

Research on Multi-Objective Optimization Methods of Urban Rail Train Automatic Driving Based on NSGA-II

Abstract
1. Introduction
2. Problem Description
3. Model Establishment
3.1. Assumptions and Variables
- (1)
- The train is a mass particle, considering the traction and rotation coefficient;
- (2)
- Stations are abstracted as nodes, and section curves are abstracted as arcs;
- (3)
- The train can output any traction force not greater than the maximum traction force at the current speed.
3.2. Multi-Objective Model Establishment and Constraints
4. Model Solution
4.1. Pareto Optimization Algorithm Implementation
4.1.1. Selection, Crossover, and Mutation
- (1)
- Selection
- (2)
- Crossover
- (3)
- Mutation
4.1.2. Fast Non-Dominated Sorting
4.1.3. Calculation of Crowding Degree
4.1.4. Elite Strategy
4.2. Algorithm Implementation Steps
4.3. Weight Is Calculated by AHP Mahalanobis Distance Method
4.3.1. Hierarchical Analysis Model of Train Operation Process
4.3.2. Weight Allocation by Mahalanobis Distance Method
- (1)
- Build the weight matrix.
- (2)
- The average weight of each performance index given by each expert is calculated, respectively, and then the covariance is calculated according to the average weight, and finally the corresponding inverse matrix of the covariance matrix is obtained.
- (3)
- Calculate Mahalanobis distance. The similarities between the weights determined by different experts can be calculated according to different running stages. The calculation formula is as follows:where represents the Mahalanobis distance value between the weights of performance indicators given by expert and expert , and represent the weight value of each performance indicator given by expert and expert , respectively. As shown in Table 4.
- (4)
- Determine the final weight value.
4.4. Multi-Objective Optimal Solution
5. Experimental Simulation and Result Analysis
5.1. Simulation Parameter Setting
5.2. Simulation Verification and Analysis
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, K.; Yang, F.; Tu, Y.; Wu, S. Multi-objective optimization of urban rail train speed curve based on multi-particle swarm collaboration. J. Railw. 2021, 43, 95–102. [Google Scholar]
- Li, C.; Wang, X.M. ATO control strategy based on particle swarm optimization. J. China Railw. Soc. 2017, 39, 53–58. [Google Scholar]
- Shang, G.W.; Yan, X.; Cai, B.; Wang, J. Multiobjective optimization for train speed trajectory in CTCS High-Speed Railway with hybrid Evolutionary Algorithm. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2215–2225. [Google Scholar] [CrossRef]
- Yang, H.; Liu, H.; Fu, Y. Multi-objective operation optimization for electric multiple unit-based on speed restriction mutation. Neurocomputing 2015, 169, 383–391. [Google Scholar] [CrossRef]
- Dullinger, C.; Struckl, W.; Kozek, M. Simulation-based multi-objective system optimization of train traction systems. Simul. Model. Pract. Theory 2017, 72, 104–117. [Google Scholar] [CrossRef]
