
Unfixed Seasonal Partition Based on Symbolic Aggregate Approximation for Forecasting Solar Power Generation Using Deep Learning

 ,
, 
Abstract
1. Introduction
- We propose a new seasonal partition criterion using the SAX algorithm. By applying data smoothing techniques and SAX, we represent each data feature as SAX symbol patterns. The SAX algorithm serves two key purposes. First, it determines whether a feature is seasonal. Second, it obtains new seasonal criteria based on the SAX symbol patterns.
- We propose a two-layer stacked Long Short-Term Memory (LSTM) network to forecast power generation by partitioning data according to the new seasonal criteria. The optimal LSTM is trained for each newly defined season: spring, summer, autumn, and winter. Subsequently, the seasonal power generation forecasts are aggregated to derive a one-year forecast. The forecast values for one year obtained from each seasonal partition criterion are combined using averaging, weighted averaging, and stacking methods to produce the final forecast value.
- We evaluate the performance of the proposed method with the forecasting results of two real-world datasets; one from Gyeongju, South Korea, and one from California, USA. We compare the performance of a single LSTM without data partitioning, seasonal LSTMs with fixed seasonal partitions, and seasonal LSTMs with unfixed seasonal partitions. The results indicate that our method achieved the highest forecasting accuracy in terms of R-squared (R²), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE). Specifically, our method outperformed the others by 2.2% to 3.5%; and by 1.6% to 6.5% for the Gyeongju and California datasets, respectively.
