
The Effect of Eye Contact in Multi-Party Conversations with Virtual Humans and Mitigating the Mona Lisa Effect

Abstract
:1. Introduction
2. Related Works
2.1. Embodied Conversational Agents (ECAs)
2.2. Nonverbal Cues
2.3. Eye Contact in 2D Display
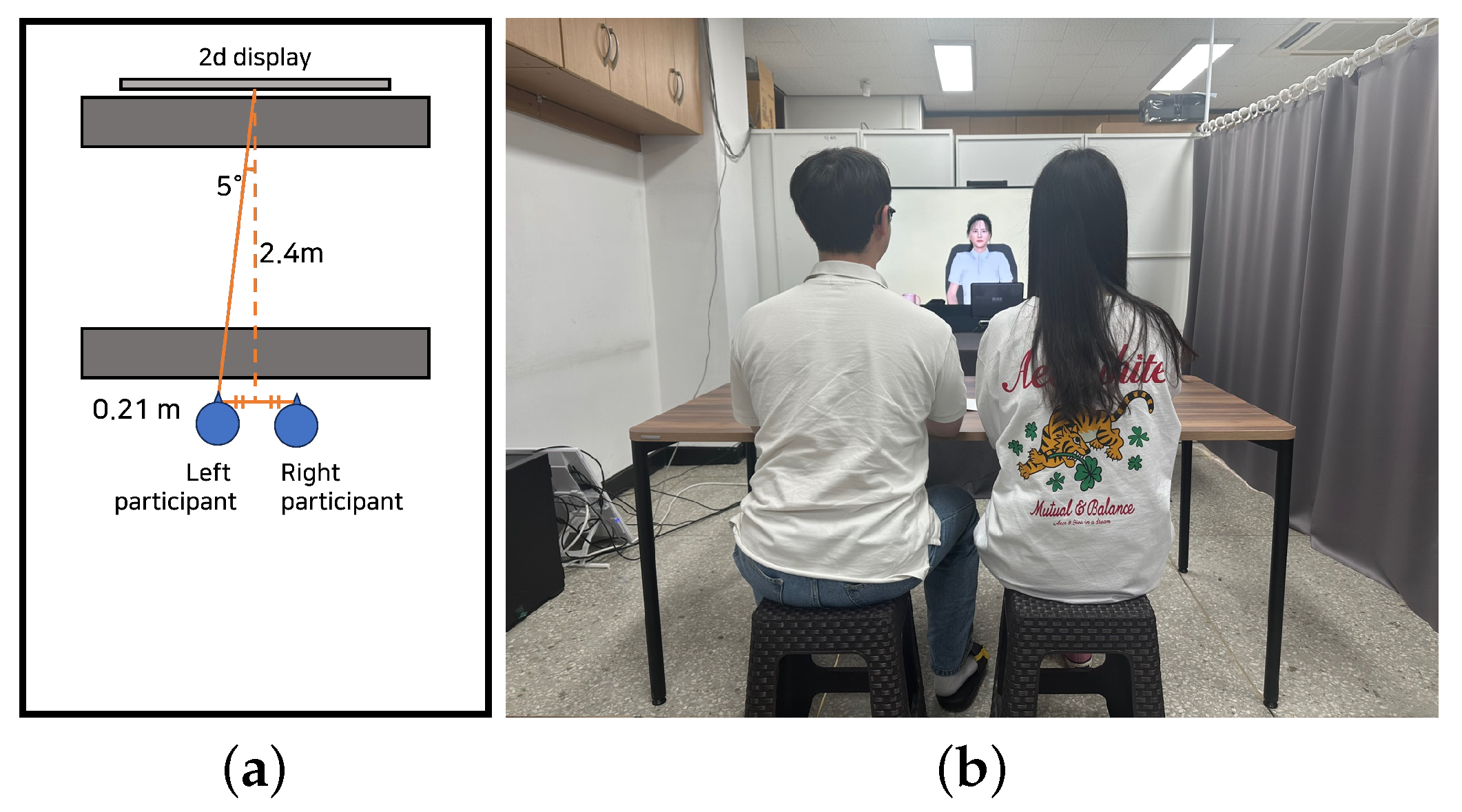
3. Experiment 1
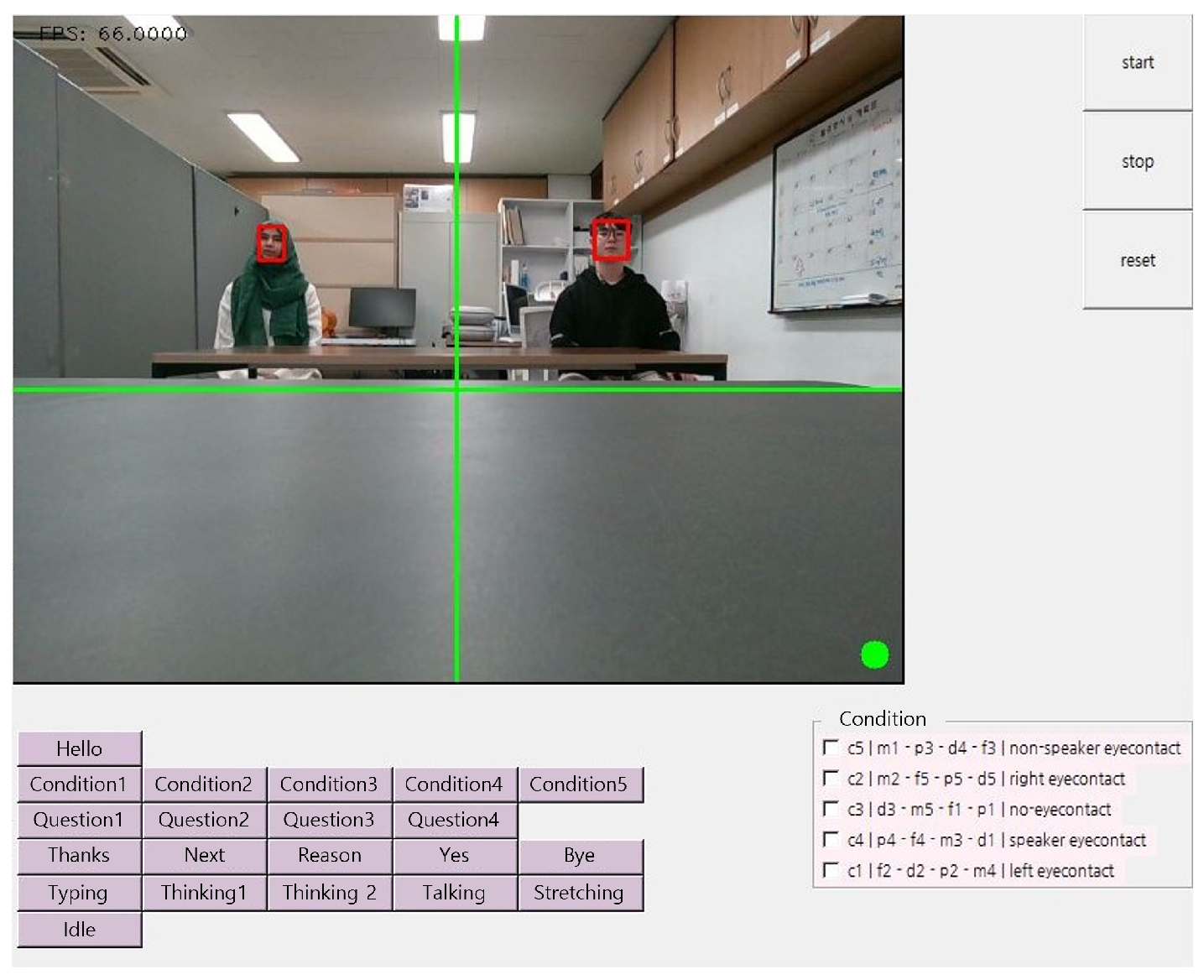
3.1. Method
- Speaker eye contact: The VH answered the question by looking at the participant who asked it.
- Non-speaker eye contact: The VH answered the question by looking at the opposite participant. For example, if the right participant asked the question, the VH stared at the left participant.
- No eye contact: The VH answered the question by staring straight ahead, irrespective of who asked it.
- Right-participant eye contact: The VH answered the question by looking at the right participant, regardless of who asked it.
- Left-participant eye contact: The VH answered the question by looking at the left participant, regardless of who asked it.
3.1.1. Materials
3.1.2. Procedure
3.2. Measurements
3.2.1. Subjective Measurements
- Eye-gaze of VHs: The participants were asked whether the VH looked between them, in the center, or at the other participants when the participants asked a question. This item aimed to determine whether the participants were adequately aware of the VH’s gaze.
- Interpersonal skill: The VH’s interpersonal skills as perceived by the participants were measured.This construct contained six items from Oh et al.’s research [38].
- Social presence: How the participants perceived the social presence of the VHs was measured. This construct contained five items from Bailenson et al.’s research [39].
- Attention: How the participants perceived that the participants and the VHs paid attention to each other during the conversation was measured. This construct contained six items from Harms and Biocca’s research [40].
- Co-presence: How the participants perceived the co-presence of the VHs was measured. This construct contained six items from Harms and Biocca’s research [40].
- Competence: RoSAS [41] was used to measure these constructs. The participants rated the competence of the VHs using six items.
- Positive attitude and negative attitude: The participants’ positive and negative attitudes were measured during the conversation with the VHs using PANAS [42].
