

Natural Language Inference with Transformer Ensembles and Explainability Techniques



Abstract
1. Introduction
2. Related Works
3. Methodology
3.1. Fine-Tuned Transformer Models Utilized
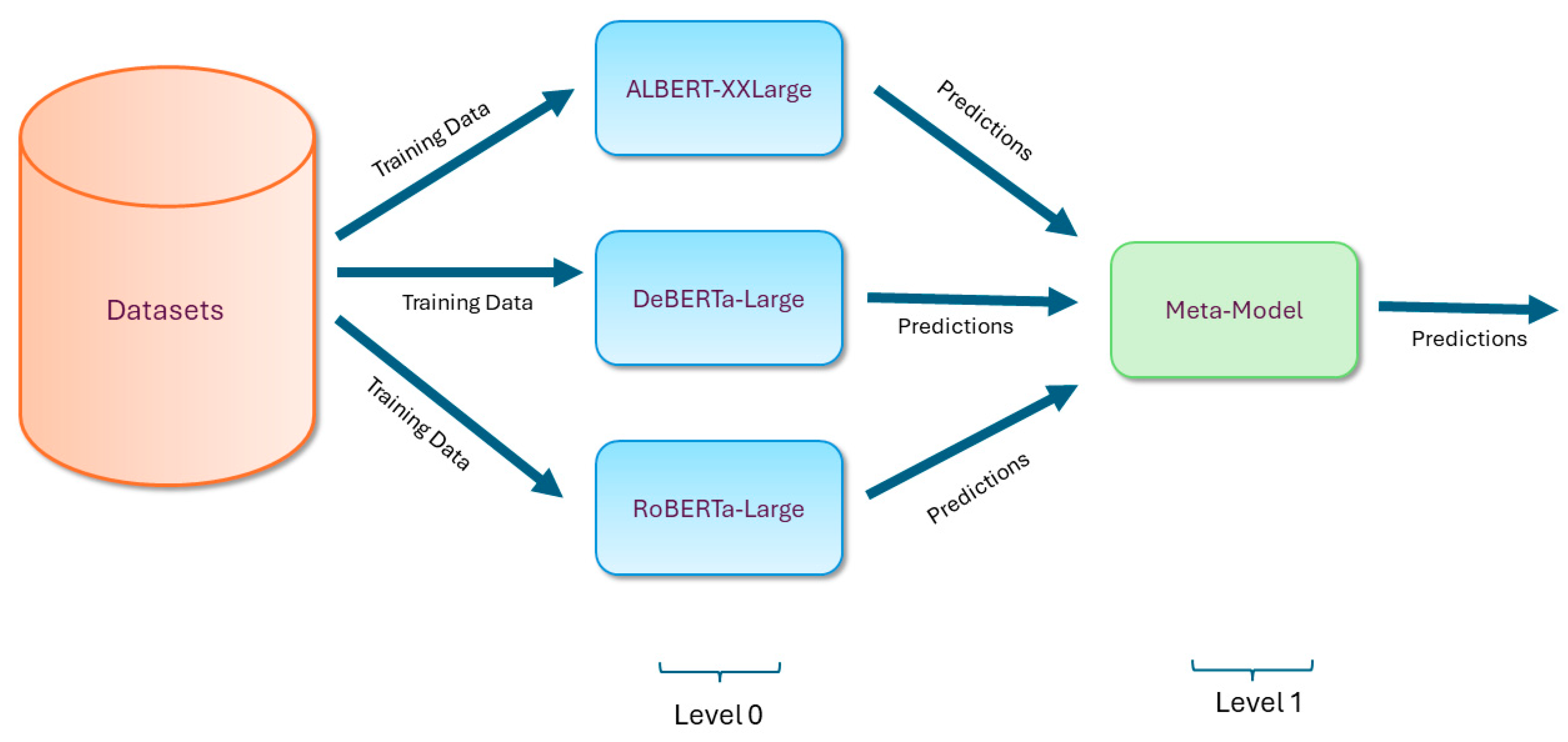
3.2. Ensemble Models Formulated
4. Experimental Study
4.1. Datasets on NLI
4.2. Results Analysis
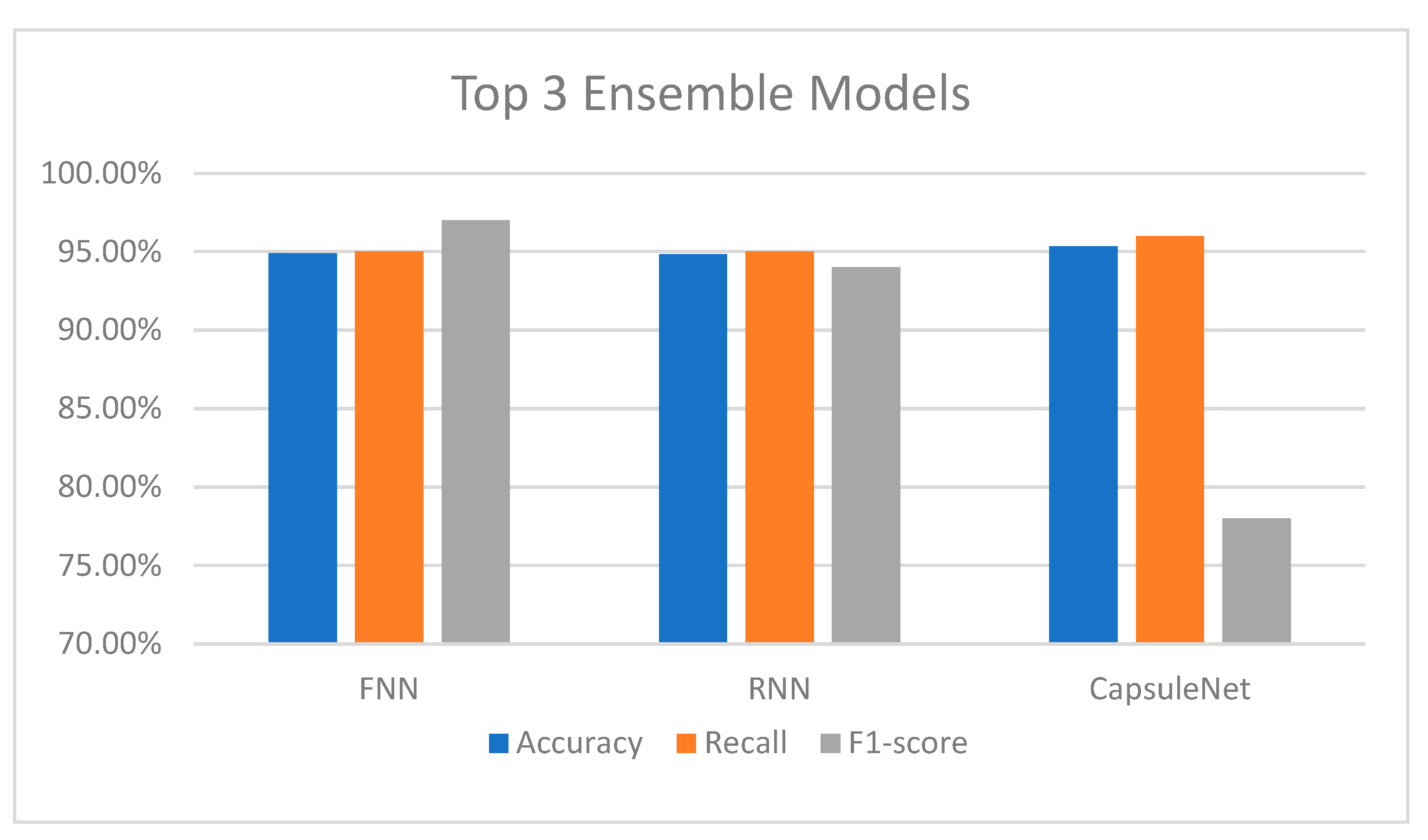
4.3. Results of the Ensemble Models
5. Models Explainability
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brahman, F.; Shwartz, V.; Rudinger, R.; Choi, Y. Learning to rationalize for nonmonotonic reasoning with distant supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 12592–12601. [Google Scholar]
- Torfi, A.; Shirvani, R.A.; Keneshloo, Y.; Tavaf, N.; Fox, E.A. Natural language processing advancements by deep learning: A survey. arXiv 2020, arXiv:2003.01200. [Google Scholar]
- Yu, F.; Zhang, H.; Tiwari, P.; Wang, B. Natural language reasoning, a survey. ACM Comput. Surv. 2023. [Google Scholar] [CrossRef]
- Poliak, A. A survey on recognizing textual entailment as an NLP evaluation. arXiv 2020, arXiv:2010.03061. [Google Scholar]
- Mishra, A.; Patel, D.; Vijayakumar, A.; Li, X.L.; Kapanipathi, P.; Talamadupula, K. Looking beyond sentence-level natural language inference for question answering and text summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 1322–1336. [Google Scholar]
- Liu, X.; Xu, P.; Wu, J.; Yuan, J.; Yang, Y.; Zhou, Y.; Liu, F.; Guan, T.; Wang, H.; Yu, T.; et al. Large language models and causal inference in collaboration: A comprehensive survey. arXiv 2024, arXiv:2403.09606. [Google Scholar]
- Zheng, Y.; Koh, H.Y.; Ju, J.; Nguyen, A.T.; May, L.T.; Webb, G.I.; Pan, S. Large language models for scientific synthesis, inference and explanation. arXiv 2023, arXiv:2310.07984. [Google Scholar]
- Du, M.; He, F.; Zou, N.; Tao, D.; Hu, X. Shortcut learning of large language models in natural language understanding. Commun. ACM 2023, 67, 110–120. [Google Scholar] [CrossRef]