2. Related Studies
2.1. Methods for General Power Generation Forecasting
2.2. Methods for Power Generation Forecasting by Seasonal Partition
2.3. Methods for Finding Unfixed Seasons
3. Materials and Methods
3.1. Overview
3.2. Data Collection
3.3. Data Preprocessing
3.3.1. Data Cleaning of Gyeongju Dataset
3.3.2. Data Cleaning of California Dataset
3.3.3. Data Normalization
3.4. Seasonal Feature Selection
| Algorithm 1. SAX-based seasonal feature selection |
| Input : Feature data to check if it is a seasonal feature : Daily interval data where is aggregated over the same days : An array containing options for the order of parameters in smoothing Output : Results of checking whether it is a seasonal feature : Final parameters of the smoothing method |
|
3.4.1. Changing Data to Day-Interval
3.4.2. Data Smoothing
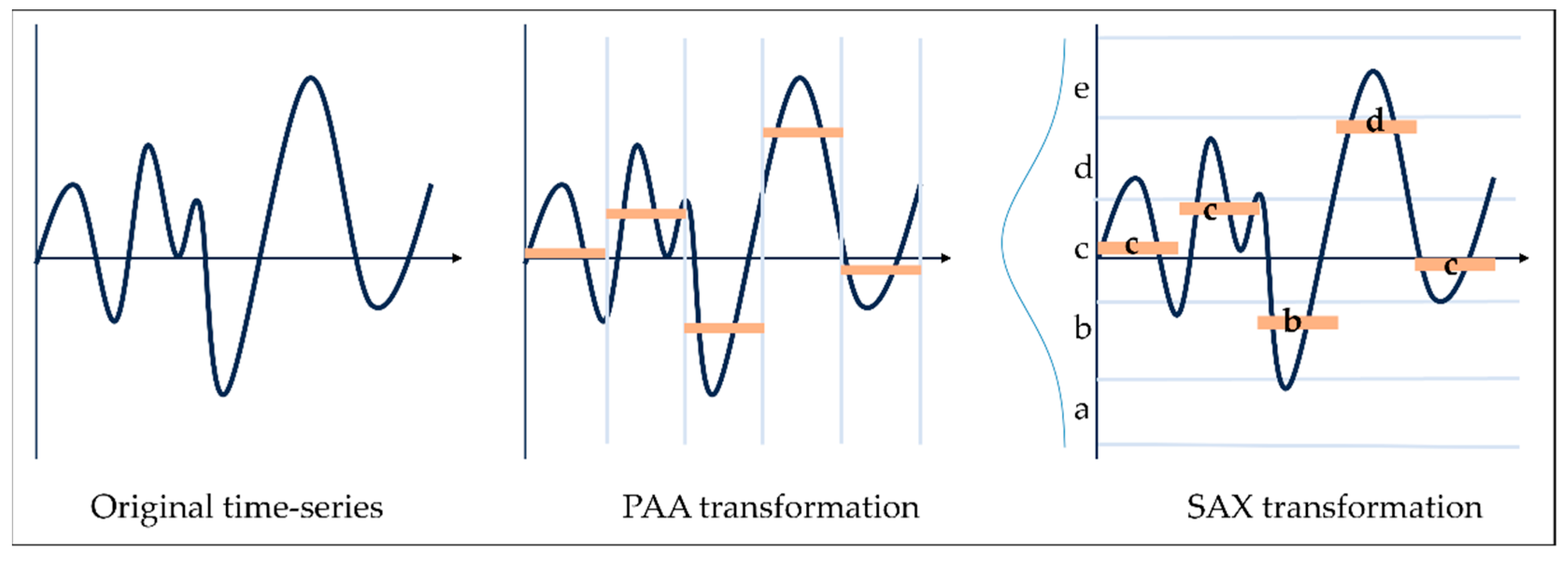
3.4.3. Assigning SAX Symbols
3.4.4. Determining Seasonal Features
- Continuous a symbols are represented as A
- Continuous b symbols are represented as B
- Continuous c symbols are represented as C
3.5. Seasonal Criteria and Data Partition
- The transition point between A and B marks the start of spring
- The transition point between B and C marks the start of summer
- The transition point between C and B marks the start of autumn
- Winter starts on January 1st and at the transition point between B and A
3.6. Training Ensemble LSTM Model
4. Performance Evaluation
4.1. Datasets
4.2. Evaluation Metrics
4.3. Competing Methods
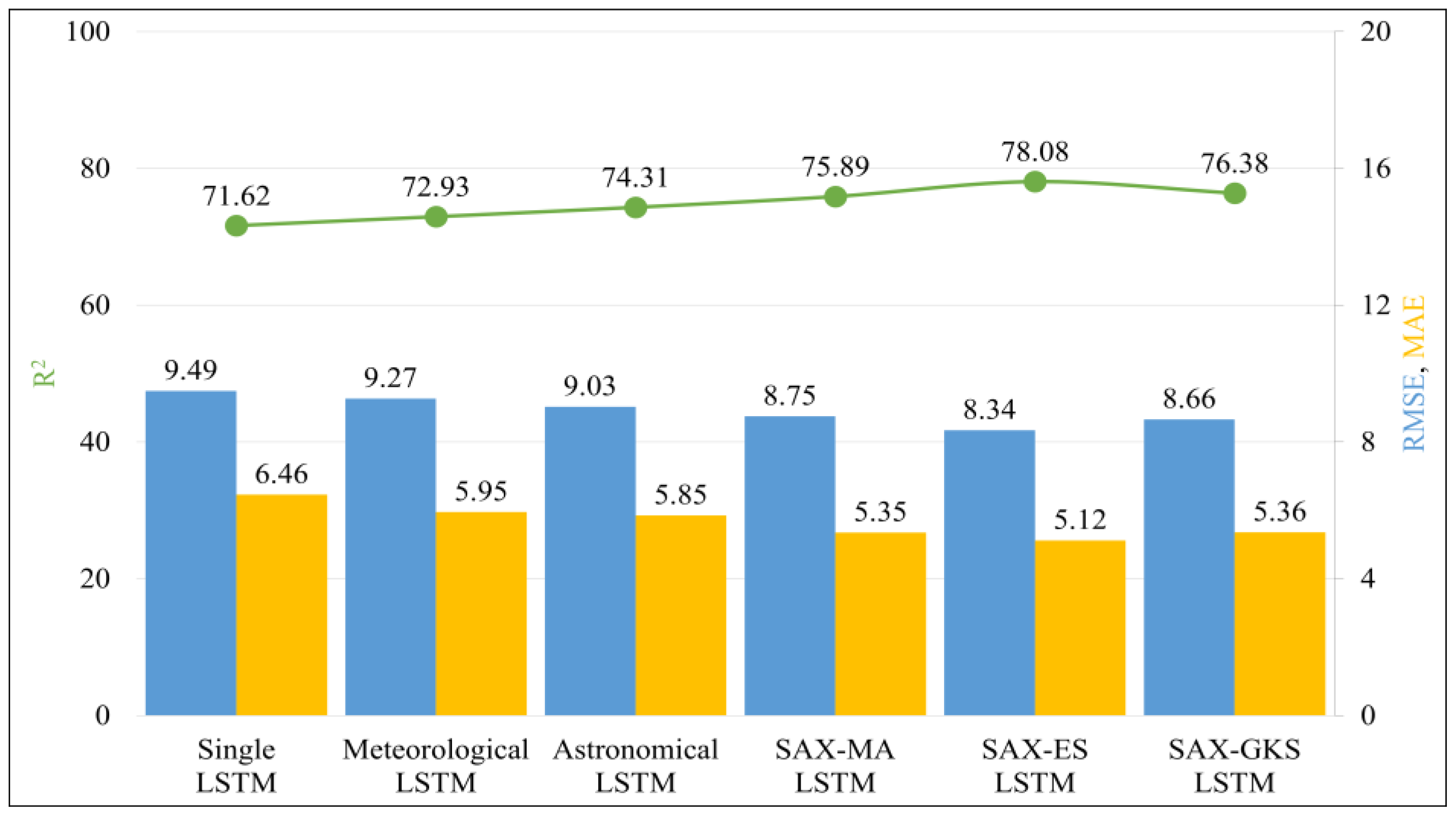
- Single LSTM: This is a method to forecast solar power generation by training an optimal LSTM on the entire dataset, without any data partition.
