1. Introduction
Remote sensing images with high resolution and rich spectral information play a pivotal role in diverse fields, such as plant pest and disease detection [
1,
2,
3], mineral exploration [
4,
5], crop yield estimation [
6,
7], and environmental monitoring [
8,
9]. Fang et al. [
10] estimated the soil moisture using satellite remote sensing data by integrating Bayesian depth image prior (BDIP) downsampling with a deep fully convolutional neural network. Pang et al. [
11] developed an advanced platform combining Lidar, CCD cameras, and hyperspectral sensors for detailed forest monitoring and analysis. Guo et al. [
12] utilized vegetation indices (VIs) and texture features (TFs) from unmanned aerial vehicle (UAV) hyperspectral images to create a disease monitoring model based on the partial least squares regression (PLSR) for detecting wheat yellow rust. Hyperspectral images (HSIs) [
13], composed of hundreds of spectral bands, offer finer spectral divisions than other images, which provides powerful material discrimination capabilities. As a critical technology in these applications, HSI classification employs traditional methods like the support vector machine (SVM) [
14], decision tree (DT) [
15], and maximum likelihood classifier (MLC) [
16]. However, these conventional methods primarily extract shallow features and often overlook deeper characteristics with the manual setting of feature selectors significantly impacting the classification accuracy.
In contrast to traditional HSI classification techniques, deep learning methods have the advantages of automatic feature learning and superior classification capabilities. They have achieved significant progress in various domains. Consequently, an increasing number of scholars are exploring HSI classification through deep learning approaches. Boulch et al. [
17] proposed an autoencoder (AE)-based network to perform HSI classification by combining multi-layer AE and pooling layers. Chen et al. [
18] proposed a Deep Belief Network (DBN)-based method to extract both shallow and deep features from HSI images for classification. The advent of Convolutional Neural Networks (CNNs) significantly enhanced the image classification accuracy. Given the abundance of sequential information in the spectral channels of HSIs, Mou et al. [
19] applied recurrent neural networks to HSI classification for the first time and achieved commendable results. Hu et al. [
20] effectively extracted spectral features from HSIs using a stack of five 1D-CNNs. Sharma et al. [
21] utilized 2D-CNNs to extract contextual spatial feature information from dimensionality-reduced HSIs, improving the classification performance with limited HSI training samples. However, utilizing the information from spectral or spatial features alone cannot fully take advantage of the rich features of HSIs. The fusion of spectral and spatial features is a beneficial complement to HSI classification. Yang et al. [
22] combined the features of 1D-CNN and 2D-CNN frameworks to extract spatial and spectral features, respectively, and then fused these features through a fully connected layer for classification. Joint spatial–spectral features can significantly improve the HSI classification accuracy. Nevertheless, dual-branch networks that extract features from spectral and spatial dimensions separately can lead to the loss of some original information, resulting in inadequate spatial–spectral joint features. The introduction of three-dimensional Convolutional Neural Networks has effectively mitigated this issue. Li et al. [
23] proposed an end-to-end five-layer 3D-CNN network. Chen et al. [
24] combined the 3D-CNN with regularization techniques to effectively extract original three-dimensional features and reduce overfitting in neural networks. Zhong et al. [
25] introduced an end-to-end Spectral–Spatial Residual Network for HSI classification, which takes the original three-dimensional data cube as the input and extracts both spectral and spatial features using the 3D-CNN. Qi et al. [
26] combined multi-scale and residual concepts to extract deeper features from different receptive fields and classify HSIs. Li et al. [
27] integrated attention mechanisms into the Dual-Branch Multi-Attention Network to refine hyperspectral features and achieve a better classification performance. Meng et al. [
28] proposed a new deep residual involution network (DRIN) for HSI classification. By using an enlarged involution kernel, the long-distance spatial interactions can be well-modeled.
Although CNNs have shown good performance in the field of HSI classification, there are still challenges to be addressed. For example, labeled HSIs require substantial human and material resources, so maximizing the utilization of existing data when HSI samples are limited is crucial. Furthermore, distinguishing the varying contributions of deep features to each node of the neural network is a challenging task. Lastly, the extraction of joint spatial–spectral features can lead to interference, and determining the correct combination of extracted features in multi-branch networks poses a challenge.