3.2.2. Objective Measurements
3.3. Participants
3.4. Results
3.4.1. Subjective Measurements
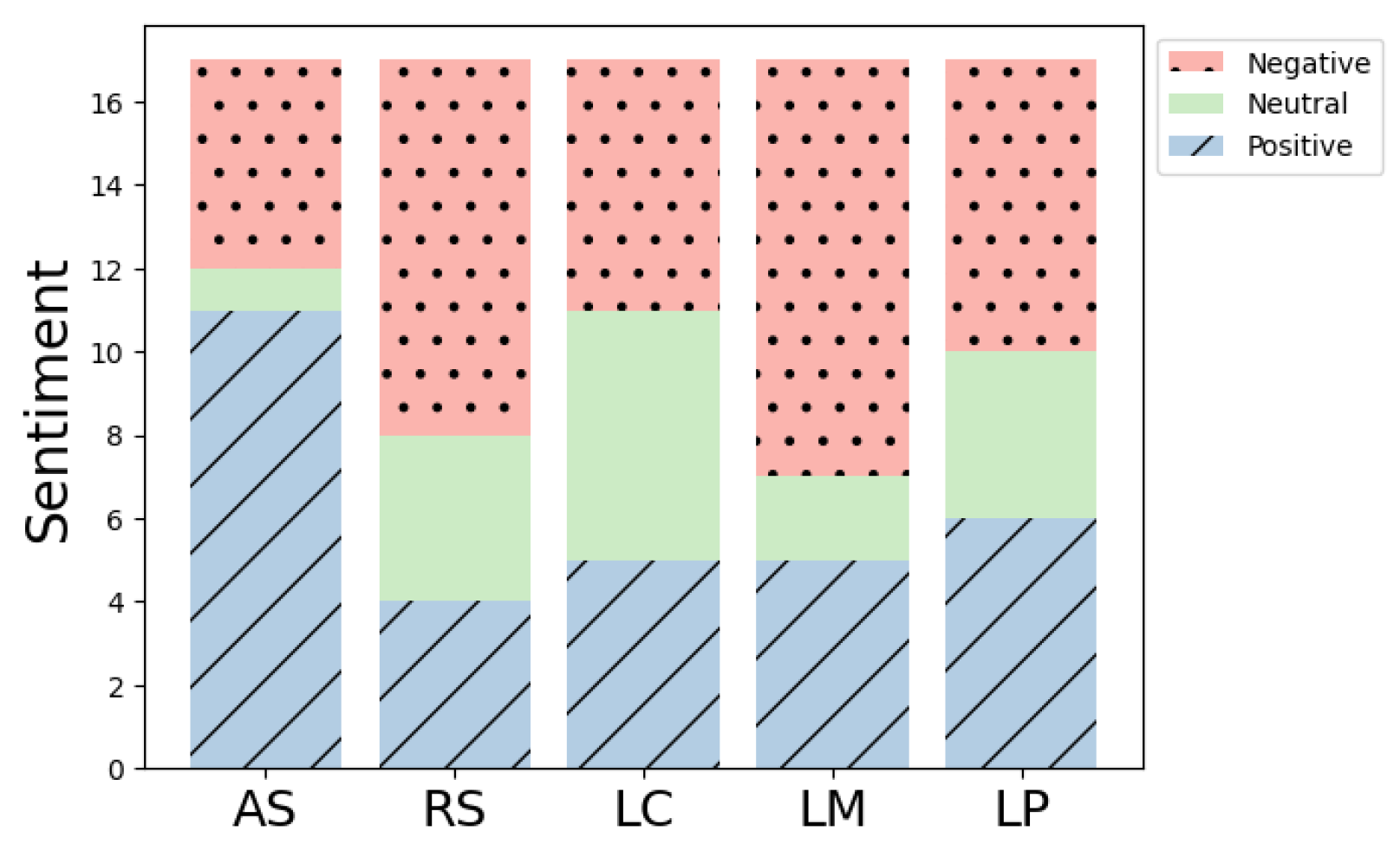
- Interpersonal skill: There were significant differences between AS and LC conditions and AS and RS conditions (p = 0.005 and p = 0.003, respectively). However, there were no statistical differences between other conditions (See Figure 5a).
- Social presence: There were significant differences between AS and RS conditions and AS and LP conditions (p = 0.004 and p = 0.001 respectively). However, there were no statistical differences between other conditions (See Figure 5b).
- Attention: There were significant differences between AS and RS conditions and AS and LP conditions (p = 0.004 and p = 0.001 respectively). However, there were no statistical differences between other conditions (See Figure 5c).
- Co-presence: There were significant differences between AS and RS conditions, AS and LP conditions, and AS and LC conditions (p < 0.001, p < 0.001, and p = 0.004 respectively). However, there were no statistical differences between other conditions (See Figure 5d).
- Competence: There was a significant difference between AS and LC conditions (p = 0.003). However, there were no statistical differences between other conditions (See Figure 5e).
- Positive attitude and Negative attitude: In these constructs, no differences between conditions were found.