- Meteorological LSTM: This method divides the data by a fixed season according to the most commonly used criteria, called meteorological: spring, March to May; summer, June to August; autumn, September to November; and winter, December to February. Afterward, the optimal LSTM is trained for each divided data to forecast power generation.
- Astronomical LSTM: This is a method of dividing fixed seasons according to the sun’s position on the celestial sphere astronomically. First, divide the data according to the astronomical seasons. Spring is from 22 March to 21 June, summer is from 22 June to 22 September, autumn is from 23 September to 21 December, and winter is from 22 December to 22 March. Then, the optimal LSTM is trained for each divided data to forecast power generation.
- SAX-MA LSTM: Method using the unfixed seasonal partition based on SAX and the Moving Average smoothing technique.
- SAX-ES LSTM: Method using the unfixed seasonal partition based on SAX and the Exponential Smoothing technique.
- SAX-GKS LSTM: Method using the unfixed seasonal partition based on SAX and the Gaussian Kernel Smoothing technique.
4.4. Experimental Results
4.4.1. Results for Comparing Competing Methods
4.4.2. Results for Ensemble Effects
4.4.3. Results for Recent Methods with Unfixed Data Partition
- TCN is a type of neural network designed to handle sequence data (i.e., time series) using convolutions to learn patterns over time. It captures long-term dependencies efficiently and avoids the problems of LSTM including slow training and vanishing/exploding gradients.
- InceptionTime is a deep learning method that adapts the Inception architecture from image processing. It uses different sized filters to capture patterns in time series sequences. By processing multiple patterns at once, it learns complex time series data quickly and effectively.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kosis Korean Statistical Information Service. Available online: https://kosis.kr/eng/ (accessed on 29 July 2024).
- Doddy Clarke, E.; Sweeney, C. Solar Energy and weather. Weather 2021, 77, 90–91. [Google Scholar] [CrossRef]
- Gopi, A.; Sharma, P.; Sudhakar, K.; Ngui, W.K.; Kirpichnikova, I.; Cuce, E. Weather impact on solar farm performance: A comparative analysis of machine learning techniques. Sustainability 2022, 15, 439. [Google Scholar] [CrossRef]
- Ramirez-Vergara, J.; Bosman, L.B.; Leon-Salas, W.D.; Wollega, E. Predicting on-site solar energy generation using off-site weather stations and deep neural networks. Int. J. Energy Environ. Eng. 2022, 14, 1–13. [Google Scholar] [CrossRef]
- Lim, S.-C.; Huh, J.-H.; Hong, S.-H.; Park, C.-Y.; Kim, J.-C. Solar Power Forecasting using CNN-LSTM hybrid model. Energies 2022, 15, 8233. [Google Scholar] [CrossRef]
- Gopi, A.; Sudhakar, K.; Keng, N.W.; Krishnan, A.R.; Priya, S.S. Performance modeling of the weather impact on a utility-scale PV power plant in a tropical region. Int. J. Photoenergy 2021, 2021, 5551014. [Google Scholar] [CrossRef]
- Hu, Y.; Lian, W.; Han, Y.; Dai, S.; Zhu, H. A seasonal model using optimized multi-layer neural networks to forecast power output of PV plants. Energies 2018, 11, 326. [Google Scholar] [CrossRef]
- Golestaneh, F.; Pinson, P.; Gooi, H.B. Very short-term nonparametric probabilistic forecasting of renewable energy generation—With application to Solar Energy. IEEE Trans. Power Syst. 2016, 31, 3850–3863. [Google Scholar] [CrossRef]
- Moreira, M.O.; Kaizer, B.M.; Ohishi, T.; Bonatto, B.D.; Zambroni de Souza, A.C.; Balestrassi, P.P. Multivariate strategy using artificial neural networks for seasonal photovoltaic generation forecasting. Energies 2022, 16, 369. [Google Scholar] [CrossRef]