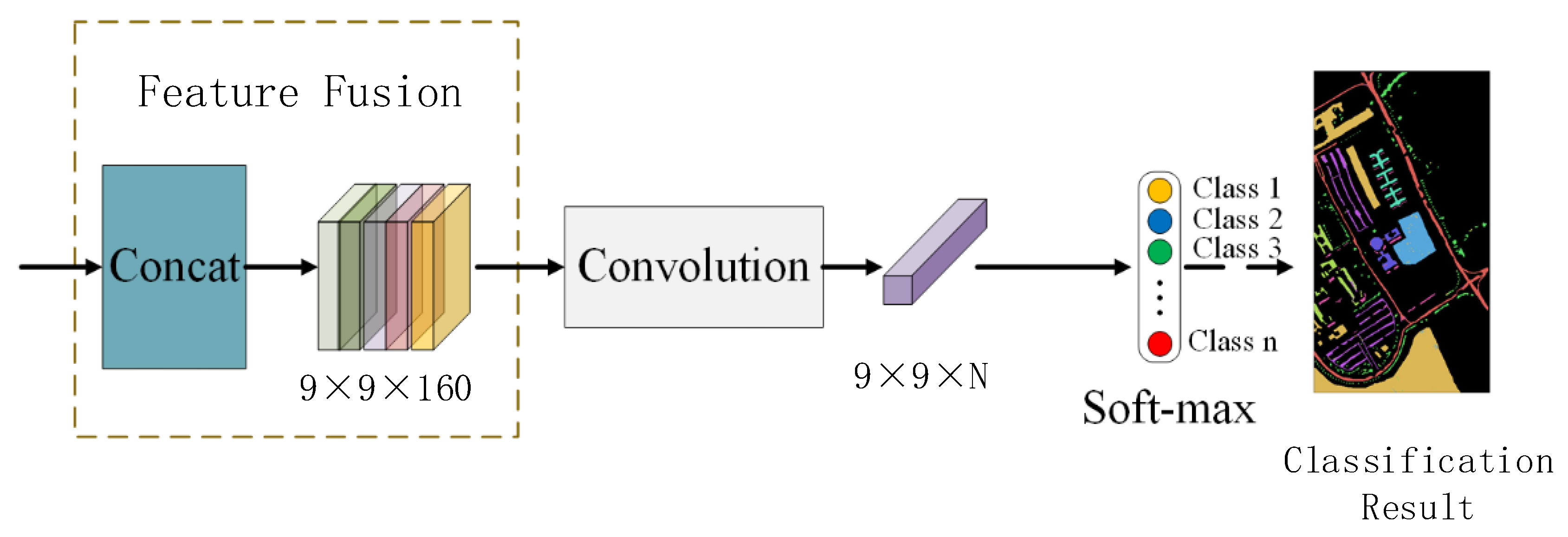
To mitigate these issues, a novel model combining 3D-CNN, 2D-CNN, multi-scale mechanisms [
29,
30], and residual attention mechanisms [
31,
32], namely MSRAN, is proposed. This method independently extracts spatial and spectral features through dual branches to minimize the interference between features of different dimensions. It then uses multi-scale mechanisms to enrich the feature diversity and employs spatial residual attention and spectral residual attention to identify effective features, thereby improving feature utilization. Finally, convolutional adaptive fusion integrates spatial texture features and spectral sequence features for classification. The contributions of this paper can be summarized as follows.
We present a Dual-Branch Multi-Scale Residual Spatial–Spectral Attention Network to classify the hyperspectral remote sensing images. This network independently extracts spatial and spectral features, minimizes the interference between these two types of information, and enables the model to focus on multi-dimensional features.
We extract the sequential and neighboring spectral features using different-sized convolution kernels. Meanwhile, multi-scale 2D convolution is employed to capture spatial features by superimposing various receptive fields. This approach improves the ability to classify the multi-boundary samples by highlighting the central pixel weight and capturing the ground contours and local details.
