emotion categories of despair and sad as the ‘sad’ emotion category, the emotion categories surprise and admiration as the ‘surprise’ emotion category, and the emotion categories of interest, relief, and tenderness as the ‘calm’ emotion category. Thus, we obtained seven emotion categories from the GEMEP database after merging. Table 1 provides the information on the seen emotion categories and the number of samples in our experiments.

Table 1.
The information about the seven emotion categories and the number of samples in our experiment.
Due to the sample size of the GEMEP database being too small (each modality only provides 145 samples), we utilized traditional methods rather than a deep learning method for feature extraction of facial expressions, body gesture analysis, and speech analysis. The feature extraction methods for the three modalities used in our experiment are summarized as follows. Moreover, the classifier, experimental strategy, comparison fusion method, kernel function, and other information used in our experiment are given together in Table 2.
- Facial expression modality: Local Binary Patterns (LBPs) [73] were used to extract features from facial expression images from the GEMEP database. Those facial expression images were selected from facial expression videos from the GEMEP database by manual selection, and every facial expression video corresponds to one facial expression image. The resolution of those facial expression images is . The facial expression feature dimension of LBP was 3776 in our experiment.
- Body gesture modality: spatial–temporal features [8,11,15,31,74] were used to extract body gesture features from body gesture videos from the GEMEP database. The dimension of the spatial-temporal features used in our experiment was 200.
- Speech modality: the openSMILE tool [3,19,22,75] was used to extract speech features (“emobase” set) from the audio data of the GEMEP database. The speech feature dimension used in our experiment was 1582.
Table 2.
Information on the experiments run on the GEMEP database.
Table 2.
Information on the experiments run on the GEMEP database.
| GEMEP database | 10 subjects; 145 samples; 3 modalities; 7 categories |
| Feature extraction | facial expressions: LBP; body gestures: spatial–temporal features; speech: openSMILE |
| Fusion method | PCA fusion [31]; CCA [58]; kernel CCA (KCCA) [58]; MCCA [61]; MKCCA [44,45]; SMCCA [69]; SLSMKCCA; SSLSMKCCA; decision-level fusion [76] |
| Classifier | support vector machines (SVMs) |
| Strategy | leave one subject out |
| Kernel function | Gaussian kernel |
(1) Monomodal emotion recognition experimental results: Firstly, we conducted three sets of monomodal emotion recognition experiments based on facial expressions, body gestures, and speech modality. The monomodal emotion recognition experimental results on the GEMEP database are shown in Table 3.
Table 3.
Three sets of monomodal emotion recognition experimental results on the GEMEP database (ARR = average recognition rate).
From Table 3, we can see that the recognition rates of three sets of monomodal emotion recognition experiments are not high, especially for body gestures as a modality. The recognition rates of facial expression and speech analysis are higher than for body gesture analysis, obviously, especially in comparison to the facial expression modality.
(2) Bimodal emotion recognition experimental results: Secondly, we conducted three sets of bimodal emotion recognition experiments between facial expressions, body gestures, and speech using PCA fusion, CCA, and KCCA. Three sets of bimodal emotion recognition experiments included bimodal emotion recognition based on facial expressions and body gestures, bimodal emotion recognition based on facial expressions and speech, and, finally, bimodal emotion recognition based on speech and body gestures. The corresponding experimental results on the GEMEP database are shown in Table 4.
Table 4.
Three sets of bimodal emotion recognition experimental results on the GEMEP database (ARR = average recognition rate).
From Table 4, we can see that the recognition rates of bimodal emotion recognition based on facial expressions and speech are higher than bimodal emotion recognition based on facial expressions and body gestures and bimodal emotion recognition based on speech and body gestures for all fusion methods. The recognition rates of bimodal emotion recognition based on speech and body gestures are visibly low.
(3) Multimodal emotion recognition experimental results: Lastly, we conducted the experiment aiming for ‘full’ multimodal emotion recognition based on facial expressions, body gestures, and speech as modalities using PCA fusion, MCCA, MKCCA, SMCCA, Convolutional Neural Networks (CNNs) [77], decision-level fusion, and our presented SLSMKCCA and SSLSMKCCA fusion methods. The corresponding multimodal emotion recognition experimental results on the GEMEP database are provided in Table 5. Moreover, the confusion matrices of the SLSMKCCA and SSLSMKCCA fusion methods on the GEMEP database are shown in Figure 1 and Figure 2, respectively.