- Adusei, K.K.; Ng, K.T.; Mahmud, T.S.; Karimi, N.; Lakhan, C. Exploring the use of astronomical seasons in municipal solid waste disposal rates modeling. Sustain. Cities Soc. 2022, 86, 104115. [Google Scholar] [CrossRef]
- Kutta, E.; Hubbart, J.A. Reconsidering meteorological seasons in a changing climate. Clim. Chang. 2016, 137, 511–524. [Google Scholar] [CrossRef]
- Kwon, J.; Choi, Y. Application of synoptic patterns to the definition of seasons in the Republic of Korea. Int. J. Climatol. 2023, 43, 6268–6284. [Google Scholar] [CrossRef]
- Lee, E.; Im, A.; Oh, J.; Song, M.; Choi, Y.; Choi, D. Improved seasonal definition and projected future seasons in South Korea. Meteorol. Appl. 2022, 29, e2110. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Peng, X.; Qin, H.; Lv, H.; Fu, J.; Wang, H. Solar radiation intensity probabilistic forecasting based on K-means time series clustering and gaussian process regression. IEEE Access 2021, 9, 89079–89092. [Google Scholar] [CrossRef]
- Lin, J.; Keogh, E.; Lonardi, S.; Chiu, B. A symbolic representation of time series, with implications for streaming algorithms. In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, San Diego, CA, USA, 13 June 2003. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, L.; Huang, C.; Zhang, Z.; Luo, X. Soil-moisture-sensor-based automated soil water content cycle classification with a hybrid symbolic aggregate approximation algorithm. IEEE Internet Things J. 2021, 8, 14003–14012. [Google Scholar] [CrossRef]
- Jung, W.-K.; Kim, H.; Park, Y.-C.; Lee, J.-W.; Ahn, S.-H. Smart sewing work measurement system using IOT-based power monitoring device and approximation algorithm. Int. J. Prod. Res. 2019, 58, 6202–6216. [Google Scholar] [CrossRef]
- Chiosa, R.; Piscitelli, M.S.; Capozzoli, A. A data analytics-based Energy Information System (EIS) tool to perform meter-level anomaly detection and diagnosis in buildings. Energies 2021, 14, 237. [Google Scholar] [CrossRef]
- Ruan, H.; Hu, X.; Xiao, J.; Zhang, G. TrSAX—An improved time series symbolic representation for classification. ISA Trans. 2020, 100, 387–395. [Google Scholar] [CrossRef]
- Bai, B.; Li, G.; Wang, S.; Wu, Z.; Yan, W. Time Series classification based on multi-feature dictionary representation and Ensemble Learning. Expert Syst. Appl. 2021, 169, 114162. [Google Scholar] [CrossRef]
- Ozbek, A.; Yildirim, A.; Bilgili, M. Deep Learning Approach for one-hour ahead forecasting of energy production in a solar-PV plant. Energy Sources Part A 2021, 44, 10465–10480. [Google Scholar] [CrossRef]
- Dhaked, D.K.; Dadhich, S.; Birla, D. Power output forecasting of Solar Photovoltaic Plant Using LSTM. Green Energy Intell. Transp. 2023, 2, 100113. [Google Scholar] [CrossRef]
- Hossain, M.S.; Mahmood, H. Short-term photovoltaic power forecasting using an LSTM neural network and synthetic weather forecast. IEEE Access 2020, 8, 172524–172533. [Google Scholar] [CrossRef]
- Li, Y.; Su, Y.; Shu, L. An ARMAX model for forecasting the power output of a grid connected photovoltaic system. Renew. Energy 2014, 66, 78–89. [Google Scholar] [CrossRef]
- Konstantinou, M.; Peratikou, S.; Charalambides, A.G. Solar photovoltaic forecasting of power output using LSTM Networks. Atmosphere 2021, 12, 124. [Google Scholar] [CrossRef]
- Elsaraiti, M.; Merabet, A. Solar power forecasting using Deep Learning Techniques. IEEE Access 2022, 10, 31692–31698. [Google Scholar] [CrossRef]
- Chuluunsaikhan, T.; Kim, J.-H.; Shin, Y.; Choi, S.; Nasridinov, A. Feasibility Study on the influence of data partition strategies on Ensemble Deep Learning: The case of forecasting power generation in South Korea. Energies 2022, 15, 7482. [Google Scholar] [CrossRef]
- Daeyeon C&I Co., Ltd. Available online: http://dycni.com/ (accessed on 29 July 2024).