The proposed MSRAN method employs dual residual spectral and spatial attention mechanisms to identify the important features for hyperspectral image classification, which eliminates the disruptive features and enhances the utilization of spatial and spectral features.
A comprehensive assessment of the proposed MSRAN method is conducted through extensive ablation studies and comparative experiments on three datasets from Pavia University (PU) [
33], Salinas Valley (SV) [
33], and WHU-Hi-LongKou (WHKL) [
34]. The results demonstrate a great improvement in the classification accuracy over advanced methods.
The subsequent parts of this paper are organized as follows:
Section 2 discusses the proposed MSRAN method. In
Section 3, ablation studies and comparative experiments are conducted to verify the effectiveness and competitiveness of the proposed model.
Section 4 summarizes our work.
3. Experimental Results and Analysis
To validate the effectiveness of the proposed MSRAN classification method, a series of ablation and comparative experiments were conducted using two classic datasets, the PU dataset and the SV dataset, along with a novel dataset, the WHLK dataset. The contributions of different modules to the network and the classification performance of various algorithms were assessed using multiple indicators (Overall Accuracy—OA, Average Accuracy—AA, the Kappa
(K) coefficient [
37], and the category-wise classification accuracy for each dataset).
3.1. Experimental Datasets
3.1.1. Pavia University Dataset
This dataset was captured by the Reflection Optical System Imaging Spectroradiometer (ROSIS) in the university town of Pavia in northern Italy in 2001. It consists of 115 spectral bands. Twelve spectral bands were removed due to noise, leaving 103 spectral bands for the experimental study. The image size is 610 × 340 pixels, the spectral resolution is 4 nm, and the spatial resolution is 1.3 m/pixel. This dataset includes real-life scenarios consisting of nine different types of land cover, with 42,776 labeled samples. In this study, 5% of the samples were used as the training set and validation set, and the rest were used as the test set.
Figure 7 shows the pseudo-color image and ground truth map.
Table 1 lists the numbers of training, validation, and testing samples for each category.
3.1.2. Salinas Valley Dataset
This dataset was captured by the Airborne Visible/Infrared Imaging Spectroradiometer (AVIRIS) sensor in the Salinas Valley agricultural region of California in 1998. It originally contained 224 spectral bands, of which 204 were retained for experimental studies after removing 20 water absorption bands. The image size is 512 × 217 pixels, the wavelength range is 400–2500 nm, and the spatial resolution is 3.7 m/pixel. This dataset contains 16 different types of land cover, with 54,129 labeled samples. In this study, 5% of the samples were used as the training set and validation set, and the rest were used as the test set.
Figure 8 shows the pseudo-color image and ground truth map.
Table 2 lists the numbers of training, validation, and testing samples for each category.
3.1.3. WHU-Hi-LongKou Dataset
This dataset was captured by the Headwall Nano-Hyperspec imaging sensor from 13:49 to 14:37 on 17 July 2018 over Longkou Town, Hubei Province, China. It consists of 270 spectral bands that are used for experimental studies. The image is 550 × 400 pixels, the wavelength range is 400–1000 nm, and the spatial resolution is 0.463 m/pixel. This dataset contains nine land cover types with 204,542 pixels labeled. In this study, 1% of the samples were used as the training set and validation set, and the rest were used as the test set.
Figure 9 shows the pseudo-color image and ground truth map.
Table 3 lists the numbers of training, validation, and testing samples for each category.
3.2. Experimental Settings
In the experiments, the Adam optimizer was utilized, with the default setting of 64 samples per batch for training. The learning rate was set to 1 × 10−3 by default, and the patch size was set to nine by default. For training periods, the PU and SV datasets were subjected to 300 epochs, while the WHLK dataset was set to 200 epochs. The parameter settings for other comparative methods were consistent with those reported in the corresponding literature. All training samples underwent the same data preprocessing methods, and the results were derived from the average of multiple experiments. In order to ensure fairness in the experimental process, all HSI classification methods were implemented on the same computing workstation. The workstation was equipped with 40 GB of memory, an Intel 8255C CPU, and an RTX 3080 GPU. The experiments were conducted on the Ubuntu 18.04 platform using the PyTorch 1.8.1 framework.