Table 5.
Multimodal emotion recognition experimental results on the GEMEP database (ARR = Average recognition rate).
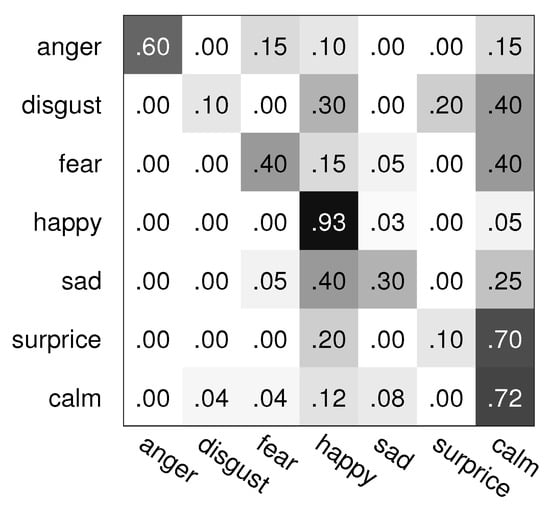
Figure 1.
The confusion matrix of SLSMKCCA fusion on the GEMEP database.
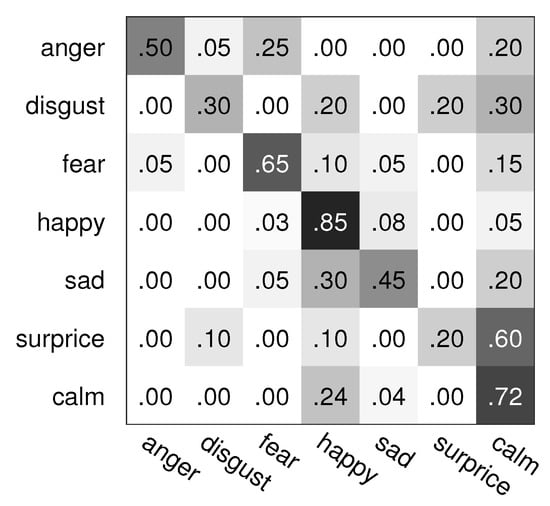
Figure 2.
The confusion matrix of SSLSMKCCA fusion on the GEMEP database.
From Table 3, Table 4 and Table 5 and Figure 1 and Figure 2, we can see that the recognition rate of multimodal emotion recognition is higher than the ones of bimodal and monomodal emotion recognition, on average, and especially higher than for monomodal emotion recognition. Our presented SLSMKCCA and SSLSMKCCA fusion methods both obtain high recognition rates, especially for SSLSMKCCA as a fusion method, and our SSLSMKCCA method obtains the best recognition rate amongst all monomodal, bimodal, and multimodal emotion recognition experimental results. In addition, the multimodal emotion recognition results of CNNs are poor due to the limited sample number of the GEMEP database.
6.2. The Polish Multimodal Emotion Database
The Polish emotional database [41] is another public multimodal emotion database that contains the modality of facial expressions, speech, and body gestures. It collected 560 samples from 16 professional actors for each modality and covers 7 emotion categories such as surprise, sadness, happiness, neutral, fear, anger, and disgust.
The feature extraction method for facial expression and speech modality on the Polish database [41] is the same as the aforementioned GEMEP database (for details, refer to the feature extraction part of the GEMEP database in Section A). However, the feature extraction method for the body gesture modality is different from the GEMEP database. As the Polish database only provides the point cloud data (each frame contains 25 key points and each key point contains three location data points and three rotation data points) instead of video data for body gesture modality. We selected 10 frames from each body gesture sample at a uniform interval and concatenated the point cloud data of 10 frames as the feature vector. Finally, the body gesture feature dimension of the Polish database was 1500 () in our experiment.
Moreover, the classifier, experimental strategy, comparison fusion method, and kernel function used in the experiment of the Polish database were the same as the aforementioned GEMEP database, which are given together in Table 2.