- Guo, M.; Chen, Y.; Xu, J.; Zhang, Y. Dynamic knowledge integration for natural language inference. In Proceedings of the 2022 4th International Conference on Natural Language Processing (ICNLP), IEEE, Xi’an, China, 25–27 March 2022; pp. 360–364. [Google Scholar]
- Gubelmann, R.; Katis, I.; Niklaus, C.; Handschuh, S. Capturing the varieties of natural language inference: A systematic survey of existing datasets and two novel benchmarks. J. Log. Lang. Inf. 2024, 33, 21–48. [Google Scholar] [CrossRef]
- Jullien, M.; Valentino, M.; Frost, H.; O’Regan, P.; Landers, D.; Freitas, A. Semeval-2023 task 7: Multi-evidence natural language inference for clinical trial data. arXiv 2023, arXiv:2305.02993. [Google Scholar]
- Eleftheriadis, P.; Perikos, I.; Hatzilygeroudis, I. Evaluating Deep Learning Techniques for Natural Language Inference. Appl. Sci. 2023, 13, 2577. [Google Scholar] [CrossRef]
- Gubelmann, R.; Niklaus, C.; Handschuh, S. A philosophically-informed contribution to the generalization problem of neural natural language inference: Shallow heuristics, bias, and the varieties of inference. In Proceedings of the 3rd Natural Logic Meets Machine Learning Workshop (NALOMA III), Galway, Ireland, 8–18 August 2022; pp. 38–50. [Google Scholar]
- Assegie, T.A. Evaluation of the Shapley additive explanation technique for ensemble learning methods. Proc. Eng. Technol. Innov. 2022, 21, 20. [Google Scholar] [CrossRef]
- Rajamanickam, S.; Rajaraman, K. I2R at SemEval-2023 Task 7: Explanations-driven Ensemble Approach for Natural Language Inference over Clinical Trial Data. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), Toronto, ON, Canada, 13–14 July 2023; pp. 1630–1635. [Google Scholar]
- Chen, C.-Y.; Tien, K.-Y.; Cheng, Y.-H.; Lee, L.-H. NCUEE-NLP at SemEval-2023 Task 7: Ensemble Biomedical LinkBERT Transformers in Multi-evidence Natural Language Inference for Clinical Trial Data. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), Toronto, ON, Canada, 13–14 July 2023; pp. 776–781. [Google Scholar]
