
Zero-Shot Image Caption Inference System Based on Pretrained Models


Abstract
1. Introduction
2. Related Work
3. Framework of Image Captioning with Zero-Shot
3.1. Formulation of Task: Image Captioning
3.2. Introduction of Framework
| Algorithm 1 Zero-shot captioning generation with fixed length |
|
4. Analysis and Improvement
4.1. Analysis of Framework
4.2. Improvement
| Algorithm 2 Algorithm of Our Method |
|
5. Experiment Design and Details
5.1. Dataset
5.2. Implementation Detail
5.3. Zero-Shot Ability with Standard Image Captioning
5.4. Emotional Zero-Shot Image Caption
6. Experiment Results
6.1. Quantitative Experiment Results
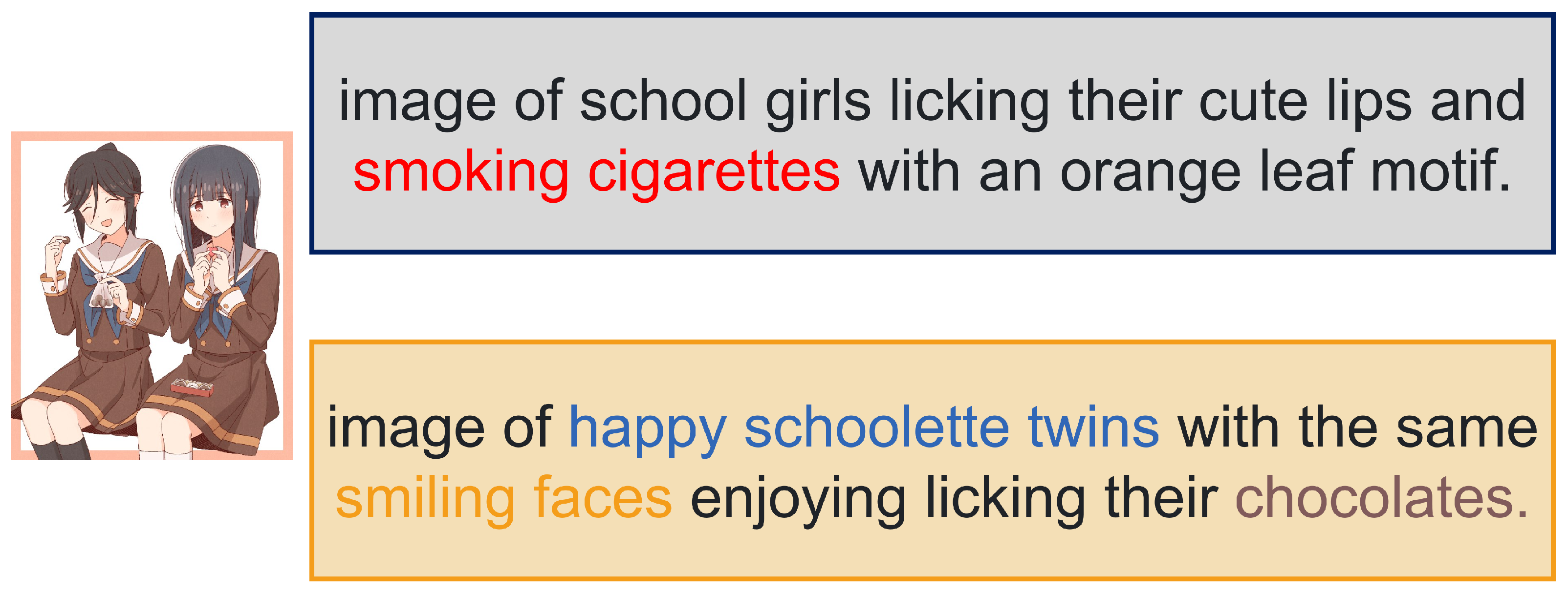
6.2. Qualitative Result
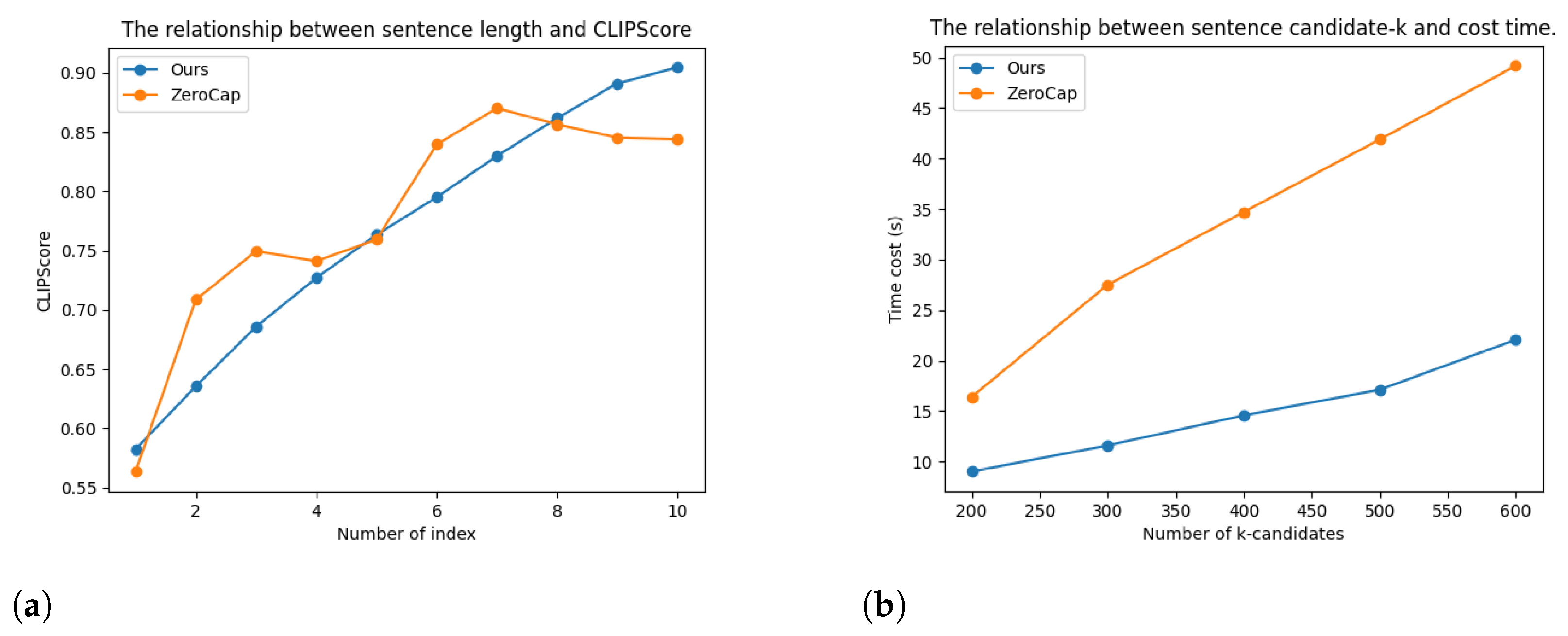
6.3. Performance on Speed
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghandi, T.; Pourreza, H.; Mahyar, H. Deep Learning Approaches on Image Captioning: A Review. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Dognin, P.; Melnyk, I.; Mroueh, Y.; Padhi, I.; Rigotti, M.; Ross, J.; Schiff, Y.; Young, R.A.; Belgodere, B. Image Captioning as an Assistive Technology: Lessons Learned from VizWiz 2020 Challenge. J. Artif. Int. Res. 2022, 73, 437–459. [Google Scholar] [CrossRef]
- Sidorov, O.; Hu, R.; Rohrbach, M.; Singh, A. TextCaps: A Dataset for Image Captioning with Reading Comprehension. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 742–758. [Google Scholar]
- Gurari, D.; Zhao, Y.; Zhang, M.; Bhattacharya, N. Captioning Images Taken by People Who Are Blind. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 417–434. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 121–137. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 457–468. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence pefrspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Zhao, W.; Wu, X.; Zhang, X. Memcap: Memorizing style knowledge for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12984–12992. [Google Scholar]
- Li, H.; Li, X.; Wang, W. Research on Image Caption of Children’s Image Based on Attention Mechanism. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 28–30 June 2021; pp. 182–186. [Google Scholar]