- Sauter, E. “Modeling PV Power On 6yrs Spatiotemporal Data,” GitHub. Available online: https://github.com/EvanSauter/Modeling-PV-Power-On-6yrs-Spatiotemporal-Data (accessed on 29 July 2024).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sansine, V.; Ortega, P.; Hissel, D.; Ferrucci, F. Hybrid Deep Learning Model for Mean Hourly Irradiance Probabilistic Forecasting. Atmosphere 2023, 14, 1192. [Google Scholar] [CrossRef]
- Meng, H.; Wu, L.; Li, H.; Song, Y. Construction and Research of Ultra-Short Term Prediction Model of Solar Short Wave Irradiance Suitable for Qinghai–Tibet Plateau. Atmosphere 2023, 14, 1150. [Google Scholar] [CrossRef]
- Shaojie, B.; Zico, J.; Vladlen, K. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Wang, Y.; Zhang, C.; Fu, Y.; Suo, L.; Song, S.; Peng, T.; Shahzad Nazir, M. Hybrid solar radiation forecasting model with temporal convolutional network using data decomposition and improved artificial ecosystem-based optimization algorithm. Energy 2023, 280, 128171. [Google Scholar] [CrossRef]
- Perera, M.; De Hoog, J.; Bandara, K.; Senanayake, D.; Halgamuge, S. Day-ahead regional solar power forecasting with hierarchical temporal convolutional neural networks using historical power generation and weather data. Appl. Energy 2024, 361, 122971. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.-A.; Petitjean, F. InceptionTime: Finding alexnet for Time Series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Li, Y.; Yang, C. Multi Time Scale Inception-time network for soft sensor of blast furnace ironmaking process. J. Process Control. 2022, 118, 106–114. [Google Scholar] [CrossRef]
- Putkonen, J.; Ahajjam, M.A.; Pasch, T.; Chance, R. A hybrid VMD-wt-InceptionTime model for multi-horizon short-term air temperature forecasting in Alaska. In Proceedings of the EGU23, the 25th EGU General Assembly, Vienna, Austria, 23–28 April 2023. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Gyeongju | California |
|---|---|---|
| Number of features | 6 | 11 |
| Samples | 17,532 | 12,056 |
| Date | 1 January 2017~31 December 2020 | 1 January 2014~31 December 2016 |
| Time | 00:00~23:00 | 10:00~15:00 |
| Unit of time | 1 h | 30 min |
| Power capacity | 1502.55 kWh | 155 kWh |
| Dataset | Mean | Std Dev | Min | Max | Explanation |
|---|---|---|---|---|---|
| Power | 489.71 | 382.08 | 0.00 | 1396.85 | The power output of panels (kW) |
| Irradiance | 297.04 | 244.07 | 0.00 | 975.00 | The amount of radiation on the ground (W/m2) |
| Dew Point | 6.83 | 12.14 | −26.90 | 28.00 | Dew Point (°C) |
| Temperature | 16.10 | 10.14 | −12.90 | 39.20 | Outside temperature (°C) |
| Humidity | 58.62 | 23.18 | 0.00 | 100.00 | The concentration of water vapor present in the air (%) |
| Cloud Cover | 3.09 | 3.97 | 0.00 | 10.00 | Amount of cloud |
| Dataset | Mean | Std Dev | Min | Max | Explanation |
|---|---|---|---|---|---|
| Power | 49.82 | 17.60 | 1.10 | 76.31 | The power output of panels (kW) |
| Irradiance | 677.35 | 243.19 | 4.00 | 1074.00 | The amount of radiation on the ground (W/m2) |