- Zhao, H.; Chen, H.; Yang, F.; Liu, N.; Deng, H.; Cai, H.; Wang, S.; Yin, D.; Du, M. Explainability for large language models: A survey. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–38. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-enhanced bert with disentangled attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in Neural Information Processing Systems 32; NeurIPS: Denver, CO, USA, 2019. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8968–8975. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Zhong, Q.; Ding, L.; Zhan, Y.; Qiao, Y.; Wen, Y.; Shen, L.; Liu, J.; Yu, B.; Du, B.; Chen, Y.; et al. Toward efficient language model pretraining and downstream adaptation via self-evolution: A case study on superglue. arXiv 2022, arXiv:2212.01853. [Google Scholar]
- Proskura, P.; Zaytsev, A. Effective Training-Time Stacking for Ensembling of Deep Neural Networks. In Proceedings of the 2022 5th International Conference on Artificial Intelligence and Pattern Recognition, Xiamen, China, 23–25 September 2022; pp. 78–82. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Malmasi, S.; Dras, M. Native language identification with classifier stacking and ensembles. Comput. Linguist. 2018, 44, 403–446. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Nie, Y.; Williams, A.; Dinan, E.; Bansal, M.; Weston, J.; Kiela, D. Adversarial NLI: A new benchmark for natural language understanding. arXiv 2019, arXiv:1910.14599. [Google Scholar]
- Levesque, H.; Davis, E.; Morgenstern, L. The winograd schema challenge. In Proceedings of the Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, Rome, Italy, 10–14 June 2012. [Google Scholar]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. arXiv 2015, arXiv:1508.05326. [Google Scholar]
- Kim, Y.; Jang, M.; Allan, J. Explaining text matching on neural natural language inference. ACM Trans. Inf. Syst. 2020, 38, 1–23. [Google Scholar] [CrossRef]
- Luo, S.; Ivison, H.; Han, S.C.; Poon, J. Local interpretations for explainable natural language processing: A survey. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’16), San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VARIATIONS | ANLI | MNLI | MNLI-m/MNLI-mm | QNLI | RTE | WNLI | SNLI | |
|---|---|---|---|---|---|---|---|---|
| BERT | -Base | - | 84.0 | 84.6/83.4 | 90.5 | 66.4 | - | - |