- Luo, R.C.; Hsu, Y.T.; Ye, H.J. Multi-modal human-aware image caption system for intelligent service robotics applications. In Proceedings of the 2019 IEEE 28th International Symposium on Industrial Electronics (ISIE), Vancouver, BC, Canada, 12–14 June 2019; pp. 1180–1185. [Google Scholar]
- Luo, R.C.; Hsu, Y.T.; Wen, Y.C.; Ye, H.J. Visual image caption generation for service robotics and industrial applications. In Proceedings of the 2019 IEEE International Conference on Industrial Cyber Physical Systems (ICPS), Taibei, Taiwan, 6–9 May 2019; pp. 827–832. [Google Scholar]
- Tewel, Y.; Shalev, Y.; Schwartz, I.; Wolf, L. Zerocap: Zero-shot image-to-text generation for visual-semantic arithmetic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 17918–17928. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International conference on machine learning. PMLR, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Rohrbach, A.; Hendricks, L.A.; Burns, K.; Darrell, T.; Saenko, K. Object hallucination in image captioning. arXiv 2018, arXiv:1809.02156. [Google Scholar]
- Stefanini, M.; Cornia, M.; Baraldi, L.; Cascianelli, S.; Fiameni, G.; Cucchiara, R. From show to tell: A survey on deep learning-based image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 539–559. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3128–3137. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Jiang, W.; Ma, L.; Jiang, Y.G.; Liu, W.; Zhang, T. Recurrent fusion network for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 499–515. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Utah, UT, USA, 19–21 June 2018; pp. 6077–6086. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Shi, Z.; Zhou, X.; Qiu, X.; Zhu, X. Improving Image Captioning with Better Use of Caption. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7454–7464. [Google Scholar]