3.4.2. Objective Measurements
3.5. Discussion
4. Experiment 2
4.1. CRAFT
4.2. Method
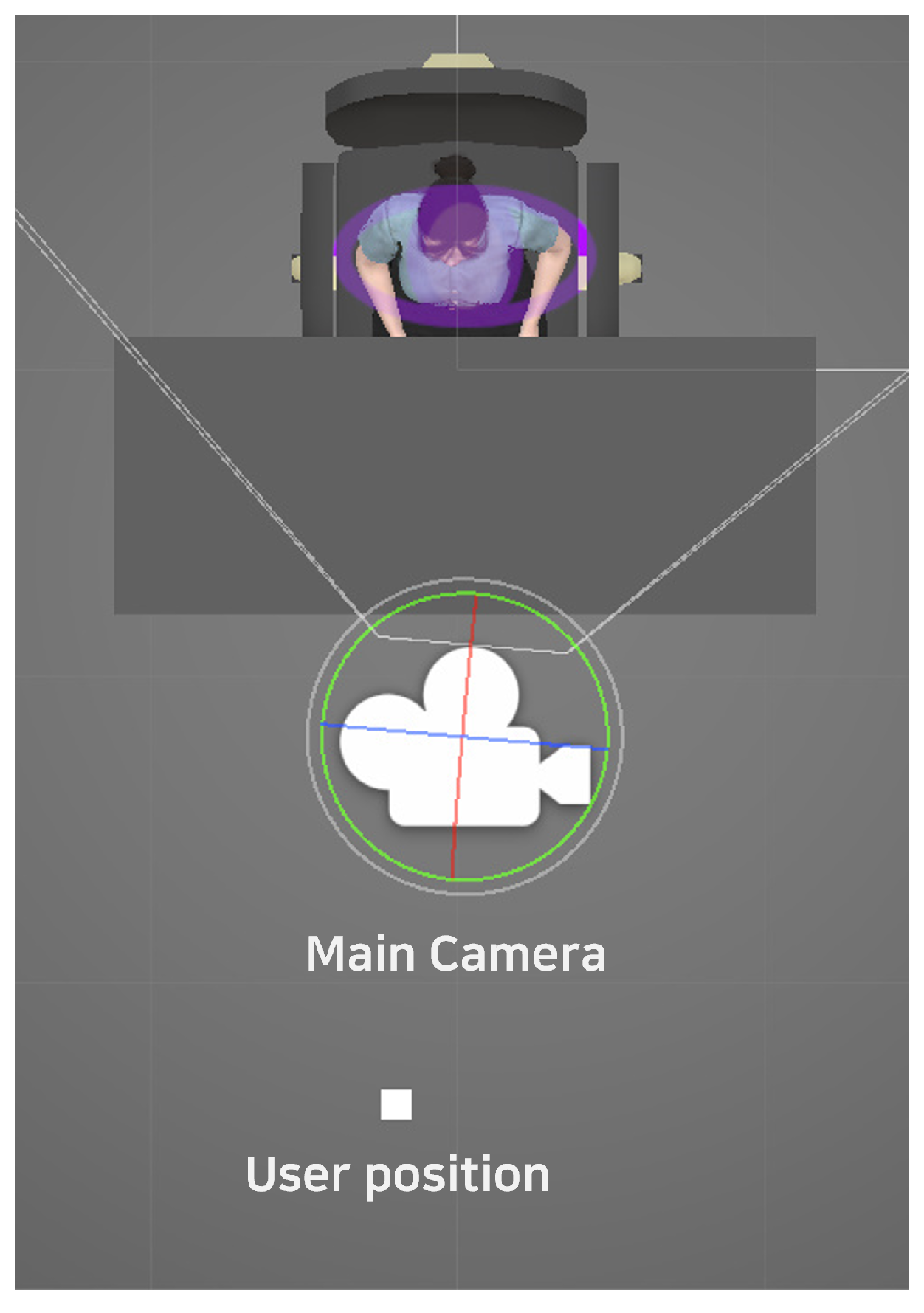
4.2.1. Materials
4.2.2. Procedure
4.3. Measurements
4.4. Participants
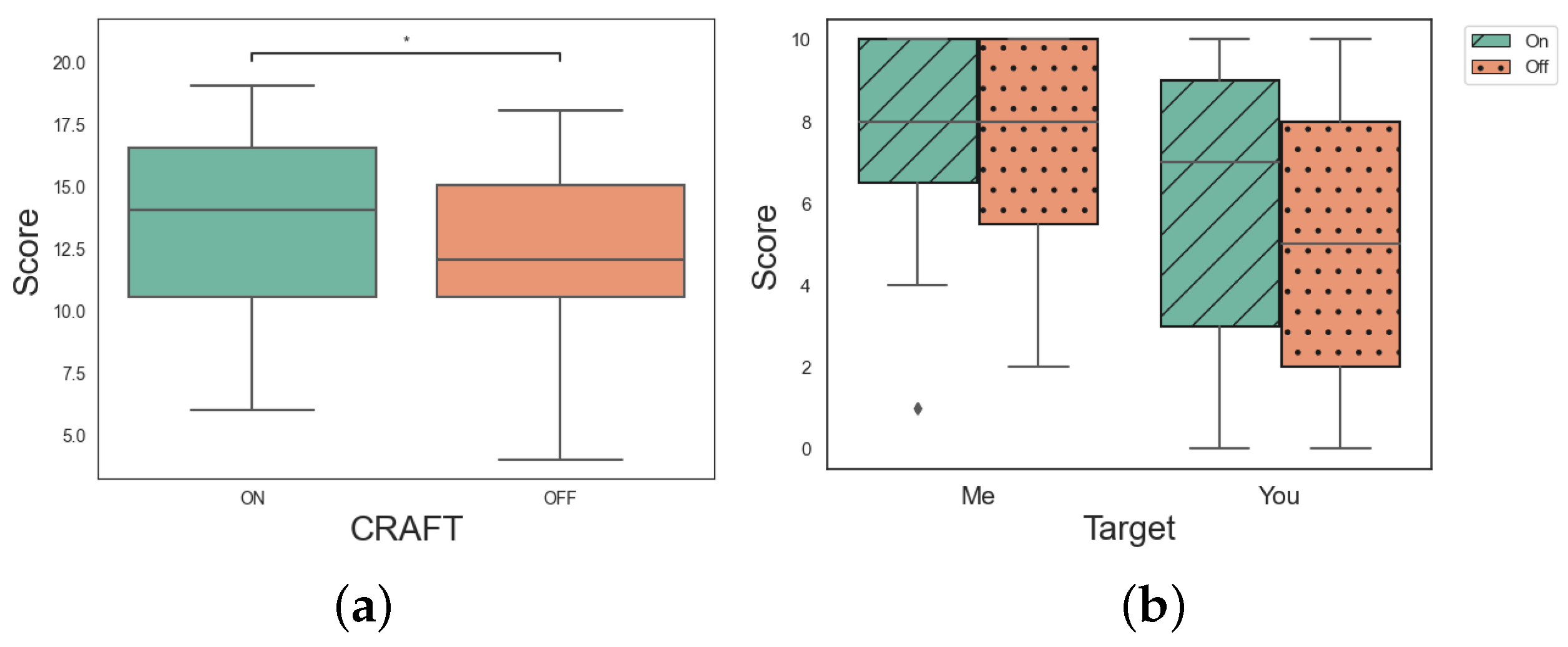
4.5. Results
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- DeVault, D.; Artstein, R.; Benn, G.; Dey, T.; Fast, E.; Gainer, A.; Georgila, K.; Gratch, J.; Hartholt, A.; Lhommet, M.; et al. SimSensei Kiosk: A virtual human interviewer for healthcare decision support. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014; pp. 1061–1068. [Google Scholar]
- Swartout, W.; Traum, D.; Artstein, R.; Noren, D.; Debevec, P.; Bronnenkant, K.; Williams, J.; Leuski, A.; Narayanan, S.; Piepol, D.; et al. Ada and Grace: Toward realistic and engaging virtual museum guides. In Proceedings of the Intelligent Virtual Agents: 10th International Conference, IVA 2010, Philadelphia, PA, USA, 20–22 September 2010; Proceedings 10. Springer: Berlin/Heidelberg, Germany, 2010; pp. 286–300. [Google Scholar]
- Cassell, J.; Stocky, T.; Bickmore, T.; Gao, Y.; Nakano, Y.; Ryokai, K.; Tversky, D.; Vaucelle, C.; Vilhjálmsson, H. Mack: Media lab autonomous conversational kiosk. In Proceedings of the IMAGINA 2002, Monte Carlo, Monaco, 12–15 February 2002; Volume 2, pp. 12–15. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Turabzadeh, S.; Meng, H.; Swash, R.M.; Pleva, M.; Juhar, J. Facial expression emotion detection for real-time embedded systems. Technologies 2018, 6, 17. [Google Scholar] [CrossRef]
- Jun, H.; Bailenson, J. Effects of behavioral and anthropomorphic realism on social influence with virtual humans in AR. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Recife, Brazil, 9–13 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 41–44. [Google Scholar]
- Cassell, J.; Thorisson, K.R. The power of a nod and a glance: Envelope vs. emotional feedback in animated conversational agents. Appl. Artif. Intell. 1999, 13, 519–538. [Google Scholar] [CrossRef]
- Aneja, D.; Hoegen, R.; McDuff, D.; Czerwinski, M. Understanding conversational and expressive style in a multimodal embodied conversational agent. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–10. [Google Scholar]
- Ruhland, K.; Peters, C.E.; Andrist, S.; Badler, J.B.; Badler, N.I.; Gleicher, M.; Mutlu, B.; McDonnell, R. A review of eye gaze in virtual agents, social robotics and hci: Behaviour generation, user interaction and perception. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015; Volume 34, pp. 299–326. [Google Scholar]