| +ASA | 50.4 | 91.4 | - | - | - | - | - | |
| +SMART | - | 85.8 | 85.6/86.0 | 92.7 | 71.2 | - | - | |
| +STraTA, Few-shot learning | - | - | - | 82.1 | 70.6 | - | 85.7 | |
| -Large | - | 86.3 | 86.7/85.9 | 92.7 | 70.1 | - | - | |
| +STraTA | - | - | - | 86.4 | 77.1 | - | 87.3 | |
| ALBERT | -Base V1 | - | 81.6 | - | - | - | - | - |
| -Base V2 | - | 84.6 | - | - | - | - | - | |
| -Large V1 | - | 83.5 | - | 95.2 | - | - | - | |
| -Large V2 | - | 86.5 | - | - | - | - | - | |
| -XLarge V1 | - | 86.4 | - | 95.2 | 88.1 | - | - | |
| -XLarge V2 | - | 87.9 | - | - | - | - | - | |
| -XXLarge V1 | - | 90.8 | - | 95.3 | 89.2 | 91.8 | ||
| -XXLarge V2 | - | 90.6 | - | - | - | - | - | |
| DeBERTa | -Base V1 | - | 88.2 | - | - | - | - | - |
| -Base V3 | - | 90.7 | 90.6/90.7 | - | - | - | - | |
| -Large V1 | 57.6 | 91.2 | 91.3/91.1 | 95.3 | - | - | - | |
| +ASA | 58.2 | - | - | - | - | - | - | |
| -Large V3 | - | 91.9 | 91.8/91.9 | 96.0 | 92.7 | - | - | |
| XLarge V1 | - | 91.4 | 91.5/91.2 | 93.1 | - | 93.2 | - | |
| XLarge V2 | - | 91.7 | 91.7/91.6 | 95.8 | 93.9 | - | - | |
| XXLarge | - | 91.8 | 91.7/91.9 | 96.0 | 93.5 | - | - | |
| +LoRA | - | 91.9 | - | 96.0 | 94.9 | - | - | |
| RoBERTa | -Base | 33.2 | 87.6 | - | 92.8 | 78.7 | - | - |
| +LoRA | - | 87.5 | - | 93.3 | 86.6 | - | - | |
| +MUPPET | - | 88.1 | - | 93.3 | 87.8 | - | - | |
| +InfoBERT (FreeLB) | 34.4 | - | - | - | - | - | - | |
| +InfoBERT (ST) (MNLI + SNLI) | - | 90.5 | 90.5/90.4 | - | - | - | 93.3 | |
| +InfoBERT (AT) (MNLI + SNLI) | - | 90.6 | 90.7/90.4 | - | - | - | 93.1 | |
| +(ST) (MNLI + SNLI) | - | 90.7 | 90.8/90.6 | - | - | - | 92.6 | |
| +(AT) FreeLB (MNLI + SNLI) | - | 90.2 | 90.1/90.3 | - | - | - | 93.4 | |
| +ASA | - | 88.0 | - | 93.4 | - | - | - | |
| -Large | 51.9 | 90.2 | - | 94.7 | 89.5 | - | - | |
| +MNLI | - | 90.2 | - | |||||
| +LoRA | - | 90.6 | - | 94.9 | 87.4 | - | - | |
| +LoRA (finetuned) | - | 90.2 * | - | 94.7 | 86.6 | - | - | |
| +SMART | 57.1 | 91.2 | 91.1/91.3 | 95.6 | 92.0 | - | - | |
| +SMART (MNLI + SNLI + ANLI_FEVER) | 57.1 | - | - | - | - | - | ||
| +EFL | - | - | 94.5 | 90.5 | - | 93.1 | ||