In order to quantitatively compare the effectiveness of the method presented in this paper with multiple other approaches, four quantitative evaluation metrics were adopted: OA, AA, the K coefficient, and the classification accuracy for individual categories in each dataset. OA represents the percentage of samples correctly classified by the model in the entire dataset, which is used as a measure of the overall performance, where the higher the value, the better the performance. AA is the mean of the precision values for each category, providing a comprehensive assessment of the performance across categories. The Kappa coefficient is a measure of the consistency between the model and random classification, taking into account the randomness in the classification results, thereby offering more reliability than the mere OA. The Kappa coefficient ranges between −1 and 1, where 0 indicates agreement with random classification and 1 denotes complete agreement. The category classification accuracy of each dataset refers to the proportion of correctly classified samples in each category.
3.3. Experimental Results and Analysis
3.3.1. Ablation Studies
To demonstrate the contribution of each module, ablation experiments were performed using a controlled module variable approach. The MSRAN is mainly composed of the multi-scale spectral residual network (spectral branch), the multi-scale spatial residual network (spatial branch), and the feature fusion module. Different combinations of these modules were tested to assess their contributions. Since the feature fusion module integrates feature fusion and classification tasks, it was included by default in our experiments. As shown in
Table 4, a comparison between NET-1 and NET-4 revealed that the inclusion of multi-scale spatial residual attention in NET-4 led to increases in the OA of 1.02% and 3.40% for the PU and SV datasets, respectively. This improvement is attributed to the fact that HSIs encompass both spatial and spectral information, making the joint spatial–spectral features more suitable for HSI classification tasks. The incorporation of spatial residual attention mechanisms enables the network to focus more on features that are effective for classification. Notably, for the WHLK dataset, the introduction of multi-scale spatial–spectral residual attention mechanisms resulted in a significant 7.91% increase in the OA. This can be attributed to the higher spatial resolution of the WHLK, which provides richer details for land cover spatial features. Multi-scale feature extraction can extract more levels of land cover contours, edges, and local details through different receptive fields, thereby enhancing the precision of the classification features. By comparing it with the NET-2, the introduction of multi-scale spectral residual attention in the NET-4 resulted in notable OA improvements of 10.75%, 7.33%, and 19.68% on three HSI datasets, respectively. This improvement is partly due to the advantages brought by the joint spatial–spectral features and partly because of the use of 3 × 3 × 3 three-dimensional convolution kernels and 5 × 1 × 1 one-dimensional convolution kernels. These kernels not only extract longer one-dimensional spectral features but also accommodate three-dimensional neighboring spectral features. Subsequently, spectral residual attention was applied to enhance the utilization of spectral features. In NET-3, the spatial and spectral multi-scale mechanisms are modified to a single scale. Specifically, in the spectral branch, the multi-scale 3DConv is replaced with a single-scale 3DConv with a 3 × 3 × 3 convolution kernel, while in the spatial branch, the multi-level multi-scale convolution is substituted with a single-scale 2DConv with a 5 × 5 kernel. All other experimental settings are retained, as they are in our final NET-4 model. By comparison, our final NET-4 model incorporates a multi-scale mechanism and improves by 6.31%, 8.54%, and 9.63% in terms of the OA on three distinct datasets, respectively. This demonstrates that the multi-scale mechanism is adept at capturing object features of various sizes. The reason for this mainly lies in the fact that the various volumes of different-sized objects lead to diverse scales of edge contours and local detail information. This diversity necessitates the use of different receptive fields for effective feature extraction. The combination of spectral and spatial multi-scale mechanisms enhances our proposed MSRAN method to achieve a superior classification performance.