- Moubayed, S.A.; Edlund, J.; Beskow, J. Taming Mona Lisa: Communicating gaze faithfully in 2D and 3D facial projections. Acm Trans. Interact. Intell. Syst. (TiiS) 2012, 1, 1–25. [Google Scholar] [CrossRef]
- Fitzpatrick, K.K.; Darcy, A.; Vierhile, M. Delivering cognitive behavior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent (Woebot): A randomized controlled trial. JMIR Ment. Health 2017, 4, e7785. [Google Scholar] [CrossRef] [PubMed]
- Denecke, K.; Vaaheesan, S.; Arulnathan, A. A mental health chatbot for regulating emotions (SERMO)-concept and usability test. IEEE Trans. Emerg. Top. Comput. 2020, 9, 1170–1182. [Google Scholar] [CrossRef]
- Rapp, A.; Curti, L.; Boldi, A. The human side of human-chatbot interaction: A systematic literature review of ten years of research on text-based chatbots. Int. J. Hum.-Comput. Stud. 2021, 151, 102630. [Google Scholar] [CrossRef]
- Følstad, A.; Skjuve, M.; Brandtzaeg, P.B. Different chatbots for different purposes: Towards a typology of chatbots to understand interaction design. In Proceedings of the Internet Science: INSCI 2018 International Workshops, St. Petersburg, Russia, 24–26 October 2018; Revised Selected Papers 5. Springer: Cham, Switzerland, 2019; pp. 145–156. [Google Scholar]
- Jain, M.; Kumar, P.; Kota, R.; Patel, S.N. Evaluating and informing the design of chatbots. In Proceedings of the 2018 Designing Interactive Systems Conference, Hong Kong, China, 9–13 June 2018; pp. 895–906. [Google Scholar]
- Zamora, J. I’m sorry, dave, i’m afraid i can’t do that: Chatbot perception and expectations. In Proceedings of the 5th International Conference on Human Agent Interaction, Bielefeld, Germany, 17–20 October 2017; pp. 253–260. [Google Scholar]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef] [PubMed]
- Broadbent, E.; Kumar, V.; Li, X.; Sollers, J., 3rd; Stafford, R.Q.; MacDonald, B.A.; Wegner, D.M. Robots with display screens: A robot with a more humanlike face display is perceived to have more mind and a better personality. PLoS ONE 2013, 8, e72589. [Google Scholar] [CrossRef]
- Luo, J.; McGoldrick, P.; Beatty, S.; Keeling, K.A. On-screen characters: Their design and influence on consumer trust. J. Serv. Mark. 2006, 20, 112–124. [Google Scholar] [CrossRef]
- Freigang, F.; Klett, S.; Kopp, S. Pragmatic multimodality: Effects of nonverbal cues of focus and certainty in a virtual human. In Proceedings of the Intelligent Virtual Agents: 17th International Conference, IVA 2017, Stockholm, Sweden, 27–30 August 2017; Proceedings 17. Springer: Cham, Switzerland, 2017; pp. 142–155. [Google Scholar]