| Dew Point | 7.85 | 4.05 | −8.00 | 20.00 | Dew point (°C) |
| Temperature | 22.95 | 5.17 | 10.00 | 36.00 | Outside temperature (°C). |
| Humidity | 46.00 | 15.73 | 13.65 | 100.00 | The concentration of water vapor present in the air (%) |
| Pressure | 991.70 | 3.95 | 980.00 | 1010.00 | Pressure (mbar) |
| Precipitable | 1.63 | 0.76 | 0.21 | 5.68 | Accumulated amount of water vapor contained in atmospheric space (mm) |
| Wind Speed | 3.29 | 1.54 | 0.00 | 9.60 | The speed of the wind within the atmosphere (m/s) |
| Wind Direction | 247.52 | 71.66 | 0.00 | 359.90 | Wind direction (degrees) |
| Surface Albedo | 0.13 | 0.01 | 0.12 | 0.14 | The fraction of solar radiation that is reflected by the surface of the Earth (degrees) |
| Solar Zenith Angle | 41.47 | 15.69 | 11.01 | 72.74 | the angle between the direct line to the sun and the location |
| Smoothing Technique | Features Identified in Gyeongju Dataset | Features Identified in California Dataset |
|---|---|---|
| Moving Average | Irradiance Dew Point Temperature | Irradiance Solar Zenith Angle Precipitable Temperature Pressure |
| Exponential Smoothing | Dew Point Temperature | Irradiance Solar Zenith Angle Pressure |
| Gaussian Kernel Smoothing | Irradiance Dew Point Temperature | Irradiance Solar Zenith Angle Precipitable Pressure |
| Gyeongju | California | |
|---|---|---|
| Training data | 2017–2019 | 2014–2015 |
| Test data | 2020 | 2016 |
| Parameter | Options | Description |
|---|---|---|
| batch_size | 64, 128 | Number of data samples processed by a model in one training iteration. |
| epochs | 1000 | Total number of dataset iterations |
| patience | 10 | The number of epochs used in early stop |
| learning_rate | 0.01, 0.001 | Learning rate in gradient descent |
| layers | 2 | Number of layers |
| units | 32, 64, 128, 256 | Number of units in each layer |
| optimizer | Adam | Optimizer |
| loss_function | MSE | Loss function |
| Method | R2 | RMSE | MAE | |
|---|---|---|---|---|
| SAX-MA LSTM | Based on Irradiation | 85.65% | 145.76 | 101.69 |
| Based on Dew Point | 86.51% | 141.3 | 99.52 | |
| Based on Temperature | 86.13% | 143.3 | 100.14 | |
| Average Ensemble | 87.87% | 133.71 | 90.95 | |
| Weighted Ensemble | 87.87% | 133.97 | 92.3 | |
| Stacking Ensemble | 87.92% | 133.71 | 90.95 | |
| SAX-ES LSTM | Based on Dew Point | 86.04% | 143.75 | 100.75 |
| Based on Temperature | 86.66% | 140.52 | 95.6 | |
| Average Ensemble | 87.91% | 133.77 | 92.37 | |
| Weighted Ensemble | 87.91% | 133.75 | 92.34 | |
| Stacking Ensemble | 88.04% | 133.04 | 90.22 | |
| SAX-GKS LSTM | Based on Irradiation | 86.75% | 140.02 | 98.99 |
| Based on Dew Point | 85.74% | 145.31 | 99.56 | |
| Based on Temperature | 86.34% | 142.17 | 96.56 | |
| Average Ensemble | 88.00% | 133.25 | 92.21 | |
| Weighted Ensemble | 88.01% | 133.21 | 92.2 | |
| Stacking Ensemble | 88.12% | 132.62 | 91.24 | |
| Method | R2 | RMSE | MAE | |
|---|---|---|---|---|
| SAX-MA LSTM | Based on Irradiation | 73.12% | 9.24 | 5.8 |
| Based on Temperature | 71.22% | 9.56 | 6.1 | |
| Based on Pressure | 72.72% | 9.48 | 6.1 | |
