
A Sememe Prediction Method Based on the Central Word of a Semantic Field


Abstract
1. Introduction
- We construct three types of semantic fields to match words and sememes and design a semantic field selection strategy to expand the applicability of semantic fields and improve the accuracy of sememes.
- By computing the semantic field’s central word for prediction, a better alignment between words and sememes is achieved, eliminating the need for vector training.
- The proposed SFCW achieves the best unstructured and structured sememe prediction results on the publicly available BabelSememe dataset. Additionally, we further qualitatively and quantitatively analyze the sememe structure of the central word.
2. Related Work
2.1. HowNet
2.2. Sememe Prediction
3. Methods
3.1. Semantic Field Organization
- As a specialist in the field of natural language processing, give #type of #word (#definition), separated by commas, no capitalization, no number, no commentary.
3.2. Semantic Field Selection
- Character fields perform best for in-vocabulary words, with a significant decrease in performance for out-of-vocabulary words. Additionally, character fields are only suitable for phrases composed of multiple words. This is because, for a single word, the character domain is just the word itself. Predicting the word using itself is not sensible.
- Synonymous fields have overall stable performance, with good performance for both in-vocabulary and out-of-vocabulary words. However, large models may not generate correct synonyms for all words, especially proper nouns (names, locations).
- Taxonomic fields have the lowest sememe compatibility, but their advantage lies in that almost all words can find corresponding hypernyms, making them suitable for a wide range of scenarios.
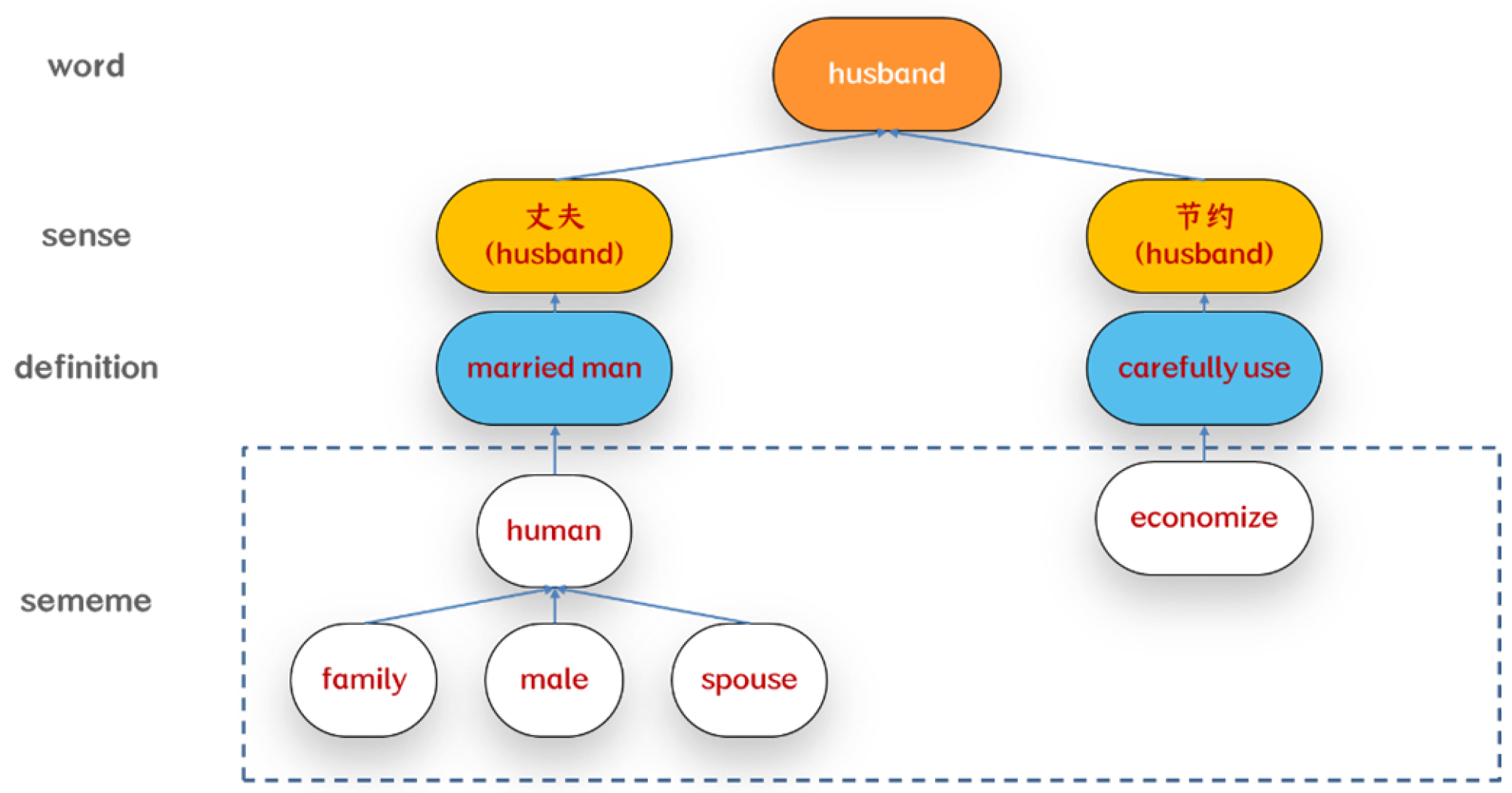
3.3. Central Word Selection
3.3.1. Semantic Relevance of Senses
3.3.2. Sememe Similarity between Words
3.3.3. Sememe Similarity between Senses
3.3.4. Word Filtering
4. Experiments
4.1. Dataset
4.2. Experiment Settings
4.3. Baselines
- SPWE [22]: A word embedding-based method that recommends sememes based on similar words in the word vector space.
- CSP [23]: An ensemble model consisting of four sub-models, including SPWCF and SPCSE using internal word information and SPWE and SPSE using external word information.
- LD + seq2seq [35]: A sequence-to-sequence model utilizing the text definition.
- ScorP [27]: A model that predicts sememes by considering the local correlation between the various sememes of a word and the semantics of the different words in the definition.
- ASPSW [25]: A model that improves sememe prediction by introducing synonyms and derives an attention-based strategy to dynamically balance knowledge from synonym sets and word embeddings.
- P-RNN [36]: A model that uses a recursive neural network (RNN) and a multi-layer perceptron (MLP) to gradually generate edges and nodes in a depth-first order for a given word pair with root sememes.
- NSTG [32]: A model that generates sememe trees by multiplying probabilities of sememe pairs from synonym sets, using sentence-BERT encoding for definition information, and computing the similarity levels.