3.3.2. Comparative Experiments
To validate the effectiveness of the proposed MSRAN method, comparative experiments were conducted against a range of both classical and contemporary networks, including the SVM [
14], 1D-RNN [
18], 1D-CNN [
20], 2D-CNN [
21], 3D-CNN [
23], DBDA [
27], DRIN [
28], and LS
2CM [
38].
Table 5,
Table 6 and
Table 7 present the OA, AA, K coefficient, and classification accuracy for each land cover type across the PU, SV, and WHLK datasets. Bolded results in these tables signify superior classification performances. Remarkably, the MSRAN outperformed the others, achieving the highest OA, AA, and Kappa coefficient values on two traditional and one novel dataset. In particular, the proposed MSRAN method achieved OA improvements of 3.68%, 4.26%, and 3.34% compared with the classical 3D-CNN method across these datasets, respectively. Even compared with the advanced DRIN and LS
2CM methods, MSRAN maintained its superiority due to its efficient integration of spatial and spectral features. The classification results across the datasets showed notable imbalances. For instance, in
Table 5 (Bitumen),
Table 6 (Lettuce R4), and
Table 7 (Mixed weed), classification methods like the SVM, 1D-CNN, and 1D-RNN utilizing one-dimensional features exhibited subpar performances due to the complex sample distribution and the predominance of boundary samples. Conversely, MSRAN along with DBDA and 3D-CNN demonstrated a consistently balanced classification accuracy across various datasets and sample types, where the proposed MSRAN showed the most uniform performance. This consistency demonstrates the ability of our MSRAN method to handle diverse and complex sample data, which can be mainly attributed to the multi-scale mechanism, feature extraction at various granularities, feature enhancement of the central pixel, as well as the residual attention mechanism. The integration of these modules enhances the utilization of spatial and spectral features, which validates the robustness of the proposed MSRAN method.
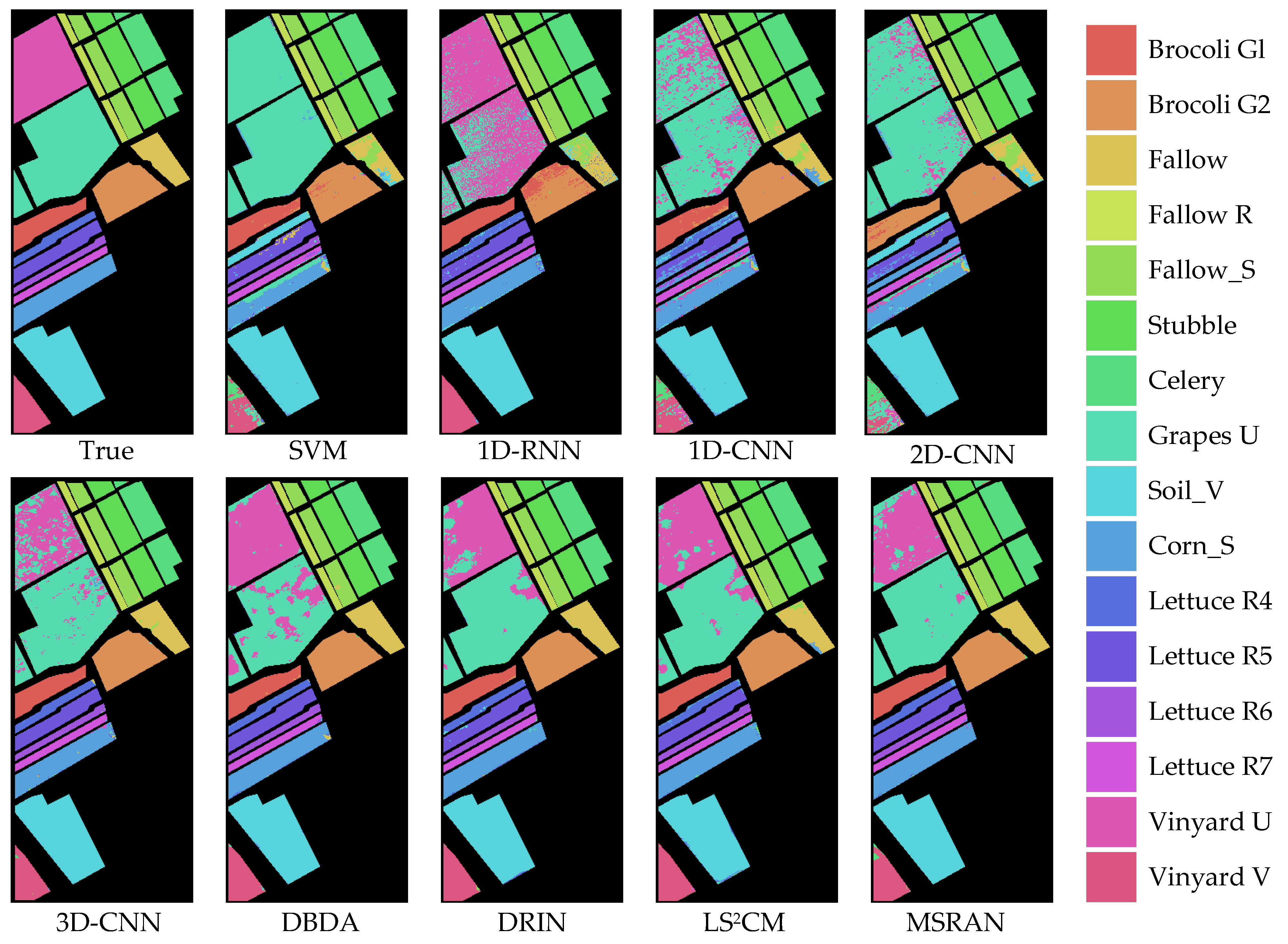
In visual comparisons, classification maps are generated by these methods on the PU, SV, and WHLK datasets, as depicted in
Figure 10,
Figure 11 and
Figure 12. As observed, the maps from the DBDA, DRIN, LS
2CM, and MSRAN align more closely with the actual ground conditions, particularly for the classification map of the proposed MSRAN method, which exhibits superior visual accuracy. Conversely, the classification maps from other methods are less precise. While some methods perform well with larger sample sizes, they struggle with smaller, more dispersed samples, such as the scattered Asphalt and Trees in the PU dataset, as shown in