- Fernández-Rodríguez, A.; Fernández-Cardador, A.; Cucala, A.P. Real time eco-driving of high speed trains by simulation-based dynamic multi-objective optimization. Simul. Model. Pract. Theory 2018, 84, 50–68. [Google Scholar] [CrossRef]
- Eskandarian, A. Scanning the issue. IEEE Trans. Intell. Transp. Syst. 2024, 25, 2174–2181. [Google Scholar] [CrossRef]
- Rajabighamchi, F.; Hajlou, E.M.H.; Hassannayebi, E. A Multi-objective Optimization Model for Robust Skip-Stop Scheduling with Earliness and Tardiness Penalties. Urban Rail Transit 2019, 5, 172–185. [Google Scholar] [CrossRef]
- Zhang, H.; Jia, L.; Wang, L. Study on Generation of Energy-saving Driving Curves of High-speed Train Based on Pareto Multi-objective Optimization. J. China Railw. Soc. 2021, 43, 85–91. [Google Scholar]
- Zhang, D.; Li, J.; Wei, W.; Meng, W.; Zhang, H. Dynamic design optimization of a vibration isolation installation system of a turboprop engine. Mech. Excell. 2022, 44, 581–587. [Google Scholar]
- Chang, H.P.; Li, W.Y.; Dong, F.G.; Guo, X.P. Multi-objective optimization of cold chain logistics distribution path based on NSGA-II. J. Transp. Sci. Technol. Econ. 2022, 24, 2. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Qu, J.; Zhang, C.; Zhang, J. Machining trajectory fitting algorithm based on NSGA-II and least squares principle. Precis. Manuf. Autom. 2019, 02, 25–28. [Google Scholar] [CrossRef]
- Ding, L.; Li, S. Research on RFID enterprise valuation based on double-precision neural network. Stat. Decis. 2012, 21, 76–80. [Google Scholar] [CrossRef]
- Meng, J.; Xu, R.; Li, D.; Chen, X. Combining the Matter-Element model with the associated function of performance indices for automatic train operation algorithm. IEEE Trans. Intell. Transp. Syst. 2019, 20, 253–263. [Google Scholar] [CrossRef]
- Li, L. Research on train automatic driving algorithm based on extenics. Railw. Comput. Appl. 2013, 22, 1–4. [Google Scholar]
- Zhang, C.; Liu, X. Research on performance index weight allocation scheme of automatic train operation system. Railw. Commun. Signal. 2012, 48, 9–12. [Google Scholar]
- Su, S.; Tang, T.; Li, X. Driving strategy optimization for trains in subway systems. Proc. Inst. Mech. Engineers. Part F J. Rail Rapid Transit 2016, 232, 369–383. [Google Scholar] [CrossRef]
- Chen, X.; Guo, X.; Meng, J.; Xu, R.; Li, S.; Li, D. Research on ATO Control Method for Urban Rail based on Deep Reinforcement Learning. IEEE Access 2023, 11, 5919–5928. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale Value | Definition | Meaning |
|---|---|---|
| 1 | Equally important | Both performance indicators are equally important to a process. |
| 3 | Slightly important | Of two performance indicators for a process, one performance is slightly more important than the other performance. |
| 5 | Obviously important | Of two performance indicators for a process, one performance is obviously more important than the other performance. |
| 7 | Highly important | Of two performance indicators for a process, one performance is highly important compared to the other performance. |