- TasTG [32]: A model that converts sememe trees into sequences through depth-first traversal, introduces the tree attention mechanism, divides the attention computation into semantic attention and positional attention, encodes definitions using BERT-base, and generates sememe sequences using a transformer decoder.
4.4. Evaluation Metrics
4.5. Main Experimental Results
4.5.1. Unstructured Sememe Prediction
4.5.2. Structured Sememe Prediction
5. Discussion
5.1. Impact of Selection Strategies
5.2. Central Word Sememe Structure
5.3. Advantages and Limitations of Semantic Fields
5.4. Case Study
5.4.1. Unstructured Sememe Cases
5.4.2. Structured Sememe Cases
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bloomfield, L. A Set of Postulates for the Science of Language. Language 1926, 2, 153–164. [Google Scholar] [CrossRef]
- Dong, Z.; Dong, Q. HowNet—A hybrid language and knowledge resource. In Proceedings of the International Conference on Natural Language Processing and Knowledge Engineering, Beijing, China, 21–23 August 2003; pp. 820–824. [Google Scholar] [CrossRef]
- Niu, Y.; Xie, R.; Liu, Z.; Sun, M. Improved Word Representation Learning with Sememes. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Barzilay, R., Kan, M.Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2049–2058. [Google Scholar] [CrossRef]
- Fan, M.; Zhang, Y.; Li, J. Word similarity computation based on HowNet. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 1487–1492. [Google Scholar] [CrossRef]
- Hu, F.S.; Guo, Y. An improved algorithm of word similarity computation based on HowNet. In Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering (CSAE), Zhangjiajie, China, 25–27 May 2012; Volume 3, pp. 372–376. [Google Scholar] [CrossRef]
- Li, H.; Zhou, C.l.; Jiang, M.; Cai, K. A hybrid approach for Chinese word similarity computing based on HowNet. In Proceedings of the International Conference on Automatic Control and Artificial Intelligence (ACAI 2012), Xiamen, China, 3–5 March 2012; pp. 80–83. [Google Scholar] [CrossRef]
- Duan, X.; Zhao, J.; Xu, B. Word Sense Disambiguation through Sememe Labeling. In Proceedings of the 20th International Joint Conference on Artifical Intelligence, Hyderabad, India, 6–12 January 2007; IJCAI’07. pp. 1594–1599. [Google Scholar]
- Hou, B.; Qi, F.; Zang, Y.; Zhang, X.; Liu, Z.; Sun, M. Try to Substitute: An Unsupervised Chinese Word Sense Disambiguation Method Based on HowNet. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; Scott, D., Bel, N., Zong, C., Eds.; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 1752–1757. [Google Scholar] [CrossRef]
- Huang, M.; Ye, B.; Wang, Y.; Chen, H.; Cheng, J.; Zhu, X. New Word Detection for Sentiment Analysis. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; Toutanova, K., Wu, H., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 531–541. [Google Scholar] [CrossRef]
- Wen, Z.; Gui, L.; Wang, Q.; Guo, M.; Yu, X.; Du, J.; Xu, R. Sememe knowledge and auxiliary information enhanced approach for sarcasm detection. Inf. Process. Manag. 2022, 59, 102883. [Google Scholar] [CrossRef]