- Yang, X.; Zhang, H.; Cai, J. Learning to collocate neural modules for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 Octber–2 November 2019; pp. 4250–4260. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled transformer for image captioning. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 Octber–2 November 2019; pp. 8928–8937. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. Clipcap: Clip prefix for image captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3156–3164. [Google Scholar]
- Ge, H.; Yan, Z.; Zhang, K.; Zhao, M.; Sun, L. Exploring overall contextual information for image captioning in human-like cognitive style. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1754–1763. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Zhu, X.; Wang, W.; Guo, L.; Liu, J. AutoCaption: Image captioning with neural architecture search. arXiv 2020, arXiv:2012.09742. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ji, J.; Luo, Y.; Sun, X.; Chen, F.; Luo, G.; Wu, Y.; Gao, Y.; Ji, R. Improving image captioning by leveraging intra-and inter-layer global representation in transformer network. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 1655–1663. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 10578–10587. [Google Scholar]
- Tu, H.; Yang, B.; Zhao, X. Zerogen: Zero-shot multimodal controllable text generation with multiple oracles. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Foshan, China, 14–15 October 2023; pp. 494–506. [Google Scholar]
- Li, W.; Zhu, L.; Wen, L.; Yang, Y. DeCap: Decoding CLIP Latents for Zero-Shot Captioning via Text-Only Training. In Proceedings of the The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023; pp. 114–514. [Google Scholar]
- Ma, Y.; Ji, J.; Sun, X.; Zhou, Y.; Hong, X.; Wu, Y.; Ji, R. Image Captioning via Dynamic Path Customization. arXiv 2024, arXiv:2406.00334. [Google Scholar] [CrossRef]
- Guo, S.; Wang, Y.; Ye, J.; Zhang, A.; Xu, K. Semantic Importance-Aware Communications with Semantic Correction Using Large Language Models. arXiv 2024, arXiv:2405.16011. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. Available online: https://insightcivic.s3.us-east-1.amazonaws.com/language-models.pdf (accessed on 14 February 2019).