(1) Monomodal emotion recognition experimental results: Similar to the GEMEP database, we also conducted three sets of monomodal emotion recognition experiments on the Polish database first. The monomodal emotion recognition experimental results are shown in Table 6.
Table 6.
Three sets of monomodal emotion recognition experimental results on the Polish database (ARR = average recognition rate).
From Table 6, we can see that the recognition rates of three sets of monomodal emotion recognition experiments on the Polish database are higher than the GEMEP database in general, especially for body gestures as a modality. The main reason is that the Polish database covers more samples than the GEMEP database.
(2) Bimodal emotion recognition experimental results: Secondly, we also conducted three sets of bimodal emotion recognition experiments between facial expressions, body gestures, and speech using PCA fusion, CCA, and KCCA on the Polish database. Similar to the GEMEP database, the corresponding three sets of bimodal emotion recognition experiment results on the Polish database are shown in Table 7.
Table 7.
Three sets of bimodal emotion recognition experimental results on the Polish database (ARR = average recognition rate).
From Table 7, we can see that the recognition rates of the three sets of bimodal emotion recognition experiments are all better than the three sets of monomodal emotion recognition for all fusion methods, which demonstrates the effectiveness of the fusion strategy.
(3) Multimodal emotion recognition experimental results: Similar to the GEMEP database, we also conducted the experiment aiming for ‘full’ multimodal emotion recognition on the Polish database. The corresponding multimodal emotion recognition experimental results on the Polish database are provided in Table 8. Moreover, the confusion matrices of the SLSMKCCA and SSLSMKCCA fusion methods are shown in Figure 3 and Figure 4 respectively.
Table 8.
Multimodal emotion recognition experimental results on the Polish database (ARR = average recognition rate).
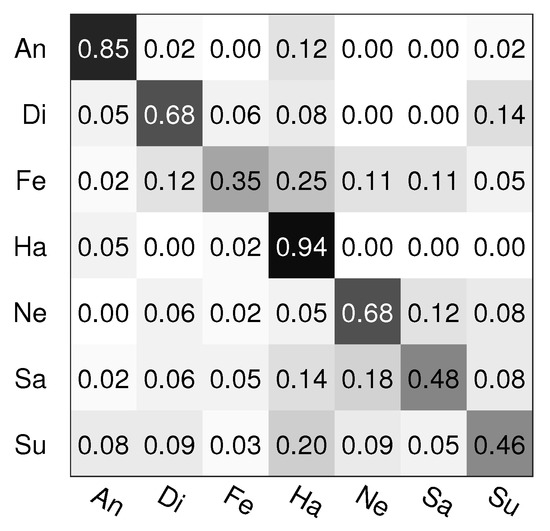
Figure 3.
The confusion matrix of SLSMKCCA fusion on the Polish database.
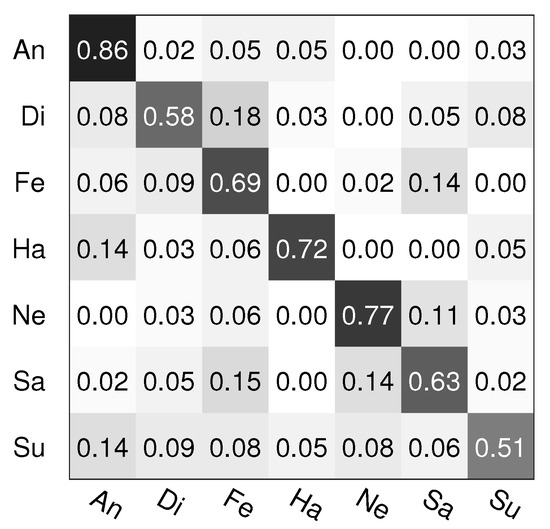
Figure 4.
The confusion matrix of SSLSMKCCA fusion on the Polish database.