- Thakur, N. MonkeyPox2022Tweets: A Large-Scale Twitter Dataset on the 2022 Monkeypox Outbreak, Findings from Analysis of Tweets, and Open Research Questions. Infect. Dis. Rep. 2022, 14, 855–883. [Google Scholar] [CrossRef] [PubMed]
- Negrón, J.B. # EULAR2018: The annual European congress of rheumatology—a twitter hashtag analysis. Rheumatol. Int. 2019, 39, 893–899. [Google Scholar] [PubMed]
- Li, F.L.; Chen, H.; Xu, G.; Qiu, T.; Ji, F.; Zhang, J.; Chen, H. AliMeKG: Domain Knowledge Graph Construction and Application in E-Commerce. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM’20), New York, NY, USA, 19–23 October 2020; pp. 2581–2588. [Google Scholar] [CrossRef]
- Qi, F.; Yao, Y.; Xu, S.; Liu, Z.; Sun, M. Turn the Combination Lock: Learnable Textual Backdoor Attacks via Word Substitution. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4873–4883. [Google Scholar] [CrossRef]
- Qiang, J.; Lu, X.; Li, Y.; Yuan, Y.; Wu, X. Chinese Lexical Simplification. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1819–1828. [Google Scholar] [CrossRef]
- Gu, Y.; Yan, J.; Zhu, H.; Liu, Z.; Xie, R.; Sun, M.; Lin, F.; Lin, L. Language Modeling with Sparse Product of Sememe Experts. arXiv 2018, arXiv:1810.12387. [Google Scholar]
- Qi, F.; Huang, J.; Yang, C.; Liu, Z.; Chen, X.; Liu, Q.; Sun, M. Modeling Semantic Compositionality with Sememe Knowledge. arXiv 2019, arXiv:1907.04744. [Google Scholar]
- Qi, F.; Chang, L.; Sun, M.; Ouyang, S.; Liu, Z. Towards Building a Multilingual Sememe Knowledge Base: Predicting Sememes for BabelNet Synsets. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8624–8631. [Google Scholar] [CrossRef]
- Yang, L.; Kong, C.; Chen, Y.; Liu, Y.; Fan, Q.; Yang, E. Incorporating Sememes into Chinese Definition Modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1669–1677. [Google Scholar] [CrossRef]
- Qian, C.; Feng, F.; Wen, L.; Chua, T.S. Conceptualized and Contextualized Gaussian Embedding. Proc. AAAI Conf. Artif. Intell. 2021, 35, 13683–13691. [Google Scholar] [CrossRef]
- Qin, Y.; Qi, F.; Ouyang, S.; Liu, Z.; Yang, C.; Wang, Y.; Liu, Q.; Sun, M. Improving Sequence Modeling Ability of Recurrent Neural Networks via Sememes. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2364–2373. [Google Scholar] [CrossRef]
- Xie, R.; Yuan, X.; Liu, Z.; Sun, M. Lexical Sememe Prediction via Word Embeddings and Matrix Factorization. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 4200–4206. [Google Scholar] [CrossRef]
- Jin, H.; Zhu, H.; Liu, Z.; Xie, R.; Sun, M.; Lin, F.; Lin, L. Incorporating Chinese Characters of Words for Lexical Sememe Prediction. arXiv 2018, arXiv:1806.06349, 06349. [Google Scholar]
- Lyu, B.; Chen, L.; Yu, K. Glyph Enhanced Chinese Character Pre-Training for Lexical Sememe Prediction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M.F., Huang, X., Specia, L., Yih, S.W.t., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4549–4555. [Google Scholar] [CrossRef]
- Kang, X.; Li, B.; Yao, H.; Liang, Q.; Li, S.; Gong, J.; Li, X. Incorporating Synonym for Lexical Sememe Prediction: An Attention-Based Model. Appl. Sci. 2020, 10, 5996. [Google Scholar] [CrossRef]