| +ALUM | 57.7 | 90.6 | 90.9/90.2 | 95.1 | - | - | 93.0 | |
| +ALUM and SMART | - | - | - | - | - | - | 93.4 | |
| +I-BERT | - | 90.4 | 90.4/90.3 | 94.5 | 87.0 | - | - | |
| ERNIE | -1.0 | - | 83.6 | 84.0/83.2 | 91.3 | 68.8 | - | - |
| -2.0 (Base) | - | 85.8 | 86.1/85.5 | 92.9 | 74.8 | 65.1 | - | |
| -2.0 (Large) | - | 88.3 | 87.7/88.8 | 94.6 | 85.2 | 67.8 | - | |
| T5 | -Base | 86.7 | 86.7 | 87.1/86.2 | 93.7 | 80.1 | 78.2 | - |
| -Large | 89.8 | 89.8 | 89.9/89.6 | 94.8 | 87.2 | 85.6 | - | |
| +explanation prompting (LP) | 52.8 | - | - | - | - | - | - | |
| +explanation prompting (EP) | 71.0 | - | - | - | - | - | - | |
| -3 B | - | 91.3 | 91.4/91.2 | 96.3 | 91.1 | 89.7 | - | |
| +explanation prompting (EP) | 76.4 | - | - | - | - | - | - | |
| -11 B | - | 92.2 | 92.2/91.9 | 96.9 | 92.8 | 94.5 | - | |
| ELECTRA | -400 K | - | 90.5 | - | 94.5 | 85.9 | - | - |
| -1.75 M | - | 90.9 | - | 95.0 | 88.0 | - | - | |
| XLNet | -Large | - | 88.4 | - | 93.9 | 81.2 | - | - |
| Vega v2 | -Base | - | - | 96.0 | - | - |
| Meta Model | Variation | SNLI ACC/LOSS | MNLI-m ACC/LOSS | MNLI-mm ACC/LOSS | ANLI R1 ACC/LOSS | ANLI R2 ACC/LOSS | ANLI R3 ACC/LOSS |
|---|---|---|---|---|---|---|---|
| Logistic Regression | -Simple | 93.13%/0.21 | 92.00%/0.22 | 91.61%/0.25 | 70.50%/0.70 | 73.50%/0.72 | 69.58%/0.67 |
| -Featured | 93.18%/0.21 | 92.40%/0.22 | 91.66%/0.25 | 72.00%/0.71 | 73.50%/0.73 | 68.75%/0.68 | |
| -Featured E | 93.12%/0.21 | 92.05%/0.22 | 91.76%/0.25 | 71.00%/0.71 | 73.50%/0.74 | 68.75%/0.69 | |
| GBM (XGBoost) | -Simple | 92.84%/0.47 | 92.01%/0.48 | 91.82%/0.31 | 78.00%/0.61 | 67.25%/0.78 | 69.58%/0.79 |
| -Featured | 92.88%/0.54 | 92.30%/0.45 | 91.51%/0.51 | 67.50%/0.87 | 68.50%/0.87 | 73.33%/0.83 | |
| -Featured E | 93.02%/0.59 | 91.90%/0.58 | 91.56%/0.60 | 68.00%/0.83 | 69.50%/0.90 | 75.00%/0.76 | |
| FNN | -Simple | 93.68%/0.20 | 92.26%/0.20 | 91.71%/0.22 | 74.00%/0.70 | 66.00%/0.81 | 61.67%/0.79 |
| -Featured | 96.36%/0.12 | 96.93%/0.13 | 96.44%/0.15 | 74.41%/0.51 | 77.78%/0.66 | 67.92%/0.66 | |
| SVC | -Simple | 93.49%/0.07 | 90.84%/0.10 | 91.77%/0.08 | 77.00%/0.23 | 64.00%/0.36 | 49.17%/0.51 |