- He, Y.; Pereira, A.; Kucherenko, T. Evaluating data-driven co-speech gestures of embodied conversational agents through real-time interaction. In Proceedings of the 22nd ACM International Conference on Intelligent Virtual Agents, Würzburg, Germany, 19–22 September 2022; pp. 1–8. [Google Scholar]
- Poggi, I.; Pelachaud, C.; de Rosis, F.; Carofiglio, V.; De Carolis, B. Greta. a believable embodied conversational agent. In Multimodal Intelligent Information Presentation; Springer: Dordrecht, The Netherlands, 2005; pp. 3–25. [Google Scholar]
- Becker, C.; Kopp, S.; Wachsmuth, I. Simulating the emotion dynamics of a multimodal conversational agent. In Proceedings of the Tutorial and Research Workshop on Affective Dialogue Systems, Kloster Irsee, Germany, 14–16 June 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 154–165. [Google Scholar]
- Ehret, J.; Bönsch, A.; Aspöck, L.; Röhr, C.T.; Baumann, S.; Grice, M.; Fels, J.; Kuhlen, T.W. Do prosody and embodiment influence the perceived naturalness of conversational agents’ speech? ACM Trans. Appl. Percept. (TAP) 2021, 18, 1–15. [Google Scholar] [CrossRef]
- Argyle, M.; Cook, M. Gaze and Mutual Gaze; Cambridge University Press: Cambridge, UK, 1976. [Google Scholar]
- Kendon, A. Conducting Interaction: Patterns of Behavior in Focused Encounters; CUP Archive: Cambridge, UK, 1990; Volume 7. [Google Scholar]
- Ding, Y.; Zhang, Y.; Xiao, M.; Deng, Z. A multifaceted study on eye contact based speaker identification in three-party conversations. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3011–3021. [Google Scholar]
- Kendon, A. Some functions of gaze-direction in social interaction. Acta Psychol. 1967, 26, 22–63. [Google Scholar] [CrossRef] [PubMed]
- Abele, A. Functions of gaze in social interaction: Communication and monitoring. J. Nonverbal Behav. 1986, 10, 83–101. [Google Scholar] [CrossRef]
- Al Moubayed, S.; Skantze, G. Turn-taking control using gaze in multiparty human-computer dialogue: Effects of 2d and 3d displays. In Proceedings of the International Conference on Audio-Visual Speech Processing 2011, Volterra, Italy, 31 August–3 September 2011; KTH Royal Institute of Technology: Stockholm, Sweden, 2011; pp. 99–102. [Google Scholar]
- Otsuka, K. MMSpace: Kinetically-augmented telepresence for small group-to-group conversations. In Proceedings of the 2016 IEEE Virtual Reality (VR), Greenville, SC, USA, 19–23 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 19–28. [Google Scholar]