- Bai, M.; Lv, P.; Long, X. Lexical Sememe Prediction with RNN and Modern Chinese Dictionary. In Proceedings of the 2018 14th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Huangshan, China, 28–30 July 2018; pp. 825–830. [Google Scholar] [CrossRef]
- Du, J.; Qi, F.; Sun, M.; Liu, Z. Lexical Sememe Prediction using Dictionary Definitions by Capturing Local Semantic Correspondence. arXiv 2019, arXiv:1907.04744. [Google Scholar]
- Qi, F.; Lin, Y.; Sun, M.; Zhu, H.; Xie, R.; Liu, Z. Cross-lingual Lexical Sememe Prediction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 358–368. [Google Scholar] [CrossRef]
- WANG, H.; LIU, S.; DUAN, J.; HE, L.; LI, X. Chinese Lexical Sememe Prediction Using CilinE Knowledge. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2023, E106.A, 146–153. [Google Scholar] [CrossRef]
- Navigli, R.; Ponzetto, S.P. BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network. Artif. Intell. 2012, 193, 217–250. [Google Scholar] [CrossRef]
- Liu, Y.; Qi, F.; Liu, Z.; Sun, M. Research on Consistency Check of Sememe Annotations in HowNet. J. Chin. Inf. Process. 2021, 35, 23–34. [Google Scholar] [CrossRef]
- Ye, Y.; Qi, F.; Liu, Z.; Sun, M. Going “Deeper”: Structured Sememe Prediction via Transformer with Tree Attention. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 128–138. [Google Scholar] [CrossRef]
- Qi, F.; Yang, C.; Liu, Z.; Dong, Q.; Sun, M.; Dong, Z. OpenHowNet: An Open Sememe-based Lexical Knowledge Base. arXiv 2019, arXiv:1901.09957. [Google Scholar]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Li, W.; Ren, X.; Dai, D.; Wu, Y.; Wang, H.; Sun, X. Sememe Prediction: Learning Semantic Knowledge from Unstructured Textual Wiki Descriptions. arXiv 2018, arXiv:1808.05437. [Google Scholar]
- Liu, B.; Shang, X.; Liu, L.; Tan, Y.; Hou, L.; Li, J. Sememe Tree Prediction for English-Chinese Word Pairs. In Proceedings of the Knowledge Graph and Semantic Computing: Knowledge Graph and Cognitive Intelligence, Guangzhou, China, 4–7 November 2021; Chen, H., Liu, K., Sun, Y., Wang, S., Hou, L., Eds.; Springer: Singapore, 2021; pp. 15–27. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word Pairs | Word2vec Similarity | Sememe Similarity |
|---|---|---|
| Water, Mineral Water | 0.73 | 0.54 |
| Water, Bottled Water | 0.53 | 0.54 |
| Water, Hard Water | 0.71 | 1 |
| Bottled Water, Mineral Water | 0.83 | 1 |
| Bottled Water, Hard Water | 0.56 | 0.54 |
| Mineral Water, Hard Water | 0.65 | 0.54 |
| Sense | HowNet Dictionary Record |
|---|---|
| 医师 doctor | NO. = 000000064959 W_C = 医师 G_C = noun E_C = W_E = doctor G_E = noun E_E= DEF = {human|人:HostOf = {Occupation|职位}, domain = {medical|医}, {doctor|医治:agent = {∼}}} |
| 患者 patient | NO. = 000000130638 W_C = 患者 G_C = noun E_C= W_E = patient G_E = noun E_E= DEF = {human|人:domain = {medical|医}, {SufferFrom|罹患:experiencer = {∼}}, {doctor|医治:patient = {∼}}} |
| Prompt | Type | Word | Definition |
|---|---|---|---|
| {"role": "user", "content": "As a specialist in the field of natural language processing, give synonyms of waffle (pancake batter baked in a waffle iron), separated by commas, no capitalization, no number, no commentary"}, {"role": "assistant", "content": "waffle: battercake, griddlecake, pancake, hotcake, flannel cake"} | synonyms | waffle | pancake batter baked in a waffle iron |