From Table 6, Table 7 and Table 8 and Figure 3 and Figure 4, we also can see that the recognition rate of multimodal emotion recognition is higher than the ones of bimodal and monomodal emotion recognition, on average, which is similar to the GEMEP database. Moreover, our presented SLSMKCCA and SSLSMKCCA fusion methods both obtain high recognition rates, and the recognition rate of our SSLSMKCCA method is 68.1% and it obtains the best recognition rate amongst all monomodal, bimodal, and multimodal emotion recognition experimental results. In addition, the multimodal emotion recognition results of CNNs are poor due to the limited sample number of the Polish database.
From the experimental results on the GEMEP and Polish databases, our presented SLSMKCCA and SSLSMKCCA fusion methods both obtain high recognition rates, especially for the SSLSMKCCA fusion method, and the possible reason is that the SLSMKCCA method effectively establishes the correlation between three modal features and category labels. The SSLSMKCCA method adds a sparse item (L1 Norm) on the basis of the SLSMKCCA method, which can more effectively select useful features from the three modalities.
7. Conclusions
In this article, we focused on the rare case of three-fold multimodal emotion recognition from facial expressions, speech, and body gestures based on the GEMEP and Polish databases, including the feature extraction, feature fusion, and multimodal classification of the three modalities. In particular, for feature fusion, two novel algorithms, namely SLSMKCCA and SSLSMKCCA, were presented in this article to carry out facial expression, speech, and body gesture feature fusion. The experimental results on the GEMEP and Polish databases showed that the recognition rates of multimodal emotion recognition were considerably higher than those of bimodal and monomodal emotion recognition on average, and our presented SLSMKCCA and SSLSMKCCA fusion methods both obtained very high recognition rates, especially for the SSLSMKCCA fusion method. Due to the limited sample number of the GEMEP and Polish databases, the recognition rate of various methods is not high. Therefore, we aimed to build a larger multimodal emotion database that covers facial expressions, speech, and body gestures as modalities and test our presented SLSMKCCA and SSLSMKCCA fusion methods on a larger database in the future. Other future work of interest includes transfer learning and generative adversarial network topologies to better cope with the data sparseness faced. In addition, we also consider applying the SLSMKCCA and SSLSMKCCA algorithms to practical multimodal scenarios. In real-world settings, the proposed SLSMKCCA and SSLSMKCCA algorithms can accommodate additional modalities such as four or more modalities, demonstrating a certain degree of robustness. Moreover, our SSLSMKCCA algorithm incorporates a sparse term (L1 Norm) to select features and eliminate irrelevant noise.
Author Contributions
Conceptualization, J.Y.; methodology, J.Y.; software, P.L.; validation, J.Y., P.L. and C.D.; formal analysis, X.Z.; investigation, Y.L.; data curation, K.Z. and P.L.; writing—original draft preparation, P.L., C.D. and X.Z.; writing—review and editing K.Z., X.Z. and J.W.; supervision, J.Y. and X.Z.; project administration, J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partly supported by the National Natural Science Foundation of China (NSFC) under Grants 61971236, is partly supported by Natural Science Research Start up Foundation of Recruiting Talents of Nanjing University of Posts and Telecommunications (Grant No.NY223030), is partly by Nanjing Science and Technology Innovation Foundation for Overseas Students under Grants NJKCZYZZ2023-04.
Data Availability Statement
Experiments used publicly available datasets.