| -Featured | 95.53%/0.10 | 96.25%/0.09 | 96.62%/0.08 | 74.42%/0.65 | 68.89%/0.74 | 45.28%/1.33 | |
| RNN | -Simple | 93.23%/0.22 | 91.90%/0.22 | 91.76%/0.26 | 71.50%/0.78 | 74.00%/0.74 | 70.41%/0.68 |
| -Featured | 96.52%/0.12 | 97.10%/0.12 | 96.28%/0.15 | 74.42%/0.54 | 77.78%/0.66 | 66.03%/0.67 | |
| GCN | -Simple | 93.13%/0.21 | 92.10%/0.23 | 91.87%/0.25 | 71.50%/0.71 | 74.50%/0.73 | 70.42%/0.67 |
| -Featured | 95.69%/0.17 | 96.33%/0.15 | 96.70%/0.12 | 82.56%/0.40 | 73.03%/0.65 | 71.70%/0.64 | |
| GAT | -Featured | 95.44%/0.17 | 96.16%/0.15 | 96.62%/0.13 | 83.72%/0.39 | 73.03%/0.65 | 63.70%/0.64 |
| -Enhanced | 95.44%/0.17 | 96.59%/0.16 | 96.62%/0.13 | 83.72/0.45 | 75.28%/0.70 | 72.64%/0.67 | |
| LSTM | -Simple | 93.20%/0.22 | 92.00%/0.23 | 91.80%/0.25 | 71.50%/0.76 | 74.50%/0.75 | 69.20%/0.67 |
| -Featured | 96.19%/0.12 | 96.93%/0.12 | 96.28%/0.15 | 74.42%/0.52 | 77.78%/0.68 | 66.04%/0.68 | |
| -Bidirectional | 96.35%/0.12 | 97.10%/0.12 | 96.45%/0.15 | 74.42%/0.51 | 77.78%/0.66 | 67.90%/0.67 | |
| -Attention | 96.36%/0/12 | 96.93%/0.12 | 96.45%/0.15 | 74.42%/0.50 | 73.33%/0.67 | 66.03%/0.68 | |
| CapsuleNet | -Simple | 93.44%/0.21 | 92.21%/0.22 | 92.12%/0.24 | 72.50%/0.75 | 74.50%/0.76 | 71.25%/0.72 |
| -Featured | 95.69%/0.17 | 96.67%/0.14 | 96.79%/0.12 | 81.40%/0.52 | 71.91%/0.82 | 74.53%/0.75 |
| Meta Model | Variation | SNLI Recall/F1-Score | MNLI-m Recall/F1-Score | MNLI-mm Recall/F1-Score | ANLI R1 Recall/F1-Score | ANLI R2 Recall/F1-Score | ANLI R3 Recall/F1-Score | Combined Tasks Recall/F1-Score |
|---|---|---|---|---|---|---|---|---|
| Logistic Regression | -Simple | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.71/0.71 | 0.74/0.74 | 0.70/0.70 | 0.89/0.89 |
| -Featured | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.72/0.72 | 0.73/0.74 | 0.69/0.68 | 0.90/0.90 | |
| -Featured E | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.71/0.71 | 0.73/0.74 | 0.68/0.68 | 0.90/0.90 | |
| GBM (XGBoost) | -Simple | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.69/0.69 | 0.70/0.70 | 0.70/0.70 | 0.89/0.89 |
| -Featured | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.68/0.67 | 0.69/0.69 | 0.73/0.73 | 0.90/0.90 | |