- Xiao, Y.; Wu, L.; Guo, J.; Li, J.; Zhang, M.; Qin, T.; Liu, T.y. A survey on non-autoregressive generation for neural machine translation and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11407–11427. [Google Scholar] [CrossRef] [PubMed]
- LeDoux, J.E. Brain mechanisms of emotion and emotional learning. Curr. Opin. Neurobiol. 1992, 2, 191–197. [Google Scholar] [CrossRef] [PubMed]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 June 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Hessel, J.; Holtzman, A.; Forbes, M.; Bras, R.L.; Choi, Y. Clipscore: A reference-free evaluation metric for image captioning. arXiv 2021, arXiv:2104.08718. [Google Scholar]
- Su, Y.; Lan, T.; Liu, Y.; Liu, F.; Yogatama, D.; Wang, Y.; Kong, L.; Collier, N. Language Models Can See: Plugging Visual Controls in Text Generation. arXiv 2022, arXiv:2205.02655. [Google Scholar]
- Nguyen, V.Q.; Suganuma, M.; Okatani, T. Grit: Faster and better image captioning transformer using dual visual features. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXXVI, Tel Aviv, Israel, 25–27 October 2022. pp. 167–184. [Google Scholar]
- Hu, X.; Gan, Z.; Wang, J.; Yang, Z.; Liu, Z.; Lu, Y.; Wang, L. Scaling Up Vision-Language Pretraining for Image Captioning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Louisiana, 21–24 June 2021; pp. 17959–17968. [Google Scholar]
- Gan, C.; Gan, Z.; He, X.; Gao, J.; Deng, L. Stylenet: Generating attractive visual captions with styles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 3137–3146. [Google Scholar]
- Guo, L.; Liu, J.; Yao, P.; Li, J.; Lu, H. Mscap: Multi-style image captioning with unpaired stylized text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, BC, USA, 16–20 June 2019; pp. 4204–4213. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| k | 600 |
| 0.001 | |
| 15 | |
| 1 | |
| temperature | 0.2 |
| Gaussian kernel size 1 | (11, 11) |
| Deviation 1 | 5 |
| Gaussian kernel size 2 | (3, 3) |
| Deviation 2 | 0.5 |
| PyTorch seed | 42 |
| Method | Type | MSCOCO | SentiCap | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Positive | Negative | |||||||||||||
| B-4 | M | C | R | C-S * | B-3 | M | C-S * | A | B-3 | M | C-S * | A | ||
| ClipCap [27] | Sup | 32.15 | 27.1 | 108.35 | 0.81 | 0.77 | / | / | / | / | / | / | / | / |
| MAGIC [46] | Sup | 12.90 | 17.22 | 48.33 | 0.74 | 0.74 | / | / | / | / | / | / | / | / |
| GRIT [47] | Sup | 42.4 | 30.6 | 144.2 | 0.77 | 0.82 | / | / | / | / | / | / | / | / |
| LEMON [48] | Sup | 42.6 | 31.4 | 145.5 | / | / | / | / | / | / | / | / | / | / |
| StyleNet [49] | Sup | / | / | / | / | / | 12.1 | 12.1 | / | 45.2 | 10.6 | 10.9 | / | 56.6 |
| MSCap [50] | Sup | / | / | / | / | / | 16.2 | 16.8 | / | 92.5 | 15.4 | 16.2 | / | 93.4 |
| MemCap [8] | Sup | / | / | / | / | / | 17.0 | 16.6 | / | 96.1 | 18.1 | 15.7 | / | 98.9 |
| ZeroCap [12] | Unsup | 2.60 | 11.50 | 14.60 | 0.79 | 0.87 | / | / | / | / | / | / | / | / |
| Ours | Unsup | 1.14 | 8.80 | 12.0 | 0.83 | 0.91 | 1.87 | 6.89 | 0.95 | 96.8 | 1.69 | 3.30 | 0.88 | 98.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Shen, J.; Wang, Y.; Xiao, J.; Li, J. Zero-Shot Image Caption Inference System Based on Pretrained Models. Electronics 2024, 13, 3854. https://doi.org/10.3390/electronics13193854
Zhang X, Shen J, Wang Y, Xiao J, Li J. Zero-Shot Image Caption Inference System Based on Pretrained Models. Electronics. 2024; 13(19):3854. https://doi.org/10.3390/electronics13193854
Chicago/Turabian StyleZhang, Xiaochen, Jiayi Shen, Yuyan Wang, Jiacong Xiao, and Jin Li. 2024. "Zero-Shot Image Caption Inference System Based on Pretrained Models" Electronics 13, no. 19: 3854. https://doi.org/10.3390/electronics13193854
APA StyleZhang, X., Shen, J., Wang, Y., Xiao, J., & Li, J. (2024). Zero-Shot Image Caption Inference System Based on Pretrained Models. Electronics, 13(19), 3854. https://doi.org/10.3390/electronics13193854