Conflicts of Interest
Author Xiaoyang Zhou is employed by the company China Mobile Zijin (Jiangsu) Innovation Research Institute Co., Ltd. and Ying Liu is employed by the company China Mobile Communications Group Jiangsu Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Martinel, N.; Micheloni, C.; Piciarelli, C.; Foresti, G.L. Camera selection for adaptive human-computer interface. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 653–664. [Google Scholar] [CrossRef]
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Yan, J.; Lu, G.; Li, H.; Wang, S. Bimodal emotion recognition based on facial expression and speech. J. Nanjing Univ. Post Telecommun. 2018, 38, 60–65. (In Chinese) [Google Scholar]
- Bian, Z.P.; Hou, J.; Chau, L.P.; Magnenat-Thalmann, N. Facial position and expression-based human-computer interface for persons with tetraplegia. IEEE J. Biomed. Health Inform. 2016, 20, 915–924. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Quadflieg, S. In our own image? emotional and neural processing differences when observing human-human vs. human-robot interactions. Soc. Cogn. Affect. Neurosci. 2015, 10, 1515–1524. [Google Scholar] [CrossRef]
- Hill, J.; Ford, W.R.; Farreras, I.G. Real conversations with artificial intelligence: A comparison between human-human online conversations and human-chatbot conversations. Comput. Hum. Behav. 2015, 49, 245–250. [Google Scholar] [CrossRef]
- Volante, M.; Babu, S.V.; Chaturvedi, H.; Newsome, N.; Ebrahimi, E.; Roy, T.; Daily, S.B.; Fasolino, T. Effects of virtual human appearance fidelity on emotion contagion in affective inter-personal simulations. IEEE Trans. Vis. Comput. Graph. 2016, 4, 1326–1335. [Google Scholar] [CrossRef]
- Yan, J.; Zheng, W.; Xin, M.; Qiu, W. Bimodal emotion recognition based on body gesture and facial expression. J. Image Graph. 2013, 18, 1101–1106. (In Chinese) [Google Scholar]
- Gunes, H.; Piccardi, M. From monomodal to multimodal: Affect recognition using visual modalities. In Intelligent Environments; Springer: London, UK, 2009; pp. 154–182. [Google Scholar]
- Gunes, H.; Piccardi, M.; Pantic, M. From the lab to the real world: Affect recognition using multiple cues and modalities. In Affective Computing: Focus on Emotion Expression, Synthesis, and Recognition; InTech Education and Publishing: Vienna, Austria, 2008; pp. 185–218. [Google Scholar]
- Yan, J.; Zheng, W.; Xin, M.; Yan, J. Integrating facial expression and body gesture in videos for emotion recognition. IEICE Trans. Inf. Syst. 2014, E95-D, 610–613. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Zeng, Z.; Tu, J.; Liu, M.; Huang, T.S.; Pianfetti, B.; Roth, D.; Levinson, S. Audio-visual affect recognition. IEEE Trans. Multimed. 2007, 9, 424–428. [Google Scholar] [CrossRef]
- Soleymani, M.; Garcia, D.; Jou, B.; Schuller, B.; Chang, S.F.; Pantic, M. A survey of multimodal sentiment analysis. Image Vis. Comput. 2017, 65, 3–14. [Google Scholar] [CrossRef]
- Yan, J.; Lu, G.; Bai, X.; Li, H.; Sun, N.; Liang, R. A novel supervised bimodal emotion recognition approach based on facial expression and body gesture. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2018, E101-A, 2003–2006. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef]
- Caridakis, G.; Castellano, G.; Kessous, L.; Raouzaiou, A.; Malatesta, L.; Asteriadis, S.; Karpouzis, K. Multimodal emotion recognition from expressive faces, body gestures and speech. In Proceedings of the 2007 International Conference on Artificial Intelligence Applications and Innovations, Los Angeles, CA, USA, 9–13 July 2007; pp. 375–388. [Google Scholar]
- Castellano, G.; Kessous, L.; Caridakis, G. Emotion recognition through multiple modalities: Face, body gesture, speech. In Affect and Emotion in Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2008; pp. 92–103. [Google Scholar]
- Yan, J.; Yan, B.; Lu, G.; Xu, Q.; Li, H.; Cheng, X.; Ca, X. Convolutional neural networks and feature fusion for bimodal emotion recognition on the emotiW 2016 challenge. In Proceedings of the 10th ACM International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–5. [Google Scholar]