- Vázquez, M.; Milkessa, Y.; Li, M.M.; Govil, N. Gaze by Semi-Virtual Robotic Heads: Effects of Eye and Head Motion. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; IEEE: Piscataway, NJ, USA, 2020; pp. 11065–11071. [Google Scholar]
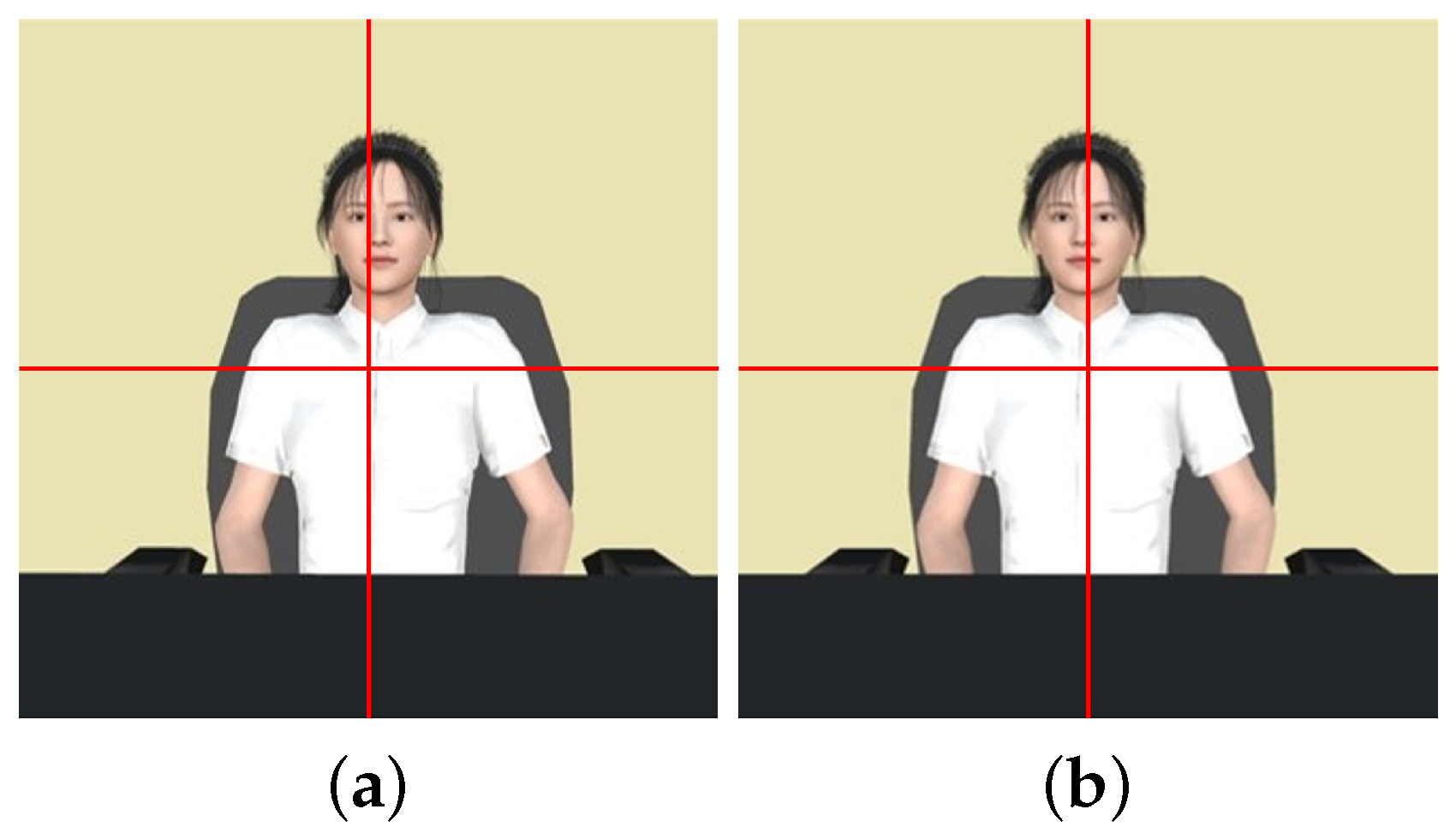
- Wu, H.H.; Mitake, H.; Hasegawa, S. Eye-Gaze Control of Virtual Agents Compensating Mona Lisa Effect. In Proceedings of the HAI: Human-Agent Interaction Symposium, Southampton, UK, 15–18 December 2018. [Google Scholar]
- Green, P.; Wei-Haas, L. The rapid development of user interfaces: Experience with the Wizard of Oz method. In Proceedings of the Human Factors Society Annual Meeting, Baltimore, MD, USA, 29 September–3 October 1985; SAGE Publications Sage CA: Los Angeles, CA, USA, 1985; Volume 29, pp. 470–474. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3fd: Single shot scale-invariant face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar]
- Kanda, T.; Kamasima, M.; Imai, M.; Ono, T.; Sakamoto, D.; Ishiguro, H.; Anzai, Y. A humanoid robot that pretends to listen to route guidance from a human. Auton. Robot. 2007, 22, 87–100. [Google Scholar] [CrossRef]
- Syrdal, D.S.; Dautenhahn, K.; Koay, K.L.; Walters, M.L. The negative attitudes towards robots scale and reactions to robot behaviour in a live human-robot interaction study. In Adaptive and Emergent Behaviour and Complex Systems, Proceedings of the 23rd Convention of the Society for the Study of Artificial Intelligence and Simulation of Behaviour, Edinburgh, UK, 6–9 April 2009; Society for the Study of Artificial Intelligence and the Simulation of Behaviour: Voluntari, Romania, 2009. [Google Scholar]
- Oh, S.Y.; Bailenson, J.; Krämer, N.; Li, B. Let the avatar brighten your smile: Effects of enhancing facial expressions in virtual environments. PLoS ONE 2016, 11, e0161794. [Google Scholar] [CrossRef] [PubMed]
- Bailenson, J.N.; Blascovich, J.; Beall, A.C.; Loomis, J.M. Interpersonal distance in immersive virtual environments. Personal. Soc. Psychol. Bull. 2003, 29, 819–833. [Google Scholar] [CrossRef] [PubMed]
- Harms, C.; Biocca, F. Internal consistency and reliability of the networked minds measure of social presence. In Proceedings of the Seventh Annual International Workshop: Presence, Valencia, Spain, 13–15 October 2004; Volume 2004. [Google Scholar]
- Carpinella, C.M.; Wyman, A.B.; Perez, M.A.; Stroessner, S.J. The robotic social attributes scale (RoSAS) development and validation. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; pp. 254–262. [Google Scholar]