| WordNet_ID | BabelNet_ID | HowNet_DEF |
|---|---|---|
| 02417725a | 00109443a | {watery|稀} |
| 02417725a | 02417725a | {sparse|疏} |
| 00617748v | 00087717v | {do|做:manner = {wrong|误}} |
| 00617748v | 00087717v | {err|出错} |
| 01899360a | 00104716a | {wise|智:adjunct = {neg|否}} |
| Similarity Threshold | F1 |
|---|---|
| 0 | 64.38 |
| 0.1 | 65.26 |
| 0.2 | 67.70 |
| 0.3 | 67.41 |
| 0.4 | 66.33 |
| 0.5 | 63.34 |
| 0.6 | 62.59 |
| 0.7 | 62.34 |
| 0.8 | 61.10 |
| 0.9 | 59.57 |
| Method | F1 |
|---|---|
| SPWE + SPSE [22] | 40.25 |
| CSP [23] | 46.53 |
| LD + seq2seq [35] | 25.85 |
| SCorP [27] | 56.32 |
| ASPSW [25] | 61.02 |
| SFCW | 67.70 |
| Method | Root | Strict | Edge | Vertex |
|---|---|---|---|---|
| P-RNN [36] | - | 50.22 | 54.53 | 60.28 |
| NSTG [32] | 29.25 | 26.18 | 26.82 | 32.11 |
| TaSTG [32] | 37.14 | 39.75 | 41.22 | 48.25 |
| SFCW | 66.51 | 59.60 | 60.32 | 67.70 |
| Type | Candidate Words | Candidate Senses | Sememe Tree | Avg Sim |
|---|---|---|---|---|
| Taxonomic field | instrument | 乐器 (instrument): any of various devices or contrivances that can be used to produce musical tones or sounds |  | 0.56 |
| 仪器 (instrument): a device that requires skill for proper use |  | 0.67 | ||
| 工具 (instrument): the mean whereby some act is accomplished |  | 0.55 | ||
| 爪牙 (instrument): a person used by another to gain an end |  | 0.39 | ||
| Synonymous field | water gauge | 水尺 (water gauge): gauge for indicating the level of water in e.g., a tank or boiler or reservoir | 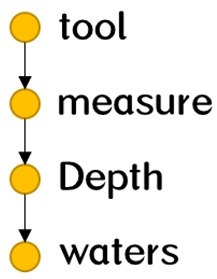 | 0.70 |
| Type | Candidate Words | Candidate Senses | Sememe Tree | Avg Sim |
|---|---|---|---|---|
| Character field | water | 水 (water): binary compound that occurs at room temperature as a clear colorless odorless tasteless liquid |  | 0.45 |
| 浇水 (water): supply with water, as with channels or ditches |  | 0.26 | ||
| 饮 (water): provide with water | 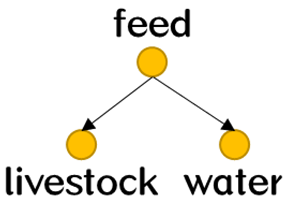 | 0.24 | ||
| meter | 仪表 (meter): any of various instruments for measuring a quantity |  | 0.70 | |
| 米 (meter): the basic unit of length adopted under the System International Unites |  | 0.16 | ||
| 韵律 (meter): rhythm as given by division into parts of equal duration |  | 0.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, G.; Cui, Y. A Sememe Prediction Method Based on the Central Word of a Semantic Field. Electronics 2024, 13, 413. https://doi.org/10.3390/electronics13020413
Luo G, Cui Y. A Sememe Prediction Method Based on the Central Word of a Semantic Field. Electronics. 2024; 13(2):413. https://doi.org/10.3390/electronics13020413
Chicago/Turabian StyleLuo, Guanran, and Yunpeng Cui. 2024. "A Sememe Prediction Method Based on the Central Word of a Semantic Field" Electronics 13, no. 2: 413. https://doi.org/10.3390/electronics13020413
APA StyleLuo, G., & Cui, Y. (2024). A Sememe Prediction Method Based on the Central Word of a Semantic Field. Electronics, 13(2), 413. https://doi.org/10.3390/electronics13020413