| 9 | Extremely important | Of two performance indicators for a process, one performance is extremely important compared to the other performance. |
| 2, 4, 6, 8 | Median value of adjacent scale | Represents the scale when there is a compromise between two adjacent scales. |
| Reciprocal | Reverse comparison | If the scale of performance indicator to another performance indicator j is , otherwise it is . |
| Index | A1 | A2 | |
|---|---|---|---|
| A1 | 1 | 2 | 0.667 |
| A2 | 1/2 | 1 | 0.333 |
| Different Experts | Operation Process | |
|---|---|---|
| Energy Consumption | Running Time | |
| Expert 1 | 0.667 | 0.333 |
| Expert 2 | 0.75 | 0.25 |
| Expert 3 | 0.5 | 0.5 |
| Expert 4 | 0.75 | 0.25 |
| Distance | Expert1 | Expert2 | Expert3 | Expert4 | The Mahalanobis Distance Value of the Population |
|---|---|---|---|---|---|
| Expert 1 | 0.0000 | 1.7468 | 2.2515 | 1.8395 | 5.8378 |
| Expert 2 | 1.7468 | 0.0000 | 3.4242 | 0.1660 | 5.3370 |
| Expert 3 | 2.2515 | 3.4242 | 0.0000 | 3.5697 | 9.2454 |
| Expert 4 | 1.8395 | 0.1660 | 3.5697 | 0.0000 | 5.5752 |
| Train Operation Process | ||
|---|---|---|
| Performance Indicator | Energy Consumption | Running Time |
| Weight | 0.7223 | 0.2777 |
| Name | Parameter Value |
|---|---|
| Train weight/(t) | 200 |
| Maximum speed/(km/h) | 80 |
| Maximum traction acceleration/(m/s2) | 1 |
| Maximum braking acceleration/(m/s2) | 1 |
| Basic operating resistance parameters |
| Sequence of Operating Conditions | Distance of Operation S (m) | Energy Consumption E (×107 J) | Running Time T (s) | Operation Time of Each Working Condition (s) |
|---|---|---|---|---|
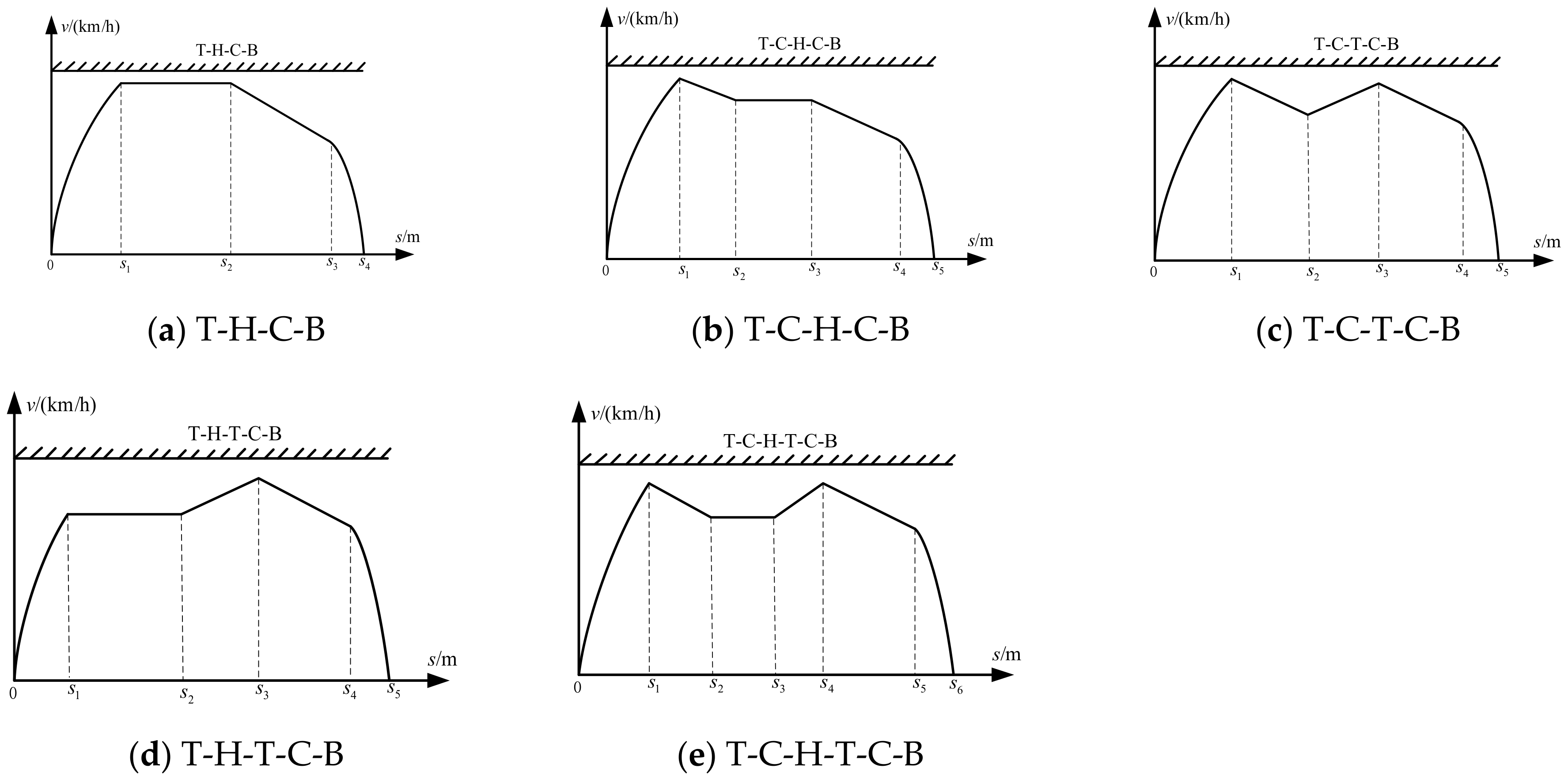
| T-H-C-B | 1982 | 9.98 | 112.2 | 22-50.8-17.8-21.6 |
| T-C-H-C-B | 1982 | 9.57 | 113.4 | 22-20.5-28.7-21-21.2 |
| T-C-T-C-B | 1982 | 8.71 | 118.9 | 20-60.1-3.2-14.4-21.7 |
| T-H-T-C-B | 1982 | 9.65 | 115.9 | 20-36.1-2-36.6-21.3 |
| T-C-H-T-C-B | 1982 | 9.71 | 116.4 | 20-6.5-33.3-2.1-33.1-21.3 |
| Algorithm | Running Time T (s) | Distance of Operation S (m) | Energy Consumption E (×107 J) |
|---|---|---|---|
| T-C-T-C-B | 118.9 | 0 | 8.71 |
| PID | 128.5 | 0.137 | 10.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Meng, J.; Xu, R.; Li, D.; Yang, H. Research on Multi-Objective Optimization Methods of Urban Rail Train Automatic Driving Based on NSGA-II. Electronics 2024, 13, 3971. https://doi.org/10.3390/electronics13193971
Chen X, Meng J, Xu R, Li D, Yang H. Research on Multi-Objective Optimization Methods of Urban Rail Train Automatic Driving Based on NSGA-II. Electronics. 2024; 13(19):3971. https://doi.org/10.3390/electronics13193971
Chicago/Turabian StyleChen, Xiaoqiang, Jianjun Meng, Ruxun Xu, Decang Li, and Haobo Yang. 2024. "Research on Multi-Objective Optimization Methods of Urban Rail Train Automatic Driving Based on NSGA-II" Electronics 13, no. 19: 3971. https://doi.org/10.3390/electronics13193971
APA StyleChen, X., Meng, J., Xu, R., Li, D., & Yang, H. (2024). Research on Multi-Objective Optimization Methods of Urban Rail Train Automatic Driving Based on NSGA-II. Electronics, 13(19), 3971. https://doi.org/10.3390/electronics13193971