- Watson, D.; Clark, L.A.; Tellegen, A. Development and validation of brief measures of positive and negative affect: The PANAS scales. J. Personal. Soc. Psychol. 1988, 54, 1063. [Google Scholar] [CrossRef] [PubMed]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Cronbach, L.J. Coefficient alpha and the internal structure of tests. Psychometrika 1951, 16, 297–334. [Google Scholar] [CrossRef]
- Cohen, I.; Huang, Y.; Chen, J.; Benesty, J.; Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Ware, C.; Arthur, K.; Booth, K.S. Fish Tank Virtual Reality. In Proceedings of the INTERACT ’93 and CHI ’93 Conference on Human Factors in Computing Systems, Amsterdam The Netherlands, 24–29 April 1993; pp. 37–42. [Google Scholar] [CrossRef]
- Wang, N.; Gratch, J. Don’t just stare at me! In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; pp. 1241–1250. [Google Scholar]
- Xu, Q.; Li, L.; Wang, G. Designing engagement-aware agents for multiparty conversations. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 2233–2242. [Google Scholar]
- Uono, S.; Hietanen, J.K. Eye contact perception in the west and east: A cross-cultural study. PLoS ONE 2015, 10, e0118094. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cronbach’s | p-Value | ||
|---|---|---|---|
| NARS | 0.687 | - | - |
| Interpersonal skill | 0.945 | 20.511 | <0.001 |
| Social presence | 0.859 | 17.142 | 0.002 |
| Co-presence | 0.883 | 22.604 | <0.001 |
| Attention | 0.812 | 27.182 | <0.001 |
| Competence | 0.925 | 9.109 | 0.058 |
| Positive attitude | 0.936 | 1.247 | 0.870 |
| Negative attitude | 0.854 | 9.896 | 0.042 |
| 5-Degree | 15-Degree | ||
|---|---|---|---|
| With CRAFT | Without CRAFT | ||
| Left participant | 10 | 10 | 10 |
| Right participant | 10 | 10 | 10 |
| center | 10 | 10 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kum, J.; Jung, S.; Lee, M. The Effect of Eye Contact in Multi-Party Conversations with Virtual Humans and Mitigating the Mona Lisa Effect. Electronics 2024, 13, 430. https://doi.org/10.3390/electronics13020430
Kum J, Jung S, Lee M. The Effect of Eye Contact in Multi-Party Conversations with Virtual Humans and Mitigating the Mona Lisa Effect. Electronics. 2024; 13(2):430. https://doi.org/10.3390/electronics13020430
Chicago/Turabian StyleKum, Junyeong, Sunghun Jung, and Myungho Lee. 2024. "The Effect of Eye Contact in Multi-Party Conversations with Virtual Humans and Mitigating the Mona Lisa Effect" Electronics 13, no. 2: 430. https://doi.org/10.3390/electronics13020430