| -Featured E | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.68/0.68 | 0.69/0.70 | 0.75/0.75 | 0.92/0.92 | |
| FNN | -Simple | 0.95/0.93 | 0.93/0.92 | 0.92/0.91 | 0.75/0.71 | 0.66/0.61 | 0.64/0.54 | 0.90/0.89 |
| -Featured | 0.96/0.98 | 0.97/0.98 | 0.96/0.98 | 0.72/0.82 | 0.71/0.92 | 066/0.88 | 0.95/0.97 | |
| SVC | -Simple | 0.94/0.93 | 0.91/0.91 | 0.92/0.92 | 0.77/0.77 | 0.64/0.65 | 0.50/0.48 | 0.89/0.90 |
| -Featured | 0.72/0.75 | 0.66/0.65 | 0.67/0.66 | 0.66/0.61 | 0.62/0.61 | 0.33/0.21 | 0.70/0.72 | |
| RNN | -Simple | 0.93/0.92 | 0.92/0.92 | 0.92/0.91 | 0.70/0.68 | 0.69/0.69 | 0.69/0.68 | 0.89/0.89 |
| -Featured | 0.97/0.96 | 0.97/0.96 | 0.96/0.95 | 0.74/0.72 | 0.78/0.77 | 0.68/0.64 | 0.95/0.94 | |
| GCN | -Simple | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.72/0.72 | 0.75/0.75 | 0.70/0.70 | 0.90/0.90 |
| -Featured | 0.77/0.80 | 0.69/0.70 | 0.68/0.69 | 0.79/0.79 | 0.73/0.74 | 0.72/0.70 | 0.74/0.76 | |
| GAT | -Featured | 0.95/0.95 | 0.96/0.95 | 0.97/0.95 | 0.80/0.80 | 0.75/0.75 | 0.74/0.72 | 0.95/0.94 |
| -Enhanced | 0.95/0.05 | 0.97/0.96 | 0.96/0.95 | 0.84/0.84 | 0.75/0.75 | 0.73/0.70 | 0.95/0.94 | |
| LSTM | -Simple | 0.93/0.93 | 0.92/0.92 | 0.92/0.92 | 0.72/0.72 | 0.74/0.75 | 0.69/0.69 | 0.89/0.89 |
| -Featured | 0.79/0.81 | 0.70/0.72 | 0.70/0.71 | 0.69/0.68 | 0.74/0.74 | 0.66/0.61 | 0.74/0.76 | |
| -Bidirectional | 0.78/0.81 | 0.72/0.75 | 0.70/0.71 | 0.69/0.68 | 0.76/0.76 | 0.64/0.60 | 0.73/0.76 | |
| -Attention | 0.78/0.80 | 0.72/0.75 | 0.70/0.71 | 0.69/0.68 | 0.76/0.76 | 0.65/0.60 | 0.74/0.76 | |
| CapsuleNet | -Simple | 0.93/0.93 | 0.91/0.91 | 0.92/0.92 | 0.70/0.70 | 0.74/0.74 | 0.70/0.70 | 0.89/0.89 |
| -Featured | 0.96/0.81 | 0.96/0.71 | 0.97/0.69 | 0.86/0.80 | 0.76/0.73 | 0.78/0.72 | 0.96/0.78 |
| Meta Model | Variation | Accuracy Combined | Loss Combined | Cross Validation Accuracy | Cross Validation Loss | Folds | Features |
|---|---|---|---|---|---|---|---|
| Logistic Regression | -Simple | 89.32% | 0.31 | 89.72% | 0.31 | 5 | - |
| -Featured | 90.05% | 0.29 | 90.07% | 0.28 | 5 | Prediction Difference | |