| Based on Precipitable | 68.86% | 9.95 | 6.65 | |
| Based on SZ Angle | 73.87% | 9.11 | 5.74 | |
| Average Ensemble | 75.51% | 8.82 | 5.4 | |
| Weighted Ensemble | 75.54% | 8.82 | 5.39 | |
| Stacking Ensemble | 75.89% | 8.75 | 5.35 | |
| SAX-ES LSTM | Based on Irradiation | 75.83% | 8.76 | 5.52 |
| Based on Pressure | 75.75% | 8.78 | 5.53 | |
| Based on SZ Angle | 73.87% | 9.11 | 5.74 | |
| Average Ensemble | 77.86% | 8.39 | 5.13 | |
| Weighted Ensemble | 77.88% | 8.38 | 5.13 | |
| Stacking Ensemble | 78.08% | 8.34 | 5.12 | |
| SAX-GKS LSTM | Based on Irradiation | 73.68% | 9.14 | 5.83 |
| Based on Pressure | 74.63% | 8.98 | 5.89 | |
| Based on Precipitable | 72.81% | 9.29 | 6.09 | |
| Based on SZ Angle | 73.87% | 9.11 | 5.74 | |
| Average Ensemble | 76.26% | 8.68 | 5.31 | |
| Weighted Ensemble | 76.26% | 8.68 | 5.31 | |
| Stacking Ensemble | 76.38% | 8.66 | 5.36 | |
| Dataset | Method | TCN | InceptionTime | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | R2 | RMSE | MAE | ||
| Gyeongju | Non-partitioned | 81.35% | 166.13 | 116.23 | 68.67% | 215.32 | 164.78 |
| Meteorological | 82.73% | 159.86 | 111.26 | 75.53% | 190.31 | 140.16 | |
| Astronomical | 83.15% | 157.91 | 111.19 | 73.27% | 198.89 | 154.37 | |
| SAX-MA | 84.89% | 149.53 | 105.77 | 80.64% | 169.28 | 125.85 | |
| SAX-ES | 85.27% | 147.64 | 101.84 | 79.61% | 173.73 | 126.84 | |
| SAX-GKS | 84.91% | 149.46 | 101.81 | 81.04% | 167.51 | 114.42 | |
| California | Non-partitioned | 64.06% | 10.69 | 7.34 | 62.99% | 10.84 | 8.26 |
| Meteorological | 68.12% | 10.06 | 6.66 | 60.20% | 11.24 | 8.23 | |
| Astronomical | 69.76% | 9.80 | 6.65 | 62.44% | 10.92 | 8.27 | |
| SAX-MA | 70.36% | 9.70 | 6.22 | 64.34% | 7.73 | 7.73 | |
| SAX-ES | 70.06% | 9.75 | 6.84 | 67.09% | 7.16 | 7.16 | |
| SAX-GKS | 70.80% | 9.63 | 6.33 | 64.41% | 10.63 | 8.00 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwak, M.; Chuluunsaikhan, T.; Marakhimov, A.; Kim, J.-H.; Nasridinov, A. Unfixed Seasonal Partition Based on Symbolic Aggregate Approximation for Forecasting Solar Power Generation Using Deep Learning. Electronics 2024, 13, 3871. https://doi.org/10.3390/electronics13193871
Kwak M, Chuluunsaikhan T, Marakhimov A, Kim J-H, Nasridinov A. Unfixed Seasonal Partition Based on Symbolic Aggregate Approximation for Forecasting Solar Power Generation Using Deep Learning. Electronics. 2024; 13(19):3871. https://doi.org/10.3390/electronics13193871
Chicago/Turabian StyleKwak, Minjin, Tserenpurev Chuluunsaikhan, Azizbek Marakhimov, Jeong-Hun Kim, and Aziz Nasridinov. 2024. "Unfixed Seasonal Partition Based on Symbolic Aggregate Approximation for Forecasting Solar Power Generation Using Deep Learning" Electronics 13, no. 19: 3871. https://doi.org/10.3390/electronics13193871
APA StyleKwak, M., Chuluunsaikhan, T., Marakhimov, A., Kim, J.-H., & Nasridinov, A. (2024). Unfixed Seasonal Partition Based on Symbolic Aggregate Approximation for Forecasting Solar Power Generation Using Deep Learning. Electronics, 13(19), 3871. https://doi.org/10.3390/electronics13193871