- Sariyanidi, E.; Gunes, H.; Cavallaro, A. Automatic analysis of facial affect: A survey of registration, representation, and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1113–1133. [Google Scholar] [CrossRef]
- D’mello, S.K.; Kory, J. A review and meta-analysis of multimodal affect detection systems. ACM Comput. Surv. (CSUR) 2015, 47, 43. [Google Scholar] [CrossRef]
- Yan, J.; Zheng, W.; Xu, Q.; Lu, G.; Li, H.; Wang, B. Sparse kernel reduced-rank regression for bimodal emotion recognition from facial expression and speech. IEEE Trans. Multimed. 2016, 18, 1319–1329. [Google Scholar] [CrossRef]
- Zheng, W.; Dong, B.; Lu, B. Multimodal emotion recognition using EEG and eye tracking data. In Proceedings of the 36th Annual International Conference on Engineering in Medicine and Biology Society (EMBC), Chicago, IL, USA, 26–30 August 2014; pp. 5040–5043. [Google Scholar]
- Zhang, Z.; Ringeval, F.; Dong, B.; Coutinho, E.; Marchi, E.; Schüller, B. Enhanced semi-supervised learning for multimodal emotion recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5185–5189. [Google Scholar]
- Yan, J.; Wang, B.; Liang, R. A novel bimodal emotion database from physiological signals and facial expression. IEICE Trans. Inf. Syst. 2018, E101-D, 1976–1979. [Google Scholar] [CrossRef]
- Xu, X.; Deng, J.; Coutinho, E.; Wu, C.; Zhao, L.; Schuller, B.W. Connecting subspace learning and extreme learning machine in speech emotion recognition. IEEE Trans. Multimed. 2019, 21, 795–808. [Google Scholar] [CrossRef]
- Luengo, I.; Navas, E.; Hernáez, I. Feature analysis and evaluation for automatic emotion identification in speech. IEEE Trans. Multimed. 2010, 12, 490–501. [Google Scholar] [CrossRef]
- Abdat, F.; Maaoui, C.; Pruski, A. Bimodal system for emotion recognition from facial expressions and physiological signals using feature-level fusion. In Proceedings of the Fifth UKSim European Symposium on Computer Modeling and Simulation (EMS), Madrid, Spain, 16–18 November 2011; pp. 24–29. [Google Scholar]
- Gonzalez-Sanchez, J.; Chavez-Echeagaray, M.E.; Atkinson, R.; Burleson, W. ABE: An agent-based software architecture for a multimodal emotion recognition framework. In Proceedings of the 9th Working IEEE/IFIP Conference on Software Architecture (WICSA), Boulder, CO, USA, 20–24 June 2011; pp. 187–193. [Google Scholar]
- JArora, S.; Chandel, S.S.; Chandra, S. An efficient multi modal emotion recognition system: ISAMC. In Proceedings of the 2014 International Conference on the IMpact of E-Technology on US (IMPETUS), Bangalore, India, 10–11 January 2014; pp. 6–12. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Beyond facial expressions: Learning human emotion from body gestures. In Proceedings of the 2007 British Machine Vision Conference (BMVC), Warwick, UK, 10–13 September 2007; pp. 1–10. [Google Scholar]
- Wang, Y.; Guan, L.; Venetsanopoulos, A.N. Kernel cross-modal factor analysis for information fusion with application to bimodal emotion recognition. IEEE Trans. Multimed. 2012, 14, 597–607. [Google Scholar] [CrossRef]
- Lin, J.; Wu, C.; Wei, W. Error weighted semi-coupled hidden markov model for audio-visual emotion recognition. IEEE Trans. Multimed. 2012, 14, 142–156. [Google Scholar] [CrossRef]
- Batrinca, L.; Mana, N.; Lepri, B.; Sebe, N.; Pianesi, F. Multimodal personality recognition in collaborative goal-oriented tasks. IEEE Trans. Multimed. 2016, 18, 659–673. [Google Scholar] [CrossRef]
- Metallinou, A.; Lee, S.; Narayanan, S. Decision level combination of multiple modalities for recognition and analysis of emotional expression. In Proceedings of the 2010 International Conference on Acoustics Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 2462–2465. [Google Scholar]
- Kessous, L.; Castellano, G.; Caridakis, G. Multimodal emotion recognition in speech-based interaction using facial expression, body gesture and acoustic analysis. J. Multimodal User Interfaces 2010, 3, 33–48. [Google Scholar] [CrossRef]