| -Featured E | 89.97% | 0.29 | 90.00% | 0.29 | 5 | Entropy | |
| GBM (XGBoost) | -Simple | - | - | 90.02% | 0.27 | 5 | - |
| -Featured | 89.95% | 0.54 | 89.00% | 0.60 | 5 | Prediction Difference | |
| -Featured E | 90.05% | 0.63 | 89.96% | 0.67 | 5 | Entropy | |
| FNN | -Simple | 89.67% | 0.28 | - | - | - | - |
| -Featured | 94.89% | 0.16 | - | - | - | Confidence Margin | |
| SVC | -Simple | 89.47% | 0.11 | - | - | - | - |
| -Featured | 94.32% | 0.13 | - | - | - | Confidence Margin | |
| RNN | -Simple | 89.16% | 0.31 | - | - | - | - |
| -Featured | 94.84% | 0.17 | 94.75% | 0.18 | 5 | Confidence Margin | |
| GCN | -Simple | 90.10% | 0.29 | 89.51% | 0.30 | 5 | - |
| -Featured | 94.61% | 0.19 | 94.53% | 0.18 | 5 | Confidence Margin | |
| GAT | -Featured | 94.51% | 0.19 | 94.61% | 0.18 | 5 | Confidence Margin |
| -Enhanced | 94.40% | 0.19 | 94.88% | 0.18 | 5 | Confidence Margin + multi-head attention | |
| LSTM | -Simple | 89.32% | 0.30 | - | - | - | - |
| -Featured | 94.84% | 0.17 | 94.75% | 0.18 | 5 | Confidence Margin | |
| -Bidirectional | 94.84% | 0.17 | 94.75% | 0.17 | 5 | Confidence Margin | |
| -Attention | 94.74% | 0.17 | 94.74% | 0.17 | 5 | Confidence Margin | |
| CapsuleNet | -Simple | 89.44% | 0.30 | - | - | - | - |
| -Featured | 95.33% | 0.16 | - | - | - | Confidence Margin |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perikos, I.; Souli, S. Natural Language Inference with Transformer Ensembles and Explainability Techniques. Electronics 2024, 13, 3876. https://doi.org/10.3390/electronics13193876
Perikos I, Souli S. Natural Language Inference with Transformer Ensembles and Explainability Techniques. Electronics. 2024; 13(19):3876. https://doi.org/10.3390/electronics13193876
Chicago/Turabian StylePerikos, Isidoros, and Spyro Souli. 2024. "Natural Language Inference with Transformer Ensembles and Explainability Techniques" Electronics 13, no. 19: 3876. https://doi.org/10.3390/electronics13193876
APA StylePerikos, I., & Souli, S. (2024). Natural Language Inference with Transformer Ensembles and Explainability Techniques. Electronics, 13(19), 3876. https://doi.org/10.3390/electronics13193876