Figure 10. Samples that are close to, or even coincident with, edge pixels, such as LettuceR4 in the SV dataset of
Figure 11 and Roads and Houses in the WHLK dataset of
Figure 12, do not perform well. In contrast, the proposed MSRAN method excels in classes with a high percentage of boundary samples, as shown in the high-resolution WHLK dataset, where it effectively managed complex samples like Roads and Houses and Mixed Weed along Riverbanks with intricate boundary challenges.
Overall, the proposed MSRAN method enhances the spectral features of the central pixel and extracts multi-level fine-grained spatial details, which cooperates with the dual-path residual attention mechanism to screen effective features. By removing the redundant feature interference and minimizing the interference between surrounding pixels, the proposed MSRAN method enables the accurate classification of land cover types in areas with complex spatial distribution, particularly for the areas with scattered and boundary samples.
3.3.3. Impacts of Different Training Ratios
Figure 13 displays the OA values of various models with different proportions of training samples. Considering the varying total number of samples and the stability of the models under exposure to different proportions, 3%, 5%, 7%, and 10% of the training samples were randomly selected for the PU and SV datasets, while 0.5%, 1%, 3%, and 7% were chosen for the WHLK dataset. Overall, it is observed that, even with a limited number of training samples, it still achieves satisfactory classification results. As the number of training samples increases, all methods show a growth trend for performance across these three datasets. Notably, the proposed MSRAN method demonstrates a stable growth trend, further affirming its robustness.
These findings suggest that MSRAN is particularly effective in scenarios with the common challenge of limited training data for HSI classification. Its ability to maintain stable performance improvements with increasing amounts of training data highlights its potential for use in various applications, particularly in areas where collecting extensive training samples is challenging or impractical. The robustness of MSRAN in these contexts underscores its suitability for real-world applications and its effectiveness for harnessing limited data for accurate classification.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}