- Nicolaou, M.A.; Gunes, H.; Pantic, M. Continuous prediction of spontaneous affect from multiple cues and modalities in valence-arousal space. IEEE Trans. Affective Comput. 2011, 2, 92–105. [Google Scholar] [CrossRef]
- Özkul, S.; Bozkurt, E.; Asta, S.; Yemez, Y.; Erzin, E. Multimodal analysis of upper-body gestures, facial expressions and speech. In Proceedings of the 4th International Workshop on Corpora for Research on Emotion Sentiment and Social Signals, Istanbul, Turkey, 26 May 2012; pp. 62–66. [Google Scholar]
- Ghayoumi, S.M.; Thafar, M.; Bansal, A.K. Towards formal multimodal analysis of emotions for affective computing. In Proceedings of the International Conference on Distributed Multimedia Systems (DMS), Salerno, Italy, 25–26 November 2016; pp. 48–54. [Google Scholar]
- Wagner, J.; Andre, E.; Lingenfelser, F.; Kim, J. Exploring fusion methods for multimodal emotion recognition with missing data. IEEE Trans. Affective Comput. 2011, 2, 206–218. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal Database of Emotional Speech, Video and Gestures. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 153–163. [Google Scholar]
- Banziger, T.; Mortillaro, M.; Scherer, K.R. Introducing the geneva multimodal expression corpus for experimental research on emotion perception. Emotion 2012, 12, 1161–1179. [Google Scholar] [CrossRef] [PubMed]
- Banziger, T.; Scherer, K.R. Introducing the geneva multimodal emotion portrayal (GEMEP) Corpus. In A Blueprint for Affective Computing a Sourcebook; Oxford University Press: Oxford, UK, 2010; pp. 271–294. [Google Scholar]
- Yu, H.; Huang, G.; Gao, J. Nonlinear blind source separation using kernel multi-set canonical correlation analysis. Int. J. Comput. Netw. Inf. Secur. 2010, 2, 1–8. [Google Scholar] [CrossRef]
- Muñoz-Marí, J.; Gómez-Chova, L.; Amorós, J.; Izquierdo, E.; Camps-Valls, G. Multiset kernel CCA for multitemporal image classification. In Proceedings of the 7th International Workshop on the Analysis of Multi-temporal Remote Sensing Images (Multi-Temp), Banff, AB, Canada, 25–27 June 2013; pp. 1–4. [Google Scholar]
- Yan, J.; Wang, X.; Gu, W.; Ma, L. Speech emotion recognition based on sparse representation. Arch. Acoust. 2013, 38, 465–470. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J. Spectral regression: A unified approach for sparse subspace learning. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM), Omaha, NE, USA, 28–31 October 2007; pp. 73–82. [Google Scholar]
- Zheng, W.; Xin, M.; Wang, X.; Wang, B. A novel speech emotion recognition method via incomplete sparse least square regression. IEEE Signal Process. Lett. 2014, 21, 569–572. [Google Scholar] [CrossRef]
- Yan, J.; Zheng, W.; Xin, M.; Yan, Y. Facial expression recognition based on sparse locality preserving projection. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2014, E97-A, 1650–1653. [Google Scholar] [CrossRef]
- Da la Torre, F. A least-squares framework for component analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1041–1055. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.; Da la Torre, F. Bilinear kernel reduced rank regression for facial expression synthesis. In Proceedings of the 11th European conference on Computer vision (ECCV), Heraklion Crete, Greece, 5–11 September 2010; pp. 364–377. [Google Scholar]
- Lin, Z.; Chen, M.; Ma, Y. The Augmented Lagrange Multiplier Method for Exact Recovery of Corrupted Low-Rank Matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Huang, D.; Cabral, R.S.; Da la Torre, F. Robust regression. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 363–375. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.; Yan, B.; Liang, R.; Lu, G.; Li, H.; Xie, S. Facial expression recognition via regression-based robust locality preserving projections. IEICE Trans. Inf. Syst. 2018, E101-D, 564–567. [Google Scholar] [CrossRef]
- Nicolaou, M.A.; Panagakis, Y.; Zafeiriou, S.; Pantic, M. Robust canonical correlation analysis: Audio-visual fusion for learning continuous interest. In Proceedings of the 39th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1522–1526. [Google Scholar]
- Zheng, W. Multi-view facial expression recognition based on group sparse reduced-rank regression. IEEE Trans. Affect. Comput. 2014, 5, 71–85. [Google Scholar] [CrossRef]
- Kettenring, J.R. Canonical analysis of several sets of variables. Biometrika 1971, 58, 433–451. [Google Scholar] [CrossRef]
- Hardoon, D.R.; Szedmak, S.; Shawe-Taylor, J. Canonical correla- tion analysis: An overview with application to learning methods. Neu-Ral Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef]
- Rupnik, J.; Shawe-Taylor, J. Multi-view canonical correlation analysis. In Proceedings of the 39th IEEE International Conference on Data Mining and Data Warehouses (SiKDD), Ljubljana, Slovenia, 12 October 2010; pp. 1–4. [Google Scholar]
- Via, J.; Santamaria, I.; Perez, J. A learning algorithm for adaptive canonical correlation analysis of several data sets. Neural Netw. 2008, 20, 139–152. [Google Scholar] [CrossRef]
- Li, Y.O.; Adali, T.; Wang, W.; Calhoun, V.D. Joint blind source separation by multiset canonical correlation analysis. IEEE Trans. Signal Process. 2009, 57, 3918–3929. [Google Scholar] [CrossRef]
- Nielsen, A. Multiset canonical correlations analysis and multispectral, truly multitemporal remote sensing data. IEEE Trans. Image Process. 2002, 11, 293–305. [Google Scholar] [CrossRef] [PubMed]
- Jing, X.; Li, S.; Lan, C.; Zhang, D.; Yang, J.; Liu, Q. Color image canonical correlation analysis for face feature extraction and recognition. Signal Process. 2011, 91, 2132–2140. [Google Scholar] [CrossRef]
- Yuan, Y.H.; Sun, Q.S.; Zhou, Q.; Xia, D.S. A novel multiset integrated canonical correlation analysis framework and its application in feature fusion. Pattern Recognit. 2010, 44, 1031–1040. [Google Scholar] [CrossRef]
- Huang, X.; Wang, C.; Zheng, W. An information fusion and recognition method for color face images. J. Image Graph. 2010, 15, 422–428. (In Chinese) [Google Scholar]
- Bach, F.R.; Jordan, M.I. Kernel independent component analysis. J. Mach. Learn. Res. 2003, 3, 1–48. [Google Scholar]
- Yamanishi, Y.; Vert, J.P.; Nakaya, A.; Kanehisa, M. Extraction of correlated gene clusters from multiple genomic data by generalized kernel canonical correlation analysis. Bioinformatics 2003, 19, 323–330. [Google Scholar] [CrossRef]
- Yu, S.; Moor, B.D.; Moreau, Y. Learning with heterogenous data sets by weighted multiple kernel canonical correlation analysis. In Proceedings of the 2007 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Thessaloniki, Greece, 27–29 August 2007; pp. 81–86. [Google Scholar]
- Witten, D.M.; Tibshirani, R.J. Extensions of sparse canonical correlation analysis with applications to genomic data. Stat. Appl. Genet. Mol. Biol. 2009, 8, 1–27. [Google Scholar] [CrossRef]
- Gross, S.M.; Tibshirani, R. Collaborative regression. Biostatistics 2014, 16, 326–338. [Google Scholar] [CrossRef]
- Luo, C.; Liu, J.; Dey, D.K.; Chen, K. Canonical variate regression. Biostatistics 2016, 17, 468–483. [Google Scholar] [CrossRef]
- Hu, W.; Lin, D.; Cao, S.; Liu, J.; Chen, J.; Calhoun, V.D.; Wang, Y.P. Adaptive sparse multiple canonical correlation analysis with application to imaging (epi) genomics study of schizophrenia. IEEE Trans. Biomed. Eng. 2018, 65, 390–399. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dollar, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatiotemporal features. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance VS-PETS, Beijing, China, 15–16 October 2005; pp. 65–72. [Google Scholar]
- Eyben, F.; Wollmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the ACM International Conference on Multimedia, Firenze, Italy, 29 October 2010; pp. 1459–1462. [Google Scholar]
- Gunes, H.; Piccardi, M. Bi-modal emotion recognition from expressive face and body gestures. J. Netw. Comput. Appl. 2007, 30, 1334–1345. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).